

Permettez-moi de vous ramener à un passé pas si lointain : je suis assis à mon bureau, un café à la main, à fixer un tableur plus vide que mon frigo un dimanche soir. L’équipe commerciale veut des données de prix concurrents, l’équipe marketing veut des prospects fraîchement collectés, et l’équipe opérations veut des fiches produits provenant d’une douzaine de sites — pour hier. Je sais que ces données existent, mais les obtenir ? C’est là que réside le vrai défi. Si vous avez déjà eu l’impression de jouer au jeu de la taupe numérique avec du copier-coller, vous n’êtes pas seul.
Aujourd’hui, le paysage a changé. Le web scraping est passé d’un projet de passionné à une stratégie d’entreprise incontournable. JavaScript et Node.js sont désormais au premier plan, alimentant aussi bien de petits scripts ponctuels que de véritables pipelines de données. Mais voilà : même si les outils sont plus puissants que jamais, la courbe d’apprentissage peut encore donner l’impression d’escalader l’Everest en tongs. Que vous soyez un utilisateur métier, un passionné de données ou simplement quelqu’un qui en a assez de la saisie manuelle, ce guide est pour vous. Je vais décrypter l’écosystème, les bibliothèques indispensables, les points de friction, et expliquer pourquoi, parfois, la meilleure option consiste à laisser l’IA faire le gros du travail.
Pourquoi le web scraping avec JavaScript et Node.js est important pour les entreprises
Commençons par le « pourquoi ». En 2026, les données web ne sont plus un simple bonus — elles sont stratégiques. Selon des recherches récentes, 73 % des entreprises attribuent aux données web publiques une prise de décision plus rapide et plus précise, et environ 42 % des budgets de données d’entreprise sont désormais consacrés à la collecte de données web. Le marché des données alternatives (qui inclut le web scraping) pèse déjà 4,9 milliards de dollars et continue de croître rapidement.
Alors, qu’est-ce qui alimente cette ruée vers l’or ? Voici quelques-uns des cas d’usage les plus courants en entreprise :
- Tarification concurrentielle et e-commerce : les enseignes extraient des sites concurrents les prix et les stocks, ce qui peut parfois augmenter les ventes de 4 % ou plus.
- Génération de leads et sales intelligence : les équipes commerciales automatisent la collecte d’e-mails, de numéros de téléphone et d’informations sur les entreprises depuis des annuaires et des plateformes sociales.
- Études de marché et agrégation de contenu : les analystes récupèrent des actualités, des avis et des données de sentiment pour repérer les tendances et anticiper les évolutions.
- Publicité et ad tech : les entreprises ad tech suivent en temps réel les emplacements publicitaires et les campagnes des concurrents.
- Immobilier et voyage : les agences extraient des annonces, des prix et des avis pour alimenter des modèles d’évaluation et des analyses de marché.
- Agrégateurs de contenu et de données : les plateformes centralisent des données provenant de plusieurs sources pour alimenter des outils de comparaison et des tableaux de bord.
JavaScript et Node.js sont devenus la pile de référence pour ces tâches, surtout avec le recours croissant des sites web à du contenu dynamique rendu en JavaScript. Node.js excelle dans les opérations asynchrones, ce qui en fait un choix naturel pour le scraping à grande échelle. Et avec un écosystème de bibliothèques particulièrement riche, vous pouvez tout construire, du script rapide au scraper robuste, prêt pour la production.
