Vous créez un compte sur ScraperAPI, vous voyez « 100,000 credits » sur le plan Hobby, et vous commencez à scraper. Trois jours plus tard, votre tableau de bord affiche que 80 % de ces crédits ont déjà disparu — alors que vous n’avez peut-être extrait que 6 000 pages. Qu’est-ce qui s’est passé ? La réponse tient au système de multiplicateurs de crédits, et c’est sans doute l’élément le plus important de ScraperAPI que presque aucun avis n’explique vraiment. J’ai passé des semaines à éplucher la documentation de ScraperAPI, à comparer les tarifs réels de cinq concurrents, et à lire tous les sujets Reddit et avis Capterra que j’ai pu trouver. Cet avis sur ScraperAPI est celui que j’aurais aimé lire quand notre équipe a commencé à évaluer les API de scraping. Je vais détailler les vrais calculs de crédits, montrer où ScraperAPI excelle — et où il se plante complètement —, synthétiser ce que disent les utilisateurs sur G2, Capterra et Reddit, et, franchement, vous aider à savoir si vous avez vraiment besoin d’une API de scraping.
Qu’est-ce que ScraperAPI et pour qui est-il conçu ?
ScraperAPI est une API de web scraping qui gère toute l’infrastructure pénible derrière les extractions à grande échelle : rotation de proxies parmi , résolution automatique des CAPTCHA, rendu JavaScript et nouvelles tentatives automatiques. Vous lui envoyez une URL via un simple appel API, et il vous renvoie le HTML (ou du JSON analysé, si vous utilisez leurs endpoints de données structurées). L’entreprise a été fondée en 2018 par Daniel Ni, son siège est à Las Vegas, et elle sert aujourd’hui , dont Deloitte, Sony et Alibaba — avec .
Le public principal, ce sont les équipes de développement et d’opérations techniques qui montent des pipelines de scraping sur mesure. Si vous ne codez pas, ScraperAPI n’est clairement pas pensé pour vous (j’y reviens plus loin).
Fonctionnalités principales : rotation de proxies, rendu JavaScript, géociblage, endpoints de données structurées pour les sites les plus courants et relances automatiques en cas d’échec.
Mais voilà ce que la plupart des avis ne disent pas : les chiffres de crédits mis en avant sur la page tarifaire de ScraperAPI sont franchement trompeurs si vous ne comprenez pas le fonctionnement des multiplicateurs. C’est donc par là qu’il faut commencer.
Comment fonctionne réellement le système de crédits de ScraperAPI (la partie que la plupart des avis ignorent)
ScraperAPI facture avec un système de crédits. Le principe de base est simple : 1 requête API = 1 crédit. Sauf qu’en pratique, c’est presque jamais aussi simple. Le vrai coût en crédits dépend de deux choses : le domaine que vous scrapez et les options que vous activez. Et ces coûts s’additionnent d’une façon pas du tout intuitive.
Le tableau des multiplicateurs de crédits que tout utilisateur devrait voir avant de s’inscrire

Avant même d’activer un seul paramètre, le type de site que vous scrapez détermine votre coût de base en crédits :
| Catégorie de domaine | Crédits de base par requête | Exemples |
|---|---|---|
| Sites classiques | 1 | Blogs, sites d’actualité, HTML simple |
| E-commerce | 5 | Amazon, eBay, Walmart |
| SERP (moteurs de recherche) | 25 | Google, Bing |
| Réseaux sociaux | 30 |
À cela s’ajoutent des crédits supplémentaires liés aux options :
| Paramètre | Crédits supplémentaires | Remarques |
|---|---|---|
render=true (rendu JS) | +10 | Tous les plans |
screenshot=true | +10 | Tous les plans |
premium=true (proxy premium) | +10 | Tous les plans |
ultra_premium=true | +30 | Plans payants uniquement |
| Contournement anti-bot (Cloudflare, DataDome, PerimeterX) | +10 chacun | Détecté automatiquement — vous ne le choisissez pas |
premium=true + render=true combinés | +25 | PAS +20 |
ultra_premium=true + render=true combinés | +75 | PAS +40 |
La dernière ligne est la plus importante. La combinaison de fonctionnalités coûte PLUS que la simple addition des coûts individuels. Un proxy premium (+10) plus le rendu JavaScript (+10) devrait logiquement faire +20 crédits, mais ScraperAPI facture . Ultra-premium (+30) plus le rendu JavaScript (+10) devrait coûter +40, mais le total grimpe en réalité à — presque le double. Cette logique de cumul non linéaire est très peu mise en avant dans la documentation, et c’est la principale raison pour laquelle les utilisateurs ont l’impression que leurs crédits fondent plus vite que prévu.
Les paramètres qui ne consomment aucun crédit supplémentaire : wait_for_selector, country_code, session_number, device_type, output_format, keep_headers=true, autoparse=true.
