

Le web n’est plus ce qu’il était. Aujourd’hui, presque tous les sites que vous consultez reposent sur JavaScript et chargent le contenu à la volée — pensez au défilement infini, aux pop-ups et aux tableaux de bord qui ne révèlent leurs données qu’après un ou deux clics. En réalité, 98,7 % de tous les sites utilisent désormais JavaScript (source), ce qui veut dire que les outils de scraping à l’ancienne, qui ne lisent que le HTML statique, passent à côté d’une énorme quantité de données précieuses. Si vous avez déjà essayé d’extraire les prix de produits d’un site e-commerce moderne ou de récupérer des annonces immobilières depuis une carte interactive, vous connaissez la frustration : les données que vous cherchez ne se trouvent tout simplement pas dans le code source.
C’est là que le scraping avec Selenium entre en jeu. Après des années passées à créer des outils d’automatisation — et, oui, à extraire plus que ma part de sites web — je peux vous le dire : maîtriser Selenium est un vrai super-pouvoir pour toute personne qui a besoin de données à jour et dynamiques. Dans ce tutoriel pratique sur le web scraping avec Selenium, je vais vous guider à travers les étapes clés, de l’installation à l’automatisation, et vous montrer comment combiner Selenium avec Thunderbit pour obtenir des données structurées et prêtes à exporter. Que vous soyez analyste métier, commercial ou simplement utilisateur Python curieux, vous repartirez avec des compétences concrètes et quelques sourires en bonus (car, soyons honnêtes, déboguer des sélecteurs XPath forge le caractère).
Essayez l'Extracteur Web IA Thunderbit
Qu’est-ce que Selenium et pourquoi l’utiliser pour le web scraping ?
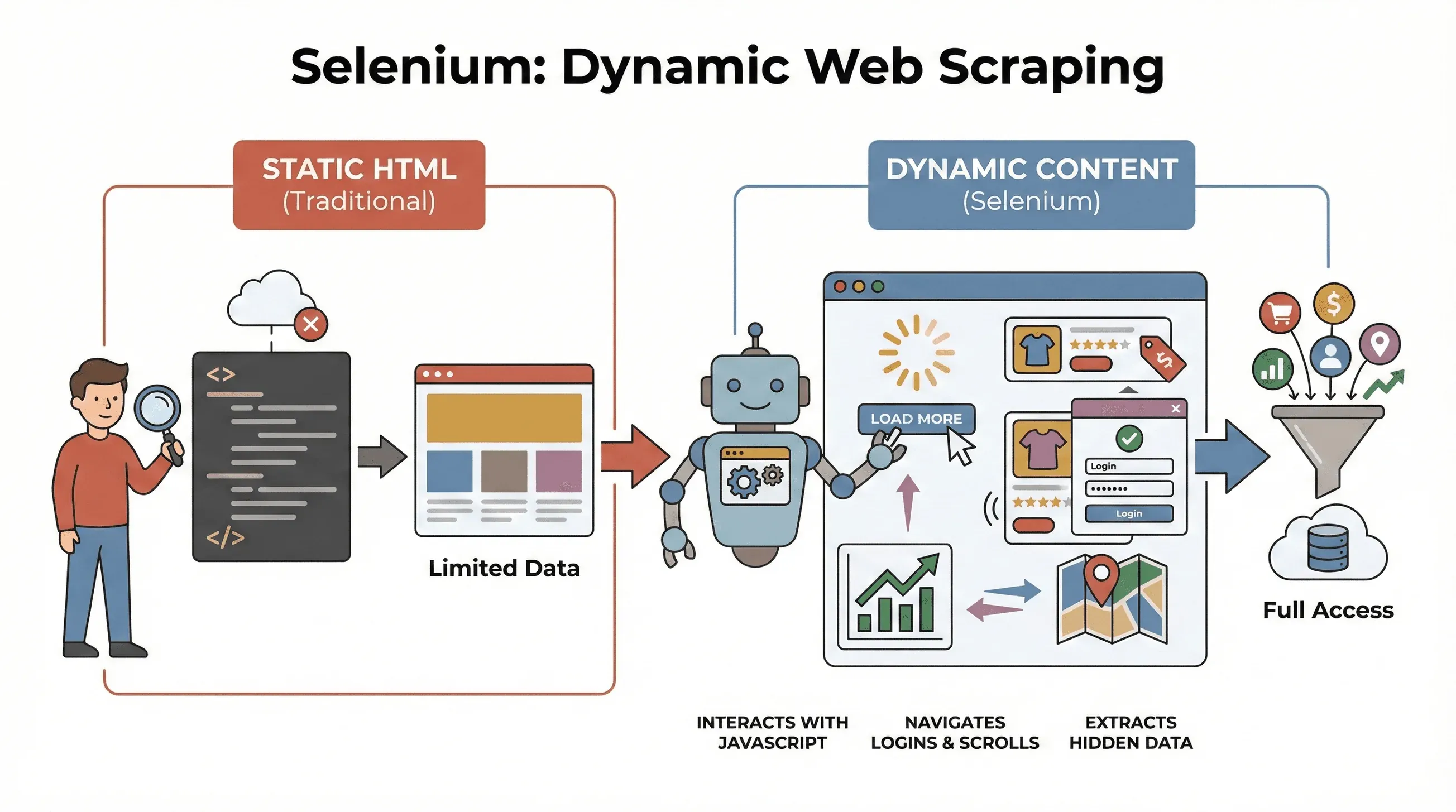 Commençons par les bases. Selenium est un framework open source qui permet de contrôler un vrai navigateur web — comme Chrome ou Firefox — à l’aide de code. Voyez-le comme un robot capable d’ouvrir des pages, de cliquer sur des boutons, de remplir des formulaires, de faire défiler la page et même d’exécuter JavaScript, tout comme un utilisateur humain. C’est essentiel, parce que la plupart des sites modernes n’affichent pas toutes leurs données d’un coup. Ils chargent plutôt le contenu de manière dynamique, souvent après une interaction avec la page.
