

Zillow s’appuie sur 160 millions de fiches immobilières américaines, et réussir à exploiter ces données à grande échelle est l’une des tâches les plus demandées — et les plus frustrantes — dans l’analyse de données immobilières. Si vous avez déjà essayé d’extraire des données sur Zillow pour finir face à une page CAPTCHA au lieu des annonces, vous n’êtes pas seul.
J’ai passé beaucoup de temps à étudier et tester différentes approches pour extraire Zillow — aussi bien avec Python qu’avec des outils no-code que nous avons développés chez Thunderbit. Ce guide couvre les deux voies. Que vous vouliez un tutoriel Python complet avec des stratégies anti-bot, ou simplement 200 annonces dans un tableur avant le déjeuner, vous trouverez ici la bonne section. Nous verrons pourquoi les données Zillow sont si précieuses, comment le site est structuré en coulisses, un tutoriel Python pas à pas, les raisons exactes pour lesquelles les extracteurs cassent, et comment automatiser des extractions récurrentes pour le suivi des prix.
Pourquoi extraire des données Zillow ?
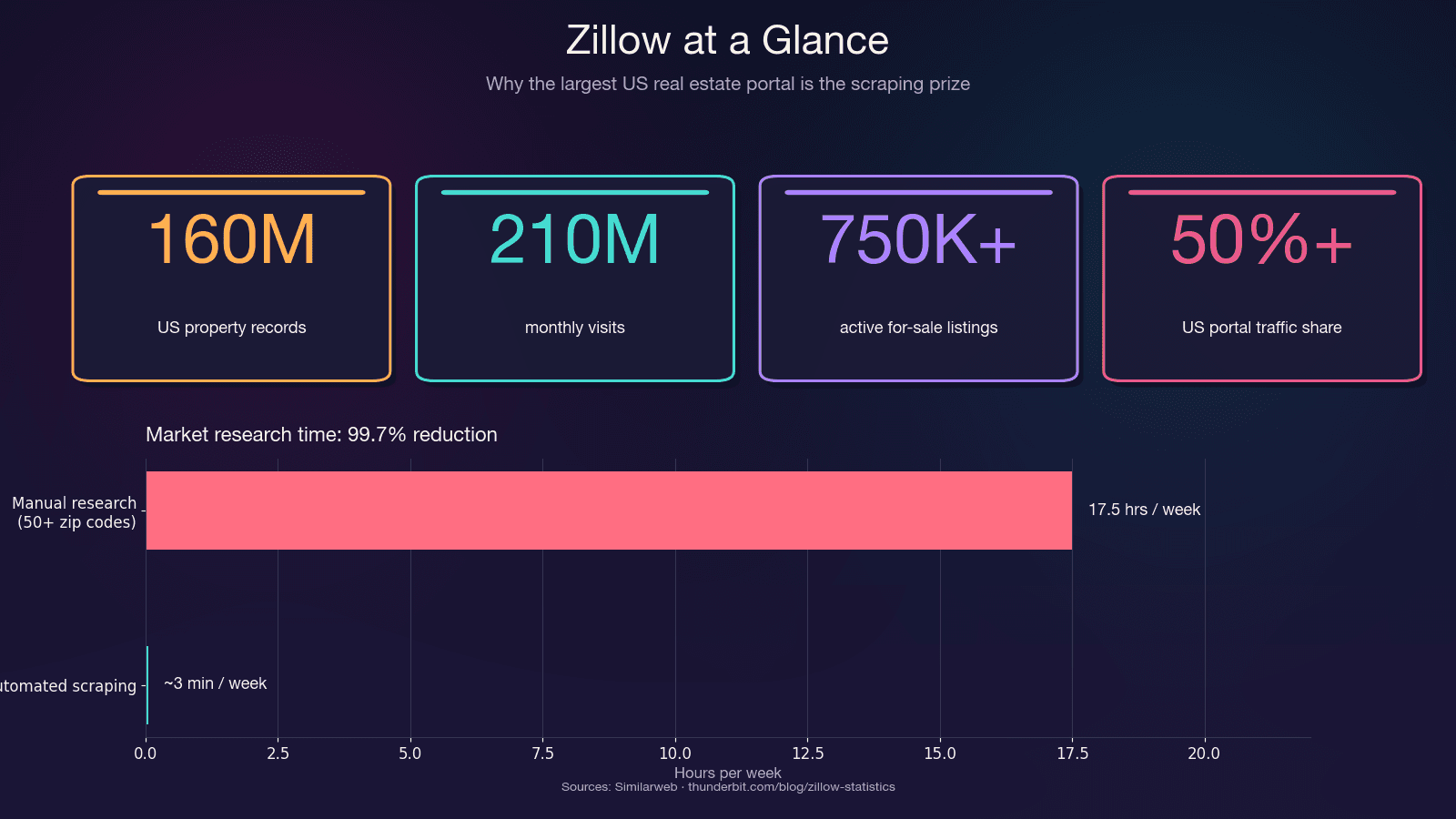
Zillow est la plus grande base de données immobilières résidentielles des États-Unis. La plateforme enregistre 210 millions de visites mensuelles et héberge environ 750 000 annonces actives à la vente ainsi que 1,9 million d’annonces locatives. Elle capte plus de 50 % du trafic total des portails immobiliers américains — soit plus du double de son concurrent le plus proche.