Ce que vous obtenez réellement avec chaque plan : du gratuit à l’entreprise
Voici les :
| Plan | Prix mensuel | Annuel (par mois) | Crédits API | Threads simultanés | Géociblage |
|---|---|---|---|---|---|
| Free | 0 $ | — | 1 000 | 5 | Non |
| Hobby | 49 $ | 44 $ | 100 000 | 20 | US et UE uniquement |
| Startup | 149 $ | 134 $ | 1 000 000 | 50 | US et UE uniquement |
| Business | 299 $ | 269 $ | 3 000 000 | 100 | Au niveau pays (50+ pays) |
| Scaling | 475 $ | 427 $ | 5 000 000 | 200 | Au niveau pays |
| Enterprise | Sur devis | Sur devis | 5 000 000+ | 200+ | Au niveau pays |
Voici maintenant le coût réel pour 1 000 requêtes à chaque niveau, en tenant compte des multiplicateurs :
| Plan | Standard (1×) | Rendu JS (10×) | E-commerce (5×) | SERP (25×) | Ultra-Premium + JS (75×) |
|---|---|---|---|---|---|
| Hobby (49 $) | 0,49 $ | 4,90 $ | 2,45 $ | 12,25 $ | 36,75 $ |
| Startup (149 $) | 0,15 $ | 1,49 $ | 0,75 $ | 3,73 $ | 11,18 $ |
| Business (299 $) | 0,10 $ | 1,00 $ | 0,50 $ | 2,49 $ | 7,48 $ |
| Scaling (475 $) | 0,10 $ | 0,95 $ | 0,48 $ | 2,38 $ | 7,13 $ |
Un plan à 49 $/mois affiché comme offrant « 100,000 credits » ne permet en réalité que 1 333 requêtes effectives lorsqu’on scrape des sites protégés avec ultra-premium + rendu JavaScript. Cela revient à environ — plus cher que beaucoup de services de scraping entièrement gérés.
Pourquoi les crédits disparaissent plus vite que prévu
Trois points surprennent souvent les utilisateurs.
D’abord : la tarification selon le domaine est automatique. Vous ne choisissez pas le multiplicateur 5× pour Amazon ou 25× pour Google. Il s’applique dès que ScraperAPI détecte le domaine. Même logique pour les crédits de contournement anti-bot (+10 pour Cloudflare, DataDome, PerimeterX) : ils sont ajoutés automatiquement lorsqu’ils sont détectés.
Ensuite : les crédits ne sont pas reportés. Les crédits non utilisés . Aucun cumul.
Et enfin — et ça pique — le paiement à l’usage n’est disponible qu’à partir du plan Scaling (475 $/mois) et au-delà. Si vous êtes sur Hobby, Startup ou Business et que vous épuisez vos crédits en cours de cycle, vous êtes tout simplement bloqué jusqu’à la prochaine période de facturation. Votre seule option est de passer au palier supérieur.
Un utilisateur sur Reddit a indiqué qu’on lui avait annoncé 3 600 $ pour 60 millions de crédits à raison d’1 crédit par requête Amazon, mais qu’après paiement, un multiplicateur de 5 crédits avait été appliqué sans avertissement préalable. Son plan de 60 M ne valait donc en réalité que 12 M de requêtes — soit un par rapport à ses attentes.
Le piège des crédits DataPipeline
La fonctionnalité no-code DataPipeline de ScraperAPI (scraping planifié avec livraison via webhook) utilise une grille de crédits distincte, nettement plus élevée. Une requête simple standard coûte via l’API standard :
| Type de requête | API standard | DataPipeline | Ratio |
|---|---|---|---|
| Requête normale de base | 1 | 6 | 6× |
| E-commerce de base | 5 | 10 | 2× |
| SERP de base | 25 | 30 | 1,2× |
| Ultra-premium + JS (normal) | 75 | 80 | 1,07× |
Les utilisateurs qui configurent des pipelines no-code en pensant payer les mêmes coûts qu’avec l’API standard découvrent qu’ils consomment 6 fois plus de crédits sur les requêtes simples. C’est documenté, mais il faut aller le chercher.
Coût réel par requête : ScraperAPI face à la concurrence
Le prix affiché ne veut rien dire si l’on ne tient pas compte des multiplicateurs. J’ai relevé les tarifs actuels de cinq fournisseurs et uniformisé la comparaison autour d’un palier d’environ 300 $/mois pour trois scénarios courants.
