

Le web scraping est-il illégal ? C’est la question à un million de dollars que j’entends chaque semaine de la part de fondateurs, de marketeurs et de passionnés de données.
Avec 51 % du trafic internet mondial provenant désormais de bots — une première, puisque le trafic automatisé dépasse désormais l’activité humaine — et une grande partie de ce trafic liée au web scraping pour la veille concurrentielle, la vente et l’entraînement de l’IA, il n’est pas surprenant que tout le monde essaie de comprendre où se situent les limites juridiques.
Un jour, vous voyez un titre annonçant qu’un tribunal a jugé que le scraping de données publiques est autorisé. Le lendemain, les régulateurs mettent en garde contre la collecte « illégale » de données sur les réseaux sociaux. C’est déroutant, même pour des gens comme moi qui passent leurs journées à construire des outils de web scraping IA chez Thunderbit.
Alors, le web scraping est-il illégal ? La réponse n’est pas un simple oui ou non. Cela dépend de ce que vous récupérez, de l’endroit où vous le récupérez, de la façon dont vous utilisez les données et de ce que dit la loi dans votre pays.
Dans cette analyse approfondie, je vais décortiquer le paysage juridique, démonter quelques idées reçues et partager des conseils pratiques — ainsi que quelques anecdotes de terrain — pour rester en conformité, que vous soyez un fondateur solo ou une équipe data d’une entreprise du Fortune 500.
Web scraping et droit : existe-t-il une ligne claire ?
Si vous espérez une réponse en une phrase, je vais vous faire gagner du temps : la loi n’a pas tracé de ligne nette et claire concernant le web scraping.
À la place, il existe un ensemble de règles qui se chevauchent — propriété des données, vie privée, propriété intellectuelle, lois anti-piratage informatique et ces fameux conditions d’utilisation (Terms of Service, ToS). Chacune peut entrer en jeu, et la réponse dépend souvent de votre cas précis (multilogin.com).
Voyons les trois grands blocs juridiques :
- Propriété des données : En général, les faits et les informations publiques (comme les prix ou les numéros de téléphone) ne sont pas protégeables par le droit d’auteur. En revanche, les contenus créatifs (articles, images) et les bases de données propriétaires peuvent être protégés — surtout dans l’UE, où les « droits sur les bases de données » existent (cliffordchance.com).
- Vie privée : Les lois modernes sur la vie privée (comme le RGPD en Europe ou la PIPL en Chine) traitent les données personnelles comme un actif réglementé, même si elles sont publiées publiquement. Extraire des noms, des e-mails ou des profils sociaux sans base légale peut vous attirer de sérieux ennuis (ico.org.uk).
- Contrats (conditions d’utilisation) : De nombreux sites interdisent explicitement le scraping dans leurs ToS. Même si les ToS ne sont pas des lois, les tribunaux peuvent les considérer comme des contrats contraignants. Les enfreindre peut entraîner des poursuites et, dans certains cas, déclencher des lois anti-intrusion si vous contournez des protections techniques (cliffordchance.com).
Alors, le web scraping est-il illégal ? Parfois oui, parfois non, et souvent « cela dépend ». Tout est dans les détails.
Comparer les approches juridiques : États-Unis, UE, Royaume-Uni, Chine
Voici un tableau rapide pour montrer comment les grandes régions abordent le web scraping :
| Région | Scraping de données publiques | Scraping de données personnelles/privées | Application et points notables |
|---|---|---|---|
| États-Unis | Généralement autorisé pour les données publiques (voir hiQ v. LinkedIn). Violer les ToS peut entraîner des poursuites civiles. | Restreint/illégal si vous contournez des identifiants de connexion ou utilisez des données personnelles de manière abusive. Les lois des États (comme le CCPA) peuvent s’appliquer. | Lettres de mise en demeure, blocage IP, poursuites. La CFAA s’applique si vous contournez des barrières techniques. |
| UE | Autorisé sous conditions pour les données publiques non personnelles. Les droits sur les bases de données peuvent s’appliquer. Le règlement européen sur l’IA (2026) ajoute des exigences de transparence pour les données d’entraînement des IA. | Fortement encadré par le RGPD — même les données personnelles publiques nécessitent une base légale. | Les autorités de protection des données peuvent infliger des amendes en cas d’atteinte à la vie privée. Les droits d’auteur et les droits sur les bases de données sont aussi appliqués. Le règlement européen sur l’IA interdit le scraping d’images faciales à des fins d’IA. |
| Royaume-Uni | Similaire à l’UE. Les données publiques non personnelles peuvent être scrapées, mais il faut respecter les droits sur les données et les contrats. | Très strict pour les données personnelles — le UK GDPR s’applique. Le Computer Misuse Act criminalise les accès non autorisés. | L’ICO peut sanctionner les violations de la protection des données. Les tribunaux peuvent faire appliquer les ToS. |
| Chine | Fortement encadré. Les données publiques non personnelles peuvent être scrapées pour un usage interne, mais l’environnement reste prudent. | Très restreint — la PIPL exige le consentement pour les données personnelles. Les lois anti-concurrence déloyale s’appliquent. | Affaires pénales pour scraping à grande échelle. Les tribunaux utilisent le droit de la concurrence déloyale pour faire cesser le scraping non autorisé. |
Le web scraping est-il illégal ? Les facteurs juridiques clés à prendre en compte
Alors, qu’est-ce qui détermine réellement si votre projet de scraping est légal ou risqué ? Voici les principaux facteurs :
- Données publiques vs privées : Scraper des données visibles par n’importe qui sur le web ouvert est généralement plus sûr. Scraper quelque chose derrière une connexion, un paywall ou une barrière technique ? C’est probablement illégal (thunderbit.com).
