
Soyons honnêtes : si vous avez déjà essayé de mettre la main sur des données d’entreprise, vous êtes sans doute tombé sur le débat « web scraping vs data mining ». J’ai vu des équipes tourner en rond : d’un côté, certains veulent récupérer chaque parcelle d’information sur le web ; de l’autre, certains veulent l’analyser pour en tirer des insights profonds. Et parfois, tout le monde finit par fixer un tableur en se demandant : « Attendez, on fait quoi exactement, là ? » Si cela vous parle, vous n’êtes pas seul.
Après des années à construire des outils SaaS et d’automatisation — et aujourd’hui en tant que cofondateur de — j’ai vu cette confusion revenir partout, des équipes commerciales aux salles de réunion. Alors, mettons de l’ordre dans le jargon et allons droit au but : quelle est la vraie différence entre web scraping et data mining, qui utilise quoi, et surtout, comment les faire travailler ensemble pour générer des résultats pour votre équipe ?
Web scraping vs data mining : définitions rapides pour les équipes pressées
Commençons simplement, sans sortir le dictionnaire technique.
- Web scraping : il s’agit de collecter des données depuis des sites web — en quelque sorte, une version automatisée du copier-coller d’informations du web vers un tableur. Les outils de web scraping parcourent les pages web, extraient des informations précises (comme les prix des produits, les noms d’entreprises ou des articles), puis les organisent dans un format structuré (lignes et colonnes). À ce stade, aucune analyse n’est effectuée : l’objectif est simplement d’obtenir les données brutes dont vous avez besoin.
- Data mining : c’est là que la magie opère… enfin, pas de la magie, mais de la vraie valeur. Une fois vos données en main, le data mining consiste à analyser des ensembles de données — à l’aide de statistiques, d’algorithmes ou d’IA — pour découvrir des tendances, des schémas et des insights. C’est un peu comme prendre ce gigantesque tableur et comprendre ce qu’il raconte : segmenter les clients, prévoir les ventes ou détecter la fraude.
L’analogie que j’utilise toujours :
Le web scraping, c’est aller chercher les ingrédients au magasin ; le data mining, c’est les transformer en repas. Il vous faut les deux si vous voulez que le dîner soit plus qu’un simple tas de courses.
Qui utilise le web scraping vs le data mining — et pourquoi ?
C’est là que les choses deviennent intéressantes. La différence ne se limite pas à « collecter vs analyser » : elle concerne surtout qui fait quoi, et dans quel but.
Qui utilise le web scraping ?
Utilisateurs types :
- Équipes commerciales (constitution de listes de leads, collecte d’informations de contact)
- Équipes marketing (veille concurrentielle, intelligence marché)
- Opérations (suivi des prix, insights sur la chaîne d’approvisionnement)
- Équipes de recherche (immobilier, finance, etc.)
Leur objectif :
Obtenir rapidement des données fraîches et externes. Qu’il s’agisse d’extraire des milliers de prix produits, de scraper LinkedIn pour trouver des leads, ou de surveiller les lancements des concurrents, ces équipes ont besoin d’informations à jour pour alimenter leurs décisions quotidiennes (, ).
Qui utilise le data mining ?
Utilisateurs types :
- Analystes de données et équipes business intelligence (BI)
- Data scientists
- Product managers et équipes stratégie
Leur objectif :
Trouver du sens dans les données. Ces équipes prennent les informations brutes — qu’elles viennent du web scraping ou de systèmes internes — et cherchent des schémas, des tendances et des insights exploitables. Elles s’intéressent moins à la façon dont les données ont été collectées qu’à ce qu’elles peuvent révéler ().
Tableau de scénarios : qui fait quoi ?
| Rôle | Exemple de web scraping | Exemple de data mining |
|---|---|---|
| Ventes | Scraper des annuaires d’entreprises pour générer des leads | Analyser quels leads convertissent le mieux |
| Marketing | Scraper les lancements de produits des concurrents | Segmenter les clients selon leur comportement d’achat |
| Opérations | Scraper les prix des fournisseurs chaque jour | Prévoir la demande et optimiser les stocks |
| BI / Data Science | (En général, ils ne scrappent pas eux-mêmes) | Construire des modèles prédictifs, repérer des tendances |
| Product Management | Scraper les avis de l’App Store pour obtenir des retours | Identifier les manques fonctionnels, prioriser la roadmap |
Web scraping : transformer les sites web en données prêtes pour l’entreprise
Soyons francs : internet est une mine d’or de données business, mais la plupart sont enfermées dans des pages web désordonnées et non structurées. Le web scraping est la clé qui vous permet de déverrouiller ces données et d’en faire quelque chose d’exploitable par votre équipe.