Qu’est-ce que le data scraping et comment le faire en 2025 Get Started Free
Le workflow de base : comment fonctionne le web scraping avec JavaScript et Node.js
Démystifions le workflow typique du web scraping. Que vous extrayiez un simple blog ou un site e-commerce très riche en JavaScript, les étapes restent globalement les mêmes :
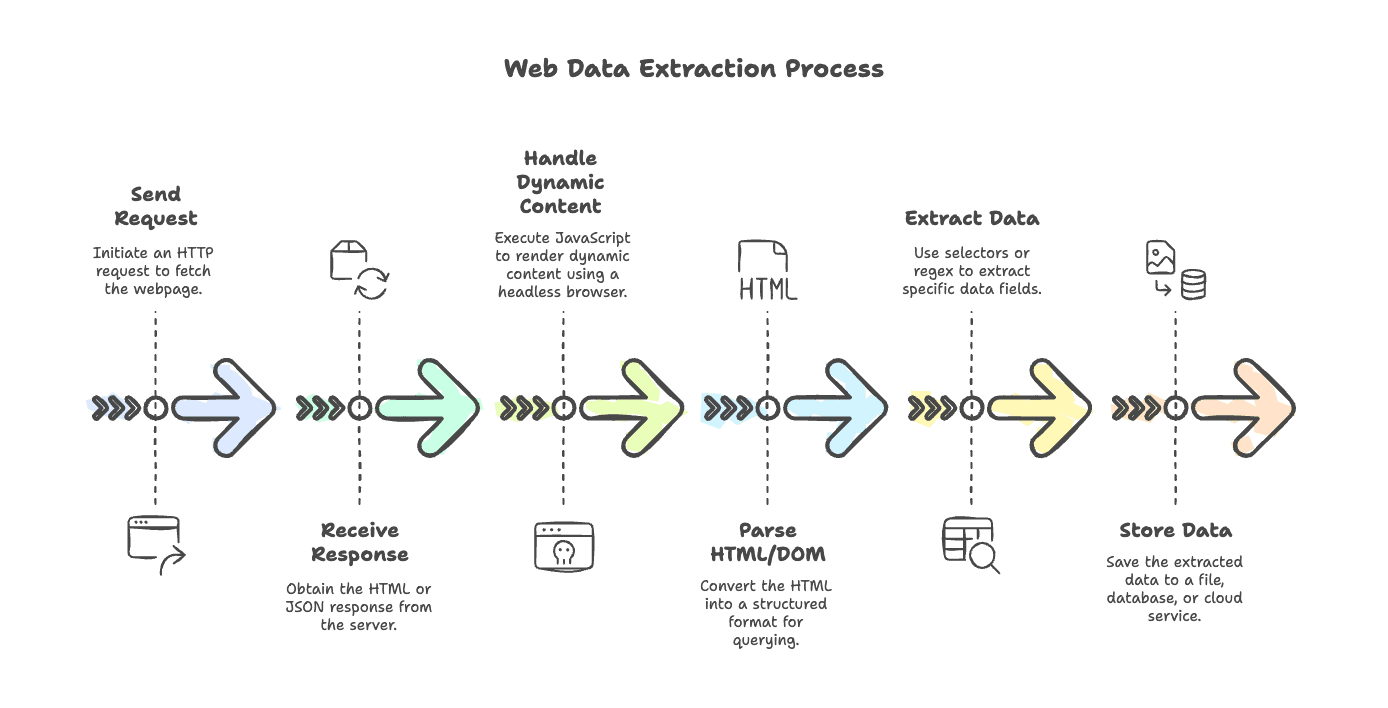
- Envoyer une requête : utilisez un client HTTP pour récupérer la page (comme
axios,node-fetchougot). - Recevoir la réponse : récupérez le HTML — ou parfois du JSON — renvoyé par le serveur.
- Gérer le contenu dynamique : si la page est rendue par JavaScript, utilisez un navigateur sans interface (comme Puppeteer ou Playwright) pour exécuter les scripts et obtenir le contenu final.
- Analyser le HTML/DOM : utilisez un parseur (
cheerio,jsdom) pour transformer le HTML en une structure interrogeable. - Extraire les données : utilisez des sélecteurs ou des expressions régulières pour récupérer les champs nécessaires.
- Stocker les données : enregistrez les résultats dans un fichier, une base de données ou un service cloud.
Chaque étape dispose de ses propres outils et bonnes pratiques, que nous allons explorer juste après.
