La collecte de données sur le web est devenue une compétence indispensable pour toute personne qui veut garder une longueur d’avance dans un monde piloté par la donnée. Que vous travailliez dans la vente, le marketing, l’immobilier ou l’e-commerce, être capable d’extraire rapidement et de façon fiable des données de sites web peut vraiment changer votre façon de travailler. Ces derniers mois, je me suis mis en quête des meilleurs outils d’extraction de données web du marché — surtout ceux qu’on peut utiliser sans doctorat en informatique. Un nom revenait sans cesse : ScrapingBee. C’est un acteur bien connu dans l’univers des API d’extraction web, et si vous avez déjà cherché une solution de collecte de données, vous êtes probablement tombé dessus vous aussi.
Mais ScrapingBee est-il vraiment le bon choix pour tout le monde ? Que disent les vrais utilisateurs à son sujet ? Et existe-t-il de meilleures alternatives, plus simples à utiliser — surtout pour celles et ceux qui ne veulent pas toucher au code ? Dans cette analyse approfondie, je vous partage mes recherches, mon expérience pratique et mon avis honnête sur ScrapingBee. Je vous présenterai aussi , un extracteur web alimenté par l’IA qui change la donne pour les utilisateurs non techniques et les équipes métiers.
Si vous envisagez ScrapingBee, si sa prise en main vous semble difficile, ou si vous cherchez simplement une manière plus intelligente et plus simple d’automatiser votre collecte de données web, poursuivez votre lecture. Je vais détailler tout ce qu’il faut savoir, comparer les fonctionnalités et les tarifs, et vous aider à choisir l’outil le plus adapté à vos besoins en 2025.
Qu’est-ce que ScrapingBee ? Un regard plus attentif sur l’entreprise et son produit
Commençons par les bases. ScrapingBee est une API d’extraction web dans le cloud, lancée en 2019 (à l’origine sous le nom ScrapingNinja). L’entreprise est basée en France et a été fondée par des développeurs qui voulaient simplifier l’extraction web pour les autres développeurs. Leur idée centrale ? Gérer tous les aspects pénibles du scraping — comme la gestion des proxys, l’exécution de navigateurs headless et le contournement des CAPTCHAs — pour que vous puissiez vous concentrer sur les données dont vous avez besoin.
Produits et fonctionnalités clés
Le produit principal de ScrapingBee est son Web Scraping API. Voici ce qu’il propose :
- Rotation des proxys : fait automatiquement tourner les adresses IP pour éviter d’être bloqué par les sites cibles.
- Rendu JavaScript : utilise Chrome headless pour afficher les pages dynamiques riches en JavaScript (comme les sites modernes d’e-commerce ou de réseaux sociaux).
- Géociblage : permet de récupérer des pages web comme si vous naviguiez depuis différents pays.
- Événements du navigateur headless : prend en charge des actions comme cliquer, faire défiler et remplir des formulaires via des scénarios JavaScript personnalisés.
- Google Search API : un point de terminaison dédié pour extraire les résultats de recherche Google, les annonces et plus encore.
- API REST et bibliothèques clientes : API bien documentée avec des bibliothèques pour Python, Node.js et d’autres langages populaires.
- Générateur de requêtes sans code : un tableau de bord web où vous pouvez composer des appels API, activer des options et générer des extraits de code pour vos scripts.
En pratique, vous envoyez une requête HTTP à l’API de ScrapingBee avec l’URL cible et les options souhaitées. ScrapingBee s’occupe du reste : récupération de la page, rendu JavaScript si nécessaire, rotation des proxys et renvoi du HTML brut ou des données extraites.