Avant de plonger dans le code Python, il faut savoir qu’utiliser Python pour extraire Zillow n’est pas la seule option, et choisir la mauvaise méthode peut faire perdre des heures. Les outils Python comme httpx et BeautifulSoup demandent un niveau intermédiaire, une gestion manuelle des en-têtes et des proxys, fonctionnent à une vitesse modérée (1 à 3 secondes par page) et nécessitent une maintenance fréquente, même s’ils sont gratuits ; Selenium ou Playwright améliorent la gestion anti-bot en rendant le JavaScript, mais ils sont plus lents (5 à 15 secondes par page) et restent lourds à maintenir ; les API de scraping comme ScraperAPI ou ScrapFly sont plus rapides, intègrent une protection anti-bot et demandent une maintenance moyenne, mais coûtent entre 30 et 599 $ par mois ; l’API officielle de Zillow via Bridge Interactive est rapide et peu contraignante, mais limitée et facturée autour de 500 $ par mois ; enfin, les outils no-code comme Thunderbit sont adaptés aux débutants, rapides, ne demandent quasiment aucune maintenance grâce à l’adaptation par IA, et proposent généralement un modèle freemium.
Le gain de temps à lui seul est énorme. Une recherche manuelle sur plus de 50 codes postaux peut vous faire perdre 15 à 20 heures par semaine. L’extraction automatisée effectue le même travail en quelques minutes — soit une réduction de 99,7 % du temps passé.
Toutes les façons d’extraire Zillow : Python, API ou no-code (comparatif)
Avant de passer au code Python, sachez que « extraire Zillow avec Python » n’est pas la seule possibilité. Choisir la mauvaise méthode fait perdre des heures. Voici un comparatif pour vous aider à trancher :
| Méthode | Niveau requis | Gestion anti-bot | Vitesse | Maintenance | Coût |
|---|---|---|---|---|---|
| Python + httpx/BeautifulSoup | Intermédiaire | Manuelle (en-têtes, proxys) | Modérée (1–3 s/page) | Élevée (les sélecteurs cassent) | Gratuit |
| Python + Selenium/Playwright | Intermédiaire | Meilleure (rend le JS) | Lente (5–15 s/page) | Élevée | Gratuit |
| API de scraping (ScraperAPI, ScrapFly) | Intermédiaire | Intégrée | Rapide | Moyenne | 30–599 $/mois |
| API officielle Zillow (Bridge Interactive) | Débutant–intermédiaire | N/A | Rapide | Faible | ~500 $/mois, accès limité |
| Outil no-code (Thunderbit) | Débutant | Intégrée (adaptation par IA) | Rapide | Aucune (l’IA relit la page) | Freemium |
Si vous avez besoin de données tout de suite sans écrire de code, commencez avec Thunderbit. Si vous voulez comprendre la mécanique ou avoir un contrôle total, poursuivez avec le tutoriel Python.
La méthode la plus rapide : extraire Zillow avec Thunderbit (sans code)
Avant d’entrer dans le détail Python, voici la solution pour ceux qui veulent simplement récupérer des données Zillow rapidement — sans installation Python, sans configuration de proxy, sans maintenance de sélecteurs. Nous avons conçu ce workflow chez Thunderbit précisément pour extraire des données immobilières structurées sans surcharge technique.
Difficulté : Débutant Temps nécessaire : environ 2 minutes Ce qu’il vous faut : un navigateur Chrome, l’extension Chrome Thunderbit (la version gratuite suffit)
Étape 1 : Installer Thunderbit et ouvrir Zillow
Installez l’extension Thunderbit depuis le Chrome Web Store. Rendez-vous sur une page de résultats de recherche Zillow — par exemple, recherchez des maisons à Houston, TX.
Étape 2 : Cliquer sur « AI Suggest Fields »
Ouvrez la barre latérale Thunderbit et cliquez sur « AI Suggest Fields ». L’IA lit la page et propose automatiquement les colonnes : prix, adresse, chambres, salles de bain, surface, Zestimate, URL de l’annonce, et bien plus. Lors de mes tests, elle détecte généralement plus de 20 champs sans aucune configuration manuelle.
Étape 3 : Cliquer sur « Scrape »
Cliquez sur le bouton Scrape. Les données s’affichent dans un tableau structuré dans l’extension. Thunderbit gère automatiquement la pagination Zillow — aussi bien par clic que via le défilement infini.
Étape 4 : Enrichir avec l’extraction des sous-pages
Vous voulez des données plus détaillées, comme l’historique fiscal, les notes des écoles ou l’historique des prix ? Utilisez « Scrape Subpages » pour enrichir votre tableau. Thunderbit visite chaque URL d’annonce et récupère les champs supplémentaires — sans code en plus.
Étape 5 : Exporter
Exportez vers Google Sheets, Excel, Airtable ou Notion. L’export est gratuit.
