est une extension Chrome d’Extracteur Web IA qui aide les équipes métier à extraire des données de sites web grâce à l’IA. Le vrai point sensible, c’est le suivant : ce qui semble abordable sur la page tarifaire de ScrapingBee peut changer du tout au tout dès que vous passez en production et que vous voyez les crédits fondre à une vitesse de 5× à 75× le tarif de base. Cet avis passe en revue cinq angles souvent laissés de côté : le vrai coût à grande échelle, l’extraction par sélecteurs face à l’IA, l’ergonomie pour les non-développeurs, les workflows de données après extraction, et les benchmarks de fiabilité 2026. Si vous évaluez ScrapingBee pour votre équipe — que vous soyez développeur, responsable sales ops ou fondateur — voici l’analyse qu’il vous faut.
Qu’est-ce que ScrapingBee ? Aperçu rapide
ScrapingBee est une API de web scraping qui prend en charge la rotation des proxys, le rendu JavaScript et la gestion des CAPTCHA, afin que les développeurs puissent extraire des données de sites web sans monter leur propre infra de scraping. Vous envoyez une requête HTTP avec des paramètres, puis vous récupérez du HTML (ou du JSON pour certains endpoints). Il n’y a pas d’interface visuelle ni de système de clic pour construire les extractions.
Les principales fonctionnalités incluent :
- Proxys rotatifs et premium (classiques, premium, stealth, résidentiels)
- Rendu par navigateur headless (Chrome complet, activé par défaut)
- Contournement automatique des CAPTCHA
- Google Search API (JSON structuré : résultats organiques, annonces, cartes, knowledge graph, People Also Ask, images, actualités)
- Capture de captures d’écran (standard, pleine page ou ciblée par sélecteur CSS)
- Ciblage géographique via le paramètre
country_code - Règles d’extraction CSS/XPath (JSON déclaratif, renvoie du JSON structuré)
- APIs dédiées pour scraper Amazon, Walmart, YouTube et ChatGPT
- Extraction IA (ajoutée vers 2024–2025) : paramètres
ai_query,ai_extract_rules,ai_selector(+5 crédits par requête) - Outil CLI (lancé vers 2025–2026) : traitement par lot, crawling, parsing de sitemap, enrichissement CSV, tâches cron planifiées, montée en gamme de proxy
Fondée en 2019 en France, ScrapingBee a atteint environ début 2026 avec plus de 2 500 clients (SAP, Zapier, Deloitte, Zillow) — le tout en bootstrap avec une équipe de 4 à 6 personnes. En juin 2025, dans une opération à huit chiffres. La marque et le leadership restent indépendants, et l’équipe support a pour mieux couvrir les fuseaux horaires.
Point important : ScrapingBee ne dispose toujours pas d’un builder visuel natif, d’une interface graphique en point-and-click, ni d’un planificateur intégré dans un tableau de bord web. La planification passe par l’outil CLI, des jobs cron ou des automatisations tierces (Zapier, Make, n8n). Les guides « no-code » qu’ils publient concernent l’utilisation des intégrations Make et Zapier — pas une interface no-code native.
À qui ScrapingBee s’adresse-t-il vraiment ?
ScrapingBee est pensé pour des développeurs à l’aise avec Python ou cURL, la lecture du HTML et la création de sélecteurs CSS/XPath. La documentation est très orientée code, avec une grosse place donnée aux exemples en Python et en cURL. Un utilisateur sur a indiqué qu’ils « ne fournissent pas d’exemples en JavaScript », et un autre a décrit la doc comme « volumineuse, il faut une journée à une semaine pour tout lire ».
Mais le public qui cherche « avis ScrapingBee » en 2026 va bien au-delà des ingénieurs backend. Il comprend des responsables marketing qui montent des listes de prospects, des équipes sales ops qui enrichissent des données CRM, des équipes e-commerce qui suivent les prix des concurrents, et des fondateurs qui comparent des outils pour leurs équipes. Dans chaque section ci-dessous, je préciserai si la fonctionnalité ou la limite concerne les développeurs, les utilisateurs métier, ou les deux.
