

Cinq textes de loi japonais encadrent le web scraping. Aucun n’emploie réellement l’expression « web scraping ».
Si vous avez déjà essayé de déterminer si votre projet de scraping est légal au Japon, vous avez probablement buté sur une masse de posts de forum vagues, d’articles centrés sur l’entraînement de l’IA et de conseils contradictoires. J’ai passé des semaines à éplucher les textes officiels japonais, les orientations gouvernementales, les données d’application et les commentaires juridiques afin de composer le guide en anglais le plus clair possible.
Que vous surveilliez les prix des concurrents sur Rakuten, que vous extrayiez des données immobilières pour une analyse de marché ou que vous constituiez une liste de prospects B2B, cet article passe en revue toutes les lois importantes — avec des tableaux pratiques, des cas concrets et une checklist de conformité en 10 étapes à utiliser avant de commencer à extraire des données.
Que signifie réellement « Le web scraping est-il légal au Japon ? »
Le web scraping — l’utilisation de logiciels pour extraire automatiquement des données de sites web — n’est encadré par aucune loi japonaise unique. Aucun texte ne dit que « le scraping est légal » ou que « le scraping est illégal ». La légalité de votre projet dépend de trois choses : quoi vous extrayez, comment vous y accédez et ce que vous faites ensuite des données.
Cinq textes composent l’architecture juridique :
| Texte de loi | Ce qu’il couvre pour les scrapeurs |
|---|---|
| Loi sur le droit d’auteur (loi n° 48 de 1970) | Protège les œuvres créatives, les images, les textes et les structures de bases de données. L’article 30-4 prévoit une exception large pour l’analyse de données. |
| APPI (Loi sur la protection des informations personnelles, loi n° 57 de 2003) | Régit la collecte, l’utilisation, le partage et le transfert transfrontalier de données personnelles concernant des individus vivants. |
| UCAL (Loi sur l’interdiction d’accès non autorisé à des ordinateurs, loi n° 128 de 1999) | Criminalise le contournement de l’authentification et des contrôles d’accès — la loi japonaise anti-hacking. |
| UCPA (Loi sur la prévention de la concurrence déloyale, loi n° 47 de 1993) | Protège les secrets d’affaires et les « données partagées à accès restreint » contre l’acquisition illicite. |
| Code pénal (loi n° 45 de 1907) | Les articles 233, 234 et 234-2 peuvent s’appliquer lorsque le scraping perturbe le fonctionnement d’un site web. |
Le reste de cet article décortique chaque loi avec des exemples pratiques et des évaluations de risque. Vous voulez passer directement aux actions à mener ? Allez à la checklist de conformité en 10 étapes.
Loi japonaise sur le droit d’auteur et article 30-4 : l’exception d’analyse de l’information
La loi japonaise sur le droit d’auteur protège les œuvres créatives : articles, photos, descriptions de produits, structures de bases de données à l’agencement créatif. Lorsqu’un scraper télécharge une page web, il la « reproduit » techniquement au sens de l’article 21 — le droit exclusif de reproduction de l’auteur.
Mais c’est là que le Japon se distingue.
En 2018, le Japon a adopté une large révision (entrée en vigueur le 1er janvier 2019) qui a ajouté l’article 30-4 — une exception souple au droit d’auteur qui rend licite la plupart des formes de web scraping analytique. La Agency for Cultural Affairs la présente comme l’un des cadres les plus permissifs au monde pour l’analyse de données et le développement de l’IA.
La plupart des articles en anglais présentent l’article 30-4 comme pertinent uniquement pour l’entraînement de l’IA. C’est trop réducteur. Le texte couvre explicitement « l’analyse de l’information » — extraction, comparaison, classification et autres analyses statistiques de données. Autrement dit, exactement ce que font les entreprises de scraping au quotidien.
Ce que dit réellement l’article 30-4 (en langage clair)
L’article 30-4 autorise l’utilisation d’une œuvre protégée par le droit d’auteur « lorsque le but n’est pas de jouir personnellement, ni de faire jouir autrui, des idées ou sentiments exprimés dans l’œuvre ». En pratique, deux conditions doivent être réunies :
-
Le critère de la « jouissance ». Si vous extrayez des données factuelles — prix, dates, surface, niveaux de stock — plutôt que de consommer ou de republier du contenu créatif, vous êtes du bon côté. Les recommandations 2024 de l’ACA sur l’IA et le droit d’auteur confirment que les usages non axés sur la jouissance incluent l’analyse, la classification et l’indexation des données.
