

Il y a quelque chose d’intemporel à ouvrir un terminal, taper une seule commande et voir les données brutes d’un site web affluer, comme si vous veniez d’ouvrir la Matrice. Pour les développeurs et les utilisateurs techniques avancés, cURL est cette baguette magique : un outil en ligne de commande discret, qui tourne silencieusement sur des milliards d’appareils, des serveurs cloud jusqu’à votre réfrigérateur connecté. Et même en 2026, avec tous les outils no-code et les solutions d’extraction par IA disponibles, l’extraction de données web avec cURL reste une méthode de référence pour celles et ceux qui veulent aller vite, garder la main et automatiser facilement.
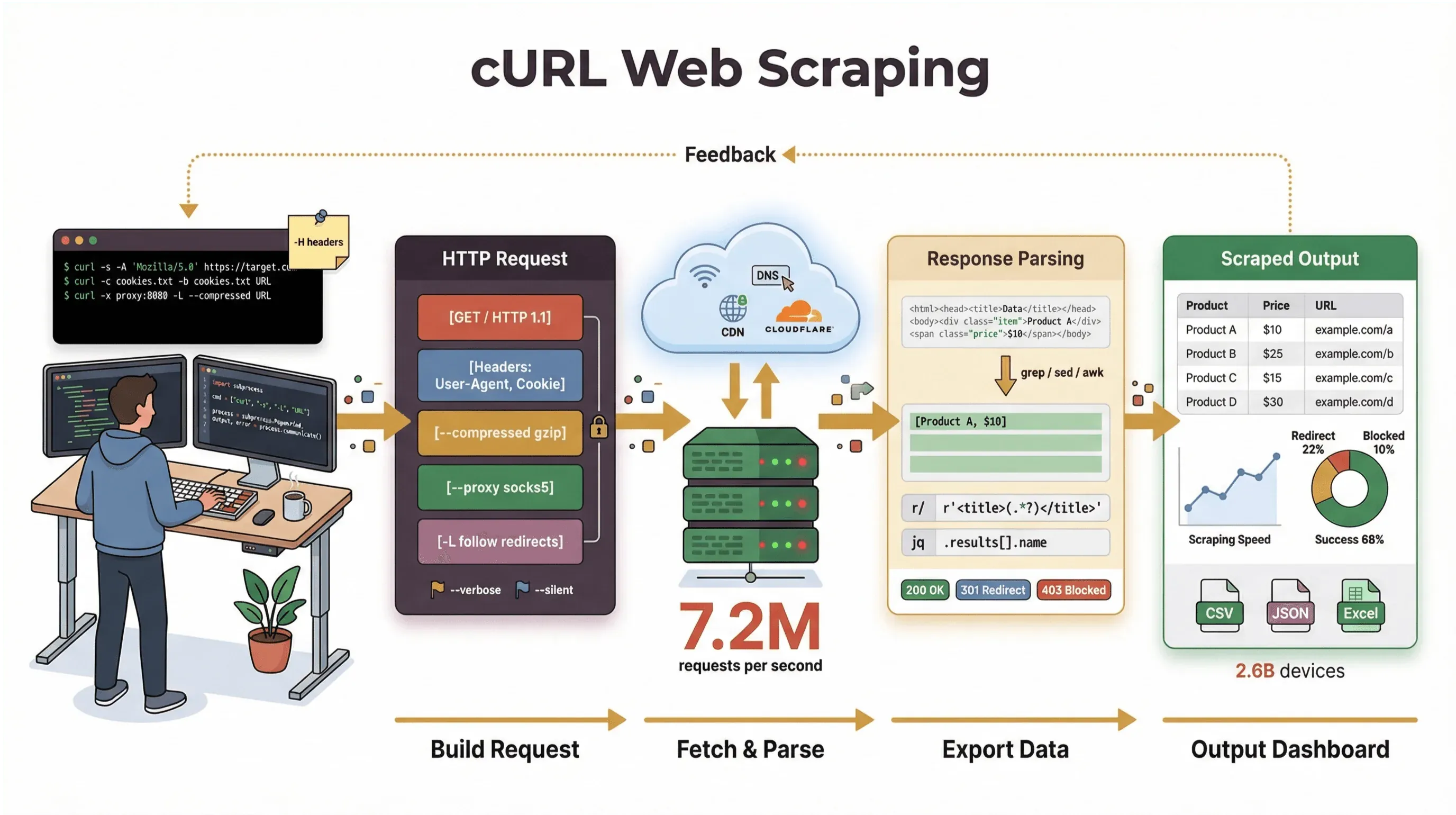 J’ai passé des années à concevoir des outils d’automatisation et à aider des équipes à manipuler des données web, et je reviens encore à cURL quand j’ai besoin de récupérer une page, de déboguer une API ou de prototyper un flux d’extraction. Dans ce guide, je vais vous montrer un tutoriel d’extraction de données web avec cURL qui couvre à la fois les bases et les astuces avancées — avec de vrais exemples de commandes, des conseils pratiques et un regard lucide sur les points forts de cURL… et ses limites. Et si vous êtes plutôt un utilisateur métier qui préfère éviter la ligne de commande, je vous montrerai comment Thunderbit, notre extracteur web propulsé par l’IA, peut vous faire passer de « j’ai besoin de ces données » à « voici mon tableau » en deux clics, sans écrire une ligne de code.
