

Laissez-moi vous ramener à la première fois où j’ai essayé d’extraire des données produit d’un site e-commerce. J’avais Python, une tasse de café et un rêve : créer un outil de suivi des prix pour Amazon. Quelques heures plus tard, mon « petit projet rapide » s’était transformé en un labyrinthe de sélecteurs XPath, de problèmes de pagination et de débogage sans fin. Si vous avez déjà essayé de manipuler des données web avec du code, vous connaissez sans doute ce sentiment : à la fois exaltant et « pourquoi est-ce si compliqué ? »
Voici l’essentiel : le web scraping n’est plus réservé aux data scientists ou aux ingénieurs. C’est devenu une compétence incontournable pour les équipes commerciales, les responsables e-commerce, les marketeurs et toute personne qui veut transformer le chaos du web en intelligence métier. En fait, le marché des logiciels d’extraction Web a atteint 1,01 milliard de dollars en 2024 et devrait atteindre 2,49 milliards de dollars d’ici 2032, et la courbe ne ralentit pas. Mais si Python et des frameworks comme Scrapy restent la référence pour les extractions personnalisées à grande échelle, ils ne sont pas vraiment pensés pour les débutants. C’est pourquoi, dans ce tutoriel, je vais vous guider pas à pas dans Scrapy — à partir d’un cas d’usage réel sur Amazon — et vous montrer une alternative bien plus simple, propulsée par l’IA, pour ceux qui ne codent pas : Thunderbit.
Qu’est-ce que Scrapy Python ? Votre outil de web scraping surpuissant
Commençons par les bases. Scrapy est un framework Python open source conçu spécifiquement pour l’exploration et l’extraction de données web. Voyez-le comme une boîte à outils tout-en-un pour créer des spiders personnalisés (c’est ainsi que Scrapy appelle ses robots d’exploration) capables de naviguer sur des sites web, suivre des liens, gérer la pagination et extraire des données structurées à grande échelle.
En quoi Scrapy diffère-t-il d’un simple usage de requests et BeautifulSoup en Python ? Ces bibliothèques sont très bien pour des extractions simples et ponctuelles, mais Scrapy est pensé pour des projets grands et complexes — ceux où vous devez :
- Parcourir des milliers de pages (par exemple, chaque produit d’un catalogue e-commerce)
- Suivre automatiquement les liens et gérer la pagination
- Traiter les données en asynchrone pour gagner en vitesse