-
Le critère du « préjudice injustifié ». Votre scraping ne doit pas se substituer à l’œuvre originale ni réduire la valeur commerciale du titulaire du droit d’auteur. Extraire, par exemple, un jeu de données payant prêt à l’emploi pour éviter de l’acheter pourrait faire échouer ce test, même si votre finalité est analytique.

Scénarios de scraping concrets au titre de l’article 30-4
C’est ici que la théorie rencontre la pratique. Le texte s’applique bien au-delà de l’entraînement de l’IA :
| Cas d’usage | L’article 30-4 s’applique-t-il ? | Pourquoi |
|---|---|---|
| Scraper des annonces immobilières pour analyser les prix du marché | ✅ Oui | Le prix demandé, la surface et l’âge du bâtiment sont des données factuelles pour l’analyse de l’information, pas une jouissance de l’expression |
| Scraper des données boursières depuis des sites d’échange | ✅ Oui | Finalité d’analyse statistique |
| Scraper des images de produits pour un site e-commerce concurrent | ❌ Non | Exploitation du contenu expressif lui-même |
| Scraper des articles de presse pour les republier | ❌ Non | Se substitue à l’œuvre originale |
| Scraper des descriptions de produits pour surveiller les prix | ✅ Probablement oui | Extraction de données factuelles, pas de jouissance de l’expression |
| Construire un système RAG sur des documents scrapés | ⚠️ Mixte | La vectorisation peut être considérée comme non-jouissance, mais la restitution de passages protégés nécessite une analyse plus poussée |
Un autre point à connaître : l’article 47-5 offre une protection plus étroite pour la « petite exploitation » incidente au traitement informatique de l’information — pensez à de courts extraits ou à des vignettes dans les résultats de recherche. Ce n’est pas le principal refuge juridique du scraping, mais cela peut soutenir la copie préparatoire nécessaire à des services de recherche ou d’analyse. Les commentaires de l’ACA de 2019 évaluent le caractère « mineur » selon la proportion, la quantité et la précision de l’affichage.
En résumé : si vous extrayez des faits pour les analyser plutôt que pour republier du contenu créatif, le cadre japonais du droit d’auteur vous est favorable.
Loi japonaise sur l’accès non autorisé à des ordinateurs (UCAL) : quand le scraping franchit la ligne rouge
Presque aucun article en anglais sur le scraping n’explique cette loi. C’est pourtant sans doute la frontière la plus importante du droit japonais.
La Loi sur l’accès non autorisé à des ordinateurs (不正アクセス禁止法, loi n° 128 de 1999) est l’équivalent fonctionnel japonais du CFAA américain. Elle criminalise l’accès non autorisé à des ordinateurs protégés par des mesures d’authentification. Les sanctions prévues à l’article 11 peuvent aller jusqu’à 3 ans d’emprisonnement ou 1 000 000 ¥ d’amende.
UCAL n’interdit pas le scraping de pages web publiques. La loi ne s’applique que lorsque vous contournez ou éludez une authentification — pages de connexion, mots de passe, jetons d’accès ou contrôles similaires. Cette distinction est essentielle.
Niveaux de risque UCAL pour des scénarios courants de scraping
| Scénario | Niveau de risque UCAL | Explication |
|---|---|---|
| Scraper des fiches produits publiques | ✅ Faible | Aucun contournement d’authentification |
| Scraper derrière une connexion avec vos propres identifiants | ⚠️ Moyen — dépend des CGU | UCAL peut ne pas s’appliquer si les identifiants sont les vôtres, mais le risque contractuel et lié aux CGU demeure |
| Contourner l’authentification ou un CAPTCHA pour accéder aux données | ❌ Élevé — violation probable | L’article 2(4)(ii) couvre l’évasion des restrictions d’accès |
| Accéder à des API restreintes sans autorisation | ❌ Élevé — violation probable | Les API authentifiées ou réservées aux partenaires relèvent clairement d’UCAL |
| Utiliser les identifiants ou jetons de session d’une autre personne | ❌ Élevé — violation probable | L’article 2(4)(i) vise directement l’usage du code d’identification d’autrui |
La National Police Agency japonaise a signalé 563 affaires UCAL élucidées en 2024, soit 8,1 % de plus que l’année précédente. Parmi elles, 511 cas (90,8 %) concernaient l’utilisation non autorisée du code d’identification d’une autre personne. L’essentiel de la répression vise donc l’usage frauduleux d’identifiants, pas le scraping public ordinaire.