Les tarifs de ScrapingBee en un coup d’œil
Voici les offres actuelles de ScrapingBee (en avril 2026) :
| Offre | Prix mensuel | Crédits API/mois | Requêtes simultanées |
|---|---|---|---|
| Freelance | 49 $ | 250 000 | 10 |
| Startup | 99 $ | 1 000 000 | 50 |
| Business | 249 $ | 3 000 000 | 100 |
| Business+ | 599 $ | 8 000 000 | 200 |
| Enterprise | Contacter les ventes | 41 M+ | Personnalisé |
La facturation annuelle offre . Un essai gratuit fournit 1 000 crédits API sans carte bancaire. L’API Google Search a récemment été par appel après l’acquisition.
Sur le papier, ces chiffres de crédits semblent généreux. Mais ils ne racontent pas toute l’histoire.
Le tableau des multiplicateurs de crédits
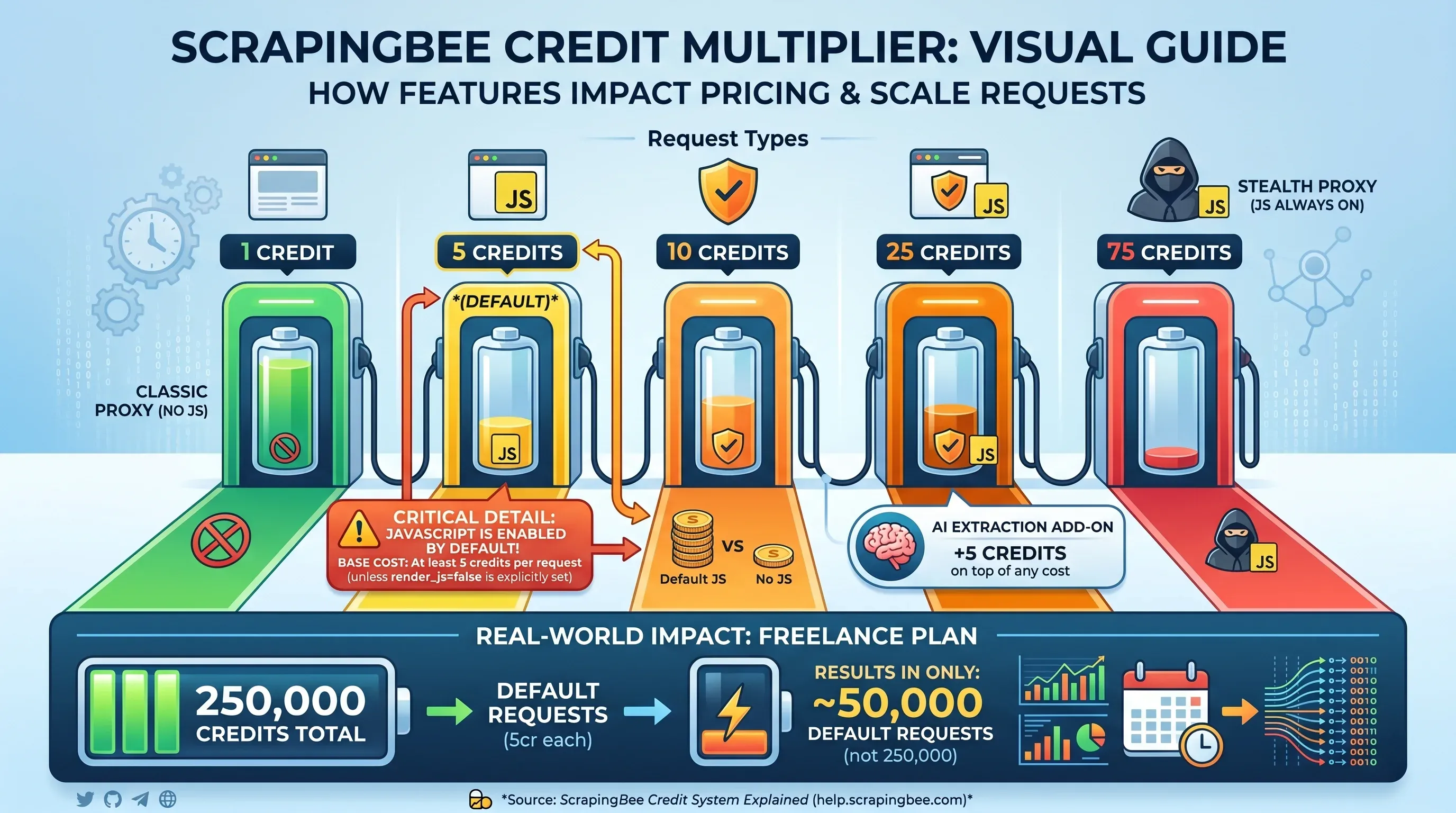
C’est là que les tarifs de ScrapingBee deviennent plus complexes. Le nombre de crédits affiché ne correspond pas au nombre de pages que vous pouvez scraper — tout dépend des options activées à chaque requête :
| Type de requête | Crédits par requête |
|---|---|
Proxy classique, sans rendu JS (render_js=false) | 1 crédit |
| Proxy classique, rendu JS (par défaut) | 5 crédits |
| Proxy premium, sans rendu JS | 10 crédits |
| Proxy premium, rendu JS | 25 crédits |
| Proxy stealth (JS toujours actif) | 75 crédits |
| Option d’extraction IA | +5 crédits en plus |
Point crucial : le rendu JavaScript est . Si vous ne définissez pas explicitement render_js=false, chaque requête coûte au minimum 5 crédits. Résultat : les 250 000 crédits de l’offre Freelance couvrent en réalité seulement 50 000 requêtes par défaut — et non 250 000.
Le calcul caché des crédits que personne ne montre
Voici ce que coûte réellement ScrapingBee pour 10 000 pages selon différents scénarios et niveaux d’offre :
| Scénario | Crédits nécessaires | Freelance (49 $/250K) | Startup (99 $/1M) | Business (249 $/3M) |
|---|---|---|---|---|