Comment ça fonctionne
Voici un flux de travail typique avec ScrapingBee :
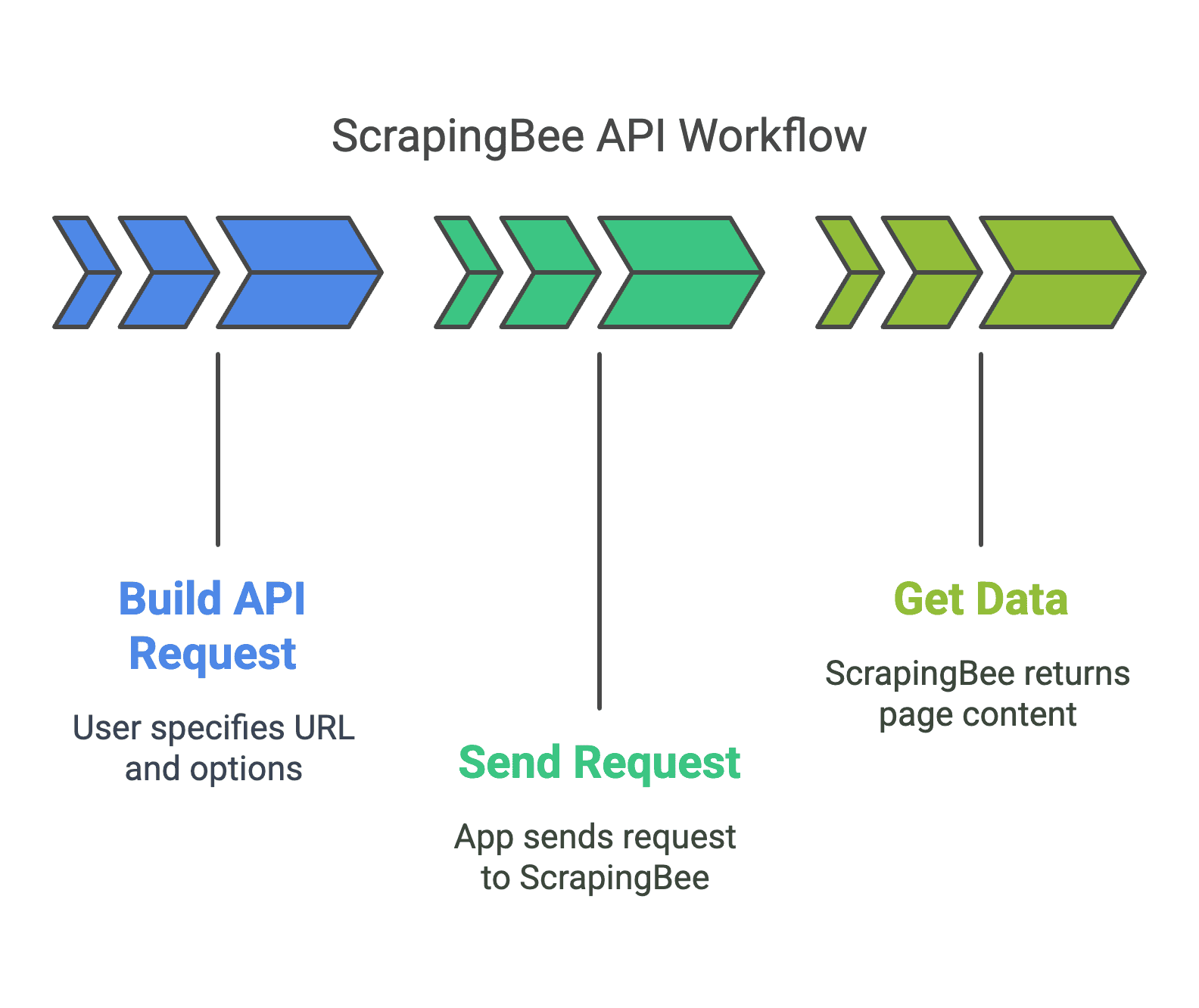
- Construisez votre requête API : utilisez le tableau de bord ou écrivez du code pour préciser l’URL, les options de rendu et les scripts personnalisés.
- Envoyez la requête : votre application ou votre script envoie la requête au point de terminaison de l’API ScrapingBee.
- Récupérez les données : ScrapingBee renvoie le contenu de la page (HTML, JSON ou données analysées) pour que vous puissiez le traiter.
C’est une approche centrée sur les développeurs, qui abstrait une grande partie du travail technique lié à l’extraction web.
À qui s’adresse ScrapingBee ?
