

La croissance du web dépasse l'entendement. Chaque jour, des milliards de pages, de produits, d'avis et de jeux de données voient le jour, et viennent alimenter aussi bien l'étude de marché que l'entraînement de l'IA — sans oublier votre prochaine virée shopping sur Amazon. Après des années passées dans le SaaS et l'automatisation, j'ai constaté de mes propres yeux à quel point une donnée de qualité peut faire pencher une décision business. Mais voici le paradoxe : collecter, actualiser et interpréter toutes ces données web devient chaque jour plus ardu, et non l'inverse. Les extracteurs web traditionnels peinent à suivre, et les entreprises réclament une solution plus intelligente et plus rapide pour convertir Internet en informations exploitables. C'est précisément le rôle du cloud crawler — un outil qui transforme en silence la façon dont les organisations découvrent et exploitent les données web à grande échelle.
Mais qu'est-ce qu'un cloud crawler, au juste ? En quoi se démarque-t-il des extracteurs web que vous connaissez peut-être déjà ? Et pourquoi, des équipes commerciales aux services opérationnels, tout le monde mise sur cette technologie pour garder une longueur d'avance dans un monde piloté par la donnée ? Reprenons tout depuis le début, clarifions le jargon à la mode, et voyons comment les cloud crawlers — et en particulier la solution de Thunderbit — rebattent les cartes pour les entreprises d'aujourd'hui.
Qu'est-ce qu'un cloud crawler ? La nouvelle étape de la découverte de données
Extraire des données de n’importe quel site grâce à l’IA Get Started Free
Disons-le simplement : un cloud crawler n'est pas un banal extracteur web hébergé dans le cloud. C'est avant tout un moteur de découverte de données — un système intelligent, basé sur le cloud, conçu pour repérer, extraire et analyser automatiquement d'énormes volumes de données sur Internet. Là où un extracteur web classique collecte des informations sur quelques pages — souvent une par une, et généralement depuis une seule machine — un cloud crawler évolue dans une autre dimension. Il s'exécute dans de puissants centres de données cloud, parcourt des milliers, voire des millions de pages en parallèle, et traite indifféremment du texte, des images ou des PDF, quelle que soit la complexité ou l'ampleur du site visé.
Une comparaison pour fixer les idées : si un extracteur web fait penser à un bibliothécaire isolé qui recopie quelques passages d'un livre, un cloud crawler ressemble à une équipe de superordinateurs qui scanne tous les ouvrages de la bibliothèque en même temps, en les étiquetant, les organisant et les analysant au fil de l'eau. Le résultat ? Les entreprises récupèrent des données plus riches, plus fraîches et plus exploitables — affranchies des limites du matériel local et des manipulations manuelles (Sitebulb, Octoparse).
Cloud crawler vs extracteur web traditionnel : où est la vraie différence ?
Si vous avez déjà manié un extracteur web, le principe vous est familier : vous lui fournissez une page, vous précisez ce que vous cherchez, et il en extrait les données. Seulement, à mesure que le web grossit et se complexifie, cette approche montre ses limites. Voici comment se positionnent les cloud crawlers face aux extracteurs web traditionnels :
| Aspect/Fonction | Extracteur Web traditionnel | Cloud Crawler |
|---|---|---|
| Déploiement | Fonctionne sur votre appareil local ou serveur | Fonctionne dans le cloud (centres de données distants) |
| Échelle | Limité par la puissance de votre ordinateur | Massivement parallèle — des milliers de pages à la fois |
| Vitesse | Plus lent, surtout pour les gros volumes | Traitement par lots à haute vitesse |
| Maintenance | Nécessite des mises à jour fréquentes, casse en cas de changement du site | Basé sur le cloud, se met à jour automatiquement, moins fragile |
| Types de données | Généralement du texte, parfois des images | Texte, images, PDF, mises en page complexes |
| Accès | Lié à votre appareil/réseau | Accessible de partout, sur n’importe quel appareil |
| Planification | Manuelle ou automatisation basique | Planification avancée, tâches récurrentes |
| Idéal pour | Petits projets, sites simples | Besoins de données à grande échelle, fréquents ou complexes |
Les cloud crawlers sont taillés pour le web actuel — un environnement où la donnée est partout, et où la vitesse comme l'échelle ne se négocient pas (GPTBots, Octoparse).
