Yelp regroupe répartis sur — et transformer ces données en un format exploitable n’a jamais été aussi corsé. La répression anti-bots menée par Yelp en 2024–2025 a discrètement cassé la plupart des tutoriels Python existants pour le scraping.
Si vous avez récemment tenté d’utiliser un scraper Yelp et que vous vous êtes heurté à une avalanche d’erreurs 403, à des réponses HTML vides ou à des CAPTCHA apparus récemment, vous n’imaginez rien. Yelp s’appuie désormais sur le fingerprint TLS/JA3, des noms de classes CSS obfusqués et tournants, ainsi que sur un scoring agressif de réputation IP — ce qui signifie que l’ancienne méthode requests + BeautifulSoup, encore recommandée partout, plante dès la première requête. J’ai passé des semaines à tester différentes approches face à la pile actuelle de Yelp, et ce guide couvre tout ce qui fonctionne réellement en 2025 : l’API officielle Fusion (et pourquoi elle ne suffira probablement pas), un workflow Python complet avec une stratégie anti-blocage en couches, ainsi qu’une alternative no-code en 2 clics avec pour ceux qui veulent simplement les données, sans se taper le marathon de débogage.
Pourquoi extraire Yelp avec Python ? Et qui y gagne vraiment ?
Avant d’écrire une seule ligne de code, quelle est la vraie valeur métier des données Yelp ? La plateforme n’est pas juste un site d’avis pour restos : c’est en pratique une base vivante d’entreprises locales avec coordonnées structurées, notes, catégories, horaires et des centaines de millions d’avis clients.
Voici les profils qui en tirent le plus de valeur et ce qu’ils en extraient :
| Cas d’usage | Champs de données clés | Pourquoi c’est important |
|---|---|---|
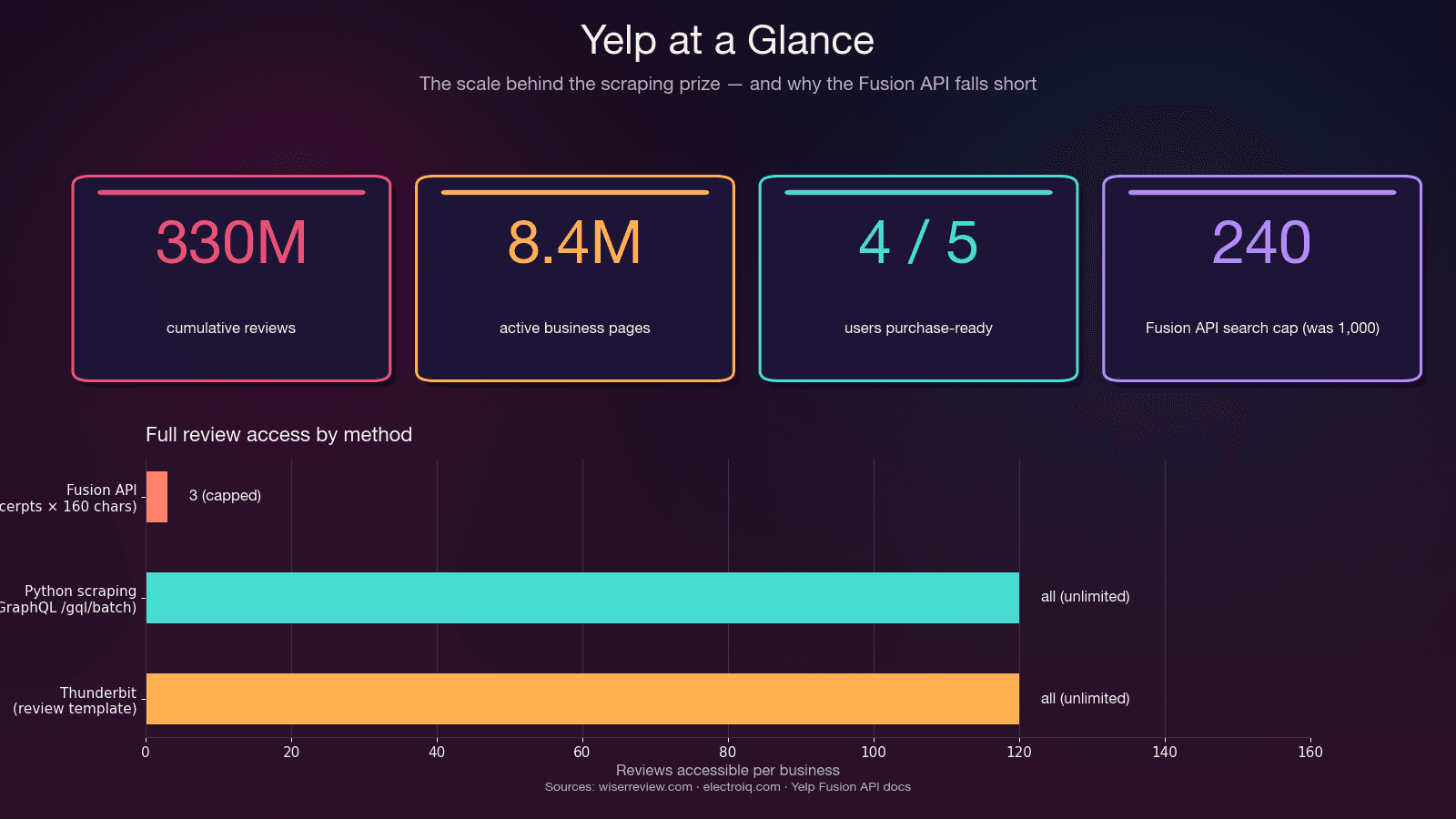
| Ventes et génération de leads | Nom de l’entreprise, téléphone, site web, adresse, catégorie, note | Construire des listes de prospects ciblées pour des PME locales — 4 utilisateurs Yelp sur 5 sont prêts à acheter dès leur arrivée |
| Veille concurrentielle | Avis, notes, volume d’avis, sentiment | Surveiller la réputation des concurrents, repérer les lacunes de service, suivre les tendances |
| Études de marché et NLP | Texte intégral des avis, dates, métadonnées des auteurs | Analyse de sentiment, modélisation de sujets — les avis Yelp comptent parmi les corpus NLP les plus utilisés dans la recherche académique |
| Immobilier et choix d’emplacement | Densité d’entreprises, mix de catégories, qualité des avis par zone | Sélection de sites pour franchises et enseignes — Yelp vend d’ailleurs Location Intelligence comme produit B2B sous licence pour précisément cet usage |
| E-commerce et opérations | Signaux de prix, plaintes clients, horaires de service | Suivre la manière dont les concurrents sont évalués et identifier des schémas opérationnels |
