
Si vous avez besoin de données web en 2026, la vraie question n’est plus « peut-on les extraire ? », mais plutôt « quelle couche d’outils me permet d’obtenir des données exploitables avec le moins de configuration, de maintenance et de coûts d’infrastructure ? » C’est pourquoi cette page est organisée d’abord selon l’usage : des extracteurs Web IA pour aller vite, des outils no-code pour les tâches répétables dans le navigateur, des API pour l’échelle et la gestion anti-bot, et des bibliothèques Python pour les équipes qui veulent garder la main sur tout.
Réponse rapide
- Choisissez un extracteur Web IA si vous voulez passer le plus vite possible d’une page à un tableur, avec un minimum de configuration.
- Choisissez un scraper no-code si vous avez besoin de pagination plus explicite, de planification, de gestion des connexions ou d’un contrôle répétable des tâches.
- Choisissez une API de scraping si le rendu des pages, la protection anti-bot, la concurrence et le taux de déblocage comptent plus que la simplicité de l’interface.
- Choisissez une bibliothèque Python si votre équipe veut garder la main sur les requêtes, l’analyse, l’automatisation du navigateur, les tentatives de retry et le déploiement.
Pour la plupart des équipes métier, l’erreur consiste à descendre trop tôt dans la pile technique. Commencez avec l’outil le plus léger capable de faire le travail correctement, puis passez de l’IA au no-code, aux API, puis au code uniquement quand votre flux de travail vous y oblige.
Téléchargez ici le pack visuel complet : .
Tableau comparatif rapide : les outils de scraping de sites web en un coup d’œil
Les indications tarifaires ci-dessous ont été vérifiées sur les pages officielles de produit, de tarification ou de documentation le 12 mai 2026. Lorsque les fournisseurs utilisent une facturation personnalisée ou à l’usage, je décris le modèle tarifaire au lieu d’inventer un faux tarif mensuel comparable.
| Outil | Catégorie | Idéal pour | Pourquoi il figure dans cette liste 2026 | Indication de prix (vérifiée en mai 2026) |
|---|---|---|---|---|
| Thunderbit | Extracteur Web IA | Ventes, opérations, e-commerce, immobilier | Le moyen le plus rapide, sans technique, de passer d’une page web à un tableau structuré | Offre gratuite, formules payantes, tarification entreprise |
| Kadoa | Plateforme d’extraction IA | Équipes data et grands programmes récurrents | Très adaptée aux flux d’extraction auto-réparants de type agent | Évaluation gratuite, forfaits à l’usage et entreprise |
| Octoparse | Scraper no-code | Analystes et tâches opérationnelles récurrentes | Scraping cloud mature et générateur de tâches visuel | Offre gratuite, Standard à partir de 69 $/mois, niveaux supérieurs |
| ParseHub | Scraper low-code | Non-développeurs techniques et chercheurs | Logique de navigation flexible pour les sites difficiles | Offre gratuite, forfaits payants à partir de 189 $/mois |
| Web Scraper | Scraper no-code dans le navigateur | Débutants et petits travaux répétables | Modèle de sitemap simple avec couche cloud en option | Extension gratuite, Cloud à partir de 50 $/mois |