Pourquoi Thunderbit fonctionne si bien pour Zillow
Le véritable avantage, c’est la robustesse. L’IA de Thunderbit relit la structure de la page à chaque extraction. Quand Zillow modifie sa mise en page — ce qui arrive souvent — il n’y a pas de sélecteurs CSS fragiles à réparer. L’IA s’adapte automatiquement. Cela résout réellement la nature « intrinsèquement cassante » des extracteurs codés, qui fait perdre patience à tant d’utilisateurs.
Quelles données peut-on extraire de Zillow ? (plus de 20 champs)
La plupart des guides se contentent du prix et de l’adresse, puis s’arrêtent là. En réalité, les annonces Zillow contiennent bien plus de données exploitables qu’on ne le pense — voici un tableau de référence :
| Champ | Où le trouver | Difficulté d’extraction |
|---|---|---|
| Prix affiché | Recherche + Détail | Facile |
| Adresse / code postal | Recherche + Détail | Facile |
| Zestimate | Recherche + Détail | Facile |
| Historique des prix (chaque événement) | Détail | Difficile (JSON imbriqué) |
| Historique fiscal | Détail | Difficile (JSON imbriqué) |
| Chambres / salles de bain / surface | Recherche + Détail | Facile |
| Année de construction | Détail | Facile |
| Frais de copropriété (HOA) | Détail | Moyen |
| Walk Score / Transit Score | Détail (iframe) | Difficile (nécessite le rendu JS) |
| Notes des écoles | Détail | Moyen |
| Superficie du terrain | Détail | Facile |
| Jours sur Zillow | Recherche | Facile |
| Agent / agence | Recherche + Détail | Moyen |
| Numéro MLS | Détail | Facile |
| Type de bien | Recherche + Détail | Facile |
| Latitude / longitude | JSON __NEXT_DATA__ | Moyen |
| Texte de description | Détail | Facile |
| URLs des photos | Recherche + Détail | Moyen |
| Rent Zestimate | Détail | Moyen |
| Ventes comparables à proximité | Détail | Difficile |
Les champs « difficiles » — historique des prix, historique fiscal, ventes comparables — se trouvent dans du JSON imbriqué sur les pages de détail. La section Python ci-dessous montre exactement comment les extraire. Et si vous préférez éviter le code, l’option AI Suggest Fields de Thunderbit détecte automatiquement la plupart de ces colonnes, tandis que l’extraction des sous-pages récupère les champs de détail sans effort.
Préparer votre environnement Python pour extraire Zillow
Difficulté : Intermédiaire Temps nécessaire : environ 5 minutes pour la mise en place, environ 30 minutes pour le tutoriel complet Ce qu’il vous faut : Python 3.8+, navigateur Chrome (pour inspecter les pages), éditeur de texte ou IDE
Installez les bibliothèques nécessaires :
pip install httpx beautifulsoup4 pandas lxml
Voici leur rôle :
- httpx — client HTTP plus performant que
requestsavec support asynchrone - beautifulsoup4 + lxml — analyse HTML
- pandas — export des données vers CSV/Excel
- En option : selenium ou playwright si vous devez rendre des pages très riches en JavaScript
Comprendre la structure des pages Zillow avant d’extraire
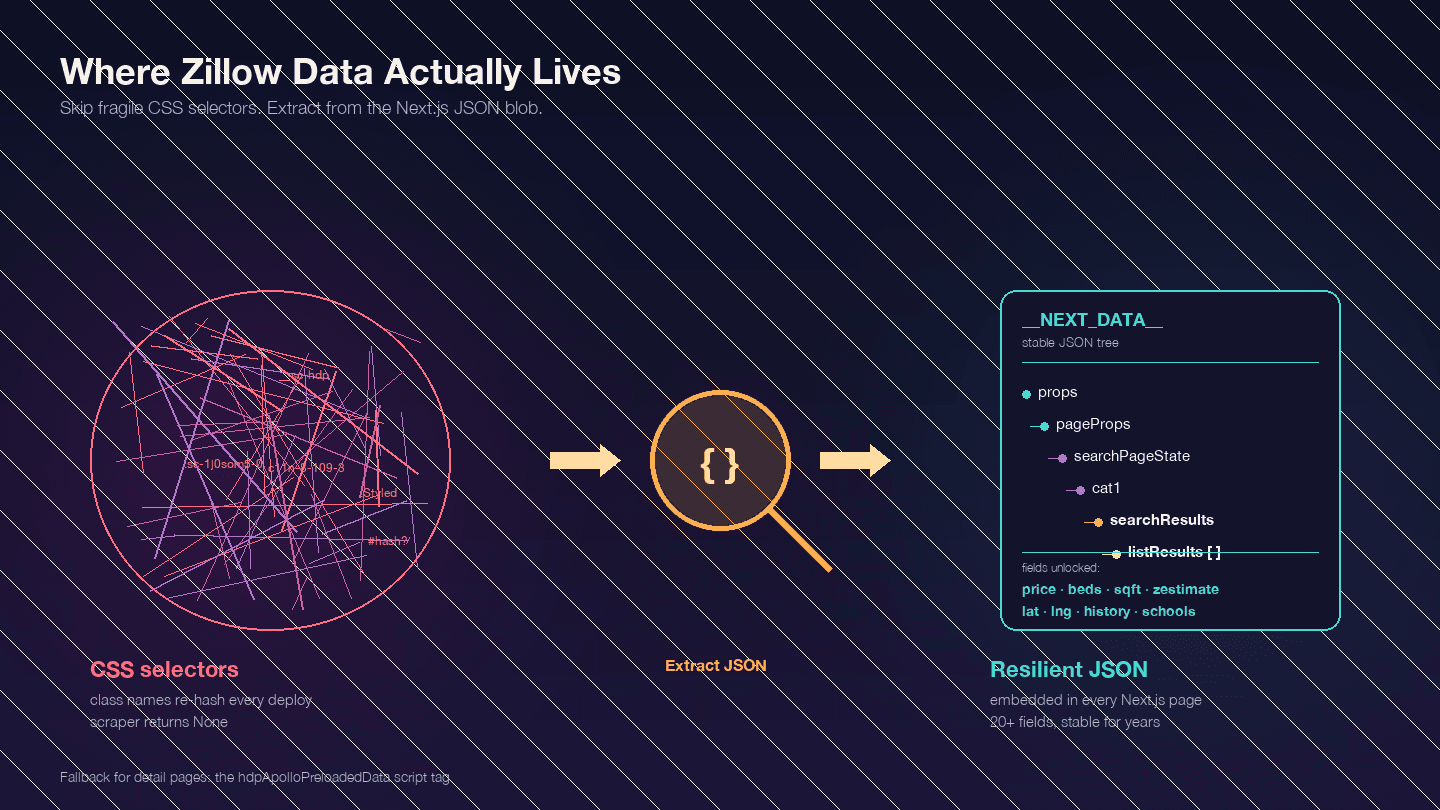