Comment les cloud crawlers démultiplient l'efficacité de la collecte de données
C'est là que tout se joue. Les cloud crawlers mettent la puissance du cloud computing au service du traitement de milliers de pages web en parallèle. Concrètement, vous pouvez extraire un catalogue e-commerce entier, surveiller les prix de vos concurrents sur des dizaines de sites, ou agréger des annonces immobilières issues de tous les grands portails — le tout en une fraction du temps qu'exigerait un extracteur classique.
Pourquoi est-ce déterminant ? Parce que dans des secteurs comme l'e-commerce, la finance ou l'immobilier, la fraîcheur des données fait toute la différence. Prix, stocks et tendances du marché évoluent parfois de minute en minute. Patienter des heures, voire des jours, le temps qu'un extracteur local boucle son travail, n'a tout bonnement aucun sens. Les cloud crawlers, eux, ne dépendent ni de la RAM de votre ordinateur portable ni du Wi-Fi du bureau : ils montent en puissance à la demande, pour absorber des volumes massifs sans effort (Zyte, Octoparse).
Parmi les secteurs qui en tirent le plus grand parti :
- E-commerce : suivi des prix, agrégation de catalogues produits, analyse des avis
- Immobilier : regroupement d'annonces, suivi des tendances du marché, comparaison de biens
- Finance : analyse de l'actualité et du sentiment, suivi des actions/crypto, veille réglementaire
- Ventes & marketing : génération de leads, veille concurrentielle, détection de tendances
Et il ne s'agit là que d'un aperçu. Dès que vos besoins en données web prennent de l'ampleur, le cloud crawler s'impose vite comme un allié de poids.
La solution cloud crawler de Thunderbit : rapide, souple et puissante
Permettez-moi de chausser ma casquette Thunderbit deux secondes (à vrai dire, je ne la quitte jamais vraiment). Le mode de scraping cloud de Thunderbit est notre réponse au défi de la donnée moderne — un cloud crawler pensé pour les utilisateurs métier qui veulent des résultats, pas des complications.
Voici ce qui distingue le cloud crawler de Thunderbit :
- Scraping par lots à haute vitesse : extrayez jusqu'à 50 pages d'un coup, grâce à des serveurs cloud aux États-Unis, en Europe et en Asie pour une couverture mondiale. Fini d'attendre que votre ordinateur s'essouffle sur une longue liste.