| 10K pages (HTML statique, 1 cr) | 10 000 | ✅ Couvert (0,20 $/1K) | ✅ Couvert (0,10 $/1K) | ✅ Couvert (0,08 $/1K) |
| 10K pages (rendu JS, 5 cr) | 50 000 | ✅ Couvert (0,98 $/1K) | ✅ Couvert (0,50 $/1K) | ✅ Couvert (0,42 $/1K) |
| 10K pages (proxy premium + JS, 25 cr) | 250 000 | ⚠️ Exactement à la limite (4,90 $/1K) | ✅ Couvert (2,48 $/1K) | ✅ Couvert (2,08 $/1K) |
| 10K pages (proxy stealth, 75 cr) | 750 000 | ❌ Bien au-delà de la limite | ✅ Juste couvert (7,43 $/1K) | ✅ Couvert (6,23 $/1K) |
Les mêmes 10 000 pages peuvent donc coûter entre 0,20 $ et 7,43 $ pour mille selon la configuration du proxy et du rendu. Et vous ne savez pas toujours quelle configuration il vous faut avant d’avoir testé.
Scénario budget : génération de leads à 10 000 pages/mois
Une équipe commerciale scrape 10 000 pages d’entreprises par mois pour générer des leads. La plupart des sites B2B modernes utilisent React ou Vue, donc le rendu JS est nécessaire :
- Crédits nécessaires : 50 000 (10K × 5 crédits)
- Offre Freelance (49 $) : couvre le besoin avec 200K crédits restants
- Mais si les cibles exigent des proxys premium : 250 000 crédits — exactement l’allocation d’une offre Freelance, sans marge
- Si des proxys stealth sont nécessaires : 750 000 crédits — il faut l’offre Startup à 99 $/mois
Scénario budget : surveillance des prix e-commerce à 100 000 pages/mois
Une équipe e-commerce surveille 100 000 pages produit sur les sites concurrents :
| Configuration | Crédits nécessaires | Offre requise | Coût mensuel |
|---|---|---|---|
| HTML statique (1 cr) | 100 000 | Freelance | 49 $ |
| Rendu JS (5 cr) | 500 000 | Startup | 99 $ |
| Proxy premium + JS (25 cr) | 2 500 000 | Business | 249 $ |
| Proxy stealth (75 cr) | 7 500 000 | Business+ | 599 $ |
Le même travail passe de 49 $ à 599 $/mois. Ce n’est pas juste une variation : c’est un écart de coût de 12× selon la configuration.