C’est une question essentielle, qui revient souvent dans les avis d’utilisateurs. ScrapingBee est principalement conçu pour les développeurs et les utilisateurs à l’aise avec la technique qui doivent extraire des données web à grande échelle. Si vous êtes à l’aise avec les API, les requêtes HTTP et, peut-être, un peu de Python ou de JavaScript, vous trouverez probablement ScrapingBee assez simple à prendre en main.
Profils d’utilisateurs typiques
- Ingénieurs data et développeurs : création de pipelines de données personnalisés, d’outils de suivi des prix ou de tableaux de bord d’étude de marché.
- Growth hackers et spécialistes SEO : extraction des résultats de recherche Google, de sites concurrents ou de métriques issues des réseaux sociaux.
- Entreprises ayant des besoins récurrents en données : agrégateurs e-commerce, plateformes immobilières ou services de veille média.
Et pour les utilisateurs non techniques ?
ScrapingBee a fait certains efforts pour abaisser la barrière d’entrée pour les personnes qui ne codent pas. Le tableau de bord web inclut un générateur de requêtes en point-and-click, et vous pouvez intégrer ScrapingBee à des plateformes d’automatisation comme Make (anciennement Integromat). Mais à la base, ScrapingBee est une solution fondée sur une API. Il faut au minimum comprendre le fonctionnement des API, savoir analyser du JSON ou du HTML, et gérer des aspects comme l’authentification et le traitement des erreurs.
Si vous débutez complètement ou si vous voulez simplement extraire quelques pages sans écrire de code, ScrapingBee peut vite sembler intimidant. Il n’existe pas d’interface visuelle de type « point-and-click » comme dans certains outils plus récents propulsés par l’IA. Et il n’y a pas non plus de planification intégrée ni d’automatisation de flux de travail — il faudra vous en charger vous-même, soit dans le code, soit avec des outils tiers.
Tarifs de ScrapingBee : combien cela coûte-t-il vraiment ?
Le prix est toujours un critère majeur lorsqu’on choisit un outil d’extraction web, surtout si vous gérez une petite entreprise ou un projet personnel. ScrapingBee fonctionne avec un modèle d’abonnement basé sur des crédits API. Chaque appel API consomme un certain nombre de crédits, selon les fonctionnalités utilisées (comme le rendu JavaScript ou les proxys premium).
Tarifs actuels (en 2025)
- Essai gratuit : 1 000 appels API gratuits (aucune carte bancaire requise).
- Freelance Plan : 49 $/mois pour 250 000 crédits et jusqu’à 10 requêtes concurrentes. (Remarque : les fonctionnalités avancées comme les proxys premium ou le géociblage ne sont pas incluses dans ce niveau.)
- Startup Plan : 99 $/mois pour 1 000 000 crédits et 50 requêtes concurrentes. (Certains types de proxys et le géociblage restent limités.)
- Business Plan : 249 $/mois pour 3 000 000 crédits et 100 requêtes concurrentes. (Débloque des fonctionnalités premium comme le mode proxy furtif et le géociblage international.)
- Business+ Plan : 599 $/mois pour 8 000 000 crédits et 200 requêtes concurrentes. (Pensé pour les entreprises ; inclut une assistance dédiée.)
Remarques importantes :
- Les crédits non utilisés ne sont pas reportés au mois suivant.
- Le coût par requête varie : une extraction simple peut coûter 5 crédits, mais l’utilisation du mode furtif ou de proxys premium peut monter à 15–75 crédits par requête.
- Vous êtes facturé uniquement pour les requêtes réussies (HTTP 200 ou 404 attendu), mais si un site renvoie une page de blocage avec un statut 200, des frais peuvent quand même s’appliquer.
Le prix en vaut-il la peine ?
Pour des développeurs ou des entreprises qui extraient des dizaines de milliers de pages par mois, la tarification de ScrapingBee peut rester raisonnable — surtout si l’on tient compte du temps économisé sur la gestion des proxys et l’automatisation du navigateur. En revanche, pour une utilisation occasionnelle ou à petite échelle, l’entrée à 49 $/mois est élevée. Il n’existe pas de formule plus abordable ni de véritable option au paiement à l’usage, ce qui peut vous amener à payer pour une capacité que vous n’exploitez pas.
