
Soyons clairs : le web, c’est un peu la jungle qui ne cesse de s’étendre. Chaque jour, plus de 252 000 nouveaux sites web débarquent, et rien que chez Google, l’index de recherche compte déjà plus de 30 milliards de pages. Tu t’es déjà demandé comment les moteurs de recherche arrivent à suivre ce rythme effréné — ou comment les boîtes arrivent à dénicher la bonne info dans ce flot continu ? Tu n’es pas le seul. Après des années dans le SaaS et l’automatisation, on me pose encore souvent la question : « C’est quoi la différence entre exploration web et extraction de données ? Ce n’est pas pareil ? » Spoiler : pas du tout, et mélanger les deux peut te faire perdre un temps fou.
Que tu sois commercial en quête de nouveaux leads, responsable e-commerce qui surveille les prix, ou juste curieux de briller en réunion, on va voir ensemble ce que fait vraiment un web crawler, en quoi il diffère d’un extracteur, et pourquoi choisir le bon outil (coucou Thunderbit) peut t’éviter bien des galères — et peut-être même te sauver ton week-end.
Les bases du Web Crawler : c’est quoi un robot d’indexation ?

Imagine le bibliothécaire le plus pointilleux du monde, qui ne se contente pas de ranger les livres, mais qui fait le tour de chaque rayon, tous les jours, pour repérer les nouveautés. C’est exactement le job d’un robot d’indexation — sauf qu’au lieu de livres, il parcourt des milliards de pages web. Un web crawler (aussi appelé spider ou bot) est un programme automatisé qui explore le web de façon méthodique, suit les liens de page en page et note tout ce qu’il trouve. C’est comme ça que Google, Bing et compagnie construisent leurs énormes index, pour rendre le web accessible à tous.
Si tu as déjà entendu parler de « Googlebot » ou « Bingbot », ce sont juste les robots d’indexation les plus connus qui bossent dans l’ombre. Il existe aussi des outils plus récents comme Firecrawl, qui permettent aux devs et aux entreprises d’explorer des sites entiers et de transformer leur contenu en données structurées pour l’IA ou l’analyse.
Mais retiens bien : l’exploration web sert à découvrir et indexer des pages, pas à extraire des infos précises. C’est là que l’extraction web entre en scène (on y revient juste après).
Comment fonctionne l’exploration web ?
Voyons comment bosse un robot d’indexation. Imagine-le comme un explorateur digital, avec un sac à dos rempli d’« URLs de départ ». Voici son parcours, étape par étape :
- URLs de départ : Il commence avec une liste d’adresses web déjà connues.
- Récupération & Analyse : Il visite chaque URL, récupère la page et cherche de nouveaux liens dedans.
- Suivi des liens : Chaque nouveau lien trouvé est ajouté à la liste des prochaines pages à explorer.
- Indexation : Au fil de sa balade, il stocke des infos sur chaque page — parfois tout le contenu, parfois juste des métadonnées.
- Respect des règles : Il regarde le fichier robots.txt de chaque site pour savoir s’il a le droit d’explorer, et il fait des pauses entre chaque requête pour ne pas surcharger les serveurs.
- Mise à jour continue : Comme le web change tout le temps, les robots repassent régulièrement pour garder l’index à jour.
C’est un peu comme cartographier une ville en arpentant chaque rue, en notant chaque nouvelle boutique ou ruelle, et en mettant la carte à jour à chaque changement.
Les composants clés d’un Web Crawler
Même sans être un as de la technique, c’est utile de savoir ce qui se passe derrière :
- File d’attente d’URLs : La liste principale des adresses à visiter.
- Téléchargeur : Celui qui va chercher la page web.
- Analyseur (Parser) : Celui qui lit la page pour en extraire les liens (et parfois d’autres infos).
- Filtre & Déduplication : Pour éviter de tourner en rond ou de repasser deux fois sur la même page.
- Stockage/Index : Là où tout ce qui a été découvert est gardé pour plus tard.
Imagine une chaîne de montage : une personne récupère le journal, une autre surligne les titres, une troisième classe les articles, et quelqu’un d’autre tient la liste des journaux à lire ensuite.