| Browse AI | Robot scraper no-code | Surveillance et équipes orientées tableurs | Très efficace pour le suivi répétable et les alertes de changement | Offre gratuite, forfaits payants, formule gérée |
| Bardeen | Automatisation de navigateur IA | Automatisation GTM et revops | Excellent quand le scraping n’est qu’une étape d’un flux plus large | Offre gratuite, Basic à partir de 10 $/mois, Premium et Enterprise |
| ScrapeStorm | Scraper visuel assisté par IA | Utilisateurs qui veulent une configuration visuelle rapide | Bon compromis entre sélecteurs manuels et aide de l’IA | Essai gratuit, forfaits payants, tarification entreprise |
| ScraperAPI | API de scraping | Développeurs qui montent en volume de requêtes | API simple avec proxy, CAPTCHA et gestion du rendu en arrière-plan | Essai de 7 jours, payant à partir de 49 $/mois |
| Bright Data Web Scraper | Plateforme de scraping entreprise | Programmes lourds en achats et axés conformité | La pile de collecte de données la plus complète du groupe | Tarification par produit et à l’usage |
| Zyte | API + pile anti-bot | Développeurs et équipes data | Actions navigateur solides, rendu JS et rotation d’IP | Crédit d’essai de 5 $, forfaits à l’usage |
| ZenRows | API de scraping | Startups et équipes de développement | API anti-bot propre, avec adoption plus simple | Essai gratuit, Developer à partir de 69 $/mois |
| ScrapingBee | API de scraping | Équipes qui extraient des sites très chargés en JS | Utile quand le rendu est le principal point de friction | Essai gratuit, payant à partir de 49 $/mois |
| Selenium | Automatisation de navigateur open source | Flux de type QA et scraping avec forte interaction | Toujours pertinent quand l’interaction utilisateur exacte compte | Gratuit et open source |
| Beautiful Soup | Bibliothèque Python d’analyse | Scraping Python léger | Le parseur le plus simple de la pile pour du HTML désordonné | Gratuit et open source |
| Playwright | Automatisation de navigateur moderne | Applications web modernes et équipes de développement | Le meilleur choix moderne pour le scraping navigateur scripté | Gratuit et open source |
| urllib3 | Bibliothèque HTTP Python | Développeurs qui veulent un contrôle bas niveau des requêtes | Base utile quand vous voulez maîtriser directement le transport | Gratuit et open source |
Comment choisir le bon outil de scraping de sites web
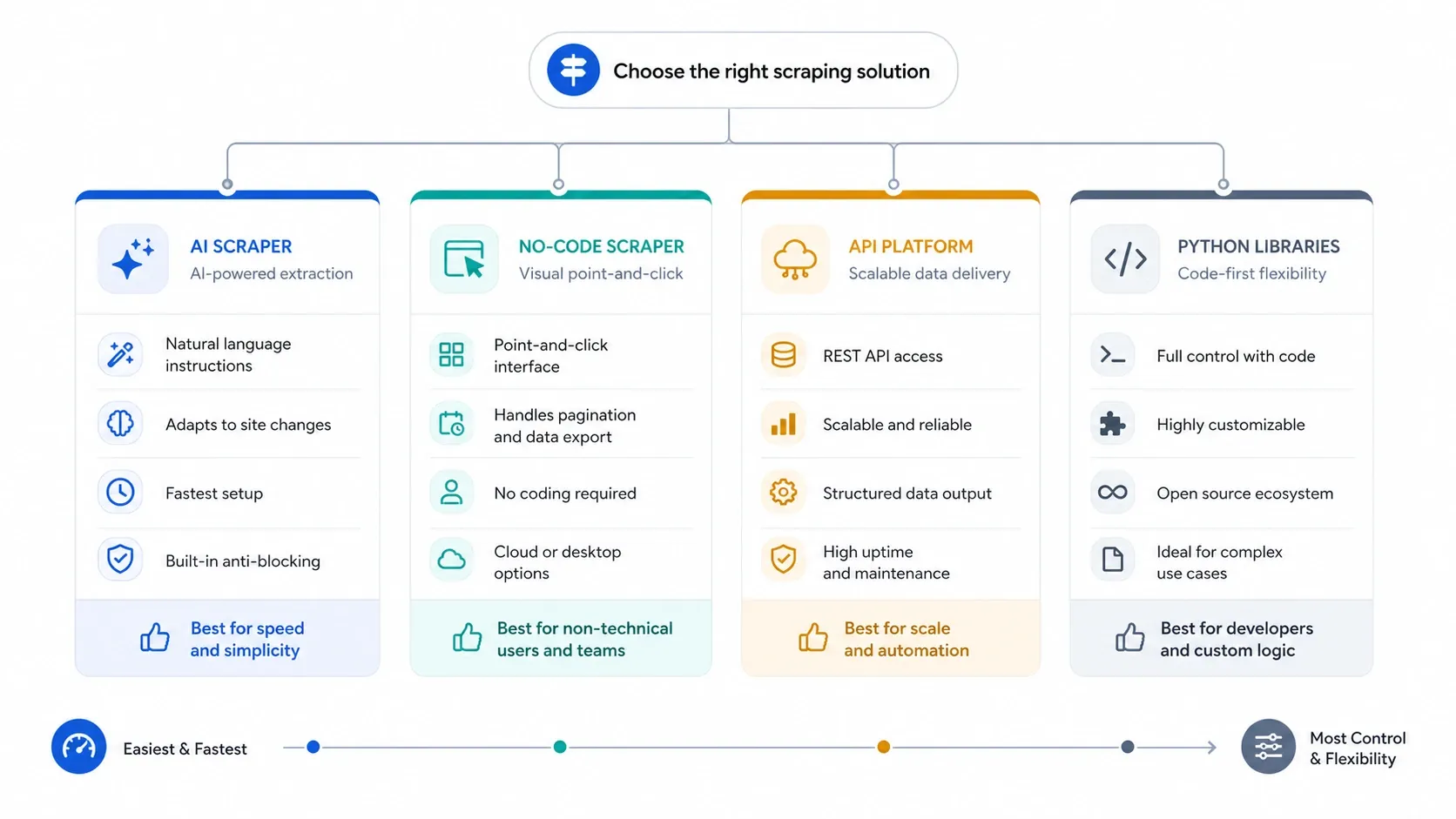
Utilisez quatre filtres avant de comparer les marques :
- Temps avant le premier résultat utile
Si l’outil ne peut pas produire rapidement un vrai tableau, il est déjà perdant dans la plupart des cas métier. - Charge de maintenance
Un scraper bon marché qui casse à chaque changement de mise en page n’est pas vraiment bon marché. - Plafond de montée en charge
Une extension de navigateur peut être parfaite pour 50 pages par semaine et catastrophique pour 5 millions de requêtes mensuelles. - Adéquation au flux de travail
Le meilleur scraper pour la revops est rarement le meilleur pour un ingénieur plateforme.
