Walmart modifie les prix de certains articles . Si vous avez déjà essayé de suivre ça automatiquement, vous connaissez le problème : votre script tourne 20 minutes, puis commence à renvoyer discrètement des pages CAPTCHA déguisées en réponses 200 OK normales.
J’ai passé beaucoup de temps à contourner les défenses anti-bot de Walmart dans le cadre de nos travaux d’extraction de données chez , et je veux partager tout ce que j’ai appris — les méthodes qui fonctionnent vraiment en 2025, les échecs silencieux qui faussent vos données, et les compromis honnêtes entre écrire votre propre scraper, payer une API de scraping ou simplement utiliser un outil no-code. Ce guide couvre trois méthodes d’extraction (parsing HTML, JSON __NEXT_DATA__ et interception d’API interne), la gestion des erreurs prête pour la production que la plupart des tutoriels ignorent complètement, ainsi qu’un cadre de décision franc pour choisir la bonne approche. Il y a ici de quoi faire, que vous écriviez en Python ou que vous vouliez simplement un tableau rempli de prix avant le déjeuner.
Pourquoi scraper Walmart avec Python ?
Walmart est le plus grand détaillant au monde en chiffre d’affaires — pour l’exercice 2025, avec la . Le site héberge environ , et le directeur financier de Walmart évoque sur la place de marché. Environ , ce qui rend le catalogue très volatil — les vendeurs changent, les variantes évoluent et le stock fluctue chaque jour.
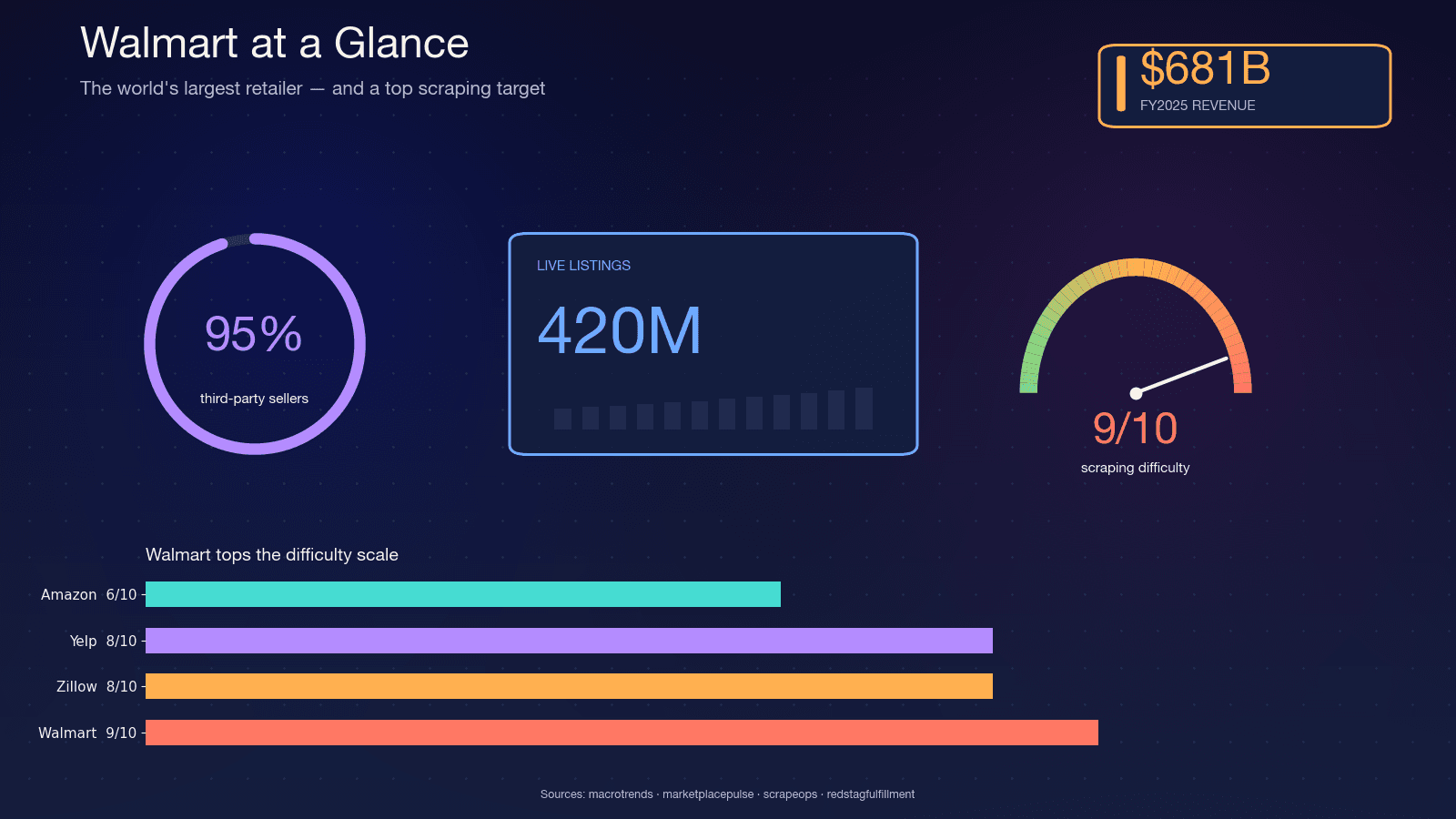
C’est précisément cette volatilité qui rend le scraping si important. Un rapport trimestriel ne peut pas capturer ce qu’un scraping quotidien peut révéler. Voici les cas d’usage les plus fréquents que je rencontre :
| Cas d’usage | Qui en a besoin | Ce qu’ils extraient |
|---|---|---|
| Veille des prix concurrents | Équipes e-commerce, outils de repricing | Prix, promotions, conformité MAP |
| Enrichissement du catalogue produits | Équipes commerciales et merchandising | Descriptions, images, spécifications, variantes |
| Suivi de la disponibilité des stocks | Chaîne d’approvisionnement, dropshippers | État du stock, informations vendeur |
| Études de marché et analyse des tendances | Marketing, chefs de produit | Notes, avis, assortiment par catégorie |
| Génération de leads | Équipes commerciales | Noms des vendeurs, nombre de produits, catégories |
Le et devrait atteindre 5,09 milliards de dollars d’ici 2033. Le comportement des consommateurs alimente ces dépenses : , et 83 % comparent les offres sur plusieurs sites.