Pourquoi le web scraping est important, surtout pour les équipes non techniques
- Gain de temps : fini les stagiaires qui copient-collent pendant des jours. Un scraper peut extraire des milliers de données en quelques minutes.
- Passage à l’échelle : vous voulez surveiller 50 sites concurrents chaque jour ? Le scraping le rend possible.
- Données à jour : obtenez des mises à jour en temps réel sur les prix, les stocks ou les actualités, sans effort manuel.
À l’échelle du marché, estime le marché du web scraping à 1,17 Md USD en 2026, pour atteindre 2,23 Md USD en 2031. Et selon une enquête BrowserCat de 2024 citée dans ce rapport, 65 % des entreprises utilisaient déjà le web scraping pour alimenter des projets d’IA et de machine learning — c’est précisément cette partie du workflow qui fait sortir l’adoption du périmètre IT pour l’amener aux équipes commerciales, marketing et opérations.
Cas d’usage pratiques
- Génération de leads : scraper des annuaires publics ou des réseaux sociaux pour récupérer noms, emails et numéros de téléphone.
- Surveillance des prix : suivre en temps réel les prix ou la disponibilité des produits chez les concurrents. L’adoption est désormais largement répandue — indique que 81 % des distributeurs américains utilisent désormais un scraping automatisé des prix pour ajuster dynamiquement leurs tarifs, contre 34 % en 2020 (selon une étude initiale d’Actowiz Solutions).
- Études de marché : agréger des avis en ligne, scraper les réseaux sociaux pour en extraire le ressenti, ou surveiller les sites d’actualité pour repérer les tendances.
- Enrichissement des données : compléter votre CRM avec des informations fraîches issues des sites d’entreprise ou de LinkedIn.
- Immobilier et finance : scraper des annonces immobilières, des actualités financières ou des données alternatives pour la recherche d’investissement ().
Et voici le plus intéressant : vous n’avez plus besoin d’être développeur. Une part croissante des nouveaux outils de scraping — Octoparse, Browse AI, Bardeen, Thunderbit — propose par défaut une configuration en glisser-déposer ou en point-and-click, et non comme une option réservée au mode développeur. À elle seule, cette évolution a fait sortir le scraping du backlog d’ingénierie pour le mettre sur les bureaux des équipes commerciales et opérations.
Comment Thunderbit simplifie le web scraping pour tout le monde
Je l’admets : quand nous avons commencé à construire , notre objectif était simple : rendre le web scraping aussi facile que demander à un stagiaire de copier-coller des données — sauf que le « stagiaire » est un agent IA qui ne dort jamais, ne se plaint jamais et ne se laisse jamais distraire par des vidéos de chats.
Voici comment Thunderbit fait le pont entre la collecte de données et l’analyse métier :
- Suggérer les champs IA : cliquez simplement sur « Suggérer les champs IA » et l’IA de Thunderbit analyse la page, recommande les champs de données à extraire et propose des noms de colonnes. Plus besoin de bricoler du HTML ou des sélecteurs : choisissez seulement ce dont vous avez besoin ().
- Scraping des sous-pages : besoin de plus de détails depuis des sous-pages (comme les fiches produit ou les descriptions de poste) ? Thunderbit peut cliquer automatiquement, récupérer les informations supplémentaires et les ajouter à votre ensemble de données.
- Export instantané des données : export en un clic vers Excel, Google Sheets, Airtable, Notion ou CSV/JSON. Aucun frais caché, aucune complication : vos données sont prêtes à l’emploi immédiatement.
- Sans code, en point-and-click : Thunderbit fonctionne dans votre navigateur. Sélectionnez ce que vous voulez, et c’est terminé. Même si vous n’avez jamais fait de scraping, vous serez opérationnel en quelques minutes.
- Résilience alimentée par l’IA : les sites web changent sans cesse, mais l’IA de Thunderbit s’adapte automatiquement à de nombreux ajustements de mise en page. Moins de maintenance, moins de frustration.
- Scraping programmé et AI Autofill : planifiez des extractions récurrentes, ou laissez l’IA remplir les formulaires et les connexions à votre place. Thunderbit gère même les PDF, les images, les emails et les numéros de téléphone en un seul clic.
