Après avoir effectué bien plus d’un millier d’extractions avec Simplescraper, j’ai arrêté de compter les réussites pour commencer à répertorier les échecs. Ce basculement — de « est-ce que ça a marché ? » à « pourquoi est-ce que ça a cassé cette fois ? » — m’a appris bien plus que n’importe quelle page de documentation.
Simplescraper est une extension Chrome solide pour extraire des données de sites web sans écrire de code. Avec sur le Chrome Web Store et une interface point-and-click vraiment accessible, l’outil s’est taillé une place dans la boîte à outils du scraping sans code. Mais voici ce que personne ne vous dit sur la page d’accueil : pour obtenir des résultats cohérents et fiables à grande échelle, il faut comprendre où les extracteurs visuels deviennent fragiles. Une que les employés passent plus de neuf heures par semaine à saisir des données répétitives — exactement le genre de corvée qui pousse les gens vers des outils comme Simplescraper. Mais si vous ne connaissez pas les particularités de l’outil, vous passerez ces neuf heures à déboguer au lieu d’avancer sur quelque chose d’utile. Cet article présente les cinq meilleures pratiques que j’ai tirées d’une vraie expérience terrain : résoudre les échecs de sélection, choisir le bon mode d’extraction, tirer le meilleur parti de l’offre gratuite, éviter les blocages et savoir quand passer à autre chose.

Qu’est-ce que Simplescraper, et pourquoi les bonnes pratiques sont-elles importantes ?
Simplescraper est une extension Chrome qui vous permet de sélectionner visuellement des éléments sur une page web — titres de produits, prix, images, coordonnées — et de les extraire sous forme de données structurées sans écrire une seule ligne de code. Vous pointez, vous cliquez, et l’outil construit une « recette » réutilisable sur des pages similaires.
Le modèle de base fonctionne ainsi :
- Sélection visuelle des éléments : cliquez sur ce que vous voulez. Simplescraper détecte automatiquement les motifs répétés (listes de produits, résultats de recherche, offres d’emploi).
- Recettes : enregistrez votre configuration d’extraction pour la réutiliser plus tard ou l’exécuter sur des lots d’URL.
- Deux modes d’extraction : Browser (local, dans votre Chrome) et Cloud (sur les serveurs de Simplescraper, sans surveillance).
- Intégrations : export vers Google Sheets, Airtable, webhooks, Zapier, Make, CSV et JSON.
- Extraction IA : une fonction plus récente, , qui génère des sélecteurs CSS à partir d’une invite de schéma.
Le public visé est large — marketeurs, équipes commerciales, opérateurs e-commerce, chercheurs — bref, toute personne qui doit extraire des données structurées depuis des sites web sans embaucher de développeur. Et pour des pages simples, Simplescraper est rapide et efficace.
Alors pourquoi les bonnes pratiques comptent-elles ? Parce qu’au-delà d’une simple liste de produits ou d’un annuaire bien propre, les frictions apparaissent vite. Contenu dynamique, protections anti-bot, images chargées à la demande, structures HTML imbriquées : ce sont ces conditions du monde réel qui font la différence entre une expérience frustrante et un usage productif. Savoir quelle approche adopter dès le départ permet d’économiser des heures d’essais et d’erreurs.
Bonne pratique 1 : que faire lorsque Simplescraper ne parvient pas à sélectionner les éléments ?