- Nature des données : Les données personnelles (noms, e-mails, profils) déclenchent les lois sur la vie privée. Les contenus protégés par le droit d’auteur (articles, images) ne peuvent pas être copiés en bloc. Les faits purs (prix, météo) sont généralement librement exploitables (oxylabs.io).
- Usage prévu : L’analyse interne ou la recherche sont perçues avec plus de souplesse que la republication ou la vente de données scrapées. Utiliser des données récupérées pour concurrencer directement la source ? C’est une action en justice en attente d’être lancée (thunderbit.com).
- Conformité aux règles du site : Vérifiez toujours robots.txt et les ToS. Robots.txt n’a pas de valeur juridique contraignante, mais il est préférable de le respecter. Les violations des ToS peuvent entraîner des poursuites civiles, voire pire (promptcloud.com).
- Mesures techniques : Il est essentiel de scraper à une vitesse proche de celle d’un humain et de ne pas contourner les mesures de sécurité. Mitrailler un serveur ou contourner des CAPTCHA peut faire basculer la situation vers le piratage (cliffordchance.com).
Ce qui a changé entre 2024 et 2026 : décisions de justice et réglementations clés
Le paysage juridique du web scraping a profondément évolué depuis 2023. Voici les développements que tout scraper doit connaître :
Grandes décisions de justice
-
Meta v. Bright Data (2024) : Un tribunal fédéral américain a jugé que les conditions d’utilisation de Meta n’interdisent pas le scraping des données publiques par des utilisateurs non connectés. Le juge a estimé qu’« un visiteur n’est pas considéré comme un “utilisateur” tant qu’il n’a pas de compte ». Meta a ensuite abandonné les autres demandes. C’est une victoire historique pour le scraping de données publiques.
-
X Corp v. Bright Data (2024) : Twitter (désormais X) a perdu une affaire similaire, confirmant le même principe : scraper des données librement accessibles sans se connecter ne viole pas les ToS, car le scraper n’a jamais accepté ces conditions.
-
Reddit v. Perplexity AI (octobre 2025) : Reddit a poursuivi Perplexity AI et plusieurs fournisseurs de scraping, en invoquant le DMCA et en alléguant un contournement des systèmes anti-bots. Cela signale une nouvelle stratégie juridique : les plateformes se tournent vers le droit d’auteur et les actions pour contournement plutôt que vers la CFAA.
-
NYT v. OpenAI (mars 2025) : Un juge fédéral a autorisé la poursuite de l’affaire de droit d’auteur intentée par le New York Times contre OpenAI, rejetant la demande de rejet d’OpenAI. Cela pourrait établir un précédent majeur sur la question de savoir si le scraping de contenus pour entraîner des modèles d’IA relève du « fair use ».
-
Règlement d’Anthropic (septembre 2025) : Anthropic a accepté de payer 1,5 milliard de dollars pour régler un recours collectif aux États-Unis portant sur l’utilisation de textes protégés par le droit d’auteur pour entraîner son modèle d’IA — preuve que les coûts du scraping pour l’IA sont bien réels.
Grande tendance : de la CFAA au droit des contrats et au droit d’auteur
La tendance est claire : la CFAA (Computer Fraud and Abuse Act) perd de sa force comme arme contre les scrapers de données publiques. Les entreprises qui ont tenté d’utiliser la CFAA contre le scraping de données publiques — Meta, X, LinkedIn — ont largement échoué. À la place, le champ de bataille juridique se déplace vers :
- Le droit des contrats (violations des ToS — mais les tribunaux disent que les non-utilisateurs ne sont pas liés par les ToS)
- Les revendications en droit d’auteur (surtout pour les données d’entraînement de l’IA)
- Les lois anti-contournement (section 1201 du DMCA)
Pour les scrapers, cela signifie que le risque juridique n’a pas disparu — il s’est simplement déplacé.