Le cadre de décision est généralement plus simple que ce que les équipes imaginent :
- Si vous voulez extraire des leads, des annonces ou des fiches produit sans toucher aux sélecteurs, commencez par l’IA.
- Si vous avez besoin de tâches répétables, d’exécutions cloud et d’un contrôle plus explicite, passez aux générateurs visuels no-code.
- Si l’anti-bot, le rendu JavaScript et la concurrence sont le vrai problème, passez directement aux API.
- Si vous voulez tout maîtriser vous-même, utilisez des bibliothèques Python et acceptez la charge de maintenance.
Meilleurs extracteurs Web IA pour des workflows métier rapides
C’est la première catégorie que je testerais si le résultat recherché est une donnée prête pour un tableur, avec le moins de configuration possible.
1. Thunderbit
Thunderbit reste ici le point de départ le plus simple pour les non-codeurs. Son principal atout n’est pas seulement « l’IA » en soi ; c’est surtout sa capacité à réduire le temps de configuration. Vous ouvrez une page, vous demandez à l’IA de suggérer des champs, vous enrichissez via des sous-pages si nécessaire, puis vous envoyez le résultat directement vers les outils déjà utilisés par votre équipe.
- Idéal pour : prospection commerciale, suivi e-commerce, collecte immobilière et équipes opérationnelles qui vivent dans le navigateur.
- Pourquoi il se démarque : le chemin le plus rapide d’une page désordonnée à un tableau structuré.
- À surveiller : si vous avez besoin d’une logique de niveau crawler ou de flux d’ingénierie très personnalisés, vous finirez probablement par passer aux API ou au code.
- Indication de prix : offre gratuite, formules payantes en self-service et tarification entreprise.
Ce tutoriel reste le moyen le plus rapide de juger si le scraping piloté par l’IA suffit à votre flux de travail :
2. Kadoa
Kadoa est l’option IA la plus orientée infrastructure dans ce groupe. Elle prend tout son sens lorsque vous voulez une extraction auto-réparante et des tâches récurrentes à une échelle opérationnelle plus importante que celle que la plupart des extensions de navigateur peuvent gérer.
- Idéal pour : équipes data, programmes d’intelligence interne et charges d’extraction récurrentes plus importantes.
- Pourquoi il se démarque : orchestration de type agent et discours plus solide autour de la réduction de maintenance.
- À surveiller : il est plus lourd que ce dont la plupart des utilisateurs métier ont besoin pour un scraping ponctuel rapide.
- Indication de prix : évaluation gratuite, forfaits à l’usage et entreprise.
Meilleurs outils de scraping de sites web no-code pour les tâches répétables
Dès que la tâche de scraping devient récurrente, les générateurs visuels de flux et l’exécution cloud comptent davantage que la simple vitesse en un clic.
3. Octoparse
Octoparse reste l’un des outils no-code les plus crédibles lorsque la tâche est plus importante qu’une extension de navigateur, sans être encore un projet d’ingénierie sur mesure. Sa valeur vient de la combinaison des exécutions cloud, des modèles et d’un générateur de tâches visuel mature.
- Idéal pour : analystes, équipes pricing et tâches récurrentes de collecte ayant un vrai enjeu opérationnel.
- Pourquoi il se démarque : plus de profondeur que les plugins de navigateur, sans vous forcer à coder.