Extraction HTML simple (sans JS, sans proxy premium)
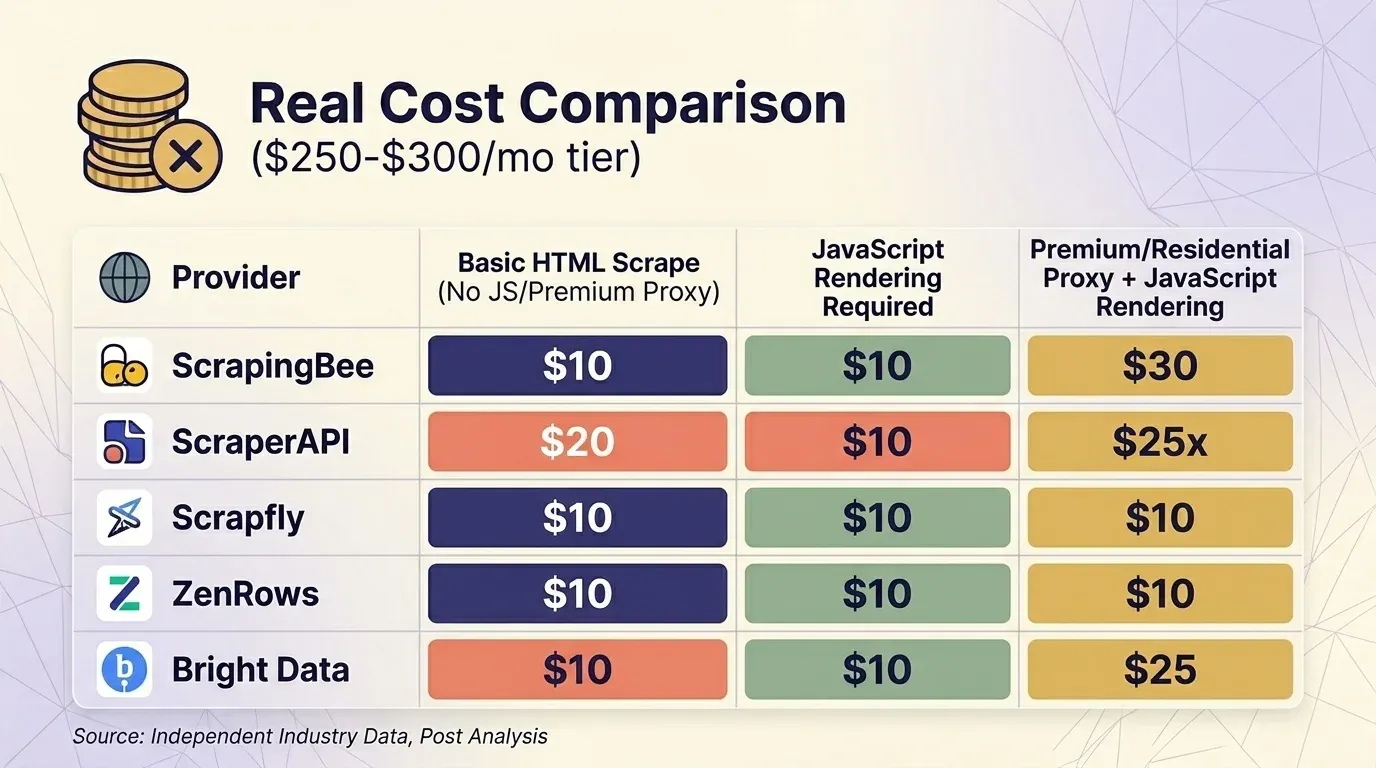
| Fournisseur | Plan | Crédits par requête | Requêtes réelles | Coût pour 1 000 |
|---|---|---|---|---|
| ScrapingBee | Business 249 $ | 1 | 3 000 000 | 0,08 $ |
| ScraperAPI | Business 299 $ | 1 | 3 000 000 | 0,10 $ |
| Scrapfly | Startup 250 $ | 1 | 2 500 000 | 0,10 $ |
| ZenRows | Business 300 $ | 0,28 $/1K | ~1 071 000 | 0,28 $ |
| Bright Data | PAYG | 1,50 $/1K | ~200 000 | 1,50 $ |
Rendu JavaScript requis
| Fournisseur | Plan | Crédits par requête | Requêtes réelles | Coût pour 1 000 |
|---|---|---|---|---|
| ScrapingBee | Business 249 $ | 5 (activé par défaut) | 600 000 | 0,42 $ |
| Scrapfly | Startup 250 $ | 6 | 416 667 | 0,60 $ |
| ScraperAPI | Business 299 $ | 10 | 300 000 | 1,00 $ |
| ZenRows | Business 300 $ | 5× | ~214 000 | 1,40 $ |
| Bright Data | PAYG | forfait | ~200 000 | 1,50 $ |
Proxy premium/résidentiel + rendu JavaScript (sites protégés)
| Fournisseur | Plan | Crédits par requête | Requêtes réelles | Coût pour 1 000 |
|---|---|---|---|---|
| Bright Data | PAYG | forfait | ~200 000 | 1,50 $ |
| ScrapingBee | Business 249 $ | 25 | 120 000 | 2,08 $ |
| ScraperAPI | Business 299 $ | 25 | 120 000 | 2,49 $ |
| Scrapfly | Startup 250 $ | 31 | 80 645 | 3,10 $ |
| ZenRows | Business 300 $ | 25× | ~42 857 | 7,00 $ |
Le Web Unlocker de Bright Data est le seul fournisseur qui — toutes les requêtes sont au même tarif fixe. Autour du palier de 300 $, ScrapingBee et ScraperAPI restent compétitifs pour le scraping de sites protégés, tandis que ZenRows est le plus cher.
Un point de comportement important : ScrapingBee avec un coût de 5×. Si vous comparez ScrapingBee et ScraperAPI, vérifiez bien que vous comparez les mêmes paramètres de rendu.
Une analyse indépendante de Scrape.do a conclu que ScraperAPI coûte en moyenne — « plus cher que tous les autres fournisseurs testés » — avec un temps de réponse moyen de , ce qui en fait « l’un des fournisseurs les plus lents du marché ». Mieux vaut le savoir avant de vous engager.
Taux de réussite par site : où ScraperAPI brille et où il peine
Aucune API de scraping ne marche aussi bien sur tous les sites. Des benchmarks indépendants de Scrapeway (avril 2026) dressent un tableau très contrasté.
