
Chaque fois que vous synchronisez votre CRM, récupérez des mises à jour d’expédition ou reliez deux outils SaaS, une API REST fait le gros du travail en coulisses. La plupart des gens n’y pensent jamais — jusqu’au jour où quelque chose casse.
Ce qui est amusant, c’est que même chez les développeurs, il existe une vraie confusion sur ce qui fait qu’une API est « RESTful ». Le terme est utilisé de façon si floue qu’un fil Reddit l’a résumé sans détour : « Je ne pense pas avoir construit une seule API véritablement RESTful, selon la définition de Roy Fielding. » Et cela venait d’un développeur, pas d’un utilisateur métier. Le concept remonte à la thèse de doctorat de Roy Fielding en à l’UC Irvine, où il décrit REST comme un style architectural — un ensemble de contraintes de conception — et non comme un protocole, un produit ou une spécification à télécharger.
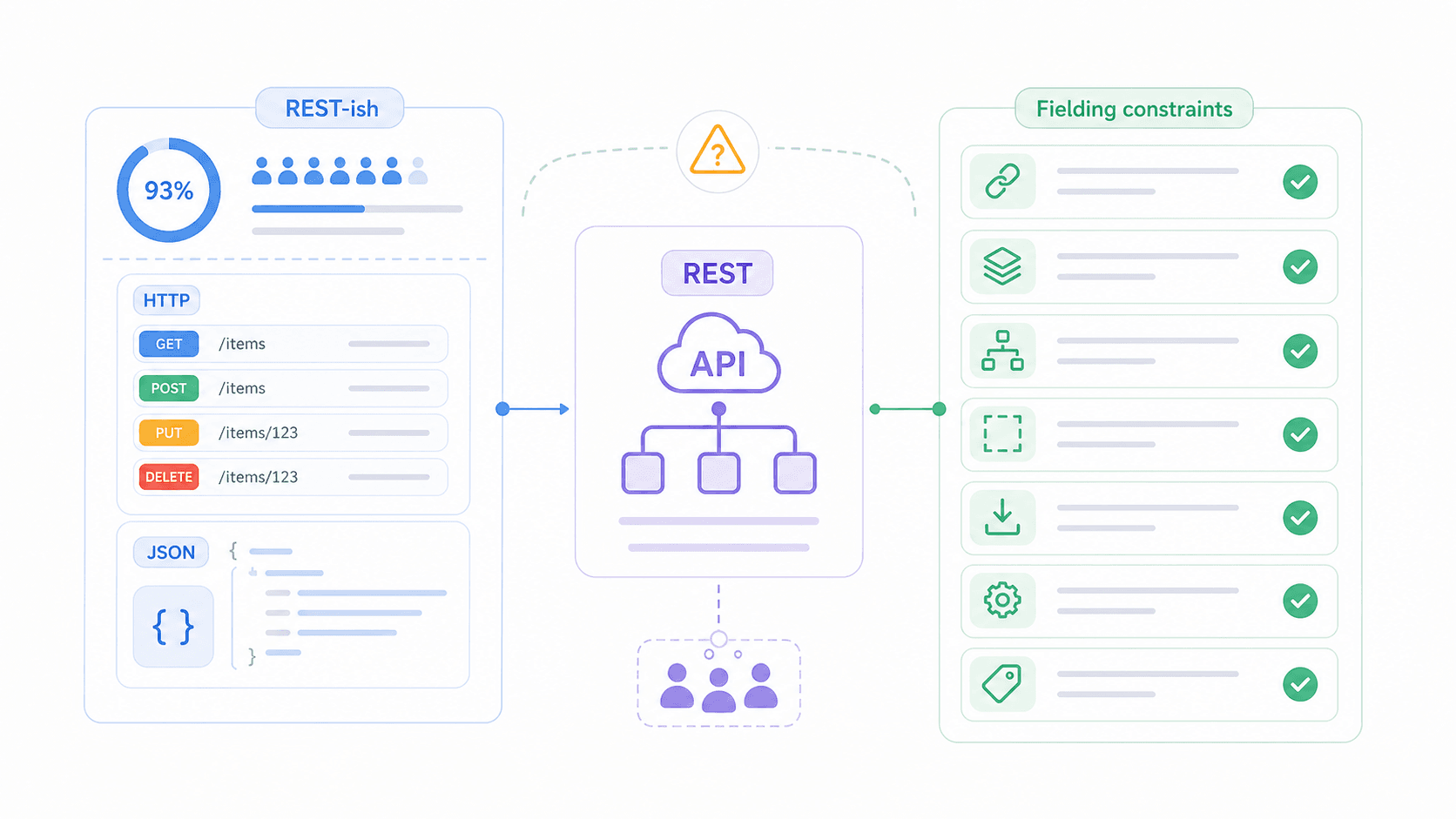
Pourtant, selon le , l’usage de REST atteint 93 % chez les professionnels de l’API. Autrement dit, presque tout le monde l’utilise, mais un nombre surprenant d’équipes ne comprend pas vraiment ce qu’il impose. Cet article passe en revue les 6 caractéristiques essentielles d’une API REST en termes simples, montre lesquelles les équipes maîtrisent le moins, présente un modèle de maturité pour vous autoévaluer, et compare REST à ses alternatives — SOAP, GraphQL et gRPC.
Qu’est-ce qu’une API REST ? (Définition simple)
REST (Representational State Transfer) est un ensemble de règles de conception qui régissent la manière dont des systèmes logiciels doivent communiquer sur un réseau.
Plus précisément, il s’agit d’un style architectural qui définit des contraintes — comme l’absence d’état, la cacheabilité et une interface uniforme — pour guider la façon dont les clients (votre navigateur, votre application mobile ou votre outil d’automatisation) interagissent avec les serveurs (là où résident les données). REST fonctionne généralement sur HTTP et renvoie le plus souvent du JSON, mais REST lui-même n’est lié à aucun protocole ni à aucun format de données spécifique.
