Le web déborde de données, mais il y a un hic : les collecter à la main est à peu près aussi passionnant que regarder la peinture sécher — et tout aussi peu productif. En 2025, les entreprises jonglent avec plus de contenu web que jamais, la quantité quotidienne moyenne de données web ingérées par une entreprise passant de 1,2 To en 2020 à 8 To en 2025 (). Que vous travailliez dans la vente, le marketing, l’e-commerce ou les opérations, le besoin de données web rapides, structurées et fiables n’est pas un simple « plus » : c’est une nécessité opérationnelle. Et soyons honnêtes : personne n’a le temps d’enchaîner les copier-coller à l’infini.
C’est pour cela que les outils de crawling de contenu ont explosé en popularité. Ces outils — des extensions Chrome dopées à l’IA aux plateformes de niveau entreprise — vous permettent d’automatiser tout le processus, en transformant des pages web en vrac en feuilles de calcul propres, en bases de données ou en tableaux de bord en temps réel. J’ai passé des années dans le SaaS et l’automatisation, et je peux vous le dire : le bon outil ne fait pas que gagner du temps, il peut transformer la façon dont votre équipe travaille. Alors, plongeons dans les 18 meilleurs outils de crawling de contenu pour un web scraping efficace en 2025, en mettant l’accent sur ce qui rend chacun unique, sur la manière dont ils répondent à différents besoins métier, et sur la façon de choisir celui qui convient le mieux à votre flux de travail.
Pourquoi les entreprises ont besoin des meilleurs outils de crawling de contenu
Si vous avez déjà essayé de constituer une liste de prospects, de surveiller les prix d’un concurrent ou de suivre le sentiment du marché à la main, vous savez à quelle vitesse la collecte manuelle de données vire au cauchemar. C’est lent, source d’erreurs, et au moment où vous avez terminé, vos données sont peut-être déjà obsolètes. C’est pourquoi plus de 70 % des entreprises ont adopté l’extraction web automatisée d’ici 2025, réduisant l’effort manuel d’environ 60 % ().
Les outils de crawling de contenu automatisent l’extraction de données structurées depuis des sites web, ce qui permet de :
- Alimenter votre CRM avec des prospects frais (fini le copier-coller depuis des annuaires)
- Surveiller en temps réel les prix et les niveaux de stock des concurrents
- Regrouper avis, actualités et mentions sur les réseaux sociaux pour en tirer des insights marketing
- Constituer des jeux de données personnalisés pour la recherche ou l’analyse
- Planifier des extractions récurrentes pour des rapports continus
Et le retour sur investissement est bien réel : les entreprises qui utilisent le web scraping ont déclaré avoir économisé collectivement plus de 500 millions de dollars entre 2020 et 2025, avec des gains d’efficacité opérationnelle de 20 à 40 % (). En bref ? Les outils de crawling de contenu libèrent votre équipe pour se concentrer sur la stratégie, et non sur les tâches fastidieuses.
Comment nous avons sélectionné les meilleurs outils de crawling de contenu
Tous les web scrapers ne se valent pas. Pour établir cette liste, j’ai examiné les outils du point de vue d’utilisateurs métiers réels — équipes commerciales, marketing, opérations et recherche qui ont besoin de résultats, pas de casse-tête. Voici ce qui comptait le plus :
- Facilité d’utilisation : des utilisateurs non techniques peuvent-ils démarrer rapidement ? Existe-t-il une interface point-and-click ou une assistance IA ?
- Automatisation et fonctionnalités : l’outil gère-t-il la pagination, les sous-pages, la planification et le contenu dynamique ? Peut-il s’exécuter dans le cloud pour gagner en vitesse et en échelle ?
- Export et intégration des données : pouvez-vous exporter vers Excel, CSV, Google Sheets, Airtable, Notion, ou vous connecter via API ?
- Évolutivité : convient-il à des besoins ponctuels ou à des projets massifs et continus ?
- Personnalisation : pouvez-vous ajuster la logique d’extraction, ajouter des champs personnalisés ou traiter des sites complexes ?
- Conformité et confidentialité : l’outil vous aide-t-il à rester du bon côté du RGPD, du CCPA et des conditions d’utilisation des sites ?
- Support et communauté : existe-t-il une documentation, un support ou une communauté d’utilisateurs pour vous aider à résoudre les problèmes ?