Performance par catégorie de site
| Site cible | Taux de réussite | Vitesse moyenne | Coût pour 1 000 (plan Business) |
|---|---|---|---|
| Zillow | 100 % | 10,5 s | 0,49 $ |
| Etsy | 99 % | 4,8 s | 4,90 $ |
| Amazon | 98 % | 6,5 s | 2,45 $ |
| 95 % | 17,8 s | 14,70 $ | |
| Walmart | 93 % | 11,4 s | 2,45 $ |
| Indeed | 90 % | 15,8 s | 4,90 $ |
| StockX | 84 % | 3,9 s | 4,90 $ |
| Realtor.com | 12 % | 11,8 s | 0,49 $ |
| 0 % | — | — | |
| Booking.com | 0 % | — | — |
| Twitter/X | 0 % | — | — |
Taux de réussite moyen global : , légèrement au-dessus de la moyenne du secteur, qui se situe entre 58,2 % et 59,5 %. Temps de réponse moyen : 5,2 à 7,3 secondes, mieux que la moyenne du secteur de 9,8 secondes.
Là où ScraperAPI fonctionne bien
ScraperAPI est vraiment solide sur l’e-commerce (Amazon, Walmart, Etsy) et l’immobilier (Zillow). Les endpoints de données structurées pour ces sites renvoient du JSON analysé de façon fiable. Si votre besoin principal consiste à extraire des pages produits Amazon ou des SERP Google, ScraperAPI reste un choix raisonnable.
Là où ScraperAPI montre ses limites
Les réseaux sociaux, c’est quasiment une zone morte. Instagram, Twitter/X et Booking.com affichent tous un taux de réussite de 0 % dans les tests indépendants. LinkedIn fonctionne à 95 %, mais à 30 crédits par requête, la facture grimpe vite.
Les sites nécessitant une connexion sont explicitement interdits. ScraperAPI prend en charge la persistance de session via le paramètre session_number, mais . Il ne sait pas gérer le remplissage de formulaires, l’authentification à deux facteurs ou des flux d’authentification complexes.
Données obsolètes sur les cibles protégées. ScraperAPI applique un , ce qui signifie que si vous extrayez des données sensibles au temps réel (prix, niveaux de stock), vous pouvez recevoir des informations vieilles de 10 minutes.
Dans le benchmark 2025 de Proxyway, ScraperAPI affichait le , avec 81,72 %.
Résumé des performances par catégorie de site
| Catégorie de site | Performance de ScraperAPI | Problèmes connus | Alternative potentielle |
|---|---|---|---|
| Amazon / e-commerce | ✅ Forte (endpoints SDP) | Très gourmand en crédits à grande échelle | Templates Thunderbit (1 clic, aucun crédit par ligne pour le template) |
| Google SERP | ✅ Forte | Le géociblage coûte plus cher ; plus faible taux de réussite Google dans un benchmark | — |
| Immobilier (Zillow) | ✅ Excellente (100 %) | — | — |
| Instagram / réseaux sociaux | ❌ 0 % de réussite | Échec total | Playwright + proxies (fait maison) |
| SPA très lourdes en JS | ⚠️ Moyenne | Nécessite un rendu headless à 10× crédits | Scrapfly, ZenRows |
| Sites avec connexion | ❌ Interdit par les CGU | Pas de support de session/auth | Scraping navigateur Thunderbit (utilise votre session de connexion) |
| Booking.com / voyage | ❌ 0 % de réussite | Échec total | Bright Data |
Ce que disent les vrais utilisateurs : synthèse des avis G2, Capterra et Reddit
J’ai compilé les retours de trois plateformes. Voici les notes actuelles :
| Plateforme | Note | Avis |
|---|---|---|
| G2 | 4,4/5 | 16 |
| Capterra | 4,6/5 | 62 |
| Trustpilot | 4,5/5 | 43 |
Sous-notes Capterra : Facilité d’utilisation 4,9/5, Service client 4,6/5, Fonctionnalités 4,5/5, Rapport qualité/prix 4,5/5.
Synthèse des sentiments par thème
| Thème | Signaux positifs | Signaux négatifs |
|---|---|---|
| Facilité de prise en main / documentation | "Super easy to set up. You can start scraping in minutes." — Latenode community; note Capterra Facilité d’utilisation 4,9/5 | — |
| Transparence tarifaire | "Affordable entry tier" (plusieurs avis Capterra) | "Breakdown of credit costs can be confusing" — John S., Founder, Capterra (févr. 2025) ; "Prices increased by 1000% and quality degraded" — CTO, Online Media, Capterra (sept. 2022) |
| Fiabilité | "Works great for Amazon/Google" (G2, Capterra) | "ScraperAPI becomes shaky for heavy duty jobs" — emcarter, Latenode; "80% failure rate on some targets" (Reddit) |
| Support client | "Responsive team" (Capterra) | Un utilisateur a indiqué avoir été facturé 5× le tarif annoncé après avoir reçu un autre devis, sans avertissement préalable (Reddit) |
| Rapport qualité/prix dans le temps | Ne facture que les requêtes réussies (200/404) | "If you're running large-scale operations, the expenses can add up quickly" et construire sa propre infrastructure est "more cost-effective in the long run" — mikezhang, Latenode |
À retenir : ScraperAPI est apprécié pour sa simplicité de prise en main et fonctionne de manière fiable sur les cibles populaires bien prises en charge. Les critiques portent surtout sur les surprises de facturation (multiplicateurs, hausses inattendues) et la fiabilité sur les cas les plus difficiles.