- Structurer, nettoyer et exporter les données de manière reproductible
En bref, Scrapy est un peu le couteau suisse du web scraping : puissant, flexible et, qu’on le veuille ou non, un peu intimidant pour les débutants.
Pourquoi utiliser Scrapy Python pour le web scraping ?
Alors, pourquoi les développeurs et les équipes data reviennent-ils sans cesse vers Scrapy ? Voici ce qui le distingue :
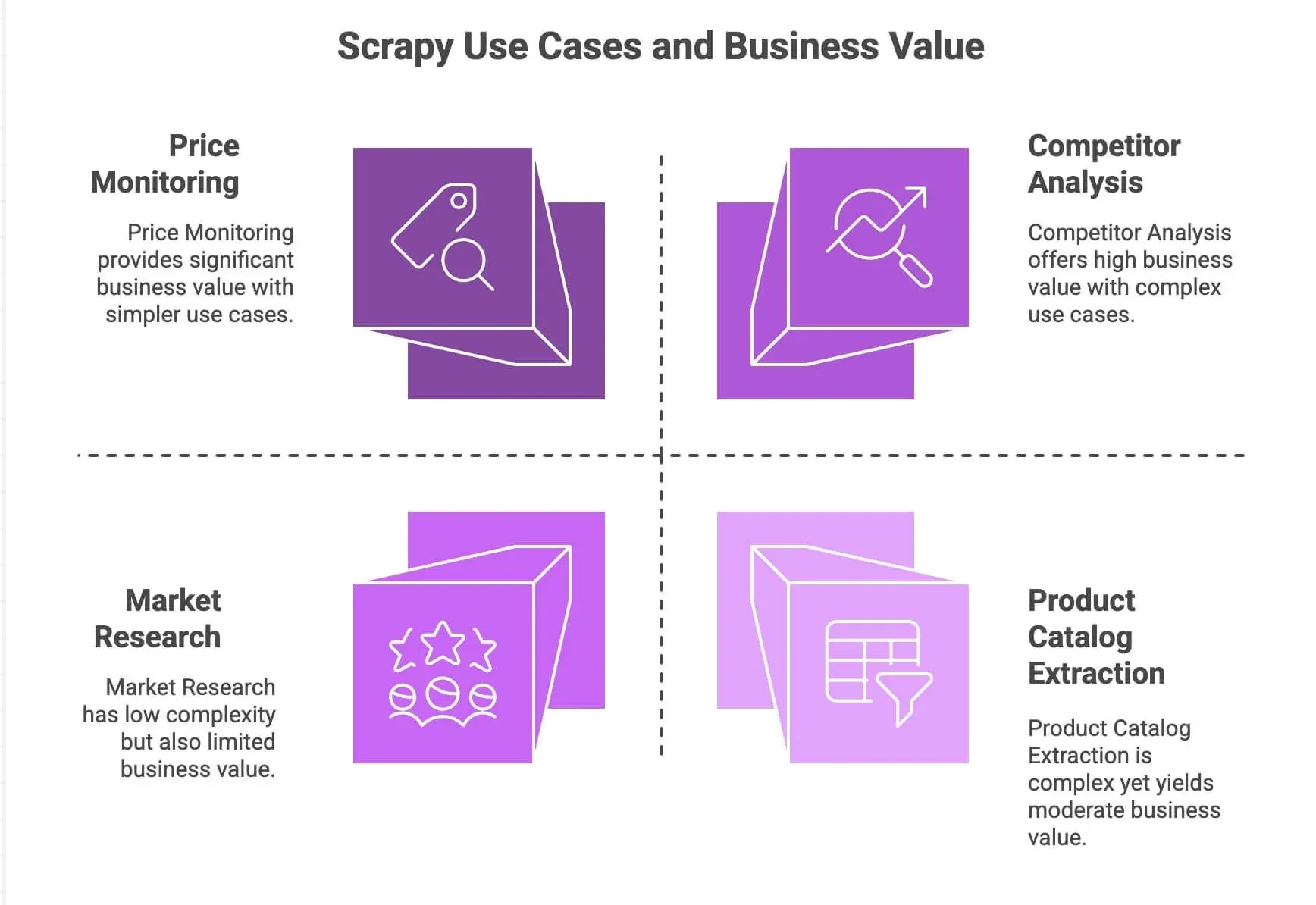
| Cas d’usage | Points forts de Scrapy | Valeur business |
|---|---|---|
| Suivi des prix | Gère la pagination, les requêtes asynchrones et la planification | Gardez une longueur d’avance sur la concurrence, tarification dynamique |
| Extraction de catalogues produits | Suit les liens, extrait des données structurées | Créez des bases produits, alimentez vos analyses |
| Analyse concurrentielle | Scalable, robuste face aux changements de site | Suivez les tendances, les nouveaux lancements, les niveaux de stock |
| Études de marché | Pipelines modulaires pour nettoyer et transformer les données | Agrégez les avis, lancez des analyses de sentiment |
Le moteur asynchrone de Scrapy (basé sur Twisted) lui permet de récupérer plusieurs pages en parallèle, ce qui le rend rapide et scalable. Sa conception modulaire vous permet d’ajouter une logique personnalisée (comme des proxys, des user-agents ou des étapes de nettoyage de données). Et avec les pipelines, vous pouvez traiter, valider et exporter les données comme vous le souhaitez — CSV, JSON, bases de données, tout ce que vous voulez.
Pour des équipes qui maîtrisent Python, Scrapy est une vraie machine de guerre. Mais soyons honnêtes : ce n’est pas exactement du « plug and play » pour l’utilisateur métier moyen.
Configurer votre environnement Scrapy Python
Prêt à mettre les mains dans le cambouis ? Voici comment installer Scrapy à partir de zéro :
1. Installer Scrapy
D’abord, assurez-vous d’avoir Python 3.10 ou plus récent installé (Scrapy 2.15.x a abandonné la prise en charge de Python 3.9 en 2026). Puis ouvrez votre terminal et lancez :
pip install scrapy
Vérifiez l’installation avec :
scrapy version
Si vous êtes sous Windows ou que vous utilisez Anaconda, vous aurez peut-être intérêt à créer un environnement virtuel pour éviter les conflits. Scrapy fonctionne sur Windows, macOS et Linux.
