
La décision « pilotée par la donnée » commence rarement par un tableau de bord. Elle commence plus souvent par une tâche beaucoup moins visible : réunir les bonnes informations, depuis les bons sites, dans un format exploitable. Et lorsque cette collecte repose sur du copier-coller, elle devient vite lente, fragile et difficile à tenir dans la durée.
Pour les équipes commerciales, marketing, e-commerce, opérations ou recherche, le data scraping répond précisément à ce problème : transformer des pages web, des fichiers ou des contenus dispersés en données structurées. L’enjeu n’est pas seulement de gagner du temps. Il s’agit aussi d’obtenir des données plus complètes, plus propres et plus faciles à réutiliser.
💡 Dans cet article, nous revenons sur ce qu’est le data scraping, sur les limites des méthodes classiques, puis sur la manière dont l’IA change concrètement la collecte de données avec des outils comme Thunderbit.
Qu’est-ce que le Data Scraping ?
Le data scraping, aussi appelé web scraping, consiste à extraire automatiquement des informations depuis des pages web pour les organiser dans un format structuré, le plus souvent sous forme de tableau. Au lieu de copier les données une par une, vous laissez un outil repérer les champs utiles, les collecter, puis les préparer pour l’analyse ou l’export.
Les usages sont très variés. Une équipe commerciale peut récupérer des données publiques depuis Google Maps pour enrichir une liste de prospects locaux. Un vendeur e-commerce peut extraire des SKU, des prix ou des descriptions depuis Amazon pour suivre un marché. Une équipe expérience client peut analyser les avis publiés sur Yelp afin d’identifier les irritants récurrents.
Dans tous les cas, le principe reste le même : partir d’une information visible ou accessible, puis la rendre exploitable sans travail manuel répétitif.
Le tournant technologique du Data Scraping
Pendant longtemps, le scraping a été perçu comme un sujet technique : scripts Python, sélecteurs XPath, maintenance régulière et intervention d’un développeur dès qu’un site changeait de structure. L’autre option, dans beaucoup d’équipes métier, était encore plus simple mais moins soutenable : ouvrir une page, copier les champs, coller dans un tableur, recommencer.
En 2025, ce modèle montre clairement ses limites. Les sites sont plus dynamiques, les contenus sont plus variés et les besoins métier vont plus vite que les cycles de développement internes.
Les méthodes traditionnelles montrent leurs limites
Les sites modernes compliquent la collecte : contenu chargé avec React ou Vue, pages qui changent selon le contexte, formats hétérogènes, images, PDF, vidéos, blocs de texte non structurés. Les méthodes traditionnelles de web scraping restent utiles dans certains cas, mais elles rencontrent trois difficultés majeures.
-
Une maintenance coûteuse Les scrapers classiques dépendent souvent de sélecteurs précis. Dès qu’un site modifie son front-end, une partie de la collecte casse. En pratique, la maintenance peut représenter 3 à 5 heures par mois et par site, et jusqu’à 60 % des sélecteurs XPath peuvent cesser de fonctionner après une refonte ou un changement de framework. Les outils appuyés sur l’IA et les modèles de langage comprennent mieux la structure sémantique des pages : ils peuvent s’adapter automatiquement à près de 90 % des changements structurels et réduire les coûts de maintenance de 60 à 80 %. Sur des sites React ou Vue, cette compréhension sémantique aide aussi à maintenir la collecte même lorsque les noms de classes changent.
-
Un périmètre de données trop étroit Les approches classiques extraient surtout des champs bien balisés. Elles passent plus facilement à côté de données importantes comme :
- les informations présentes dans des images
- le texte inclus dans des articles longs
- les contenus non structurés qui ne suivent pas une hiérarchie HTML propre
-
Une qualité de données inégale Le contenu dynamique crée souvent des trous dans les jeux de données :
- sur des listes paginées, comme des catalogues e-commerce, les scrapers classiques ne récupèrent parfois que 30 à 50 % du contenu visible au premier écran ;
- sur des pages à défilement infini, plus de 60 % des données critiques peuvent être manquées ;
- sur des listes mal structurées, les champs peuvent être mal associés entre eux, ce qui produit des lignes incomplètes ou incohérentes.