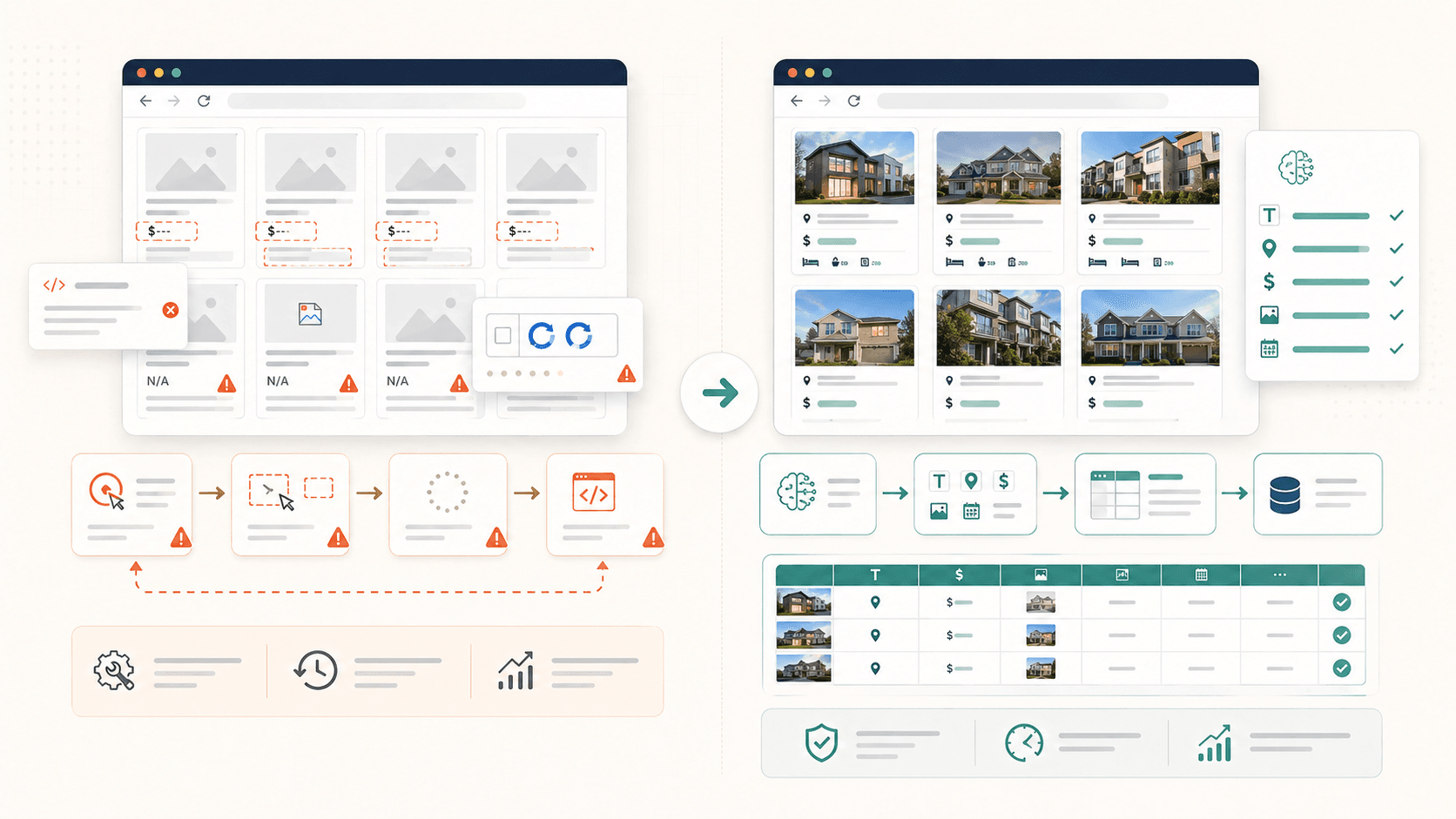
C’est de loin la frustration la plus fréquente que j’ai observée. Vous cliquez sur un élément, Simplescraper le met en surbrillance, vous êtes rassuré — puis l’export contient la moitié des données manquantes. Les photos sont vides. Les bios sont absentes. Les localisations ont disparu.
Le fondateur lui-même que « the element/css selector still ain't 100% ». C’est honnête, certes, mais ça ne répare pas votre extraction cassée à 23 h un mercredi soir.
Échecs de sélection courants, et pourquoi ils se produisent
Quatre cas piègent le plus souvent Simplescraper :
- Images chargées à la demande : l’élément image tant que vous n’avez pas fait défiler jusqu’à lui. Si vous extrayez avant de scroller, les champs d’image restent vides.
- Conteneurs imbriqués ou groupés : la détection automatique de Simplescraper , ce qui signifie parfois qu’elle ne récupère qu’une seule section de la page au lieu de l’ensemble répétitif complet. Des utilisateurs signalent des tableaux qui « ne sélectionnent pas toutes les lignes en une seule fois ».