2. Créer un nouveau projet Scrapy
Lançons un nouveau projet appelé amazonscraper :
scrapy startproject amazonscraper
Vous obtiendrez une arborescence de dossiers comme celle-ci :
amazonscraper/
├── scrapy.cfg
├── amazonscraper/
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── middlewares.py
│ ├── settings.py
│ └── spiders/
À quoi servent ces fichiers ?
scrapy.cfg: configuration du projet (vous y touchez rarement)items.py: définition de vos modèles de données (par exemple un produit avec son nom, son prix, etc.)pipelines.py: là où vous nettoyez, validez et exportez vos donnéesmiddlewares.py: fonctionnalités avancées (proxys, en-têtes personnalisés)settings.py: réglages du comportement de Scrapy (concurrence, délais, etc.)spiders/: l’endroit où réside votre logique d’extraction
Si vous vous sentez déjà un peu dépassé, vous n’êtes pas seul. C’est souvent à ce stade que beaucoup de non-codeurs commencent à transpirer.
Créer un scraper Python : extraire des données produit Amazon avec Scrapy
Prenons un exemple concret : extraire des données produit depuis les résultats de recherche Amazon. (Attention : les conditions d’utilisation d’Amazon n’autorisent pas l’extraction, et leurs mécanismes anti-bot sont agressifs. Ceci est à des fins pédagogiques uniquement !)
1. Créer un spider
Dans le dossier spiders/, créez un fichier appelé amazon_spider.py :
import scrapy
class AmazonSpider(scrapy.Spider):
name = "amazon_example"
allowed_domains = ["amazon.com"]
start_urls = ["https://www.amazon.com/s?k=smartphones"]
def parse(self, response):
products = response.xpath("//div[@data-component-type='s-search-result']")
for product in products:
yield {
'name': product.xpath(".//span[@class='a-size-medium a-color-base a-text-normal']/text()").get(),
'price': product.xpath(".//span[@class='a-price-whole']/text()").get(),
'rating': product.xpath(".//span[@aria-label]/text()").get()
}
next_page = response.xpath("//li[@class='a-last']/a/@href").get()
if next_page:
yield scrapy.Request(url=response.urljoin(next_page), callback=self.parse)
Que se passe-t-il ici ?
- Nous commençons sur une page de résultats Amazon pour « smartphones ».
- Pour chaque produit, nous extrayons le nom, le prix et la note à l’aide de sélecteurs XPath.
- Nous cherchons le lien de la « page suivante » et demandons à Scrapy de le suivre pour récupérer d’autres produits.
2. Exécuter votre spider
Depuis la racine de votre projet, lancez :
scrapy crawl amazon_example -o products.json
Et voilà — Scrapy parcourt les résultats, suit la pagination et enregistre vos données dans un fichier JSON.
Gestion de la pagination et du contenu dynamique
La prise en charge intégrée par Scrapy du suivi des liens et de la pagination fait partie de ses superpouvoirs. Mais qu’en est-il du contenu dynamique — ces pages qui chargent des données via JavaScript ? Par défaut, Scrapy ne voit que le HTML statique. Si vous devez extraire du contenu chargé par JavaScript (comme le défilement infini ou des avis qui s’ouvrent en pop-up), il faudra l’intégrer à des outils comme Selenium ou Splash. C’est un autre tunnel sans fin.
Traiter et exporter des données avec Scrapy Python
Une fois vos données extraites, vous voudrez probablement les nettoyer et les exporter vers un emplacement utile.
- Pipelines : dans
pipelines.py, vous pouvez écrire des classes Python pour nettoyer, valider ou enrichir vos données (par exemple convertir les prix en nombres, supprimer les lignes incomplètes, ou même appeler une API de traduction). - Export : Scrapy peut exporter directement vers CSV, JSON ou XML avec l’option
-o. Pour des exports plus avancés (comme l’envoi vers Google Sheets), vous devrez écrire du code supplémentaire ou utiliser des bibliothèques tierces.