C’est l’élément le plus important à comprendre avant d’écrire le moindre code. Zillow est une application Next.js — confirmé par des publications d’ingénieurs Zillow. Cela signifie que la plupart des données recherchées ne se trouvent pas dans le HTML visible. Elles sont intégrées dans un blob JSON <script id="__NEXT_DATA__">.
Ouvrez n’importe quelle page de bien immobilier sur Zillow, appuyez sur F12, allez dans Elements, puis recherchez __NEXT_DATA__. Vous trouverez un énorme objet JSON contenant toutes les données de l’annonce — prix, coordonnées, caractéristiques du bien, historique des prix, données fiscales, notes des écoles, etc.
Pourquoi est-ce important ? Les noms de classes CSS de Zillow sont hachés (générés par styled-components) et changent à chaque déploiement. Une classe comme StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0 aura un hash complètement différent la semaine suivante. Tout extracteur basé sur des sélecteurs CSS cassera régulièrement.
L’approche JSON __NEXT_DATA__ est bien plus stable, car elle ne dépend pas du tout de la structure HTML.
Principaux chemins JSON pour les résultats de recherche :
| Chemin | Contenu |
|---|---|
props.pageProps.searchPageState.cat1.searchResults.listResults | Tableau des résultats de recherche |
props.pageProps.searchPageState.cat1.searchResults.mapResults | Résultats de la vue carte |
props.pageProps.searchPageState.cat1.searchList.totalPages | Nombre total de pages disponibles |
Pour les pages de détail, certaines utilisent __NEXT_DATA__ et d’autres un script alternatif hdpApolloPreloadedData. Le code ci-dessous gère les deux cas.
Étape par étape : comment extraire Zillow avec Python
Étape 1 : définir des en-têtes HTTP pour éviter un blocage immédiat
Envoyer un simple httpx.get() à Zillow renvoie une page CAPTCHA, pas les données des annonces. Zillow utilise PerimeterX (HUMAN Security) en plus de Cloudflare — les deux sont classés 8/10 en difficulté par les benchmarks de scraping. Le système vérifie votre empreinte TLS, vos en-têtes HTTP et la réputation de votre IP.
Voici les en-têtes minimum qui fonctionnent en 2025 :
import httpx
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
"image/avif,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Sec-Ch-Ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
"Sec-Ch-Ua-Platform": '"Windows"',
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
}
Les en-têtes Sec-Ch-Ua sont essentiels. Beaucoup de tutoriels les omettent — c’est précisément pour cela que leur code ne fonctionne pas face à PerimeterX.
Étape 2 : extraire les résultats de recherche Zillow
Les URL de recherche Zillow suivent un modèle prévisible. Pour Houston, TX :
- Page 1 :
https://www.zillow.com/houston-tx/ - Page 2 :
https://www.zillow.com/houston-tx/2_p/ - Page 3 :
https://www.zillow.com/houston-tx/3_p/
Chaque page contient environ 41 annonces. Zillow limite les résultats à 20 pages (environ 820 annonces). Pour des jeux de données plus volumineux, il faut découper par zone géographique (nous y revenons plus loin).