Voyez cela comme les règles de savoir-vivre lors d’un dîner. REST ne vous dit pas quels plats servir ni quelle langue parler — il définit comment vous passez les plats, comment vous demandez à être resservi et comment vous signalez que vous avez terminé. Deux systèmes qui suivent les mêmes règles peuvent communiquer de manière prévisible, même s’ils ne se sont jamais rencontrés.
Ce que REST n’est pas : REST n’est pas un produit que l’on installe. Ce n’est pas un protocole comme HTTP ou SOAP. Et qualifier une API de « RESTful » ne signifie pas qu’elle respecte pleinement les contraintes originales de Fielding — cela veut souvent simplement dire qu’elle utilise des URL de ressources et des méthodes HTTP. L’écart entre « REST-ish » et « véritablement RESTful » est l’une des plus grandes sources de confusion du secteur, et nous y reviendrons bientôt.
Les 6 caractéristiques d’une API REST en un coup d’œil
Avant d’entrer dans le détail, voici la fiche mémo. Fielding a défini 6 contraintes qu’une API doit respecter pour être considérée comme RESTful. Cinq sont obligatoires ; une est facultative.
This paragraph contains content that cannot be parsed and has been skipped.
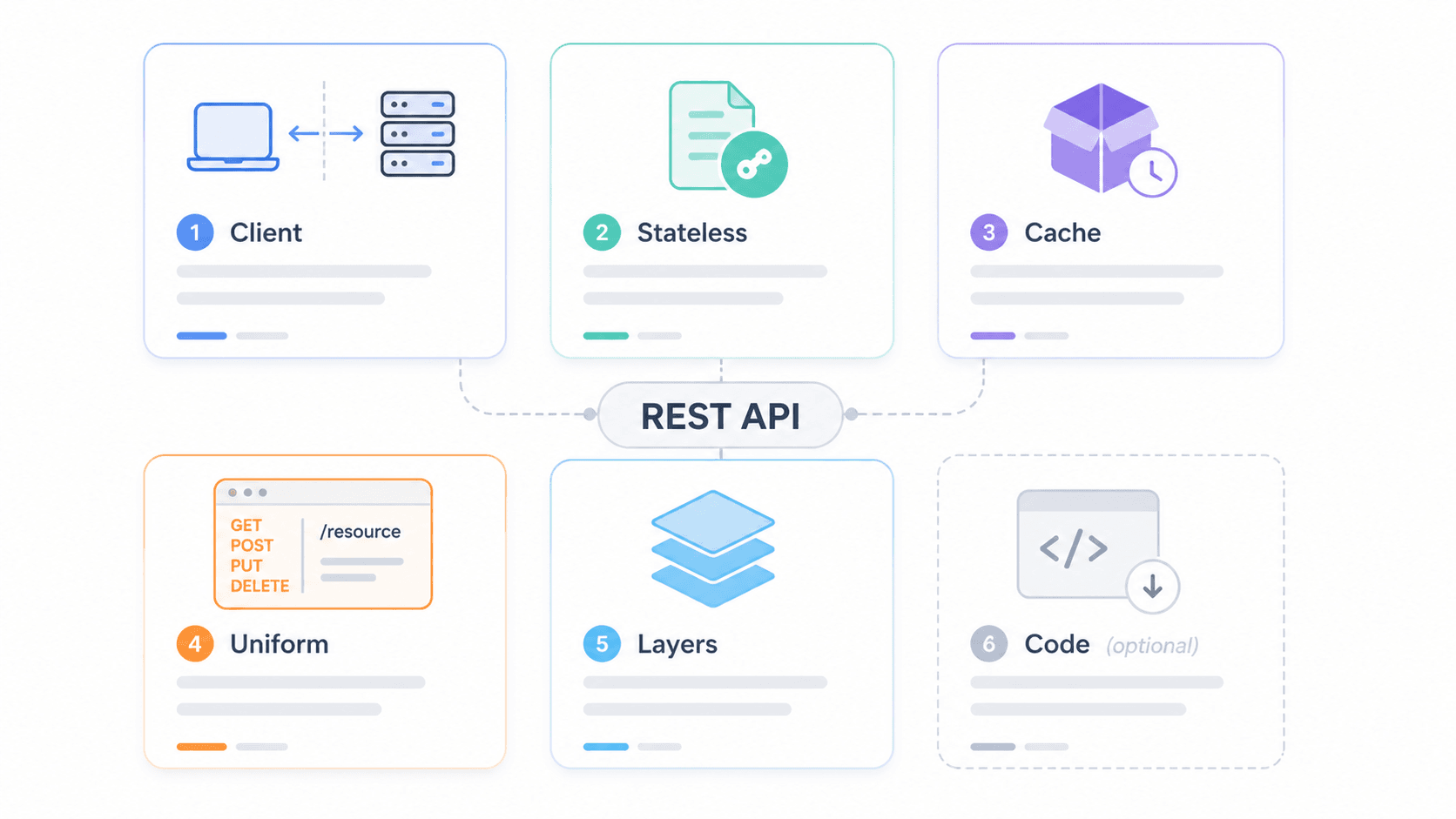
Pour voir comment ces contraintes fonctionnent ensemble dans un système réel, imaginez cette architecture en couches :
1Client / application mobile
2 ↓
3CDN / cache de bordure (par ex. Cloudflare)
4 ↓
5API Gateway (limitation de débit, auth, CORS)
6 ↓
7Load balancer
8 ↓
9Serveurs d’application
10 ↓
11Base de données / services internesLe client ne communique qu’avec la couche CDN. Il n’a aucune idée du nombre de couches situées derrière. C’est la contrainte du système en couches en action — et c’est aussi là que la sécurité, la mise en cache et la montée en charge se font sans que le client ait besoin de le savoir.
Passons maintenant au détail.
Les caractéristiques d’une API REST expliquées une par une
Séparation client-serveur
Première contrainte de Fielding : le client (ce avec quoi les utilisateurs interagissent) et le serveur (là où les données vivent et où la logique s’exécute) doivent être séparés. Il appelait cela la séparation des préoccupations.