J’ai passé des années à concevoir des outils d’automatisation et à aider des équipes à manipuler des données web, et je reviens encore à cURL quand j’ai besoin de récupérer une page, de déboguer une API ou de prototyper un flux d’extraction. Dans ce guide, je vais vous montrer un tutoriel d’extraction de données web avec cURL qui couvre à la fois les bases et les astuces avancées — avec de vrais exemples de commandes, des conseils pratiques et un regard lucide sur les points forts de cURL… et ses limites. Et si vous êtes plutôt un utilisateur métier qui préfère éviter la ligne de commande, je vous montrerai comment Thunderbit, notre extracteur web propulsé par l’IA, peut vous faire passer de « j’ai besoin de ces données » à « voici mon tableau » en deux clics, sans écrire une ligne de code.
Entrons dans le vif du sujet et voyons pourquoi cURL reste pertinent pour l’extraction web en 2026, comment l’utiliser efficacement et à quel moment il vaut mieux passer à un outil encore plus puissant.
Qu’est-ce que cURL ? La base de l’extraction de données web avec cURL
À la base, cURL est un outil en ligne de commande et une bibliothèque conçus pour transférer des données via des URL. Il existe depuis près de 30 ans (oui, vraiment) et on le retrouve partout : intégré aux systèmes d’exploitation, au cœur de scripts, et gérant discrètement des transferts de données sur plus de vingt milliards d’installations. Si vous avez déjà exécuté une commande rapide pour récupérer une page web, tester une API ou télécharger un fichier, il y a de fortes chances que vous ayez utilisé cURL.