Commençons par les bases. Selenium est un framework open source qui permet de contrôler un vrai navigateur web — comme Chrome ou Firefox — à l’aide de code. Voyez-le comme un robot capable d’ouvrir des pages, de cliquer sur des boutons, de remplir des formulaires, de faire défiler la page et même d’exécuter JavaScript, tout comme un utilisateur humain. C’est essentiel, parce que la plupart des sites modernes n’affichent pas toutes leurs données d’un coup. Ils chargent plutôt le contenu de manière dynamique, souvent après une interaction avec la page.
Qu’est-ce que le data scraping et comment le faire en 2026 Get Started Free
Pourquoi est-ce important pour le scraping ? Les outils traditionnels comme BeautifulSoup ou Scrapy sont excellents pour le HTML statique, mais ils ne peuvent pas « voir » ce qui est chargé par JavaScript après le premier chargement de la page. Selenium, en revanche, peut interagir avec la page en temps réel, ce qui le rend idéal pour :
- Extraire des listes de produits qui n’apparaissent qu’après un clic sur « Charger plus »
- Récupérer des prix ou des avis qui se mettent à jour dynamiquement
- Naviguer dans des formulaires de connexion, des pop-ups ou un défilement infini
- Extraire des données depuis des tableaux de bord, des cartes ou d’autres éléments interactifs
En bref, Selenium est l’outil de référence quand vous devez extraire des données qui n’apparaissent qu’une fois la page entièrement chargée — ou après une action de l’utilisateur.
Étapes clés du web scraping Python avec Selenium
Le scraping avec Selenium se résume à trois étapes essentielles :
| Étape | Ce que vous faites | Pourquoi c’est important |
|---|---|---|
| 1. Configuration de l’environnement | Installer Selenium, WebDriver et les bibliothèques Python | Préparer vos outils et éviter les problèmes de configuration |
| 2. Localisation des éléments | Trouver les données souhaitées à l’aide d’ID, de classes, de XPath, etc. | Cibler la bonne information, même si elle est masquée par JavaScript |
| 3. Extraction et sauvegarde des données | Récupérer du texte, des liens ou des tableaux et enregistrer en CSV/Excel | Transformer les données web brutes en quelque chose d’exploitable |
Voyons chaque étape avec des exemples pratiques et du code que vous pourrez copier, adapter et montrer fièrement à vos amis.