Évolutions réglementaires
- Mises à jour du CCPA 2026 : Les règlements révisés du CCPA en Californie sont entrés en vigueur le 1er janvier 2026, avec de nouvelles règles concernant la technologie de prise de décision automatisée (ADMT), les analyses de risques et les obligations des courtiers en données.
- Nouvelles lois d’État sur la vie privée aux États-Unis : L’Indiana, le Kentucky et le Rhode Island ont adopté des lois complètes sur la vie privée entrées en vigueur en 2026.
- Règlement européen sur l’IA : L’application complète débute le 2 août 2026 — avec obligation pour les développeurs d’IA de divulguer les sources des données d’entraînement, de respecter les refus d’indexation de copyright et d’interdire le scraping d’images faciales pour les systèmes d’IA.
- AI Accountability for Publishers Act (février 2026) : Projet de loi américain qui exigerait des entreprises d’IA qu’elles obtiennent une autorisation et rémunèrent les éditeurs avant de scraper leurs contenus.
Les politiques de scraping des grandes plateformes : ce qu’il faut savoir
Tous les sites ne traitent pas le scraping de la même manière. Voici un aperçu, plateforme par plateforme, de ce que les plus gros sites autorisent, bloquent et ce que les tribunaux ont dit :
| Plateforme | ToS sur le scraping | Défenses techniques | Application juridique | Ce qui est pratiquement sûr |
|---|---|---|---|---|
| Google (Search & Maps) | Interdit l’accès automatisé dans les ToS. La Maps Platform contient une clause explicite « No Scraping ». | Défis SearchGuard JS, CAPTCHA, limitation de débit. robots.txt mis à jour en 2025 pour bloquer les crawlers IA. | A poursuivi des scrapers en décembre 2025 en s’appuyant sur le DMCA. Bloque activement les crawlers IA (Anthropic, Meta, OpenAI). | Le scraping des données publiques d’entreprises sur Google Maps est juridiquement défendable (précédent hiQ), mais attendez-vous à des blocages techniques. Utilisez les API officielles autant que possible. |
| Amazon | Interdit explicitement tout scraping dans les Conditions d’utilisation (« no robot, spider, scraper, or other automated means »). | Détection agressive des bots, CAPTCHA, blocage IP. robots.txt bloque tous les bots sauf Googlebot/Bingbot. Bloque explicitement les crawlers IA depuis 2025. | A poursuivi Perplexity AI en novembre 2025. Envoie régulièrement des lettres de mise en demeure. BSA mise à jour en mars 2026 avec des règles pour les agents IA. | Les données publiques de produits (prix, fiches) sont factuelles et scrapables au regard du droit américain, mais Amazon réagit très agressivement. Limitez le débit et évitez les données personnelles. |
| Interdit le scraping dans les ToS ; exige l’accord de l’utilisateur pour accéder aux services. | Portes de connexion pour la plupart des données de profil, détection anti-bots, limitation de débit. | L’affaire hiQ a confirmé que le scraping des profils publics ne viole pas la CFAA, mais LinkedIn a gagné sur des revendications contractuelles / de concurrence déloyale lorsque de faux comptes ont été utilisés. | Les profils publics (visibles sans connexion) sont juridiquement défendables à scraper. Ne créez jamais de faux comptes et ne récupérez jamais de données derrière une connexion. | |
| Meta (Facebook & Instagram) | Les ToS interdisent le scraping ; règles distinctes pour les données connectées et déconnectées. | Portes de connexion pour la plupart des contenus, détection avancée des bots. | A perdu face à Bright Data en 2024 — le tribunal a jugé que les ToS ne s’appliquent pas aux scrapers non connectés. A abandonné les autres demandes. | Les données publiques (pages d’entreprise, publications publiques) visibles sans connexion sont plus sûres. Ne scrappez jamais de profils privés ni de données derrière connexion. |
| X (Twitter) | Les ToS mises à jour en 2023 interdisent tout scraping et crawling sans consentement écrit. L’ancienne exception robots.txt a été supprimée. | robots.txt bloque tous les crawlers (Disallow: /). Défis Cloudflare Turnstile. Limites strictes (300 requêtes/heure). Score de réputation IP. | A perdu face à Bright Data pour les données publiques, mais limite de façon agressive l’accès technique. | Les tweets et profils publics sont juridiquement défendables, mais les barrières techniques de X comptent parmi les plus difficiles en 2026. Attendez-vous à des blocages sans infrastructure proxy premium. |
En bref : les tribunaux ont régulièrement jugé que le scraping de données publiquement visibles sans connexion ne viole pas la CFAA. Mais les plateformes peuvent toujours agir contre vous sur le terrain du droit des contrats, du droit d’auteur ou des lois anti-contournement — et elles vous compliqueront la vie avec des barrières techniques. Scrapez toujours de manière responsable.
