Imagine un instant : on est en 2025, tu bois ton café du matin et tu veux checker si Walmart a enfin baissé le prix de ce téléviseur 65 pouces qui te fait rêver. Ou alors, tu gères une boutique en ligne et tu dois garder un œil sur les prix, le stock et les avis clients de Walmart, en temps réel. Aller vérifier chaque produit à la main, tous les jours ? C’est carrément un job à plein temps (et franchement, c’est pas la joie). Heureusement, avec un peu de Python et quelques bases d’extraction web, tu peux automatiser tout ça et accéder à une vraie mine d’or d’infos.
Après avoir passé des années à créer des outils d’automatisation et d’IA pour les pros, je peux te dire que le scraping walmart, c’est un peu le « cheat code » qui transforme des heures de surveillance en quelques lignes de code. Dans ce guide, je t’explique ce qu’est le scraping walmart, pourquoi c’est devenu indispensable pour les boîtes en 2025, et comment monter un extracteur walmart solide en Python — étape par étape, avec du code concret et des astuces de terrain. Prends ton café (ou ton snack préféré pour les sessions de débogage) et c’est parti !
C’est quoi le scraping walmart ? Les bases en 2025
Pour faire simple, scraping walmart veut dire extraire automatiquement des infos de produits, de prix ou d’avis depuis le site de Walmart grâce à un logiciel — souvent un script qui agit comme un navigateur super rapide. Plutôt que de copier-coller les infos à la main (personne n’aime ça !), tu écris un script Python qui va chercher les pages Walmart, extrait les données qui t’intéressent et les sauvegarde pour analyse.
Pourquoi Python ? Parce que c’est l’outil passe-partout pour l’extraction web : facile à lire, blindé de bibliothèques puissantes (Requests, BeautifulSoup, pandas…), et une communauté énorme pour partager des astuces et du code. Que tu sois solo ou dans une équipe business, Python rend le scraping walmart accessible — même sans être un développeur pro.
À noter : il y a une différence entre extraire walmart pour un usage perso (genre suivre le prix de quelques produits pour tes achats) et pour un usage pro (surveiller des milliers de références pour la veille concurrentielle). Plus tu montes en volume, plus ça devient technique — surtout que Walmart ne propose pas d’API publique pour ses produits en 2025 ().
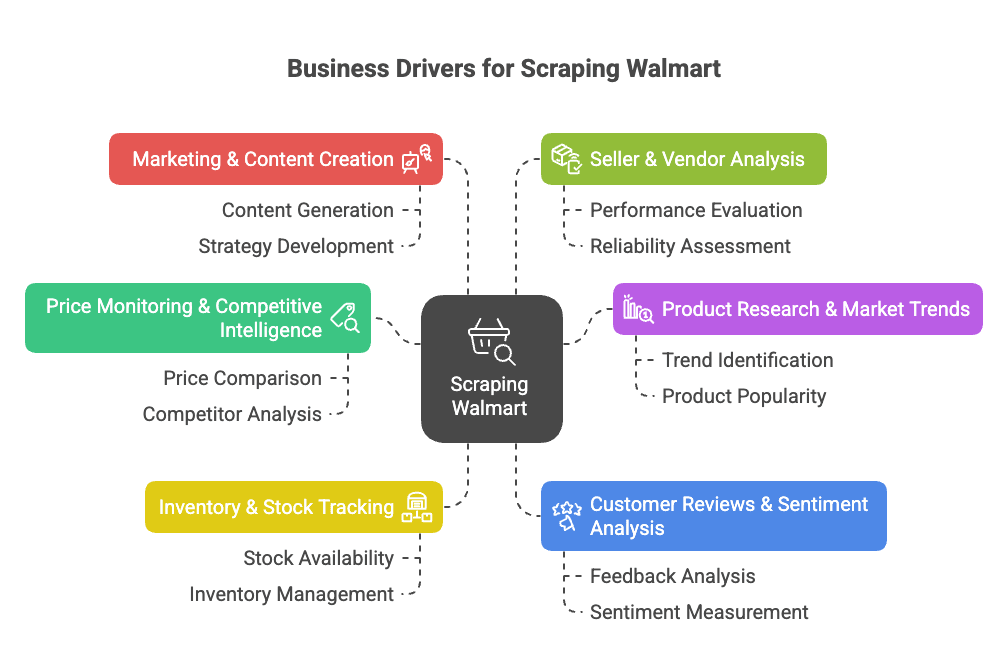
Pourquoi scraper Walmart ? Les vrais bénéfices business
Walmart, ce n’est plus juste le géant des supermarchés US : c’est aussi un mastodonte du digital, avec plus de et près de 18% de ses ventes sur Internet (). Autant dire qu’il y a de quoi analyser !