Le fil conducteur est simple : l’objectif réel, c’est la donnée structurée, et Python n’est qu’un moyen d’y parvenir. Certains lecteurs voudront un contrôle programmatique total. D’autres auront juste besoin d’un tableur avec les coordonnées de plombiers à Austin. Ce guide couvre les deux approches.
API Yelp Fusion ou scraping Python : que faut-il choisir ?
La plupart des guides zappent complètement cette question et passent directement au code, sans vérifier si l’ officielle — désormais rebaptisée « Yelp Places API » — n’aurait pas suffi. D’après mon expérience, ce simple arbitrage fait gagner des heures perdues, car l’API est excellente pour certaines tâches et franchement insuffisante pour d’autres.
Ce que l’API Fusion fournit réellement
L’API Fusion propose la recherche d’entreprises structurée, les détails d’une entreprise, l’autocomplétion et un endpoint d’avis. Elle est autorisée, bien documentée et ne nécessite pas de bidouille anti-bot.
Mais tout se complique avec l’endpoint d’avis. Voici ce que des employés de Yelp ont confirmé sur GitHub :
« L’API Yelp ne renvoie pas le texte intégral des avis. Trois extraits de 160 caractères sont fournis par défaut. » —
Ce n’est pas un bug, c’est voulu. L’API est limitée à 3 extraits d’avis (7 avec Premium), chacun tronqué à environ 160 caractères. Pas de métadonnées d’avis (votes utile/drôle/sympa), pas d’historique de l’auteur, pas de réponses du propriétaire. Et la après mai 2023 — contre 5 000 auparavant. Les tarifs commencent à .
Cadre de décision
| Critère | API Yelp Fusion | Scraping Python | Thunderbit (no-code) |
|---|---|---|---|
| Avis complets | ❌ Seulement 3 extraits (~160 caractères chacun) | ✅ Tous les avis via GraphQL | ✅ Tous les avis visibles |
| Limites de requêtes | 300–500/jour (nouveaux) ; 5 000 (anciens) | À votre charge (budget proxy) | Basé sur des crédits |
| Effort de mise en place | ~15 min (clé API + SDK) | De quelques heures à plusieurs jours | ~2 minutes |
| Champs métiers | ~20 champs structurés | Illimités (analyse HTML/JSON) | Champs suggérés par IA |
| Gestion anti-bot | N/A (autorisé) | À construire soi-même | Gérée automatiquement |
| Risque légal | ✅ Autorisé | ⚠️ Zone grise des CGU | ⚠️ Même risque que le scraping |
| Coût | 29 $/mois minimum | Gratuit (+ coûts proxy 0,75–4 $/Go) | Offre gratuite disponible |
| Maintenance | Faible (API stable) | Élevée (sélecteurs cassés, anti-bot plus strict) | Faible (l’IA se réadapte) |
Choisissez l’API Fusion si : vous avez besoin d’informations basiques sur les entreprises, de recherches à petite échelle ou d’une intégration autorisée — et que 3 extraits d’avis par entreprise suffisent.
Choisissez le scraping Python si : vous avez besoin du texte intégral des avis, de tous les avis d’une entreprise, des métadonnées d’avis, de plus de 240 résultats par recherche, ou si votre budget est inférieur à 29 $/mois.
Choisissez Thunderbit si : vous voulez les données vite, sans écrire ni maintenir de code. On détaille ça dans la section no-code ci-dessous.