- Coût : existe-t-il une version gratuite ou un essai ? Le prix est-il adapté à votre volume et à votre budget ?
Et bien sûr, j’ai accordé une attention particulière à Thunderbit — l’outil que mon équipe et moi avons construit — parce que je suis sincèrement convaincu qu’il s’agit du moyen le plus simple pour les utilisateurs métiers de démarrer avec le web scraping propulsé par l’IA.
Les 18 meilleurs outils de crawling de contenu pour un web scraping efficace
Passons en revue le meilleur du meilleur, de la simplicité boostée par l’IA aux poids lourds pour développeurs, en passant par tout le reste.
1. Thunderbit
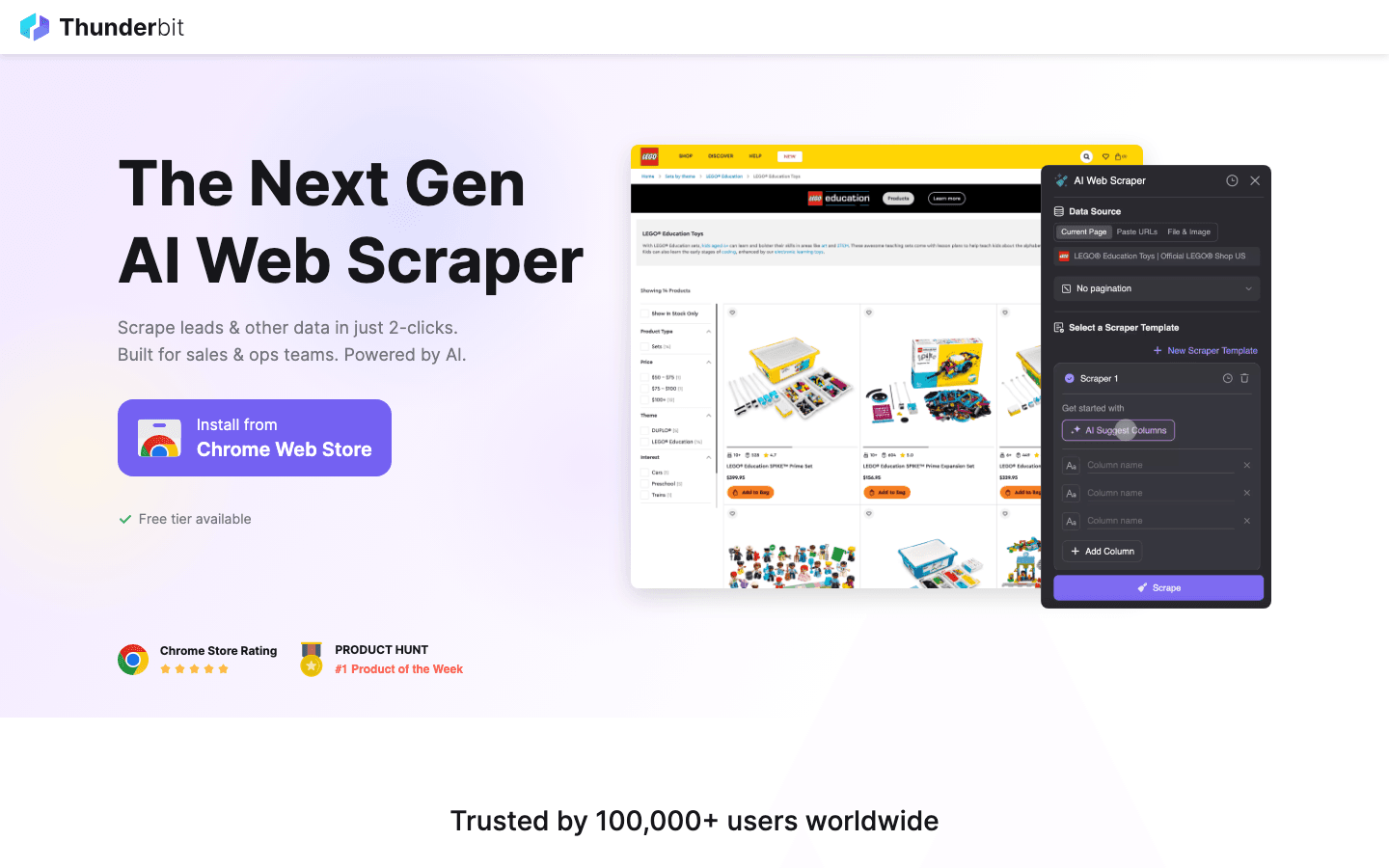 est une extension Chrome d’Extracteur Web IA conçue pour les utilisateurs métiers qui veulent des résultats — et vite. Sa fonctionnalité phare est AI Suggest Fields : visitez simplement une page web, cliquez sur « AI Suggest », et l’IA de Thunderbit lit la page, recommande les champs à extraire et configure le scraper pour vous. Pas de code, pas de réglages fastidieux de sélecteurs — il suffit de cliquer, extraire et exporter.