Avis utilisateurs sur ScrapingBee : ce qu’en disent les vrais utilisateurs
Pour me faire une idée de la performance réelle de ScrapingBee, j’ai consulté des avis utilisateurs sur des plateformes reconnues comme , , et . Voici ce que j’ai trouvé.
Retours positifs : ce que les utilisateurs apprécient
- Facilité d’utilisation (pour les développeurs) : beaucoup d’utilisateurs saluent l’API de ScrapingBee, jugée simple et bien documentée. Si vous êtes à l’aise avec les API, vous trouverez de nombreux exemples de code et des consignes claires.
- Fiabilité : les utilisateurs signalent de bons taux de réussite et des performances constantes, en particulier pour les sites dynamiques riches en JavaScript.
- Gain de temps : ScrapingBee vous évite de gérer vous-même les proxys, les navigateurs headless et les mesures anti-bot — un vrai plus pour les équipes très occupées.
- Support client : l’équipe support est réactive et utile, avec la plupart des demandes traitées sous 24 heures.
- Tableau de bord intuitif : l’interface web facilite le suivi de la consommation, la consultation des journaux et la gestion des clés API.
Un évaluateur a résumé son expérience ainsi : « Les API de ScrapingBee étaient extrêmement faciles à utiliser grâce à l’excellente documentation fournie. L’interface du site web est très intuitive et le tableau de bord est idéal pour visualiser l’utilisation de votre API. »
Retours négatifs : là où ScrapingBee montre ses limites
1. Courbe d’apprentissage élevée pour les débutants
Malgré sa réputation de simplicité auprès des développeurs, ScrapingBee peut être intimidant pour les utilisateurs non techniques. Voici pourquoi :
- Approche API-first : il faut savoir envoyer des requêtes HTTP, gérer l’authentification et analyser les réponses.
- Pas d’outil visuel de scraping : il n’existe pas d’interface point-and-click pour sélectionner des données directement sur une page web.
- Pas de planificateur intégré : il faut configurer soi-même la planification (via des tâches cron, des scripts ou des outils tiers).
- Options sans code limitées : même si vous pouvez vous intégrer à des plateformes comme Make, vous devez quand même configurer les appels API et gérer l’analyse des données.
Comme le résume une comparaison : « Outscraper ne nécessite aucune compétence en codage, alors que ScrapingBee est basé sur une API et demande de coder. » ()
Pour les débutants ou les utilisateurs métiers qui veulent simplement récupérer des données sans écrire de code, c’est un frein majeur. J’ai vu plusieurs utilisateurs s’inscrire en pensant obtenir une solution prête à l’emploi, puis rester bloqués sur la configuration technique.
2. Problèmes de vitesse et de performance
Même si ScrapingBee est généralement rapide, certains utilisateurs ont signalé des temps de réponse lents lors de l’extraction de pages nécessitant un rendu JavaScript complet. C’est un problème courant pour tout extracteur basé sur un navigateur headless, mais cela mérite d’être pris en compte si vous devez extraire rapidement de gros volumes de contenu dynamique.
3. Pas infaillible à 100 %
Aucun extracteur web n’est parfait, et ScrapingBee ne fait pas exception. Certains utilisateurs ont rencontré des difficultés avec des systèmes anti-bot sophistiqués, capables de bloquer encore certaines requêtes ou de déclencher des CAPTCHAs que ScrapingBee ne peut pas toujours résoudre. Dans ce cas, il faudra prévoir des tentatives répétées ou des contournements dans votre propre code.
Conclusion sur l’avis ScrapingBee
ScrapingBee est une API d’extraction web puissante et pensée pour les développeurs, qui excelle sur les sites complexes et dynamiques. Si vous êtes développeur ou ingénieur data et que vous devez extraire à grande échelle, il peut vous faire gagner énormément de temps et vous éviter bien des tracas. La documentation est excellente, le support est réactif, et l’API fonctionne — la plupart du temps.