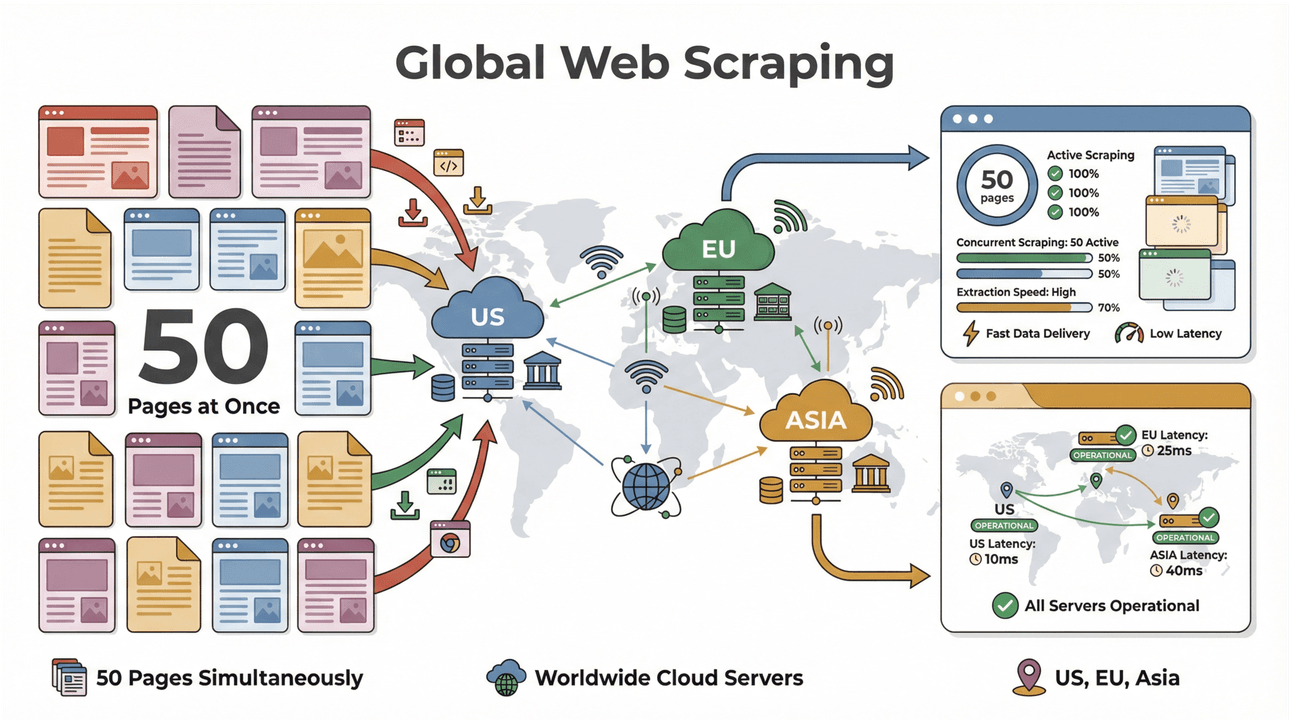
- Prise en charge des pages complexes : l'IA de Thunderbit gère aussi bien les sites e-commerce dynamiques que les PDF récalcitrants, sans oublier l'extraction d'images. Si c'est sur le web, Thunderbit saura probablement l'extraire (Thunderbit).
- Exploration des sous-pages : besoin d'enrichir vos données avec des détails nichés dans des sous-pages (fiches techniques produit, biographies d'auteurs) ? L'IA de Thunderbit visite chaque sous-page et fusionne les résultats dans votre jeu de données principal (Thunderbit).
- Structuration intelligente des données : activez « AI Suggest Fields » pour laisser Thunderbit analyser le site et recommander les meilleures colonnes — sans code ni création de modèle.
- Export partout : envoyez vos données directement vers Excel, Google Sheets, Airtable ou Notion. Ou téléchargez-les simplement en CSV/JSON — selon votre flux de travail (Thunderbit).
- Zéro maintenance : l'IA de Thunderbit s'adapte aux changements du site, ce qui vous épargne la réparation perpétuelle d'extracteurs cassés (Thunderbit).
Et oui, vous pouvez tout tester avec une formule gratuite — inutile de me croire sur parole.
Essayer gratuitement le Cloud Scraper de Thunderbit
Déployer un cloud crawler : cloud ou local, que choisir ?
L'un des plus grands atouts des cloud crawlers tient à leur souplesse de déploiement. Avec un crawler traditionnel (local), vous restez prisonnier d'un appareil précis, d'un réseau donné, et souvent d'une configuration laborieuse. Si votre ordinateur se met en veille ou si votre connexion lâche, l'extraction s'interrompt. Et pour gagner en capacité, il faut acheter du matériel supplémentaire ou multiplier les scripts.
Les cloud crawlers renversent complètement la table :
- Aucun matériel particulier requis : tout le travail lourd se déroule dans le cloud. Vous pouvez lancer d'énormes extractions depuis un Chromebook, un Mac, voire votre téléphone.
- Accès depuis n'importe où : en déplacement ? En télétravail ? Aucune importance — votre cloud crawler reste disponible en permanence.