C’est précisément dans ces zones grises que les outils de scraping pilotés par l’IA deviennent intéressants. Ils ne remplacent pas le besoin de cadrer correctement une collecte, mais ils abaissent fortement la barrière technique.
L’essor du data scraping par l’IA
Extraire des données depuis n’importe quel site grâce à l’IA Get Started Free
Les grands modèles de langage (LLM) ont changé la manière dont les outils comprennent une page web. Ils ne se limitent plus à repérer une balise ou une classe CSS : ils peuvent interpréter le rôle d’un bloc, reconnaître un prix, distinguer une description produit d’un avis client ou proposer une structure de colonnes.
Après avoir testé 13 outils de data scraping ces derniers mois, je recommande Thunderbit AI Web Scraper pour les équipes qui veulent collecter des données sans construire toute une infrastructure technique.
Voici ce qui fait la différence.
-
Une configuration en langage naturel Vous pouvez décrire les données attendues avec des instructions simples. Thunderbit génère ensuite un plan d’extraction, ce qui réduit le temps de configuration de 87 % par rapport à des outils plus traditionnels.
-
Une extraction au plus près du navigateur Comme Thunderbit fonctionne sous forme d’extension de navigateur, il peut travailler sur les pages que vous consultez déjà :
- extraction rapide des données visibles ou accessibles dans la page
- prise en charge de contenus dynamiques et de pages à défilement infini
- collecte sur des pages auxquelles vous avez accès depuis votre session de navigateur
-
Un traitement multimodal Thunderbit peut aussi traiter des contenus qui ne se présentent pas comme de simples tableaux HTML :
- extraction de texte depuis des articles
- extraction de tableaux financiers depuis des PDF
- reconnaissance d’informations dans plusieurs images et conversion en tableau
- extraction et résumé de sous-titres vidéo
Ce changement est important pour les équipes métier : vous pouvez passer d’une page ou d’un document à une table utilisable, sans écrire de scraper sur mesure pour chaque cas.
Comment faire du Data Scraping avec l’IA
Voici le parcours de base pour utiliser les capacités de web scraping par IA de Thunderbit.
-
Installez l’extension de navigateur Rendez-vous sur le site de Thunderbit, installez l’extension depuis le Chrome Web Store, puis épinglez-la dans la barre d’outils. L’objectif est de pouvoir lancer une extraction directement depuis la page que vous analysez.
-
Créez un compte et utilisez les crédits d’essai Depuis l’extension, créez votre compte pour obtenir des crédits gratuits. Vous pouvez tester les fonctions clés, notamment le web scraping IA, l’auto-remplissage de formulaires et la synthèse intelligente. Avant de consommer vos crédits sur un vrai workflow, il est utile de faire un premier essai dans le playground pour vérifier le résultat attendu.
-
Lancez l’extraction intelligente Ouvrez un modèle depuis la barre latérale de Thunderbit, décrivez les données à récupérer, précisez le format souhaité si nécessaire, puis ajustez les paramètres. Il ne reste plus qu’à lancer l’extraction.
Fonctionnalités avancées de scraping (formule Pro)
Avec la formule Pro de Thunderbit, ou pendant un essai gratuit, vous pouvez utiliser des fonctions plus avancées pour traiter des cas de collecte plus complexes.
-
Traitement multimodal des données Thunderbit gère des cas comme l’analyse de documents PDF, par exemple des rapports financiers ou des manuels produits, l’extraction de données depuis des images comme des étiquettes de prix ou des fiches techniques, ainsi que l’extraction de sous-titres vidéo. Les données non structurées sont ensuite standardisées pour être plus faciles à exploiter.
-
Scraping approfondi des sous-pages Vous pouvez demander à Thunderbit d’ouvrir les liens secondaires d’une page, par exemple des pages détaillées de produits ou des pages d’avis clients, puis d’identifier les informations associées et de les fusionner dans le tableau principal. C’est particulièrement utile pour les catalogues e-commerce, les annonces immobilières ou les annuaires publics où les informations sont réparties sur plusieurs niveaux.
