Le web regorge de données précieuses — que vous travailliez dans la vente, l’e-commerce ou l’étude de marché, le web scraping est un atout puissant pour la génération de leads, la surveillance des prix et l’analyse concurrentielle. Mais voilà le problème : à mesure que de plus en plus d’entreprises se lancent dans le scraping, les sites web réagissent de plus en plus fermement. En réalité, plus de , et les sont désormais monnaie courante. Si vous avez déjà vu votre script Python tourner sans problème pendant 20 minutes, puis se heurter d’un coup à un mur d’erreurs 403, vous savez à quel point la frustration peut être réelle.
J’ai passé des années dans le SaaS et l’automatisation, et j’ai vu de mes propres yeux des projets de scraping passer de « waouh, c’est facile » à « pourquoi suis-je bloqué partout ? » en un clin d’œil. Alors, entrons dans le vif du sujet : je vais vous montrer comment faire du web scraping en Python sans se faire bloquer, partager les meilleures techniques et quelques extraits de code, et vous expliquer quand il est temps d’envisager des alternatives propulsées par l’IA comme . Que vous soyez un pro de Python ou que vous vous débrouilliez comme vous pouvez, vous repartirez avec une boîte à outils pour extraire des données de façon fiable et sans blocage.
Qu’est-ce que le web scraping sans blocage en Python ?
À la base, faire du web scraping sans se faire bloquer consiste à extraire des données de sites web d’une manière qui évite de déclencher leurs défenses anti-bot. Dans l’univers Python, cela ne se limite pas à écrire une boucle requests.get() : il faut se fondre dans le trafic normal, imiter de vrais utilisateurs et garder une longueur d’avance sur les systèmes de détection.
Pourquoi Python ? — grâce à sa syntaxe simple, à son écosystème immense (pensez à requests, BeautifulSoup, Scrapy, Selenium) et à sa flexibilité, des petits scripts aux robots d’exploration distribués. Mais cette popularité a un revers : beaucoup de systèmes anti-bot savent désormais repérer les schémas de scraping basés sur Python.
Donc, si vous voulez scraper de manière fiable, il faut aller au-delà des bases. Cela veut dire comprendre comment les sites détectent les bots, et comment les contourner — sans franchir les limites éthiques ou juridiques.
Pourquoi éviter les blocages est crucial pour les projets de web scraping en Python
Être bloqué n’est pas qu’un simple contretemps technique : cela peut faire dérailler des processus métier entiers. Voyons cela plus en détail :
| Cas d’usage | Impact d’un blocage |
|---|---|
| Génération de leads | Listes de prospects incomplètes ou obsolètes, ventes perdues |
| Suivi des prix | Changements de prix des concurrents manqués, mauvaises décisions tarifaires |
| Agrégation de contenu | Lacunes dans les actualités, avis ou données de recherche |
| Intelligence de marché | Angles morts dans le suivi des concurrents ou du secteur |
| Annonces immobilières | Données immobilières inexactes ou obsolètes, opportunités manquées |
Lorsqu’un scraper est bloqué, vous ne perdez pas seulement des données : vous gaspillez des ressources, prenez des risques en matière de conformité et pouvez même prendre de mauvaises décisions commerciales sur la base d’informations incomplètes. Dans un monde où , la fiabilité est essentielle.
Comment les sites détectent et bloquent les web scrapers Python
Les sites web sont devenus très ingénieux pour repérer les bots. Voici les défenses anti-scraping les plus courantes que vous rencontrerez (, ) :
- Liste noire d’adresses IP : trop de requêtes depuis la même IP ? Blocage.
- Vérification du User-Agent et des en-têtes : les requêtes sans en-têtes ou avec des en-têtes génériques (comme le
python-requests/2.25.1par défaut de Python) sautent immédiatement aux yeux. - Limitation de débit : trop de requêtes en peu de temps déclenchent un ralentissement ou un bannissement.
- CAPTCHA : des énigmes du type « prouvez que vous êtes humain » que les bots ne peuvent pas résoudre (facilement).
- Analyse comportementale : les sites surveillent les schémas robotiques, comme cliquer sur le même bouton à intervalles réguliers.
- Honeypots : des liens ou champs cachés qui n’attirent que les bots.
- Browser fingerprinting : collecte de détails sur votre navigateur et votre appareil pour repérer les outils d’automatisation.
- Suivi des cookies et des sessions : les bots qui ne gèrent pas correctement cookies ou sessions sont signalés.