- Contenu JavaScript dynamique : les éléments rendus après le chargement initial via React, Vue ou des appels AJAX ne sont tout simplement pas là lorsque l’extracteur agit trop tôt.
- Pagination à défilement infini : les données que vous cherchez n’ont pas encore été chargées dans le HTML, car il faut faire défiler ou cliquer sur « charger plus ».
Étapes pratiques de dépannage
Avant de passer aux sélecteurs manuels, essayez ceci :
- Faites d’abord défiler toute la page. Cela force les images et le contenu chargés à la demande à entrer dans le DOM.
- Utilisez « Include Similar » lorsque le nombre d’éléments semble anormalement faible. La documentation de Simplescraper recommande cette option pour le contenu groupé.
- Attendez le rendu complet de la page sur les sites très riches en JavaScript. Laissez quelques secondes de plus avant de lancer l’extraction.
- Commencez par un petit échantillon. Vérifiez le nombre de lignes sur 2 à 3 pages avant de lancer un lot de 500 pages.
Passer aux sélecteurs CSS manuels
Quand la sélection visuelle échoue encore et encore, il faut passer en mode manuel. C’est l’option qui distingue les utilisateurs occasionnels des utilisateurs vraiment efficaces.
Voici le flux de travail :
- Faites un clic droit sur l’élément voulu dans Chrome → Inspecter.
- Dans DevTools, identifiez la classe de l’élément ou son attribut de données (par ex.
.product-card .priceou[data-test="location"]). - Dans Simplescraper, passez à l’onglet et collez votre sélecteur.
- Testez le sélecteur en lançant une petite extraction.
Conseils pour des sélecteurs robustes :
- Préférez les noms de classe (
.listing-title) aux sélecteurs positionnels (div:nth-child(3)) - Utilisez les quand ils existent — ils sont généralement plus stables lors des mises à jour du site
- Évitez les chemins trop profondément imbriqués, qui cassent dès que la structure HTML du site change
L’alternative IA : laisser Thunderbit détecter automatiquement les champs
Je vais être franc — mon équipe a créé précisément parce que nous étions fatigués de ce problème. La fonction « AI Suggest Fields » de Thunderbit lit la structure de la page et recommande automatiquement les colonnes et la logique d’extraction. Aucun besoin de connaître le CSS. L’IA s’adapte à la mise en page de chaque site, y compris le contenu imbriqué et les images chargées à la demande.
Si vous passez plus de quelques minutes par extraction à déboguer des sélecteurs, cela vaut franchement la peine d’essayer une autre approche.
Bonne pratique 2 : choisir entre le scraping Cloud et le scraping Browser
La plupart des utilisateurs de Simplescraper choisissent un mode par défaut — généralement celui qu’ils ont essayé en premier — sans réfléchir à celui qui correspond réellement à leur cas d’usage. Cela provoque des échecs évitables.
Quand utiliser le scraping Browser (local)
- Pages nécessitant une connexion : LinkedIn, tableaux de bord CRM, outils internes — tout ce qui est derrière une authentification requiert votre session de navigateur active.
- Extractions ponctuelles rapides : vous êtes déjà sur la page, vous voulez juste les données maintenant.
- Préserver les crédits gratuits : le scraping Browser ne consomme pas de crédits cloud.
Le compromis : votre ordinateur doit rester allumé, et les gros traitements sont plus lents que dans le cloud.
Quand utiliser le scraping Cloud
- Pages publiques (listes e-commerce, annuaires, sites immobiliers) qui ne nécessitent aucune connexion.
- Suivi planifié : exécution automatisée de manière récurrente.
- Traitements par lots : en un seul lot cloud.
- Livraison vers des intégrations : envoi automatique vers Google Sheets, Airtable ou des webhooks.
Le compromis : le scraping cloud — 2 par page avec JavaScript, 1 par page sans JavaScript — et brûle vite l’allocation mensuelle gratuite de 100 crédits.