Python est le langage de référence pour ce travail. Le rapport 2026 d’Apify sur l’infrastructure estime que , et la bibliothèque centrale (requests) enregistre . Si vous scrapez à n’importe quelle échelle, vous le faites presque certainement en Python.
Pourquoi Walmart est l’un des sites les plus difficiles à scraper
Walmart est particulièrement difficile à scraper parce qu’il exécute deux produits commerciaux anti-bot en série : comme couche WAF en périphérie et de fingerprinting TLS, puis comme couche de challenge JavaScript comportemental. Scrape.do qualifie cette combinaison de « rare et extrêmement difficile à contourner ».
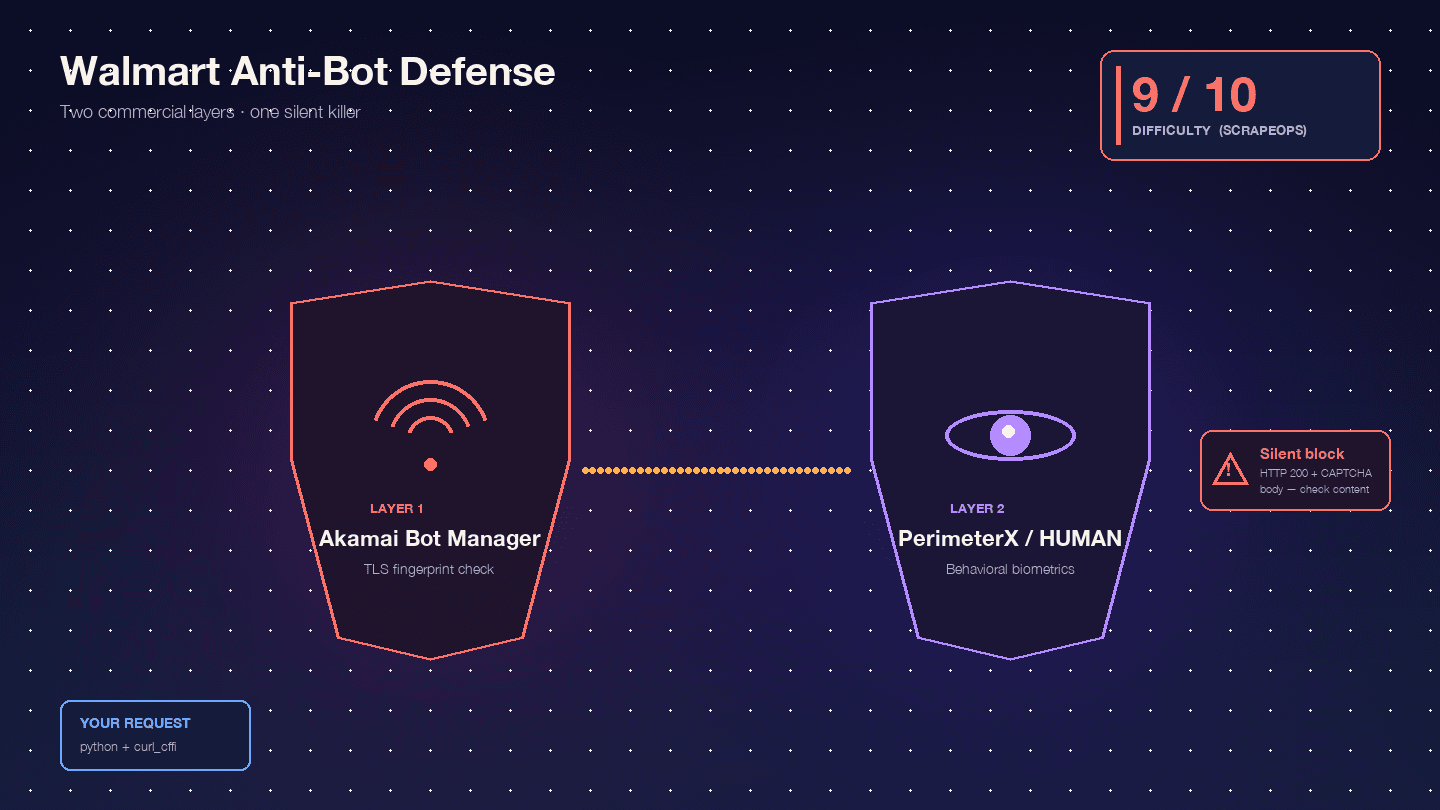
, Akamai seul étant déjà à 9/10. D’après mon expérience, c’est à peu près juste.