Bibliothèques HTTP indispensables pour le web scraping en JavaScript
La première étape de tout scraper consiste à envoyer des requêtes HTTP. Node.js vous offre un large choix d’options, des plus classiques aux plus modernes. Voici un tour d’horizon des bibliothèques les plus populaires :
1. Axios
Un client HTTP basé sur les promesses pour Node et les navigateurs. C’est le « couteau suisse » de la plupart des besoins en scraping.
const axios = require('axios');
const response = await axios.get('https://example.com/api/items', { timeout: 5000 });
console.log(response.data);
Avantages : très complet, compatible async/await, parsing JSON automatique, intercepteurs et prise en charge des proxys.
Inconvénients : un peu plus lourd, et parfois un peu trop « magique » dans sa gestion des données.
2. node-fetch
Implémente l’API fetch du navigateur dans Node.js. Minimaliste et moderne.
import fetch from 'node-fetch';
const res = await fetch('https://api.github.com/users/github');
const data = await res.json();
console.log(data);
Avantages : léger, API familière pour celles et ceux qui viennent du JavaScript frontend.
Inconvénients : peu de fonctionnalités, gestion des erreurs manuelle, configuration du proxy assez verbeuse.
3. SuperAgent
Une bibliothèque HTTP éprouvée avec une API enchaînable.
const superagent = require('superagent');
const res = await superagent.get('https://example.com/data');
console.log(res.body);
Avantages : mature, prise en charge des formulaires, uploads de fichiers et plugins.
Inconvénients : API un peu datée, dépendance plus lourde.
4. Unirest
Un client HTTP simple et agnostique du langage.
const unirest = require('unirest');
unirest.get('https://httpbin.org/get?query=web')
.end(response => {
console.log(response.body);
});
Avantages : syntaxe simple, pratique pour les scripts rapides.
Inconvénients : moins de fonctionnalités, communauté moins active.
5. Got
Un client HTTP Node.js robuste et rapide, avec des fonctionnalités avancées.
import got from 'got';
const html = await got('https://example.com/page').text();
console.log(html.length);
Avantages : rapide, prend en charge HTTP/2, les tentatives automatiques et les streams.
Inconvénients : réservé à Node, API parfois un peu dense pour les débutants.
6. Le http/https natif de Node
Vous pouvez toujours revenir aux bases :
const https = require('https');
https.get('https://example.com/data', (res) => {
let data = '';
res.on('data', chunk => { data += chunk; });
res.on('end', () => {
console.log('Longueur de la réponse :', data.length);
});
});
Avantages : aucune dépendance.
Inconvénients : verbeux, basé sur les callbacks, sans promesses.
Voir ici une comparaison détaillée des fonctionnalités et des exemples de code.
Choisir le bon client HTTP pour votre projet
Comment choisir le bon outil ? Voici ce que je regarde :
- Facilité d’utilisation : Axios et Got sont excellents pour async/await et une syntaxe claire.
- Performance : Got et node-fetch sont légers et rapides pour le scraping à forte concurrence.
- Prise en charge des proxys : Axios et Got facilitent la rotation des proxys.
- Gestion des erreurs : Axios lève des erreurs par défaut sur les réponses HTTP ; node-fetch nécessite des vérifications manuelles.
- Communauté : Axios et Got disposent de communautés actives et de nombreux exemples.
Mes recommandations rapides :
- Scripts rapides ou prototypes : node-fetch ou Unirest.
- Scraping en production : Axios (pour ses fonctionnalités) ou Got (pour ses performances).
- Automatisation du navigateur : Puppeteer ou Playwright gèrent les requêtes en interne.
Analyse HTML et extraction de données : Cheerio, jsdom, et plus encore
Une fois le HTML récupéré, il faut le transformer en quelque chose d’exploitable. C’est là qu’interviennent les parseurs.
Cheerio
Voyez Cheerio comme jQuery côté serveur. C’est rapide, léger et parfait pour du HTML statique.
const cheerio = require('cheerio');
const $ = cheerio.load('<ul><li class="item">Item 1</li></ul>');
$('.item').each((i, el) => {
console.log($(el).text());
});
Avantages : extrêmement rapide, API familière, gère le HTML imparfait.