Voyez cela comme le contrôle de sécurité à l’aéroport : si vous avez l’air, les gestes et les déplacements de tout le monde, vous passez sans encombre. Si vous arrivez en trench-coat et lunettes de soleil, attendez-vous à quelques questions supplémentaires.
Techniques Python essentielles pour faire du web scraping sans se faire bloquer
Passons au concret : comment éviter réellement les blocages quand vous scrapez avec Python. Voici les stratégies de base que tout scraper devrait connaître :

Proxys rotatifs et adresses IP
Pourquoi c’est important : si toutes vos requêtes proviennent de la même IP, vous êtes une cible facile pour les bannissements d’IP. Les proxys rotatifs vous permettent de répartir les requêtes sur plusieurs IP, ce qui rend votre blocage beaucoup plus difficile.
Comment faire en Python :
1import requests
2proxies = [
3 "<http://proxy1.example.com:8000>",
4 "<http://proxy2.example.com:8000>",
5 # ...plus de proxys
6]
7for i, url in enumerate(urls):
8 proxy = {"http": proxies[i % len(proxies)]}
9 response = requests.get(url, proxies=proxy)
10 # traiter la réponseVous pouvez utiliser des services de proxy payants (comme des proxys résidentiels ou rotatifs) pour plus de fiabilité ().
Définir le User-Agent et des en-têtes personnalisés
Pourquoi c’est important : les en-têtes Python par défaut crient « bot ». Imitiez de vrais navigateurs en définissant le user-agent et d’autres en-têtes.
Exemple de code :
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4 "Accept-Encoding": "gzip, deflate, br",
5 "Connection": "keep-alive"
6}
7response = requests.get(url, headers=headers)Faites tourner les user-agents pour rester plus discret ().
Randomiser le timing et les schémas de requêtes
Pourquoi c’est important : les bots sont rapides et prévisibles ; les humains sont lents et imprévisibles. Ajoutez des délais et variez votre navigation.
Astuce Python :
1import time, random
2for url in urls:
3 response = requests.get(url)
4 time.sleep(random.uniform(2, 7)) # attendre 2 à 7 secondesVous pouvez aussi randomiser les chemins de clic et les schémas de défilement si vous utilisez Selenium.
Gérer les cookies et les sessions
Pourquoi c’est important : de nombreux sites exigent des cookies ou des jetons de session pour accéder au contenu. Les bots qui les ignorent se font bloquer.
Comment gérer cela en Python :
1import requests
2session = requests.Session()
3response = session.get(url)
4# la session gérera automatiquement les cookiesPour des flux plus complexes, utilisez Selenium pour capturer et réutiliser les cookies.
Simuler un comportement humain avec des navigateurs headless
Pourquoi c’est important : certains sites utilisent JavaScript, les mouvements de souris ou le défilement comme signaux d’utilisateurs réels. Les navigateurs headless comme Selenium ou Playwright peuvent imiter ces actions.
Exemple avec Selenium :
1from selenium import webdriver
2from selenium.webdriver.common.action_chains import ActionChains
3import random, time
4driver = webdriver.Chrome()
5driver.get(url)
6actions = ActionChains(driver)
7actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
8time.sleep(random.uniform(2, 5))Cela vous aide à contourner l’analyse comportementale et le contenu dynamique ().
Stratégies avancées : contourner les CAPTCHA et les honeypots en Python
Les CAPTCHA sont conçus pour stopper les bots net au plus vite. Même si certaines bibliothèques Python peuvent résoudre des CAPTCHA simples, la plupart des scrapers sérieux s’appuient sur des services tiers (comme 2Captcha ou Anti-Captcha) pour les résoudre moyennant paiement ().
Exemple d’intégration :
1# Pseudo-code pour utiliser l'API 2Captcha
2import requests
3captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
4# attendre la solution, puis l’envoyer avec votre requêteLes honeypots sont des champs ou des liens cachés avec lesquels seuls les bots interagissent. Évitez de cliquer sur quoi que ce soit ou de soumettre quoi que ce soit qui n’est pas visible dans un vrai navigateur ().
Concevoir des en-têtes de requête robustes avec les bibliothèques Python
Au-delà du user-agent, vous pouvez faire tourner et randomiser d’autres en-têtes (comme Referer, Accept, Origin, etc.) pour mieux vous fondre dans le trafic normal.
Avec Scrapy :
1class MySpider(scrapy.Spider):
2 custom_settings = {
3 'DEFAULT_REQUEST_HEADERS': {
4 'User-Agent': '...',
5 'Accept-Language': 'en-US,en;q=0.9',
6 # autres en-têtes
7 }
8 }Avec Selenium : utilisez des profils de navigateur ou des extensions pour définir les en-têtes, ou injectez-les via JavaScript.