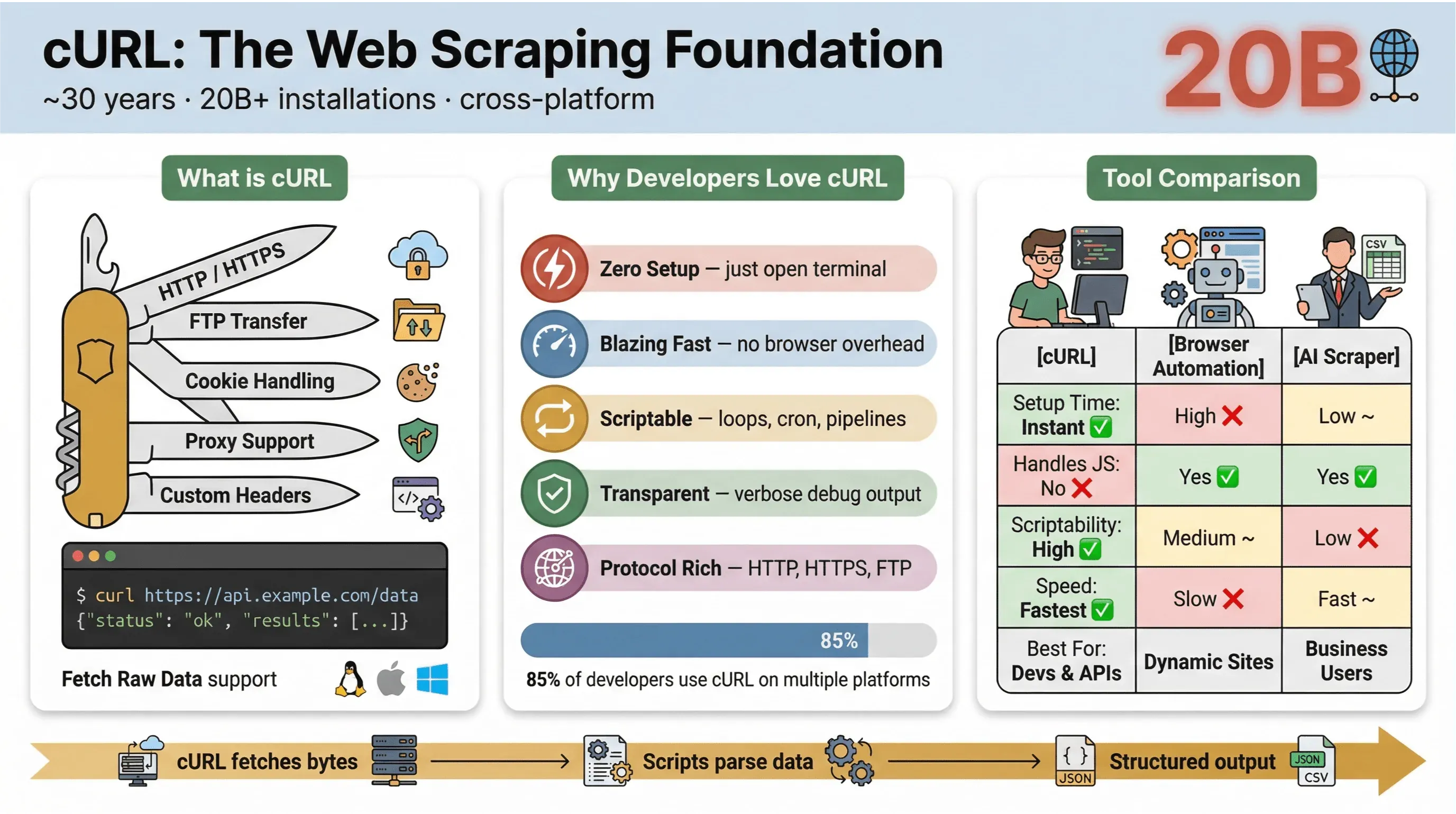 Voici ce qui rend cURL si populaire pour l’extraction web :
Voici ce qui rend cURL si populaire pour l’extraction web :
- Léger et multiplateforme : fonctionne sous Linux, macOS, Windows, et même sur des appareils embarqués.
- Prise en charge des protocoles : gère HTTP, HTTPS, FTP, et bien plus.
- Scriptable : parfait pour l’automatisation, les tâches cron et le code d’assemblage.
- Aucune interaction utilisateur requise : pensé pour un usage non interactif — idéal pour les traitements par lots et les pipelines.
Mais soyons clairs : la mission principale de cURL est de récupérer des données brutes — HTML, JSON, images, tout ce que vous voulez. Il ne parse pas, ne rend pas et ne structure pas ces données pour vous. Voyez cURL comme le « premier kilomètre » de l’extraction web : il vous apporte les octets, mais il vous faudra d’autres outils (comme des scripts Python, grep/sed/awk, ou un extracteur web IA) pour transformer tout cela en informations structurées.