Mais pour les utilisateurs non techniques, les petites entreprises ou toute personne à la recherche d’une vraie solution sans code en point-and-click, la courbe d’apprentissage et le modèle tarifaire de ScrapingBee peuvent être de sérieux points faibles. L’absence d’un extracteur visuel, d’un planificateur intégré et d’options tarifaires plus basses le rend moins accessible pour les débutants ou les utilisateurs occasionnels.
Si vous êtes à l’aise avec les API et que vous avez besoin d’une solution d’extraction robuste et évolutive, ScrapingBee est un choix solide. Mais si vous voulez quelque chose de plus simple, plus rapide et plus abordable — surtout si vous ne souhaitez pas écrire de code — il existe de meilleures alternatives.
Thunderbit : l’extracteur web IA le plus simple pour tout le monde
est une extension Chrome d’extraction web alimentée par l’IA conçue pour rendre la collecte de données aussi simple que possible — sans aucun code. Elle a été pensée pour les utilisateurs métiers, les équipes commerciales et marketing, les agents immobiliers, les opérateurs e-commerce et toute personne qui veut automatiser des tâches web répétitives sans se noyer dans les détails techniques.
L’atout distinctif de Thunderbit est sa fonctionnalité AI Suggest Columns. Voici comment cela fonctionne :
- Rendez-vous sur n’importe quel site web : ouvrez la page que vous voulez extraire.
- Cliquez sur « AI Suggest Columns » : l’IA de Thunderbit analyse la page et suggère automatiquement les meilleures colonnes à extraire (comme les noms de produits, les prix, les images, les coordonnées, etc.).
- Ajustez les colonnes si nécessaire : vous pouvez modifier les noms de colonnes ou ajouter/supprimer des champs comme vous le souhaitez.
- Cliquez sur « Scrape » : Thunderbit extrait les données et les présente dans un tableau structuré.
- Exportez gratuitement : téléchargez vos données vers Excel, Google Sheets, Airtable ou Notion, sans frais supplémentaires.