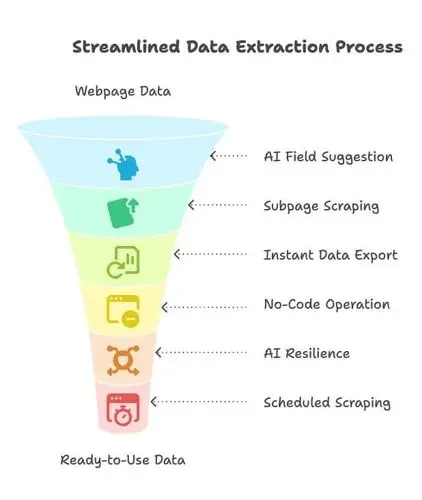
En bref ? Thunderbit réduit l’écart de compétences. Désormais, les équipes Sales Ops, marketing, voire votre CEO, peuvent mettre en place une extraction sans appeler l’IT. C’est la couche intermédiaire qui relie les données web désordonnées aux outils que vous utilisez réellement pour analyser.
Vous voulez le voir en action ? Découvrez notre ou explorez d’autres cas d’usage sur le .
Data mining : découvrir des insights à partir de vos données collectées
D’accord, vous avez extrait une montagne de données. Et maintenant ? C’est là que le data mining entre en scène.
Qu’est-ce que le data mining ?
Le data mining est le processus d’analyse de grands ensembles de données pour y trouver des schémas cachés, des corrélations ou des anomalies susceptibles d’éclairer une décision business. Il s’agit de transformer des chiffres bruts en connaissances exploitables — par exemple, découvrir que les clients qui achètent le produit A ont aussi tendance à acheter le produit B, ou que certains comportements signalent un fort risque de churn.
Objectifs business courants
- Découverte de tendances et prévisions : repérer les tendances de vente, la saisonnalité ou les évolutions du marché — et prédire la suite.
- Segmentation client : regrouper les clients par comportement ou données démographiques pour des campagnes ciblées.
- Détection d’anomalies : identifier des valeurs aberrantes qui peuvent signaler une fraude, un risque ou de nouvelles opportunités.
- Vision stratégique : combiner plusieurs ensembles de données (internes + extraits du web) pour guider des décisions importantes — comme entrer sur un nouveau marché ou ajuster les prix.
Voici le piège : le data mining ne vaut que ce que valent les données qu’on lui fournit. Le vieil adage « garbage in, garbage out » est tristement vrai. En fait, les analystes passent souvent jusqu’à à nettoyer et préparer les données avant même de pouvoir les analyser.
C’est pourquoi un web scraping structuré — comme celui produit par Thunderbit — est si précieux : il vous fournit un jeu de données propre, prêt à analyser, afin que vos analystes puissent passer directement à l’essentiel.
Web scraping vs data mining : comparaison côte à côte
Mettons les deux face à face pour voir clairement ce qui les distingue — et ce qu’ils ont en commun.
| Aspect | Web scraping | Data mining |
|---|---|---|
| Objectif principal | Collecter des données brutes depuis des sites web (extraction de données) | Analyser des ensembles de données pour découvrir des schémas et des insights (analyse de données) |
| Utilisateurs types | Ventes, marketing, opérations, recherche (souvent non techniques, experts métier) | Analystes de données, équipes BI, data scientists, responsables stratégie (rôles analytiques / techniques) |
| Sources de données | Pages web, sources en ligne, annuaires publics, API | Ensembles de données structurés : données extraites, bases internes, CSV, entrepôts de données |
| Processus et outils | Exploration, extraction (outils sans code comme Thunderbit, extensions de navigateur) | Analyse de données (outils BI, Python/R, SQL, plateformes de machine learning) |
| Résultat | Jeu de données structuré (CSV, tableur, table de base de données) | Insights, rapports, tableaux de bord, modèles prédictifs |
| Exemples d’usage | Compiler les prix des concurrents, scraper des mentions sociales, récupérer des annonces | Segmenter les clients, prédire le churn, scorer les leads |
| Principaux défis | Changements de sites, défenses anti-scraping, qualité des données, enjeux juridiques / éthiques | Données sales / incomplètes, choix du bon modèle, confidentialité, interprétation des résultats |
À retenir :
Le web scraping est le « carburant » (les données), le data mining est le « moteur » (les insights). Vous avez besoin des deux pour aller quelque part.
Comment le web scraping et le data mining travaillent ensemble en entreprise
C’est ici que la vraie magie opère : le web scraping et le data mining ne sont pas des concurrents, ce sont des coéquipiers. Pensez-les comme l’amont et l’aval de votre workflow de données.