Voici ce à quoi vous êtes réellement confronté :
Akamai Bot Manager inspecte votre empreinte TLS (hash JA3/JA4), l’ordre des frames HTTP/2, l’ordre et la casse des en-têtes, ainsi que les cookies de session (_abck, ak_bmsc). Un simple appel Python requests émet une empreinte TLS qu’aucun vrai navigateur ne produit — Akamai vous bloque avant même que votre requête n’atteigne les serveurs de Walmart.
PerimeterX/HUMAN intervient après Akamai et exécute un fingerprinting JavaScript (px.js) qui vérifie les propriétés de navigator, le rendu canvas, WebGL, le contexte audio et des biométries comportementales (mouvements de souris, vitesse de défilement, dynamique des frappes). L’échec visible est le fameux challenge — un bouton que vous devez maintenir environ 10 secondes pendant que les signaux comportementaux sont échantillonnés. Oxylabs est direct : « Walmart utilise le modèle CAPTCHA “Press & Hold”, proposé par PerimeterX, qui est connu pour être presque impossible à résoudre depuis votre code. »
Le vrai danger, c’est le blocage silencieux. Walmart renvoie un HTTP 200 avec un corps CAPTCHA au lieu d’un 403. : « Walmart renvoie un code d’état 200 OK même lorsqu’il sert une page CAPTCHA. Vous ne pouvez pas vous fier uniquement au code d’état pour savoir si votre requête a réussi. » Votre script analyse tranquillement le HTML du CAPTCHA comme si le produit n’existait pas, puis passe à la suite. La moitié de votre jeu de données devient inutilisable, et vous ne le savez même pas.
Ensuite, il y a le problème des données dépendantes du magasin. Les prix et le stock Walmart sont liés à la localisation, via des cookies comme locDataV3 et assortmentStoreId. Sans les bons cookies, vous obtenez des données « nationales par défaut » qui peuvent sembler complètes mais ne correspondent pas à ce que voient de vrais clients. Les cookies manquants ne produisent pas une page de blocage — ils produisent de mauvaises données sans échec visible, ce qui est pire.
Trois méthodes pour extraire des données de Walmart (et comment elles se comparent)
Avant le pas-à-pas, voici les trois principales approches d’extraction. La plupart des tutoriels concurrents n’en couvrent qu’une ou deux. Je vais vous présenter les trois afin que vous puissiez choisir celle qui correspond à votre cas.
| Méthode | Fiabilité | Complétude des données | Difficulté anti-bot | Charge de maintenance |
|---|---|---|---|---|
| HTML + BeautifulSoup | ⚠️ Faible (les sélecteurs cassent à chaque déploiement) | Moyenne | Élevée | Élevée |
JSON __NEXT_DATA__ | ✅ Bonne | Élevée | Moyenne à élevée | Moyenne |
| Interception d’API interne | ✅ Meilleure | Très élevée (variantes, stock, avis) | Moyenne à élevée | Faible (JSON structuré) |
| Thunderbit (no-code) | ✅ Bonne | Élevée | Faible (gérée par l’IA) | Aucune |
Le parsing HTML est la pire option pour Walmart — le site utilise des bundles Next.js avec des noms de classes CSS hachés qui changent à chaque déploiement. La méthode JSON __NEXT_DATA__ est le choix pragmatique utilisé par tous les scrapers Walmart open source sérieux de 2024 à 2026. L’interception d’API interne est la plus puissante, mais elle s’accompagne de réserves que la plupart des tutoriels passent sous silence. Et Thunderbit est la bonne solution quand vous n’avez pas besoin d’un pipeline personnalisé.
Configurer votre environnement Python pour scraper Walmart
Voici ce qu’il vous faut :
- Difficulté : intermédiaire
- Temps requis : environ 30 minutes pour la configuration, plus le temps de codage
- Ce qu’il vous faut : Python 3.10+, pip, un éditeur de code et, pour un usage en production, un service de proxy ou une API de scraping
Créez votre dossier projet et votre environnement virtuel :
1mkdir walmart-scraper && cd walmart-scraper
2python -m venv venv
3source venv/bin/activate # Sous Windows : venv\Scripts\activateInstallez les bibliothèques nécessaires :
1pip install curl_cffi parsel beautifulsoup4 lxmlcurl_cffi est la référence en 2025 pour scraper des cibles difficiles. C’est une liaison libcurl capable d’imiter exactement les empreintes TLS des navigateurs. : « Walmart utilise le fingerprinting TLS dans sa détection des bots, et même définir le User-Agent pour simuler un vrai navigateur ne permet pas de le contourner. » requests ou httpx classiques ne peuvent pas passer Akamai, quels que soient les en-têtes que vous définissez. curl_cffi avec impersonate="chrome124" fait toute la différence.
Vous voudrez aussi json (intégré), csv (intégré), time, random et logging pour les modèles de production que nous verrons plus loin.