En quoi UCAL diffère du CFAA américain
UCAL est, sur un point important, plus étroit que le CFAA. Il se concentre spécifiquement sur le contournement de l’authentification, alors que l’expression « exceeds authorized access » du CFAA a fait l’objet de débats devant les tribunaux américains pendant des décennies. Après la décision Van Buren de la Cour suprême des États-Unis, la seule violation des CGU d’un site est moins susceptible d’entraîner une responsabilité pénale au titre du CFAA. Le Japon aboutit à un résultat pratique similaire : la violation des CGU relève du contrat, pas d’UCAL, sauf s’il existe un élément autonome de contrôle d’accès.
Amendements APPI de 2022 : ce que les scrapeurs doivent savoir sur les données personnelles
La Loi sur la protection des informations personnelles (APPI) est la principale loi japonaise sur la protection des données — et les amendements de 2022 ont nettement durci les règles. Si vous scrapez des noms, des e-mails, des numéros de téléphone ou toute donnée identifiant une personne vivante depuis des sites japonais, APPI s’applique.
La vraie question pratique est la suivante : à partir de quand le scraping déclenche-t-il la conformité APPI ?
Ce qui constitue des « informations personnelles » au sens d’APPI
L’article 2 d’APPI définit les informations personnelles comme des données permettant d’identifier un individu vivant déterminé — y compris par recoupement simple avec d’autres informations. Les FAQ du PPC confirment qu’une adresse e-mail professionnelle comme prenom.nom@entreprise.jp peut être une information personnelle lorsqu’elle identifie une personne précise, et que les identifiants de cookies deviennent des informations personnelles lorsqu’ils sont combinés à d’autres données permettant l’identification.
Les amendements de 2022 ont introduit une nouvelle catégorie : les « informations relatives à un individu » — des données qui n’identifient pas directement quelqu’un mais pourraient le faire une fois combinées à d’autres données (identifiants de cookie, historique de navigation, historique d’achats). Pourquoi cela compte pour le scraping : des données qui semblent anonymes pour le scraper peuvent devenir identifiables une fois fusionnées avec des données CRM ou adtech côté destinataire.
Restrictions sur les transferts transfrontaliers
Si vous scrapez des sites japonais depuis l’étranger et collectez des données personnelles, l’article 28 d’APPI exige une analyse avant le transfert de ces données à l’étranger. Le guide du PPC sur les transferts internationaux décrit trois voies courantes : le destinataire se trouve dans un pays désigné par le PPC comme équivalent, le destinataire a mis en place des mesures de protection équivalentes, ou une exception de l’article 27(1) s’applique.
Si une entreprise américaine, européenne ou singapourienne scrape des données personnelles depuis des sites japonais et les stocke hors du Japon, une analyse du transfert international au titre d’APPI est nécessaire. C’est un point qui surprend beaucoup d’équipes internationales.
La disposition de sortie (« opt-out ») pour les tiers de l’article 27
La question de forum que je vois le plus souvent : « Que se passe-t-il si je partage ou vends des données scrapées depuis des sites japonais ? »
L’article 27 d’APPI exige généralement un consentement préalable pour fournir des données personnelles à des tiers. Il existe un mécanisme formel d’opt-out — mais il suppose une déclaration auprès de la Personal Information Protection Commission, une notification aux personnes concernées et la possibilité pour elles d’empêcher cette mise à disposition. Les amendements de 2022 ont encore resserré ce cadre : la fourniture sur opt-out ne peut pas être utilisée pour des données personnelles obtenues par des moyens illicites ou reçues d’une autre entreprise via un mécanisme d’opt-out.
Le rapport annuel FY2024 du PPC indique 405 déclarations d’opt-out acceptées au total depuis octobre 2021, dont 93 pour FY2024. Le système existe, mais il est formel, pas informel.