Pourquoi est-ce important en pratique ? Parce qu’une application bancaire mobile peut bénéficier d’une refonte visuelle complète sans que la banque touche à sa base de données de comptes ou à son moteur de transactions. L’, par exemple, expose les contacts, les campagnes, les parcours et les notifications push via des points de terminaison de ressources. Que vous construisiez un tableau de bord sur mesure, une application mobile ou que vous connectiez un outil tiers, le back-end reste le même.
Pour les équipes métier, cela se traduit par des cycles d’itération plus rapides. Vos designers front-end et vos ingénieurs back-end n’ont pas besoin d’être synchronisés sur le même calendrier de publication. Tant que le contrat d’API reste stable, chaque partie peut avancer indépendamment.
Absence d’état
Aucune mémoire entre les requêtes. Chaque appel du client vers le serveur doit inclure toutes les informations nécessaires au traitement — le serveur ne conserve rien des interactions précédentes.
J’aime comparer cela à un appel à une hotline support où vous devez réexpliquer votre problème à chaque fois. Pénible ? Oui. Mais l’avantage est énorme : n’importe quel agent disponible peut vous aider, et le centre d’appels peut ajouter 500 agents de plus sans rien revoir à l’architecture. C’est la scalabilité horizontale.
En termes techniques, l’absence d’état signifie qu’il n’y a pas de session collante. Un load balancer peut acheminer votre prochaine requête vers n’importe quel serveur en bonne santé. Si un serveur tombe, un autre prend le relais sans interruption. La thèse de Fielding que l’absence d’état améliore la visibilité (les outils de supervision peuvent comprendre chaque requête isolément), la fiabilité (les pannes ne corrompent pas un état de session partagé) et la scalabilité (les serveurs peuvent libérer leurs ressources entre les requêtes).
La nuance pratique : dans les systèmes réels, il existe quand même des jetons d’authentification, des paniers d’achat et des flux OAuth. L’idée n’est pas qu’aucun état n’existe nulle part — c’est que le serveur ne stocke pas l’état de session du client dans sa propre mémoire entre les requêtes. Ce rôle est assuré par les jetons, les bases de données et les caches partagés.
Cacheabilité
Cette réponse peut-elle être réutilisée ? C’est à cette question que répond la cacheabilité. Les réponses doivent indiquer explicitement si elles peuvent être mises en cache et, si oui, les clients et intermédiaires (comme les CDN) les réutilisent pour des requêtes futures équivalentes — ce qui réduit la charge serveur et améliore la vitesse.
Le mécanisme HTTP est simple : des en-têtes comme Cache-Control, ETag, Last-Modified et Expires indiquent aux caches combien de temps une réponse reste valide et quand la vérifier de nouveau. Pour un lecteur métier, imaginez une étiquette sur la réponse qui dit « cette réponse est valable pendant la prochaine heure » ou « demandez-moi toujours une version fraîche ».
L’impact sur les performances est bien réel. Les essais de ont montré une amélioration de 50 à 100 ms sur les temps de réponse des cache hits en bout de chaîne. Et la propre thèse de Fielding documente comment le trafic Web est passé de 100 000 requêtes/jour en 1994 à 600 000 000 requêtes/jour en 1999 — la mise en cache étant un facteur de conception déterminant.
Généralement cacheables : catalogues produits, contenu de blog public, listes de pays/devises, documentation API.
Généralement non cacheables : tableaux de bord personnels, totaux de panier, soldes bancaires, rapports d’administration.
Interface uniforme
C’est la contrainte que Fielding lui-même qualifie de caractéristique centrale qui distingue REST des autres styles architecturaux. Elle standardise la manière dont les clients interagissent avec les ressources, ce qui rend les API prévisibles.
Quatre sous-contraintes se cachent derrière ce principe :
- Identification des ressources : chaque ressource reçoit un URI stable.
/customers/123est un client./orders/456est une commande. - Manipulation via représentations : les clients manipulent des représentations (JSON, XML, HTML) des ressources, et non les objets internes du serveur.
- Messages auto-descriptifs : les requêtes et réponses transportent suffisamment de métadonnées — méthode, code de statut, type de contenu, détails d’erreur — pour qu’un intermédiaire ou un client puisse les comprendre.
- HATEOAS (Hypermedia as the Engine of Application State) : les réponses incluent des liens vers les actions et ressources liées, afin que les clients sachent quoi faire ensuite sans coder en dur chaque point de terminaison.
La correspondance des méthodes HTTP est la partie la plus visible de l’interface uniforme :
| Méthode HTTP | Sens CRUD | Sûre ? | Idempotente ? | Exemple |
|---|---|---|---|---|
| GET | Lecture | Oui | Oui | GET /products/42 |
| POST | Création / action | Non | Non | POST /orders |
| PUT | Remplacer entièrement la ressource | Non | Oui | PUT /users/42 |
| PATCH | Mise à jour partielle | Non | Non garanti | PATCH /users/42 |
| DELETE | Suppression | Non | Oui | DELETE /sessions/abc |
Les précisent explicitement que GET doit être sûr, et que GET, PUT et DELETE doivent être idempotents. Des API connues comme celles de GitHub, Stripe et Spotify suivent de près ces conventions, ce qui explique pourquoi un développeur qui en apprend une peut en prendre une autre en main rapidement.
Système en couches
Votre client n’a aucune idée s’il parle au serveur d’origine, à un cache CDN, à une API Gateway ou à un load balancer. Et c’est précisément le but : chaque composant ne voit que la couche voisine.
C’est ce qui permet :
- Aux CDN comme Cloudflare de se placer devant votre API pour mettre en cache et accélérer les réponses
- Aux API gateways (AWS API Gateway, Kong, Apigee) de gérer l’authentification, la limitation de débit et les quotas
- Aux load balancers de répartir les requêtes sans état sur plusieurs serveurs d’application
Le indique que utilisent AWS API Gateway, 26 % la gateway d’Azure, et 31 % plusieurs gateways simultanément. L’architecture en couches n’est pas théorique — c’est ainsi que fonctionnent réellement les systèmes en production.