Vous voulez faire de l’analyse de sentiment ou traduire des descriptions produit ? Il faudra intégrer des API externes ou des bibliothèques Python — rien de tout cela n’est inclus nativement.
Les coûts cachés : les défis de Scrapy Python pour les utilisateurs métier
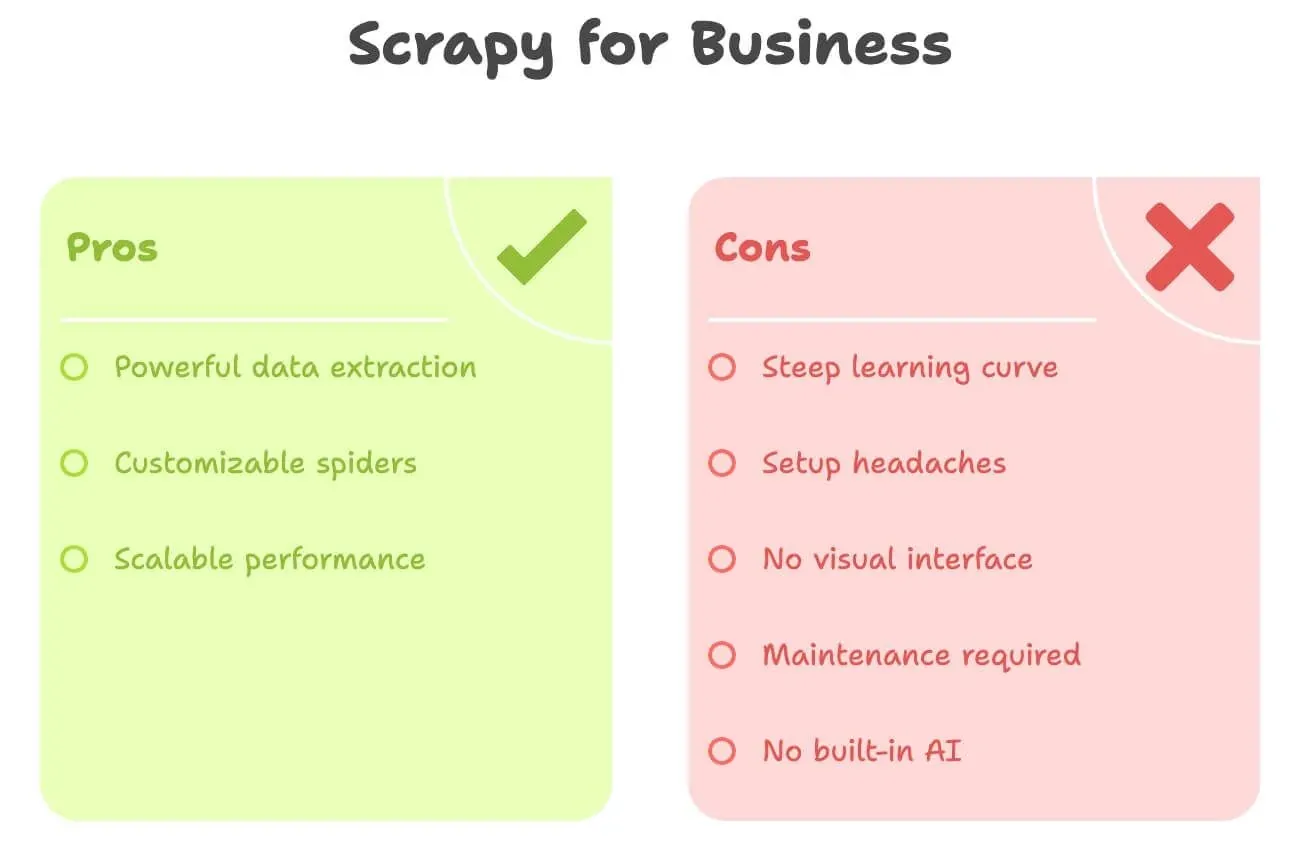
Soyons francs : Scrapy est puissant, mais il n’est pas vraiment pensé pour les non-développeurs. Voici ce qui bloque le plus souvent les utilisateurs métier :
- Courbe d’apprentissage abrupte : il faut connaître Python, HTML, les sélecteurs XPath/CSS et la structure de projet de Scrapy. Il faut parfois des jours, voire des semaines, pour être à l’aise.