Quand le scraping ne déclenche pas APPI
APPI ne s’applique pas aux données qui ne permettent pas d’identifier un individu vivant. Les champs à risque APPI plus faible incluent :
- Prix de produits, SKU, niveaux de stock et frais de livraison
- Horaires d’ouverture des magasins et coordonnées génériques d’entreprise (info@company.jp)
- Prix d’annonces immobilières, surface, âge du bâtiment et distance à la gare — lorsqu’ils ne sont pas liés à des propriétaires ou agents nommés
- Statistiques de marché agrégées où toute correspondance individuelle a été éliminée
Un choix de conception pratique à retenir : la fonctionnalité Thunderbit AI Suggest Fields permet aux utilisateurs de définir précisément quelles colonnes de données extraire. Vous pouvez volontairement exclure les champs de données personnelles et ne conserver que les faits commerciaux dont vous avez besoin — ce qui réduit l’exposition à APPI par conception plutôt que par accident.
Loi sur la prévention de la concurrence déloyale (UCPA) : le scraping des données d’un concurrent
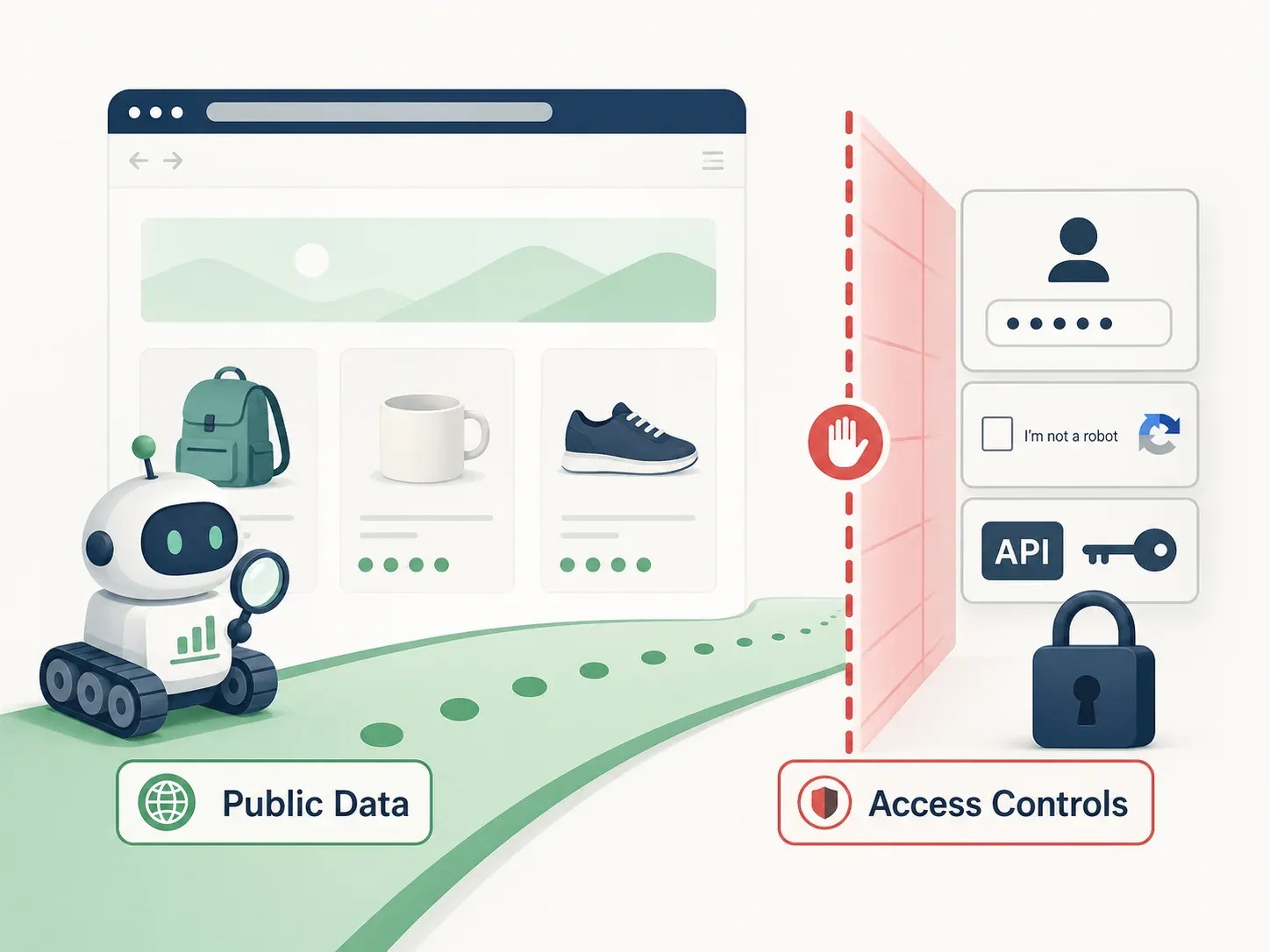
La Loi sur la prévention de la concurrence déloyale entre en jeu lorsque le scraping passe de faits publics à des informations commerciales confidentielles ou à des jeux de données protégés.