Cadre de décision
| Scénario | Mode recommandé | Pourquoi | Risque si vous vous trompez |
|---|---|---|---|
| Pages nécessitant une connexion (LinkedIn, tableaux de bord) | Browser | Nécessite votre session authentifiée | Le mode Cloud se heurte aux murs de connexion |
| Listes de produits e-commerce publiques | Cloud | Plus rapide, fonctionne sans surveillance | Le mode Browser monopolise votre machine |
| Suivi récurrent planifié | Cloud | Fonctionne sans votre présence | Le mode Browser exige que vous soyez là |
| Sites très protégés contre les bots (Amazon, Yelp) | Browser (solution de repli) ou Cloud avec proxy | Rotation d’IP ou réutilisation de session nécessaire | Le Cloud sans proxy est vite bloqué |
| Extraction ponctuelle rapide | Browser | Immédiat, sans coût en crédits | Déployer le cloud pour une seule page est excessif |

En quoi Thunderbit simplifie cela
Dans , le choix se résume à un simple interrupteur dans la même interface. Le mode Cloud traite jusqu’à 50 pages en parallèle — sans palier payant séparé pour l’accès cloud. Le mode Browser gère les sites nécessitant une connexion sans configuration supplémentaire. La charge mentale liée au « quel mode dois-je utiliser ? » diminue fortement quand les deux modes vivent dans le même flux de travail.
Bonne pratique 3 : tirer le meilleur parti de l’offre gratuite de Simplescraper
La confusion autour des tarifs est bien réelle. J’ai vu des messages sur des forums où des gens supposent que « extension Chrome gratuite » signifie « tout est gratuit ». Ce n’est pas le cas. Et à l’inverse, j’ai vu des personnes penser que Simplescraper est cher parce que les offres payantes ne sont pas mises en avant. Aucune de ces deux suppositions n’aide vraiment.
Ce que comprend réellement le plan gratuit de Simplescraper
D’après les :
- Scraping Browser : illimité (s’exécute localement dans votre Chrome)
- Crédits cloud : 100 par mois
- Recettes enregistrées : 3
- Formats d’export : CSV et JSON
- Ce qui n’est PAS inclus : support prioritaire, options de proxy avancées, quotas de crédits cloud plus élevés
Un scénario réaliste avec l’offre gratuite
Imaginons que vous deviez extraire 50 pages produits d’un site e-commerce public.
- Mode Browser (gratuit) : vous pouvez le faire entièrement gratuitement. Ouvrez chaque page (ou utilisez une liste), lancez la recette, exportez en CSV. Temps requis : cela dépend de votre patience et de votre connexion, mais comptez 15 à 30 minutes de travail actif pour 50 pages avec navigation manuelle.
- Mode Cloud (offre gratuite) : avec le rendu JavaScript activé, chaque page coûte 2 crédits. 50 pages = 100 crédits. Cela consomme tout votre quota cloud mensuel en une seule tâche. Pas de planification, pas de relance si quelque chose échoue.
L’offre gratuite est réellement utile pour des extractions ponctuelles de petite taille. Mais elle s’épuise vite dès qu’il faut automatiser dans le cloud ou passer à l’échelle.
Comparaison de l’offre gratuite : Simplescraper vs Thunderbit
| Fonctionnalité | Simplescraper gratuit | Thunderbit gratuit |
|---|---|---|
| Pages/crédits | Browser illimité + 100 crédits cloud | 6 pages avec toutes les fonctions IA |
| Extraction alimentée par l’IA | Limitée (Smart Extract consomme des crédits) | AI Suggest Fields inclus |
| Destinations d’export | CSV, JSON | Excel, Google Sheets, Airtable, Notion — le tout gratuitement |
| Configurations enregistrées | 3 recettes | Modèles disponibles |
| Extraction de sous-pages | Configuration manuelle de la recette | Incluse dans le quota de pages |
Les modèles sont vraiment différents. Simplescraper vous offre une extraction locale illimitée avec un cloud limité. vous donne moins de pages, mais y intègre l’IA complète, ainsi que des exports gratuits vers les outils réellement utilisés par la plupart des équipes. L’offre gratuite de Simplescraper fonctionne si vous avez besoin d’une extraction locale basique et que le travail manuel ne vous dérange pas. Mais si vous voulez une extraction alimentée par l’IA avec des exports flexibles, l’offre gratuite de Thunderbit est plus puissante page par page.