- Installation fastidieuse : installer Python, gérer les dépendances et résoudre les erreurs peut vite devenir pénible — surtout sous Windows.
- Aucune interface visuelle : tout se fait par le code. Impossible de cliquer simplement sur une page pour sélectionner des données.
- Maintenance : si le site change, votre spider casse. C’est à vous de le réparer.
- Pas d’IA intégrée : vous voulez traduire, résumer ou analyser le sentiment ? Il faut ajouter du code.
Voici une comparaison rapide :
| Défi | Scrapy (Python) | Besoin de l’utilisateur métier |
|---|---|---|
| Codage requis | Oui | Préférence pour le no-code |
| Temps de configuration | Heures (ou jours) | Minutes |
| Maintenance | Continue (si le site change) | Minimale |
| Export des données | CSV/JSON (intégration manuelle) | Export direct vers Excel/Sheets/Notion |
| Fonctionnalités IA | Aucune (intégration DIY) | Traduction/analyse de sentiment intégrées |
Si vous êtes marketeur solo, commercial ou responsable des opérations, Scrapy peut donner l’impression d’apporter un bazooka à une bataille de ballons d’eau.
Découvrez Thunderbit : l’alternative sans code à Scrapy Python
C’est là qu’intervient Thunderbit. En tant que personne ayant passé des années à construire des outils d’automatisation, je peux vous le dire : la plupart des utilisateurs métier ne veulent pas coder — ils veulent juste la donnée, vite.
Thunderbit est un extracteur Web IA proposé sous forme d’extension Chrome. Il est conçu pour les utilisateurs non techniques qui veulent :
- Extraire des données de n’importe quel site en quelques clics
- Décrire ce qu’ils veulent en langage naturel (« Nom du produit, prix, note »)
- Gérer automatiquement la pagination et les sous-pages
- Exporter les données directement vers Excel, Google Sheets, Airtable ou Notion
- Traduire, résumer ou analyser le sentiment à la volée
Pas de Python. Pas de sélecteurs. Pas de galères de maintenance.
Comment extraire n’importe quel site web avec l’IA Get Started Free
Thunderbit est conçu pour les utilisateurs métier qui veulent aller vite et laisser l’IA faire le gros du travail.
Thunderbit vs. Scrapy Python : comparaison côte à côte
Mettons-les face à face :
| Aspect | Scrapy (Python) | Thunderbit (outil IA) |
|---|---|---|
| Compétences requises | Python, HTML, sélecteurs | Aucune — point and click, langage naturel |
| Temps de configuration | Heures (installation, code, débogage) | Minutes (installer l’extension Chrome, se connecter) |
| Structuration des données | Manuelle (définir items, pipelines) | L’IA détecte automatiquement les colonnes et suggère des champs |
| Pagination / sous-pages | Code requis | En 1 clic (géré par l’IA) |
| Traduction | Code personnalisé ou intégration d’API | Intégrée — il suffit d’activer « Traduire » |
| Analyse de sentiment | Bibliothèque/API externe | Intégrée — ajoutez une colonne « Sentiment » |
| Options d’export | CSV/JSON (import manuel vers Sheets/Excel) | Export en 1 clic vers Excel, Google Sheets, Airtable, Notion |
| Maintenance | Manuelle (mettre à jour le code si le site change) | L’IA s’adapte automatiquement aux changements mineurs du site |
| Échelle | Idéal pour les projets volumineux et continus | Idéal pour les tâches rapides, à échelle modérée (centaines/milliers de lignes) |