UCPA définit un secret d’affaires comme une information qui est : (1) gardée secrète, (2) utile pour l’activité économique et (3) non connue du public. Le METI résume ces trois critères comme les conditions de la protection du secret d’affaires.
Les faits visibles sur un site public — prix de produits, emplacements de magasins, offres d’emploi, catalogues produits — ne sont généralement pas des secrets d’affaires, car ils ne sont pas secrets et sont déjà publics. Les scraper n’enfreint donc généralement pas UCPA.
Dans quels cas UCPA peut s’appliquer au scraping
| Scénario | Risque UCPA | Pourquoi |
|---|---|---|
| Scraper le catalogue public d’un concurrent pour surveiller les prix | Généralement faible | Les faits d’un catalogue public ne sont en général pas secrets |
| Scraper des données de tarification internes en exploitant une faille d’API | Élevé | Informations commerciales utiles non publiques acquises par des moyens illicites |
| Scraper une base de données payante réservée aux partenaires ou une API sous licence hors du périmètre autorisé | Élevé | Les amendements UCPA de 2018 protègent les « données partagées à accès restreint » |
| Utiliser des données scrapées pour créer un produit concurrent qui profite gratuitement d’une base de données coûteuse | Zone grise | Les tribunaux peuvent examiner les restrictions d’accès, l’investissement et la substitution |
L’amendement UCPA de 2018 a ajouté une protection pour les « données partagées à accès restreint » — des informations techniques ou commerciales accumulées de façon significative, gérées électroniquement et fournies régulièrement à des personnes déterminées. Mais l’article 19 d’UCPA exclut les données substantiellement identiques à des informations rendues publiques sans contrepartie. Ainsi, une fiche produit publique gratuite n’est pas la même chose qu’un jeu de données commercial réservé aux membres.
Surcharge serveur et Code pénal japonais : ne faites pas planter le site
Les données elles-mêmes peuvent être parfaitement licites à collecter. Mais la manière dont vous les scrapez peut créer un risque pénal. Le Code pénal japonais contient des dispositions sur l’entrave à l’activité qui s’appliquent lorsque l’accès automatisé perturbe un site ou un système d’entreprise.
| Article du Code pénal | Conduite | Sanction |
|---|---|---|
| Article 233 | Entrave à l’activité par des moyens frauduleux | Jusqu’à 3 ans ou 500 000 ¥ |
| Article 234 | Entrave forcée à l’activité | Même sanction que l’article 233 |
| Article 234-2 | Entrave par endommagement/interférence avec un ordinateur | Jusqu’à 5 ans ou 1 000 000 ¥ |
Toute discussion sur le scraping au Japon finit par revenir à l’incident de la bibliothèque centrale de la ville d’Okazaki (vers 2010). Un ingénieur logiciel a créé un crawler pour collecter des informations sur les nouveaux livres à partir du site de la bibliothèque, générant environ 33 000 accès automatisés en deux semaines. Le serveur de la bibliothèque est devenu difficile à utiliser, et la police a arrêté l’utilisateur pour suspicion d’entrave à l’activité. L’affaire s’est terminée sans jugement au fond, mais elle reste un rappel fort : l’impact sur le serveur compte — même lorsque les données sont publiques.
Pour comprendre pourquoi les exploitants de sites réagissent vivement : Thales/Imperva a indiqué que les bots automatisés représentaient 51 % du trafic web en 2024, dont 37 % de mauvais bots. Akamai a constaté que les bots représentaient 42 % du trafic web total, l’e-commerce étant particulièrement touché.
Comment éviter les problèmes de surcharge serveur
- Respectez robots.txt (même si ce n’est pas une loi, cela prouve l’intention de l’opérateur)
- Ajoutez des délais entre les requêtes et limitez la concurrence
- Évitez les heures de pointe du site cible
- Arrêtez ou réduisez le trafic si vous voyez des erreurs, des blocages ou des réponses de limitation de débit
- Mettez en cache les pages déjà récupérées au lieu de solliciter sans cesse les mêmes URL
La fonctionnalité de scraping cloud de Thunderbit répartit les requêtes sur plusieurs serveurs, ce qui dilue naturellement la charge et réduit le risque de submerger un serveur cible unique. Ce n’est pas un bouclier juridique, mais c’est un choix de conception pragmatique qui va dans le sens d’un scraping responsable.