Pas à pas : scraper des pages produits Walmart avec Python
Étape 1 : récupérer la page produit Walmart
Votre première tâche consiste à envoyer une requête HTTP qui ne soit pas immédiatement bloquée. Voici l’ensemble d’en-têtes canonique utilisé par Scrapfly, Scrapingdog, Oxylabs et ScrapeOps entre 2024 et 2026 :
1from curl_cffi import requests
2HEADERS = {
3 "User-Agent": (
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
5 "AppleWebKit/537.36 (KHTML, like Gecko) "
6 "Chrome/124.0.0.0 Safari/537.36"
7 ),
8 "Accept": (
9 "text/html,application/xhtml+xml,application/xml;q=0.9,"
10 "image/avif,image/webp,*/*;q=0.8"
11 ),
12 "Accept-Language": "en-US,en;q=0.9",
13 "Accept-Encoding": "gzip, deflate, br",
14 "Upgrade-Insecure-Requests": "1",
15 "Sec-Fetch-Dest": "document",
16 "Sec-Fetch-Mode": "navigate",
17 "Sec-Fetch-Site": "none",
18 "Sec-Fetch-User": "?1",
19 "Referer": "https://www.google.com/",
20}
21session = requests.Session(impersonate="chrome124")
22url = "https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/1752657021"
23response = session.get(url, headers=HEADERS)Le paramètre impersonate="chrome124" fait ici le gros du travail. Il indique à curl_cffi de reproduire exactement le ClientHello TLS de Chrome 124, l’ordre des frames HTTP/2 et la séquence des pseudo-en-têtes. Sans cela, Akamai voit un hash JA3 spécifique à Python et vous bloque avant même que votre requête n’atteigne la couche applicative de Walmart.
À quoi ressemble une réponse bloquée : si vous voyez "Robot or human?" dans le titre HTML de la réponse, ou si la réponse redirige vers walmart.com/blocked, vous êtes tombé dans le piège. Le point délicat est que Walmart renvoie souvent un code 200 avec le corps CAPTCHA — donc vérifier uniquement response.ok ne suffit pas.
Pour tout usage en production ou répété, vous aurez besoin de proxies résidentiels. Les IP de datacenter sont immédiatement grillées par le système de réputation d’IP d’Akamai. Je couvre la stratégie complète de gestion des erreurs et des proxies dans la section production ci-dessous.
Étape 2 : analyser les données produit à partir du JSON __NEXT_DATA__
Walmart.com est une application Next.js, et le HTML rendu côté serveur embarque toute la charge utile de l’hydratation dans une seule balise script : <script id="__NEXT_DATA__" type="application/json">. C’est la mine d’or.
: « En 2026, Walmart utilise Next.js avec du JSON structuré dans les balises script __NEXT_DATA__, ce qui rend l’extraction de données cachées plus fiable que le parsing traditionnel par sélecteurs CSS. » Tous les scrapers open source Walmart les plus connus — , , — utilisent cette méthode.
Voici comment l’extraire :
1import json
2from parsel import Selector
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6product = data["props"]["pageProps"]["initialData"]["data"]["product"]
7idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})La plupart des tutoriels s’arrêtent là. Voici une carte complète des chemins JSON pour les champs qui vous intéressent vraiment — vérifiée sur des pages Walmart en direct entre 2024 et 2026 :
| Champ de données | Chemin JSON (sous initialData) | Type | Remarques |
|---|---|---|---|
| Nom du produit | data > product > name | Chaîne | — |
| Marque | data > product > brand | Chaîne | — |
| Prix actuel (numérique) | data > product > priceInfo > currentPrice > price | Flottant | Peut varier selon le cookie du magasin |
| Prix actuel (texte) | data > product > priceInfo > currentPrice > priceString | Chaîne | Formaté, par ex. "$9.99" |
| Courte description | data > product > shortDescription | Chaîne HTML | À analyser avec BeautifulSoup pour obtenir le texte |
| Longue description | data > idml > longDescription | Chaîne HTML | Se trouve dans idml, PAS dans product — c’est le piège que les anciens tutoriels se trompent à placer |
| Toutes les images | data > product > imageInfo > allImages | Tableau | Liste d’objets {id, url} |
| Note moyenne | data > product > averageRating | Flottant | La clé est averageRating, pas le vieux rating |
| Nombre d’avis | data > product > numberOfReviews | Entier | — |
| Variantes | data > product > variantCriteria | Tableau | Groupes d’options (taille, couleur) |
| Disponibilité | data > product > availabilityStatus | Chaîne | IN_STOCK, OUT_OF_STOCK, LIMITED_STOCK |
| Vendeur | data > product > sellerDisplayName | Chaîne | — |
| Fabricant | data > product > manufacturerName | Chaîne | — |
Le chemin longDescription est le piège qui fait trébucher beaucoup de monde. Un article de ScrapeHero de 2023 le plaçait dans product.longDescription, mais les sources de 2024+ le mettent systématiquement sur la clé voisine idml. Lisez toujours d’abord idml.longDescription, puis revenez à product.longDescription pour les anciennes pages.
Voici le modèle d’extraction sûr en utilisant des chaînes .get() :
1def extract_product(data):
2 product = data["props"]["pageProps"]["initialData"]["data"]["product"]
3 idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})
4 price_info = product.get("priceInfo", {})
5 current_price = price_info.get("currentPrice", {})
6 image_info = product.get("imageInfo", {})
7 return {
8 "name": product.get("name"),
9 "brand": product.get("brand"),
10 "price": current_price.get("price"),
11 "price_string": current_price.get("priceString"),
12 "short_desc": product.get("shortDescription"),
13 "long_desc": idml.get("longDescription", product.get("longDescription")),
14 "images": [img.get("url") for img in image_info.get("allImages", [])],
15 "rating": product.get("averageRating"),
16 "review_count": product.get("numberOfReviews"),
17 "variants": product.get("variantCriteria"),
18 "availability": product.get("availabilityStatus"),
19 "seller": product.get("sellerDisplayName"),
20 "manufacturer": product.get("manufacturerName"),
21 }Pour les utilisateurs qui ne veulent pas du tout gérer la navigation par chemins JSON, l’ identifie et structure automatiquement ces champs — sans cartographie manuelle. Vous cliquez sur « AI Suggest Fields », elle lit la page, et vous obtenez un tableau. Mais si vous construisez un pipeline personnalisé, la carte ci-dessus est votre référence.