Voici le code pour extraire les résultats de recherche en récupérant les données du JSON __NEXT_DATA__ :
from bs4 import BeautifulSoup
import json
import time
import random
def scrape_zillow_search(url):
"""Extraire les données d'annonces depuis une page de résultats Zillow."""
response = httpx.get(url, headers=headers, timeout=15)
if response.status_code != 200:
print(f"Statut {response.status_code} pour {url}")
return []
soup = BeautifulSoup(response.text, "lxml")
script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
if not script_tag:
print("Aucun __NEXT_DATA__ trouvé — probablement bloqué par un CAPTCHA")
return []
next_data = json.loads(script_tag.string)
try:
results = (
next_data["props"]["pageProps"]["searchPageState"]
["cat1"]["searchResults"]["listResults"]
)
except KeyError:
print("Structure JSON inattendue — Zillow a peut-être changé son format")
return []
listings = []
for item in results:
listing = {
"zpid": item.get("zpid"),
"address": item.get("addressStreet"),
"city": item.get("addressCity"),
"state": item.get("addressState"),
"zipcode": item.get("addressZipcode"),
"price": item.get("unformattedPrice") or item.get("price"),
"beds": item.get("beds"),
"baths": item.get("baths"),
"sqft": item.get("area"),
"zestimate": item.get("zestimate"),
"days_on_zillow": item.get("daysOnZillow"),
"listing_url": item.get("detailUrl"),
"img_src": item.get("imgSrc"),
"property_type": item.get("hdpData", {}).get("homeInfo", {}).get("homeType"),
"latitude": item.get("latLong", {}).get("latitude"),
"longitude": item.get("latLong", {}).get("longitude"),
}
listings.append(listing)
return listings
Pour extraire plusieurs pages, bouclez avec des délais :
all_listings = []
base_url = "https://www.zillow.com/houston-tx/"
for page in range(1, 6): # 5 premières pages
url = base_url if page == 1 else f"{base_url}{page}_p/"
print(f"Extraction de la page {page}...")
page_listings = scrape_zillow_search(url)
all_listings.extend(page_listings)
# Délai aléatoire entre 3 et 7 secondes
delay = random.uniform(3, 7)
time.sleep(delay)
print(f"Nombre total d'annonces extraites : {len(all_listings)}")
Vous devriez voir des données d’annonces structurées s’accumuler dans all_listings. Si vous obtenez des résultats vides, consultez la section « Pourquoi les extracteurs cassent » ci-dessous.
Étape 3 : extraire les pages de détail des biens Zillow
Les résultats de recherche donnent les bases. Les pages de détail contiennent les données plus poussées : historique des prix, historique fiscal, notes des écoles, informations sur l’agent et description du bien. Chaque URL d’annonce issue de l’étape 2 mène à une page de détail.
Les pages de détail Zillow utilisent deux formats de données possibles. Voici un code qui prend les deux en charge :
def scrape_zillow_detail(url):
"""Extraire les données détaillées d'un bien depuis une page Zillow."""
response = httpx.get(url, headers=headers, timeout=15)
if response.status_code != 200:
return None
soup = BeautifulSoup(response.text, "lxml")
# Essayer d'abord __NEXT_DATA__ (le plus courant)
script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
if script_tag:
next_data = json.loads(script_tag.string)
try:
cache_str = next_data["props"]["pageProps"]["componentProps"]["gdpClientCache"]
cache = json.loads(cache_str)
first_key = next(iter(cache))
prop = cache[first_key]["property"]
return extract_property_fields(prop)
except (KeyError, StopIteration):
pass
# Solution de repli : hdpApolloPreloadedData
apollo_tag = soup.find("script", {"id": "hdpApolloPreloadedData"})
if apollo_tag:
raw = json.loads(apollo_tag.string)
api_cache = json.loads(raw["apiCache"])
for key, value in api_cache.items():
if "ForSale" in key or "property" in str(value)[:100]:
prop = value.get("property", value)
return extract_property_fields(prop)
return None
def extract_property_fields(prop):
"""Extraire des champs structurés depuis un objet JSON Zillow."""
return {
"zpid": prop.get("zpid"),
"zestimate": prop.get("zestimate"),
"rent_zestimate": prop.get("rentZestimate"),
"description": prop.get("description"),
"year_built": prop.get("yearBuilt"),
"lot_size": prop.get("lotSize"),
"hoa_fee": prop.get("monthlyHoaFee"),
"mls_id": prop.get("mlsid"),
"broker_name": prop.get("brokerName") or prop.get("attributionInfo", {}).get("brokerName"),
"price_history": [
{
"date": event.get("date"),
"event": event.get("event"),
"price": event.get("price"),
}
for event in prop.get("priceHistory", [])
],
"tax_history": [
{
"year": record.get("time"),
"tax_paid": record.get("taxPaid"),
"value": record.get("value"),
}
for record in prop.get("taxHistory", [])
],
"schools": [
{
"name": school.get("name"),
"rating": school.get("rating"),
"distance": school.get("distance"),
}
for school in prop.get("schools", [])
],
}
Parcourez ensuite vos URL d’annonces avec des délais :
detail_data = []
for listing in all_listings[:10]: # Commencez par 10 pour tester
detail_url = listing.get("listing_url")
if not detail_url:
continue
if not detail_url.startswith("http"):
detail_url = f"https://www.zillow.com{detail_url}"
print(f"Extraction du détail : {detail_url}")
detail = scrape_zillow_detail(detail_url)
if detail:
detail_data.append({**listing, **detail})
time.sleep(random.uniform(3, 8))
Après cette étape, vous devriez obtenir une liste de dictionnaires contenant à la fois les données de recherche et les données détaillées pour chaque bien.