Violations des conditions d’utilisation : risque contractuel, pas risque pénal
De nombreux sites japonais incluent des conditions d’utilisation qui interdisent le scraping ou la collecte automatisée de données. En droit japonais, une violation des CGU relève du contrat — pas d’une infraction pénale.
Les lignes directrices interprétatives du METI sur le commerce électronique expliquent que les conditions d’un site sont opposables lorsqu’elles sont correctement intégrées au contrat de transaction. Les accords de type click-wrap (où vous devez cliquer sur « J’accepte ») sont les plus solides. Les conditions enfouies dans des liens de pied de page difficiles à remarquer sont plus faibles.
| Conception des CGU | Indice d’opposabilité |
|---|---|
| Click-wrap clair avec bouton « J’accepte » obligatoire | Le plus solide |
| Conditions liées près de la transaction, mais sans clic d’acceptation | Plus incertain |
| Conditions cachées dans le pied de page ou dans un emplacement difficile | Plus faible |
| Aucune relation contractuelle avec l’opérateur | La demande contractuelle peut être faible |
Aucune autorité fiable n’indique qu’une simple violation des CGU, sans autre élément, se transforme en infraction pénale japonaise. En pratique, la violation des CGU peut créer un risque civil contractuel (dommages-intérêts, injonction), mais l’exposition pénale exige généralement un élément supplémentaire — contournement des contrôles d’accès au titre d’UCAL, entrave à l’activité au titre du Code pénal ou violation du droit d’auteur.
Mon conseil : lisez les CGU avant de scraper un site japonais. Si elles interdisent explicitement le scraping, cherchez des alternatives — une API, un partenariat de données ou une autre source pour les mêmes informations.
Japon vs États-Unis vs UE : comparaison des lois sur le web scraping
Si vous venez d’un contexte juridique américain ou européen, ce tableau vous aidera à vous repérer. Le cadre japonais est plus permissif sur certains points et plus restrictif sur d’autres.
| Dimension juridique | Japon | États-Unis | UE |
|---|---|---|---|
| Texte principal sur le scraping | Pas de texte unique ; ensemble hétérogène : loi sur le droit d’auteur, APPI, UCPA, UCAL, Code pénal | CFAA, lois des États | RGPD, directive Bases de données, directive DSM |
| Exception de droit d’auteur pour l’analyse de données | Article 30-4 (large) | Fair use (au cas par cas) | Exception TDM (articles 3-4 de la directive DSM) — avec opt-out pour le TDM commercial |
| Scraping de données personnelles | APPI — disposition de fourniture à des tiers avec opt-out (art. 27) | Varie selon les États (CCPA, etc.) | RGPD — consentement/intérêt légitime strict |
| Contournement des contrôles d’accès | UCAL — infraction pénale | CFAA — pénal + civil | Varie selon l’État membre |
| Violation des CGU = illégal ? | Droit des contrats seulement ; aucune responsabilité pénale constatée | CFAA après Van Buren : probablement non | Varie ; le RGPD peut néanmoins s’appliquer |
| Risque de surcharge serveur | Code pénal art. 233, 234-2 (entrave à l’activité) | CFAA + responsabilité délictuelle | Varie |
Ce qu’il faut retenir de la comparaison
L’article 30-4 japonais est plus large que le fair use américain ou les exceptions TDM européennes — ce qui fait du Japon l’un des pays les plus permissifs pour le scraping analytique du point de vue du droit d’auteur. UCAL est plus étroit que le CFAA, car il se concentre uniquement sur le contournement de l’authentification. Les règles d’APPI sur les transferts transfrontaliers sont plus strictes que les cadres américains fragmentés de protection de la vie privée, mais dans certains détails opérationnels elles sont moins prescriptives que le RGPD.
Pour les équipes internationales : vous avez peut-être plus de liberté que vous ne le pensez pour scraper des données japonaises publiques à des fins d’analyse. La complexité se situe surtout dans le traitement des données personnelles — en particulier les transferts transfrontaliers et le partage à des tiers.
Votre checklist de conformité en 10 étapes pour le scraping de sites japonais
Avant de commencer à scraper n’importe quel site japonais, passez en revue ces dix questions oui/non. Chacune renvoie à l’un des cinq textes ci-dessus.