Étape 1 : configurer votre environnement Python Selenium
Première chose à faire : installer Selenium et un pilote de navigateur (comme ChromeDriver pour Chrome). Bonne nouvelle : c’est plus simple que jamais.
Installer Selenium
Ouvrez votre terminal et lancez :
pip install selenium
Obtenir un WebDriver
- Chrome : téléchargez ChromeDriver (assurez-vous qu’il correspond à votre version de Chrome).
- Firefox : téléchargez GeckoDriver.
Astuce de pro : avec Selenium 4.6+, vous pouvez utiliser Selenium Manager pour télécharger automatiquement les pilotes, ce qui signifie que vous n’aurez peut-être même plus à vous soucier des variables PATH (documentation).
Votre premier script Selenium
Voici un petit « hello world » pour Selenium :
from selenium import webdriver
driver = webdriver.Chrome() # Ou webdriver.Firefox()
driver.get("https://example.com")
print(driver.title)
driver.quit()
Conseils de dépannage :
- Si vous obtenez une erreur « driver not found », vérifiez votre PATH ou utilisez Selenium Manager.
- Assurez-vous que les versions de votre navigateur et de votre pilote correspondent.
- Si vous êtes sur un serveur sans interface graphique (headless), consultez les conseils sur le mode headless ci-dessous.
Étape 2 : localiser les éléments web pour extraire les données
Passons maintenant à la partie la plus amusante : dire à Selenium quelles données vous voulez. Les sites web sont construits avec des éléments — div, span, tableaux, etc. — et Selenium vous donne plusieurs façons de les trouver.
Stratégies de localisation courantes
By.ID: trouver un élément avec un ID uniqueBy.CLASS_NAME: trouver des éléments par classe CSSBy.XPATH: utiliser des expressions XPath (très flexible, mais parfois fragile)By.CSS_SELECTOR: utiliser des sélecteurs CSS (parfait pour les requêtes complexes)
Voici comment les utiliser :
from selenium.webdriver.common.by import By
# Trouver par ID
price = driver.find_element(By.ID, "price").text
# Trouver par XPath
title = driver.find_element(By.XPATH, "//h1").text
# Trouver toutes les images de produits par sélecteur CSS
images = driver.find_elements(By.CSS_SELECTOR, ".product img")
for img in images:
print(img.get_attribute("src"))
Astuce de pro : utilisez toujours le sélecteur le plus simple et le plus stable possible (ID > class > CSS > XPath). Et si vous extrayez une page qui charge les données avec un délai, utilisez des attentes explicites :
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 10)
price_elem = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".price")))
Cela évite que votre script plante si les données mettent une seconde à apparaître.
Étape 3 : extraire et sauvegarder les données
Une fois vos éléments trouvés, il est temps de récupérer les données et de les enregistrer dans un format utile.
Extraire du texte, des liens et des tableaux
Imaginons que vous extrayez un tableau de produits :
data = []
rows = driver.find_elements(By.XPATH, "//table/tbody/tr")
for row in rows:
cells = row.find_elements(By.TAG_NAME, "td")
data.append([cell.text for cell in cells])
Enregistrer en CSV avec Pandas
import pandas as pd
df = pd.DataFrame(data, columns=["Nom", "Prix", "Stock"])
df.to_csv("produits.csv", index=False)
Vous pouvez aussi enregistrer au format Excel (df.to_excel("produits.xlsx")) ou même envoyer les données vers Google Sheets via leur API.