Données d’entraînement pour l’IA et web scraping : la nouvelle frontière juridique
Si vous suivez l’actualité en 2026, vous savez que le scraping de données pour entraîner des modèles d’IA est devenu le front juridique le plus brûlant. Voici ce qui se passe :
- Les procès pour violation de copyright s’accumulent. Le New York Times, des auteurs et des éditeurs ont poursuivi OpenAI, Anthropic et d’autres, en affirmant que le scraping massif de contenus protégés pour entraîner des LLM n’est pas un « fair use ». Anthropic a réglé un important recours collectif pour 1,5 milliard de dollars en 2025 — signe que les coûts du scraping pour l’IA sont bien réels.
- La défense du « fair use » est fragile. Les tribunaux américains n’ont pas encore rendu de décision définitive sur la question de savoir si l’entraînement d’une IA sur des données scrapées relève du fair use. Les premières décisions suggèrent que cela dépend fortement de la manière dont les données ont été obtenues et de ce qui est fait avec la sortie de l’IA.
- De nouvelles lois arrivent. Le AI Accountability for Publishers Act (présenté en février 2026) vise à obliger les entreprises d’IA à obtenir une autorisation et à rémunérer les éditeurs avant de scraper leurs contenus.
- Le règlement européen sur l’IA (application complète en août 2026) impose aux développeurs d’IA de divulguer les sources des données d’entraînement, de respecter les refus d’exploitation lisibles par machine (dans le cadre de l’exception TDM de la directive sur le droit d’auteur) et d’étiqueter les contenus générés par IA. Il interdit aussi les systèmes d’IA qui scrappent des images faciales sur Internet.
- Les crawlers IA/LLM explosent. Les crawlers IA ont quadruplé leur part du trafic web, passant de 2,6 % à 10,1 % en seulement huit mois. À lui seul, GPTBot d’OpenAI a progressé de 305 %. En réponse, de grands sites (Amazon, Reddit, le NYT) mettent à jour robots.txt pour bloquer explicitement les crawlers IA.
Ce que cela signifie pour vous : si vous récupérez des données pour des usages business traditionnels (génération de leads, suivi des prix, étude de marché), ces règles spécifiques à l’IA peuvent ne pas s’appliquer directement. Mais si vous injectez des données scrapées dans des modèles d’IA, redoublez de prudence — et demandez un avis juridique.
Les lois sur le web scraping dans le monde : comparaison rapide
Prenons un peu de recul pour voir comment les règles se présentent à l’échelle mondiale :
- États-Unis : Pas d’interdiction générale. Le scraping de sites publics est en général licite (hiQ v. LinkedIn), et les décisions Meta et X Corp de 2024 ont encore renforcé la position en faveur du scraping de données publiques. Mais scraper derrière des connexions ou des barrières techniques peut toujours déclencher la CFAA. La tendance va désormais vers l’usage du droit des contrats et du droit d’auteur par les entreprises. Les lois sur la vie privée évoluent rapidement : le CCPA a reçu d’importantes mises à jour entrées en vigueur le 1er janvier 2026, incluant de nouvelles règles sur la prise de décision automatisée et les obligations des courtiers en données. L’Indiana, le Kentucky et le Rhode Island ont également adopté des lois complètes sur la vie privée en 2026.
- Union européenne : Lois de protection de la vie privée strictes. Le RGPD s’applique même aux données personnelles publiques. Les droits sur les bases de données peuvent bloquer le scraping à grande échelle de données structurées (cliffordchance.com). NOUVEAU : le règlement européen sur l’IA entre en application complète le 2 août 2026, obligeant les développeurs d’IA à divulguer les sources des données d’entraînement et à respecter les refus d’utilisation de copyright. Le règlement interdit le scraping d’images faciales sur Internet pour les systèmes d’IA.
- Royaume-Uni : S’aligne sur les règles de l’UE après le Brexit. Les données publiques peuvent être scrapées, mais le scraping d’informations personnelles est strictement encadré. Le Computer Misuse Act peut criminaliser l’accès non autorisé.
- Chine : Très restrictive. La PIPL et la Data Security Law exigent le consentement pour les données personnelles. Les tribunaux utilisent le droit de la concurrence déloyale pour bloquer le scraping qui nuit aux entreprises (malwarebytes.com).