Bonne pratique 4 : comment éviter les blocages pendant le scraping
Personne ne pense aux protections anti-bot avant de se retrouver face à un CAPTCHA ou à un jeu de données vide. À ce moment-là, vous avez déjà perdu du temps et parfois aussi des crédits.
Mieux vaut prévenir que dépanner dans l’urgence.
Définir des limites de débit et rythmer les requêtes
La première cause de blocage : inonder un site de requêtes à la chaîne. Pour un serveur web, 50 requêtes en 10 secondes depuis une seule IP ressemblent à une attaque, pas à une recherche curieuse.
Règles générales :
- Ajoutez 2 à 5 secondes entre les requêtes de pages pour la plupart des sites commerciaux.
- Pour les cibles sensibles (places de marché, sites d’avis), allez plus lentement — 5 à 10 secondes.
- Si vous utilisez l’API de Simplescraper, le paramètre peut aider à garantir que les pages se chargent complètement avant l’extraction, ce qui ralentit aussi naturellement le rythme.
Quand activer la rotation de proxy
La rotation de proxy change votre adresse IP entre les requêtes, vous faisant passer pour plusieurs utilisateurs différents. Vous en aurez besoin pour :
- Amazon, Yelp, TripAdvisor, LinkedIn (systèmes anti-bot agressifs)
- Tout site qui limite le débit par IP
- Les gros traitements par lots (des centaines de pages d’un même domaine)
La plateforme Simplescraper standard, premium et résidentiel. Toutefois, la disponibilité exacte selon le plan n’est pas toujours très claire dans la documentation publique — vérifiez avant de supposer que l’offre gratuite couvre les cibles difficiles. Les proxies résidentiels coûtent généralement plus cher, mais ils risquent moins d’être signalés.
Gérer les sites lourds en JavaScript
Les sites modernes construits avec React, Vue ou Angular affichent le contenu après le chargement initial de la page. Si votre extracteur agit avant la fin de l’exécution du JavaScript, vous obtenez des champs vides.
Stratégies :
- Utilisez le mode Cloud pour un meilleur rendu (le cloud de Simplescraper peut exécuter JavaScript).
- Faites défiler manuellement la page avant de lancer une extraction Browser pour déclencher le contenu chargé à la demande.
- Utilisez
waitForSelectordans les workflows basés sur l’API pour attendre que les éléments cibles apparaissent. - Acceptez que certaines applications monopage très dynamiques soient simplement hors de portée d’un extracteur visuel fiable.
L’alternative sans intervention
gère automatiquement la protection anti-bot, les CAPTCHA et le rendu JavaScript — aucune configuration de proxy, aucun réglage de délai, aucun défilement manuel. Pour les utilisateurs qui ne veulent pas devenir des ingénieurs DevOps amateurs juste pour extraire un catalogue de produits, cela compte vraiment. Les problèmes ne disparaissent pas — ils deviennent simplement le problème de quelqu’un d’autre.
Bonne pratique 5 : savoir quand Simplescraper a atteint sa limite
J’aurais aimé que quelqu’un m’écrive cette section il y a deux ans.
Il arrive un moment où l’outil cesse de faire gagner du temps et commence à en faire perdre. Reconnaître ce seuil tôt vous évite le piège des coûts irrécupérables : « j’ai déjà construit 15 recettes, je ne peux plus changer maintenant ».
Les limites pratiques de Simplescraper
- Applications monopage dynamiques qui chargent le contenu via AJAX sans navigation de page traditionnelle
- Défilement infini qui exige de scroller en continu pour charger tous les éléments (et non une pagination classique par clic)
- Enrichissement de sous-pages : extraire une page de liste puis visiter chaque page de détail pour des données supplémentaires. Simplescraper peut le faire avec des , mais la complexité de configuration augmente vite.
- Changements de mise en page qui cassent les recettes existantes. Lorsqu’un site met à jour sa structure HTML, vos sélecteurs CSS soigneusement réglés cessent de fonctionner.