Pourquoi extraire walmart ? Voici les gros avantages business :
- Veille tarifaire & intelligence concurrentielle : Suis en direct les prix, promos et changements de catalogue de Walmart pour ajuster ta stratégie ().
- Étude de marché & tendances : Analyse l’assortiment, les caractéristiques et les tendances par catégorie pour repérer des opportunités ou des manques ().
- Suivi du stock : Surveille les ruptures ou les dispos pour optimiser ta logistique ou profiter des pénuries chez les concurrents ().
- Analyse des avis clients : Récupère et analyse les retours pour améliorer tes produits ou détecter les points de friction ().
- Marketing & création de contenu : Repère les produits « Meilleure vente », leur présentation et les contenus qui cartonnent ().
- Analyse des vendeurs : Identifie les meilleurs vendeurs tiers ou les listings non autorisés ().
Voici un tableau récap des cas d’usage, des bénéficiaires et des avantages :
| Cas d’usage | Pour qui ? | Bénéfices & ROI |
|---|---|---|
| Veille tarifaire | Équipes pricing & ventes | Prix concurrents en temps réel, pricing dynamique, protection des marges |
| Analyse d’assortiment & catalogue | Gestion produit, merchandising | Repérer les manques, lancer de nouveaux produits, enrichir le catalogue |
| Suivi des stocks | Opérations & logistique | Meilleure prévision, éviter les ruptures, optimiser la distribution |
| Avis clients & analyse de sentiment | Dév. produit, expérience client | Amélioration produit basée sur la data, satisfaction accrue |
| Tendances marché & analytics | Stratégie & études de marché | Détecter les tendances, orienter la stratégie, anticiper les segments |
| Stratégie contenu & prix | Marketing & e-commerce | Affiner les prix, s’inspirer des contenus performants |
| Suivi des vendeurs | Ventes & partenariats | Trouver des partenaires, protéger la marque, surveiller les vendeurs non autorisés |
En clair ? Le scraping walmart te fait gagner un temps fou, booste ton chiffre d’affaires et te donne un vrai avantage data. Au lieu de checker 50 pages à la main chaque matin, ton script peut extraire des milliers de fiches produits en quelques minutes ().
Le scraping walmart, c’est un vrai game changer pour les équipes e-commerce, ventes et études de marché. Avec les bons outils, tu automatises la collecte et tu te concentres sur l’analyse, pas sur la corvée.
Scraper Walmart avec Python : ce qu’il te faut
Avant de te lancer, prépare ton environnement Python. Voici la boîte à outils :
- Python 3.9+ (je conseille 3.11 ou 3.12 en 2025)
- Requests : pour récupérer les pages web
- BeautifulSoup (bs4) : pour analyser le HTML
- pandas : pour organiser et exporter les données
- json : pour manipuler les données JSON (déjà inclus)
- Un navigateur avec outils développeur : pour inspecter la structure des pages Walmart (F12, c’est ton pote)
- pip : pour installer les packages Python
Pour installer rapidement :
1pip install requests beautifulsoup4 pandasOptionnel : pour garder ton projet clean, crée un environnement virtuel :
1python3 -m venv walmart-scraper
2source walmart-scraper/bin/activate # Sur Mac/Linux
3# ou
4walmart-scraper\\Scripts\\activate.bat # Sur WindowsTeste ton install :
1import requests, bs4, pandas
2print("Bibliothèques chargées avec succès !")Si tu vois ce message, tout roule.
Étape 1 : Préparer ton extracteur walmart en Python
Organise-toi :
- Crée un dossier projet (ex :
walmart_scraper/). - Ouvre ton éditeur de code (VSCode, PyCharm, ou même Notepad++ — on ne juge pas).
- Démarre un nouveau script (ex :
walmart_scraper.py).
Voici le modèle de base :
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4import jsonTu es prêt pour la suite : récupérer les pages produits Walmart.
Étape 2 : Récupérer les pages produits Walmart avec Python
Pour extraire walmart, il faut d’abord choper le HTML d’une fiche produit. Mais attention : Walmart n’aime pas trop les robots. Si tu fais un simple requests.get(url), tu risques de tomber sur un challenge « Robot ou humain ? » direct.