« Le prix d’entrée à 49 $ est le chiffre le plus trompeur du marché des API de scraping. » —
« Les crédits sont consommés très vite dès qu’on utilise le rendu JavaScript ou des fonctionnalités avancées, ce qui rend l’outil plus difficile à justifier pour les petits projets ou les équipes avec des volumes imprévisibles. » — Nick S, Manager, Computer Software,
Et les crédits non utilisés d’un mois sur l’autre.
Comment les coûts de ScrapingBee se comparent à ceux des concurrents

En prenant des offres de milieu de gamme pour une comparaison équitable :
| Scénario (pour 1K pages) | ScrapingBee (99 $/1M) | ScraperAPI (149 $/1M) | Scrapfly (100 $/1M) |
|---|---|---|---|
| HTML statique | 0,10 $ | 0,15 $ | 0,10 $ |
| Pages rendues en JS | 0,50 $ | 1,64 $ | 0,60 $ |
| Premium + JS | 2,48 $ | 3,73 $ | 3,00 $ |
| Stealth/ultra premium + JS | 7,43 $ | 11,18 $ | N/A |
ScrapingBee est généralement le moins cher, ou à égalité avec le moins cher, pour les pages statiques et rendues en JS. est systématiquement le plus cher — son rendu JS coûte +10 crédits contre +5 pour ScrapingBee et Scrapfly. Mais des tests indépendants de racontent une autre histoire quand on prend en compte la complexité réelle des sites :
| Service | Coût moyen pour 1K requêtes | Taux de réussite | Temps de réponse moyen |
|---|---|---|---|
| Scrape.do | 0,80 $ | 98,19 % | 4,7 s |
| ScrapingBee | 3,90 $ | 92,69 % | 11,7 s |
| Scrapfly | 4,11 $ | — | — |
| ZenRows | 4,48 $ | 92,64 % | 10,0 s |
| ScraperAPI | 8,49 $ | 92,70 % | 15,7 s |
Le modèle de crédits de Thunderbit : une approche différente
utilise un modèle tarifaire beaucoup plus simple : 1 crédit = 1 ligne de sortie, sans multiplicateurs liés au rendu JS, au type de proxy ou au domaine cible. Le scraping de sous-pages coûte 2 crédits par ligne.
| Offre | Prix mensuel | Crédits | Coût par ligne |
|---|---|---|---|
| Free | 0 $ | 6 pages/mois | Gratuit |
| Starter | 15 $ | 500 | 0,030 $ |
| Pro 1 | 38 $ | 3 000 | 0,013 $ |
| Pro 2 | 75 $ | 6 000 | 0,013 $ |
| Pro 3 | 125 $ | 10 000 | 0,013 $ |
| Pro 4 | 249 $ | 20 000 | 0,012 $ |
Un utilisateur Thunderbit qui extrait 10 000 fiches produit depuis des sites e-commerce lourds en JavaScript paie 125 $/mois, que ces sites exigent ou non du rendu JavaScript, des proxys premium ou du contournement anti-bot. Avec ScrapingBee, le même travail peut coûter de 49 $ à 599 $ selon la configuration. La prévisibilité budgétaire, ça change tout.
Sélecteurs CSS vs extraction IA : le coût de maintenance à connaître
La plupart des avis sur ScrapingBee passent complètement à côté de ce point. Pourtant, c’est sans doute la question la plus importante si vous comptez scraper à grande échelle pendant des mois ou des années.
ScrapingBee s’appuie sur des sélecteurs CSS/XPath pour extraire les données du HTML. Vous définissez des règles d’extraction sous forme d’objets JSON avec des sélecteurs CSS, puis ScrapingBee renvoie les données correspondantes. Ça fonctionne bien au départ. Le vrai sujet, c’est la suite.