Si vous voulez consulter la documentation officielle, jetez un œil au guide de scripting HTTP de cURL.
Pourquoi utiliser cURL pour l’extraction web ? (tutoriel d’extraction de données web avec cURL)
Alors, pourquoi les développeurs et les utilisateurs techniques reviennent-ils sans cesse à cURL pour l’extraction web, malgré tous les nouveaux outils disponibles ? Voici ce qui fait la différence :
- Installation minimale : pas d’installation, pas de dépendances — ouvrez simplement votre terminal et lancez-vous.
- Rapidité : récupérez les données instantanément, sans attendre le chargement d’un navigateur.
- Scriptabilité : parcourez facilement des listes d’URL, automatisez des requêtes et enchaînez des commandes.
- Prise en charge des protocoles et des fonctionnalités : gérez les cookies, les proxies, les redirections, les en-têtes personnalisés, et plus encore.
- Transparence : voyez exactement ce qui se passe grâce aux sorties verbeuses et de débogage.
Dans l’enquête 2025 auprès des utilisateurs de cURL, 85,7 % des répondants ont déclaré utiliser l’outil en ligne de commande cURL, et 96,2 % ont indiqué l’utiliser sous Linux — toujours de loin la plateforme la plus utilisée pour cURL.
--- cURL reste l’outil suisse des requêtes HTTP, des récupérations rapides de données et du dépannage.
Voici une comparaison rapide entre cURL et d’autres méthodes d’extraction :
| Fonctionnalité | cURL | Automatisation de navigateur (par ex. Selenium) | Extracteur Web IA (par ex. Thunderbit) |
|---|---|---|---|
| Temps de configuration | Instantané | Élevé | Faible |
| Scriptabilité | Élevée | Moyenne | Faible (sans code nécessaire) |
| Gère JavaScript | Non | Oui | Oui (Thunderbit : via le navigateur) |
| Prise en charge des cookies/sessions | Manuelle | Automatique | Automatique |
| Structuration des données | Manuelle (analyse ensuite) | Manuelle (analyse ensuite) | Basée sur l’IA / des modèles |
| Idéal pour | Développeurs, récupérations rapides | Sites complexes et dynamiques | Utilisateurs métier, export structuré |
En bref : cURL est imbattable pour des récupérations de données rapides et scriptables — surtout pour les pages statiques, les API ou les workflows simples à automatiser. Mais dès qu’il faut parser du HTML complexe, gérer JavaScript ou exporter des données structurées, vous aurez besoin d’un outil plus spécialisé.
Bien démarrer : exemples de commandes cURL pour l’extraction web de base
Passons à la pratique. Voici comment utiliser cURL pour des tâches d’extraction web de base, étape par étape.
Récupérer du HTML brut avec cURL
Le cas le plus simple : récupérer le HTML d’une page web.
curl https://books.toscrape.com/
Cette commande récupère la page d’accueil de Books to Scrape, un site de démonstration public pour l’extraction web. Vous verrez le HTML brut dans votre terminal — cherchez des balises comme <title> ou des extraits comme « In stock ».
Enregistrer la sortie dans un fichier
Vous voulez conserver ce HTML pour l’analyser plus tard ? Utilisez l’option -o :
curl -o page.html https://books.toscrape.com/
Vous obtiendrez maintenant un fichier page.html contenant l’intégralité du HTML. C’est parfait pour faire des analyses supplémentaires ou le parser avec d’autres outils.
Envoyer des requêtes POST avec cURL
Vous devez soumettre un formulaire ou interagir avec une API ? Utilisez l’option -d pour les requêtes POST. Voici un exemple avec httpbin, un site conçu pour tester HTTP :
curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"
Vous obtiendrez une réponse JSON qui renvoie vos données envoyées — idéal pour les tests et le prototypage.