Le compromis : chaque couche ajoute un peu de latence. Mais Fielding soutenait que la mise en cache partagée dans les couches intermédiaires compense largement ce surcoût dans la plupart des systèmes réels.
Code à la demande (facultatif)
C’est l’exception. Le code à la demande est la seule contrainte REST facultative : le serveur peut envoyer du code exécutable — comme du JavaScript — pour étendre à la volée les fonctionnalités du client.
L’exemple le plus courant dans le monde réel est simplement une page web qui charge du JavaScript depuis un serveur. Mais pour les API REST JSON classiques consommées par des applications mobiles, des tâches back-end ou des outils d’automatisation, le code à la demande est presque jamais utilisé. En général, les clients d’API ne veulent pas exécuter du code arbitraire provenant d’un serveur distant.
Pour la plupart des lecteurs, cette contrainte est une note de bas de page. Elle existe dans le modèle de Fielding pour être complet, mais elle n’entrera pas dans vos évaluations quotidiennes d’API.
Ce que beaucoup de gens comprennent mal : la plupart des API REST sont-elles vraiment RESTful ?
Voici la partie dont personne ne veut parler : la plupart des API de production qui se disent « RESTful » sont en réalité des API HTTP JSON avec des conventions de type REST. Elles utilisent des URL de ressources, des méthodes HTTP et des codes de statut — et c’est à peu près tout. Un fil Reddit sur r/softwarearchitecture voyait des développeurs admettre qu’ils n’avaient jamais construit une API REST réellement conforme à Fielding. Une autre discussion sur r/learnprogramming a tourné à l’argumentation sur la possibilité même de se mettre d’accord sur ce que signifie « RESTful ».
Une étude de 2026, menée auprès de 16 experts d’API REST, a montré que si les bonnes pratiques améliorent l’utilisabilité, les développeurs résistent fortement aux règles REST strictes — invoquant la taille des directives et leur faible adéquation à leur organisation comme obstacles.
Alors, dans la pratique, où se situent réellement les contraintes ?
| Contrainte | Adoption en pratique | Pourquoi |
|---|---|---|
| Client-serveur | ✅ Presque universelle | Fondamentale pour l’architecture Web ; difficile à éviter |
| Absence d’état | ✅ Presque universelle | Nécessaire à la scalabilité horizontale ; pratique standard |
| Interface uniforme (de base) | ✅ Courante | Les URI de ressources + les verbes HTTP sont le schéma par défaut |
| Cacheabilité | ⚠️ Inconstante | Beaucoup d’équipes omettent complètement les en-têtes Cache-Control |
| Système en couches | ⚠️ Implicite | Les CDN et gateways existent, mais ne sont pas toujours conçus délibérément |
| HATEOAS | ❌ Rare | La plupart des clients codent les points de terminaison en dur ; la découverte par liens ajoute de la complexité |
| Code à la demande | ❌ Très rare | Facultatif par définition ; presque jamais implémenté dans les API JSON |
Pourquoi les équipes sautent HATEOAS : les développeurs côté client préfèrent lire la documentation OpenAPI et utiliser des SDK plutôt que de suivre dynamiquement des liens à l’exécution. HATEOAS exige des types de médias stables, des définitions de relations de liens et une modélisation des workflows — le coût à court terme est élevé, et le bénéfice reste flou pour la plupart des équipes.
L’enseignement pragmatique : une API n’a pas besoin d’être conforme à 100 % à Fielding pour être utile. Mais savoir quelles contraintes vous avez écartées — et ce que vous perdez en les écartant — vous aide à prendre de meilleures décisions de conception et d’intégration.
Le modèle de maturité de Richardson : votre API est-elle vraiment RESTful ?
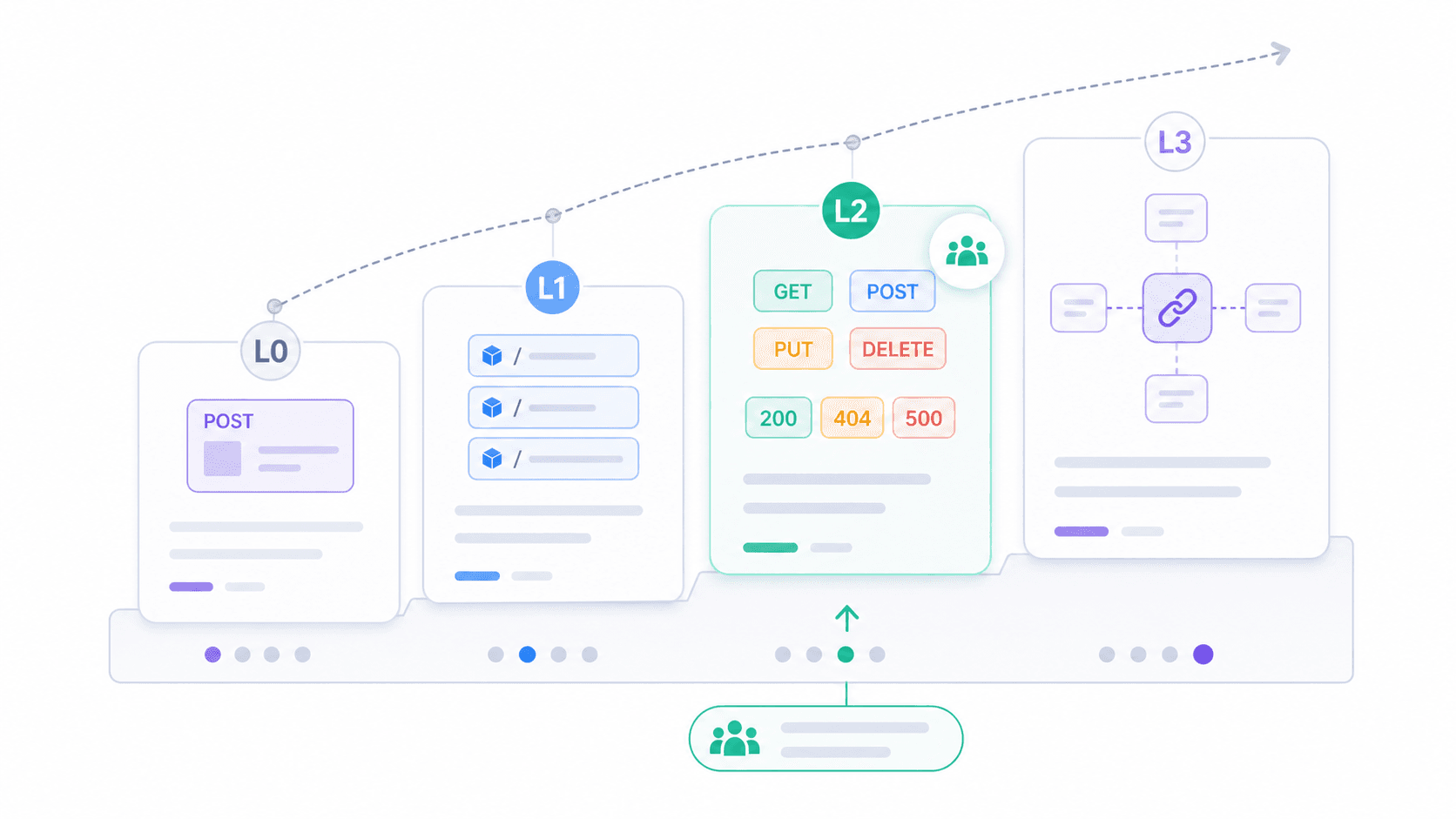
Si la question binaire « Est-ce RESTful ou non ? » vous semble peu utile, le Richardson Maturity Model offre un cadre plus concret. Proposé par Leonard Richardson et , il découpe l’adoption de REST en quatre niveaux.