est une extension Chrome d’Extracteur Web IA conçue pour les utilisateurs métiers qui veulent des résultats — et vite. Sa fonctionnalité phare est AI Suggest Fields : visitez simplement une page web, cliquez sur « AI Suggest », et l’IA de Thunderbit lit la page, recommande les champs à extraire et configure le scraper pour vous. Pas de code, pas de réglages fastidieux de sélecteurs — il suffit de cliquer, extraire et exporter.
- Extraction de sous-pages : Thunderbit peut visiter automatiquement chaque sous-page (comme les détails produit ou profil) et enrichir votre jeu de données, ce qui est parfait pour la génération de leads ou la recherche e-commerce.
- Pagination et modèles : gère les listes multi-pages et propose des modèles instantanés pour des sites comme Amazon, Zillow et Instagram.
- Export gratuit des données : exportez vers Excel, Google Sheets, Airtable, Notion, CSV ou JSON — sans mur payant.
- AI Autofill : automatisez le remplissage de formulaires en ligne avec l’IA, en allant au-delà du scraping pour couvrir l’automatisation des workflows.
- Scraping cloud et navigateur : choisissez le scraping cloud rapide pour les sites publics ou le mode navigateur pour les sessions connectées.
- Tarifs : gratuit jusqu’à 6 pages (ou 10 avec un essai), avec des offres payantes à partir de seulement 15 $/mois.
Thunderbit est idéal pour les équipes commerciales, marketing et opérations qui veulent automatiser la collecte de données sans prise de tête technique. C’est l’outil que j’aurais aimé avoir il y a des années — aujourd’hui, n’importe qui peut constituer une liste de prospects ou surveiller ses concurrents en quelques minutes.
2. Scrapy
 est une référence open source pour les développeurs. C’est un framework basé sur Python qui vous permet d’écrire des spiders personnalisés pour crawler et extraire des données à grande échelle. Scrapy est conçu pour la vitesse et la flexibilité, avec prise en charge du crawling asynchrone, de pipelines personnalisés, de la rotation de proxies et de l’intégration avec des bases de données ou des API.
est une référence open source pour les développeurs. C’est un framework basé sur Python qui vous permet d’écrire des spiders personnalisés pour crawler et extraire des données à grande échelle. Scrapy est conçu pour la vitesse et la flexibilité, avec prise en charge du crawling asynchrone, de pipelines personnalisés, de la rotation de proxies et de l’intégration avec des bases de données ou des API.
- Idéal pour : développeurs et data engineers qui construisent des projets de scraping volumineux, complexes ou récurrents.
- Points forts : contrôle total, extensibilité, grande communauté et fiabilité éprouvée.
- Inconvénients : courbe d’apprentissage élevée pour les non-codeurs ; pas d’interface visuelle.
Si vous maîtrisez Python et que vous voulez créer des crawlers robustes et évolutifs, Scrapy est la référence.
3. Octoparse
 est un Extracteur Web sans code, basé sur le cloud, avec une interface visuelle en glisser-déposer. Vous pouvez sélectionner les données au point-and-click, configurer la pagination et même utiliser une détection de motifs assistée par l’IA pour accélérer la mise en place.
est un Extracteur Web sans code, basé sur le cloud, avec une interface visuelle en glisser-déposer. Vous pouvez sélectionner les données au point-and-click, configurer la pagination et même utiliser une détection de motifs assistée par l’IA pour accélérer la mise en place.
- Modèles prédéfinis : extrayez en quelques minutes des données de sites populaires comme Amazon, Twitter et Google Maps.