Inspecter les en-têtes et déboguer
Parfois, vous voulez voir les en-têtes de réponse ou déboguer la requête :
-
En-têtes seuls (requête HEAD) :
curl -I https://books.toscrape.com/ -
Inclure les en-têtes avec le corps :
curl -i https://httpbin.org/get -
Sortie verbeuse/de débogage :
curl -v https://books.toscrape.com/
Ces options vous aident à comprendre ce qui se passe sous le capot — essentiel pour le dépannage.
Voici un tableau de référence rapide pour ces commandes :
| Tâche | Exemple de commande | Remarques |
|---|---|---|
| Récupérer le HTML | curl URL | Affiche le HTML dans le terminal |
| Enregistrer dans un fichier | curl -o fichier.html URL | Écrit la sortie dans un fichier |
| Inspecter les en-têtes | curl -I URL ou curl -i URL | -I pour les en-têtes seuls, -i inclut les en-têtes avec le corps |
| Envoyer des données de formulaire POST | curl -d "a=1&b=2" URL | Envoie des données encodées en formulaire |
| Déboguer la requête/réponse | curl -v URL | Affiche des informations détaillées sur la requête et la réponse |
Pour plus d’exemples, consultez la documentation officielle de scripting de cURL.
Passer à la vitesse supérieure : extraction web avancée avec cURL (extraction de données web avec cURL)
Une fois les bases maîtrisées, cURL ouvre la porte à des fonctionnalités avancées pour des tâches d’extraction plus complexes.
Gérer les cookies et les sessions
De nombreux sites exigent des cookies pour conserver les sessions de connexion ou suivre les utilisateurs. Avec cURL, vous pouvez stocker et réutiliser les cookies entre plusieurs requêtes :
# Stocker les cookies après la connexion
curl -c cookies.txt https://example.com/login
# Utiliser les cookies pour les requêtes suivantes
curl -b cookies.txt https://example.com/account
Cela vous permet d’imiter des sessions de navigateur et d’accéder à des pages protégées par authentification (tant qu’il n’y a pas de challenge JavaScript).
Simuler le User-Agent et des en-têtes personnalisés
Certains sites affichent un contenu différent selon votre User-Agent ou vos en-têtes. Par défaut, cURL s’identifie comme « curl/VERSION », ce qui peut déclencher des blocages ou un contenu alternatif. Pour imiter un navigateur :
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/
Vous pouvez aussi définir des en-têtes personnalisés, comme la langue préférée :
curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/
Cela vous aide à obtenir le même contenu qu’un vrai navigateur.
Utiliser des proxies pour l’extraction web
Besoin de faire passer vos requêtes par un proxy (pour des tests géographiques ou éviter des bannissements d’IP) ? Utilisez l’option -x :
curl -x http://proxy.example.org:4321 https://remote.example.org/
Veillez simplement à utiliser les proxies de manière responsable et dans le respect des conditions d’utilisation du site.
Automatiser l’extraction de pages multiples
Vous voulez extraire plusieurs pages — par exemple des listes de produits paginées ? Utilisez une simple boucle shell :
for p in $(seq 2 5); do
curl -s -o "books-page-${p}.html" \
"https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
sleep 1
done
Cela récupère les pages 2 à 5 du catalogue Books to Scrape et enregistre chaque page dans un fichier séparé. (La page 1 correspond à la page d’accueil.)
Limites de l’extraction de données web avec cURL : ce qu’il faut savoir
Aussi beaucoup que j’aime cURL, ce n’est pas une solution miracle. Voici ses limites :
- Aucune exécution de JavaScript : cURL ne peut pas gérer les pages qui nécessitent JavaScript pour rendre le contenu ou résoudre des protections anti-bot (developers.cloudflare.com).
- Analyse manuelle requise : vous obtenez du HTML ou du JSON brut, mais vous devrez l’analyser vous-même — souvent avec des scripts ou outils supplémentaires.