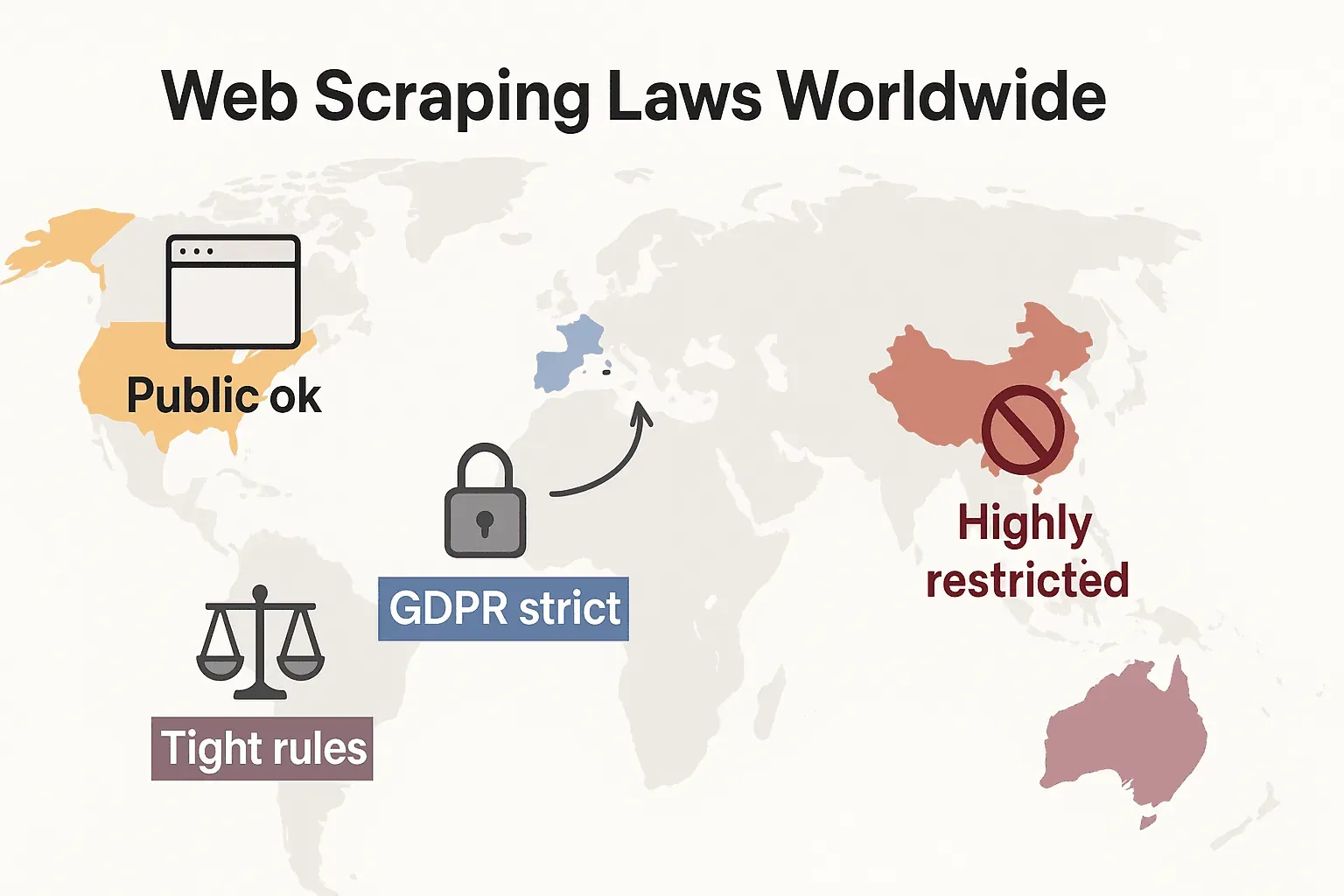
En résumé : le scraping de données publiques non personnelles pour un usage interne est généralement le plus sûr. Tout le reste ? Vérifiez les lois locales et avancez avec prudence.