Étape 4 : gérer la pagination pour extraire plusieurs pages
Pour les zones qui dépassent 820 annonces (la limite de 20 pages), il faut diviser par zone géographique. L’API interne de Zillow accepte des paramètres mapBounds. La stratégie : découper la carte en quadrants et extraire chaque partie séparément.
def split_bounds(bounds):
"""Diviser les limites de la carte en 4 quadrants."""
mid_lat = (bounds["north"] + bounds["south"]) / 2
mid_lng = (bounds["east"] + bounds["west"]) / 2
return [
{"north": bounds["north"], "south": mid_lat, "east": bounds["east"], "west": mid_lng},
{"north": bounds["north"], "south": mid_lat, "east": mid_lng, "west": bounds["west"]},
{"north": mid_lat, "south": bounds["south"], "east": bounds["east"], "west": mid_lng},
{"north": mid_lat, "south": bounds["south"], "east": mid_lng, "west": bounds["west"]},
]
Pour la plupart des cas d’usage — surveiller 50 à 200 annonces dans une zone précise — la pagination classique par URL suffit. L’approche par quadrants est réservée aux extractions à l’échelle d’une ville ou d’un État.
Étape 5 : exporter vos données Zillow extraites
Enregistrez tout au format CSV avec pandas :
import pandas as pd
df = pd.DataFrame(detail_data)
df.to_csv("zillow_houston_listings.csv", index=False)
print(f"Export de {len(df)} annonces vers zillow_houston_listings.csv")
Pour un export JSON :
with open("zillow_houston_listings.json", "w") as f:
json.dump(detail_data, f, indent=2)
Si vous voulez vous passer complètement de l’étape d’export, Thunderbit exporte gratuitement vers Google Sheets, Airtable et Notion — pratique si vous souhaitez disposer immédiatement des données dans un format collaboratif.
Pourquoi les extracteurs Zillow cassent-ils ? Et comment en construire de robustes
Voici le guide de survie.
D’après mon expérience, les extracteurs cassent sur Zillow pour trois raisons précises — et chacune a une solution concrète.
PerimeterX et CAPTCHA : pourquoi vos requêtes renvoient des données vides
L’intégration PerimeterX de Zillow vérifie plusieurs signaux simultanément : empreinte TLS, en-têtes HTTP, réputation IP et schémas de requêtes. Lorsqu’elle détecte une automatisation, elle renvoie une page CAPTCHA « Press & Hold » au lieu des annonces.
Scénario exact d’échec : vous envoyez une requête avec les en-têtes Python par défaut. Le HTML de réponse contient les scripts de challenge PerimeterX au lieu des données du bien — et votre parse BeautifulSoup ne trouve aucun tag __NEXT_DATA__.
La solution : utilisez les en-têtes complets de l’étape 1, proches d’un vrai navigateur. Si vous effectuez plus que quelques dizaines de requêtes, il vous faut aussi une rotation de proxys (voir plus bas). Pour du scraping intensif, envisagez une bibliothèque comme curl_cffi avec impersonate="chrome" — c’est le seul client HTTP Python capable d’imiter l’empreinte TLS d’un vrai Chrome.
Sélecteurs CSS dynamiques : pourquoi BeautifulSoup renvoie None
Si vous utilisez des sélecteurs CSS comme .list-card-price ou des noms de classe avec hash, votre extracteur cassera à chaque nouveau déploiement de Zillow.
Zillow utilise styled-components, qui génèrent des noms de classe comme StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0. La partie hachée change à chaque build.
La solution : n’utilisez pas de sélecteurs CSS du tout. Extrayez les données du blob JSON __NEXT_DATA__ comme montré dans le code ci-dessus. Cette méthode est stable depuis des années parce que la structure JSON évolue bien moins souvent que le HTML.
Si vous devez absolument analyser le HTML, cherchez des attributs data-test (par exemple data-test="property-card") ou utilisez une correspondance de sous-chaîne sur les classes comme [class*="PropertyCard"]. Mais l’extraction JSON reste la voie la plus fiable.
Rotation de proxys et backoff exponentiel : du code qui survit aux bannissements d’IP
Les IP de centres de données sont immédiatement mises sur liste noire par Zillow. Vous avez besoin de proxys résidentiels pour un accès fiable. Cadence sûre : 1 requête toutes les 3 à 8 secondes par IP, avec moins d’environ 500 requêtes par heure.