- Scraping cloud et planification : exécutez les tâches sur les serveurs d’Octoparse, planifiez des tâches récurrentes et gérez des projets à grande échelle.
- Options d’export : CSV, Excel, JSON, intégration API.
- Tarifs : offre gratuite limitée ; les formules payantes commencent autour de 75 $/mois.
Octoparse est idéal pour les analystes métiers et les non-programmeurs qui veulent un scraping puissant sans écrire de code.
4. ParseHub
 est un Extracteur Web visuel qui excelle dans la gestion du contenu dynamique et des structures de sites complexes. Son interface point-and-click vous permet de créer des workflows avec logique conditionnelle, boucles et navigation multi-niveaux.
est un Extracteur Web visuel qui excelle dans la gestion du contenu dynamique et des structures de sites complexes. Son interface point-and-click vous permet de créer des workflows avec logique conditionnelle, boucles et navigation multi-niveaux.
- Contenu dynamique : gère les menus déroulants, le défilement infini et les éléments interactifs.
- Exécutions cloud et locales : lancez les projets dans le cloud (payant) ou en local pour les tâches plus petites.
- Export : CSV, Excel, JSON, API.
- Tarifs : offre gratuite généreuse ; formules payantes à partir de 49 $/mois.
ParseHub est excellent pour les non-codeurs qui ont besoin de flexibilité et de puissance pour des sites web difficiles.
5. Data Miner
 est une extension Chrome/Edge pour un scraping rapide basé sur des modèles. Avec plus de 50 000 recettes d’extraction publiques pour plus de 15 000 sites web, vous pouvez souvent extraire une page en un clic.
est une extension Chrome/Edge pour un scraping rapide basé sur des modèles. Avec plus de 50 000 recettes d’extraction publiques pour plus de 15 000 sites web, vous pouvez souvent extraire une page en un clic.
- Intégration Google Sheets : envoyez les données extraites directement vers Sheets.
- Recettes personnalisées : créez votre propre logique d’extraction avec du point-and-click ou du XPath.
- Pagination et automatisation : gère le scraping multi-pages et les exécutions planifiées.
- Tarifs : offre gratuite ; formules payantes à partir de 19 $/mois.
Parfait pour les analystes et les marketeurs qui ont besoin d’extractions rapides de petite à moyenne envergure directement depuis le navigateur.
6. WebHarvy
 est une application de bureau Windows avec une interface point-and-click et une détection automatique de motifs. Il suffit de cliquer sur un élément, et WebHarvy met en évidence tous les éléments similaires à extraire.
est une application de bureau Windows avec une interface point-and-click et une détection automatique de motifs. Il suffit de cliquer sur un élément, et WebHarvy met en évidence tous les éléments similaires à extraire.
- Prise en charge des images, du texte et de la pagination : extrayez des photos de produits, des e-mails, des URLs et bien plus encore.
- Planification sur ordinateur : programmez des extractions sur votre PC.
- Licence à vie : environ 199 $ par PC.
Très bien pour les petites entreprises qui veulent un outil simple, sans abonnement, pour des extractions périodiques.
7. Import.io
 est une plateforme cloud de niveau entreprise pour l’extraction de données à grande échelle. Elle propose un nettoyage des données assisté par l’IA, une surveillance en temps réel et des fonctionnalités de conformité robustes.
est une plateforme cloud de niveau entreprise pour l’extraction de données à grande échelle. Elle propose un nettoyage des données assisté par l’IA, une surveillance en temps réel et des fonctionnalités de conformité robustes.
- Intégrations API : envoyez les données directement vers des bases de données, des tableaux de bord BI ou des applications.
- Conformité : conçue en tenant compte du RGPD et du CCPA.
- Tarifs : contrats entreprise ; positionnement haut de gamme.
Le meilleur choix pour les grandes organisations qui ont besoin de pipelines de données web fiables, conformes et évolutifs.
8. Apify
 est une plateforme d’automatisation cloud et une place de marché pour des « actors » de web scraping (bots). Utilisez des actors préconstruits pour des sites courants ou créez le vôtre en JavaScript ou en Python.
est une plateforme d’automatisation cloud et une place de marché pour des « actors » de web scraping (bots). Utilisez des actors préconstruits pour des sites courants ou créez le vôtre en JavaScript ou en Python.