Comment explorer un site web : outils et méthodes
Si tu bosses en entreprise, tu pourrais être tenté de créer ton propre robot d’indexation. Mon conseil ? Laisse tomber. Sauf si tu veux concurrencer Google, il existe déjà plein d’outils qui font ça très bien.
Outils populaires d’exploration web :
- Scrapy : Open source, pour les développeurs, parfait pour les gros projets.
- Apache Nutch : Utilisé pour l’indexation big data et la recherche.
- Heritrix : L’outil d’archivage du web de l’Internet Archive.
- Screaming Frog SEO Spider : Chouchou des pros du SEO pour l’audit et l’exploration de sites.
- Firecrawl : Moderne, piloté par API, permet d’explorer et d’extraire des données structurées de sites entiers.
À savoir : La plupart de ces outils demandent un peu de technique. Même les solutions « no-code » nécessitent souvent un temps d’adaptation — il faut choisir les bons éléments HTML, gérer les changements de site ou le contenu dynamique. Si tu veux juste récupérer des infos sur quelques pages, un extracteur complet n’est sûrement pas nécessaire.
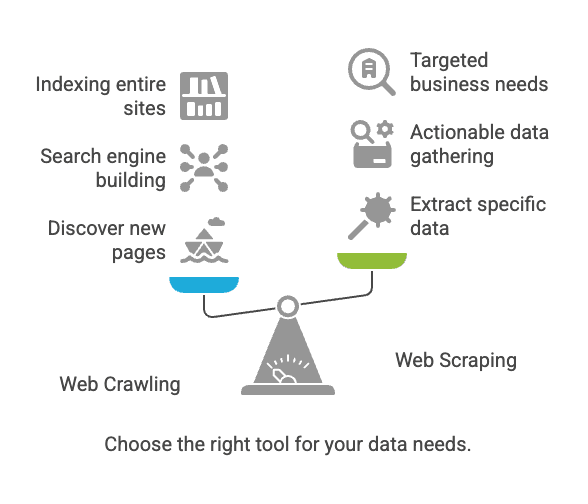
Exploration web vs. extraction web : quelle différence ?
C’est souvent là que ça coince. Exploration et extraction web sont liées, mais ce n’est pas du tout la même chose.
| Aspect | Exploration Web | Extraction Web |
|---|---|---|
| Objectif | Découvrir et indexer des pages web | Extraire des données précises des pages |
| Analogie | Bibliothécaire qui catalogue tous les livres | Copier les infos clés de quelques pages |
| Résultat | Liste d’URLs, contenu de pages, plan de site | Données structurées (CSV, Excel, JSON, etc.) |
| Utilisateurs | Moteurs de recherche, outils SEO, archivistes | Commerciaux, e-commerce, analystes, chercheurs |
| Échelle typique | Milliards de pages (large couverture) | Douzaines à milliers de pages (ciblé) |
En bref : L’exploration sert à trouver des pages ; l’extraction sert à récupérer les infos qui t’intéressent (nimbleway.com).
Défis courants et bonnes pratiques en exploration et extraction web
Défis fréquents
- Changements de structure de site : Une simple refonte peut casser ton outil (octoparse.com).
- Contenu dynamique : Beaucoup de sites chargent des infos via JavaScript, invisibles pour les robots classiques.
- Anti-bots : CAPTCHAs, blocages d’IP, connexions obligatoires peuvent te bloquer l’accès.
- Échelle : Explorer des milliers de pages peut saturer ton ordi (ou faire bannir ton IP).
- Questions légales/éthiques : Extraire des données publiques est généralement ok, mais vérifie toujours les conditions d’utilisation et la loi (web.instantapi.ai).
Bonnes pratiques
- Choisis le bon outil : Si tu n’es pas dev, privilégie un extracteur no-code.
- Définis tes objectifs : Sache exactement quelles données tu veux et pourquoi.
- Respecte les règles des sites : Consulte toujours le fichier
robots.txtet les conditions d’utilisation. - N’abuse pas des serveurs : Mets des pauses entre les requêtes ; ne surcharge pas les sites.