L’astuce no-code : extraire Yelp avec Thunderbit (sans Python)
Avant de rentrer dans le détail côté Python, voici l’option la plus rapide pour ceux dont le vrai but est la donnée, pas l’exercice de code. Tous les guides concurrents partent du principe que tu maîtrises Python, mais dans mon travail chez Thunderbit, j’ai constaté qu’une grande partie des personnes qui cherchent « scrape Yelp » sont des commerciaux, des responsables opérations et des dirigeants de petites entreprises qui veulent simplement un tableur d’entreprises locales — pas un cours express sur le fingerprint TLS.
propose déjà des modèles Yelp prêts à l’emploi :
- — extrait le nom de l’entreprise, la note, les coordonnées, l’adresse, les horaires et la catégorie
- — extrait le nom d’utilisateur de l’auteur, le contenu de l’avis, la note, la date et la localisation de l’auteur
Comment ça marche en pratique
- Ouvrez une page de résultats Yelp ou une page d’entreprise dans Chrome
- Cliquez sur AI Suggest Fields dans l’ — l’IA lit la page et propose des colonnes (nom de l’entreprise, note, nombre d’avis, gamme de prix, catégorie, adresse, téléphone, URL)
- Cliquez sur Scrape — et c’est plié
Avec les modèles Yelp prêts à l’emploi, c’est encore plus simple : ouvre le modèle, clique sur Scrape.
Le scraping de sous-pages gère automatiquement l’enrichissement — pars d’une page de résultats Yelp, active le scraping de sous-pages, et Thunderbit visite chaque page d’entreprise pour récupérer les horaires, les avis complets, le site web, les photos et les équipements. Aucun réglage supplémentaire.
La pagination est automatique — qu’elle soit basée sur les clics ou sur le défilement, elle est prise en charge nativement. (Pour plus de détails, consulte notre .)
Les exports sont gratuits sur tous les plans — Excel, Google Sheets, Airtable, Notion, CSV, JSON. Pas de pandas, pas de code d’écriture CSV.
Comparaison du temps nécessaire
| Temps | Scraper Python | Thunderbit |
|---|---|---|
| Premier lancement | De quelques heures à plusieurs jours (écrire les sélecteurs, gérer la pagination, les proxys, la logique de retry) | ~30 secondes avec le modèle Yelp prêt à l’emploi |
| Quand Yelp change le balisage | Réécriture manuelle des sélecteurs | Relancer AI Suggest Fields — réadaptation automatique |
| Quand l’IP est bloquée | Déboguer, faire tourner les pools de proxys, retester | Le mode cloud gère la rotation d’IP |
| Export vers Google Sheets | Écrire l’auth OAuth + le raccordement pandas | Un clic, gratuit |
Si tu testes Thunderbit d’abord et qu’il couvre ton besoin, tu peux sauter le reste de l’article. Si tu as besoin d’un contrôle programmatique complet, de champs personnalisés ou d’une montée en charge au-delà de quelques milliers d’enregistrements par mois — continue.
Bibliothèques Python pour scraper Yelp : laquelle choisir ?
« Dois-je utiliser Scrapy, BS4+requests ou Selenium ? » est l’une des questions les plus fréquentes dans les discussions r/webscraping sur Yelp. Pourtant, chaque tutoriel choisit sa bibliothèque préférée sans expliquer pourquoi. Voici une comparaison honnête.
La réalité en 2025 : requests + BeautifulSoup est cassé pour Yelp
La pile que chaque tutoriel classique Yelp recommande — pip install requests beautifulsoup4 — te fait bloquer dès la première requête en 2025. Pas à la 50e. À la première.
La raison : la bibliothèque requests de Python embarque une empreinte TLS/JA3 qui ne correspond à aucun navigateur réel. La couche anti-bot de Yelp la détecte au niveau de la poignée de main TLS, avant même la lecture de ton en-tête User-Agent. Je l’ai testé à répétition — nouvelle IP, en-têtes réalistes, délais aléatoires — et j’obtenais quand même immédiatement un 403 Forbidden avec requests brut.
Matrice de choix des bibliothèques
| Bibliothèque | Idéale pour | Gère le JS ? | Anti-bot ? | Courbe d’apprentissage | Vitesse |
|---|---|---|---|---|---|
requests + BeautifulSoup | ❌ | ❌ | Très faible | Rapide (jusqu’au blocage) | |
httpx async + parsel | Scraping asynchrone à grande échelle | ❌ | ❌ | Faible | Très rapide |
curl_cffi + parsel | Spécifique Yelp : impersonation TLS | ❌ | ✅ TLS/JA3/HTTP2 | Faible | Très rapide |
Scrapy 2.14 | Pipelines de crawl complets avec pagination | Partiel (via scrapy-playwright) | AutoThrottle, middleware de retry | Moyenne à élevée | Rapide |
Selenium 4.43 / Playwright 1.58 | Pages très dépendantes du JS, contournement de CAPTCHA | ✅ | Partiel | Moyenne | Lente (~10–30 pages/min) |
| Thunderbit | Non-développeurs, extraction rapide | ✅ (navigateur) | Intégré (mode Cloud) | Très faible | Rapide |
La révélation curl_cffi
La bibliothèque qui a changé mon workflow de scraping Yelp est — un binding Python pour curl-impersonate. Elle reproduit exactement la même empreinte TLS/JA3 + HTTP/2 qu’un vrai Chrome, et son API remplace requests sans changement majeur :
1from curl_cffi import requests
2r = requests.get(
3 "https://www.yelp.com/biz/some-restaurant",
4 impersonate="chrome131",
5)
6print(r.status_code, len(r.text))Ce simple changement — from curl_cffi import requests plus impersonate="chrome131" — contourne la sans lancer de navigateur. Dans mes tests, la différence est nette : de 403 immédiats à des réponses 200 propres.