| Coût | Gratuit (mais coûte du temps et des ressources développeur) | Version gratuite + offres payantes (à partir de 9 $/mois, mais énormément de temps et de stress économisés) |
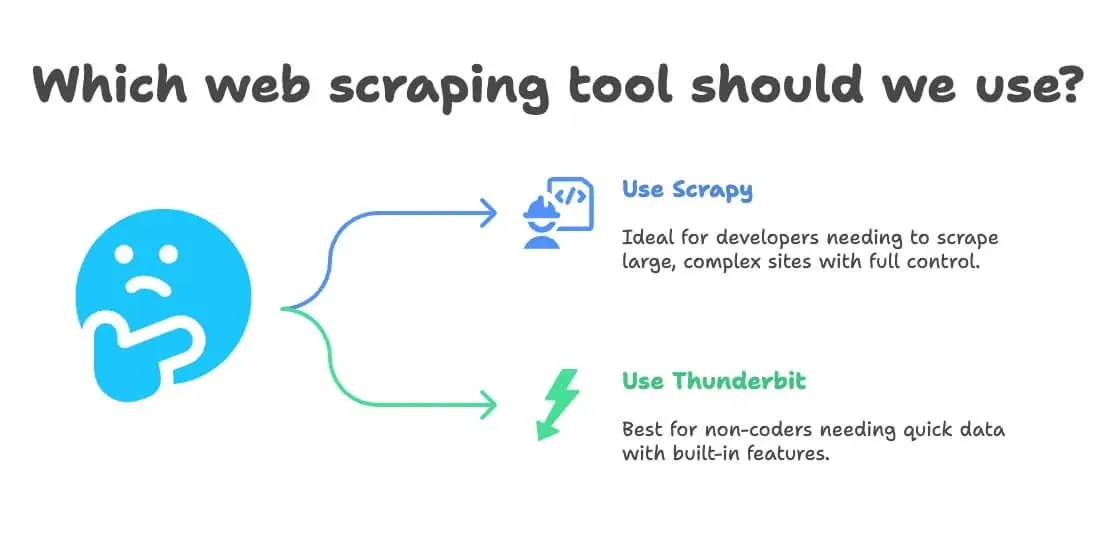
Quand choisir Scrapy Python ou Thunderbit pour le web scraping ?
Voici ma règle simple :
- Choisissez Scrapy si :
- Vous êtes développeur ou en avez un dans votre équipe
- Vous devez extraire des dizaines de milliers de pages, ou construire un pipeline personnalisé et continu
- Le site est très complexe ou nécessite une logique avancée
- Vous voulez un contrôle total (et la maintenance ne vous dérange pas)
- Choisissez Thunderbit si :
- Vous ne codez pas (ou n’en avez pas envie)
- Vous avez besoin de données rapidement, pour une tâche ponctuelle ou récurrente
- Vous voulez la traduction, le sentiment ou l’enrichissement de données intégrés
- Vous privilégiez la vitesse et la flexibilité plutôt que la personnalisation brute
Voici un petit arbre de décision :
- Savez-vous coder en Python ?
- Oui → Scrapy ou Thunderbit (pour des résultats rapides)
- Non → Thunderbit
- Votre projet est-il énorme et continu ?
- Oui → Scrapy
- Non → Thunderbit
- Avez-vous besoin de traduction ou d’analyse de sentiment ?
- Oui → Thunderbit
- Non → L’un ou l’autre
Étape par étape : extraire des données produit Amazon avec Thunderbit (sans code)
Refaisons notre exemple Amazon — cette fois, de la manière la plus simple.
1. Installer Thunderbit
- Téléchargez l’extension Chrome Thunderbit
- Inscrivez-vous (version gratuite disponible)
Essayer gratuitement l’extension Chrome Thunderbit
2. Aller sur Amazon et rechercher votre produit
- Ouvrez Amazon.com et recherchez « laptops » (ou tout autre produit)
3. Lancer Thunderbit sur la page
- Cliquez sur l’icône Thunderbit dans votre navigateur
- Le panneau latéral s’ouvre et reconnaît la page Amazon
4. Utiliser la suggestion de champs par l’IA
- Cliquez sur « Suggestion de champs IA »
- L’IA de Thunderbit analyse la page et suggère des colonnes comme « Nom du produit », « Prix », « Note », « Nombre d’avis »
- Ajoutez ou supprimez des colonnes selon vos besoins (vous voulez « URL du produit » ou « éligibilité Prime » ? Il suffit de le saisir)
5. Activer la pagination et l’extraction des sous-pages
- Activez Pagination : Thunderbit cliquera automatiquement sur « Suivant » et extraira toutes les pages
- Activez l’extraction des sous-pages : Thunderbit visitera la page de détail de chaque produit et récupérera des informations supplémentaires (comme des descriptions ou des numéros ASIN)
6. Lancer l’extraction
- Cliquez sur Extraire
- Regardez Thunderbit collecter les données en temps réel, page par page
7. Traduire et analyser le sentiment (facultatif)
- Vous voulez traduire des descriptions produit ? Activez « Traduire » pour cette colonne
- Vous voulez analyser le sentiment des avis ? Ajoutez une colonne « Sentiment » — l’IA de Thunderbit la remplira
8. Exporter vos données
- Cliquez sur Exporter
- Choisissez Excel, Google Sheets, Airtable ou Notion
- Vos données sont prêtes à l’emploi — pas d’import manuel, pas de manipulation de CSV
9. Planifier des extractions récurrentes (facultatif)
- Mettez en place une planification (par exemple, tous les jours à 8 h)
- Thunderbit exécutera l’extraction automatiquement et mettra à jour la destination choisie
C’est tout. Pas de code, pas de sélecteurs, pas de maintenance. Juste des données, prêtes pour l’entreprise.