-
Bibliothèque de modèles prêts à l’emploi La bibliothèque de modèles couvre plus de 30 plateformes, dont TikTok, Amazon et Zillow. Ces modèles sont optimisés pour les structures courantes et s’adaptent aux évolutions des pages. Pour les nouveaux utilisateurs, le gain moyen de configuration atteint 83 %.
-
Tâches de scraping en masse Vous pouvez lancer plusieurs extractions en parallèle et importer des listes d’URL pour traiter des volumes plus importants.
-
Gestion intelligente de la pagination Thunderbit reconnaît les contenus paginés, les boutons « charger plus » et les pages à défilement infini. Des tests ont montré une extraction complète de plus de 200 pages de listes de produits e-commerce.
Guide pratique Thunderbit
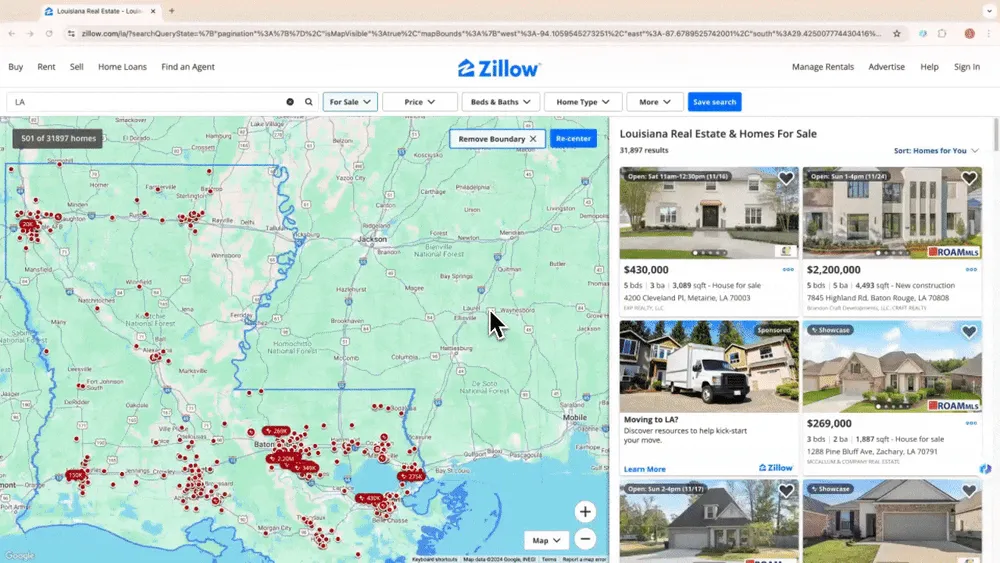
Scénario 1 : collecte de données immobilières
Pour un agent immobilier, un investisseur ou une équipe d’analyse marché, les annonces immobilières changent vite : prix, surface, localisation, statut, photos, détails du bien. Un web scraper IA peut vous aider à réunir ces informations depuis Zillow afin de suivre les opportunités, comparer les biens et éviter les saisies manuelles. La vidéo tutorielle montre comment scraper Zillow avec Thunderbit.
Scénario 2 : prospection de talents et de clients
Pour les équipes RH, sales ou partenariats, la difficulté n’est pas seulement de trouver des contacts : c’est de transformer des informations dispersées en listes propres. Thunderbit peut extraire des informations utiles depuis des sites publics, des annuaires d’entreprises, des pages de profils professionnels, des job boards ou des pages de contact, puis les organiser pour faciliter la qualification. Pour un workflow prêt à l’emploi, commencez avec le Website Contact Scraper.
Scénario 3 : analyse de marché et ciblage client
Si vous analysez une zone géographique, préparez une campagne locale ou cherchez des entreprises dans une catégorie précise, les données de cartes et d’annuaires sont souvent précieuses. Thunderbit permet d’extraire des informations clés depuis Google Maps, puis de les exploiter pour prioriser des segments, enrichir une base de prospection ou comparer des zones commerciales.