| Niveau | Nom | Description | Exemple réel |
|---|---|---|---|
| 0 | Le marécage du POX | URI unique, verbe HTTP unique (généralement POST) | Points de terminaison SOAP sur HTTP hérités ; POST /api avec { "action": "getUser" } |
| 1 | Ressources | Plusieurs URI (une par ressource), mais toujours surtout POST | POST /users/123/getProfile, POST /orders/456/cancel |
| 2 | Verbes HTTP | Utilisation correcte de GET, POST, PUT, DELETE + bons codes de statut | La plupart des API « REST » de production aujourd’hui |
| 3 | Hypermedia (HATEOAS) | Les réponses incluent des liens vers les actions/ressources liées | Spring Data REST, APIs basées sur HAL ; très peu d’API publiques en pratique |
La plupart des API que vous rencontrerez sur le terrain se situent au niveau 2. Elles utilisent correctement les ressources, les verbes et les codes de statut. C’est suffisant pour être pratique, interopérable et bien prise en charge par les outils. Le niveau 3 correspond à la vision complète de Fielding, mais son adoption reste limitée.
À quel niveau se situe votre API ? Posez-vous ces questions :
- L’API possède-t-elle un point de terminaison unique pour tout ? (Niveau 0)
- Chaque objet métier a-t-il son propre URI ? (Niveau 1+)
- Les méthodes HTTP et les codes de statut sont-ils utilisés correctement ? (Niveau 2)
- Les réponses indiquent-elles au client ce qu’il peut faire ensuite, sans dépendre d’une documentation externe ? (Niveau 3)
Ce modèle est, selon moi, l’outil le plus utile pour sortir du débat « est-ce REST ou non ». Il remplace un jugement binaire par un spectre.
Erreurs courantes avec les API REST (et comment les éviter)
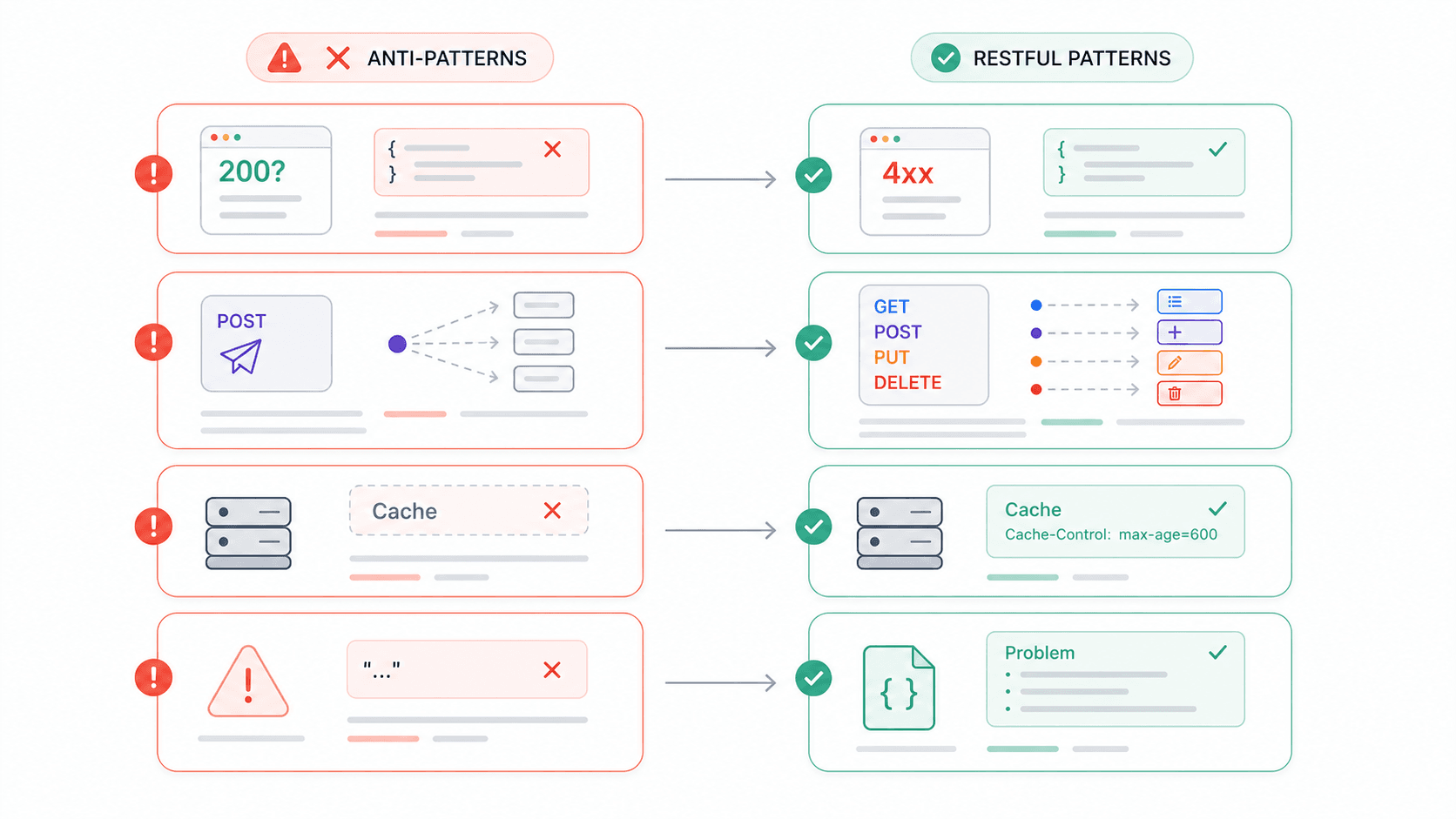
J’ai passé assez de temps à intégrer des API tierces pour avoir une liste de frustrations bien fournie. Et à en juger par les forums de développeurs, je ne suis pas le seul. Voici les anti-patterns qui reviennent le plus souvent — et chacun correspond directement à une violation d’une contrainte REST.
