L’extraction de données Facebook reste intéressante en 2026, mais seulement si vous choisissez le bon modèle de collecte. Le Pew Research Center a indiqué le 20 novembre 2025 que , et Meta a déclaré le 29 avril 2026 que sa en mars 2026. Cette ampleur continue de rendre Facebook utile pour la surveillance de Marketplace, la recherche sur les pages publiques, la génération de leads et le suivi concurrentiel. Le plus difficile n’est pas de trouver des cas d’usage. Le plus difficile, c’est d’obtenir des données propres sans se heurter aux murs de connexion, aux chargements dynamiques, aux blocages temporaires ou à des configurations d’extraction fragiles.
Cette sélection annuelle est conçue pour vous aider à décider vite. J’ai revérifié les pages produits officielles, la documentation et les signaux tarifaires le 8 mai 2026, puis j’ai limité la liste aux outils qui restent pertinents pour de vrais usages professionnels. Si votre flux de travail consiste surtout à « récupérer les données de cette page et les envoyer dans une feuille », commencez par Thunderbit. Si vous avez besoin d’une infrastructure à l’échelle d’une API, Bright Data, Apify et Nimble by Nimbleway méritent une place en haut de la liste. Si votre activité inclut des automatisations cloud ou des actions de suivi après la collecte, PhantomBuster mérite un examen plus attentif.
Choix rapides par besoin
- Besoin de l’export Facebook ou Marketplace sans code le plus rapide ? Commencez avec .
- Besoin d’une API d’entreprise à grande échelle et d’un déblocage géré ? Retenez .
- Besoin de workflows d’extraction cloud flexibles ? Regardez de près .
- Besoin d’une collecte Web publique orientée API avec moins de maintenance du scraper ? Envisagez .
- Besoin d’une API économique pour des tâches légères ? reste pertinent.
- Besoin d’extraction et d’automatisation de workflows ? est plus adapté.
- Besoin d’un constructeur de workflows visuel avec planification ? reste une bonne option sans code.
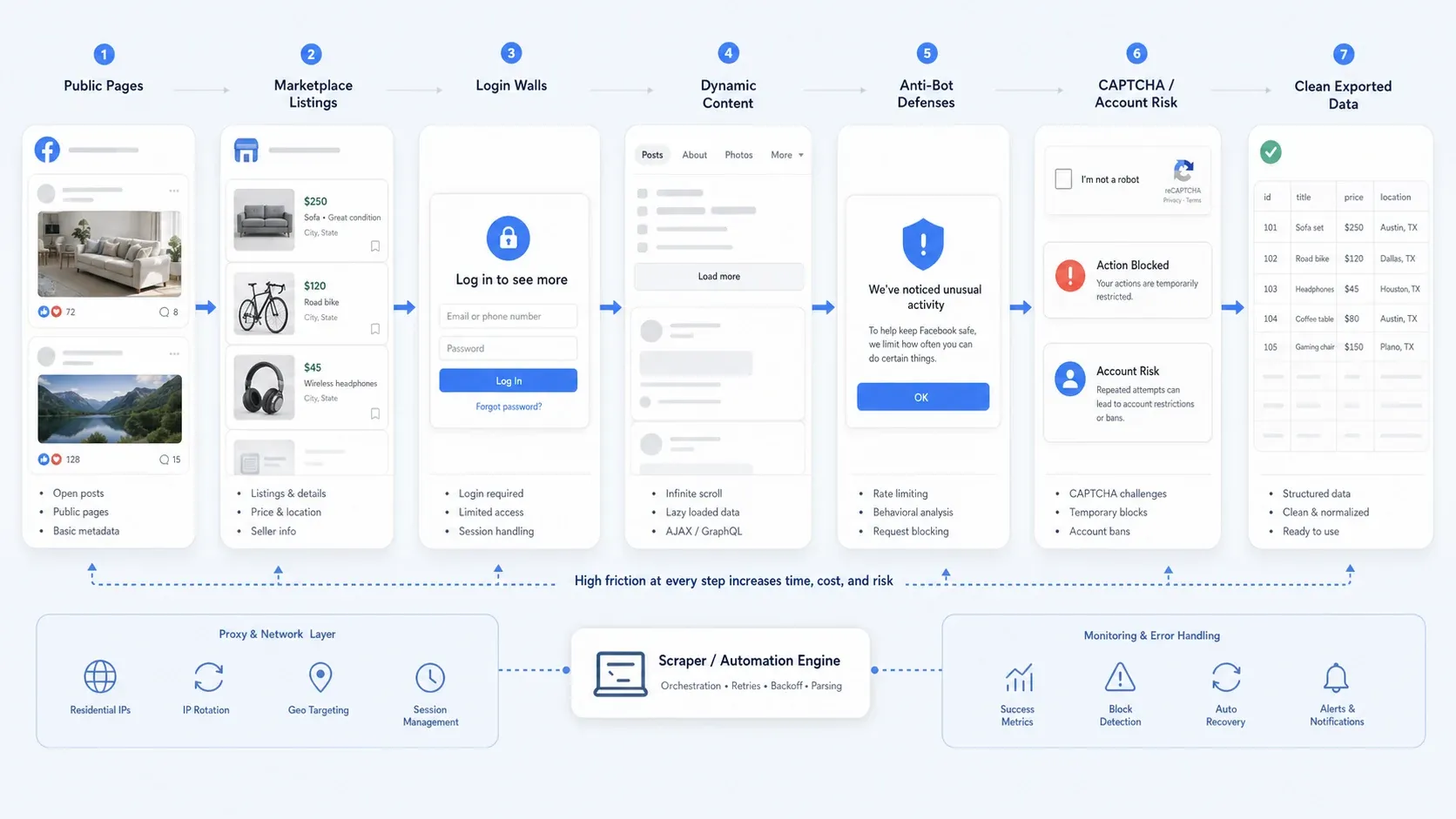
Pourquoi l’extraction de Facebook reste difficile en 2026