- Les données sont-elles accessibles publiquement ? (Pas de connexion, pas de paywall, pas de contournement des contrôles d’accès) → Si oui, le risque UCAL est faible.
- Les CGU du site interdisent-elles le scraping ? → Si oui, évaluez le risque contractuel ; envisagez d’autres sources de données.
- Collectez-vous des informations personnelles au sens d’APPI ? (Noms, e-mails, numéros de téléphone, identifiants) → Si oui, assurez-vous d’être conforme à APPI.
- Transférerez-vous hors du Japon des données personnelles scrapées ? → Si oui, respectez les règles de transfert transfrontalier de l’article 28 d’APPI.
- Prévoyez-vous de partager ou vendre ces données à des tiers ? → Si oui, suivez la procédure d’opt-out de l’article 27 d’APPI ou obtenez un consentement.
- Les données sont-elles protégées par le droit d’auteur ? → Si le scraping sert à l’analyse de l’information (et non à republier du contenu créatif), l’article 30-4 s’applique probablement.
- Votre activité de scraping se substituera-t-elle à l’œuvre originale ? → Si oui, la protection de l’article 30-4 ne s’applique probablement pas.
- Contournez-vous une authentification, un CAPTCHA ou des contrôles d’accès ? → Si oui, risque UCAL élevé — ne poursuivez pas sans avis juridique.
- Votre volume de scraping risque-t-il de surcharger le serveur ? → Si oui, limitez les requêtes, ajoutez des délais, utilisez un scraping distribué.
- Les données cibles sont-elles gérées comme un secret d’affaires par l’entreprise ? → Si ce sont des données non publiques et propriétaires, UCPA peut s’appliquer.
Si toutes les réponses pointent vers des données publiques, factuelles, non personnelles, limitées en débit et non destinées à la republication — vous êtes sur une bonne base. Le moindre signal d’alerte devrait déclencher une revue juridique avant de commencer.

Comment Thunderbit vous aide à scraper les sites japonais en respectant la conformité
Je veux être transparent : Thunderbit est un outil, pas un conseil juridique. Mais il est conçu d’une manière qui s’aligne sur les principes de conformité exposés ci-dessus.
- AI Suggest Fields : l’IA de Thunderbit lit la page et suggère exactement quelles colonnes de données extraire. Cela vous aide à définir délibérément uniquement les champs non personnels dont vous avez besoin — en réduisant la collecte inutile de données personnelles par conception plutôt que par accident.
- Scraping cloud : répartit les requêtes sur plusieurs serveurs, dispersant naturellement la charge et réduisant le risque de submerger un serveur japonais unique. (Voyez cela comme une compatibilité native avec la limitation de débit.)
- Extracteurs d’e-mails et de numéros de téléphone gratuits : lorsque vous devez réellement collecter des coordonnées depuis des sites japonais, l’extracteur d’e-mails de Thunderbit et l’extracteur de numéros de téléphone permettent une extraction en un clic. Mais combinez cela avec les recommandations APPI ci-dessus — la collecte de données personnelles exige de comprendre vos obligations de conformité.
- Export vers Excel, Google Sheets, Airtable ou Notion : les données scrapées peuvent être structurées et exportées immédiatement pour l’analyse, ce qui soutient la finalité d’« analyse de l’information » protégée par l’article 30-4.
- Aucune maintenance requise : l’IA de Thunderbit relit le site à chaque fois et s’adapte aux changements de mise en page. Cela évite les scrapers cassés qui martèlent un serveur avec des requêtes en échec — une manière concrète d’éviter les problèmes de charge serveur qui ont déclenché l’incident de la bibliothèque d’Okazaki.
Pour voir comment utiliser Thunderbit en pratique, consultez notre chaîne YouTube ou le guide de démarrage rapide. Vous pouvez l’essayer gratuitement via l’extension Chrome.