- Prévois de l’entretien : Les sites changent — pense à ajuster ta config de temps en temps.
- Garde tes données propres et sécurisées : Stocke-les en sécurité et vérifie les doublons ou erreurs.
Cas d’usage typiques : exploration vs. extraction
Exploration web
- Indexation pour moteurs de recherche : Googlebot et Bingbot parcourent le web pour garder les résultats à jour (en.wikipedia.org).
- Archivage web : L’Internet Archive explore les sites pour la Wayback Machine.
- Audit SEO : Les outils analysent ton site pour repérer les liens cassés ou balises manquantes.
Extraction web
- Veille tarifaire : Les commerçants extraient les prix des concurrents (nextgeninvent.com).
- Génération de leads : Les équipes commerciales extraient des contacts depuis des annuaires.
- Agrégation de contenu : Les sites d’actus ou d’emploi rassemblent des annonces de plusieurs sources.
- Études de marché : Les analystes extraient des avis ou des posts sur les réseaux sociaux pour analyser les tendances.
À retenir : Plus de 82 % des entreprises e-commerce utilisent l’extraction web pour collecter des données externes. Si ce n’est pas ton cas, tes concurrents le font sûrement déjà.
Quand utiliser l’exploration ou l’extraction web ?
Petit guide pour choisir :
-
Tu dois découvrir de nouvelles pages ou indexer un site entier ?
→ Prends l’exploration web.
-
Tu sais déjà où sont les infos (pages ou sections précises) ?
→ L’extraction web est ce qu’il te faut.
-
Tu construis un moteur de recherche ou tu archives le web ?
→ L’exploration est pour toi.
-
Tu veux des données exploitables pour la vente, la veille tarifaire ou la recherche ?
→ L’extraction est la meilleure option.
-
Tu hésites ?
→ Commence par l’extraction. La plupart des besoins business ne nécessitent pas une exploration à grande échelle.
Pour la majorité des pros, c’est l’extraction qui compte : des données ciblées, structurées, prêtes à l’emploi.
L’extraction web pour les pros : l’atout Thunderbit
Voyons pourquoi la plupart des pros — surtout ceux qui ne codent pas — devraient privilégier l’extraction, et pourquoi Thunderbit a été pensé pour toi.
J’ai vu trop d’équipes perdre des jours (voire des semaines) à essayer de dompter des extracteurs soi-disant « simples » qui se révèlent bien trop complexes. C’est pour ça qu’on a créé Thunderbit : pour rendre l’extraction de données web aussi simple que deux clics.
Ce qui fait la différence avec Thunderbit :
- Flux en deux clics : Clique sur « Suggestion IA de champs », puis sur « Extraire ». C’est tout. Pas de code, pas de prise de tête.
- Gestion des URLs et PDF en masse : Tu veux extraire des données d’une liste d’URLs ou même de fichiers PDF ? Thunderbit s’en occupe.
- Export flexible : Envoie tes données direct vers Google Sheets, Airtable, Notion, ou télécharge-les en CSV/JSON. Pas de frais cachés.
- Extraction de sous-pages : Thunderbit peut automatiquement visiter les sous-pages (ex : fiches produits) et enrichir ton tableau de données.
- Remplissage automatique par IA : Automatise le remplissage de formulaires et les tâches répétitives — ton assistant digital pour les corvées web.
- Extracteurs d’emails et téléphones gratuits : Récupère tous les contacts d’une page en un clic.
- Extraction cloud ou navigateur : À toi de choisir — Thunderbit peut extraire dans le cloud (ultra rapide) ou dans ton navigateur (pratique pour les pages nécessitant une connexion).
- Aucune courbe d’apprentissage : Pensé pour les équipes commerciales, e-commerce et marketing qui veulent des résultats tout de suite.
Pour aller plus loin, jette un œil à nos guides sur l’extraction de produits Amazon, l’extraction de résultats Google, ou l’extraction de données vers Excel.