Les signes que l’outil a atteint son plafond
Vous avez probablement atteint la limite quand :
- Vous ajustez manuellement les sélecteurs CSS à chaque extraction parce que la détection automatique échoue sans cesse
- Les recettes cassent après des mises à jour du site et doivent être reconstruites
- Vous devez extraire simultanément des dizaines ou des centaines de pages, mais vous butez toujours sur des limites de crédits ou de vitesse
- Les données des sous-pages nécessitent des chaînes de recettes complexes en plusieurs étapes
- Vous passez plus de temps à maintenir les extractions qu’à utiliser les données extraites
Ce dernier point est le signal le plus clair. Quand la maintenance devient le travail, le dividende de confort du no-code a disparu.
Passer à un flux de travail alimenté par l’IA
C’est ici que je parlerai de ce que mon équipe a construit avec , car l’outil a été conçu précisément pour les cas d’échec décrits ci-dessus :

- L’IA relit chaque page à chaque exécution — pas de recettes fragiles ni de sélecteurs CSS à entretenir. Si un site change de mise en page, l’IA s’adapte au lancement suivant.
- L’extraction de sous-pages enrichit votre tableau de données en un clic. Extrayez une liste, puis visitez automatiquement chaque page de détail pour récupérer des champs supplémentaires.
- Le scraping programmé utilise le langage naturel (« tous les lundis à 9 h ») plutôt que de configurer des préréglages horaires.
- Le scraping Cloud à 50 pages en parallèle pour accélérer le traitement sur les sites publics.
- Exports gratuits natifs vers Google Sheets, Airtable, Notion et Excel, sans configuration de webhook.
Simplescraper vs Thunderbit : comparaison côte à côte
Tout est rassemblé ici :

| Capacité | Simplescraper | Thunderbit |
|---|---|---|
| Configuration des champs | Sélecteurs CSS manuels / sélection visuelle | AI Suggest Fields (anglais simple) |
| Enrichissement de sous-pages | Possible via des workflows par lots (configuration complexe) | Enrichissement automatique en 1 clic |
| Adaptation automatique aux changements de mise en page | Casse (correction manuelle requise) | L’IA relit la structure de la page à chaque fois |
| Concurrence de pages en cloud | Lots jusqu’à 5 000 URL (varie selon le plan) | 50 pages simultanément |
| Export vers Notion/Airtable | Via webhook (offres payantes) | Natif, gratuit |
| Planification | Préréglages + contrôles horaires personnalisés | Description en langage naturel |
| Gestion anti-bot / CAPTCHA | Modes proxy disponibles (selon le plan) | Automatique, sans configuration |
| Offre gratuite | 100 crédits cloud + Browser illimité + 3 recettes | 6 pages avec toutes les fonctions IA + exports gratuits |
En résumé : Simplescraper excelle pour une extraction simple, visuelle et peu configurée, où un ajustement manuel occasionnel reste acceptable. Thunderbit prend le relais là où ce modèle s’essouffle — en gérant l’interprétation des pages, l’adaptation à la mise en page et la complexité des workflows, pour que vous n’ayez pas à le faire.
Aucun des deux outils n’est universellement meilleur. Ils se situent à des points différents du continuum de complexité — et c’est très bien ainsi.
Mémo rapide : checklist des meilleures pratiques Simplescraper
Mettez ce mémo en favori pour votre prochaine session de scraping :
- Testez toujours d’abord sur un petit échantillon. Vérifiez le nombre de lignes et l’exhaustivité des champs sur 2 à 3 pages avant de passer à l’échelle.
- Faites défiler la page avant d’extraire pour déclencher le contenu chargé à la demande.
- Utilisez « Include Similar » lorsque la détection des listes semble trop restrictive.
- Choisissez volontairement votre mode d’extraction. Browser pour les sites nécessitant une connexion ; Cloud pour les pages publiques et les tâches planifiées.
- Définissez des délais entre les requêtes — au minimum 2 à 5 secondes pour les sites commerciaux, davantage pour les cibles très protégées contre les bots.
- Comprenez votre calcul de l’offre gratuite. 100 crédits cloud = 50 pages avec JavaScript. Planifiez en conséquence.
- N’enregistrez des recettes que pour des pages stables. Si un site se met à jour fréquemment, les recettes casseront.
- Apprenez les bases des sélecteurs CSS comme solution de repli. Les noms de classe et les attributs de données valent mieux que les sélecteurs positionnels.
- Surveillez les blocages de façon proactive. Si vous obtenez des résultats vides ou des CAPTCHA, ralentissez ou changez de mode.