- Gestion de session limitée : gérer des connexions complexes, des jetons ou des formulaires en plusieurs étapes peut vite devenir compliqué.
- Aucune structuration des données intégrée : cURL ne transforme pas les pages web en lignes, tableaux ou feuilles de calcul.
- Vulnérable à la détection anti-bot : de nombreux sites utilisent désormais des défenses avancées (JavaScript, fingerprinting, CAPTCHA) que cURL ne peut tout simplement pas contourner (datadome.co).
Voici un tableau comparatif rapide :
| Limitation | cURL seul | Outils d’extraction modernes (par ex. Thunderbit) |
|---|---|---|
| Prise en charge de JavaScript | Non | Oui |
| Structuration des données | Manuelle | Automatique (IA / modèle) |
| Gestion des sessions | Manuelle | Automatique |
| Contournement anti-bot | Limité | Avancé (basé sur le navigateur / IA) |
| Facilité d’utilisation | Technique | Sans compétences techniques |
Pour les pages statiques et les API, cURL est excellent. Pour tout ce qui est plus dynamique ou protégé, il faudra passer à l’outil supérieur.
Thunderbit vs cURL : la meilleure approche d’extraction web pour les utilisateurs non techniques
Parlons maintenant de Thunderbit, notre extension Chrome d’extracteur web propulsée par l’IA. Si vous êtes commercial, marketeur ou responsable des opérations et que vous voulez simplement transférer des données d’un site vers Excel, Google Sheets ou Notion — sans toucher à la ligne de commande — Thunderbit est fait pour vous.
Voici comment Thunderbit se compare à cURL :
| Fonctionnalité | cURL | Thunderbit |
|---|---|---|
| Interface utilisateur | Ligne de commande | Clics sur l’interface (extension Chrome) |
| Suggestion de champs par l’IA | Non | Oui (l’IA lit la page et suggère des colonnes) |
| Gère la pagination / sous-pages | Script manuel | Automatique (l’IA détecte et extrait) |
| Export des données | Manuel (parser + enregistrer) | Direct vers Excel, Google Sheets, Notion, Airtable |
| Pages JavaScript / protégées | Non | Oui (extraction via navigateur) |
| Sans code requis | Non (nécessite du script) | Oui (tout le monde peut l’utiliser) |
| Offre gratuite | Toujours gratuite | Gratuite jusqu’à 6 pages (10 avec le boost d’essai) |
Avec Thunderbit, il suffit d’ouvrir l’extension, de cliquer sur « AI Suggest Fields », et de laisser l’IA déterminer quelles données extraire. Vous pouvez extraire des tableaux, des listes, des fiches produit et même visiter automatiquement des sous-pages. Ensuite, exportez vos données directement vers vos outils métier préférés — sans parsing, sans prise de tête.
Thunderbit est utilisé par plus de 100 000 utilisateurs dans le monde, et il est particulièrement apprécié des équipes commerciales, e-commerce et immobilières qui ont besoin rapidement de données structurées.
Essayez l’extension Chrome Thunderbit pour l’extraction web
Vous voulez l’essayer ? Téléchargez l’extension Chrome ici.
Combiner cURL et Thunderbit : stratégies flexibles d’extraction web
Si vous êtes un utilisateur technique, nul besoin de choisir un seul outil. En réalité, de nombreuses équipes utilisent cURL et Thunderbit ensemble pour bénéficier d’une flexibilité maximale :
- Prototyper avec cURL : utilisez cURL pour tester rapidement des endpoints, inspecter les en-têtes et comprendre comment un site réagit.
- Passer à l’échelle avec Thunderbit : lorsque vous avez besoin de données structurées, d’une extraction multi-pages ou d’un workflow reproductible, basculez vers Thunderbit pour une extraction en clics et des exports directs.