Inconvénients : n’exécute pas le JavaScript — il ne voit que ce qui est présent dans le HTML.
En savoir plus sur la vitesse de Cheerio et ses cas d’usage.
jsdom
jsdom simule un DOM proche de celui d’un navigateur dans Node.js. Il peut exécuter des scripts simples et se rapproche davantage d’un navigateur que Cheerio.
const { JSDOM } = require('jsdom');
const dom = new JSDOM(`<p id="greet">Hello</p><script>document.querySelector('#greet').textContent += ", world!";</script>`);
console.log(dom.window.document.querySelector('#greet').textContent);
Avantages : peut exécuter des scripts, prend en charge l’API DOM complète.
Inconvénients : plus lent et plus lourd que Cheerio, sans être un vrai navigateur.
Comparer Cheerio et jsdom en détail.
Quand utiliser les expressions régulières ou d’autres méthodes d’analyse
En web scraping, les regex, c’est comme la sauce piquante : très bien avec modération, mais n’en versez pas partout. Elles sont utiles pour :
- Extraire des motifs dans du texte (e-mails, numéros de téléphone, prix).
- Nettoyer ou valider des données extraites.
- Récupérer des informations depuis des blocs de texte ou des balises script.
Exemple : extraire un nombre depuis du texte
const text = "Total sales: 1,234 units";
const match = text.match(/([\d,]+)\s*units/);
if (match) {
const units = parseInt(match[1].replace(/,/g, ''));
console.log("Unités vendues :", units);
}
Mais n’essayez pas d’analyser du HTML complet avec des regex — pour cela, utilisez un parseur DOM. Plus de conseils regex pour le scraping.
Gérer les sites dynamiques : Puppeteer, Playwright et les navigateurs sans interface
Les sites web modernes adorent JavaScript. Parfois, les données que vous cherchez ne figurent pas dans le HTML initial : elles sont rendues par des scripts après le chargement de la page. C’est là qu’entrent en scène les navigateurs sans interface.
Puppeteer
Une bibliothèque Node.js de Google qui contrôle Chrome/Chromium. C’est comme avoir un robot qui clique et fait défiler les pages à votre place.
const puppeteer = require('puppeteer');
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const title = await page.$eval('h1', el => el.textContent);
console.log(title);
await browser.close();
Avantages : rendu complet de Chrome, API simple, idéale pour le contenu dynamique.
Inconvénients : limité à Chromium, plus gourmand en ressources.
En savoir plus sur les points forts de Puppeteer.
Playwright
Une bibliothèque plus récente de Microsoft, Playwright prend en charge Chromium, Firefox et WebKit. C’est un peu le cousin plus cool et multi-navigateurs de Puppeteer.
const { chromium } = require('playwright');
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const content = await page.textContent('h1');
console.log(content);
await browser.close();
Avantages : multi-navigateurs, contextes parallèles, attente automatique des éléments.
Inconvénients : courbe d’apprentissage un peu plus raide, installation plus volumineuse.
Pourquoi Playwright gagne du terrain.
Nightmare
Un outil d’automatisation basé sur Electron, autrefois populaire. Le dépôt a été transféré dans l’organisation GitHub segment-boneyard — le dépôt de projets abandonnés de Segment — et la dernière version npm date de 2019. Je ne le recommanderais plus pour un nouveau projet en 2026 ; si vous reprenez un script qui l’utilise encore, pourquoi pas, mais pour un projet neuf, passez directement à Playwright ou Puppeteer.