Les endpoints de données structurées de ScraperAPI : valent-ils les crédits premium ?
ScraperAPI propose sur 5 plateformes, renvoyant du JSON analysé au lieu du HTML brut :
- Amazon (3 endpoints) : détails produit par ASIN, résultats de recherche, offres concurrentes. Retourne plus de 18 champs, dont les prix, notes, descriptions, avis, BSR, images et infos vendeur. Prend en charge .
- Google (5 endpoints) : (résultats organiques, knowledge graph, vidéos, questions associées, pagination), Shopping, Maps, News, Jobs.
- Walmart (4 endpoints) : produit, recherche, catégorie, avis.
- eBay (2 endpoints) : produit, recherche.
- Redfin (4 endpoints) : recherche, détails d’agent, locations, biens à vendre.
Les SDE sont disponibles sur tous les plans, y compris Free. ScraperAPI revendique un pour les domaines SDE pris en charge — même si les benchmarks indépendants nuancent ce chiffre selon le site.
Complétude des données
Le SDP Amazon est l’offre la plus solide de ScraperAPI. Il renvoie un ensemble très complet de champs : prix, avis, BSR, variantes, images, informations vendeur, etc. Le SDP Google SERP fournit les résultats organiques, les annonces, les extraits optimisés et les blocs People Also Ask. La complétude des données est vraiment très bonne sur ces deux plateformes.
Efficacité des crédits : SDP vs parsing maison
Sur le plan Business (299 $/mois, 3 M de crédits), extraire 10 000 produits Amazon via le SDE coûte 50 000 crédits (5 crédits chacun) — soit environ 5 $ du plan. Construire son propre parseur avec une requête standard (1 crédit chacun) ne coûterait que 10 000 crédits, mais il faudrait investir du temps développeur pour le créer et le maintenir.
Pour les petites équipes sans développeur, les SDE font gagner un vrai temps.
Pour les équipes qui ont des ressources d’ingénierie et travaillent à grande échelle, la prime de 5× en crédits est plus difficile à justifier.
Comment les SDPs se comparent aux templates no-code de scraping
Cette comparaison compte plus que la plupart des avis ne le laissent entendre. propose des templates instantanés pour Amazon, Shopify, Zillow et , sans code et sans coût de crédit par ligne pour le template lui-même.
| Critère | ScraperAPI SDP (Amazon) | Template Amazon Thunderbit |
|---|---|---|
| Temps de mise en route | 30 à 60 min (code + intégration API) | ~2 min (installer l’extension, ouvrir Amazon, cliquer sur le template) |
| Coût pour 1 000 produits (plan Business) | ~5 $ (50 000 crédits à 0,10 $/crédit) | ~16,50 $ (1 000 lignes × 1 crédit à 0,0165 $/crédit sur Pro) |
| Champs renvoyés | 18+ (très complet) | Nom du produit, prix, note, avis, images, URL, et plus encore |
| Options d’export | JSON (nécessite du code pour l’analyse) | Excel, CSV, Google Sheets, Airtable, Notion — 1 clic |
| Maintenance | ScraperAPI maintient le SDP | L’équipe Thunderbit maintient les templates |
| Compétences techniques | Python/Node.js requis | Aucune |
Pour les équipes de développement qui extraient d’Amazon à gros volume, le SDP de ScraperAPI est plus rentable par produit à grande échelle. Pour les utilisateurs métier qui veulent les données Amazon dans un tableur sans coder, Thunderbit est nettement plus rapide à installer et à utiliser.
Avez-vous vraiment besoin d’une API de scraping ? L’option no-code que la plupart des avis négligent
Beaucoup de personnes qui cherchent un « Scraper API review » n’ont pas encore décidé d’adopter un workflow basé sur une API. Elles essaient d’abord de voir si elles en ont vraiment besoin.
Et, contre toute attente, beaucoup n’en ont pas besoin. Le marché des API de web scraping pèse et croît de 14 à 18 % par an, mais cette croissance est surtout portée par des équipes d’ingénierie en entreprise — pas par un responsable commercial qui a besoin de 500 leads depuis un site web.