Voici un exemple de workflow pour de l’étude de marché :
- Utilisez cURL pour récupérer quelques pages et inspecter la structure HTML.
- Identifiez les champs de données que vous voulez (par ex. noms de produits, prix, avis).
- Ouvrez Thunderbit, cliquez sur « AI Suggest Fields », et laissez l’IA configurer l’extracteur.
- Extrayez toutes les pages (y compris les sous-pages ou les listes paginées) et exportez vers Google Sheets.
- Analysez, partagez et exploitez vos données — sans parsing manuel.
Voici un tableau de décision rapide :
| Scénario | Utiliser cURL | Utiliser Thunderbit | Utiliser les deux |
|---|---|---|---|
| Récupération rapide d’une API ou d’une page statique | ✅ | ||
| Besoin de données structurées dans un tableur | ✅ | ||
| Débogage des en-têtes/cookies | ✅ | ||
| Extraction de pages dynamiques / lourdes en JS | ✅ | ||
| Création d’un workflow reproductible sans code | ✅ | ||
| Prototyper puis passer à l’échelle | ✅ | ✅ | Workflow hybride |
Défis et pièges courants de l’extraction web avec cURL
Avant de vous lancer à fond avec cURL, parlons des défis concrets que vous rencontrerez :
- Systèmes anti-bot : de nombreux sites utilisent désormais des défenses avancées (challenges JavaScript, CAPTCHA, fingerprinting) que cURL ne peut pas contourner (developers.cloudflare.com).
- Problèmes de qualité des données : des changements dans le HTML, des champs manquants ou des mises en page incohérentes peuvent casser vos scripts.
- Coût de maintenance : chaque fois qu’un site change, vous devrez mettre à jour votre logique d’analyse.
- Risques juridiques et de conformité : vérifiez toujours les conditions d’utilisation du site, le fichier robots.txt et les lois applicables avant d’extraire des données. Ce n’est pas parce qu’une donnée est publique qu’elle est librement réutilisable (calawyers.org, polsinelli.com).
- Limites d’échelle : cURL est excellent pour les petites tâches, mais pour une extraction à grande échelle, il faudra gérer des proxies, des limites de débit et la gestion des erreurs.
Conseils pour le dépannage et la conformité :
- Commencez toujours par des sites autorisés ou de démonstration (comme Books to Scrape).
- Respectez les limites de débit — n’inondez pas les endpoints de requêtes.
- Évitez d’extraire des données personnelles sans base légale.
- Si vous tombez sur des murs JavaScript ou CAPTCHA, envisagez de passer à un outil basé sur le navigateur comme Thunderbit.
Résumé étape par étape : comment extraire des sites web avec cURL
Voici votre checklist de référence rapide pour l’extraction de données web avec cURL :
- Identifiez l’URL ou les URL cibles : commencez par une page statique ou un endpoint d’API.
- Récupérez la page :
curl URL - Enregistrez la sortie dans un fichier :
curl -o fichier.html URL - Inspectez les en-têtes / déboguez :
curl -I URL,curl -v URL - Envoyez des données POST :
curl -d "a=1&b=2" URL - Gérez les cookies / sessions :
curl -c cookies.txt ...,curl -b cookies.txt ... - Définissez des en-têtes personnalisés / un User-Agent :
curl -A "..." -H "..." URL - Suivez les redirections :
curl -L URL - Utilisez des proxies (si nécessaire) :
curl -x proxy:port URL - Automatisez l’extraction multi-pages : utilisez des boucles shell ou des scripts.
- Analysez et structurez les données : utilisez des outils ou scripts supplémentaires si nécessaire.
- Passez à Thunderbit pour une extraction structurée, sans code, ou pour des pages dynamiques.