Étape 3 : intercepter les points de terminaison API internes de Walmart pour des données plus riches
Aucun article concurrent ne couvre correctement cette méthode. C’est la voie d’extraction la plus puissante — et la plus complexe.
Le front-end de Walmart appelle un . Les points de terminaison se trouvent sous www.walmart.com/orchestra/* :
/orchestra/pdp/graphql/...— hydratation de la fiche produit + changement de variantes/orchestra/snb/graphql/...— pagination search-n-browse/orchestra/reviews/graphql/...— avis paginés
Ils renvoient un JSON propre et structuré avec des données que __NEXT_DATA__ tronque parfois — tarification par variante, comptage du stock en temps réel, pagination complète des avis.
Le piège que les articles de blog évitent de nommer : Walmart utilise des . Le corps de requête envoie seulement un hash SHA-256 (persistedQuery.sha256Hash), pas le texte de la requête. Si le serveur ne connaît pas ce hash, vous obtenez PersistedQueryNotFound. Walmart fait tourner ces hash à chaque déploiement. C’est pour cela qu’aucun scraper Walmart open source de premier plan ne publie de code /orchestra/ directement copiable-collable.
La version pratique et honnête de cette méthode est un exercice dans DevTools :
- Ouvrez une page produit Walmart dans Chrome
- Ouvrez DevTools → onglet Network, filtrez par « Fetch/XHR »
- Parcourez la page normalement — cliquez sur les variantes, faites défiler les avis, changez l’emplacement du magasin
- Repérez les requêtes vers des endpoints
/orchestra/*qui renvoient du JSON avec des données produit - Faites un clic droit sur la requête → « Copy as cURL »
- Convertissez la commande cURL en Python avec
curl_cffi
Voici à quoi ressemble un appel API rejoué :
1import json
2from curl_cffi import requests
3session = requests.Session(impersonate="chrome124")
4# D’abord, réchauffez la session en visitant la page produit
5session.get("https://www.walmart.com/ip/some-product/1234567", headers=HEADERS)
6# Puis rejouez l’appel API interne (copié depuis DevTools)
7api_url = "https://www.walmart.com/orchestra/pdp/graphql"
8api_headers = {
9 **HEADERS,
10 "accept": "application/json",
11 "content-type": "application/json",
12 "referer": "https://www.walmart.com/ip/some-product/1234567",
13 "wm_qos.correlation_id": "your-copied-correlation-id",
14}
15payload = {
16 # Collez ici le corps exact de la requête depuis DevTools
17 "variables": {"productId": "1234567"},
18 "extensions": {
19 "persistedQuery": {
20 "version": 1,
21 "sha256Hash": "the-hash-you-copied"
22 }
23 }
24}
25api_response = session.post(api_url, headers=api_headers, json=payload)
26api_data = api_response.json()L’étape de réchauffement de session est essentielle. Les cookies PerimeterX de Walmart (_px3, _pxhd, ACID) doivent être définis par la première récupération HTML avant que l’appel API puisse réussir. Sans eux, vous obtiendrez un 412 ou un 403.
Quand utiliser cette méthode : lorsque vous avez besoin de données que __NEXT_DATA__ n’inclut pas — tarification fine par variante, avis paginés au-delà du premier lot, ou stocks en temps réel. Pour la plupart des cas, __NEXT_DATA__ suffit et est bien plus simple.
Scraper les résultats de recherche Walmart et plusieurs pages
Les résultats de recherche suivent un schéma __NEXT_DATA__ similaire, mais avec un chemin JSON différent :
1search_url = "https://www.walmart.com/search?q=laptops&page=1"
2response = session.get(search_url, headers=HEADERS)
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6search_result = data["props"]["pageProps"]["initialData"]["searchResult"]
7items = search_result["itemStacks"][0]["items"]
8# Filtrer les produits sponsorisés
9organic_items = [i for i in items if i.get("__typename") == "Product"]
10for item in organic_items:
11 print(item.get("name"), item.get("priceInfo", {}).get("currentPrice", {}).get("price"))La pagination fonctionne en incrémentant le paramètre page : &page=1, &page=2, etc. Mais voici la limite non documentée : Walmart limite les résultats de recherche à 25 pages, quel que soit le nombre total réel. : « Walmart fixe à 25 le nombre maximal de pages de résultats accessibles, quel que soit le nombre total de pages disponibles. »
Solutions pour couvrir plus de résultats :
- Inverser l’ordre de tri : exécutez la même requête avec
&sort=price_low, puis avec&sort=price_highpour obtenir environ 50 pages de couverture - Découpage par plage de prix : ajoutez
&min_price=X&max_price=Ypour diviser le catalogue en fenêtres plus petites - Découpage par catégorie : recherchez dans des catégories spécifiques plutôt que sur l’ensemble du site
Notez que itemStacks est un tableau. Scrapfly code en dur [0] dans son dépôt, mais les pages catégorie et navigation contiennent parfois plusieurs piles (« Top picks », « More results »). Le modèle robuste consiste à parcourir toutes les piles :
1for stack in search_result.get("itemStacks", []):
2 for item in stack.get("items", []):
3 if item.get("__typename") == "Product":
4 # traiter l’élément
5 passAutre point à noter : le robots.txt de Walmart . Les pages produit (/ip/...) et la plupart des pages catégorie (/cp/...) ne sont pas interdites. Si la conformité vous préoccupe, commencez par les pages produit et les arbres de catégories plutôt que par la recherche.