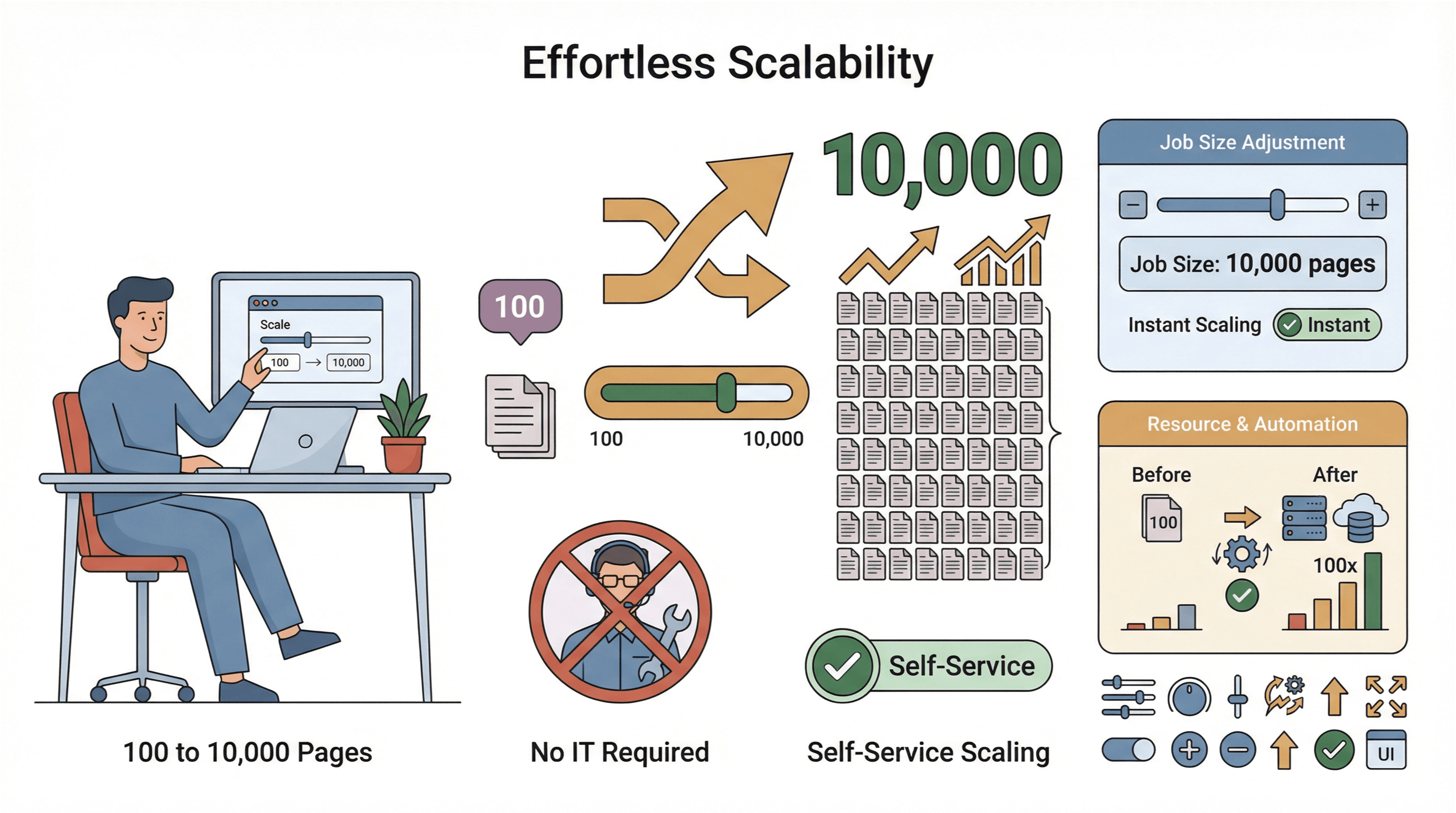
- Montée en charge sans douleur : vous devez extraire 10 000 pages plutôt que 100 ? Il suffit d'augmenter la taille du job — sans solliciter l'informatique.
- Collecte mondiale de données : avec des serveurs cloud répartis sur plusieurs régions, vous accédez à des contenus géorestreints et gérez plus aisément la conformité (PromptCloud).
Bien entendu, sécurité et conformité demeurent des priorités absolues. Les meilleurs cloud crawlers, Thunderbit compris, recourent à des connexions chiffrées, respectent les conditions d'utilisation des sites et offrent de quoi traiter les données sensibles de manière responsable.
Impact concret : comment les cloud crawlers transforment les stratégies pilotées par la donnée
Venons-en au concret. Pourquoi les entreprises basculent-elles vers les cloud crawlers ? Parce qu'elles en mesurent un impact réel et chiffrable :
- Analyse de marché en temps réel : les distributeurs surveillent prix et stocks des concurrents en temps réel, ce qui ouvre la voie à une tarification dynamique et à des réactions plus promptes aux mouvements du marché (Zyte).