Le problème des sélecteurs qui cassent
Quand un site cible change sa mise en page — noms de classes, structure DOM, version du framework — vos sélecteurs CSS cessent de fonctionner. Dans des systèmes de scraping matures qui gèrent plus de 2 500 jobs actifs, des recherches montrent un , ce qui impose 30 à 35 correctifs par semaine juste pour garder les extracteurs en état. Pour des organisations qui scrapent 50 sites, la maintenance annuelle représente 850 à 1 300 heures, soit 64 000 à 156 000 $ au coût complet d’un ingénieur.
Les équipes sous-estiment presque toujours ce point. Les estimations de départ parlent généralement de 10 à 15 heures de maintenance par mois, mais la réalité est (40 à 90 heures/mois). Une seule panne silencieuse — quand un sélecteur casse mais continue à renvoyer des données vides sans alerter personne — coûte environ 38 000 à 57 000 $ en ventes perdues, récupération de classement et temps humain.
Les causes les plus fréquentes : renommage de classes CSS lors de mises à jour de framework, ajout de nouveaux conteneurs autour des éléments ciblés, mises à niveau React/Vue/Angular qui restructurent le DOM, tests A/B avec classes dynamiques, et obfuscation anti-scraping.
L’extraction par IA réduit la maintenance de 60 à 80 %
Une étude DataRobot de 2025 a montré que les extracteurs pilotés par l’IA nécessitent que les extracteurs traditionnels basés sur des sélecteurs après une refonte de site. La répartition du temps s’en trouve presque inversée :
| Indicateur | Traditionnel (sélecteurs CSS) | Piloté par l’IA | |---|---|---|---| | Maintenance après refonte | Référence | 70 % de moins | | Répartition du temps (mise en place : maintenance) | 20 % : 80 % | 5 % : 95 % selon les données | | Réduction globale de maintenance | Référence | 60–80 % de réduction | | Vitesse sur pages lourdes en JS | Référence | 30–40 % plus rapide |
Temps de configuration : écrire des sélecteurs vs champs suggérés par l’IA
Configuration ScrapingBee : inspecter le code source → repérer les sélecteurs CSS → écrire les règles d’extraction en JSON → tester et déboguer → gérer les cas particuliers selon les variations de pages → surveiller les cassures → corriger les sélecteurs quand les sites se mettent à jour.
Configuration Thunderbit : ouvrir la page dans Chrome → cliquer sur « AI Suggest Fields » → l’IA lit la page et propose des colonnes avec les bons types de données → cliquer sur « Scrape ». Pas d’écriture de sélecteurs, pas d’inspection du code source. L’IA de Thunderbit s’appuie sur plusieurs modèles de fondation (ChatGPT, Gemini, Claude, DeepSeek R1) qui lisent les pages web visuellement, comme le ferait une personne.
Les de Thunderbit ajoutent une autre couche : chaque colonne peut recevoir une instruction IA personnalisée qui transforme les données pendant l’extraction — mise en forme des dates, traduction de texte, catégorisation des produits, découpage des noms, normalisation des numéros de téléphone. Cela élimine une étape de post-traitement que les utilisateurs de ScrapingBee doivent construire eux-mêmes.
Sortie structurée : HTML brut vs lignes prêtes à l’emploi
| Dimension | ScrapingBee (basé sur sélecteurs) | Thunderbit (piloté par l’IA) | |---|---|---|---| | Sortie par défaut | HTML brut | Lignes structurées avec colonnes typées | | Extraction structurée | Nécessite des règles CSS/XPath ou l’option IA (+5 crédits) | Détection automatique des champs par l’IA | | Types de données pris en charge | Texte (parsing HTML requis) | Texte, nombre, date, URL, email, téléphone, image | | Résilience aux changements de mise en page | ⚠️ Mises à jour manuelles des sélecteurs nécessaires | ✅ L’IA relit la page à chaque fois | | Compétences techniques requises | Python/cURL, sélecteurs CSS, compréhension du HTML | Aucune — extension Chrome en workflow 2 clics | | Maintenance dans le temps | Continue (taux de casse hebdomadaire de 1 à 2 %) | Minimale (l’IA s’adapte automatiquement) |
ScrapingBee a ajouté des fonctionnalités d’extraction IA (ai_query, ai_extract_rules) qui répondent en partie au problème de maintenance des sélecteurs. Mais cela ajoute +5 crédits par requête en plus du coût de base, et l’outil reste fondamentalement orienté API, sans interface visuelle.