Ne laissez pas des blocages silencieux ruiner vos données : gestion des erreurs prête pour la production
La plupart des tutoriels s’effondrent ici. Ils vous montrent comment récupérer une page, analyser un produit, puis s’arrêtent là. En production, vous récupérez des milliers de pages, et Walmart essaie activement de vous arrêter. La différence entre un scraper de démonstration et un scraper vraiment utilisable, c’est la manière dont il gère les échecs.
Détecter les blocages silencieux avant qu’ils ne corrompent vos données
La fonction la plus importante dans un scraper Walmart est le détecteur de blocage. D’après le consensus des fournisseurs — , , et — vous avez besoin de quatre contrôles indépendants :
1BLOCK_MARKERS = (
2 "Robot or human",
3 "Press & Hold",
4 "Press & Hold",
5 "px-captcha",
6 "perimeterx",
7)
8def is_walmart_blocked(response) -> bool:
9 # 1. Redirection vers l’endpoint de blocage dédié
10 if "/blocked" in str(response.url):
11 return True
12 # 2. Codes d’état bloquants
13 if response.status_code in (403, 412, 428, 429, 503):
14 return True
15 # 3. 200 OK avec corps CAPTCHA (le cas de blocage silencieux)
16 body = response.text or ""
17 if any(m.lower() in body.lower() for m in BLOCK_MARKERS):
18 return True
19 # 4. Vérification de la taille de la réponse — les vraies PDP font 300 à 900 Ko
20 if len(response.content) < 50_000 and "/ip/" in str(response.url):
21 return True
22 return FalseCe quatrième contrôle — la taille de la réponse — permet de détecter les cas où Walmart renvoie une page allégée qui ne contient aucun marqueur CAPTCHA évident, mais pas non plus les données produit dont vous avez besoin.
Logique de retry avec backoff exponentiel et jitter
Lorsqu’une requête échoue, vous ne voulez pas marteler Walmart immédiatement. Le schéma standard utilise un backoff exponentiel avec jitter pour désynchroniser les retries :
1import time
2import random
3import logging
4from curl_cffi import requests as cffi_requests
5log = logging.getLogger("walmart")
6def fetch_with_retry(session, url, max_retries=5, base_delay=2, max_delay=60):
7 for attempt in range(max_retries):
8 try:
9 response = session.get(url, headers=HEADERS, timeout=15)
10 if response.status_code in (429, 503):
11 raise Exception(f"Throttled: \{response.status_code\}")
12 if is_walmart_blocked(response):
13 raise Exception("Silent block detected")
14 return response
15 except Exception as e:
16 if attempt == max_retries - 1:
17 raise
18 wait = min(max_delay, base_delay * (2 ** attempt)) + random.uniform(0, 3)
19 log.warning(f"Tentative {attempt + 1} échouée : \{e\}. Nouvelle tentative dans {wait:.1f} s")
20 time.sleep(wait)
21 return NoneLe jitter (random.uniform(0, 3)) n’est pas décoratif — il désynchronise les workers pour qu’une flotte de scrapers ne retente pas tous au même moment et ne déclenche pas les détecteurs de vélocité d’Akamai.
Limitation du débit
que convergent vers un délai aléatoire de 3 à 6 secondes par requête pour Walmart : « limitez vos requêtes en attendant 3 à 6 secondes entre les chargements de page et randomisez vos délais. »
1import time
2import random
3def rate_limited_fetch(session, url):
4 response = fetch_with_retry(session, url)
5 time.sleep(random.uniform(3.0, 6.0))
6 return responseÀ grande échelle, envisagez aiolimiter pour la limitation de débit asynchrone :
1from aiolimiter import AsyncLimiter
2limiter = AsyncLimiter(max_rate=10, time_period=60) # 10 requêtes par minuteValidation des données
Même lorsque la réponse n’est pas bloquée, les données analysées peuvent être erronées (mauvais magasin, charge utile dégradée). Validez avant d’écrire la sortie :
1def validate_product(product):
2 """Renvoie True si les données produit semblent légitimes."""
3 if not product.get("name"):
4 return False
5 price = (product.get("priceInfo") or {}).get("currentPrice", {}).get("price")
6 if not isinstance(price, (int, float)) or price <= 0:
7 return False
8 if product.get("availabilityStatus") not in ("IN_STOCK", "OUT_OF_STOCK", "LIMITED_STOCK"):
9 return False
10 return TrueJournalisation des sessions
Suivez votre taux de réussite par session. Lorsqu’il passe sous 80 % pendant 10 minutes, quelque chose a changé — soit votre IP est grillée, soit vos cookies ont expiré, soit Walmart a déployé une nouvelle règle anti-bot.