- Place de marché : des centaines de scrapers prêts à l’emploi pour des sites comme LinkedIn, Amazon et bien d’autres.
- Planification et API : exécutez, planifiez et intégrez les actors via API.
- Tarifs : offre gratuite ; l’utilisation payante commence à 49 $/mois.
Idéal pour les développeurs et les équipes à l’aise avec la tech qui veulent de l’automatisation, de la flexibilité et des solutions portées par la communauté.
9. Visual Web Ripper
 est un outil de bureau destiné à l’extraction avancée de données en masse. Son constructeur de workflows vous permet de concevoir des crawls multi-niveaux et d’automatiser des projets à grande échelle.
est un outil de bureau destiné à l’extraction avancée de données en masse. Son constructeur de workflows vous permet de concevoir des crawls multi-niveaux et d’automatiser des projets à grande échelle.
- Planification et automatisation : exécutez les projets à intervalles définis.
- Intégration de bases de données : exportez directement vers SQL, Excel, CSV, XML ou JSON.
- Licence à vie : environ 349 $.
Très adapté aux équipes IT ou aux utilisateurs avancés qui doivent extraire de grands jeux de données en interne.
10. Dexi.io
 est une plateforme cloud pour les projets collaboratifs de données web. Elle propose l’automatisation des workflows, la planification et des fonctionnalités de gestion d’équipe.
est une plateforme cloud pour les projets collaboratifs de données web. Elle propose l’automatisation des workflows, la planification et des fonctionnalités de gestion d’équipe.
- Automatisation des workflows : créez et partagez des pipelines de données entre équipes.
- API et export : intégrez avec des bases de données, du stockage cloud ou des outils BI.
- Tarifs : personnalisés ; pensé pour les équipes et les entreprises.
Parfait pour les organisations qui gèrent des projets de données collaboratifs et continus.
11. Content Grabber
 est un outil de scraping professionnel destiné aux agences et aux entreprises. Il offre une automatisation avancée, la gestion des erreurs et même des options de marque blanche.
est un outil de scraping professionnel destiné aux agences et aux entreprises. Il offre une automatisation avancée, la gestion des erreurs et même des options de marque blanche.
- Scripting et personnalisation : utilisez C# ou VB.NET pour un contrôle approfondi.
- Récupération d’erreurs et journalisation : conçu pour la fiabilité sur les gros volumes.
- Tarifs entreprise : positionnement haut de gamme ; essai gratuit disponible.
Le meilleur choix pour les agences ou les entreprises qui construisent des solutions de scraping répétables et sur mesure pour leurs clients.
12. Helium Scraper
 est un outil de bureau qui combine extraction visuelle et flexibilité du scripting. Utilisez le point-and-click pour la plupart des tâches, ou passez au JavaScript personnalisé pour une logique avancée.
est un outil de bureau qui combine extraction visuelle et flexibilité du scripting. Utilisez le point-and-click pour la plupart des tâches, ou passez au JavaScript personnalisé pour une logique avancée.
- Gère le contenu dynamique : extrait des sites riches en AJAX.
- Nettoyage et transformation des données : scripting intégré pour des workflows personnalisés.
- Licence à vie : environ 99 $.
Parfait pour les utilisateurs avancés qui veulent de la flexibilité sans abonnement.
13. Web Scraper
 est une extension Chrome gratuite qui fait découvrir le web scraping à beaucoup de monde. Définissez un sitemap, cliquez pour sélectionner des éléments, puis exportez vers CSV ou JSON.
est une extension Chrome gratuite qui fait découvrir le web scraping à beaucoup de monde. Définissez un sitemap, cliquez pour sélectionner des éléments, puis exportez vers CSV ou JSON.
- Crawling multi-niveaux : suivez les liens, gérez la pagination et extrayez des données imbriquées.
- Gratuit en local : une version cloud payante est disponible pour la planification et le passage à l’échelle.
Idéal pour les débutants, les étudiants ou toute personne ayant besoin d’une solution rapide et gratuite pour de petites tâches.
14. Mozenda
 est une plateforme cloud d’entreprise axée sur la conformité, l’évolutivité et les services managés. Son interface point-and-click vous permet de créer des « agents » d’extraction de données.
est une plateforme cloud d’entreprise axée sur la conformité, l’évolutivité et les services managés. Son interface point-and-click vous permet de créer des « agents » d’extraction de données.