Gardez votre liste d’en-têtes à jour — copiez les requêtes réelles d’un navigateur avec les outils de développement pour vous en inspirer.
Quand le scraping Python traditionnel ne suffit plus : l’essor des technologies anti-bot
Voici la réalité : plus le scraping gagne en popularité, plus les systèmes anti-bot se renforcent. . La détection par IA, les seuils de requêtes dynamiques et le browser fingerprinting rendent plus difficile que jamais le fait de rester invisible, même pour des scripts Python avancés ().
Parfois, quelle que soit l’ingéniosité de votre code, vous vous heurtez à un mur. C’est là qu’il faut envisager une autre approche.
Thunderbit : une alternative d’Extracteur Web IA au scraping Python
Quand Python atteint ses limites, prend le relais en tant qu’Extracteur Web IA sans code, conçu pour les utilisateurs métier — pas seulement pour les développeurs. Au lieu de vous battre avec les proxys, les en-têtes et les CAPTCHA, l’agent IA de Thunderbit lit le site, suggère les meilleurs champs à extraire et s’occupe de tout, de la navigation sur les sous-pages à l’export des données.
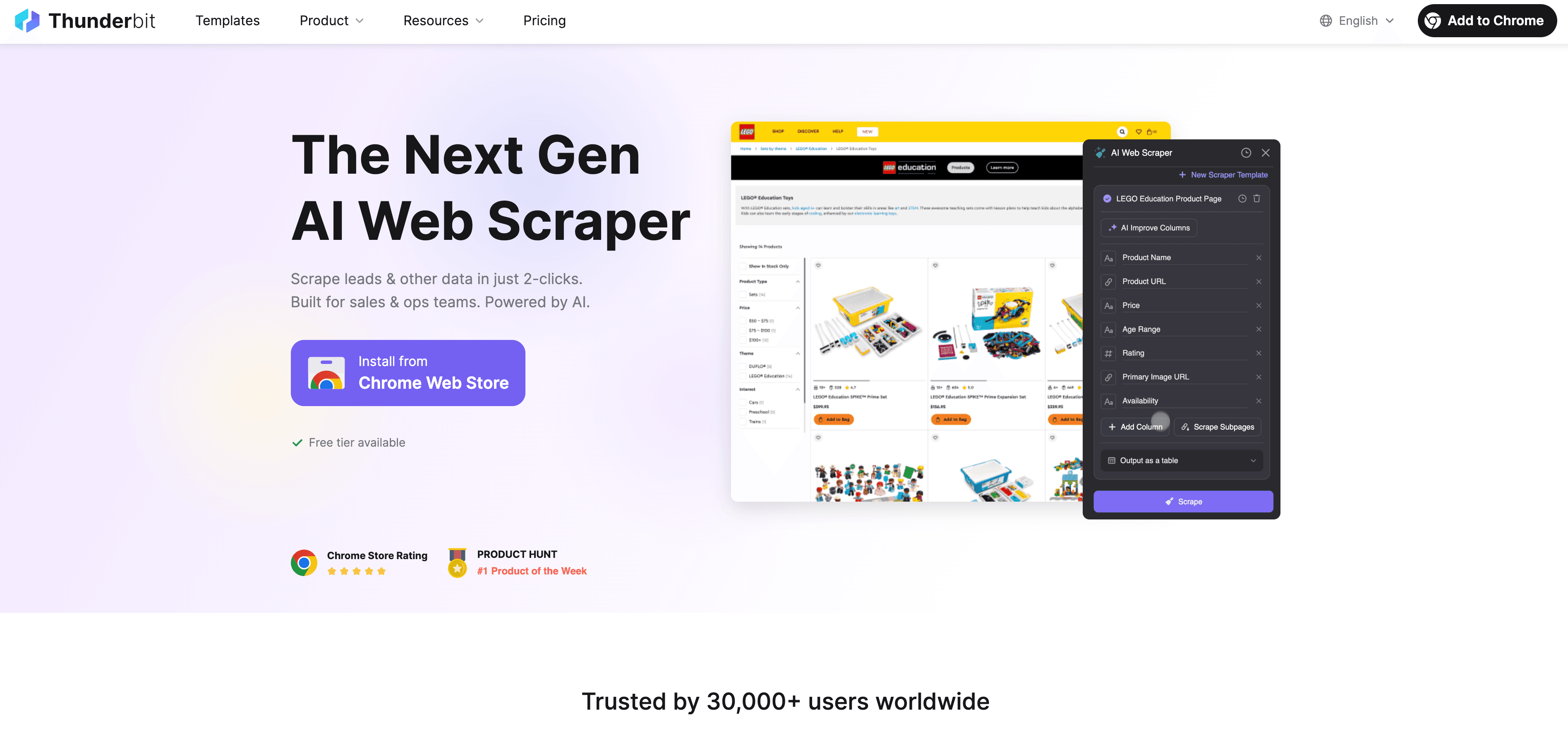
Qu’est-ce qui rend Thunderbit différent ?