Extraire n’importe quel site avec l’IA en 2 clics
Thunderbit vs. extracteur web traditionnel
Comparons pour les pros :
| Fonctionnalité/Besoin | Thunderbit | Extracteur web traditionnel (ex : Scrapy, Nutch) |
|---|---|---|
| Mise en place | 2 clics, sans code | Configuration technique, souvent du script |
| Courbe d’apprentissage | Minime | Élevée (surtout pour les non-développeurs) |
| Gestion des sous-pages | Automatique, pilotée par IA | Script manuel ou configuration avancée |
| URLs/PDFs en masse | Prise en charge native | Rarement intégré d’office |
| Formats d’export | Google Sheets, Airtable, Notion, CSV | CSV, JSON (intégration souvent manuelle) |
| Adaptabilité | L’IA s’adapte aux changements de site | Mises à jour manuelles nécessaires |
| Cas d’usage business | Vente, e-commerce, SEO, opérations | Indexation, recherche, archivage |
| Planification | Programmation en langage naturel | Cron jobs ou planificateurs externes |
| Tarifs | À partir de 15€/mois, version gratuite | Gratuit/open source, mais coûts de mise en place/maintenance |
| Support | Centré utilisateur, interface moderne | Communautaire, orienté développeurs |
Thunderbit te fait passer de « j’ai besoin de ces données » à « voici mon tableau » en un temps record — sans avoir à déranger l’IT.
Conclusion : choisis la bonne approche pour ton business

En résumé :
- L’exploration web sert à découvrir et indexer des pages — parfait pour les moteurs de recherche et les audits de site.
- L’extraction web permet de récupérer des infos précises et exploitables — pour la prospection, la veille tarifaire ou l’agrégation de contenu.
- Pour la plupart des pros, c’est l’extraction qui compte. Et pas besoin de savoir coder.
Le web ne fait que grandir et se complexifier. Mais avec la bonne méthode — et le bon outil — tu peux transformer ce chaos en opportunité. Si tu en as marre des extracteurs compliqués ou d’attendre l’IT, teste Thunderbit. Tu seras surpris de voir ce que tu peux faire en deux clics (et tu pourras enfin profiter de ton week-end).
Pour voir Thunderbit en action, installe notre extension Chrome, ou découvre plus d’astuces et de guides sur le blog Thunderbit.
Installer l’extension Chrome Thunderbit
Bonne extraction (et laisse l’exploration aux moteurs de recherche — sauf si tu veux créer le prochain Google) !
FAQ
1. Ai-je besoin à la fois d’un robot d’indexation et d’un extracteur pour mon entreprise ?
Pas forcément. Si tu sais déjà quelles pages contiennent les infos que tu cherches, un extracteur web comme Thunderbit suffit largement. Les robots d’indexation sont utiles si tu dois découvrir de nouvelles pages — par exemple pour cartographier un site ou faire un audit SEO.
2. L’extraction web est-elle légale ?
En général, extraire des données publiques est légal — tant que tu ne contournes pas de connexion, ne violes pas les conditions d’utilisation ou ne récupères pas d’infos sensibles. Il vaut mieux vérifier le fichier robots.txt et la politique de confidentialité du site, surtout pour un usage pro.
3. Qu’est-ce qui distingue Thunderbit des autres outils d’extraction ?
Thunderbit est pensé pour les pros qui ne codent pas. Contrairement aux extracteurs classiques qui demandent de l’HTML ou une config manuelle, Thunderbit utilise l’IA pour repérer les champs, naviguer dans les sous-pages et exporter les données au format voulu — le tout en deux clics.
4. Thunderbit gère-t-il les sites dynamiques et les pages nécessitant une connexion ?
Oui. Thunderbit propose l’extraction via navigateur pour les sessions connectées et le contenu dynamique, ainsi que l’extraction cloud pour la rapidité et le volume. À toi de choisir le mode qui te convient.
Pour aller plus loin
- Qu’est-ce que l’extraction de données et comment la pratiquer en 2025
- Combien de sites web existe-t-il dans le monde ?
- Qu’est-ce qu’un robot d’indexation ? | Fonctionnement des spiders | Cloudflare
Essayez l’Extracteur Web IA gratuitement Get Started Free