API de scraping vs outil no-code : une grille de décision côte à côte
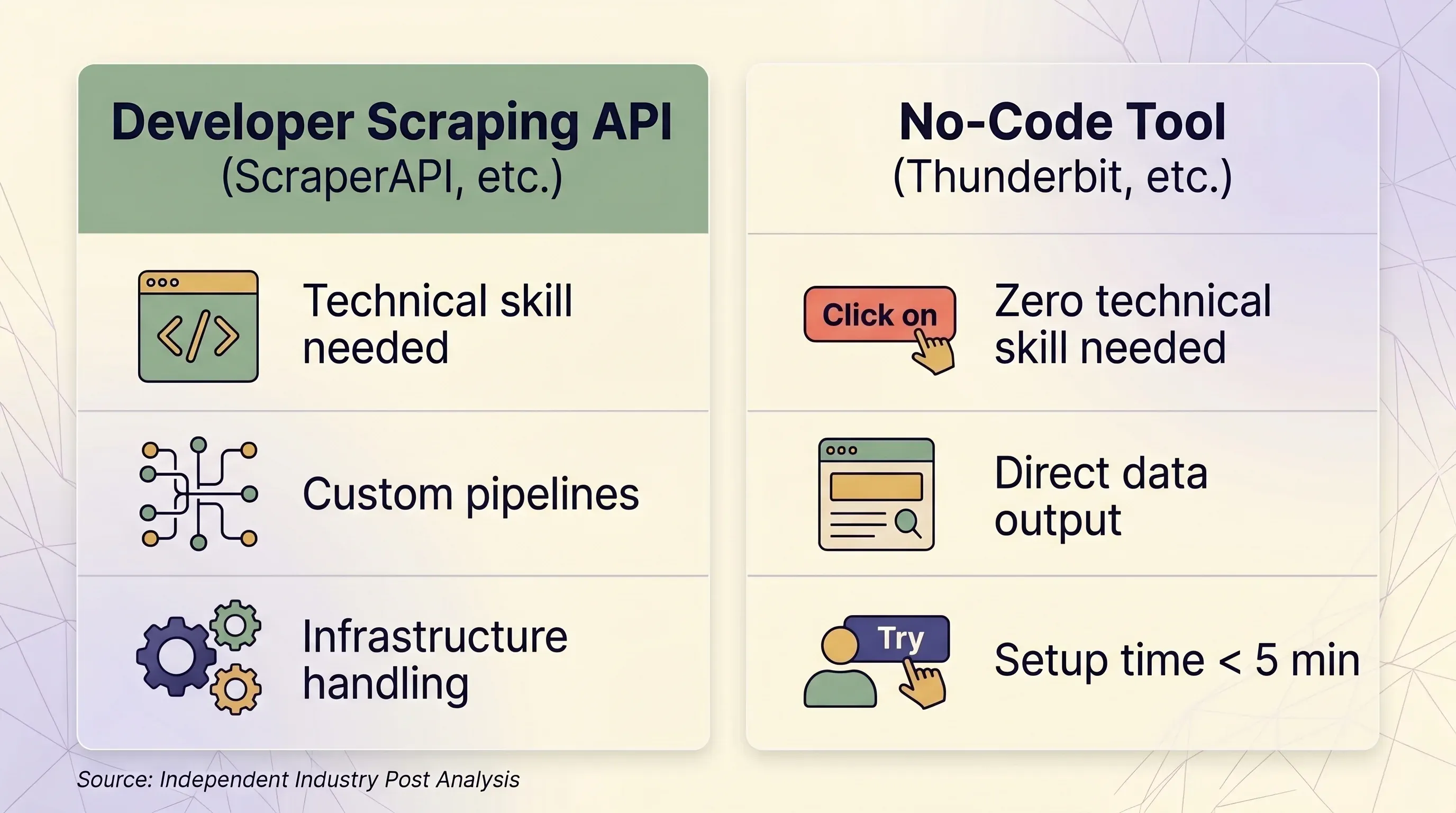
| Critère | API de scraping (ScraperAPI, etc.) | Outil no-code (Thunderbit, etc.) | |---|---|---|---| | Idéal pour | Développeurs qui construisent des pipelines de données à grande échelle | Utilisateurs métier, marketeurs, équipes commerciales, chercheurs | | Compétences techniques requises | Python/Node.js, notions HTTP, parsing JSON | Aucune — clics dans le navigateur | | Temps de configuration | 1 à 2 heures minimum (code + tests + débogage) | Moins de 5 minutes | | Gestion anti-bot | Proxies premium (10 à 75 crédits/requête) | Session de navigateur réelle — contourne naturellement le fingerprinting | | Sites avec connexion | ❌ Interdit par les CGU de ScraperAPI | ✅ Browser Scraping utilise votre session existante | | Volume (pages/jour) | 100K à 3M+ requêtes/mois | Ponctuel, généralement moins de 1 000 pages/jour | | Sortie des données | HTML brut ou JSON (nécessite du code) | Lignes/colonnes structurées — prêtes à l’emploi | | Export | JSON, CSV (via code) | Excel, CSV, Google Sheets, Airtable, Notion, Word, JSON | | Maintenance | Il faut mettre à jour les sélecteurs, la logique de relance, l’infrastructure | Aucune — l’IA relit la structure de la page à chaque fois | | Unité de prix | Crédits par requête (variable : 1 à 75 crédits/requête) | Crédits par ligne (1 crédit = 1 ligne, 2 pour les sous-pages) | | Prix d’entrée | 49 $/mois pour 100K crédits | 9 $/mois pour 5 000 crédits (annuel) | | Offre gratuite | 1 000 crédits/mois, 5 simultanés | 6 pages/mois, 30 crédits/page | | Prévisibilité tarifaire | Faible — les multiplicateurs créent des coûts imprévus | Élevée — 1 ligne = toujours 1 crédit |
Quand une API de scraping a du sens
- Vous avez un développeur ou une équipe d’ingénierie
- Vous devez scraper plus de 100 000 pages par jour de façon programmatique
- Vous avez besoin d’une personnalisation poussée des en-têtes, des sessions et de la logique de relance
- Vos cibles sont bien prises en charge (Amazon, Google, Walmart, Zillow)
Quand un outil no-code comme Thunderbit est plus pertinent
- Vous travaillez dans la vente, l’e-commerce, le marketing ou l’immobilier — pas dans l’ingénierie
- Vous avez besoin de données provenant de dizaines de sites différents sans écrire un parseur spécifique pour chacun
- Vous voulez exporter directement vers Excel, Google Sheets, Airtable ou Notion
- Vous devez scraper des sites qui exigent une connexion (le de Thunderbit utilise votre session)
- Vous voulez que l’IA relise la page à chaque fois — sans maintenance de code quand les sites changent de mise en page
- Vous avez besoin d’un scraping de sous-pages : Thunderbit peut visiter chaque page détail et enrichir les lignes automatiquement
Le flux de travail de est vraiment simple : installez l’extension, ouvrez n’importe quelle page, cliquez sur « AI Suggest Fields », cliquez sur « Scrape », puis exportez. L’IA identifie les données présentes sur la page et suggère les colonnes — vous n’avez pas à écrire de sélecteurs ni de code. Pour en savoir plus, consultez notre .