Ma pile recommandée pour Yelp en 2025 : curl_cffi + parsel + jmespath + proxys résidentiels. Si tu as besoin d’un pipeline complet avec planification, intègre ça dans Scrapy 2.14 via un middleware de téléchargement basé sur curl_cffi.
Préparer votre environnement Python pour extraire Yelp
- Niveau : intermédiaire
- Temps nécessaire : ~15 minutes pour l’installation, 1 à 2 heures pour un scraper fonctionnel
- Ce qu’il vous faut : Python 3.10+ (3.12 recommandé), un terminal, et éventuellement un fournisseur de proxys résidentiels
Étape 1 : créer un environnement virtuel et installer les packages
1python3.12 -m venv .venv
2source .venv/bin/activate # Sous Windows : .venv\Scripts\activate
3pip install "curl_cffi>=0.11" "parsel>=1.9" "jmespath>=1.0" pandasRôle de chaque package :
curl_cffi— effectue les requêtes HTTP avec l’empreinte TLS de Chrome (le contournement anti-bot)parsel— sélecteurs CSS/XPath pour parser le HTML (moteur proche de Scrapy, mais plus léger)jmespath— requêtes JSON déclaratives (plus propre que l’accès imbriqué à des dictionnaires pour le JSON embarqué de Yelp)pandas— export des données en CSV/Excel
Optionnel mais utile :
1pip install fake-useragent # Remarque : dépôt archivé en avril 2026, mais encore installableÉtape par étape : comment extraire Yelp avec Python
Voici le tutoriel central. L’idée clé qui rend l’ensemble bien plus robuste : évite les sélecteurs CSS, récupère plutôt le JSON caché. Yelp randomise les noms de classes CSS à la compilation (y-css-14xwok2 une semaine, y-css-hcq7b9 la suivante), donc tout scraper dépendant de ces classes casse en quelques semaines. Les payloads JSON intégrés — application/ld+json et react-root-props — sont stables.
Étape 2 : extraire les résultats de recherche Yelp
Les URL de recherche Yelp suivent un schéma prévisible : https://www.yelp.com/search?find_desc={term}&find_loc={location}. Les données des résultats sont intégrées dans une balise <script data-id="react-root-props"> sous forme de JSON — et non pas dispersées dans un fouillis de classes CSS.
1import re, json, jmespath
2from curl_cffi import requests
3from parsel import Selector
4> This paragraph contains content that cannot be parsed and has been skipped.
5> This paragraph contains content that cannot be parsed and has been skipped.
6Tu devrais obtenir une liste de dictionnaires contenant le nom de l’entreprise, l’URL, la note et le nombre d’avis. Si `react-root-props` est absent de la réponse, cela signifie que tu as reçu une coquille de blocage — change d’IP et réessaie.
7L’en-tête `Cookie: intl_splash=false` est un contournement standard du redirect Yelp vers la page de pays. Sans lui, les IP non américaines tombent sur une page d’accueil pays qui ressemble à un blocage doux, mais n’en est pas un.
8### Étape 3 : extraire les pages d’entreprise Yelp
9Chaque URL d’entreprise issue des résultats mène à une page de détail avec des données plus riches. La cible d’extraction la plus stable est le bloc `<script type="application/ld+json">` — il contient des données schema.org structurées que Yelp maintient pour le SEO et n’obfusque pas.
10```python
11def scrape_business(biz_url: str) -> dict:
12 url = f"https://www.yelp.com{biz_url}" if biz_url.startswith("/") else biz_url
13 r = requests.get(url, headers=HEADERS, impersonate="chrome131")
14 if r.status_code != 200:
15 return {"url": url, "error": r.status_code}
16 sel = Selector(text=r.text)
17 biz_id = sel.css('meta[name="yelp-biz-id"]::attr(content)').get()
18 for raw in sel.css('script[type="application/ld+json"]::text').getall():
19 try:
20 data = json.loads(raw)
21 except json.JSONDecodeError:
22 continue
23 for node in (data if isinstance(data, list) else [data]):
24 if node.get("@type") in (
25 "Restaurant", "LocalBusiness", "FoodEstablishment",
26 "HealthAndBeautyBusiness", "HomeAndConstructionBusiness",
27 ):
28 return {
29 "biz_id": biz_id,
30 "name": node.get("name"),
31 "rating": (node.get("aggregateRating") or {}).get("ratingValue"),
32 "review_count": (node.get("aggregateRating") or {}).get("reviewCount"),
33 "address": node.get("address"),
34 "telephone": node.get("telephone"),
35 "price_range": node.get("priceRange"),
36 "hours": node.get("openingHours"),
37 "url": url,
38 }
39 return {"biz_id": biz_id, "url": url}La valeur meta[name="yelp-biz-id"] correspond à l’identifiant encodé de l’entreprise dont tu auras besoin pour l’endpoint d’avis. Récupère-le ici — tu l’utiliseras à l’étape suivante.