Voici un décorateur de retry avec backoff exponentiel et jitter :
import random
import time
def backoff_with_jitter(attempt, base_delay=2, max_delay=60):
"""Backoff exponentiel avec jitter complet, style AWS."""
delay = min(max_delay, base_delay * (2 ** attempt))
return random.uniform(0, delay)
def fetch_with_retry(url, max_retries=5):
for attempt in range(max_retries):
try:
response = httpx.get(url, headers=headers, timeout=15)
if response.status_code == 200:
return response
if response.status_code in (403, 429):
delay = backoff_with_jitter(attempt, base_delay=5)
print(f"Blocage ({response.status_code}). Nouvelle tentative dans {delay:.1f}s...")
time.sleep(delay)
continue
except Exception as e:
if attempt == max_retries - 1:
raise
time.sleep(backoff_with_jitter(attempt))
return None
Et un pool simple de rotation de proxys :
class ProxyPool:
def __init__(self, proxies):
self.proxies = proxies
self.index = 0
self.failures = {}
def get_next(self):
proxy = self.proxies[self.index % len(self.proxies)]
self.index += 1
return {"http://": proxy, "https://": proxy}
def report_failure(self, proxy):
self.failures[proxy] = self.failures.get(proxy, 0) + 1
if self.failures[proxy] > 3:
self.proxies.remove(proxy)
# Utilisation :
pool = ProxyPool(proxies=[
"http://user:pass@residential1.example.com:8080",
"http://user:pass@residential2.example.com:8080",
])
Pour les fournisseurs de proxys, DataImpulse propose des proxys résidentiels à environ 1 $/Go (l’option la moins chère), tandis que IPRoyal et Smartproxy sont de bonnes options milieu de gamme à 4–7 $/Go.
L’alternative sans maintenance
Si vous extraitez Zillow régulièrement et que vous en avez assez de réparer des sélecteurs cassés ou de gérer des pools de proxys, l’IA de Thunderbit relit la structure de la page à chaque extraction. Aucun sélecteur à entretenir, aucune configuration de proxy. Cela règle réellement le problème de fragilité qui rend les extracteurs codés si pénibles au quotidien.
Automatiser l’extraction Zillow : planification et suivi des prix
Tous les investisseurs immobiliers à qui j’ai parlé veulent cela, et aucun autre guide sur Zillow ne l’aborde : des extractions automatisées récurrentes pour suivre les prix.
Pour les utilisateurs Python : tâches cron et détection des variations de prix
Mettez en place une tâche cron qui exécute votre extracteur chaque semaine et signale les changements de prix :
import pandas as pd
from datetime import datetime
def detect_price_changes(new_data, historical_file, threshold=0.05):
"""Comparer la nouvelle extraction avec l’historique et signaler les changements > seuil."""
try:
old = pd.read_csv(historical_file)
except FileNotFoundError:
new_data.to_csv(historical_file, index=False)
print("Premier passage — données de base enregistrées.")
return pd.DataFrame()
merged = new_data.merge(old, on="zpid", suffixes=("_new", "_old"))
merged["price_change_pct"] = (
(merged["price_new"] - merged["price_old"]) / merged["price_old"]
)
alerts = merged[merged["price_change_pct"].abs() > threshold]
# Ajouter les nouvelles données avec horodatage
new_data["scraped_at"] = datetime.now().isoformat()
new_data.to_csv(historical_file, mode="a", header=False, index=False)
return alerts
Ajoutez cela à votre crontab pour une exécution hebdomadaire le lundi à 6 h :
0 6 * * 1 cd /path/to/scraper && python zillow_monitor.py
Exemple concret : surveiller 50 annonces à Austin, TX, chaque semaine. Chaque lundi, le script extrait les prix actuels, les compare à ceux de la semaine précédente, puis génère un CSV mettant en évidence toute baisse supérieure à 5 %.
Pour les non-codeurs : Thunderbit Scheduled Scraper
Le Scheduled Scraper de Thunderbit vous permet de décrire l’intervalle en langage naturel (« chaque lundi à 9 h »), de saisir vos URL de recherche Zillow, puis de cliquer sur Planifier. Les données sont exportées automatiquement vers Google Sheets à chaque exécution. Pas de Python, pas de cron, pas de serveur à maintenir. C’est particulièrement utile pour les agents immobiliers ou les équipes opérationnelles qui ont besoin d’un suivi régulier des prix sans support technique.
Conseils pour extraire Zillow de manière responsable
Quelques rappels pour rester dans un cadre raisonnable :
- N’extrayez que des données accessibles publiquement. N’accédez pas aux pages protégées par authentification.
- Respectez des cadences de requêtes raisonnables. 3 à 8 secondes entre chaque requête. N’inondez pas le serveur.
- N’extrayez pas de données personnelles ou privées. Les noms d’agents et les informations d’agence visibles sur les annonces sont publiques ; les données de comptes utilisateurs ne le sont pas.
- Stockez et utilisez les données de façon éthique. La veille de marché, l’analyse d’investissement et la génération de leads sont des usages légitimes. Le spam ne l’est pas.
- Contexte juridique : l’arrêt hiQ v. LinkedIn a établi que l’extraction de données publiquement accessibles ne viole pas le CFAA. La décision Meta v. Bright Data (2024) a confirmé des principes similaires. Cela dit, les conditions d’utilisation de Zillow limitent l’accès automatisé, et la société applique ces restrictions via des bannissements d’IP et des CAPTCHA plutôt que par action judiciaire. Vérifiez toujours les recommandations à jour et respectez robots.txt.