ont subi des dépassements de coûts cloud en 2024, et les sociétés qui utilisent une tarification basée sur l’usage sans protections adéquates constatent à cause des surprises de facturation. La prévisibilité d’un modèle de crédits par ligne mérite d’être prise en compte si vous avez déjà été pénalisé par des coûts d’API variables.
Avantages et inconvénients de ScraperAPI en un coup d’œil
| Avantages | Inconvénients |
|---|---|
| Infrastructure de proxy puissante (40M+ d’IP, 50+ pays) | Système de multiplicateurs de crédits confus — combiner des fonctionnalités coûte plus que la somme |
| Excellente documentation et prise en main simple (Capterra Ease of Use : 4,9/5) | Les crédits ne sont PAS reportés d’un mois à l’autre |
| Fiable sur Amazon, Google, Zillow, Etsy | 0 % de réussite sur Instagram, Twitter/X, Booking.com |
| Facture uniquement les requêtes réussies (200/404) | Les réponses 404 consomment quand même des crédits |
| 18 endpoints de données structurées avec sortie JSON analysée | Les sites nécessitant une connexion sont explicitement interdits |
| Disponible sur tous les plans, y compris Free | Le paiement à l’usage n’est disponible qu’à partir de Scaling (475 $/mois) |
| Politique de remboursement de 7 jours sans justification | Cache forcé de 10 minutes sur les cibles difficiles — risque de données obsolètes |
| Une croissance annuelle de 30 à 35 % du chiffre d’affaires suggère un développement actif | DataPipeline peut coûter jusqu’à 6× les crédits de l’API standard |
| — | Le géociblage au-delà des US et de l’UE nécessite le plan Business (299 $/mois) |
| — | Aucune alerte proactive d’utilisation — il faut vérifier le tableau de bord manuellement |
Conseils pratiques pour tirer le meilleur parti de ScraperAPI si vous décidez de l’utiliser
Surveillez votre consommation de crédits chaque jour
Le de ScraperAPI fournit des statistiques d’utilisation, notamment la latence moyenne, les domaines scrapés et les métriques de concurrence. En revanche, il n’existe aucune alerte proactive — aucun e-mail ni SMS quand les crédits sont presque épuisés. Vous devez vérifier à la main. L’historique analytique est limité à 2 semaines sur les plans Hobby/Startup et à 6 mois sur Business+.
Programmez un rappel quotidien pendant le premier mois pour jeter un œil à votre tableau de bord. Vous devez apprendre à anticiper la vitesse réelle de consommation sur vos cibles.
Commencez par l’offre gratuite pour tester vos sites cibles
Utilisez les 1 000 crédits gratuits (plus un essai de 7 jours avec 5 000 crédits) pour mesurer les taux de réussite sur vos sites cibles avant de souscrire à un plan payant. Notez quels sites nécessitent le rendu JavaScript ou des proxies premium afin d’estimer des coûts mensuels réalistes avec les multiplicateurs.
Désactivez les options premium sauf si la cible en a besoin
ScraperAPI n’active PAS automatiquement les proxies premium ni le rendu JavaScript — vous devez définir explicitement render=true, premium=true ou ultra_premium=true. En revanche, la tarification selon le domaine est automatique : Amazon coûte toujours 5 crédits, Google 25, LinkedIn 30. Les crédits de contournement anti-bot (+10 pour Cloudflare, DataDome, PerimeterX) sont aussi ajoutés automatiquement lorsqu’ils sont détectés. Gardez cela en tête avant de lancer un lot.
Utilisez les endpoints de données structurées pour les sites pris en charge
Si vous scrapez Amazon ou Google, les SDE vous font gagner du temps de développement, même s’ils consomment plus de crédits. Pour les sites non pris en charge, demandez-vous si un ne serait pas plus rapide et moins cher qu’un parseur sur mesure.
Prévoyez une solution de secours pour les cibles peu fiables
Si le taux de réussite de ScraperAPI sur un site donné est inférieur à 90 %, envisagez de router ces requêtes vers un autre fournisseur ou d’utiliser un outil basé sur le navigateur. Pour les sites nécessitant une connexion, ScraperAPI ne fonctionnera tout simplement pas — il faudra un outil comme qui opère dans votre session de navigateur.