Étape 4 : extraire les avis Yelp avec pagination
C’est ici que l’API Fusion montre ses limites et que le scraping prend l’avantage. L’endpoint GraphQL interne de Yelp renvoie le texte intégral des avis, les infos sur l’auteur, les dates, les notes et les comptages de votes — tout ce que l’API refuse de fournir.
L’endpoint est https://www.yelp.com/gql/batch, et il utilise un documentId statique pour l’opération GetBusinessReviewFeed. La pagination passe par un curseur encodé en base64.
1import base64
2GQL_URL = "https://www.yelp.com/gql/batch"
3DOC_ID = "ef51f33d1b0eccc958dddbf6cde15739c48b34637a00ebe316441031d4bf7681"
4> This paragraph contains content that cannot be parsed and has been skipped.
5Chaque page renvoie 10 avis. Incrémentez l’`offset` dans le curseur base64 pour paginer. Le paramètre `sortBy` accepte `DATE_DESC` (plus récents d’abord), `RATING_ASC`, `RATING_DESC` et d’autres valeurs.
6### Étape 5 : exporter vos données Yelp extraites
7```python
8import pandas as pd
9# En supposant que vous avez récupéré les entreprises et les avis
10df_businesses = pd.DataFrame(businesses)
11df_businesses.to_csv("yelp_businesses.csv", index=False)
12df_reviews = pd.DataFrame(all_reviews)
13df_reviews.to_csv("yelp_reviews.csv", index=False)
14> This paragraph contains content that cannot be parsed and has been skipped.
15Pour les lecteurs qui préfèrent le no-code, Thunderbit exporte les mêmes données directement vers Excel, Google Sheets, Airtable ou Notion — sans pandas ni code d’écriture de fichiers.
16## Le plan anti-blocage : comment scraper Yelp sans se faire bloquer
17Cette section est la vraie raison d’être de l’article. Les mesures anti-bot de Yelp sont devenues nettement plus strictes depuis fin 2024 — [fingerprinting TLS, contrôle de réputation IP, CAPTCHA et analyse comportementale](https://blog.apify.com/how-to-scrape-yelp/) sont tous de la partie. La plupart des guides existants sont obsolètes car écrits avant cette offensive.
18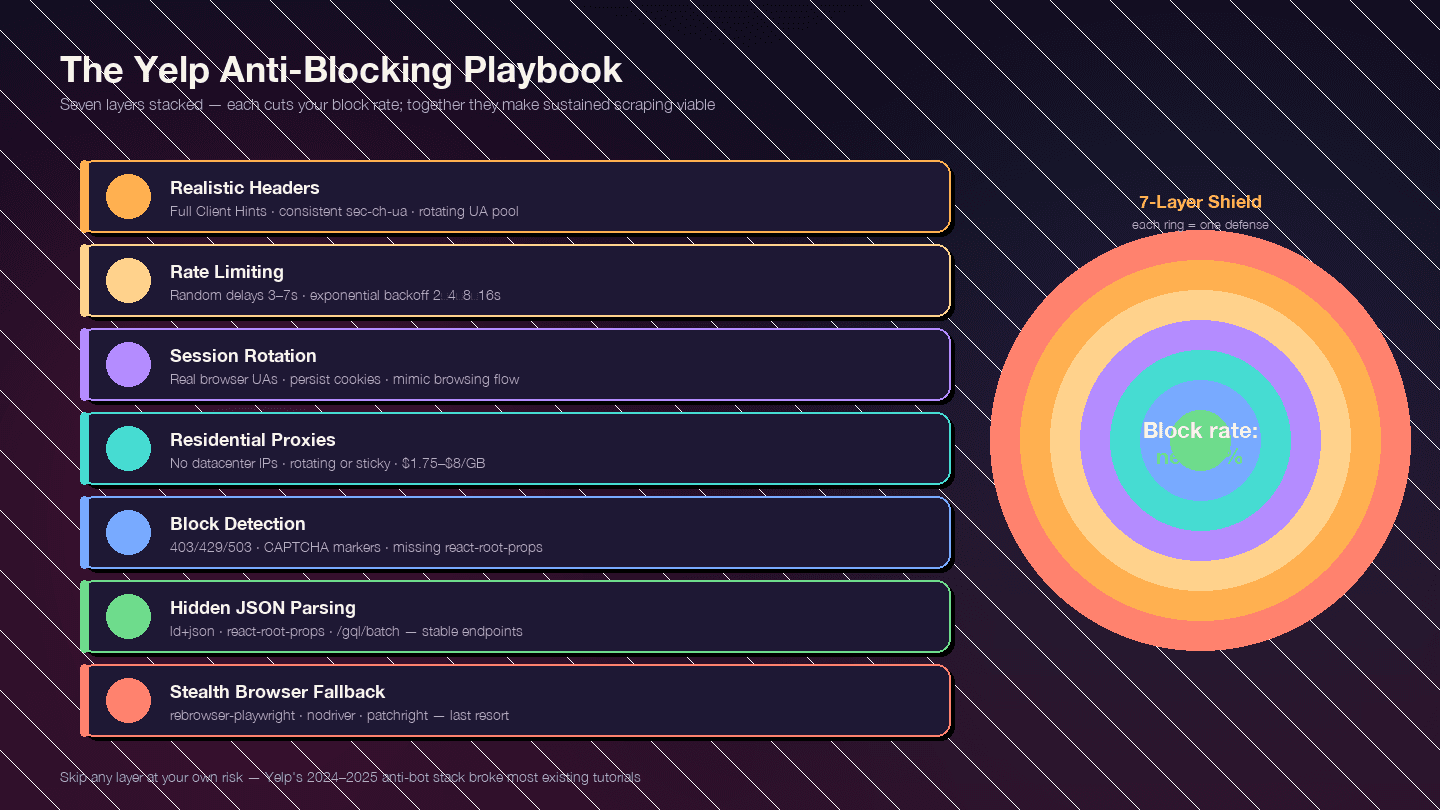
19La stratégie fonctionne par couches. Chaque couche réduit ton taux de blocage ; ensemble, elles rendent le scraping durablement viable.