Choisir la bonne approche pour extraire Zillow avec Python
La meilleure méthode dépend de votre contexte :
Besoin de données rapidement, sans code ? Thunderbit vous fait passer d’une page de recherche Zillow à un tableur structuré en environ 2 minutes. L’IA s’adapte aux changements de mise en page, gère la pagination et exporte gratuitement. Installez l’extension Chrome et testez-la sur une page Zillow.
Vous voulez un contrôle total ? Utilisez le code Python de ce guide. Extrayez les données du JSON __NEXT_DATA__ (et non des sélecteurs CSS) pour plus de stabilité. Définissez des en-têtes réalistes de type navigateur. Faites tourner des proxys résidentiels et utilisez un backoff exponentiel pour plus de fiabilité.
Vous passez à l’échelle ? Les API de scraping comme ScrapFly (taux de réussite de 99 % sur Zillow) ou ScraperAPI gèrent pour vous l’infrastructure proxy et CAPTCHA, pour 30 à 599 $ par mois selon le volume.
Vous suivez les prix dans le temps ? Mettez en place une tâche cron avec le script de détection des variations de prix, ou utilisez le Scheduled Scraper de Thunderbit pour une approche sans maintenance.
Les données sont là. La seule question est le temps d’ingénierie que vous voulez y consacrer. Pour en savoir plus sur l’intégration des données web dans des tableurs, consultez notre guide sur l’extraction de données d’un site vers Excel ou notre récapitulatif des statistiques Zillow pour les dernières données sur la plateforme. Vous pouvez aussi regarder des tutoriels sur la chaîne YouTube Thunderbit.
Essayez Thunderbit pour extraire Zillow Get Started Free
FAQ
Peut-on extraire Zillow avec Python gratuitement ?
Oui — httpx, BeautifulSoup et pandas sont tous gratuits et open source. Le compromis, c’est le temps : vous devrez gérer vous-même les en-têtes, la rotation des proxys et la maintenance des sélecteurs. Comptez 4 à 8 heures pour la mise en place initiale et 4 à 10 heures par mois pour la maintenance lorsque Zillow modifie son site. Thunderbit propose aussi une offre gratuite si vous voulez éviter complètement la charge de développement.
Zillow propose-t-il une API officielle ?
Zillow a supprimé son API publique gratuite en septembre 2021. L’accès passe désormais par Bridge Interactive, qui nécessite une approbation, coûte environ 500 $ par mois et s’adresse aux professionnels agréés de l’immobilier. Pour la plupart des utilisateurs — investisseurs, chercheurs, agents réalisant des analyses de marché — l’extraction reste l’alternative la plus pratique. Zillow publie toutefois encore des données de recherche gratuites sous forme de CSV téléchargeables sur zillow.com/research/data/, notamment le Zillow Home Value Index et le Zillow Observed Rent Index.
Comment éviter d’être bloqué lors de l’extraction de Zillow ?
Trois points : (1) utilisez des en-têtes de navigateur réalistes, y compris Sec-Ch-Ua — c’est l’en-tête que la plupart des tutoriels oublient, et celui que PerimeterX vérifie en premier ; (2) faites tourner des proxys résidentiels — les IP de centres de données sont immédiatement blacklistées ; (3) extrayez les données depuis le JSON __NEXT_DATA__ au lieu des sélecteurs HTML pour éviter les ruptures dues aux changements de mise en page. Maintenez un rythme d’environ 1 requête toutes les 3 à 8 secondes par IP. Ou utilisez un outil comme Thunderbit qui gère automatiquement la protection anti-bot.
Quelle est la meilleure façon d’extraire Zillow sans coder ?
L’AI Web Scraper de Thunderbit est la voie la plus rapide. Installez l’extension Chrome, ouvrez une page de recherche Zillow, cliquez sur « AI Suggest Fields » pour détecter automatiquement les colonnes, puis cliquez sur « Scrape ». Exportez vers Google Sheets, Excel, Airtable ou Notion sans écrire une ligne de code. L’IA relit la page à chaque fois, donc elle ne casse pas lorsque Zillow met à jour sa mise en page.
À quelle fréquence Zillow modifie-t-il la structure de son site, et quel impact sur les extracteurs ?
Zillow déploie des mises à jour fréquemment — parfois chaque semaine. Comme le site utilise styled-components, les noms de classes CSS changent à chaque déploiement, et les extracteurs construits sur des sélecteurs CSS cassent régulièrement. Pour Python, l’approche la plus robuste consiste à extraire le blob JSON __NEXT_DATA__, dont la structure change bien moins souvent. Pour une approche sans maintenance, l’IA de Thunderbit relit la structure de la page à chaque extraction et s’adapte automatiquement aux changements de mise en page.
En savoir plus
- Comment faire du web scraping sans se faire bloquer en Python
- Web scraping Python : éviter les blocages avec une utilisation intelligente des proxys
- Comment extraire des données d’un site web avec Python efficacement
- Comment créer un web scraper avec Python : du début à la fin
- Guide complet du web scraping en Python : pas à pas