Idées reçues sur la légalité du web scraping
Démystifions quelques idées reçues que j’entends tout le temps :
- Mythe 1 : « Le web scraping est illégal, point final. »
Faux. Aucune loi n’interdit tout le web scraping. Ce qui compte, c’est la manière dont vous scrapez et ce que vous scrapez (oxylabs.io). - Mythe 2 : « Si les données sont publiques, je peux en faire ce que je veux. »
Pas tout à fait. Les données publiques peuvent tout de même être protégées par la vie privée ou le droit d’auteur, et les ToS peuvent limiter certains usages (ico.org.uk). - Mythe 3 : « Le web scraping, c’est la même chose que le piratage. »
Non. Scraper des pages web publiques n’est pas du piratage. Contourner des connexions ou des barrières techniques, c’est une autre histoire (calawyers.org). - Mythe 4 : « Tant que je ne me fais pas attraper, tout va bien. »
C’est un raisonnement risqué. Beaucoup de sites utilisent des technologies anti-bot et finiront par vous repérer. Le silence ne vaut pas consentement. - Mythe 5 : « Donner le crédit ou utiliser les données en interne suffit à rendre ça acceptable. »
L’attribution ne prime pas sur le droit d’auteur ou la vie privée. L’usage interne est plus sûr, mais ce n’est pas un passe-droit. - Mythe 6 : « Tout web scraping viole la vie privée. »
Tous les scrapers ne traitent pas des données personnelles. En revanche, extraire de gros volumes d’informations personnelles sans garanties est presque toujours illégal (oxylabs.io). - Mythe 7 : « Si les ToS d’un site interdisent le scraping, il est toujours illégal de scraper. »
Pas nécessairement. En 2024, les tribunaux ont jugé dans Meta v. Bright Data et X Corp v. Bright Data que les ToS ne peuvent pas lier des utilisateurs qui ne les ont jamais acceptées — autrement dit, si vous scrapez sans vous connecter ni créer de compte, les ToS du site peuvent ne pas vous être opposables. Le sujet évolue encore, mais c’est un changement important.
Comment scraper des données légalement : bonnes pratiques de conformité
Voici ma checklist de référence pour un web scraping légal et éthique :
- Lisez et respectez les conditions d’utilisation du site. S’ils disent « pas de scraping », envisagez d’arrêter ou demandez une autorisation (ql2.com).
- Limitez-vous aux données publiques. Si un mot de passe est nécessaire, l’accès est restreint — ne le scrapez pas (thunderbit.com).
- Vérifiez robots.txt et adoptez un crawling poli. Ce n’est pas contraignant juridiquement, mais c’est une bonne pratique. N’assailliez pas les serveurs — espacez vos requêtes (promptcloud.com).
- Évitez les données personnelles sauf si vous avez une base légale. Si vous devez les collecter, respectez le RGPD/CCPA et réduisez au minimum ce que vous recueillez.
- Ne republiez pas les contenus scrapés en bloc. Ajoutez de la valeur ou de l’analyse, ou obtenez une autorisation (thunderbit.com).
- N’alimentez pas de modèles d’IA avec du contenu scrapé sans vérifier le droit d’auteur. Le paysage juridique évolue vite — demandez conseil si c’est votre cas d’usage.
- Utilisez des API officielles ou des exports de données quand ils existent. Ils sont conçus pour cela et sont en général plus sûrs (thunderbit.com).
- Soyez transparent et responsable. Si vous collectez des données personnelles, informez les personnes concernées et conservez un journal de vos activités.
- Réduisez et sécurisez vos données. Ne collectez que ce dont vous avez besoin, gardez-les exactes et stockez-les de manière sûre.
- Restez informé et demandez un avis juridique pour les cas limites. Les lois et les décisions de justice évoluent rapidement — en particulier le règlement européen sur l’IA et les lois d’État américaines sur la vie privée. En cas de doute, consultez un professionnel.
Essayez l’extension Chrome Thunderbit pour un scraping conforme
Utiliser légalement des outils de web scraping : ce que les entreprises doivent savoir
Des outils de web scraping comme Thunderbit rendent la collecte de données accessible aux non-développeurs, mais il faut tout de même les utiliser de manière responsable :
- Choisissez des outils axés sur la conformité. Thunderbit, par exemple, ne scrape que ce que vous pouvez voir dans votre navigateur — pas de piratage d’API en douce ni d’accès non autorisé (thunderbit.com).
- Restez dans des cas d’usage légitimes. L’analyse interne, l’étude de marché et la surveillance concurrentielle des prix sont généralement sûres. Republier ou vendre des données scrapées ? Beaucoup plus risqué.
- Configurez les outils pour la conformité. Réglez des délais de crawl, respectez robots.txt et utilisez des modèles qui ne collectent que ce dont vous avez besoin.
- Gardez cela en interne. L’usage interne des données scrapées est plus sûr que leur republication.
- Formez votre équipe. Assurez-vous que tout le monde comprend les règles et les bonnes pratiques.
- Exploitez les fonctionnalités de conformité intégrées. Thunderbit avertit les utilisateurs lorsqu’un site est risqué, scrape à une vitesse proche de celle d’un humain et ne stocke pas vos données sur ses serveurs.
- N’insistez pas à tout prix. Si un outil ne peut pas scraper un site, n’essayez pas de contourner la limite. Toutes les données ne sont pas récupérables sans risque.