20### Couche 1 : des en-têtes de requête réalistes
21Les en-têtes par défaut de `requests` envoient `User-Agent: python-requests/2.x` — blocage instantané. Mais un User-Agent réaliste ne suffit pas. Yelp vérifie tout l’ensemble des en-têtes [Client Hints](https://scraperapi.com/web-scraping/yelp/) pour s’assurer qu’ils collent entre eux.
22```python
23FULL_HEADERS = {
24 "authority": "www.yelp.com",
25 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
26 "AppleWebKit/537.36 (KHTML, like Gecko) "
27 "Chrome/124.0.0.0 Safari/537.36",
28 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
29 "image/avif,image/webp,image/apng,*/*;q=0.8",
30 "accept-language": "en-US,en;q=0.9",
31 "accept-encoding": "gzip, deflate, br",
32 "sec-ch-ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
33 "sec-ch-ua-mobile": "?0",
34 "sec-ch-ua-platform": '"Windows"',
35 "sec-fetch-dest": "document",
36 "sec-fetch-mode": "navigate",
37 "sec-fetch-site": "same-origin",
38 "sec-fetch-user": "?1",
39 "upgrade-insecure-requests": "1",
40 "referer": "https://www.yelp.com/",
41 "cookie": "intl_splash=false",
42}Trois erreurs qui te font repérer :
- Le UA prétend être Chrome mais
sec-ch-uaest absent ou contredit la version annoncée sec-ch-ua-platformindique "Windows" alors que la chaîne UA indique macOS- Le même UA exact est utilisé pour des milliers de requêtes depuis une seule IP — fais tourner un pool de 10 à 20 chaînes récentes Chrome/Firefox/Safari
Couche 2 : limitation de débit et délais aléatoires
Des schémas temporels prévisibles sont un signal d’alerte. Ajoute des intervalles de sommeil aléatoires et mets en place un backoff exponentiel sur les erreurs.
1import random, time
2> This paragraph contains content that cannot be parsed and has been skipped.
3> This paragraph contains content that cannot be parsed and has been skipped.
4### Couche 3 : rotation des User-Agent et des sessions
5Fais tourner un pool de chaînes User-Agent réelles de navigateurs. Conserve les sessions et les cookies pour imiter un comportement de navigation naturel — Yelp utilise une détection basée sur les cookies, donc créer une nouvelle session à chaque requête est en soi suspect.
6```python
7UA_POOL = [
8 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
9 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
10 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:125.0) Gecko/20100101 Firefox/125.0",
11 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14.4; rv:125.0) Gecko/20100101 Firefox/125.0",
12 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/605.1.15 Safari/17.4.1",
13 # Ajoutez 5 à 10 chaînes récentes supplémentaires
14]Couche 4 : rotation des proxys
À volume réel, il te faut des proxys résidentiels. Les proxys datacenter et les proxys gratuits ne fonctionnent pas sur Yelp — la couche de réputation IP de Yelp renvoie des 403 par anticipation sur les plages AWS, GCP et DigitalOcean.
| Fournisseur | Prix d’entrée / Go | Remarques |
|---|---|---|
| IPRoyal | 1,75 $/Go | Le moins cher ; exécute le tutoriel Yelp le plus cité |
| Decodo (ex-Smartproxy) | 3,20–3,50 $ | Meilleur ratio Go/$ à grande échelle |
| Bright Data | 4,00 $ (PAYG) | Plus de 150 M d’IP ; page dédiée Yelp Proxies |
| Oxylabs | 6,00–8,00 $ | Premium ; plus de 10 M d’IP |
| Aluvia (SIM mobile) | 3,00 $ | Vraies IP mobiles d’opérateurs US, pensées pour Yelp |
Les proxys résidentiels tournants (nouvelle IP par requête) sont les meilleurs pour les crawls de recherche à gros volume. Les sessions persistantes (une IP conservée pendant 10 minutes) sont préférables lorsque tu dois garder les cookies tout au long d’un flux page entreprise → avis → pagination.