Astuces bonus : tirer davantage de vos projets de web scraping
Que vous utilisiez Scrapy, Thunderbit ou un autre outil, voici quelques bonnes pratiques que j’ai apprises à la dure :
- Validez vos données : vérifiez toujours les valeurs manquantes ou étranges (comme des prix à 0 $ ou des noms vides)
- Restez conforme : vérifiez les conditions d’utilisation du site, respectez
robots.txtet ne surchargez pas les serveurs - Automatisez intelligemment : utilisez la planification pour garder les données à jour, mais n’extrayez pas plus souvent que nécessaire
- Tirez parti des outils gratuits : Thunderbit inclut des extracteurs d’e-mails, de téléphones et d’images gratuits — idéal pour la génération de leads ou la curation de contenu
- Organisez pour l’analyse : exportez directement vers Sheets/Excel afin de filtrer, croiser et visualiser rapidement
Pour plus de conseils, consultez le blog de Thunderbit ou leur guide pour extraire n’importe quel site web avec l’IA.
Comment extraire des données de sites web vers Excel avec l’IA Get Started Free
Pour plus de conseils, consultez le blog de Thunderbit ou leur guide pour extraire n’importe quel site web avec l’IA.
Conclusion : le web scraping simplifié — choisissez le bon outil pour votre équipe
En résumé : Scrapy est une machine de guerre pour les développeurs, mais il est excessif pour la plupart des utilisateurs métier. Si vous êtes à l’aise avec Python et que vous devez construire un extracteur personnalisé à grande échelle, Scrapy est un excellent choix. Mais si vous voulez aller vite, éviter le code et obtenir des données avec la traduction et l’analyse de sentiment intégrées, Thunderbit est la solution qu’il vous faut.
J’ai vu de première main à quel point Thunderbit fait gagner du temps et évite de la frustration aux équipes non techniques. Vous pouvez passer de « J’aimerais avoir ces données » à « elles sont dans mon tableur » en quelques minutes, pas en heures ni en jours. Et avec des fonctionnalités comme la suggestion de champs par IA, l’extraction des sous-pages et les exportations en un clic, il n’a jamais été aussi simple de transformer le web en intelligence métier.
Alors, la prochaine fois que vous devrez extraire des données produit, surveiller des prix ou constituer une liste de prospects, demandez-vous : voulez-vous écrire du Python, ou voulez-vous des résultats ? Essayez la version gratuite de Thunderbit et voyez à quel point le web scraping peut être plus simple.
Essayer Thunderbit gratuitement
Curieux d’en savoir plus ? Consultez le site officiel de Thunderbit, téléchargez l’extension Chrome ou approfondissez les bonnes pratiques du web scraping sur le blog Thunderbit.
Lectures complémentaires :
- Qu’est-ce que l’extraction de données et comment la faire en 2026
- Comment extraire des données de sites web vers Excel avec l’IA
- Les meilleurs outils et logiciels de web scraping en 2026
- Rapport sur l’état du web scraping
Avertissement : assurez-vous toujours que vos activités de web scraping respectent les conditions d’utilisation des sites et les lois locales. En cas de doute, consultez un avocat — personne ne veut être ce « scraper » qui reçoit une mise en demeure à cause d’un tableur.
Rédigé par Shuai Guan, cofondateur et PDG de Thunderbit. J’ai passé des années dans le SaaS, l’automatisation et l’IA — pour que vous n’ayez pas à le faire.
Essayer l’Extracteur Web IA Get Started Free