Scénario 1 : intelligence marché
- Étape 1 : scraper les fiches produits, les prix et les avis des concurrents sur plusieurs sites.
- Étape 2 : exploiter les données pour repérer des tendances — identifier des manques sur le marché, les plaintes récurrentes des clients ou l’évolution des prix dans le temps.
- Résultat : vous obtenez des insights actionnables pour orienter la stratégie produit ou la tarification.
Scénario 2 : scoring des leads commerciaux
- Étape 1 : scraper LinkedIn ou des annuaires d’entreprises pour enrichir votre base de leads avec la taille de l’entreprise, le secteur et les actualités récentes.
- Étape 2 : analyser quels attributs sont corrélés à de forts taux de conversion, puis prioriser les leads en conséquence.
- Résultat : votre équipe commerciale se concentre sur les prospects les plus pertinents, pas seulement sur la plus grosse liste.
Scénario 3 : optimisation des prix
- Étape 1 : scraper en temps réel les prix et les stocks des concurrents.
- Étape 2 : injecter ces données dans vos algorithmes de tarification pour ajuster vos propres prix de manière dynamique.
- Résultat : vous restez compétitif tout en maximisant votre chiffre d’affaires.
Le risque de les traiter comme des activités isolées ?
Si vous ne faites que scraper sans jamais analyser, vous vous noyez dans les données tout en manquant d’insights. Si vous n’analysez que les données internes, vous perdez le contexte plus large du marché. Les meilleures équipes utilisent les deux : le scraping pour constituer un jeu de données complet, le data mining pour en extraire des insights pertinents ().
Surmonter les défis courants du web scraping et du data mining
Soyons réalistes : le web scraping comme le data mining ont leur lot de problèmes. Voici comment gérer les principaux — et comment Thunderbit aide :
1. Qualité et nettoyage des données
- Problème : les données extraites peuvent être désordonnées — champs manquants, formats incohérents, doublons.
- Solution : utilisez des outils qui permettent le nettoyage pendant l’extraction. Thunderbit peut formater et catégoriser les données à la volée grâce à l’IA, afin que votre sortie soit déjà prête pour l’analyse (). Vérifiez toujours vos données avant de vous lancer dans l’analyse.
2. Changements de sites web et mesures anti-scraping
- Problème : les sites changent de mise en page, ajoutent des CAPTCHA ou bloquent les bots.
- Solution : utilisez des scrapers pilotés par l’IA comme Thunderbit, qui s’adaptent automatiquement aux changements de mise en page. Respectez
robots.txt, évitez de surcharger les sites et envisagez l’usage de proxys si nécessaire ().
3. Questions juridiques et éthiques
- Problème : le scraping de données publiques est généralement légal, mais les lois sur la vie privée et les conditions d’utilisation comptent.
- Solution : consultez toujours les conditions du site, concentrez-vous sur les données publiques, anonymisez lorsque c’est possible et respectez le RGPD / CCPA. Soyez un « citoyen éthique des données » — votre réputation vaut plus que n’importe quel jeu de données ().
4. Des données aux insights actionnables
- Problème : les équipes collectent des données mais peinent à les transformer en décisions.
- Solution : partez de questions business claires, utilisez la visualisation et faites intervenir des experts métier pour interpréter les résultats. Intégrez les insights dans les workflows (par exemple, signaler les clients à risque dans votre CRM).
5. Outils et manque de compétences
- Problème : toutes les équipes n’ont pas de développeurs ni de data scientists.
- Solution : tirez parti d’outils no-code et faciles à prendre en main comme Thunderbit pour le scraping, et de plateformes BI modernes pour le mining. Investissez dans une formation de base à la culture data — parfois, un simple tableau croisé dynamique suffit.
Choisir la bonne approche : web scraping, data mining, ou les deux ?
Alors, comment savoir de quoi vous avez besoin ? Voici un guide de décision rapide :
- Avez-vous déjà les données dont vous avez besoin ?
- Non : commencez par le web scraping pour les collecter.
- Oui : passez au data mining pour en extraire des insights.
- Vos questions portent-elles sur le monde externe ou sur des schémas internes ?
- Externe (concurrents, marché, leads) : web scraping.
- Interne (comportement client, tendances commerciales) : data mining.
- Avez-vous besoin des deux ?
- La plupart des projets réels, oui ! Extrayez d’abord les données externes, puis analysez-les — avec vos données internes — pour obtenir une vue complète.
- Capacités de l’équipe :
- Pas de compétences en code ? Utilisez des outils de scraping no-code comme Thunderbit.