Conclusion et points clés : choisir le bon outil d’extraction web
Extraire des données depuis n’importe quel site grâce à l’IA Get Started Free
L’extraction de données web avec cURL reste une compétence puissante pour les utilisateurs techniques en 2026 — surtout pour les récupérations rapides de données, le prototypage et l’automatisation. La rapidité, la scriptabilité et l’ubiquité de cURL en font un incontournable de la boîte à outils de tout développeur. Mais à mesure que le web devient plus dynamique et mieux protégé, et que les utilisateurs métier exigent des données structurées sans code, des outils comme Thunderbit redéfinissent ce qui est possible.
Points clés :
- Utilisez cURL pour les pages statiques, les API et le prototypage rapide — surtout lorsque vous voulez un contrôle total.
- Passez à Thunderbit (ou à un extracteur web IA similaire) quand vous avez besoin de données structurées, de pages dynamiques / lourdes en JavaScript, ou d’un workflow no-code adapté aux besoins métier.
- Combinez les deux pour une flexibilité maximale : prototypez avec cURL, puis structurez et passez à l’échelle avec Thunderbit.
- Extrayez toujours les données de manière responsable — respectez les conditions du site, les limites de débit et les cadres juridiques.
Curieux de voir à quel point l’extraction web peut être simple ? Essayez l’extension Chrome gratuite de Thunderbit et découvrez l’extraction de données assistée par l’IA par vous-même. Et si vous voulez aller plus loin, consultez le blog Thunderbit pour d’autres tutoriels, conseils et analyses sectorielles. Vous aimerez peut-être aussi :
- Comment extraire n’importe quel site web avec l’IA
- Comment extraire des données de sites web vers Excel avec l’IA
- Qu’est-ce que l’extraction de données et comment la faire en 2025
Bonne extraction — et que vos données soient toujours propres, structurées et à portée d’une commande (ou d’un clic).
Découvrez les forfaits Thunderbit pour une extraction web à grande échelle
FAQ
1. cURL peut-il gérer des pages web rendues par JavaScript ?
Non, cURL ne peut pas exécuter JavaScript. Il récupère le HTML brut tel qu’il est fourni par le serveur. Si une page nécessite JavaScript pour afficher le contenu ou résoudre des protections anti-bot, cURL ne pourra pas accéder aux données. Dans ces cas-là, utilisez des outils basés sur le navigateur comme Thunderbit.
2. Comment enregistrer directement la sortie de cURL dans un fichier ?
Utilisez l’option -o : curl -o nomdefichier.html URL. Cela écrit le corps de la réponse dans un fichier au lieu de l’afficher dans votre terminal.
3. Quelle est la différence entre cURL et Thunderbit pour l’extraction web ?
cURL est un outil en ligne de commande pour récupérer des données web brutes — idéal pour les utilisateurs techniques et l’automatisation. Thunderbit est une extension Chrome propulsée par l’IA, conçue pour les utilisateurs métier qui veulent extraire des données structurées de n’importe quel site, gérer des pages dynamiques et exporter directement vers des outils comme Excel ou Google Sheets — sans code.
4. Est-il légal d’extraire des sites web avec cURL ?
L’extraction de données publiques est généralement légale aux États-Unis à la lumière de récentes décisions de justice, mais vous devez toujours vérifier les conditions d’utilisation du site, le fichier robots.txt et les lois applicables. Évitez d’extraire des données personnelles ou protégées sans autorisation, et respectez les limites de débit ainsi que les règles éthiques (calawyers.org, polsinelli.com).
5. Quand dois-je passer de cURL à un outil plus avancé comme Thunderbit ?
Si vous devez extraire des pages dynamiques / lourdes en JavaScript, si vous voulez des données structurées dans un tableur ou si vous préférez un workflow sans code, Thunderbit est le meilleur choix. Utilisez cURL pour les tâches rapides et techniques ; utilisez Thunderbit pour une extraction de données reproductible et adaptée aux usages métier.
Pour plus de conseils et de tutoriels sur l’extraction web, visitez le blog Thunderbit ou consultez notre chaîne YouTube.
Essayez Thunderbit AI Web Scraper Get Started Free