ScrapingBee pour les non-développeurs : évaluation honnête de l’ergonomie
ScrapingBee n’est pas pensé pour les utilisateurs non techniques. C’est une API. Il faut écrire du code pour l’utiliser. Si tu es responsable marketing ou sales ops et que tu lis ceci, le message est clair.
Voici ce que vit concrètement un utilisateur non technique avec ScrapingBee :
- Écrire un appel API en Python, cURL ou dans un autre langage
- Comprendre les paramètres HTTP comme
render_js=true,premium_proxy=true,country_code=us - Parser les réponses HTML brutes avec une bibliothèque comme BeautifulSoup
- Écrire des sélecteurs CSS pour extraire des champs précis
- Gérer la pagination en construisant une logique de crawl personnalisée (ScrapingBee gère seulement les requêtes sur une page)
- Monter un pipeline de données pour nettoyer, structurer et stocker les données extraites
Il n’y a pas de builder glisser-déposer. Pas d’interface point-and-click. Pas d’aperçu visuel de ce que tu scrapes.
« Il y a une courbe d’apprentissage. Et la documentation est volumineuse, il faut une journée à une semaine pour la lire. » — Arvind K, Propriétaire, services financiers,
« Leur système est très particulier et il faut du temps pour apprendre leur code et leur structure. » —
Les développeurs adorent ça. Un utilisateur a décrit l’outil comme « entièrement basé API : très moderne et élégant : ça marche tout simplement ». Mais la « facilité d’utilisation » pour un développeur qui évalue une API n’est pas la même chose que la « facilité d’utilisation » pour quelqu’un qui essaie de monter une liste de prospects sans écrire de code.
Quand une alternative no-code est plus pertinente
propose une expérience fondamentalement différente :
- Ouvrir une page web dans Chrome avec l’extension installée
- Cliquer sur « AI Suggest Fields » — l’IA analyse la page et propose des colonnes (Product Name, Price, Rating, URL, etc.) avec les bons types de données
- Vérifier et personnaliser — ajouter, supprimer ou renommer des colonnes ; ajouter des Field AI Prompts pour transformer les données
- Cliquer sur « Scrape » — les données sont extraites en lignes structurées
- Exporter — en un clic vers Google Sheets, Airtable, Notion, Excel, CSV ou JSON (tous les exports sont gratuits)
Pas d’appel API, pas de sélecteurs, pas de code. Thunderbit prend en charge en avril 2026.
Pour les sites courants, Thunderbit propose aussi des — des modèles prêts à l’emploi et maintenus pour Amazon, Zillow, Shopify, LinkedIn, Google Maps, Instagram, eBay, Apollo, et plus encore. Tu n’as même pas besoin d’attendre que l’IA propose les champs ; le modèle est déjà prêt.
En plus, Thunderbit inclut plusieurs qui ne demandent aucun abonnement : extracteur d’email, extracteur de numéro de téléphone et extracteur d’images — pratique pour les équipes commerciales et marketing qui veulent simplement récupérer des données rapidement.
Grille de décision : qui devrait utiliser quoi
| Si vous êtes… | Meilleur choix |
|---|---|
| Développeur à l’aise avec les API et le parsing HTML | ScrapingBee ou ScraperAPI |
| Utilisateur technique qui veut des données structurées sans écrire de sélecteurs | API Thunderbit (endpoint Extract) |
| Utilisateur métier (sales, marketing, e-commerce) sans compétences en code | Extension Chrome Thunderbit |
| Équipe ayant besoin d’une surveillance planifiée sans DevOps | Thunderbit Scheduled Scraper (planification en langage naturel) |
| Construction de pipelines LLM/RAG nécessitant du markdown propre | Thunderbit Distill API ou Firecrawl |
| Vous voulez une prévisibilité budgétaire et aucun multiplicateur de crédits | Thunderbit (1 crédit = 1 ligne) |
Après le scraping : où vont réellement vos données ?