Comparer les solutions de navigateur sans interface
| Aspect | Puppeteer (Chrome) | Playwright (multi-navigateurs) | Nightmare (Electron) |
|---|---|---|---|
| Prise en charge des navigateurs | Chrome/Edge | Chrome, Firefox, WebKit | Chrome (ancien) |
| Performance et montée en charge | Rapide, mais lourd | Rapide, meilleure parallélisation | Plus lent, moins stable |
| Scraping dynamique | Excellent | Excellent + davantage de fonctionnalités | Correct pour les sites simples |
| Maintenance | Bien maintenu | Très actif | Archivé (segment-boneyard, dernière publication npm en 2019) |
| Idéal pour | Scraping Chrome | Projets complexes, multi-navigateurs | Tâches simples, héritées |
Mon conseil : utilisez Playwright pour les nouveaux projets complexes. Puppeteer reste excellent pour les tâches limitées à Chrome. Nightmare, lui, relève surtout de la nostalgie ou des anciens scripts.
Outils complémentaires : planification, environnement, CLI et stockage des données
Un vrai scraper ne se limite pas à récupérer puis analyser des pages. Voici quelques outils complémentaires sur lesquels je m’appuie :
Planification : node-cron
Planifiez l’exécution automatique des scrapers.
const cron = require('node-cron');
cron.schedule('0 9 * * MON', () => {
console.log('Scraping à 9 h tous les lundis');
});
Node-cron est parfait pour automatiser les tâches répétitives.
Gestion de l’environnement : dotenv
Gardez les secrets et les configurations hors de votre code.
require('dotenv').config();
const apiKey = process.env.API_KEY;
Outils CLI : chalk, commander, inquirer
- chalk : colore la sortie du terminal.
- commander : analyse les options de ligne de commande.
- inquirer : invite interactive pour la saisie utilisateur.
Stockage des données
- fs : écrire dans des fichiers (JSON, CSV).
- lowdb : base de données JSON légère.
- sqlite3 : base de données SQL locale.
- mongodb : base de données NoSQL pour les projets plus importants.
Exemple : enregistrer des données au format JSON
const fs = require('fs');
fs.writeFileSync('output.json', JSON.stringify(data, null, 2));
Les points douloureux du web scraping traditionnel avec JavaScript et Node.js
Soyons honnêtes : le scraping traditionnel n’est pas un long fleuve tranquille. Voici les principaux casse-têtes que j’ai observés — et ressentis :

- Courbe d’apprentissage élevée : il faut comprendre le DOM, les sélecteurs, la logique asynchrone et parfois les particularités des navigateurs.
- Charge de maintenance : les sites changent, les sélecteurs cassent, et vous passez votre temps à corriger le code.
- Faible évolutivité : chaque site a besoin de son propre script ; rien n’est vraiment universel.
- Complexité du nettoyage des données : les données extraites sont souvent sales ; les nettoyer, les formater et supprimer les doublons est déjà un travail à part entière.
- Limites de performance : l’automatisation du navigateur est lente et gourmande en ressources pour les gros volumes.
- Blocages et mesures anti-bot : les sites bloquent les scrapers, affichent des CAPTCHA ou cachent les données derrière une connexion.
- Zones grises juridiques et éthiques : il faut composer avec les conditions d’utilisation, la confidentialité et la conformité.
En savoir plus sur ces points de friction et sur les chiffres du terrain.
Thunderbit vs le web scraping traditionnel : une révolution en productivité
Parlons maintenant de l’éléphant dans la pièce : et si vous pouviez vous passer de tout le code, des sélecteurs et de la maintenance ?
C’est là qu’intervient Thunderbit. En tant que cofondateur et CEO, je suis peut-être un peu biaisé, mais laissez-moi vous expliquer : Thunderbit est conçu pour les utilisateurs métier qui veulent des données, pas des migraines.
Comment Thunderbit se compare
| Aspect | Thunderbit (IA sans code) | Scraping JS/Node traditionnel |
|---|---|---|
| Configuration | 2 clics, sans code | Écrire des scripts, déboguer |
| Contenu dynamique | Géré dans le navigateur | Script avec navigateur sans interface |
| Maintenance | L’IA s’adapte aux changements | Mises à jour manuelles du code |
| Extraction de données | Suggestion de champs par l’IA | Sélecteurs manuels |
| Scraping de sous-pages | Intégré, en 1 clic | Boucles et code par site |
| Export | Excel, Sheets, Notion | Intégration manuelle fichier/base de données |
| Post-traitement | Résumer, taguer, formater | Code ou outils supplémentaires |
| Qui peut l’utiliser | Toute personne avec un navigateur | Développeurs uniquement |
L’IA de Thunderbit lit la page, suggère les champs et extrait les données en seulement quelques clics. Elle gère les sous-pages, s’adapte aux changements de mise en page et peut même résumer, taguer ou traduire les données pendant l’extraction. Vous pouvez exporter vers Excel, Google Sheets, Airtable ou Notion — sans aucune configuration technique.