| Anti-pattern | Pourquoi cela casse REST | Que faire à la place |
|---|---|---|---|
| HTTP 200 avec un corps d’erreur ({ "error": "Invalid username" }) | Viole les messages auto-descriptifs ; les clients ne peuvent pas se fier aux codes de statut | Utilisez les codes 4xx/5xx appropriés + un corps d’erreur structuré (par ex. application/problem+json) |
| POST pour tout | Ignore l’interface uniforme ; perd les sémantiques de sûreté/idempotence | Faites correspondre CRUD à GET/POST/PUT(PATCH)/DELETE |
| Pas d’en-têtes Cache-Control | Gâche complètement la contrainte de cacheabilité | Définissez des directives de cache explicites — même no-store pour les données sensibles |
| Réponses d’erreur vagues (« 409 error ») | Humains et machines ne peuvent pas déterminer ce qui a échoué | Incluez le type d’erreur, un message lisible et un lien vers la documentation |
| Pas de HTTPS | Les jetons bearer et les clés API circulent en clair | Imposer TLS partout ; les API Google sont HTTPS uniquement par défaut |
| Versionner dans le corps de la requête | Casse l’identification des ressources ; les gateways et caches ne peuvent pas router correctement | Utilisez le versionnement dans le chemin URI (/v1/) ou le versionnement via l’en-tête Accept |
Les exigent des codes de statut HTTP officiels et recommandent Problem JSON pour les réponses d’erreur. Les précisent que Problem Detail ne doit être utilisé que pour les 4xx/5xx, jamais mélangé avec des 2xx. Ce ne sont pas des préférences académiques — ce sont des standards de production issus d’équipes qui exploitent des API à grande échelle.
Un fil Reddit sur r/learnprogramming contenait un développeur demandant sérieusement s’il était acceptable de toujours renvoyer HTTP 200 en cas d’erreur. Le simple fait que cette question revienne encore en 2026 montre à quel point ces anti-patterns restent tenaces.
REST vs SOAP vs GraphQL vs gRPC : comparaison des caractéristiques d’une API REST
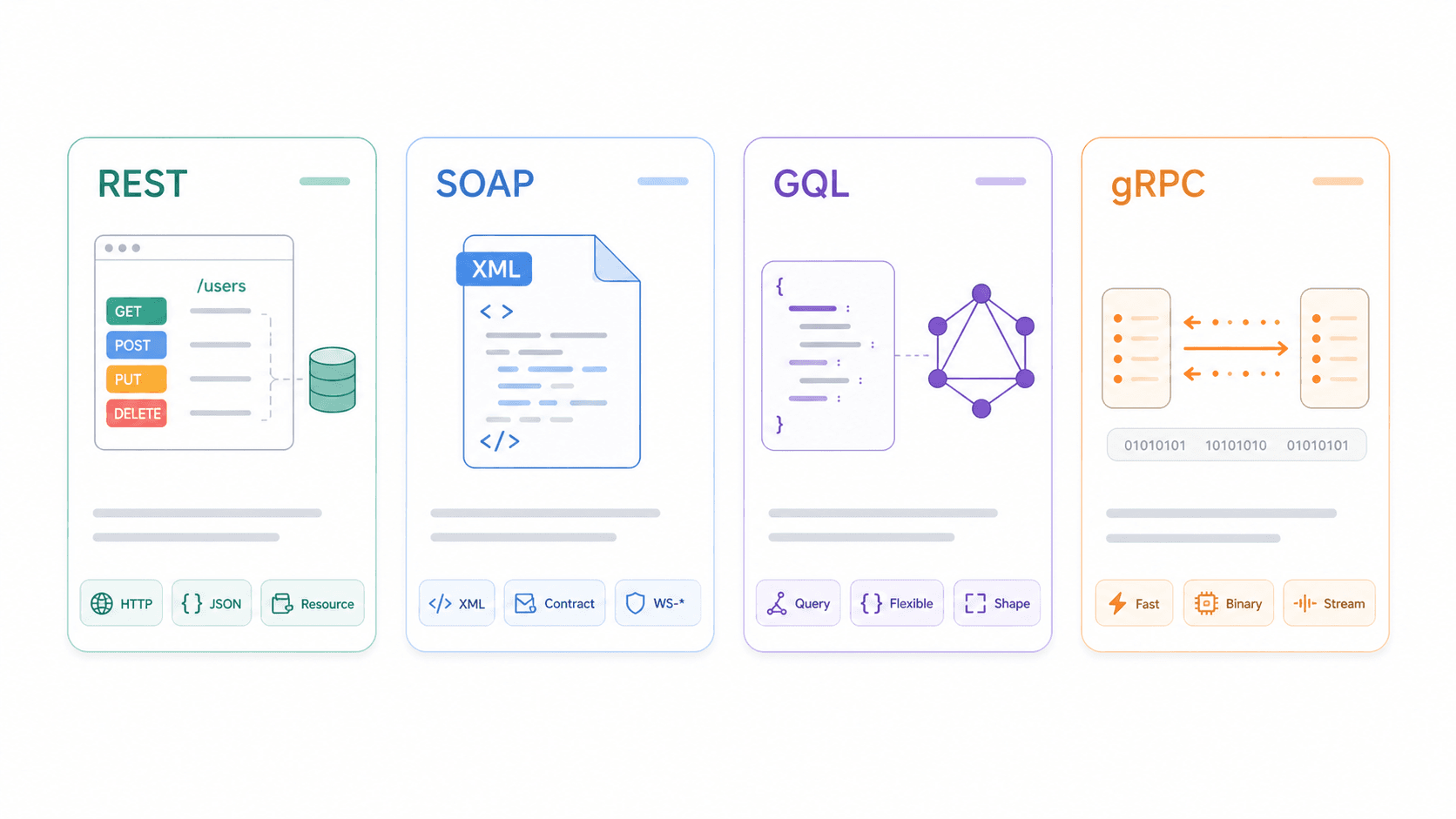
Comprendre REST isolément est utile. Le comprendre par rapport aux alternatives l’est encore plus.