Le scraping n’est que la moitié du travail. L’autre moitié — faire arriver ces données là où elles servent vraiment — est l’endroit où la plupart des avis sur ScrapingBee deviennent silencieux.
ScrapingBee : HTML brut en sortie, pipeline à construire soi-même
ScrapingBee renvoie du HTML brut par défaut. Ensuite, vous devez :
- Parser le HTML avec BeautifulSoup ou lxml
- Retirer la navigation, les pieds de page, les scripts et les styles (qui représentent )
- Extraire les champs de données pertinents
- Convertir en formats structurés
- Gérer la pagination et les erreurs
- Stocker et diffuser les données
« ScrapingBee renvoie du HTML brut. Les agents IA ont besoin de markdown propre, de recherche sémantique et de webhooks. » —
ScrapingBee propose bien return_page_markdown=true et return_page_text=true comme alternatives optionnelles, et l’API Google Search renvoie du JSON structuré. Mais le workflow par défaut — et l’expérience de scraping généraliste — repose sur du HTML brut que vous devez traiter vous-même.
Les utilisateurs ont souvent besoin d’outils supplémentaires : BeautifulSoup/lxml pour le parsing, Pandas pour le nettoyage des données, cron/Airflow pour la planification, une logique de crawl personnalisée pour le scraping multi-page, et . C’est beaucoup d’ingénierie entre « j’ai extrait les données » et « je peux les utiliser ».
Thunderbit : sortie structurée avec export intégré
Thunderbit renvoie des lignes structurées avec des types de données définis (texte, nombre, date, URL, email, téléphone, image) prêtes à être exportées. Tous les exports sont gratuits, quelle que soit l’offre :
| Destination d’export | Coût |
|---|---|
| Excel (.xlsx) | Gratuit |
| Google Sheets | Gratuit (intégration directe) |
| Airtable | Gratuit (intégration directe) |
| Notion | Gratuit (intégration directe) |
| CSV | Gratuit |
| JSON | Gratuit |
Pour les équipes qui utilisent déjà Google Sheets ou Airtable comme CRM ou centre opérationnel, cela enlève une couche entière d’ingénierie. Lors de l’export vers Notion ou Airtable, les images sont téléversées dans la bibliothèque d’images pour s’afficher directement dans les fiches — un petit détail qui compte beaucoup en pratique.
L’écosystème d’intégrations de ScrapingBee
ScrapingBee propose bien des intégrations tierces : (plus de 8 000 connexions d’apps), (plus de 3 000 apps), n8n et Microsoft Power Automate. Elles peuvent faire le lien entre le HTML brut et vos outils cibles — mais elles ajoutent du coût, de la complexité et un point de défaillance supplémentaire.
Pour les développeurs : l’API ouverte de Thunderbit
Pour les lecteurs qui veulent quand même des pipelines programmatiques, Thunderbit propose une API ouverte avec deux endpoints clés :
- Endpoint Distill — convertit les pages en markdown propre, idéal pour les pipelines LLM/RAG (1 crédit par appel)
- Endpoint Extract — renvoie du JSON structuré correspondant à un schéma défini par l’utilisateur (20 crédits par appel)
- Traitement par lot — jusqu’à 100 URL par requête
Thunderbit sert donc à la fois les utilisateurs no-code (extension Chrome) et les développeurs (Open API) via le même moteur IA. Ne demandez pas seulement « est-ce qu’il scrape ? » — demandez aussi « où vont les données ? »
Vérification de fiabilité 2026 : ScrapingBee tient-il la route en production ?
D’anciens fils Reddit (2021–2023) contiennent des critiques sur la fiabilité de ScrapingBee. Est-ce encore représentatif en 2026 ? J’ai compilé des données provenant de six benchmarks indépendants. Les résultats sont mitigés — et parfois contradictoires.