Exemple complet : extraire les titres et prix de produits
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
driver = webdriver.Chrome()
driver.get("https://example.com/products")
data = []
products = driver.find_elements(By.CLASS_NAME, "product-card")
for p in products:
title = p.find_element(By.CLASS_NAME, "title").text
price = p.find_element(By.CLASS_NAME, "price").text
data.append([title, price])
driver.quit()
df = pd.DataFrame(data, columns=["Titre", "Prix"])
df.to_csv("produits.csv", index=False)
Selenium vs BeautifulSoup et Scrapy : qu’est-ce qui rend Selenium unique ?
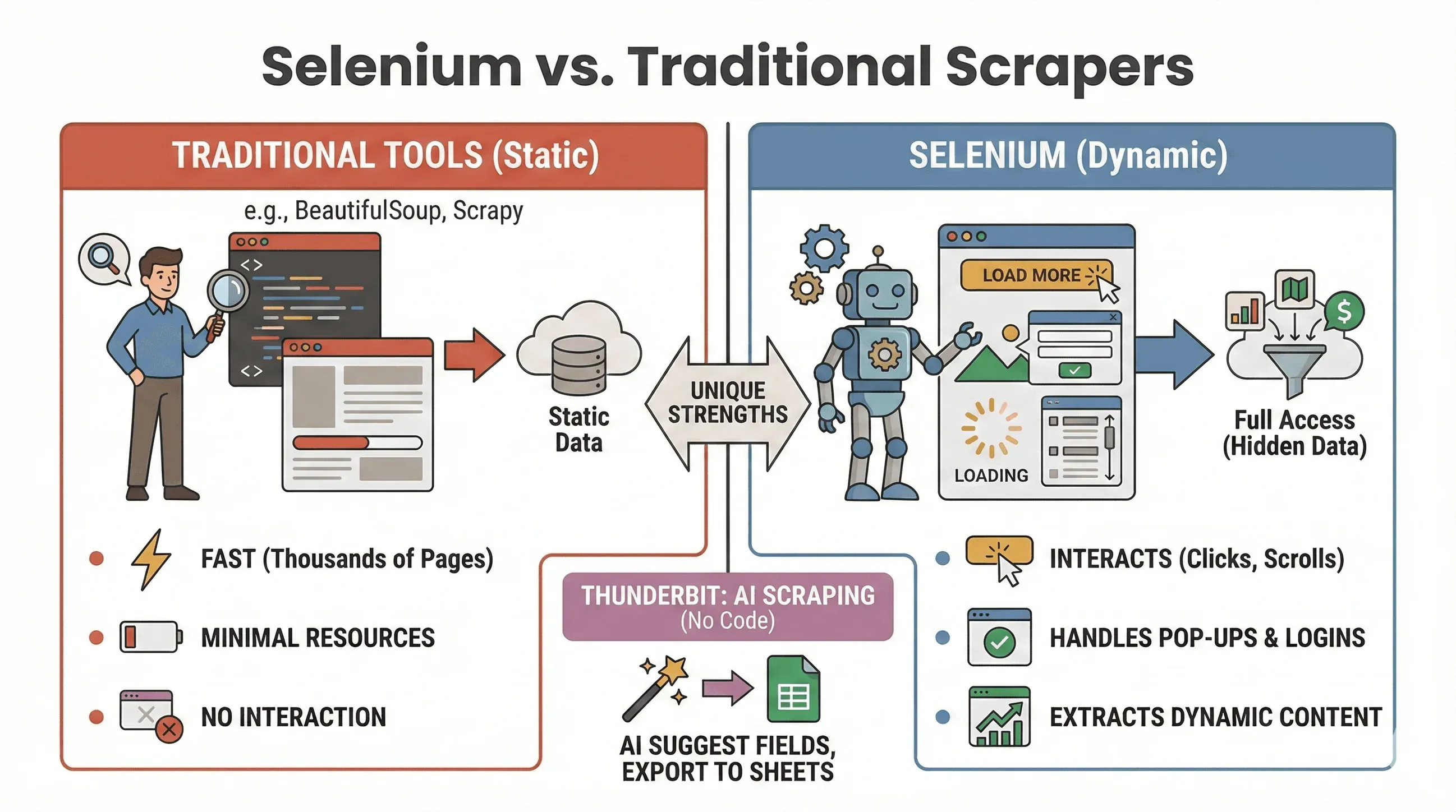 Mettons fin au débat : quand faut-il utiliser Selenium, et quand BeautifulSoup ou Scrapy est-il plus adapté ? Voici une comparaison rapide :
Mettons fin au débat : quand faut-il utiliser Selenium, et quand BeautifulSoup ou Scrapy est-il plus adapté ? Voici une comparaison rapide :
| Outil | Idéal pour | Gère JavaScript ? | Vitesse et consommation de ressources |
|---|---|---|---|
| Selenium | Sites dynamiques / interactifs | Oui | Plus lent, utilise plus de mémoire |
| BeautifulSoup | Scraping simple de HTML statique | Non | Très rapide, léger |
| Scrapy | Exploration de sites statiques à grande échelle | Limité* | Très rapide, asynchrone, faible RAM |
| Thunderbit | Scraping métier sans code | Oui (IA) | Rapide pour les tâches petites à moyennes |
*Scrapy peut gérer une partie du contenu dynamique avec des plugins, mais ce n’est pas son point fort (ScrapingBee).
Quand utiliser Selenium :
- Les données n’apparaissent qu’après un clic, un défilement ou une connexion
- Vous devez interagir avec des pop-ups, un défilement infini ou des tableaux de bord dynamiques
- Les extracteurs statiques ne suffisent tout simplement pas
Quand utiliser BeautifulSoup/Scrapy :
- Les données se trouvent dans le HTML initial
- Vous devez extraire des milliers de pages rapidement
- Vous voulez une consommation minimale de ressources
Et si vous voulez éviter complètement le code, Thunderbit vous permet d’extraire des sites dynamiques avec l’IA — il suffit de cliquer sur « AI Suggest Fields » puis d’exporter vers Sheets, Notion ou Airtable. (Nous y revenons plus bas.)