- Pas de data scientists ? Utilisez des outils BI faciles à prendre en main ou commencez par une analyse basique.
- Sensibilité au temps :
- Besoin en temps réel ? Mettez en place une extraction et une analyse continues.
- Projet ponctuel ? Faites une extraction unique puis analysez les données.
Checklist :
- « Ai-je toutes les données internes dont j’ai besoin ? » Si non, scrappez.
- « Comprends-je les données que j’ai ? » Si non, analysez-les.
- « Le problème est-il assez important pour combiner les deux approches ? » Si oui, faites les deux.
- « Mon équipe a-t-elle les compétences requises ? » Si non, utilisez des outils no-code ou demandez de l’aide.
Et n’oubliez pas : vous n’avez pas besoin de tout faire d’un coup. Commencez petit, lancez un pilote, puis montez en puissance à mesure que vous obtenez des résultats.
Points clés à retenir : faire des données un atout pour votre équipe
Récapitulons l’essentiel :
- Le web scraping et le data mining sont deux étapes d’un même parcours. Le scraping collecte les données, surtout depuis des sources externes ; le mining les analyse pour en tirer des insights.
- Des rôles différents, des objectifs différents : les équipes commerciales, marketing et opérations utilisent le scraping pour obtenir des données ; les analystes et équipes BI les exploitent pour leur donner du sens.
- Ce sont des approches complémentaires, pas concurrentes : les meilleurs résultats viennent de leur combinaison — scraping pour obtenir un jeu de données riche, mining pour obtenir des insights actionnables.
- Les outils no-code et l’IA ont abaissé la barrière d’entrée : Thunderbit et des outils similaires rendent le scraping accessible à tous. Les plateformes BI modernes facilitent aussi le mining.
- La qualité des données et l’éthique comptent : nettoyez vos données, respectez la vie privée et agissez toujours avec éthique.
- Laissez votre cas d’usage guider votre approche : partez de votre question métier, puis décidez quelles données vous нужны et comment les analyser.
- Commencez petit, puis passez à l’échelle : utilisez les offres gratuites, les projets pilotes et les gains rapides pour créer de l’élan.
Au fond, l’objectif est de donner à votre équipe les moyens de prendre de meilleures décisions grâce aux données. Cela peut vouloir dire que votre équipe commerciale passe moins de temps sur la recherche manuelle (grâce au scraping), ou que vos réunions stratégiques reposent sur de vrais insights (grâce au mining). Dans tous les cas, combiner les deux approches est la façon dont les équipes modernes gagnent un avantage concurrentiel.
Alors, récoltez ces ingrédients de données web, cuisinez quelques insights, et servez à votre équipe les informations actionnables dont elle a besoin. Et si vous avez besoin d’un coup de main en cuisine, est là pour vous simplifier la préparation.
Envie d’essayer ? Téléchargez et voyez à quel point le web scraping peut être simple. Pour plus d’astuces et d’histoires du terrain autour de la donnée, consultez le .
FAQ
1. Quelle est la principale différence entre web scraping et data mining ?
Le web scraping consiste à collecter des données brutes depuis des sites web, tandis que le data mining consiste à analyser ces données pour découvrir des schémas, des insights ou des tendances. Voyez le scraping comme le fait de rassembler les ingrédients et le mining comme celui de cuisiner le repas.
2. Qui utilise généralement le web scraping par rapport au data mining ?
Le web scraping est surtout utilisé par les équipes commerciales, marketing, opérations et recherche qui ont besoin rapidement de données externes fraîches. Le data mining est utilisé par les analystes, data scientists et équipes produit qui cherchent à tirer des insights stratégiques des données.
3. Ai-je besoin de compétences en code pour faire du web scraping ?
Plus maintenant. Des outils comme proposent des interfaces sans code, pilotées par l’IA, qui permettent à n’importe qui — quel que soit son niveau technique — d’extraire des données via des actions en point-and-click et des fonctions d’export instantané.
4. Comment le web scraping et le data mining travaillent-ils ensemble ?
Le web scraping fournit les données brutes et structurées dont le data mining a besoin. Ensemble, ils créent un pipeline : collecter les données externes avec le scraping, puis les analyser avec le mining pour orienter les décisions business.
5. Quels sont quelques cas d’usage concrets pour chacun ?
Le web scraping sert à des tâches comme la génération de leads, la surveillance des prix et le suivi des concurrents. Le data mining soutient la segmentation client, les prévisions de tendances, la détection de fraude et la planification stratégique à partir des données extraites.