L’approche de Thunderbit : permettre un web scraping IA conforme
Chez Thunderbit, nous avons beaucoup réfléchi à la conformité. Voici comment notre AI Web Scraper aide les utilisateurs à rester dans les clous :
- Ne scrape que ce que vous pouvez voir. Thunderbit fonctionne dans votre session de navigateur, donc il ne peut pas accéder à des données que vous ne pourriez pas copier manuellement.
- Guide les utilisateurs avec des avertissements. Si vous essayez de scraper un site aux politiques anti-scraping strictes, Thunderbit vous alerte.
- Vitesses de scraping proches de celles d’un humain. Que vous travailliez en local ou dans le cloud, Thunderbit évite de saturer les serveurs.
- Sélection de données personnalisable. Notre IA suggère les colonnes pertinentes, ce qui vous aide à ne collecter que ce dont vous avez besoin.
- Gestion des sous-pages et de la pagination. Thunderbit navigue sur les sites comme un vrai utilisateur, en respectant leur structure.
- Confidentialité et sécurité. Vos données restent chez vous — Thunderbit ne les stocke pas et ne les réutilise pas.
- Exports favorables à la conformité. Exportez directement vers Google Sheets, Airtable, Notion ou CSV pour un usage interne sécurisé.
- Planification et automatisation. Configurez des extractions récurrentes à intervalles responsables.
- Prise en charge multilingue. L’interface de Thunderbit prend en charge 34 langues, rendant la conformité accessible dans le monde entier.
- Mises à jour régulières des modèles. Nos modèles instantanés pour les sites populaires sont tenus à jour selon les évolutions juridiques et techniques.
En intégrant la conformité au cœur du produit, Thunderbit aide les équipes à collecter les données dont elles ont besoin — sans prise de tête juridique.
Garder une longueur d’avance : s’adapter aux évolutions juridiques et techniques du web scraping
Découvrir plus de guides sur le web scraping Get Started Free
Le web scraping n’est pas un jeu où l’on lance une fois puis on oublie. Les lois et la structure des sites évoluent sans cesse. Voici comment garder une longueur d’avance :
- Surveillez les évolutions juridiques. Le rythme du changement s’est accéléré entre 2024 et 2026 — suivez l’actualité du droit des technologies, les mises à jour des régulateurs et les blogs spécialisés (comme celui de Thunderbit). Gardez un œil sur l’entrée en application du règlement européen sur l’IA (août 2026), sur les nouvelles lois d’État américaines sur la vie privée et sur les contentieux en cours liés au droit d’auteur sur l’IA.
- Adaptez-vous aux changements techniques. Les sites mettent constamment à jour leurs interfaces et leurs défenses anti-bots. Les grandes plateformes (Amazon, X, Google) ont considérablement renforcé leurs protections en 2025–2026. L’IA et les modèles de Thunderbit sont conçus pour s’adapter automatiquement.
- Adoptez les API officielles lorsqu’elles existent. Si un site passe à un modèle d’API payante, envisagez de l’utiliser pour des raisons de fiabilité et de conformité.
- Auditez régulièrement votre scraping. Documentez vos sources, vérifiez les modifications des ToS ou des politiques, et ajustez votre stratégie au besoin.
- Profitez des mises à jour de modèles de Thunderbit. Notre équipe maintient les modèles à jour, afin que vous n’ayez pas à vous soucier des changements cassants ni des nouvelles exigences de conformité.
- Restez flexible. Si une source de données devient trop risquée, pivotez vers une autre ou cherchez un partenariat.
Avec les bons outils et le bon état d’esprit, vous pouvez garder votre pipeline de données en marche — sans marcher sur des mines juridiques.
Conclusion : naviguer dans le paysage juridique du web scraping
Le web scraping n’est pas intrinsèquement illégal — c’est un outil puissant pour le business, la recherche et l’innovation. Mais comme tout outil, il comporte des règles. L’essentiel est de comprendre ce que vous scrapez, comment vous le scrapez et ce que vous ferez des données. Respectez les lois locales, suivez les politiques des sites et utilisez des outils axés sur la conformité comme Thunderbit pour garder vos opérations dans les clous.
Les décisions de justice de 2024–2026 (Meta v. Bright Data, X Corp v. Bright Data) ont renforcé la position en faveur du scraping de données publiques, mais de nouveaux risques apparaissent autour des données d’entraînement de l’IA, des revendications de droit d’auteur et du règlement européen sur l’IA. Les politiques varient fortement selon les plateformes — Google, Amazon, LinkedIn, Meta et X appliquent tous leurs règles différemment — alors connaissez le terrain avant de scraper.
En cas de doute, demandez un avis juridique — surtout pour les projets importants ou sensibles. Et n’oubliez pas : le paysage juridique change en permanence, alors restez informé et agile.