- Services managés : l’équipe de Mozenda peut créer et maintenir les scrapers pour vous.
- Conformité et support : forte attention portée au RGPD, au CCPA et aux besoins des entreprises.
- Tarifs : à partir d’environ 500 $/mois.
Le meilleur choix pour les grandes organisations qui veulent une solution clé en main, évolutive et bien accompagnée pour les données web.
15. SimpleIndex
 est un outil d’automatisation pour l’extraction de données documentaires et web, avec un accent sur l’OCR et l’indexation.
est un outil d’automatisation pour l’extraction de données documentaires et web, avec un accent sur l’OCR et l’indexation.
- OCR de screen scraping : extrayez des données depuis des documents scannés, des PDF ou même des formulaires web affichés à l’écran.
- Intégration : sortie vers des bases de données et des systèmes de gestion documentaire.
- Licence à vie : quelques centaines de dollars par poste de travail.
Excellent pour les organisations qui combinent des workflows documentaires et des données web.
16. Spinn3r
 est une plateforme de crawling de contenu en temps réel pour les blogs, les actualités et les réseaux sociaux. Son API Firehose fournit un flux continu de nouveaux contenus provenant de millions de sources.
est une plateforme de crawling de contenu en temps réel pour les blogs, les actualités et les réseaux sociaux. Son API Firehose fournit un flux continu de nouveaux contenus provenant de millions de sources.
- Filtrage du spam et traitement du langage : flux de données propres et structurés.
- Accès API : intégrez directement à vos systèmes.
- Tarification par abonnement : basée sur l’utilisation.
Le meilleur choix pour la veille média, l’agrégation d’actualités ou les équipes de recherche qui ont besoin de flux de contenu en temps réel.
17. FMiner
 est un constructeur visuel de workflows pour les crawls web complexes. Son interface en glisser-déposer vous permet de concevoir des routines d’extraction multi-niveaux et conditionnelles.
est un constructeur visuel de workflows pour les crawls web complexes. Son interface en glisser-déposer vous permet de concevoir des routines d’extraction multi-niveaux et conditionnelles.
- Scripting Python : insérez du code personnalisé pour une logique avancée.
- Multiplateforme : disponible pour Windows et Mac.
- Licence à vie : à partir d’environ 168 $.
Parfait pour les analystes ou les data scientists qui veulent modéliser visuellement des workflows sophistiqués.
18. G2 Webscraper
 (qui renvoie aux outils les mieux notés sur G2) est apprécié pour sa simplicité et son efficacité. Les utilisateurs adorent les outils gratuits, faciles et très économes en temps — comme l’extension Chrome Web Scraper ou Data Miner.
(qui renvoie aux outils les mieux notés sur G2) est apprécié pour sa simplicité et son efficacité. Les utilisateurs adorent les outils gratuits, faciles et très économes en temps — comme l’extension Chrome Web Scraper ou Data Miner.
- Excellents avis utilisateurs : très bonnes notes pour la facilité d’utilisation et la fiabilité.
- Mise en route rapide : courbe d’apprentissage minimale pour les tâches basiques à intermédiaires.
Si vous voulez un outil qui « fonctionne tout simplement » pour des extractions simples, les favoris des utilisateurs sur G2 constituent un choix sûr.