1class ScrapeMetrics:
2 def __init__(self):
3 self.total = 0
4 self.success = 0
5 self.blocks = 0
6 self.errors = 0
7 def record(self, result):
8 self.total += 1
9 if result == "success":
10 self.success += 1
11 elif result == "blocked":
12 self.blocks += 1
13 else:
14 self.errors += 1
15 @property
16 def success_rate(self):
17 return (self.success / self.total * 100) if self.total > 0 else 0
18 def check_health(self):
19 if self.total > 20 and self.success_rate < 80:
20 log.critical(f"Le taux de réussite est tombé à {self.success_rate:.1f} % — envisagez de faire tourner les proxies ou de mettre en pause")Ce n’est pas glamour. Mais c’est ce qui garde vos données propres.
Python en mode DIY vs API de scraping vs no-code : choisir la bonne approche pour scraper Walmart
Beaucoup de développeurs se lancent directement dans l’écriture d’un scraper personnalisé sans se demander si c’est vraiment la bonne solution. . Sur les forums, les utilisateurs le décrivent comme « pratiquement 9/10 » et se demandent si « une API dédiée de web scraping ne serait pas excessif ». La réponse dépend du volume, du budget et de la capacité d’ingénierie.
| Facteur | Python DIY (requests + proxies) | API de scraping (Oxylabs, Bright Data, etc.) | Outil no-code (Thunderbit) |
|---|---|---|---|
| Temps de mise en place pour la première ligne | Heures | 15 à 60 min | ~2 min |
| Temps de mise en place en production | 40 à 80 h | 4 à 16 h | ~30 min |
| Gestion anti-bot | À votre charge (difficile) | Gérée par le fournisseur | Gérée automatiquement |
| Coût à petite échelle (<1K pages/mois) | Faible (proxies ~4 à 8 $/Go) | Paliers d’entrée à 40–49 $/mois | Gratuit–15 $/mois |
| Coût à l’échelle (100K+ pages/mois) | Coût par requête plus faible | Coût par requête plus élevé | Variable |
| Personnalisation | Contrôle total | Paramètres d’API | Limité par l’interface et les champs |
| Maintenance continue | 4 à 8 h/mois | Quasiment nulle | Aucune (l’IA s’adapte) |
| Idéal pour | Développeurs construisant des pipelines sur mesure | Scraping de production à échelle moyenne | Utilisateurs métier, extractions ponctuelles rapides |
Quand le Python DIY a du sens
Le DIY l’emporte si vous avez déjà un contrat de proxy, si vous avez besoin d’un contrôle strict sur les en-têtes, le ciblage par code postal ou les cohortes de vendeurs, si vous indexez des millions de pages par mois où les frais API par enregistrement s’additionnent, ou si vous avez besoin de garanties on-prem ou de conformité. Le compromis, c’est du vrai temps d’ingénierie : un spider Scrapy prêt pour la production avec pagination, retries, rotation de proxies, imitation TLS et plusieurs schémas de types de pages prend , plus 4 à 8 heures de maintenance par mois à mesure que Walmart change ses empreintes.
Quand une API de scraping vous fait gagner du temps
Les API de scraping gèrent la couche anti-bot à votre place. Les montrent des taux de réussite de et 98 % pour Scrape.do sur Walmart. Les tarifs d’entrée se situent entre 40 et 49 $/mois pour des outils comme , et . Si vous êtes une équipe de 2 à 5 ingénieurs et que votre volume de scraping se situe entre 10K et 1M de pages par mois, une API est presque toujours la bonne option. Vous échangez un coût par requête contre zéro maintenance.
Quand le no-code est la bonne solution
correspond à un profil différent. Si vous êtes PM, analyste ou responsable e-commerce et que vous avez besoin de données produit Walmart dans un tableur cet après-midi — pas au prochain sprint — un outil no-code est la réponse honnête.
Le workflow : installez , ouvrez une page produit ou de recherche Walmart, cliquez sur « AI Suggest Fields », et l’IA de Thunderbit lit la page et propose des colonnes (nom du produit, prix, note, etc.). Cliquez sur « Scrape », et les données remplissent un tableau. Exportez vers Excel, Google Sheets, Airtable ou Notion — gratuitement, sans paywall.
Thunderbit gère l’anti-bot dans le cloud, donc vous n’avez pas à gérer les CAPTCHA, les proxies ou le fingerprinting TLS. L’IA s’adapte automatiquement aux changements de mise en page, donc il n’y a aucune maintenance. Pour les utilisateurs qui ne veulent pas du tout gérer la navigation par chemins JSON, c’est la voie la plus simple.
Limites honnêtes : Thunderbit n’est pas conçu pour 100K+ pages par jour. Les budgets de crédits et les plafonds cloud rendent l’ingestion à haut volume peu économique par rapport aux API brutes. Vous ne pouvez pas non plus imposer un code postal ou un ASN spécifique, sauf si l’outil le permet. Pour des pipelines continus à haut volume, le DIY ou une API de scraping reste la meilleure solution.
Prix approximatif : 1 000 lignes de produits Walmart sur Thunderbit coûtent environ 2 000 crédits (environ 0,60 à 1,10 $ selon les formules Starter/Pro). C’est comparable à l’API Walmart d’Oxylabs et moins cher que la plupart des API de scraping grand public à faible volume. pour les détails à jour.