La collecte de données Facebook n’est plus, dans la plupart des cas, une simple question de sélecteurs. En pratique, la plupart des équipes se heurtent à un ou plusieurs de ces problèmes :
- Accès public partiel : certaines pages restent publiques, tandis que d’autres flux vous poussent vers la connexion pour voir plus de détails.
- Contenu dynamique : les vues Marketplace, les longs fils de commentaires et le contenu des pages se chargent souvent progressivement.
- Défenses anti-bot : limitation de débit, contrôles comportementaux, CAPTCHA et blocages temporaires perturbent les automatisations naïves.
- Risque opérationnel : la collecte nécessitant une connexion est bien plus risquée que l’extraction de pages publiques, surtout si vous tenez à la sécurité du compte et à la répétabilité.
Comment j’ai évalué ces outils
J’ai optimisé cette page pour construire une shortlist, pas pour gonfler artificiellement les fonctionnalités. Les outils présentés ici ont été comparés selon :
- Adéquation au workflow : le produit correspond-il vraiment aux tâches d’extraction Facebook et Marketplace que les équipes réalisent réellement ?
- Facilité d’utilisation : les non-développeurs ou les petites équipes peuvent-ils obtenir rapidement un résultat exploitable ?
- Échelle et fiabilité : l’outil reste-t-il pertinent au-delà d’une extraction ponctuelle ?
- Gestion anti-bot et session : combien de complexité d’infrastructure le produit vous évite-t-il ?
- Qualité de sortie : pouvez-vous obtenir des données structurées dans CSV, Sheets ou des systèmes en aval sans gros nettoyage ?
- Signal tarifaire : le produit est-il pratique à évaluer, ou exige-t-il une démarche commerciale lourde de type entreprise ?
- Positionnement conformité : l’outil est-il clairement orienté vers la collecte de données publiques et un usage responsable ?
De quel type d’extracteur Facebook avez-vous besoin ?
Le moyen le plus rapide de faire le bon choix consiste d’abord à choisir la bonne catégorie. Les outils d’extraction Facebook se répartissent généralement en quatre modèles opérationnels :
- Outils de navigateur sans code : idéaux quand vous voulez extraire rapidement les données de la page déjà ouverte devant vous.