Benchmark bimensuel Scrapeway (avril 2026)
Globalement : — 7e sur 9 services testés.
| Site web | Taux de réussite | |---|---|---| | Amazon | 48 % | | Instagram | 41 % | | Indeed | 38 % | | Etsy | 21 % | | Booking | 17 % | | Realtor | 0 % | | StockX | 0 % | | Twitter/X | 0 % | | Zillow | 0 % | | Walmart | 0 % | | LinkedIn | 0 % |
Test comparatif Scrapingdog (2025)
| Site web | ScrapingBee | Scrapingdog | ScraperAPI |
|---|---|---|---|
| Amazon | 100 % | 100 % | 100 % |
| Glassdoor | 0 % | 100 % | 100 % |
| eBay | 100 % | 100 % | 100 % |
| Walmart | 40 % | 100 % | 100 % |
| 90 % | 100 % | 80 % |
Benchmark Proxyway (décembre 2025)
- 72,98 % de réussite à 10 requêtes/seconde — une baisse de 12 points sous charge
- 25,46 s de temps de réponse moyen — le plus lent du groupe testé
Benchmark Scrape.do (2025–2026)
- Très bon sur certains sites : Amazon 99,11 %, Indeed 99,29 %, GitHub 100 %, X/Twitter 99,6 %
- Faible sur Capterra : seulement 59 % de réussite avec des temps de réponse de 36 secondes
Le schéma qui se dégage
Les données montrent une tendance nette :
- ScrapingBee fonctionne bien sur des sites grand public modérément protégés — Amazon, eBay, GitHub et Indeed affichent souvent des taux de réussite de 90 à 100 %
- ScrapingBee échoue complètement sur les sites très protégés — 0 % revient régulièrement sur LinkedIn, Zillow, Realtor.com, StockX et Twitter dans plusieurs benchmarks
- Les performances chutent fortement sous charge — de 84 % à 2 req/s à 73 % à 10 req/s
- Les résultats varient énormément selon la méthodologie — de 33,3 % (Scrapeway, large mix de sites) à 92,69 % (Scrape.do, cibles plus modérées)
La note de ScrapingBee (137 avis) est un bon signal, mais de bonnes notes sur la prise en main ne reflètent pas toujours la fiabilité en production sur le long terme et à grande échelle. Les utilisateurs qui changent de solution évoquent souvent une hausse du taux d’échec et des coûts — pas la difficulté de départ.
« Très positif. ScrapingBee a été stable, prévisible et facile à intégrer en production. » — Verified Reviewer, CEO,
ScrapingBee a montré une « fiabilité incohérente », avec notamment un « taux de réussite de 0 % sur Glassdoor » et « ».
Comment le scraping piloté par l’IA gère la fiabilité différemment
L’IA de Thunderbit lit la page rendue en temps réel, en s’adaptant aux mesures anti-bot et aux changements de mise en page à chaque session. Deux modes de scraping répondent à des enjeux de fiabilité différents :
- Scraping cloud — s’exécute sur les serveurs cloud de Thunderbit, gère jusqu’à 50 pages à la fois, idéal pour les gros jobs de scraping public sur des sites comme Amazon, Zillow et Shopify
- Scraping navigateur — s’exécute localement dans le navigateur Chrome de l’utilisateur, en utilisant sa propre session authentifiée — idéal pour les sites connectés (LinkedIn, tableaux de bord privés, plateformes SaaS) où les outils basés sur API comme ScrapingBee ne peuvent pas accéder au contenu derrière authentification
Thunderbit propose aussi des pour les sites populaires, préconstruits et maintenus, afin qu’ils continuent à fonctionner même quand la structure des sites change. Pour les sites où ScrapingBee affiche 0 % de réussite (LinkedIn, Zillow), le mode browser scraping de Thunderbit — en utilisant votre propre session connectée — repose sur une approche fondamentalement différente.
ScrapingBee vs principales alternatives : comparaison côte à côte
This paragraph contains content that cannot be parsed and has been skipped.