Essayez Thunderbit pour le web scraping japonais
Exemples pratiques de cas d’usage
| Cas d’usage | Champs recommandés à extraire | Justification juridique |
|---|---|---|
| Suivi des prix de l’e-commerce japonais | Nom du produit, prix affiché, disponibilité, vendeur, SKU, URL, horodatage | Données commerciales factuelles ; analyse de l’information au titre de l’article 30-4 ; évitez de copier les images de produits ou les avis pour les republier |
| Analyse du marché immobilier japonais | Prix demandé, zone géographique, surface, âge du bâtiment, type de bien, gare la plus proche, URL, horodatage | Soutient l’analyse agrégée du marché ; excluez les noms d’agents, numéros de téléphone et noms de propriétaires sauf si la conformité APPI est en place |
| Suivi des opérations B2B | Nom de l’entreprise, adresse de l’agence, e-mail générique de l’entreprise, horaires d’ouverture, catégorie de service | Risque APPI plus faible si aucun individu vivant n’est identifié ; vérifiez les CGU et les limites de débit |
Points clés sur la légalité du web scraping au Japon
Le web scraping est légal au Japon dans la plupart des cas — surtout lorsque vous scrapez des données publiques, non personnelles et factuelles à des fins d’analyse. Mais « la plupart des cas » ne veut pas dire « tous les cas ».
- Loi sur le droit d’auteur (article 30-4) : le scraping analytique de données publiques est autorisé ; la republication de contenu créatif ne l’est pas.
- UCAL : ne contournez pas l’authentification ni les contrôles d’accès.
- APPI : traitez les données personnelles avec prudence, surtout pour les transferts transfrontaliers et le partage à des tiers.
- UCPA : les données publiques ne constituent généralement pas un secret d’affaires ; les données verrouillées ou payantes présentent un risque plus élevé.
- Code pénal : ne faites pas planter le serveur.
Utilisez la checklist en 10 étapes avant tout projet de scraping. En cas de doute, consultez un avocat — surtout pour les projets impliquant des données personnelles ou du contenu soumis à restriction d’accès.
Si vous êtes prêt à commencer à scraper des sites japonais en conformité, Thunderbit est conçu pour simplifier le processus pour les utilisateurs non techniques. Définissez vos champs, extrayez les données, exportez vers l’outil de votre choix et concentrez-vous sur l’analyse.
Essayez l’Extracteur Web IA pour les sites japonais Get Started Free
FAQ
Est-il légal de scraper des sites web publics au Japon ?
En général, oui. Le scraping de données publiques à des fins d’analyse de l’information est généralement légal au titre de l’article 30-4 de la loi japonaise sur le droit d’auteur, à condition de ne pas surcharger le serveur, de ne pas contourner les contrôles d’accès, de ne pas collecter de données personnelles sans respecter APPI, ni de republier une expression protégée. Le facteur déterminant est la finalité : analyse, pas republication.
Puis-je scraper des données personnelles (e-mails, numéros de téléphone) depuis des sites japonais ?
Oui, mais APPI s’applique. Vous devez avoir une finalité licite, expliquer comment vous utiliserez les données et respecter des restrictions sur les transferts transfrontaliers et le partage à des tiers. Les amendements de 2022 ont nettement durci ces règles — en particulier pour les données qui quittent le Japon ou sont partagées avec d’autres entreprises.
Que se passe-t-il si les conditions d’utilisation d’un site japonais interdisent le scraping ?
La violation des CGU est un problème contractuel (responsabilité civile potentielle pour dommages ou injonction), pas une infraction pénale. Cela dit, elle peut renforcer d’autres arguments juridiques et aggraver l’application des règles. Lisez toujours les CGU avant de scraper et demandez-vous si les données sont accessibles par d’autres moyens.
Le scraping derrière une page de connexion est-il légal au Japon ?
Utiliser vos propres identifiants est une zone grise — UCAL peut ne pas s’appliquer directement, mais le risque de violation des CGU et le risque contractuel demeurent. Le contournement de l’authentification, l’utilisation des identifiants d’autrui ou l’évasion des contrôles d’accès constitue probablement une infraction pénale à la loi sur l’accès non autorisé à des ordinateurs, passible de jusqu’à 3 ans d’emprisonnement ou 1 000 000 ¥ d’amende.
Puis-je vendre des données que j’ai scrapées sur des sites japonais ?
Si les données contiennent des informations personnelles, vous devez suivre le mécanisme de fourniture à des tiers avec opt-out prévu à l’article 27 d’APPI — ce qui exige une déclaration formelle auprès du PPC, une notification individuelle et des mécanismes d’opt-out. Vendre des données personnelles sans procédure adéquate constitue une violation de conformité. Pour les agrégats factuels non personnels, le risque APPI est plus faible, mais le droit d’auteur, UCPA, les CGU et les implications juridiques du web scraping s’appliquent toujours.
En savoir plus