- Anticipation des tendances consommateurs : les marques agrègent avis, publications sociales et discussions de forums pour capter les signaux émergents et ajuster leurs campagnes en temps réel.
- Ventes & génération de leads : les équipes commerciales constituent des listes de prospects à jour à partir d'annuaires, de sites d'événements et même de PDF — et alimentent les CRM en contacts frais et qualifiés (Thunderbit).
- Opérations & conformité : les institutions financières s'appuient sur les cloud crawlers pour suivre les évolutions réglementaires, l'actualité et les dépôts officiels dans plusieurs juridictions — réduisant les risques et anticipant les changements.
Le fil rouge ? Les cloud crawlers permettent aux équipes d'avancer plus vite, de décider mieux et de distancer des concurrents encore coincés sur la voie lente.
Les fonctionnalités essentielles à exiger d'un cloud crawler
Voir les tarifs et fonctionnalités de Thunderbit Get Started Free
Tous les cloud crawlers ne se valent pas. Si vous en comparez plusieurs, voici les fonctionnalités qui comptent le plus — et celles où Thunderbit tire son épingle du jeu :
- Scalabilité : encaisse-t-il des milliers de pages simultanément ? Ralentit-il quand les jobs gonflent ?
- Facilité d'utilisation : l'interface reste-t-elle accessible aux non-techniciens ? Peut-on lancer une extraction en quelques clics ?
- Prise en charge multiformat : texte, images, PDF, sous-pages — sait-il tout absorber ?
- Intégrations : exporte-t-il vers vos outils favoris (Excel, Sheets, Notion, Airtable) ?
- Planification : pouvez-vous programmer des tâches récurrentes pour conserver des données toujours fraîches ?
- Assistance IA : propose-t-il des suggestions intelligentes de champs, l'enrichissement des données et l'adaptation automatique aux changements du site ?
- Sécurité & conformité : vos données et identifiants sont-ils protégés ? Vous aide-t-il à rester en règle avec les lois sur la confidentialité ?
Thunderbit coche toutes ces cases, ce qui en fait une excellente option pour les équipes en quête de puissance sans la complexité.
Premiers pas : comment utiliser un cloud crawler pour votre activité
Prêt à vous lancer ? Voici comment un utilisateur métier démarre habituellement avec un cloud crawler comme Thunderbit :
- Installez l'extension Chrome Thunderbit : installation rapide, sans intervention de l'informatique.
- Choisissez votre cible : ouvrez le site, la liste ou le document à extraire.
- Cliquez sur « AI Suggest Fields » : laissez l'IA de Thunderbit analyser la page et recommander les meilleures colonnes à extraire.
- Personnalisez au besoin : ajoutez, supprimez ou renommez les champs selon vos attentes.
- Sélectionnez le mode de scraping cloud : pour les gros volumes ou les sites complexes, passez en mode cloud afin d'atteindre la vitesse maximale.
- Lancez l'extraction : Thunderbit traite jusqu'à 50 pages à la fois dans le cloud.
- Vérifiez et exportez : prévisualisez vos résultats, puis exportez vers Excel, Google Sheets, Notion ou Airtable.
- Programmez des tâches récurrentes : pour vos besoins continus, mettez en place des extractions planifiées — vos données s'actualiseront d'elles-mêmes (Thunderbit Docs).
Un conseil d'expérience : commencez par une petite tâche pour prendre vos marques, puis montez en puissance une fois à l'aise. Et n'hésitez pas à solliciter le support ou la documentation Thunderbit — ils sont là pour vous épauler.
Commencer le cloud crawling avec Thunderbit
L'avenir de la collecte de données : quelle suite pour les cloud crawlers ?
La révolution des cloud crawlers n'en est qu'à ses débuts. Voici ce que je guette pour les prochaines années :
- Extraction IA plus fine : les cloud crawlers progressent dans la compréhension du contexte, des relations et même du sentiment — de quoi rendre les données collectées encore plus précieuses (GPTBots).
- Prise en charge de nouveaux types de données : attendez-vous à une meilleure gestion de la vidéo, de l'audio et des contenus interactifs — au-delà du seul texte et des images statiques.
- Automatisation poussée à l'extrême : de la planification automatique aux alertes en temps réel, les cloud crawlers gagneront en autonomie pour les utilisateurs métier.