Comment extraire n’importe quel site web avec l’IA Get Started Free
Automatiser les tâches de web scraping avec Selenium et Python
Soyons honnêtes : personne n’a envie de se lever à 2 h du matin pour lancer un script de scraping. La bonne nouvelle, c’est que vous pouvez automatiser vos tâches Selenium avec les outils de planification de Python ou le planificateur de votre système d’exploitation (comme cron sous Linux/Mac ou le Planificateur de tâches sous Windows).
Utiliser la bibliothèque schedule
import schedule
import time
def job():
# Votre code de scraping ici
print("Scraping...")
schedule.every().day.at("09:00").do(job)
while True:
schedule.run_pending()
time.sleep(1)
Ou avec cron (Linux/Mac)
Ajoutez ceci à votre crontab pour l’exécuter toutes les heures :
0 * * * * python /path/to/your_script.py
Conseils pour l’automatisation :
- Exécutez Selenium en mode headless (voir ci-dessous) pour éviter les pop-ups de l’interface graphique.
- Consignez les erreurs et envoyez-vous des alertes en cas de problème.
- Fermez toujours le navigateur avec
driver.quit()pour libérer les ressources.
Gagner en efficacité : conseils pour un scraping Selenium plus rapide et plus fiable
Selenium est puissant, mais il peut être lent et gourmand en ressources si vous n’y prenez pas garde. Voici comment accélérer le tout et éviter les problèmes les plus courants :
1. Utiliser le mode headless
Inutile de regarder Chrome s’ouvrir et se fermer cent fois. Le mode headless exécute le navigateur en arrière-plan :
from selenium.webdriver.chrome.options import Options
opts = Options()
opts.headless = True
driver = webdriver.Chrome(options=opts)
2. Bloquer les images et autres contenus inutiles
Pourquoi charger des images si vous ne faites que récupérer du texte ? Bloquez-les pour accélérer le chargement des pages :
prefs = {"profile.managed_default_content_settings.images": 2}
opts.add_experimental_option("prefs", prefs)
3. Utiliser des sélecteurs efficaces
- Préférez les ID ou les sélecteurs CSS simples aux XPath complexes.