- Reconnaissez le plafond. Quand le temps de maintenance dépasse le temps d’utilisation des données, évaluez d’autres options.
Conclusion : faites compter chaque extraction
La leçon générale tirée de plus d’un millier d’extractions ne concerne pas un outil en particulier. C’est que l’approche compte plus que le logiciel. Comprendre pourquoi une extraction échoue — chargement différé, mauvais mode, anti-bot agressif, sélecteurs fragiles — est plus précieux que n’importe quelle liste de fonctionnalités.
Simplescraper fonctionne réellement bien pour les extractions simples. Si vos pages sont propres, vos besoins modestes et que des réglages manuels occasionnels ne vous dérangent pas, l’outil tient ses promesses.
Mais si vous vous retrouvez à lutter contre l’outil plus qu’à l’utiliser — à déboguer des sélecteurs, reconstruire des recettes cassées, configurer des proxys, faire défiler des pages à la main — ce n’est pas un échec personnel. C’est le signe que vous avez dépassé ce que le scraping visuel seul peut gérer efficacement.
Si cela vous parle, essayez — six pages avec toutes les fonctions IA, exports gratuits vers Sheets, Airtable et Notion. Comparez-la à votre workflow actuel et voyez ce qui vous convient le mieux. Parfois, la meilleure pratique consiste à savoir quand passer à un autre outil.
FAQ
Simplescraper est-il gratuit ?
Oui, Simplescraper propose un plan gratuit qui inclut le scraping local illimité dans le navigateur, , 3 recettes enregistrées et l’export CSV/JSON. Les pages cloud avec JavaScript coûtent 2 crédits chacune, donc ces 100 crédits couvrent environ 50 pages en mode Cloud. Les plans payants commencent à 39 $/mois (Plus) pour 6 000 crédits et à 70 $/mois (Pro) pour 15 000 crédits.
Simplescraper peut-il gérer des sites web lourds en JavaScript ?
Parfois. Le mode Cloud de Simplescraper peut rendre JavaScript, et l’outil annonce une prise en charge des applications monopage. Toutefois, les SPA complexes avec rendu dynamique intensif, défilement infini ou protections anti-bot agressives peuvent encore produire des résultats incomplets. Utiliser le mode Cloud avec des temps d’attente appropriés améliore la fiabilité, mais les sites très dynamiques restent un défi pour tout extracteur visuel.
Quelle est la différence entre le scraping Cloud et le scraping Browser dans Simplescraper ?
Le scraping Browser s’exécute localement dans votre navigateur Chrome — il utilise votre session active (parfait pour les sites nécessitant une connexion), ne coûte aucun crédit, mais demande que votre ordinateur reste allumé. Le s’exécute sur les serveurs de Simplescraper — il est plus rapide, fonctionne sans surveillance, prend en charge la planification et les intégrations, mais consomme des crédits par page et ne peut pas accéder aux pages derrière votre connexion personnelle.
Quand devrais-je passer de Simplescraper à une alternative comme Thunderbit ?
Le signal le plus clair est lorsque le temps consacré à la maintenance dépasse le temps consacré à l’utilisation des données. Si vous corrigez régulièrement des sélecteurs cassés après des mises à jour de sites, configurez manuellement des proxys, reconstruisez des recettes ou passez plus de temps à dépanner qu’à analyser vos données extraites, vous avez dépassé ce que le scraping visuel manuel peut fournir efficacement. Des outils comme , qui utilisent l’IA pour interpréter la structure de la page à chaque exécution, éliminent la majeure partie de cette charge de maintenance.
Comment éviter les blocages lors du scraping avec Simplescraper ?
Trois pratiques clés : d’abord, cadencez vos requêtes avec 2 à 5 secondes de délai entre les pages, voire davantage pour les sites très protégés contre les bots comme Amazon ou Yelp. Ensuite, utilisez le mode Browser comme solution de repli pour les sites qui bloquent agressivement les IP cloud — votre session de navigateur ressemble davantage à du trafic normal. Enfin, activez la rotation de proxy pour les gros lots sur les cibles sensibles, en vérifiant toutefois quelles options proxy votre plan inclut avant d’en dépendre.
En savoir plus