- À surveiller : cette flexibilité se paie par une courbe d’apprentissage plus raide que celle des outils centrés IA.
- Indication de prix : offre gratuite, Standard à partir de 69 $/mois, niveaux payants supérieurs.
Si vous souhaitez évaluer un espace de travail no-code plus traditionnel avant d’investir dans un outil centré IA, cet aperçu officiel d’Octoparse reste utile :
4. ParseHub
ParseHub reste pertinent, car de nombreuses équipes veulent une logique de tâches plus étape par étape que ce qu’offre un extracteur Web IA léger. Ce n’est pas le produit le plus séduisant de la catégorie, mais il demeure flexible.
- Idéal pour : chercheurs, journalistes et non-développeurs techniques prêts à consacrer plus de temps à la configuration.
- Pourquoi il se démarque : une logique conditionnelle et un contrôle de navigation plus solides que ceux de nombreux outils pour débutants.
- À surveiller : plus lent à prendre en main et moins moderne que les entrants récents.
- Indication de prix : offre gratuite, forfaits payants à partir de 189 $/mois.
5. Web Scraper
Web Scraper est l’une des options les plus claires pour apprendre les bases sans acheter une plateforme complète. Si vous aimez le modèle de sitemap, c’est encore une bonne porte d’entrée.
- Idéal pour : débutants, projets personnels et petits travaux pilotés par navigateur.
- Pourquoi il se démarque : configuration simple et passage facile de l’extension locale aux offres cloud.
- À surveiller : il devient limitant dès que vous avez besoin d’une logique plus adaptative ou d’une meilleure gestion du blocage.
- Indication de prix : extension gratuite, Cloud à partir de 50 $/mois.
6. Browse AI
Browse AI reste un très bon choix lorsque le scraping et la surveillance comptent à parts égales. Son modèle de robot est intuitif pour les utilisateurs métier qui pensent en termes de « surveillez cette page et dites-moi ce qui a changé ».
- Idéal pour : veille concurrentielle, suivi des prix et équipes orientées tableurs.
- Pourquoi il se démarque : onboarding soigné, surveillance récurrente et sorties faciles à automatiser.
- À surveiller : les tâches complexes à grand volume peuvent coûter plus vite que les piles centrées API.
- Indication de prix : offre gratuite, forfaits payants, formule gérée.
Pour les équipes qui évaluent la surveillance de pages plutôt qu’une extraction ponctuelle, cet aperçu officiel court reste un bon signal :
7. Bardeen
Bardeen est moins centré sur la profondeur pure du scraping et davantage sur ce qui se passe après l’extraction. Il est particulièrement fort lorsque l’extraction web n’est qu’une étape d’un flux plus large d’automatisation du navigateur.
- Idéal pour : opérations GTM, routage des leads, transfert vers CRM et automatisation native du navigateur.
- Pourquoi il se démarque : un solide discours d’automatisation autour du flux lui-même.
- À surveiller : ce n’est pas le choix le plus propre lorsque seule la précision de l’extraction compte.
- Indication de prix : offre gratuite, Basic à partir de 10 $/mois, niveaux Premium et Enterprise.
8. ScrapeStorm
ScrapeStorm occupe encore un juste milieu utile pour les utilisateurs qui veulent une assistance IA mais attendent aussi un environnement de scraping visuel plus traditionnel.
- Idéal pour : scraping d’annuaires, collecte de pages e-commerce et tâches récurrentes configurées visuellement.
- Pourquoi il se démarque : plus simple à démarrer que de nombreux outils visuels plus anciens.
- À surveiller : il est moins poli que les leaders de la catégorie et peut sembler plus limité sur les sites difficiles.
- Indication de prix : essai gratuit, forfaits payants, tarification entreprise.

Meilleures API de scraping quand l’échelle et l’anti-bot comptent
C’est la catégorie vers laquelle il faut se tourner lorsque la vraie contrainte n’est plus « comment sélectionner les données ? » mais « comment garder cette solution fiable sous charge ? »
9. ScraperAPI
ScraperAPI reste l’un des produits API-first les plus accessibles pour les développeurs qui veulent arrêter de penser aux proxies et aux taux de réussite des requêtes.
- Idéal pour : développeurs qui doivent passer rapidement du prototype à la production.
- Pourquoi il se démarque : API simple, avec prise en charge des proxies, des CAPTCHA et du rendu.
- À surveiller : vous gardez la responsabilité de l’analyse, des retries et de la qualité des données en aval.
- Indication de prix : essai de 7 jours, payant à partir de 49 $/mois.