Couche 5 : détecter et gérer les blocages
Tous les blocages ne se présentent pas de la même manière. Yelp affiche souvent un shell générique de type « page not available » plutôt qu’un CAPTCHA, ce qui pousse les scrapers naïfs à croire qu’ils récupèrent des données alors qu’ils reçoivent en réalité une réponse vide.
1BLOCK_MARKERS = (
2 "captcha", "px-captcha", "page not available",
3 "access denied", "unusual traffic",
4)
5def is_blocked(resp):
6 if resp.status_code in (401, 403, 429, 503):
7 return True
8 body = resp.text.lower()
9 if any(m in body for m in BLOCK_MARKERS):
10 return True
11 # Si c’est une page de recherche/entreprise mais que react-root-props est absent,
12 # Yelp a renvoyé une réponse de blocage épurée
13 if "react-root-props" not in body and "/biz/" in str(resp.url):
14 return True
15 return False| Signal | Signification |
|---|---|
| HTTP 403 | Blocage dur — IP/headers/TLS grillés |
| HTTP 429 | Limitation de débit — souvent récupérable avec backoff |
| HTTP 503 | Blocage générique ou surcharge |
Redirection vers /error ou corps contenant « page not available » | Blocage doux |
| vide avec seulement des | Page de challenge en attente de JS |
captcha / g-recaptcha / px-captcha dans le corps | Escalade — CAPTCHA requis |
react-root-props manquant sur une page de listing | Réponse de blocage épurée |
Couche 6 : l’astuce de parsing résiliente — privilégier le JSON caché aux sélecteurs CSS
Il faut le répéter : Yelp randomise les noms de classes CSS à la compilation. Un scraper basé sur h3.y-css-14xwok2 cassera en quelques semaines quand Yelp déploiera h3.y-css-hcq7b9.
Les payloads qui ne bougent pas :
<script type="application/ld+json">— données structurées schema.org (nom, adresse, téléphone, note, horaires)<script data-id="react-root-props">— données complètes des résultats de recherche en JSONhttps://www.yelp.com/gql/batch— endpoint GraphQL des avis avec undocumentIdstable
Si tu parses des classes CSS, tu bâtis sur du sable. Parse le JSON à la place.
Couche 7 : le plan B navigateur furtif
Passe à un navigateur headless uniquement lorsque curl_cffi + proxys résidentiels ne suffisent pas — en général quand Yelp sert une page de challenge JavaScript ou un CAPTCHA.
Pour 95 % du scraping d’entreprises, de recherches et d’avis, curl_cffi + JSON caché + proxys résidentiels est plus rapide, moins cher et plus fiable qu’un navigateur. Mais si tu as besoin d’un navigateur :
This paragraph contains content that cannot be parsed and has been skipped.
Évite Selenium classique pour Yelp. Il est trop facile à fingerprint.
API Yelp Fusion vs scraping Python vs Thunderbit : comparaison complète
| Dimension | API Yelp Fusion | Scraping Python | Thunderbit |
|---|---|---|---|
| Texte intégral des avis | ❌ 3 extraits × ~160 caractères | ✅ Illimité (GraphQL) | ✅ Modèle d’avis intégré |
| Métadonnées des avis (votes, réponses du propriétaire) | ❌ | ✅ | ✅ Via champs suggérés par IA |
| Photos | ❌ (0 sur l’offre de base) | ✅ Illimité | ✅ |
| Nombre max de résultats par recherche | 240 (contre 1 000 avant 2024) | Illimité (avec pagination) | Illimité |
| Limite journalière | 300–500 (nouveaux) / 5 000 (anciens) | Seulement le budget proxy | Basé sur des crédits (3 000/mois sur Pro) |
| Effort de mise en place | ~15 min | De quelques heures à plusieurs jours | ~2 minutes |
| Gestion anti-bot | N/A | Ton problème | Gérée (mode Cloud) |
| Risque légal | Faible (autorisé) | Moyen (zone grise des CGU) | Moyen (même risque que le scraping) |
| Coût d’entrée | 29 $/mois | ~0,75–4 $/Go de proxys + temps de dev | Offre gratuite |
| Coût en usage intensif | 643 $+/mois | 50–500 $/mois de proxys + temps de dev | 38–49 $/mois |
| Export des données | JSON | CSV/JSON (à coder vous-même) | Excel / Sheets / Airtable / Notion — gratuit |
| Maintenance | Faible | Élevée (sélecteurs cassés, anti-bot plus strict) | Faible (l’IA se réadapte) |
Conseils juridiques et éthiques pour scraper Yelp
Je ne suis pas avocat, et ceci ne constitue pas un conseil juridique. Mais le cadre légal a suffisamment bougé ces deux dernières années pour que ce soit utile d’en connaître les bases avant d’investir du temps dans un projet de scraping Yelp.