- Conformité renforcée : à mesure que les lois sur la vie privée évoluent, les cloud crawlers intégreront davantage d'outils pour aider les équipes à rester dans les clous.
- Intégration aux outils BI et IA : des flux directs depuis les cloud crawlers vers les plateformes d'analyse, les tableaux de bord et le machine learning.
En somme, les cloud crawlers sont bien partis pour devenir la colonne vertébrale de la stratégie numérique des entreprises — en alimentant tout, du lancement de produits aux prévisions assistées par l'IA (Thunderbit Blog).
Conclusion : pourquoi les cloud crawlers sont devenus indispensables aux entreprises modernes
En résumé : le web explose en volumes de données, et les anciennes méthodes de collecte ne tiennent plus la cadence. Les cloud crawlers marquent l'étape suivante — ils offrent une vitesse, une échelle et une intelligence que les extracteurs traditionnels ne peuvent tout simplement pas rivaliser. Des outils comme Thunderbit mettent tout le potentiel des données web à la portée de n'importe quelle équipe, technique ou non — pour décider mieux, réagir plus vite et se forger un véritable avantage concurrentiel.
Si vous êtes prêt à tourner le dos à l'extraction manuelle et aux données qui arrivent au compte-gouttes, le moment est venu d'explorer ce qu'un cloud crawler peut apporter à votre entreprise. Essayez le mode de scraping cloud de Thunderbit et mesurez à quel point la découverte de données moderne peut être simple — et puissante. Et pour aller plus loin, parcourez le Thunderbit Blog, riche en guides, conseils et exemples concrets.
FAQ
1. Qu'est-ce qu'un cloud crawler, en quelques mots ?
Un cloud crawler est un outil basé sur le cloud qui découvre, extrait et analyse automatiquement de grandes quantités de données sur le web. Contrairement aux extracteurs traditionnels qui tournent sur votre appareil local, les cloud crawlers s'exécutent dans de puissants centres de données, ce qui autorise une échelle et une vitesse considérables.
2. En quoi un cloud crawler diffère-t-il d'un extracteur web classique ?
Les cloud crawlers opèrent dans le cloud, traitent des milliers de pages en parallèle, prennent en charge des types de données complexes (images, PDF) et ne réclament ni maintenance ni matériel local. Les extracteurs classiques, eux, restent bridés par la puissance de votre appareil et conviennent davantage à des tâches plus modestes et plus simples.
3. Quels sont les principaux atouts d'un cloud crawler ?
Les cloud crawlers assurent une collecte de données rapide et à grande échelle, gèrent les sites complexes, restent accessibles de partout et proposent des fonctionnalités avancées comme la planification et l'extraction assistée par l'IA. Ils sont taillés pour les entreprises qui veulent des données fraîches et exploitables sans attendre.
4. Comment fonctionne le cloud crawler de Thunderbit pour les utilisateurs métier ?
Le cloud crawler de Thunderbit vous permet de configurer une extraction en quelques clics, sans code. Vous extrayez des données depuis des sites web, des PDF et des images, vous les enrichissez avec l'IA, puis vous les exportez directement vers Excel, Google Sheets, Notion ou Airtable. Il est conçu pour les non-techniciens qui veulent des résultats, pas de la complexité.
5. Le cloud crawling est-il sécurisé et conforme aux lois sur la protection des données ?
Oui. Les principaux cloud crawlers comme Thunderbit recourent à des connexions chiffrées et aux meilleures pratiques de sécurité des données. Veillez néanmoins à n'extraire que des données publiques et à respecter les conditions d'utilisation des sites ainsi que les réglementations sur la vie privée.
Prêt à découvrir ce qu'un cloud crawler a dans le ventre ? Téléchargez Thunderbit et lancez-vous dès aujourd'hui dans la collecte de données à grande échelle, propulsée par le cloud.
Essayez le cloud crawler Thunderbit dès aujourd’hui Get Started Free
En savoir plus
- Top 15 des meilleurs cloud crawlers IA à connaître en 2025
- Le crawling web en direct avec l’IA : guide rapide
- Les 10 meilleures options gratuites de crawler de site web en ligne pour 2025
- Comment extraire des données d’une page web avec Thunderbit
- Comment maîtriser le scraping automatisé de données avec Thunderbit