10. Bright Data Web Scraper
Bright Data est le choix lourd lorsque la capacité de déblocage, l’inventaire de proxies, la posture de conformité et les options gérées comptent plus que la simplicité.
- Idéal pour : collecte à l’échelle entreprise et programmes sensibles à la conformité.
- Pourquoi il se démarque : la pile la plus large de cette comparaison, des proxies aux produits de collecte gérés.
- À surveiller : il est facile d’acheter trop grand si votre équipe a encore un flux de travail relativement simple.
- Indication de prix : tarification par produit et à l’usage.
11. Zyte
Zyte reste une option sérieuse pour les équipes de développement qui veulent des actions navigateur, le rendu JavaScript, la rotation d’IP et une posture anti-bot réunis dans une même plateforme.
- Idéal pour : programmes de scraping pilotés par l’ingénierie et systèmes d’extraction répétables.
- Pourquoi il se démarque : solide pile anti-détection et workflows API-first.
- À surveiller : mieux adapté aux équipes disposant d’une maîtrise technique qu’aux utilisateurs métier.
- Indication de prix : crédit d’essai de 5 $, forfaits à l’usage.
12. ZenRows
ZenRows offre l’une des expériences développeur les plus propres dans la catégorie API si vous voulez gérer l’anti-bot sans processus d’achat de type entreprise.
- Idéal pour : startups, développeurs et équipes internes légères.
- Pourquoi il se démarque : adoption relativement sans friction et positionnement anti-bot fort.
- À surveiller : cela reste un produit API, donc vous conservez la logique applicative et la charge de QA.
- Indication de prix : essai gratuit, Developer à partir de 69 $/mois.
13. ScrapingBee
ScrapingBee a du sens lorsque votre besoin réel est une page rendue, avec moins de travail d’infrastructure, en particulier pour les sites très chargés en JS.
- Idéal pour : développeurs qui extraient des sites dynamiques et veulent déléguer le rendu.
- Pourquoi il se démarque : API simple autour du navigateur sans interface et des proxies.
- À surveiller : il supprime le travail d’infrastructure, pas le besoin d’une bonne logique de scraping.
- Indication de prix : essai gratuit, payant à partir de 49 $/mois.
Meilleures bibliothèques Python de scraping web pour les piles sur mesure
Ce groupe reste la bonne réponse lorsque le contrôle compte plus que la commodité et que votre équipe est prête à assumer la maintenance.
14. Selenium
Selenium n’est pas l’outil navigateur le plus récent, mais il reste pertinent là où la fidélité de l’interaction utilisateur compte davantage que le débit brut de scraping.
- Idéal pour : flux à forte interaction, chevauchement avec la QA et sites où le comportement du navigateur est le défi principal.
- Pourquoi il se démarque : écosystème mature et large support des navigateurs.
- À surveiller : plus lourd et plus lent que les piles d’automatisation récentes pour de nombreuses charges de scraping.
- Indication de prix : gratuit et open source.
15. Beautiful Soup

Beautiful Soup reste le parseur le plus simple de la pile de scraping Python. Ce n’est pas une plateforme de scraping complète, mais cela reste le moyen le plus simple de transformer du HTML désordonné en structure exploitable.
- Idéal pour : tâches Python légères, pages HTML statiques et prototypes rapides.
- Pourquoi il se démarque : faible charge cognitive et analyse tolérante.
- À surveiller : associez-le à
requests, à une couche navigateur ou à un crawler ; seul, il ne fait qu’analyser. - Indication de prix : gratuit et open source.
16. Playwright
Playwright est ma recommandation moderne par défaut pour les équipes de développement qui ont besoin d’une automatisation navigateur robuste sur le web actuel.
- Idéal pour : sites très chargés en JavaScript, automatisation moderne du navigateur et équipes déjà à l’aise avec le code.
- Pourquoi il se démarque : excellents comportements d’attente, support multi-navigateurs et API propres.
- À surveiller : vous gardez la responsabilité de la concurrence, des sélecteurs, de l’infrastructure navigateur et de la validation des données.
- Indication de prix : gratuit et open source.
17. urllib3
urllib3 mérite sa place dans cette liste parce que certaines équipes veulent un contrôle direct du comportement du transport plutôt qu’une abstraction de niveau supérieur. Ce n’est pas un scraper pour débutants, mais c’est une bibliothèque de base utile quand vous construisez votre propre pile.
- Idéal pour : développeurs qui veulent un contrôle précis des retries, des proxies, des sessions et du comportement HTTP.