L’astuce ? Faire croire que tu es un vrai navigateur. Il faut donc ajouter des headers comme User-Agent et Accept-Language pour ressembler à Chrome ou Firefox.
Exemple :
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
3 "Accept-Language": "fr-FR,fr;q=0.9"
4}
5response = requests.get(url, headers=headers)
6html = response.textAstuce pro : Utilise un requests.Session() pour garder les cookies et passer encore plus pour un humain :
1session = requests.Session()
2session.headers.update(headers)
3session.get("<https://www.walmart.com/>") # Va sur la page d’accueil pour poser les cookies
4response = session.get(product_url)Vérifie toujours response.status_code (doit être 200). Si tu tombes sur une page bizarre ou un CAPTCHA, ralentis, change d’IP ou fais une pause. Les protections anti-bot de Walmart sont coriaces ().
Gérer les protections anti-bot de Walmart
Walmart utilise des solutions comme Akamai et PerimeterX pour repérer les robots via ton IP, tes headers, cookies, et même l’empreinte TLS. Pour passer sous le radar :
- Mets toujours des headers réalistes (voir plus haut).
- Espace tes requêtes — attends 3 à 6 secondes entre chaque page.
- Varie les délais pour ne pas ressembler à un robot sous Red Bull.
- Utilise des proxies si tu extrais à grande échelle (on en reparle plus loin).
- Si tu tombes sur un CAPTCHA, fais une pause — n’essaie pas de forcer.
Pour aller plus loin, des bibliothèques comme curl_cffi rendent tes requêtes Python encore plus proches de celles d’un navigateur (). Mais dans la plupart des cas, headers et patience suffisent.
Étape 3 : Extraire les données produits Walmart avec BeautifulSoup
Place à l’extraction : repère les infos qui t’intéressent. Le site de Walmart est fait avec Next.js, donc la plupart des données produits sont cachées dans une balise <script id="__NEXT_DATA__"> sous forme de gros JSON.
Voici comment les récupérer :
1from bs4 import BeautifulSoup
2import json
3soup = BeautifulSoup(html, "html.parser")
4script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
5if script_tag:
6 json_text = script_tag.string
7 data = json.loads(json_text)Tu obtiens alors un dictionnaire Python avec toutes les infos du produit. Pour une fiche classique, les détails sont là :
1product_data = data["props"]["pageProps"]["initialData"]["data"]["product"]Ensuite, tu extrais ce qu’il te faut :
1name = product_data.get("name")
2price_info = product_data.get("price", {})
3current_price = price_info.get("price")
4currency = price_info.get("currency")
5rating_info = product_data.get("rating", {})
6average_rating = rating_info.get("averageRating")
7review_count = rating_info.get("numberOfReviews")
8description = product_data.get("shortDescription") or product_data.get("description")Pourquoi passer par le JSON ? Parce que c’est structuré, stable, et moins sensible aux changements d’HTML. Tu récupères souvent plus d’infos que ce qui s’affiche sur la page ().
Gérer le contenu dynamique et les données JSON
Parfois, les avis ou le stock sont chargés dynamiquement via JavaScript ou des appels API. Bonne nouvelle : le JSON initial contient souvent un snapshot suffisant. Sinon, va dans l’onglet Réseau des outils développeur pour repérer les endpoints API utilisés par Walmart et imite-les.
Mais pour la plupart des données produits, le JSON __NEXT_DATA__ est ton meilleur allié.
Étape 4 : Sauvegarder et exporter les données Walmart
Une fois les données extraites, sauvegarde-les dans un format structuré — CSV, Excel ou JSON. Exemple avec pandas :
1import pandas as pd
2product_record = {
3 "Nom du produit": name,
4 "Prix (USD)": current_price,
5 "Note": average_rating,
6 "Nombre d’avis": review_count,
7 "Description": description
8}
9df = pd.DataFrame([product_record])
10df.to_csv("walmart_products.csv", index=False)Si tu extrais plusieurs produits, ajoute chaque fiche à une liste puis crée le DataFrame à la fin.
Pour Excel : df.to_excel("walmart_products.xlsx", index=False) (pense à installer openpyxl). Pour JSON : df.to_json("walmart_products.json", orient="records", indent=2).
Astuce : Vérifie toujours un échantillon de tes exports pour éviter les mauvaises surprises (genre 1 000 prix « None » parce que Walmart a changé un nom de champ).