| Dimension | REST | SOAP | GraphQL | gRPC |
|---|---|---|---|---|
| Protocole / transport | Style architectural, généralement HTTP | Protocole de messagerie basé sur XML ; HTTP, SMTP, etc. | Langage/runtime de requête, généralement sur HTTP | Framework RPC sur HTTP/2 |
| Format de données | JSON (généralement), aussi XML/HTML | XML uniquement (contrats WSDL) | JSON correspondant à la forme de la requête | Protocol Buffers (binaire) |
| Mise en cache | ✅ Cache HTTP natif bien conçu | ❌ Complexe ; peu compatible avec le cache HTTP | ⚠️ Plus difficile (POST + point de terminaison unique + variation de requête) | ❌ Pas orienté cache HTTP |
| Support temps réel | ❌ Polling/webhooks | ❌ Modèles de messagerie d’entreprise | ✅ Subscriptions | ✅ Streaming, faible latence |
| Courbe d’apprentissage | Faible à moyenne | Élevée | Moyenne | Moyenne à élevée |
| Idéal pour | API publiques, CRUD, intégrations web/mobile | Entreprise/héritage, contrats stricts, conformité | Requêtes complexes, front-ends flexibles, apps mobiles | Microservices entre eux, usages internes à haute performance |
La comparaison de recommande de choisir en fonction de la compatibilité, de la forme des données, des opérations et des outils utilisés par les équipes.
Quand choisir quoi :
- REST s’impose quand vous avez besoin d’une large compatibilité, d’opérations CRUD simples et du cache HTTP. C’est le choix par défaut pour les API publiques et les intégrations web/mobile.
- SOAP reste pertinent pour les systèmes d’entreprise avec des contrats stricts, des exigences WS-Security ou des intégrations héritées qui ne vont pas disparaître.
- GraphQL brille lorsque votre front-end a besoin de requêtes flexibles et imbriquées, et que vous voulez éviter de sur-récupérer ou de sous-récupérer des données — ce qui est courant dans les applications mobiles complexes.
- gRPC est conçu pour la communication interne entre microservices, où la faible latence et la sérialisation binaire comptent davantage que la compatibilité navigateur.
À titre d’exemple REST concret : l’ utilise des points de terminaison POST simples (/distill et /extract), des corps de requête/réponse JSON, l’authentification par bearer token et des codes de statut HTTP standard (400, 401, 402, 408, 422, 429, 500, 502, 503, 504). Elle illustre les caractéristiques REST dans un produit IA de production, sans exiger de contrats SOAP ni la complexité de gRPC. Ce n’est pas une vitrine HATEOAS — mais une API de niveau 2 pratique, facile à intégrer pour les équipes métier comme pour les développeurs.
Pourquoi les caractéristiques REST comptent pour les équipes métier
Sales, Operations, Ecommerce — aucune de ces équipes n’écrit de code API. Mais vous choisissez bien des fournisseurs, connectez des outils et construisez des workflows d’automatisation — et la qualité d’une API REST a un impact direct sur le caractère pénible, ou non, de ces intégrations.
Intégration d’outils : quand votre CRM se synchronise avec une plateforme d’automatisation marketing, la conception de l’API REST détermine si cette synchronisation est fiable ou fragile. L’ gère les contacts, les campagnes, les parcours et les notifications push via des points de terminaison de ressources prévisibles. Si ces points de terminaison suivent les conventions REST, votre équipe RevOps peut automatiser sans contournements sur mesure.
Opérations e-commerce : les gèrent les commandes à expédier, les numéros de suivi et l’état des expéditions. Les applications d’expédition et les outils de fulfillment reposent sur cette couche. Quand l’API est bien conçue — codes de statut corrects, données de catalogue mises en cache, messages d’erreur clairs — votre chaîne logistique tourne sans accroc. Quand elle ne l’est pas, vous obtenez des pannes mystérieuses à 2 h du matin.
Évaluation de fournisseurs : connaître les 6 contraintes vous donne une check-list concrète :
- L’API utilise-t-elle des codes de statut standards, ou chaque échec ressemble-t-il à un 200 OK ?
- Les erreurs sont-elles assez précises pour que votre outil d’automatisation puisse se rétablir ?
- La documentation sur les limites de débit, la pagination et l’authentification est-elle claire ?
- Les réponses courantes peuvent-elles être mises en cache pour réduire la charge ?