- Évitez
time.sleep(); utilisez plutôt des attentes explicites (WebDriverWait).
4. Randomiser les délais
Ajoutez des pauses aléatoires pour imiter une navigation humaine et éviter le blocage :
import random, time
time.sleep(random.uniform(1, 3))
5. Faire tourner les user agents et les IPs si nécessaire
Si vous extrayez beaucoup de données, faites varier votre chaîne user agent et envisagez d’utiliser des proxies pour éviter les mécanismes anti-bot simples.
6. Gérer les sessions et les erreurs
- Utilisez des blocs try/except pour gérer proprement les éléments manquants.
- Journalisez les erreurs et prenez des captures d’écran pour le débogage.
Pour plus de conseils d’optimisation, consultez le guide de BrowserStack.
Avancé : combiner Selenium avec Thunderbit pour exporter des données structurées
C’est là que les choses deviennent vraiment intéressantes — surtout si vous voulez gagner du temps sur le nettoyage et l’export des données.
Après avoir extrait les données brutes avec Selenium, vous pouvez utiliser Thunderbit pour :
- Détecter automatiquement les champs : l’IA de Thunderbit peut lire vos pages extraites ou vos CSV et suggérer des noms de colonnes (« AI Suggest Fields »).
- Scraping de sous-pages : si vous avez une liste d’URL (comme des pages produit), Thunderbit peut visiter chacune d’elles et enrichir votre tableau avec davantage de détails — sans code supplémentaire.
- Enrichissement des données : traduire, catégoriser ou analyser les données à la volée.
- Exporter partout : export en un clic vers Google Sheets, Airtable, Notion, CSV ou Excel.
Exemple de workflow :
- Utilisez Selenium pour extraire une liste d’URL et de titres de produits.
- Exportez les données en CSV.
- Ouvrez Thunderbit, importez votre CSV et laissez l’IA suggérer les champs.
- Utilisez le scraping de sous-pages de Thunderbit pour récupérer davantage de détails (comme des images ou des spécifications) depuis chaque URL produit.
- Exportez votre jeu de données final et structuré vers Sheets ou Notion.
Cette combinaison vous fait gagner des heures de nettoyage manuel et vous permet de vous concentrer sur l’analyse, pas sur la manipulation de données sales. Pour en savoir plus sur ce workflow, consultez le guide Selenium de Thunderbit.
Exportez vos données Selenium avec Thunderbit IA
Bonnes pratiques et dépannage pour le web scraping avec Selenium
Le web scraping, c’est un peu comme la pêche : parfois vous attrapez un gros poisson, parfois vous vous emmêlez dans les herbes. Voici comment garder des scripts fiables — et éthiques :
Bonnes pratiques
- Respectez robots.txt et les conditions du site : vérifiez toujours si le scraping est autorisé.
- Limitez le rythme de vos requêtes : n’inondez pas les serveurs — ajoutez des délais et surveillez les erreurs HTTP 429.
- Utilisez les API lorsqu’elles existent : si les données sont accessibles publiquement via une API, privilégiez-la ; c’est plus sûr et plus fiable.
- Ne récupérez que des données publiques : évitez les informations personnelles ou sensibles, et tenez compte des lois sur la protection de la vie privée.
- Gérez les pop-ups et les CAPTCHAs : utilisez Selenium pour fermer les pop-ups, mais méfiez-vous des CAPTCHAs — ils sont difficiles à automatiser.
- Randomisez les user agents et les délais : cela aide à éviter la détection et le blocage.