- Suggestion de champs par IA : cliquez sur « Suggestion de champs IA » et Thunderbit analyse la page, recommande des colonnes et génère même des instructions d’extraction.
- Scraping des sous-pages : Thunderbit peut visiter chaque sous-page (comme les fiches produit ou les profils LinkedIn) et enrichir automatiquement votre tableau.
- Scraping cloud ou navigateur : choisissez l’option la plus rapide — le cloud pour les sites publics, le navigateur pour les pages protégées par connexion.
- Scraping programmé : configurez une fois et oubliez — Thunderbit peut scraper selon un calendrier, pour que vos données restent toujours à jour.
- Modèles instantanés : pour les sites populaires (Amazon, Zillow, Shopify, etc.), Thunderbit propose des modèles en 1 clic — aucune configuration requise.
- Export gratuit des données : exportez vers Excel, Google Sheets, Airtable ou Notion — sans frais supplémentaires.
Thunderbit est utilisé par plus de , et vous n’avez pas besoin d’écrire une seule ligne de code.
Comment Thunderbit aide les utilisateurs à éviter les blocages et à automatiser l’extraction de données
L’IA de Thunderbit ne se contente pas d’imiter un comportement humain : elle s’adapte à chaque site en temps réel, réduisant ainsi le risque de blocage. Voici comment :
- L’IA s’adapte aux changements de mise en page : fini les scripts cassés quand un site modifie son design.
- Gestion des sous-pages et de la pagination : Thunderbit suit automatiquement les liens et les listes paginées, comme un véritable utilisateur.
- Scraping cloud à grande échelle : extrayez jusqu’à 50 pages à la fois, à une vitesse fulgurante.
- Pas de code, pas de maintenance : consacrez votre temps à l’analyse, pas au débogage.
Pour aller plus loin, consultez .
Comparer le scraping Python et Thunderbit : lequel choisir ?
Mettons-les côte à côte :
| Fonctionnalité | Scraping Python | Thunderbit |
|---|---|---|
| Temps de configuration | Moyen à élevé (scripts, proxys, etc.) | Faible (2 clics, l’IA fait le reste) |
| Compétences techniques | Codage requis | Aucun codage nécessaire |
| Fiabilité | Variable (facile à casser) | Élevée (l’IA s’adapte aux changements) |
| Risque de blocage | Moyen à élevé | Faible (l’IA imite l’utilisateur, s’adapte) |
| Passage à l’échelle | Nécessite du code personnalisé et une configuration cloud | Scraping cloud et par lots intégrés |
| Maintenance | Fréquente (changements de site, blocages) | Minimale (ajustement automatique par l’IA) |
| Options d’export | Manuelles (CSV, base de données) | Direct vers Sheets, Notion, Airtable, CSV |
| Coût | Gratuit (mais chronophage) | Formule gratuite, abonnements payants pour le passage à l’échelle |
Quand utiliser Python :
- Vous avez besoin d’un contrôle total, d’une logique personnalisée ou d’une intégration avec d’autres workflows Python.
- Vous scrapez des sites avec peu de défenses anti-bot.
Quand utiliser Thunderbit :
- Vous voulez de la rapidité, de la fiabilité et zéro configuration.
- Vous scrapez des sites complexes ou qui changent souvent.
- Vous ne voulez pas gérer les proxys, les CAPTCHA ou le code.
Guide étape par étape : configurer un web scraping sans blocage en Python
Voyons un exemple concret : extraire des données produit d’un site de démonstration, tout en appliquant les bonnes pratiques anti-blocage.