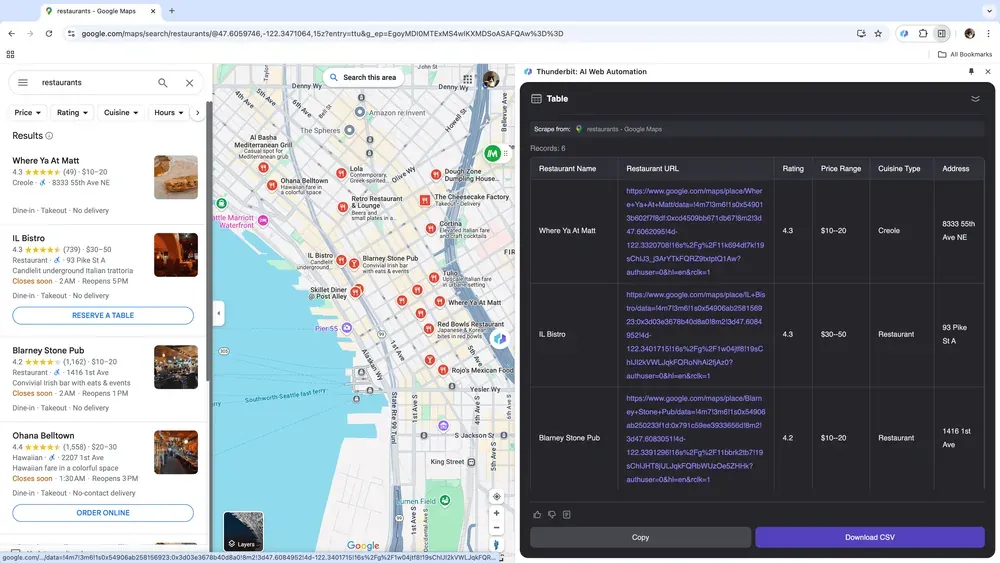
Scénario 4 : analyse des données e-commerce
Pour un vendeur en ligne, un category manager ou une équipe marketplace, le scraping aide à suivre les prix, les descriptions, les variations de produits et les avis concurrents. Thunderbit peut collecter des données produits depuis Amazon, notamment les descriptions détaillées, les prix et les avis clients.
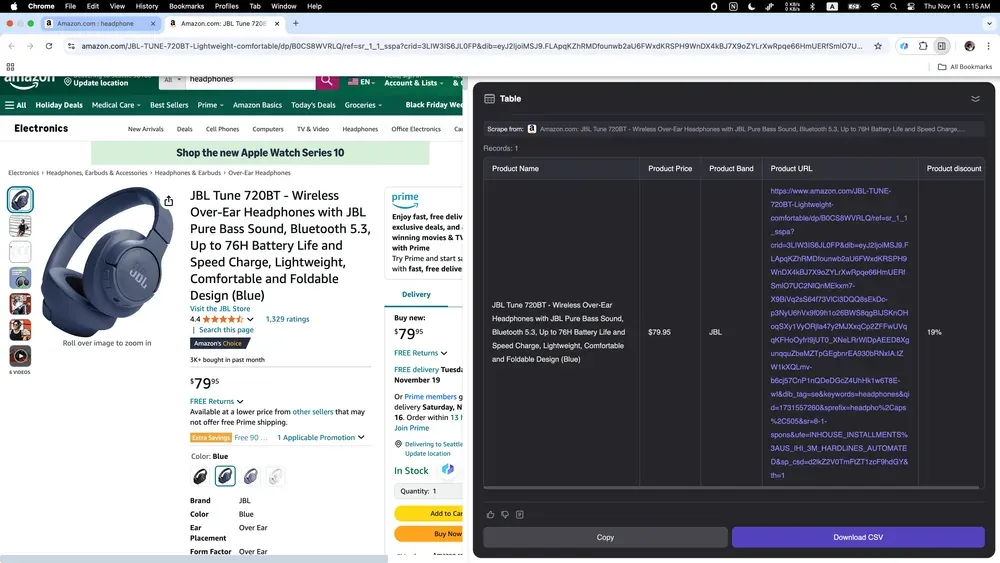
Le point commun de ces scénarios est simple : les données existent déjà, mais elles ne sont pas encore dans un format de travail. Thunderbit réduit ce passage entre la page web et le tableau exploitable, que vous travailliez sur des annonces immobilières, des contacts professionnels, des données locales ou des catalogues e-commerce.