- API de scraper : idéales quand vous avez besoin d’une collecte fiable et répétable à plus grand volume.
- Workflows d’automatisation : idéaux quand l’extraction n’est qu’une étape d’un processus go-to-market plus large.
- Stacks DIY pour développeurs : idéales quand votre équipe veut un contrôle maximal et est prête à assumer la maintenance.
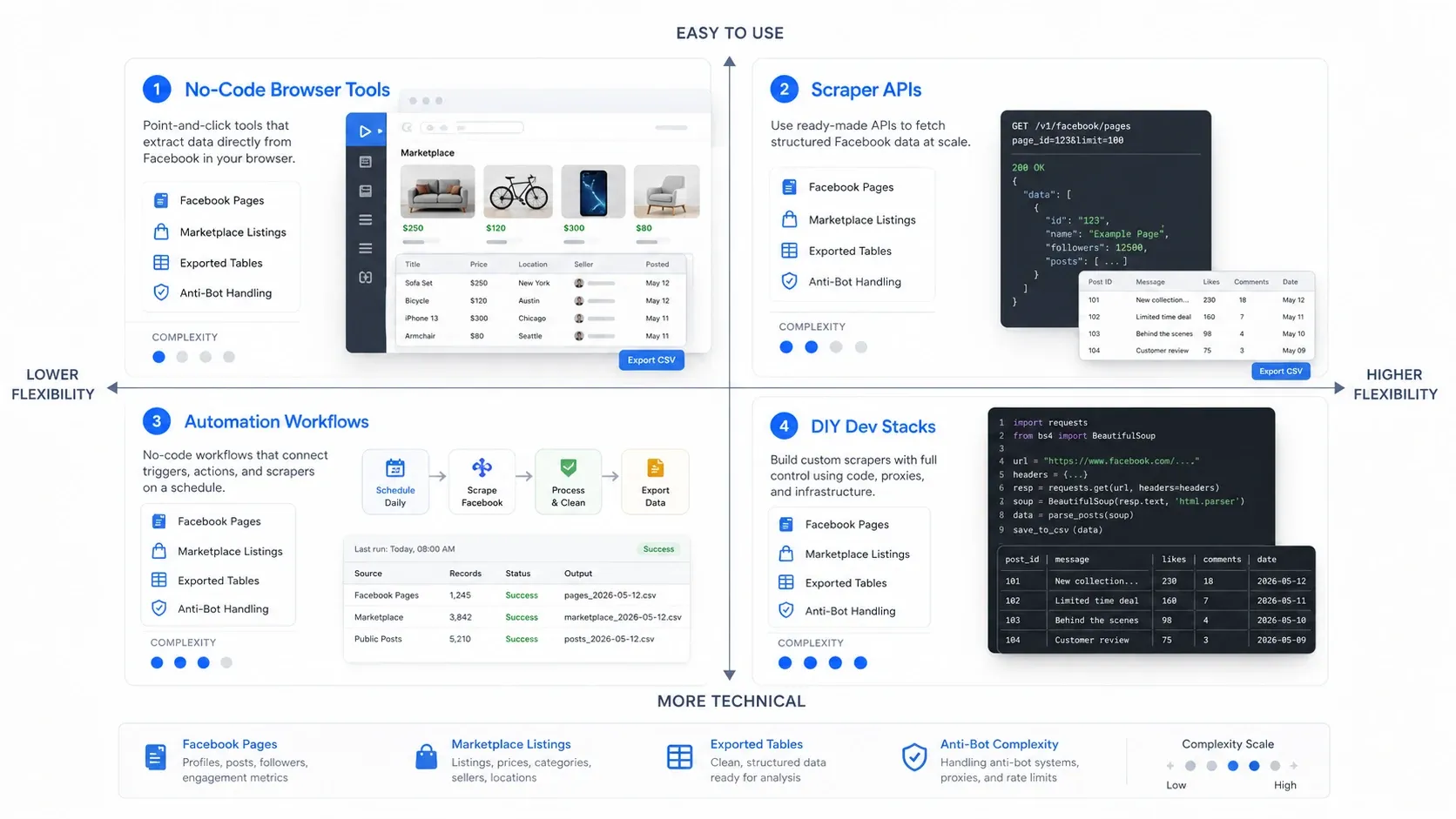
Tableau comparatif
| Outil | Idéal pour | Pourquoi il figure dans la shortlist | Signal tarifaire |
|---|---|---|---|
| Thunderbit | Équipes non techniques et tâches ponctuelles rapides | Détection de champs par IA, gestion des pages dynamiques directement dans le navigateur, exports rapides | Essai gratuit ; abonnements payants basés sur des crédits |
| Bright Data | Pipelines de données sociales publiques à grande échelle | API dédiées de scraping pour les réseaux sociaux, déblocage géré, forte capacité d’échelle | Tarification à l’usage et offres entreprise |
| Apify | Workflows d’extraction cloud flexibles | Actors Facebook prêts à l’emploi, planification, accès API, marge de personnalisation | Offres payantes de plateforme plus usage mesuré |
| Nimble by Nimbleway | Collecte Web publique orientée API | Flux API centré sur l’URL et moins de maintenance du scraper | Tarification pilotée par les ventes |
| ScrapingBot | Petites tâches de données publiques et prototypes | API simple, prise en charge du rendu, coût d’entrée plus faible | Offre gratuite ; forfaits payants à partir d’environ 22 $/mois |
| PhantomBuster | Workflows d’automatisation GTM | Automatisations cloud, workflows d’actions navigateur, bon fit pour la génération de leads | Essai gratuit ; forfaits payants à partir d’environ 56 $/mois |
| Octoparse | Extraction planifiée visuelle sans code | Constructeur en glisser-déposer, extraction cloud, workflows répétables | Forfait gratuit ; forfaits payants à partir d’environ 119 $/mois |
1. Thunderbit