Le processus prend littéralement deux clics, et il fonctionne sur n’importe quel site web, y compris les sites difficiles comme Amazon, Zillow, Instagram, Shopify et même OnlyFans. Vous pouvez aussi extraire des données à partir de PDF, d’images et de sous-pages, grâce aux capacités avancées d’IA et d’analyse documentaire de Thunderbit.
Thunderbit en un coup d’œil
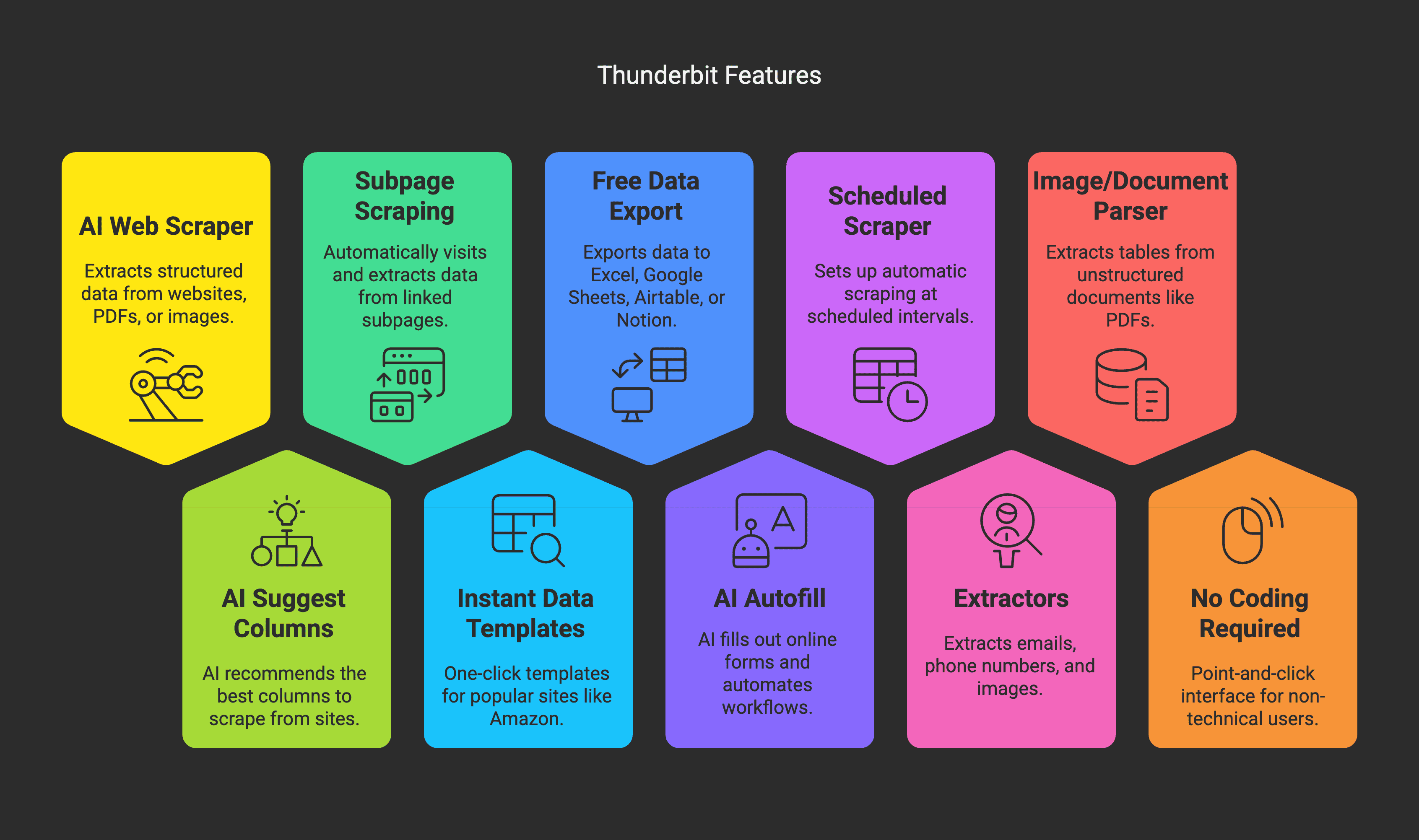
- Extracteur Web IA : extraire des données structurées depuis n’importe quel site web, PDF ou image en seulement deux clics.
- AI Suggest Columns : laissez l’IA recommander les meilleures colonnes à extraire, adaptées à chaque site.
- Extraction de sous-pages : visitez et extrayez automatiquement les données des sous-pages liées (par exemple, fiches produit, pages de contact).
- Modèles d’extraction instantanés : modèles en un clic pour les sites populaires comme Amazon, Zillow, Instagram, et plus encore.
- Export gratuit des données : exportez vers Excel, Google Sheets, Airtable ou Notion, sans frais cachés.
- AI Autofill (entièrement gratuit) : utilisez l’IA pour remplir des formulaires en ligne et automatiser vos workflows.
- Extracteur programmé : configurez des extractions automatiques à intervalles planifiés — décrivez simplement l’heure et les URL, et Thunderbit s’occupe du reste.
- Extracteurs d’e-mails, de téléphones et d’images : extrayez e-mails, numéros de téléphone et images depuis n’importe quel site en un clic (le tout gratuitement).
- Analyseur d’images et de documents : extrayez des tableaux depuis des documents non structurés comme des PDF, des fichiers Word, Excel et des images.
- Aucun code requis : interface 100 % point-and-click — parfaite pour les utilisateurs non techniques.
Vous pouvez télécharger et commencer à extraire gratuitement.
À qui s’adresse Thunderbit ?
Thunderbit est conçu pour tout le monde — pas seulement pour les développeurs. Voici quelques profils d’utilisateurs typiques :
- Équipes commerciales et marketing : créer des listes de prospects, surveiller les concurrents et automatiser la collecte de données.
- Agents immobiliers : extraire des annonces immobilières, des coordonnées et des données de marché depuis Zillow, et plus encore.
- Opérateurs e-commerce : suivre les prix, les avis et les stocks sur plusieurs plateformes.