- Pourquoi il se démarque : léger, fiable et largement utilisé comme infrastructure.
- À surveiller : vous construisez vous-même la majeure partie de la pile.
- Indication de prix : gratuit et open source.
Outils de scraping de sites web gratuits à tester en premier
Si vous voulez tester avant d’acheter, les meilleurs points de départ gratuits de cette liste sont Thunderbit, Octoparse, ParseHub, Web Scraper, Browse AI, Bardeen, Selenium, Beautiful Soup, Playwright et urllib3. L’expérience gratuite suffit à comprendre quel type de scraper vous avez réellement besoin, ce qui est généralement plus important que de s’obséder dès le premier jour sur une liste parfaite de fonctionnalités.
Ma sélection par type d’équipe

- Équipes commerciales, opérations et e-commerce : commencez avec Thunderbit, puis comparez Browse AI si la surveillance compte davantage que l’enrichissement des sous-pages.
- Analystes et opérateurs récurrents en mode manuel : Octoparse en premier, puis ParseHub si vous avez besoin d’une logique de tâche plus personnalisée.
- Équipes d’automatisation GTM : Bardeen si l’extraction doit s’enchaîner directement vers le CRM, Sheets ou des workflows navigateur.
- Équipes de développement qui construisent des outils internes : ScraperAPI, ZenRows, Zyte ou Playwright selon le niveau de maîtrise de la pile que vous souhaitez.
- Programmes data d’entreprise : Bright Data et Zyte sont ici les conversations d’infrastructure les plus sérieuses, avec Kadoa comme alternative pilotée par l’IA lorsque la réduction de maintenance est l’objectif principal.
Quand descendre dans la pile technique
Utilisez cet itinéraire de montée en puissance :
- Restez sur des extracteurs Web IA jusqu’à atteindre des limites de répétabilité ou des cas limites.
- Passez aux générateurs no-code lorsque la planification, la pagination et l’exécution cloud comptent plus que la simplicité du clic unique.
- Passez aux API lorsque le taux de déblocage, le rendu et la concurrence deviennent le goulot d’étranglement.
- Passez aux bibliothèques Python lorsque l’abstraction du fournisseur coûte plus cher que le fait d’assumer vous-même l’ensemble du système.
La plupart des équipes font cela dans le mauvais ordre. Elles surconstruisent d’abord, puis réalisent plus tard qu’un outil plus léger aurait pu résoudre le vrai problème du workflow.
Conclusion
Le meilleur outil de scraping de sites web en 2026 n’est pas celui qui affiche la liste de fonctionnalités la plus longue. C’est celui qui transmet des données exactes au workflow suivant avec le moins de maintenance possible pour votre équipe. C’est pour cela que les outils centrés IA continuent de gagner chez les opérateurs, que les outils no-code restent précieux pour les tâches répétables dans le navigateur, que les API dominent quand l’échelle et le blocage deviennent déterminants, et que les bibliothèques Python conservent le contrôle de la partie la plus technique de la pile.
Si votre objectif est d’obtenir des données utiles cette semaine, commencez simplement. Si votre charge de travail vous indique déjà que le taux de déblocage, le rendu navigateur et le contrôle par l’ingénierie sont le vrai problème, descendez délibérément dans la pile plutôt que par habitude.
FAQ
1. Quel est le meilleur outil de scraping de sites web pour les utilisateurs non techniques en 2026 ?
Pour la plupart des équipes non techniques, des outils centrés IA comme Thunderbit et Browse AI restent la voie la plus rapide, car ils réduisent le temps de configuration, le travail sur les sélecteurs et la charge de maintenance.
2. Que dois-je choisir pour des sites très chargés en JavaScript ou protégés par anti-bot ?
C’est généralement là que ScraperAPI, Bright Data, Zyte, ZenRows, ScrapingBee, Playwright ou Selenium deviennent plus pertinents que les extensions de navigateur.
3. Les outils de scraping no-code sont-ils encore pertinents maintenant que les extracteurs IA sont meilleurs ?
Oui. Octoparse, ParseHub, Web Scraper et Browse AI restent importants lorsque vous avez besoin d’un contrôle plus explicite des tâches, d’exécutions récurrentes ou d’un débogage visible dans le navigateur.
4. Quels outils conviennent le mieux aux équipes de développement ?
ScraperAPI, Zyte, ZenRows, ScrapingBee, Playwright, Selenium, Beautiful Soup et urllib3 sont les choix les plus naturels lorsque l’ingénierie possède le workflow.
Lectures connexes