Étape 5 : Passer à l’échelle avec ton extracteur walmart
Prêt à extraire en masse ? Voici comment traiter plusieurs pages produits :
1product_urls = [
2 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
3 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
4 # ...plus d’URLs
5]
6all_records = []
7for url in product_urls:
8 resp = session.get(url)
9 # ...parse et extrais comme avant...
10 all_records.append(product_record)
11 time.sleep(random.uniform(3, 6)) # Sois cool avec les serveurs !Si tu n’as pas la liste d’URLs, pars d’une page de résultats de recherche, récupère les liens produits, puis extrais chaque fiche ().
Attention : Extraire des centaines ou milliers de pages trop vite = blocage assuré de ton IP. C’est là que les proxies entrent en jeu.
Utiliser des proxies et des APIs d’extraction pour Walmart
Les proxies te permettent de changer d’IP et d’éviter les blocages. Tu peux acheter des proxies résidentiels (qui ressemblent à de vrais utilisateurs) ou utiliser des pools de proxies. Exemple avec requests :
1proxies = {
2 "http": "<http://your.proxy.address>:port",
3 "https": "<https://your.proxy.address>:port"
4}
5response = session.get(url, proxies=proxies)Pour du scraping à grande échelle, pense à une API d’extraction : ces services gèrent les proxies, les CAPTCHAs et même le rendu JavaScript pour toi. Tu envoies une URL Walmart, ils te renvoient les données (parfois déjà en JSON).
Petit comparatif :
| Approche | Avantages | Inconvénients | Pour qui ? |
|---|---|---|---|
| Python DIY + proxies | Contrôle total, économique pour petits volumes | Maintenance, coût des proxies, risque de blocage | Développeurs, besoins sur-mesure |
| API d’extraction tierce | Facile, gère l’anti-bot, passe à l’échelle | Coût à grande échelle, moins flexible, dépendance | Utilisateurs business, gros volumes, résultats rapides |
Si tu n’es pas développeur ou que tu veux aller vite, des outils comme l’extension Chrome font tout ça en quelques clics — sans code, sans proxy, sans prise de tête. (On y revient juste après.)
Les défis courants du scraping walmart (et comment les surmonter)
Le scraping walmart, ce n’est pas que des promos et des prix cassés. Voici les principaux obstacles — et comment les contourner :
- Anti-bot agressif : Walmart repère les robots via IP, headers, cookies, empreinte TLS, JavaScript… Solution : headers réalistes, sessions, délais, proxies ().
- CAPTCHAs : Si tu en croises un, fais une pause et réessaie plus tard. Pour les cas récurrents, il existe des services de résolution de CAPTCHA, mais c’est plus complexe et coûteux ().
- Changements de structure du site : Walmart change souvent son site. Si ton script plante, réinspecte le JSON et adapte ton code. Un code modulaire, ça aide beaucoup.
- Pagination & sous-pages : Pour beaucoup de données, il faut gérer la pagination. Utilise des boucles avec conditions d’arrêt, et vérifie si tu es arrivé au bout ().
- Volume de données & limites de débit : Pour de gros volumes, batch tes requêtes et sauvegarde au fur et à mesure. N’essaie pas de charger 100 000 produits en mémoire d’un coup.
- Questions légales & éthiques : Ne récupère que les données publiques, respecte les conditions d’utilisation de Walmart et n’inonde pas leurs serveurs. Si ton business dépend de ces données, vérifie la conformité.
Quand passer à une solution gérée ? Si tu passes plus de temps à contourner les CAPTCHAs qu’à analyser tes données, il est temps d’utiliser un outil comme Thunderbit ou une API d’extraction. Pour les non-développeurs, les outils no-code sont souvent le meilleur choix ().
Scraper Walmart avec Python : exemple de code complet
Voici un script Python complet et commenté pour extraire des fiches produits Walmart :
1import requests
2from bs4 import BeautifulSoup
3import json
4import pandas as pd
5import time
6import random
7# Initialisation de la session et des headers
8session = requests.Session()
9session.headers.update({
10 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
11 "Accept-Language": "fr-FR,fr;q=0.9"
12})
13# Visite de la page d’accueil pour poser les cookies
14session.get("<https://www.walmart.com/>")
15# Liste des URLs produits à scraper
16product_urls = [
17 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
18 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
19 # Ajoute d’autres