Cas d’usage où Thunderbit excelle :
- équipes e-commerce qui suivent les SKU et les prix des concurrents
- équipes commerciales qui extraient des leads et des coordonnées
- chercheurs en marché qui agrègent des actualités ou des avis
- agents immobiliers qui récupèrent des annonces et des détails de biens
Pour un scraping fréquent et critique pour l’activité, Thunderbit fait gagner énormément de temps. Pour des projets sur mesure, à grande échelle ou profondément intégrés, le scripting traditionnel garde toute sa place — mais pour la plupart des équipes, Thunderbit est le moyen le plus rapide de passer de « j’ai besoin de données » à « j’ai les données ».
Voir l’extension Chrome Thunderbit en action ou découvrez d’autres cas d’usage sur le Thunderbit Blog.
Essayez l’Extracteur Web IA de Thunderbit
Référence rapide : bibliothèques JavaScript et Node.js populaires pour le web scraping
Voici votre mémo de référence pour l’écosystème JavaScript du scraping en 2026 :
Requêtes HTTP
- Axios : client HTTP basé sur les promesses, très complet.
- node-fetch : API
fetchpour Node.js. - Got : client HTTP rapide et avancé.
- SuperAgent : requêtes HTTP matures et enchaînables.
- Unirest : client simple et agnostique du langage.
Analyse HTML
Contenu dynamique
- Puppeteer : automatisation headless de Chrome.
- Playwright : automatisation multi-navigateurs.
- Nightmare : automatisation de navigateur héritée, basée sur Electron.
Planification
- node-cron : tâches cron dans Node.js.
CLI et utilitaires
- chalk : mise en forme des chaînes dans le terminal.
- commander : analyseur d’arguments CLI.
- inquirer : invites CLI interactives.
- dotenv : chargeur de variables d’environnement.
Stockage
- fs : système de fichiers intégré.
- lowdb : mini base de données JSON locale.
- sqlite3 : base de données SQL locale.
- mongodb : base de données NoSQL.
Frameworks
- Crawlee : framework de crawl et de scraping haut niveau d’Apify. La version JavaScript/TypeScript est en v3.16 en mai 2026 et constitue la voie la plus mature (le portage Python est plus récent). Il encapsule Puppeteer, Playwright, Cheerio et JSDOM derrière une seule API, avec rotation des proxys et files d’attente intégrées — utile si vous vous retrouvez à reconstruire sans cesse la même base autour de vos scrapers.
(Vérifiez toujours les dernières documentations et les dépôts GitHub pour les mises à jour.)
Ressources recommandées pour maîtriser le web scraping en JavaScript
Envie d’aller plus loin ? Voici une sélection de ressources pour faire passer vos compétences en scraping au niveau supérieur :
Documentation officielle et guides
- MDN Web Docs : Web Scraping
- Documentation Puppeteer
- Documentation Playwright
- Documentation Crawlee
- Apify Web Scraping Academy
Tutoriels et cours
- freeCodeCamp : The Ultimate Guide to Web Scraping with Node.js
- YouTube : Web Scraping with Node.js (freeCodeCamp)
- DigitalOcean : How To Scrape a Website using Node.js and Puppeteer
Projets open source et exemples
Communauté et forums
Livres et guides complets
- « Web Scraping with Python » d’O’Reilly (pour les concepts transposables entre langages)
- Cours Udemy/Coursera : « Web Scraping in Node.js »
(Pensez toujours à vérifier les dernières éditions et mises à jour.)