Connaissez les pièges
- Les réponses 404 consomment des crédits — ScraperAPI facture les codes de statut 200 et 404
- Les requêtes annulées sont facturées si vous annulez avant la fin de la fenêtre de traitement de 70 secondes
- Cache forcé de 10 minutes sur les cibles difficiles — vous pouvez recevoir des données obsolètes
- Le paiement à l’usage n’est disponible qu’à partir de Scaling (475 $/mois) — les plans inférieurs sont bloqués lorsqu’ils n’ont plus de crédits
- Le géociblage au-delà des US et de l’UE nécessite le plan Business (299 $/mois)
Points clés à retenir : ScraperAPI est-il le bon outil pour vous ?
Voici ma conclusion après tout ce travail de recherche :
- ScraperAPI est un bon choix pour les équipes techniques qui extraient de gros volumes sur des cibles bien prises en charge comme Amazon, Google, Walmart et Zillow. Les endpoints de données structurées sont vraiment utiles, l’infrastructure de proxy est vaste et la documentation est au-dessus de la moyenne.
- Le système de multiplicateurs de crédits est le plus gros risque. Si vous ne comprenez pas comment les multiplicateurs se cumulent, vous allez trop dépenser. L’écart entre les crédits annoncés et les requêtes réelles peut aller de 5× à 75×. Faites le calcul pour votre cas d’usage avant de souscrire.
- La fiabilité dépend du site. ScraperAPI est excellent sur l’e-commerce et l’immobilier, moyen sur les job boards et les réseaux sociaux, et totalement inutile sur Instagram, Twitter/X et Booking.com. Ne partez pas du principe qu’il donnera les mêmes résultats partout.
- Pour les équipes non techniques, ScraperAPI n’est pas le bon outil. Si vous travaillez dans les ventes, le marketing ou les opérations et que vous avez besoin de données structurées sans écrire de code, un outil no-code comme vous y amène en deux clics — avec détection des champs par IA, export direct vers tableur, enrichissement des sous-pages et aucune maintenance. Consultez ou regardez les tutoriels sur la .
- Pour les développeurs au budget serré, testez d’abord l’offre gratuite de ScraperAPI sur vos cibles, puis comparez le coût effectif par requête avec ScrapingBee, Scrapfly et Bright Data avant de choisir. L’option la moins chère dépend entièrement de votre cas d’usage et des fonctionnalités requises.
Vous voulez voir comment les chiffres s’appliquent à vos besoins de scraping ? Commencez par l’offre gratuite de ScraperAPI pour tester vos sites cibles, ou pour voir jusqu’où deux clics peuvent vous mener. Pour en savoir plus sur , consultez nos formules.
FAQ
ScraperAPI est-il gratuit ?
Oui, ScraperAPI propose une offre gratuite avec et un essai de 7 jours avec 5 000 crédits. Toutefois, les multiplicateurs de crédits pour le rendu JavaScript, les proxies premium ou les domaines à coût élevé (Amazon = 5×, Google = 25×, LinkedIn = 30×) font que votre capacité réelle peut être bien inférieure à 1 000 requêtes. Sur l’offre gratuite, les proxies ultra-premium ne sont pas disponibles.
Combien coûte ScraperAPI par requête ?
Cela dépend fortement des options activées et du domaine cible. Une requête standard vers un site HTML simple coûte 1 crédit. Une requête Amazon coûte 5 crédits. Une requête Google SERP coûte 25 crédits. L’ajout du rendu JavaScript ajoute 10 crédits. La combinaison proxy ultra-premium + rendu JavaScript coûte 75 crédits par requête. Sur le plan Hobby (49 $/mois, 100K crédits), cela représente entre 0,00049 $ par requête (standard) et 0,0368 $ par requête (ultra-premium + JS). Consultez les tableaux complets ci-dessus pour plus de détails.
ScraperAPI est-il adapté pour scraper Amazon ?
L’endpoint Amazon Structured Data de ScraperAPI est l’une de ses meilleures fonctionnalités, avec un dans les benchmarks indépendants et une sortie JSON analysée très complète (18+ champs). Cependant, chaque requête Amazon coûte au minimum 5 crédits, ce qui fait vite grimper la facture à grande échelle. Pour les petites équipes qui veulent des données Amazon dans un tableur sans coder, offre une alternative en 1 clic avec export direct.
Quelles sont les meilleures alternatives à ScraperAPI ?
Pour les développeurs : (le moins cher pour le HTML simple), (bon rendu JavaScript), (le meilleur pour les sites protégés — tarif fixe quel que soit le rendu) et . Pour les utilisateurs non techniques : — une extension Chrome no-code, propulsée par l’IA, avec export direct vers Excel, Google Sheets, Airtable et Notion. Consultez notre pour aller plus loin.
ScraperAPI peut-il scraper des sites nécessitant une connexion ?
ScraperAPI prend en charge la persistance de session via le paramètre session_number (même IP sur plusieurs requêtes), mais . Il ne sait pas gérer le remplissage de formulaires, l’authentification à deux facteurs ni les flux d’authentification complexes. Pour les sites nécessitant une connexion, les outils basés sur le navigateur comme — qui utilise votre session de navigateur existante pour extraire ce que vous voyez — sont l’option la plus fiable.
En savoir plus