Ce que disent les CGU de Yelp : la interdit explicitement l’utilisation de « tout robot, spider... ou autre dispositif automatisé » pour « accéder, récupérer, copier, scraper ou indexer toute partie du Service ». Un passage sur les « AI Technologies and/or other automated tools » a aussi été ajouté.
: « Yelp n’autorise aucun scraping du site. »
Ce que dit robots.txt : le de Yelp contient un User-agent: * / Disallow: / global et bloque explicitement GPTBot, ClaudeBot, PerplexityBot, CCBot et Meta-ExternalAgent. Seuls Googlebot, Bingbot et quelques crawlers de réseaux sociaux sont autorisés.
Le précédent juridique à retenir : dans (N.D. Cal., janvier 2024), le tribunal a jugé que le scraping de données publiques accessibles sans connexion ne violait pas les CGU de Meta. La distinction clé : données publiques déconnectées vs données derrière connexion. L’affaire a établi que le scraping de données publiques ne viole probablement pas le CFAA, mais hiQ a quand même perdu sur des fondements de responsabilité civile d’État (atteinte aux biens mobiliers, détournement) et a été condamné à 500 000 $.
Recommandations pratiques :
- Ne scrape que des pages publiques accessibles sans connexion
- Limite le débit de tes requêtes (les pauses de ce guide servent aussi de limite éthique)
- Ne revends pas le texte brut des avis attribué à des utilisateurs nommés — respecte la vie privée des auteurs
- Respecte les lois locales sur la protection des données (CCPA, GDPR)
- Ne te connecte pas pour scraper — ça franchit la ligne de l’autorisation
- Traite les infos d’entreprise (nom/adresse/téléphone/note) comme des données factuelles publiques ; considère le texte des avis comme plus sensible
Consulte un professionnel du droit pour ta situation spécifique.
Conclusion
Trois chemins, un seul objectif.
L’API Yelp Fusion est l’option autorisée et la moins lourde à maintenir — mais elle se limite à 3 extraits d’avis et démarre à 29 $/mois. Le scraping Python te donne un contrôle total sur chaque donnée Yelp, mais demande un vrai investissement : curl_cffi pour l’impersonation TLS, des proxys résidentiels, des délais aléatoires, l’analyse du JSON caché et une maintenance continue à mesure que les défenses de Yelp évoluent. Thunderbit te fait passer de « j’ai besoin de données Yelp » à « voici mon tableur » en une trentaine de secondes, sans code ni configuration de proxy.
Les fondamentaux anti-blocage qui fonctionnent vraiment en 2025 : des en-têtes réalistes avec tous les Client Hints, curl_cffi pour imiter le fingerprint TLS, des délais aléatoires avec backoff exponentiel, la rotation de proxys résidentiels et — surtout — l’analyse du JSON caché (application/ld+json et react-root-props) plutôt que des sélecteurs CSS fragiles.
Tu hésites sur la bonne voie ? Essaie d’abord . Si elle couvre ton besoin, tu viens d’économiser des heures. Si tu as besoin de plus de contrôle — pipelines programmatiques complets, champs personnalisés, intégration CRM serrée — le guide Python ci-dessus te donne tout ce qu’il faut. Et pour aller plus loin sur l’écosystème des outils de scraping, consulte notre sélection des ou notre guide pour .
FAQ
Puis-je scraper Yelp gratuitement avec Python ?
Oui — en utilisant des bibliothèques gratuites comme curl_cffi, parsel et jmespath. Mais à partir d’un volume réel (plus de quelques dizaines de pages), il te faudra des proxys résidentiels payants, qui commencent autour de . Thunderbit propose aussi une offre gratuite avec 6 pages/mois pour une extraction rapide sans code.
Yelp bloque-t-il les scrapers ?
Oui, de manière agressive. Yelp utilise . requests brut est bloqué dès la première requête. La stratégie anti-blocage en couches décrite ici — curl_cffi pour l’impersonation TLS, des en-têtes réalistes, des délais aléatoires et des proxys résidentiels — est ce qui fonctionne en 2025.
L’API Yelp Fusion est-elle meilleure que le scraping ?
Ça dépend de ton besoin. L’API est autorisée et peu risquée, mais elle ne renvoie que , limite les résultats de recherche à 240 et commence à 29 $/mois. Si tu as besoin du texte complet des avis, des métadonnées d’avis ou de plus de quelques centaines d’enregistrements par jour, le scraping est la seule option.
Comment extraire les avis Yelp avec Python ?
Utilise curl_cffi avec impersonate="chrome131" pour récupérer la page d’entreprise, récupère l’identifiant encodé de l’entreprise dans <meta name="yelp-biz-id">, puis envoie un POST vers https://www.yelp.com/gql/batch avec l’opération GetBusinessReviewFeed et pagine via un curseur after encodé en base64. Le code détaillé étape par étape figure plus haut dans le tutoriel. Le est aussi une bonne référence d’implémentation.
Puis-je scraper Yelp sans coder ?
Oui — propose des modèles prêts à l’emploi pour les et les . Ouvre une page Yelp, clique sur AI Suggest Fields, puis sur Scrape. Les exports vers Google Sheets, Excel, Airtable et Notion sont gratuits sur tous les plans, y compris l’offre gratuite.
En savoir plus