Tableau comparatif : aperçu des meilleurs outils de crawling de contenu
| Outil | Facilité d’utilisation | Automatisation et fonctionnalités | Formats d’export | Conformité et confidentialité | Tarifs | Idéal pour |
|---|---|---|---|---|---|---|
| Thunderbit | ⭐⭐⭐⭐⭐ | Champs IA, sous-pages, cloud | Excel, CSV, Sheets, Notion, Airtable, JSON | Guidé par l’utilisateur | Gratuit, à partir de 15 $/mois | Non-codeurs, ventes, opérations |
| Scrapy | ⭐ | Code complet, asynchrone, plugins | CSV, JSON, BD | Géré par l’utilisateur | Gratuit, open source | Développeurs, gros projets |
| Octoparse | ⭐⭐⭐⭐ | Visuel, modèles, cloud | CSV, Excel, JSON, API | Guidé par l’utilisateur | Gratuit, à partir de 75 $/mois | Analystes, e-commerce, non-codeurs |
| ParseHub | ⭐⭐⭐⭐ | Visuel, dynamique, cloud | CSV, Excel, JSON, API | Guidé par l’utilisateur | Gratuit, à partir de 49 $/mois | Non-codeurs, sites complexes |
| Data Miner | ⭐⭐⭐⭐⭐ | Modèles, navigateur, Sheets | CSV, Excel, Sheets | Guidé par l’utilisateur | Gratuit, à partir de 19 $/mois | Tâches rapides dans le navigateur |
| WebHarvy | ⭐⭐⭐⭐⭐ | Visuel, détection de motifs | Excel, CSV, XML, JSON | Guidé par l’utilisateur | 199 $ à vie | Utilisateurs Windows, petites entreprises |
| Import.io | ⭐⭐⭐⭐ | IA, cloud, surveillance | CSV, API, BD | RGPD, CCPA | Entreprise | Grandes organisations, conformité |
| Apify | ⭐⭐⭐ | Cloud, marketplace, API | JSON, API, Sheets | Géré par l’utilisateur | Gratuit, à partir de 49 $/mois | Dévs, automatisation, intégrations |
| Visual Web Ripper | ⭐⭐⭐ | Workflow, planification | CSV, Excel, BD | Guidé par l’utilisateur | 349 $ à vie | Équipes IT, données en masse |
| Dexi.io | ⭐⭐⭐ | Cloud, équipe, workflow | CSV, API, BD, stockage | Guidé par l’utilisateur | Personnalisé | Équipes, projets continus |
| Content Grabber | ⭐⭐⭐ | Scripting, automatisation | CSV, XML, BD | Guidé par l’utilisateur | Entreprise | Agences, solutions sur mesure |
| Helium Scraper | ⭐⭐⭐ | Visuel + scripting | CSV, BD | Guidé par l’utilisateur | 99 $ à vie | Utilisateurs avancés, logique personnalisée |
| Web Scraper | ⭐⭐⭐⭐⭐ | Sitemap, navigateur | CSV, JSON | Guidé par l’utilisateur | Gratuit (local) | Débutants, petites tâches |
| Mozenda | ⭐⭐⭐ | Cloud, services managés, conformité | CSV, API, BD | RGPD, CCPA | 500 $+/mois | Entreprise, service managé |
| SimpleIndex | ⭐⭐⭐ | OCR, web, docs | BD, GED | Guidé par l’utilisateur | 500 $ à vie | Docs + données web |
| Spinn3r | ⭐⭐ | Temps réel, API | JSON, API | Guidé par l’utilisateur | Abonnement | Médias, actualités, recherche |
| FMiner | ⭐⭐⭐ | Workflow visuel, Python | CSV, BD | Guidé par l’utilisateur | 168 $ à vie | Workflows complexes et visuels |
| G2 Webscraper | ⭐⭐⭐⭐⭐ | Simple, navigateur | CSV, JSON | Guidé par l’utilisateur | Gratuit / variable | Simplicité, gains rapides |
Comment choisir le bon outil de crawling de contenu pour votre entreprise
Choisir le bon outil consiste surtout à faire correspondre vos besoins aux points forts de l’outil. Voici ma liste de vérification rapide :
- Définissez votre cas d’usage : ponctuel ou récurrent ? Petite ou grande échelle ? Données publiques ou accessibles après connexion ?
- Faites correspondre au niveau de compétence : les non-codeurs devraient commencer avec Thunderbit, Octoparse, ParseHub ou WebHarvy. Les développeurs peuvent se tourner vers Scrapy ou Apify.
- Vérifiez les besoins d’export : besoin d’Excel, de Sheets ou d’une intégration API ? Assurez-vous que l’outil le prend en charge.
- Tenez compte de la conformité : si vous êtes dans un secteur réglementé ou que vous extrayez des données personnelles, privilégiez les outils dotés de fonctionnalités de conformité (Import.io, Mozenda).
- Commencez petit : utilisez les offres gratuites ou les essais pour tester sur de vraies données avant de vous engager.
- Voyez à long terme : vos besoins vont-ils grandir ? Choisissez un outil avec lequel vous pouvez monter en charge.
Et souvenez-vous : parfois, l’outil le plus simple est le meilleur choix. N’en faites pas trop si vous avez juste besoin d’un tableau rapide.