- Chercheurs et analystes : collecter des données pour des études de marché, des recherches académiques ou de la veille stratégique.
- Dirigeants de petites entreprises : automatiser des tâches web répétitives et gagner des heures chaque semaine.
Si vous avez déjà eu du mal avec le code, les API ou des outils d’extraction complexes, Thunderbit est une vraie bouffée d’air frais. C’est aussi simple que naviguer sur le web.
Tarifs de Thunderbit : simples, transparents et abordables
Thunderbit utilise un système de crédits basé sur le nombre de lignes de sortie extraites. Voici comment cela se répartit :
| Formule | Tarif mensuel | Tarif annuel | Prix total annuel | Crédits mensuels | Crédits annuels |
|---|---|---|---|---|---|
| Gratuit | Gratuit | Gratuit | Gratuit | 6 pages | N/A |
| Starter | 15 $ | 9 $ | 108 $ | 500 | 5 000 |
| Pro 1 | 38 $ | 16,5 $ | 199 $ | 3 000 | 30 000 |
| Pro 2 | 75 $ | 33,8 $ | 406 $ | 6 000 | 60 000 |
| Pro 3 | 125 $ | 68,4 $ | 821 $ | 10 000 | 120 000 |
| Pro 4 | 249 $ | 137,5 $ | 1 650 $ | 20 000 | 240 000 |
- Formule gratuite : extrayez jusqu’à 6 pages par mois (quel que soit le nombre de lignes par page).
- Formule Starter : 15 $/mois (ou 9 $/mois en facturation annuelle) pour 500 crédits.
- Formules Pro : montez en gamme selon vos besoins, avec des crédits généreux et des tarifs annuels remisés.
- Aucuns frais supplémentaires pour l’export des données : l’export vers Excel, Google Sheets, Airtable ou Notion est toujours gratuit.
Vous pouvez consulter tous les détails sur la .
Thunderbit vs ScrapingBee : comparaison côte à côte
Comparons Thunderbit et ScrapingBee face à face, pour voir précisément là où chaque outil brille — et là où Thunderbit prend l’avantage, surtout pour les utilisateurs non techniques.
| Fonctionnalité | Thunderbit 🚀 | ScrapingBee 🧰 |
|---|---|---|
| Interface utilisateur | 🖱️ Extension Chrome, 100 % point-and-click, aucun code requis | 💻 Basé sur une API, nécessite de coder ou de connaître les API |
| Extraction de données alimentée par l’IA | 🤖 Oui – AI Suggest Columns détecte automatiquement la structure des données | ⚙️ Non – configuration manuelle via les paramètres API |
| Extraction de sous-pages | 🔄 Oui – l’IA peut visiter et extraire automatiquement les sous-pages | 🛠️ Non – il faut gérer les sous-pages dans votre propre code |
| Modèles instantanés | ⚡ Oui – modèles en 1 clic pour Amazon, Zillow, Instagram, Shopify, etc. | 📜 Non – il faut créer vos propres requêtes API |
| Export des données | 📤 Gratuit vers Excel, Google Sheets, Airtable, Notion | 🧾 Données renvoyées en HTML/JSON ; vous devez les traiter et les exporter vous-même |
| Extracteurs d’e-mails/téléphones/images | 📧📱🖼️ Oui – en 1 clic, totalement gratuit | 🧪 Non – vous devez analyser les données vous-même |
| Analyseur d’images et de documents | 📄 Oui – extrait des tableaux depuis des PDF, images, Word, Excel | 🌐 Non – extrait uniquement des pages web |
| AI Autofill | ✍️ Oui – gratuit, automatise le remplissage de formulaires et les workflows | 🚫 Non |
| Extracteur programmé | ⏰ Oui – configuration simple, sans code | 🧭 Non intégré ; automatisation externe nécessaire |
| Tarification | 💸 À partir de 0 $ (gratuit), formules payantes dès 15 $/mois | 💳 À partir de 49 $/mois |
| Courbe d’apprentissage | 📈 Minime – conçu pour les utilisateurs non techniques | 🧗 Forte – conçu pour les développeurs |
| Support | 🆘 E-mail, tutoriels, chaîne YouTube | 📚 E-mail, documentation |
| Idéal pour | 👥 Utilisateurs métiers, ventes, marketing, immobilier, e-commerce, recherche | 👨💻 Développeurs, ingénieurs data, équipes techniques |
En résumé : Thunderbit est le grand gagnant pour toute personne qui veut un moyen rapide, simple et abordable d’extraire des données web — sans écrire de code. ScrapingBee est un bon choix pour les développeurs qui ont besoin d’une API robuste, mais il n’est pas conçu pour les débutants ou les utilisateurs métiers qui veulent une solution prête à l’emploi.