Erreurs courantes et solutions
| Erreur | Ce que cela signifie | Comment corriger |
|---|---|---|
NoSuchElementException | Impossible de trouver l’élément | Vérifiez votre sélecteur ; utilisez des attentes |
| Erreurs de délai d’attente | La page ou l’élément a mis trop longtemps | Augmentez le délai d’attente ; vérifiez la vitesse du réseau |
| Incompatibilité driver/navigateur | Selenium ne peut pas lancer le navigateur | Mettez à jour les versions du driver et du navigateur |
| Crash de session | Le navigateur s’est fermé de façon inattendue | Utilisez le mode headless ; gérez les ressources |
Pour plus de conseils de dépannage, consultez le tutoriel Selenium de Thunderbit.
Conclusion et points clés à retenir
Le web scraping dynamique n’est plus réservé aux développeurs chevronnés. Avec Python Selenium, vous pouvez automatiser n’importe quel navigateur, interagir avec les sites JavaScript les plus complexes et récupérer les données dont votre activité a besoin — que ce soit pour la vente, la recherche ou simplement par curiosité. Rappelez-vous :
- Selenium est l’outil de choix pour les sites dynamiques et interactifs.
- Les trois étapes clés : configuration, localisation, extraction et sauvegarde.
- Automatisez vos scripts pour obtenir des mises à jour régulières des données.
- Optimisez la vitesse et la fiabilité avec le mode headless, des attentes intelligentes et des sélecteurs efficaces.
- Combinez Selenium avec Thunderbit pour structurer et exporter facilement les données — surtout si vous voulez éviter les casse-têtes de tableurs.
Prêt à vous lancer ? Commencez avec les exemples de code ci-dessus, puis, quand vous serez prêt à passer à l’étape supérieure, essayez Thunderbit pour un nettoyage et un export de données instantanés, propulsés par l’IA. Et si vous voulez aller plus loin, consultez le blog Thunderbit pour des analyses approfondies, des tutoriels et les dernières nouveautés en automatisation web.
Bon scraping — et que vos sélecteurs trouvent toujours ce que vous cherchez.
Essayez gratuitement l'Extracteur Web IA Thunderbit Get Started Free
FAQ
1. Pourquoi devrais-je utiliser Selenium pour le web scraping plutôt que BeautifulSoup ou Scrapy ?
Selenium est idéal pour extraire des sites dynamiques dont le contenu se charge après des actions de l’utilisateur ou l’exécution de JavaScript. BeautifulSoup et Scrapy sont plus rapides pour le HTML statique, mais ne peuvent pas interagir avec des éléments dynamiques ni simuler des clics ou des défilements.
2. Comment rendre mon extracteur Selenium plus rapide ?
Utilisez le mode headless, bloquez les images et les ressources inutiles, utilisez des sélecteurs efficaces et ajoutez des délais aléatoires pour imiter une navigation humaine. Consultez le guide de BrowserStack pour plus de conseils.
3. Puis-je programmer des tâches de scraping Selenium pour qu’elles s’exécutent automatiquement ?
Oui ! Utilisez la bibliothèque schedule de Python ou le planificateur de votre système d’exploitation (cron ou le Planificateur de tâches) pour lancer les scripts à intervalles réguliers. L’automatisation aide à garder vos données à jour.
4. Quelle est la meilleure façon d’exporter des données extraites avec Selenium ?
Utilisez Pandas pour enregistrer les données en CSV ou Excel. Pour des exports plus avancés (Google Sheets, Notion, Airtable), importez vos données dans Thunderbit et utilisez ses fonctions d’export en un clic.
5. Comment gérer les pop-ups et les CAPTCHAs dans Selenium ?
Vous pouvez fermer les pop-ups en localisant leur bouton de fermeture et en cliquant dessus. Les CAPTCHAs sont beaucoup plus difficiles à gérer ; si vous en rencontrez, envisagez une solution manuelle ou un service de résolution de CAPTCHA, et respectez toujours les conditions d’utilisation du site.
Vous voulez voir d’autres tutoriels de scraping, des conseils d’automatisation IA ou les dernières nouveautés sur les outils de données métier ? Abonnez-vous au blog Thunderbit ou consultez notre chaîne YouTube pour des démonstrations pratiques.
En savoir plus