Essayer le web scraper IA de Thunderbit
Conseils exclusifs pour le nettoyage des données
Avec beaucoup de scrapers traditionnels, le travail ne s’arrête pas à l’extraction. Il faut ensuite nettoyer les lignes, harmoniser les champs, corriger les formats et vérifier les incohérences. L’IA de Thunderbit peut effectuer une partie de ce nettoyage pendant l’extraction grâce aux LLM, avec une réduction de charge annoncée de 83 %. Voici les cas les plus utiles.
Conseil 1 : alignement intelligent des champs
Lorsque vous traitez des données hétérogènes issues de plusieurs sources, par exemple des annonces immobilières et des catalogues produits, Thunderbit peut créer des correspondances sémantiques :
- il identifie les équivalences entre champs provenant de sources différentes, par exemple « price » ↔ « 售价 » ↔ « Price »
- il fusionne les champs similaires, par exemple « area » et « square feet »
- il standardise les données entre plateformes, par exemple en rapprochant un statut de bien immobilier, une disponibilité produit ou une catégorie d’annonce sous des étiquettes cohérentes
Conseil 2 : complétion contextuelle
Grâce aux capacités de compréhension contextuelle des grands modèles de langage, Thunderbit atteint un taux de remplissage des données de 99 %, parmi les meilleurs du secteur :
- Complétion d’adresse : remplit automatiquement la ville et l’État à partir du code postal, par exemple 10001 → New York City, NY
- Déduction de catégorie : propose une catégorie ou un segment à partir du contenu d’une annonce publique, d’une fiche entreprise ou d’une description produit
Conseil 3 : optimisation des données
- Traduction multilingue, avec prise en charge de la traduction en temps réel dans 12 langues, dont l’anglais, le chinois et le japonais
- Synthèse intelligente, par exemple condenser une description produit de 500 mots en trois arguments clés
- Harmonisation des unités, comme la conversion pieds carrés ↔ mètres carrés ou Fahrenheit ↔ Celsius
- Standardisation du format, par exemple dates unifiées au format YYYY-MM-DD et devise unifiée en USD
Conseil 4 : vérification de la qualité
- Correction intelligente des erreurs : corrige automatiquement les erreurs de format, par exemple numéro de téléphone +01 138-1234-5678 → +113812345678
- Validation logique : vérifie que l’« année de construction » est antérieure à la « date de dernière rénovation »
Conseil 5 : étiquetage par IA
Thunderbit peut générer automatiquement des tags grâce au traitement du langage naturel :
- tags d’analyse de sentiment, avec classification des avis clients en positif, négatif ou neutre
- tags de valeur commerciale, par exemple « prospects à fort potentiel » ou « biens à relancer »
- tags de classification sectorielle, comme « tech | finance | healthcare », appliqués à des fiches d’entreprise ou à des annuaires publics
Les inconvénients du data scraping
Le data scraping reste un outil puissant, mais il doit être utilisé avec méthode. Les questions juridiques sont centrales : le RGPD en Europe et le CCPA aux États-Unis imposent des exigences strictes sur la collecte, le traitement et la conservation des données. Les équipes doivent donc vérifier les bases légales, respecter les conditions d’utilisation des sites et éviter toute collecte de données sensibles ou non autorisées.
Il existe aussi des limites techniques. Certains sites utilisent Cloudflare ou d’autres protections pour détecter et bloquer les comportements automatisés, notamment via des restrictions d’IP. Même avec un bon outil, une collecte doit rester proportionnée, documentée et alignée avec les règles de conformité de l’entreprise.