1. Installer les bibliothèques requises
1pip install requests beautifulsoup4 fake-useragent2. Préparer votre script
1import requests
2from bs4 import BeautifulSoup
3from fake_useragent import UserAgent
4import time, random
5ua = UserAgent()
6urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # remplacez par vos URL
7for url in urls:
8 headers = {
9 "User-Agent": ua.random,
10 "Accept-Language": "en-US,en;q=0.9"
11 }
12 response = requests.get(url, headers=headers)
13 if response.status_code == 200:
14 soup = BeautifulSoup(response.text, "html.parser")
15 # extraire les données ici
16 print(soup.title.text)
17 else:
18 print(f"Bloqué ou erreur sur \{url\} : \{response.status_code\}")
19 time.sleep(random.uniform(2, 6)) # délai aléatoire3. Ajouter la rotation des proxys (facultatif)
1proxies = [
2 "<http://proxy1.example.com:8000>",
3 "<http://proxy2.example.com:8000>",
4 # plus de proxys
5]
6for i, url in enumerate(urls):
7 proxy = {"http": proxies[i % len(proxies)]}
8 headers = {"User-Agent": ua.random}
9 response = requests.get(url, headers=headers, proxies=proxy)
10 # ...suite du code4. Gérer les cookies et les sessions
1session = requests.Session()
2for url in urls:
3 response = session.get(url, headers=headers)
4 # ...suite du code5. Conseils de dépannage
- Si vous voyez beaucoup d’erreurs 403/429, ralentissez vos requêtes ou essayez de nouveaux proxys.
- Si vous tombez sur des CAPTCHA, envisagez Selenium ou un service de résolution de CAPTCHA.
- Vérifiez toujours le
robots.txtdu site et ses conditions d’utilisation.
Conclusion et points clés à retenir
Le web scraping en Python est puissant — mais le risque de blocage reste constant à mesure que les technologies anti-bot évoluent. La meilleure façon de prévenir le web scraping ? Combiner les bonnes pratiques techniques (proxys rotatifs, en-têtes intelligents, délais aléatoires, gestion des sessions et navigateurs headless) avec un vrai respect des règles et de l’éthique du site.
Mais parfois, même les meilleures astuces Python ne suffisent pas. C’est là que des outils propulsés par l’IA comme brillent — en offrant une manière sans code, résistante aux blocages et adaptée aux besoins métiers pour extraire rapidement les données dont vous avez besoin.
Vous voulez voir à quel point le scraping peut être simple ? et essayez-la vous-même — ou consultez notre pour plus d’astuces et de tutoriels sur le scraping.
FAQ
1. Pourquoi les sites web bloquent-ils les web scrapers Python ?
Les sites bloquent les scrapers pour protéger leurs données, éviter la surcharge des serveurs et empêcher les bots automatisés d’abuser de leurs services. Les scripts Python sont faciles à repérer s’ils utilisent les en-têtes par défaut, ne gèrent pas les cookies ou envoient trop de requêtes trop rapidement.
2. Quelles sont les méthodes les plus efficaces pour éviter d’être bloqué lors d’un scraping avec Python ?
Utilisez des proxys rotatifs, définissez un user-agent et des en-têtes réalistes, randomisez le timing des requêtes, gérez les cookies et les sessions, et simulez un comportement humain avec des outils comme Selenium ou Playwright.
3. Comment Thunderbit aide-t-il à éviter les blocages par rapport aux scripts Python ?
Thunderbit utilise l’IA pour s’adapter aux mises en page des sites, imiter la navigation humaine et gérer automatiquement les sous-pages et la pagination. Il réduit le risque de blocage en se fondant dans le trafic normal et en ajustant son approche en temps réel — sans code ni proxys.
4. Quand dois-je utiliser le scraping Python plutôt qu’un outil d’IA comme Thunderbit ?
Utilisez Python lorsque vous avez besoin d’une logique personnalisée, d’une intégration avec d’autres codes Python, ou si vous scrapez des sites simples. Utilisez Thunderbit pour un scraping rapide, fiable et scalable — surtout lorsque les sites sont complexes, changent souvent ou bloquent agressivement les scripts.
5. Le web scraping est-il légal ?
Le web scraping est légal pour les données accessibles publiquement, mais vous devez respecter les conditions d’utilisation, les politiques de confidentialité et les lois applicables à chaque site. Ne scrapez jamais de données sensibles ou privées, et pratiquez toujours le scraping de manière éthique et responsable.
Prêt à scraper plus intelligemment, pas plus difficilement ? Essayez Thunderbit et laissez les blocages derrière vous.
En savoir plus :
- Scraping Google News avec Python : guide étape par étape
- Créer un outil de suivi des prix Best Buy avec Python
- 14 méthodes pour faire du web scraping sans se faire bloquer
- 10 meilleurs conseils pour ne pas se faire bloquer lors d’un web scraping