Comment extraire n’importe quel site web avec l’IA Get Started Free
Conclusion : choisir la bonne approche pour votre équipe
En résumé : JavaScript et Node.js vous offrent une puissance et une flexibilité incroyables pour le web scraping. Vous pouvez tout construire — des scripts rapides et bricolés aux crawlers robustes et évolutifs. Mais avec un grand pouvoir vient une grande… maintenance. Le scripting traditionnel est idéal pour les projets sur mesure, à forte composante technique, où vous avez besoin d’un contrôle total et êtes prêts à assurer un suivi continu.
Pour tous les autres — utilisateurs métier, analystes, marketeurs, et toute personne qui veut simplement les données — les solutions modernes sans code comme Thunderbit sont une vraie bouffée d’air frais. L’extension Chrome propulsée par l’IA de Thunderbit vous permet d’extraire, structurer et exporter des données en quelques minutes, pas en plusieurs jours. Pas de code, pas de sélecteurs, pas de casse-tête.
Alors, quelle est la bonne approche ? Si votre équipe a de solides ressources d’ingénierie et des besoins uniques, plongez dans la boîte à outils Node.js. Si vous voulez aller vite, rester simple et vous concentrer sur les insights plutôt que sur l’infrastructure, essayez Thunderbit. Dans tous les cas, le web est votre base de données — allez chercher ces données.
Et si vous êtes un jour bloqué, souvenez-vous : même les meilleurs scrapers ont commencé avec une page blanche et une bonne tasse de café. Bon scraping.
Vous voulez en savoir plus sur le scraping propulsé par l’IA ou voir Thunderbit en action ?
- Site officiel de Thunderbit
- Télécharger l’extension Chrome Thunderbit
- Thunderbit Blog
- Comment extraire n’importe quel site web avec l’IA
- Qu’est-ce que le data scraping et comment le faire en 2025
Si vous avez des questions, des anecdotes ou vos pires histoires de scraping, laissez-les en commentaire ou contactez-moi. J’adore voir comment les gens transforment le web en terrain de jeu pour leurs données.
Restez curieux, restez caféiné, et scrapez plus intelligemment — pas plus difficilement.
Télécharger l’extension Chrome Thunderbit
Essayez l’Extracteur Web IA Get Started Free
FAQ :
1. Pourquoi utiliser JavaScript et Node.js pour le web scraping en 2025 ?
Parce que la plupart des sites modernes sont construits avec JavaScript. Node.js est rapide, adapté à l’asynchrone, et dispose d’un riche écosystème (par exemple Axios, Cheerio, Puppeteer) qui prend en charge aussi bien les simples requêtes que l’extraction de contenu dynamique à grande échelle.
2. Quel est le workflow typique pour extraire un site avec Node.js ?
En général, cela ressemble à ceci :
Requête → Gestion de la réponse → (Exécution JS optionnelle) → Analyse du HTML → Extraction des données → Enregistrement ou export
Chaque étape peut être prise en charge par des outils dédiés comme axios, cheerio ou puppeteer.
3. Comment extraire des pages dynamiques rendues en JavaScript ?
Utilisez des navigateurs sans interface comme Puppeteer ou Playwright. Ils chargent la page complète, y compris le JavaScript, ce qui permet d’extraire ce que les utilisateurs voient réellement.
4. Quels sont les plus grands défis du scraping traditionnel ?
- changements dans la structure du site
- détection anti-bot
- coût en ressources du navigateur
- nettoyage manuel des données
- forte maintenance dans le temps
Ces points rendent difficile la pérennité d’un scraping à grande échelle ou peu accessible aux développeurs.
5. Quand dois-je utiliser quelque chose comme Thunderbit plutôt que du code ?
Utilisez Thunderbit si vous avez besoin de rapidité, de simplicité, et que vous ne voulez pas écrire ni maintenir de code. C’est idéal pour les équipes commerciales, marketing ou de recherche qui veulent extraire et structurer rapidement des données — surtout depuis des sites complexes ou multi-pages.