est ici le meilleur choix si votre objectif est de transformer rapidement une page Facebook ou une liste de résultats Marketplace en données structurées, sans construire ni maintenir un scraper. Son principal avantage est l’extraction sémantique : il lit la page, suggère les champs utiles et vous permet d’exporter le résultat sans avoir à gérer sélecteurs, proxys ou code.
Ce qui le distingue :
- Suggérer des champs avec l’IA : Thunderbit identifie des champs probables comme le titre, le prix, le vendeur, la localisation, les coordonnées et les URL.
- Gestion native dans le navigateur : comme il s’exécute là où la page est rendue, il fonctionne bien sur les pages dynamiques et très longues.
- Enrichissement des sous-pages : vous pouvez d’abord collecter les données de liste, puis ouvrir chaque annonce ou page pour obtenir plus de détails.
- Exports utiles : Excel, Google Sheets, Airtable et Notion sont tous des destinations naturelles.
Si vous voulez voir une vidéo avant de tester vous-même un workflow natif navigateur, ce tutoriel pratique Thunderbit est le meilleur point de départ, car il montre le véritable flux d’extraction au lieu de rester au niveau des promesses produit :
Idéal pour : les utilisateurs non techniques, les équipes commerciales, les opérations et les chercheurs qui veulent des résultats rapides.
Signal tarifaire : essai gratuit disponible ; les offres payantes sont basées sur des crédits. Consultez la .
2. Bright Data
est le choix axé infrastructure. La documentation de Bright Data indique que ses couvrent 10 plateformes et 68 points de terminaison dédiés, dont Facebook. Si votre travail consiste à collecter des données publiques à grande échelle, ce type de pile API gérée est généralement plus réaliste qu’une extension de navigateur ou qu’un scraper artisanal.
Pourquoi il mérite sa place dans la shortlist :
- Points de terminaison dédiés au scraping des réseaux sociaux
- Déblocage et extraction gérés
- Livraison de sorties structurées pour les pipelines de données
- Meilleur ajustement pour les tâches de monitoring et d’analytique sensibles à la fiabilité
Idéal pour : les analystes, les équipes data, les grands projets de surveillance et les jeux de données sociaux publics à grande échelle.