Extraction de données et automatisation : des outils comme utilisent une architecture basée sur REST pour permettre aux utilisateurs métier d’extraire des données structurées depuis des sites web, des PDF et des images — puis de les exporter vers Google Sheets, Airtable, Notion ou Excel. L’ gère la complexité derrière une interface en 2 clics, mais sous le capot, ce sont les principes REST — requêtes sans état, réponses JSON, erreurs standardisées — qui rendent la couche d’intégration fiable.
Un autre point mérite d’être signalé : le rapport Postman 2025 a révélé que seulement conçoivent activement des API en pensant aux agents IA, tandis que 51 % s’inquiètent d’appels API non autorisés ou excessifs provenant d’agents IA. À mesure que l’automatisation et les workflows pilotés par l’IA deviennent la norme dans les équipes métier, les patterns REST prévisibles, les clés API à privilège minimal et les limites de débit ne sont plus seulement des préoccupations de développeurs — ce sont des facteurs de risque opérationnel.
Comment Thunderbit applique les principes REST pour les utilisateurs métier
Nous avons conçu en partant du principe que la plupart de nos utilisateurs ne liraient jamais une spécification REST — et n’auraient pas à le faire. Mais les choix de conception qui rendent Thunderbit simple à utiliser reposent sur les mêmes caractéristiques REST que cet article présente.
Voici un aperçu rapide de son fonctionnement en pratique :
- Installez l’extension Chrome depuis le et ouvrez n’importe quel site web, PDF ou image à partir duquel vous souhaitez extraire des données.
- Cliquez sur « AI Suggest Fields » et l’IA de Thunderbit lit la page et propose un tableau structuré de colonnes — noms de produits, prix, e-mails, tout ce que contient la page.
- Ajustez les colonnes si nécessaire, puis cliquez sur « Scrape ». Thunderbit gère automatiquement la pagination, les sous-pages et le contenu dynamique.
- Exportez vos données vers Google Sheets, Airtable, Notion, CSV ou Excel — gratuitement, sans mur payant.
Pour les développeurs et les workflows d’automatisation, l’ expose /distill (extraction Markdown propre) et /extract (extraction de données structurées) sous forme de points de terminaison POST de style REST avec corps JSON et codes d’erreur HTTP standards. En termes de Richardson Maturity Model, c’est un solide niveau 2 — ressources, bonnes méthodes, codes de statut parlants.
Si vous explorez plus largement le web scraping ou l’extraction de données, nous avons rédigé des guides plus approfondis sur le , le et .
Points clés à retenir
- REST est un style architectural, pas un protocole. Il définit 6 contraintes — client-serveur, absence d’état, cacheable, interface uniforme, système en couches et code à la demande facultatif — qui guident la conception des API.
- La plupart des API « RESTful » ne sont pas pleinement RESTful. La majorité se situe au niveau 2 de Richardson (ressources + verbes HTTP + codes de statut). HATEOAS et le code à la demande sont rarement implémentés.
- Le Richardson Maturity Model est le meilleur outil d’auto-évaluation. Il remplace la question binaire « REST ou non » par un spectre pratique (niveaux 0 à 3).
- Les erreurs courantes — 200 OK pour les erreurs, POST pour tout, en-têtes de cache absents — restent très répandues. Connaître les contraintes vous aide à repérer et corriger ces anti-patterns.
- REST vs SOAP vs GraphQL vs gRPC n’est pas une question de “meilleur” — c’est une question d’adéquation. REST domine les API publiques et les intégrations CRUD. GraphQL convient aux front-ends complexes. gRPC excelle dans les microservices internes. SOAP persiste dans les contextes d’entreprise et de legacy.
- Les équipes métier gagnent à comprendre les caractéristiques REST lorsqu’elles évaluent des fournisseurs, connectent des outils et construisent des workflows d’automatisation. Des outils comme appliquent les principes REST pour rendre l’extraction de données accessible sans expertise technique.
FAQ
Quelles sont les 6 caractéristiques d’une API REST ?
Les 6 contraintes REST sont : (1) la séparation client-serveur, (2) l’absence d’état, (3) la cacheabilité, (4) l’interface uniforme, (5) le système en couches, et (6) le code à la demande (facultatif). Les cinq premières sont obligatoires pour qu’une API soit considérée comme RESTful selon la définition originale de Fielding.
Quelle est la différence entre REST et RESTful ?
REST est le style architectural — l’ensemble des contraintes de conception définies par Roy Fielding. « RESTful » décrit une API qui suit ces contraintes. En pratique, beaucoup d’API qualifiées de « RESTful » ne les respectent que partiellement, en implémentant généralement des ressources, des méthodes HTTP et des codes de statut, tout en laissant de côté HATEOAS et le code à la demande.
Toutes les API REST respectent-elles chaque contrainte REST ?
Non. La plupart des API de production respectent la séparation client-serveur, l’absence d’état et une interface uniforme de base (ressources + verbes HTTP). La cacheabilité et la conception en couches sont appliquées de manière inégale. HATEOAS est rare, et le code à la demande n’est presque jamais utilisé dans les API JSON.
Quelle est la différence entre REST et GraphQL ?
REST expose des ressources via plusieurs points de terminaison avec des méthodes HTTP standard (GET, POST, PUT, DELETE). GraphQL utilise généralement un point de terminaison unique où les clients spécifient exactement les champs qu’ils veulent dans une requête. REST dispose d’un cache HTTP natif plus robuste ; GraphQL offre plus de flexibilité pour les besoins de données complexes et imbriqués, et réduit la sur-récupération.
Qu’est-ce que HATEOAS, et est-ce que quelqu’un l’utilise vraiment ?
HATEOAS (Hypermedia as the Engine of Application State) signifie que les réponses d’API incluent des liens indiquant aux clients quelles actions sont disponibles ensuite — ce qui leur permet de naviguer dans l’API sans coder en dur chaque point de terminaison. C’est central dans la vision REST de Fielding (niveau 3 de Richardson), mais en pratique, très peu d’API publiques l’implémentent. La plupart des équipes s’arrêtent au niveau 2 et s’appuient plutôt sur la documentation et les SDK.
En savoir plus