Confidentialité des données et conformité : ce qu’il faut surveiller
Le web scraping ouvre un monde de possibilités — mais aussi de responsabilités. Voici comment rester du bon côté de la loi et des bonnes pratiques :
- Respectez robots.txt et les politiques des sites : vérifiez toujours si un site autorise le scraping et suivez ses règles.
- Évitez d’extraire des données personnelles sans raison légitime et sans consentement : le RGPD et le CCPA ne plaisantent pas.
- N’attaquez pas les serveurs en continu : utilisez le throttling, les délais et la planification intégrés pour éviter d’être bloqué (et pour rester un bon citoyen du web).
- Utilisez des outils dotés de fonctions de conformité si vous évoluez dans un secteur sensible : Import.io et Mozenda ont été conçus en tenant compte du RGPD/CCPA.
- Documentez vos actions : conservez une trace de ce que vous extrayez et pourquoi, en particulier pour les usages métier ou réglementés.
Un scraping éthique est un scraping durable — et il évite à votre entreprise des ennuis.
Conclusion : donnez à votre équipe les moyens d’agir avec le bon outil de crawling de contenu
Le web est la base de données la plus vaste et la plus chaotique de votre entreprise — et avec le bon outil de crawling de contenu, vous pouvez enfin le mettre au travail. Que vous construisiez des listes de prospects, suiviez vos concurrents ou alimentiez des tableaux de bord en temps réel, ces 18 outils couvrent tous les scénarios, tous les niveaux de compétence et tous les budgets.
Si vous voulez la voie la plus rapide vers des résultats, est mon premier choix pour les utilisateurs métiers : propulsé par l’IA, sans code, et prêt à transformer n’importe quel site web en jeu de données structuré en quelques minutes. Mais quels que soient vos besoins, commencez par un essai gratuit, testez et voyez ce qui correspond le mieux à votre flux de travail.
Prêt à abandonner la corvée du copier-coller ? Téléchargez l’ et voyez à quel point les données web peuvent être simples à exploiter. Et si vous voulez aller plus loin dans le web scraping, consultez le pour davantage de guides, conseils et tutoriels.
FAQ
1. Qu’est-ce qu’un outil de crawling de contenu, et en quoi est-il différent d’un web scraper classique ?
Un outil de crawling de contenu est un type de web scraper conçu pour automatiser l’extraction de données structurées à partir de sites web. Si tous les web scrapers collectent des données, les outils de crawling de contenu proposent souvent des fonctions comme la planification, la navigation entre sous-pages, la détection de champs par IA et l’intégration dans des workflows métier — ce qui les rend plus puissants et plus faciles à utiliser pour les équipes.
2. Quel outil de crawling de contenu est le meilleur pour les utilisateurs non techniques ?
Thunderbit, Octoparse, ParseHub, Data Miner et WebHarvy sont tous excellents pour les non-codeurs. Thunderbit se distingue par sa simplicité portée par l’IA et son export instantané vers Excel, Sheets, Airtable ou Notion.
3. Comment m’assurer que mon web scraping est légal et conforme ?
Respectez toujours les conditions d’utilisation des sites, robots.txt et les lois sur la vie privée comme le RGPD et le CCPA. Évitez d’extraire des données personnelles sans raison légitime et sans consentement. Pour les secteurs sensibles, choisissez des outils dotés de fonctions de conformité intégrées (par exemple Import.io, Mozenda).
4. Ces outils peuvent-ils gérer des sites dynamiques avec JavaScript ou défilement infini ?
Oui — des outils comme Thunderbit, Octoparse, ParseHub, Apify et FMiner peuvent gérer le contenu dynamique, le défilement infini et la navigation multi-niveaux. Certains peuvent nécessiter une configuration supplémentaire ou des exécutions cloud pour les sites complexes.
5. Que dois-je prendre en compte pour choisir un outil de crawling de contenu pour mon entreprise ?
Prenez en compte les compétences techniques de votre équipe, l’ampleur de vos besoins en données, les exigences d’export/intégration, les contraintes de conformité et le budget. Commencez par une version gratuite ou un essai, puis testez l’outil sur votre cas d’usage réel avant de vous engager.
Bon scraping — et que vos données soient toujours fraîches, structurées et prêtes à l’action.
En savoir plus