Vous voulez en savoir plus sur le web scraping, la conformité et l’automatisation ? Consultez le blog Thunderbit pour davantage de guides, ou essayez vous-même l’extension Chrome de Thunderbit.
Commencez un web scraping conforme avec Thunderbit
FAQ
1. Le web scraping est-il illégal partout ?
Non. Le web scraping n’est pas illégal par nature, mais sa légalité dépend de ce que vous scrapez, de la manière dont vous le faites et de votre localisation. Le scraping de données publiques non personnelles pour un usage interne est généralement autorisé dans la plupart des régions, mais le scraping de données personnelles ou protégées par le droit d’auteur, ou la violation des conditions du site, peut être illégal (oxylabs.io).
2. Robots.txt rend-il le scraping illégal si je l’ignore ?
Robots.txt n’est pas juridiquement contraignant, mais il est préférable de le respecter. L’ignorer ne suffit pas, à lui seul, pour être poursuivi, mais cela peut vous faire passer pour un « mauvais acteur » en cas de litige (promptcloud.com).
3. Puis-je scraper Google, Amazon ou LinkedIn ?
C’est compliqué. Les trois interdisent le scraping dans leurs ToS, mais les tribunaux ont jugé que les ToS peuvent ne pas s’appliquer aux utilisateurs non connectés (voir Meta v. Bright Data et X Corp v. Bright Data, tous deux en 2024). Le scraping de données visibles publiquement (prix de produits, fiches d’entreprise, profils publics) est généralement défendable au regard du droit américain. Toutefois, chaque plateforme applique ses règles différemment : Amazon est la plus agressive sur le plan juridique (elle a poursuivi Perplexity AI en novembre 2025) ; LinkedIn s’appuie sur des barrières techniques et des actions contractuelles ; Google utilise de plus en plus le DMCA. Scrapez toujours de manière responsable et attendez-vous à des contre-mesures techniques.
4. Puis-je scraper Facebook ou Instagram ?
Après Meta v. Bright Data (2024), le scraping de données publiques sur Facebook et Instagram sans connexion repose sur une base juridique plus solide. Le tribunal a jugé que les ToS de Meta ne s’appliquent pas aux non-utilisateurs. Mais ne créez jamais de faux comptes et ne scrapez jamais des données derrière une connexion — ce serait franchir la ligne.
5. Puis-je scraper X (Twitter) ?
X a mis à jour ses ToS en 2023 pour interdire tout scraping sans consentement écrit et a déployé des défenses techniques agressives (Cloudflare Turnstile, limites de 300 requêtes/heure, score de réputation IP). Toutefois, Bright Data a gagné en justice sur des bases similaires — les données publiques scrapées sans compte ne sont pas liées par les ToS de X. Techniquement, X reste l’une des plateformes les plus difficiles à scraper en 2026.
6. Le scraping de données pour entraîner des modèles d’IA est-il légal ?
C’est la plus grande question ouverte en 2026. Les grands procès (NYT v. OpenAI, règlement de 1,5 milliard de dollars d’Anthropic) indiquent un risque juridique important. Le règlement européen sur l’IA exige la divulgation des sources des données d’entraînement et le respect des refus d’utilisation de copyright. Le projet AI Accountability for Publishers Act imposerait autorisation et rémunération. Si vous scrapez pour entraîner une IA, demandez un avis juridique avant d’avancer.
7. Quelle est la façon la plus sûre d’utiliser des outils de web scraping comme Thunderbit ?
Limitez-vous aux données publiques, respectez les conditions du site, évitez les informations personnelles sauf base légale, et utilisez les données en interne. Thunderbit est conçu pour vous aider à rester conforme en ne scrappant que ce qui est visible dans votre navigateur et en vous avertissant des sites risqués (thunderbit.com).
8. Puis-je scraper des données à des fins commerciales ?
Cela dépend. L’usage de données scrapées pour l’analyse interne ou la recherche est généralement plus sûr. Republier ou vendre des données scrapées, surtout si elles sont protégées par le droit d’auteur ou personnelles, est bien plus risqué et peut nécessiter une autorisation ou une licence.
9. Comment suivre les évolutions juridiques et techniques du web scraping ?
Suivez l’actualité du droit des technologies, surveillez les changements de ToS ou de politiques sur vos sites cibles et utilisez des outils comme Thunderbit qui mettent régulièrement à jour leurs modèles et leurs fonctions de conformité. À surveiller en 2026 : l’application du règlement européen sur l’IA (août), les contentieux en cours sur le droit d’auteur lié à l’IA, et les nouvelles lois d’État américaines sur la vie privée. En cas de doute, consultez un professionnel du droit.
Essayez AI Web Scraper Get Started Free