Signal tarifaire : la tarification varie selon le produit et le volume. Vérifiez la .
3. Apify
reste pertinent parce qu’il offre un bon compromis entre modèles prêts à l’emploi et personnalisation complète. Son acteur Facebook Pages Scraper est un point de départ utile, tandis que la plateforme Apify au sens large vous donne des exécutions cloud, la planification, des API et de la marge pour étendre le workflow si vos besoins deviennent plus complexes.
Pourquoi il figure dans la liste :
- Actors Facebook prêts à l’emploi
- Exécution cloud et planifications récurrentes
- Exports flexibles et accès API
- Plus facile à étendre qu’un workflow navigateur purement sans code
Idéal pour : les spécialistes marketing techniques, les agences, les équipes ops et les tâches de collecte récurrentes sur plusieurs sites.
Signal tarifaire : les offres de la plateforme sont payantes et l’usage des actors est facturé séparément. Consultez la .
4. Nimble by Nimbleway
est l’option orientée API pour les équipes qui veulent envoyer une URL et laisser la plateforme gérer l’accès, le rendu et la livraison. Nimble présente son comme une collecte de données Web publiques de bout en bout, ce qui le rend utile lorsque l’extraction Facebook n’est qu’une partie d’une pile de données plus large.
Pourquoi cela vaut la peine d’être évalué :
- Flux API centré sur l’URL
- Moins de maintenance du scraper pour les équipes d’ingénierie
- Bon ajustement pour une extraction Web publique robuste
- Utile lorsque les données extraites alimentent des produits internes ou des tableaux de bord
Idéal pour : les équipes pilotées par l’ingénierie, les pipelines de données produit et les organisations qui veulent une couche d’abstraction d’infrastructure plutôt qu’un outil ponctuel.
Signal tarifaire : Nimble ne met pas particulièrement en avant de tarification publique en self-service sur ses pages API principales ; attendez-vous donc à une tarification commerciale et vérifiez directement auprès de .
5. ScrapingBot
est l’option API la plus attentive au budget de cette liste. Ce n’est pas la plateforme la plus spécialisée Facebook ici, mais elle reste pertinente pour des petits travaux de données publiques où vous voulez une API, la prise en charge du rendu et un coût d’entrée plus bas que les infrastructures de scraping d’entreprise.
À quel besoin elle répond :
- Scraping public simple piloté par API
- Tarification d’entrée plus basse
- Rendu et gestion des proxys inclus
- Mieux adapté aux prototypes et aux extractions légères récurrentes qu’aux gros programmes d’intelligence
Idéal pour : les startups, les petites entreprises et les développeurs qui testent des cas d’usage légers de collecte de pages publiques.
Signal tarifaire : offre gratuite disponible ; la page de tarification publique actuelle démarre les forfaits payants à environ .
6. PhantomBuster
concerne moins l’infrastructure brute d’extraction que ce qui se passe après la collecte. Si votre cas d’usage consiste à « collecter les données, puis déclencher une prise de contact, un enrichissement ou des actions de suivi », PhantomBuster est souvent plus utile qu’un simple extracteur, car il est conçu autour des automatisations cloud et des workflows d’actions navigateur.
Pourquoi les équipes le retiennent encore :
- Workflows d’automatisation cloud
- Utile pour la génération de leads et les opérations GTM
- Meilleur ajustement quand l’extraction n’est qu’une étape d’un processus plus large
- Pratique pour les opérateurs qui s’intéressent aux actions, pas seulement aux exports
Idéal pour : les équipes GTM, les équipes growth, les recruteurs et les opérateurs qui enchaînent collecte et action aval.
Signal tarifaire : essai gratuit disponible ; les forfaits payants sur la page de tarification actuelle commencent à environ .
7. Octoparse
reste l’un des meilleurs outils d’extraction visuelle sans code pour les utilisateurs qui veulent des workflows répétables et des exécutions cloud planifiées. Il n’est pas aussi léger que Thunderbit pour de petites tâches Facebook ponctuelles, mais il donne aux non-développeurs un contrôle plus explicite sur la manière dont la logique d’extraction est construite et répétée.