L’avenir du data scraping à l’ère de l’IA
L’IA fait évoluer le web scraping vers une expérience plus proche d’un assistant métier. Vous pourriez indiquer un domaine, comme zillow.com, puis formuler une demande du type : « extraire toutes les annonces immobilières à New York ». L’outil cartographierait ensuite les champs pertinents, des caractéristiques du bien aux tendances de prix, sans configuration manuelle lourde.
La prochaine étape sera l’intégration plus fluide des données collectées dans les workflows : fiches prospects envoyées vers un CRM, indicateurs e-commerce transmis à un tableau de bord, surveillance de stock, suivi de prix ou détection de nouvelles tendances de marché. Les capacités de reconnaissance de modèles permettront aussi d’aller vers un scraping plus prédictif, capable d’alerter lorsque des signaux changent.
Le sujet conformité prendra également plus de place. Les systèmes les plus utiles seront ceux qui aident à adapter les paramètres d’extraction, à conserver des journaux d’audit et à documenter les décisions. Pour les organisations qui travaillent déjà avec des données web, les solutions de scraping par IA comme Thunderbit peuvent devenir un avantage opérationnel : moins de collecte manuelle, plus de données utilisables, et des équipes capables de tester plus vite leurs hypothèses.
FAQ
-
Qu’est-ce que Thunderbit ? Thunderbit est une extension de navigateur intelligente basée sur les grands modèles de langage (LLM), conçue pour répondre aux besoins modernes de collecte de données. Elle propose des fonctions de web scraping IA et de traitement multimodal pour extraire des données depuis des pages web dynamiques, des PDF, des images et des vidéos. Comme elle fonctionne dans le navigateur, elle peut travailler sur les pages auxquelles vous avez accès dans votre session et s’adapter aux évolutions des frameworks front-end modernes.
-
Comment fonctionne le web scraper IA de Thunderbit ? Le web scraper IA de Thunderbit utilise l’IA pour extraire des données structurées depuis des sites web. Vous pouvez cliquer sur « AI Suggest Columns » pour laisser l’IA proposer la meilleure structure d’extraction pour la page actuelle, puis sur « Scrape » pour collecter les données. En deux clics, l’outil peut traiter des données provenant d’un site, d’un PDF ou d’une image.
-
Quelle est la différence entre le scraping de listes et le scraping de sous-pages ? Le scraping de listes est conçu pour les scénarios paginés, comme les listes de produits e-commerce : il reconnaît la logique de pagination et extrait de nombreuses lignes de données. Le scraping de sous-pages suit une structure arborescente, par exemple annonces Zillow → pages détaillées → plans d’étage, puis relie automatiquement la table principale et les informations de détail grâce à l’association sémantique.
-
Les non-programmeurs peuvent-ils utiliser Thunderbit ? Oui. Thunderbit repose sur une interaction en langage naturel : vous décrivez simplement les champs voulus, par exemple « nom, email, téléphone », et le système génère un plan d’extraction. Les données de test indiquent que 85 % des utilisateurs terminent leur première collecte en moins de 10 minutes, sans connaissance en programmation web.
-
Quels types de données Thunderbit peut-il traiter ? Thunderbit prend en charge plusieurs types de données :
- données structurées : tableaux, listes, par exemple spécifications de produits Amazon
- données non structurées : texte d’avis, documents PDF avec reconnaissance automatique
- données multimodales : étiquettes de prix dans des images, extraction de sous-titres vidéo
- données dynamiques : contenu à défilement infini, images en chargement différé
- données associées : cartographie des relations entre pages, par exemple fiche produit → avis clients → variantes
-
Comment commencer à utiliser Thunderbit ? Découvrez davantage nos capacités d’extraction ou explorez notre bibliothèque de modèles pour démarrer immédiatement.
En savoir plus :
- Les meilleurs outils et logiciels de web scraping en 2025
- Comment extraire n’importe quel site web avec l’IA
- Comment configurer Thunderbit
Essayer le web scraper IA Get Started Free