Pourquoi je recommande Thunderbit (et comment il a changé mon flux de travail)
Après avoir testé les deux outils en profondeur, voici mon avis sincère :
- Thunderbit est, de loin, l’extracteur web le plus simple que j’aie jamais utilisé. Je suis passé de plusieurs heures à écrire des scripts et déboguer des appels API à l’extraction de sites entiers en quelques minutes — en seulement quelques clics.
- La fonctionnalité AI Suggest Columns change vraiment la donne. Je n’ai plus à deviner quels champs extraire ni à manipuler des sélecteurs CSS. L’IA de Thunderbit s’en charge pour moi, et je peux ajuster les colonnes si besoin.
- L’export des données est un jeu d’enfant. Je peux envoyer mes données extraites directement vers Excel, Google Sheets ou Notion — sans étapes supplémentaires ni frais cachés.
- Il fonctionne sur n’importe quel site, y compris les plus délicats. J’ai utilisé Thunderbit pour extraire des annonces produits Amazon, des données immobilières Zillow, des profils Instagram et même des tableaux à partir de PDF et d’images.
- La formule gratuite est généreuse et les offres payantes restent abordables. J’ai commencé avec l’offre gratuite, puis je suis passé à Starter, et je n’ai jamais regretté. J’économise par rapport à d’autres outils et j’en fais davantage en moins de temps.
- Fini les migraines liées au code. Je peux me concentrer sur l’essentiel — analyser les données, construire des listes de prospects et développer mon activité — au lieu de me battre avec des API et des scripts.
Si vous en avez assez des outils d’extraction compliqués, ou si vous voulez simplement une manière plus intelligente et plus rapide d’automatiser votre collecte de données web, je recommande Thunderbit sans hésiter. Vous pouvez et l’essayer gratuitement.
Conclusion : quel extracteur web choisir en 2025 ?
Choisir le bon outil d’extraction web dépend de vos besoins, de votre niveau technique et de votre budget. Voici mon conseil sincère :
- Si vous êtes développeur ou ingénieur data et que vous avez besoin d’une solution robuste, fondée sur une API, pour de l’extraction à grande échelle, ScrapingBee est un choix solide. L’outil est fiable, bien documenté et prend en charge le plus gros du travail. Préparez-vous simplement à une courbe d’apprentissage et à un prix plus élevé.
- Si vous êtes un utilisateur métier, un marketeur, un agent immobilier, un opérateur e-commerce, ou simplement quelqu’un qui veut extraire des données web rapidement, facilement et à moindre coût — sans écrire de code — Thunderbit est le grand gagnant. Ses fonctionnalités propulsées par l’IA, son interface point-and-click et sa formule gratuite généreuse le rendent accessible à tout le monde.
J’ai testé les deux outils, et pour mon argent — et pour ma tranquillité d’esprit — est le meilleur extracteur web de 2025. Il m’a fait gagner des heures de travail, m’a aidé à construire de meilleures listes de prospects, et m’a permis de me concentrer sur la croissance de mon activité plutôt que sur des problèmes de code.
Prêt à le constater par vous-même ? , essayez-le et découvrez dès aujourd’hui l’avenir de l’extraction web.
Vous avez des questions ou vous voulez en savoir plus ? Consultez la pour des tutoriels vidéo, ou visitez le pour les dernières astuces et mises à jour.
En savoir plus
- Découvrez comment
- Explorez
- Découvrez comment
- Comprenez