Pourquoi il reste pertinent :
- Constructeur visuel en glisser-déposer
- Extraction cloud et planification
- Bon pour les tâches structurées et répétitives
- Plus adapté aux analystes qui veulent de la répétabilité sans code
Idéal pour : les analystes non techniques, les équipes ops des PME et les tâches de collecte répétables avec une logique de workflow plus explicite.
Signal tarifaire : la page de tarification publique d’Octoparse indique des forfaits payants à partir d’environ .
Shortlist par type d’équipe
Si vous savez déjà quel type d’équipe va porter le workflow, commencez ici :
- Exploitant solo ou petite entreprise : Thunderbit, ScrapingBot ou Octoparse
- Équipe commerciale / GTM : Thunderbit ou PhantomBuster
- Analyste ops : Thunderbit, Apify ou Octoparse
- Équipe d’automatisation growth : PhantomBuster ou Apify
- Équipe d’ingénierie data : Bright Data, Nimble ou Apify

Comment choisir le bon extracteur Facebook
- Choisissez Thunderbit si la vitesse et la simplicité comptent plus que l’échelle maximale.
- Choisissez Bright Data si vous avez besoin d’une grande échelle de données publiques et d’une fiabilité gérée.
- Choisissez Apify si vous voulez de la flexibilité de plateforme et des workflows basés sur des actors.
- Choisissez Nimble si vous voulez une couche d’abstraction orientée API avec moins de maintenance du scraper.
- Choisissez PhantomBuster si l’extraction n’est qu’une étape d’un workflow d’automatisation GTM plus large.
- Choisissez Octoparse si vous voulez une répétabilité visuelle sans code.
- Choisissez ScrapingBot si le budget compte et que la tâche est relativement simple.
Conclusion
En 2026, le marché est plus clairement segmenté qu’il y a un an. Vous ne choisissez pas vraiment un unique « meilleur extracteur Facebook » universel. Vous choisissez un modèle de collecte : extraction rapide sans code, API gérée à grande échelle, automatisation cloud ou contrôle visuel pratique du workflow. En partant de là, la shortlist devient beaucoup plus simple.
Si votre équipe veut aller le plus vite possible d’une page Facebook ou d’une annonce Marketplace à des données structurées exploitables, Thunderbit reste le point de départ le plus simple. Si vos volumes ou vos besoins d’ingénierie sont bien plus élevés, Bright Data, Apify et Nimble sont plus logiques. Si votre workflow commence par l’extraction mais se termine par des actions de suivi, PhantomBuster est la shortlist la plus intelligente.
FAQ
1. Quel est l’outil d’extraction Facebook le plus simple pour les utilisateurs non techniques ?
Thunderbit est le point de départ le plus simple pour la plupart des utilisateurs non techniques, car il fonctionne dans le navigateur, suggère automatiquement les champs et exporte rapidement les données sans code.
2. Quel outil d’extraction Facebook est le meilleur pour la collecte de données publiques à grande échelle ?
Bright Data est le choix infrastructure le plus solide de cette liste lorsque la tâche consiste à collecter des données sociales publiques à grande échelle et que la fiabilité compte plus que la facilité d’utilisation.
3. Que faire si j’ai besoin d’extraction plus automatisation de suivi ?
PhantomBuster est plus adapté lorsque la collecte de données n’est qu’une étape d’un workflow plus large de génération de leads ou de GTM.
4. L’extraction Facebook est-elle toujours difficile en 2026 ?
Oui. Le contenu dynamique, les murs de connexion, les limites de débit, les systèmes anti-bot et les risques liés aux comptes rendent encore Facebook plus difficile à extraire que des sites publics plus simples.
5. Comment les équipes doivent-elles penser la conformité ?
Restez concentrés sur les données publiques, utilisez des débits raisonnables, évitez tout abus d’identifiants et vérifiez les conditions de la plateforme ainsi que les règles de confidentialité applicables avant de faire passer un workflow à l’échelle.
À lire aussi :