Exporter vos données Walmart extraites
Une fois les données obtenues, il faut les mettre quelque part d’utile. Trois formats couvrent la plupart des besoins :
CSV — le format passe-partout que les analystes ouvrent réellement :
1import csv
2def export_csv(products, filename="walmart_products.csv"):
3 fieldnames = ["name", "price", "availability", "rating", "review_count", "seller", "url"]
4 with open(filename, "w", newline="", encoding="utf-8-sig") as f:
5 writer = csv.DictWriter(f, fieldnames=fieldnames, quoting=csv.QUOTE_MINIMAL)
6 writer.writeheader()
7 for p in products:
8 writer.writerow({k: p.get(k) for k in fieldnames})Utilisez l’encodage utf-8-sig pour la compatibilité avec Excel. Le marqueur BOM empêche Excel de mal interpréter les caractères spéciaux.
JSONL — le format de production pour les pipelines de scraping :
1import json
2import gzip
3def export_jsonl(products, filename="walmart_products.jsonl.gz"):
4 with gzip.open(filename, "at", encoding="utf-8") as f:
5 for p in products:
6 f.write(json.dumps(p, ensure_ascii=False) + "\n")(une écriture interrompue ne fait perdre que la dernière ligne), peut être diffusé en flux avec une mémoire constante, et conserve intactes les données imbriquées comme les variantes et les avis.
Excel — pour les remises ponctuelles à destination d’analystes :
1from openpyxl import Workbook
2def export_excel(products, filename="walmart_products.xlsx"):
3 wb = Workbook(write_only=True)
4 ws = wb.create_sheet("Products")
5 ws.append(["Nom", "Prix", "Disponibilité", "Note", "Avis", "Vendeur"])
6 for p in products:
7 ws.append([p.get("name"), p.get("price"), p.get("availability"),
8 p.get("rating"), p.get("review_count"), p.get("seller")])
9 wb.save(filename)Thunderbit couvre aussi l’export pour les utilisateurs non Python : export en un clic vers Google Sheets, Airtable, Notion, Excel, CSV et JSON — gratuitement sur l’offre de base. Pour le suivi récurrent, la fonction de scraper planifié de Thunderbit peut lancer automatiquement des extractions répétées.
Une réserve sur la planification : . Les runners GitHub Actions se trouvent dans des plages d’IP Azure que les défenses anti-bot de Walmart bloquent immédiatement. Utilisez APScheduler sur un VPS, ou faites passer tout le trafic par des proxies résidentiels.
Directives légales et éthiques pour scraper Walmart
Les utilisateurs de forums expriment clairement cette inquiétude : « Ça ne me dérange pas de jouer au chat et à la souris avec les développeurs, mais je me méfie de leur équipe juridique. »
Les conditions d’utilisation de Walmart l’utilisation de « tout robot, spider… ou autre dispositif manuel ou automatique pour récupérer, indexer, “scraper”, “data miner” ou collecter de toute autre manière des matériaux » sans « consentement écrit préalable exprès ».
Le robots.txt de Walmart /search, /account, /api/ et des dizaines de points de terminaison internes. Les pages produit (/ip/...) et les avis (/reviews/product/) ne sont pas interdites.
Le précédent hiQ c. LinkedIn (9e circuit, ) a établi que le scraping de données accessibles publiquement a peu de chances de violer le CFAA fédéral. Mais cette même affaire s’est ensuite soldée par une et un contre lui. Des décisions plus récentes en 2024 (, ) ont encore restreint le CFAA et créé des défenses fondées sur la préemption du droit d’auteur, mais ces décisions reposaient sur un langage ToU spécifique qui ne se transpose pas proprement à Walmart.
Directives pratiques : ne surchargez pas les serveurs. Respectez les limites de débit. Ne scrapez pas de données personnelles ou d’utilisateurs. Utilisez les données de manière responsable. Scraper des pages produit publiques Walmart à un rythme modeste pour une recherche personnelle n’a pas le même niveau de risque que du scraping à l’échelle commerciale en violation des conditions de Walmart. Si vous construisez un produit basé sur les données Walmart, parlez-en à un avocat et regardez les .
Avertissement : ces informations sont éducatives et ne constituent pas un conseil juridique.
Conclusion et points clés à retenir
Scraper Walmart avec Python est un défi de à cause de sa double pile anti-bot Akamai + PerimeterX. Pas impossible — mais il faut les bons outils et les bons réflexes.
Points clés :
- L’extraction JSON
__NEXT_DATA__est le choix pragmatique pour la plupart des cas. C’est ce que tous les scrapers open source Walmart sérieux de 2024 à 2026 utilisent. Le chemin de base estprops.pageProps.initialData.data.productpour les PDP etsearchResult.itemStackspour la recherche/navigation. curl_cffiavecimpersonate="chrome124"est obligatoire.requestsouhttpxclassiques ne peuvent pas franchir le fingerprinting TLS d’Akamai, quels que soient les en-têtes.- Les blocages silencieux sont le vrai danger. Walmart renvoie un 200 OK avec des corps CAPTCHA. Vérifiez le contenu de la réponse, pas seulement les codes d’état.
- Les scrapers de production ont besoin de plus que du code pour le chemin heureux. Backoff exponentiel avec jitter, détection de blocage sur quatre signaux, limitation du débit à 3–6 secondes par requête, validation des données et surveillance de l’état des sessions sont indispensables.
- L’interception des API internes via
/orchestra/*est puissante mais fragile. Utilisez-la comme exercice DevTools pour des besoins précis, pas comme méthode principale d’extraction. - Walmart plafonne les résultats de recherche à 25 pages. Élargissez avec l’inversion de l’ordre de tri et le découpage par plage de prix.
- Choisissez honnêtement votre approche : Python DIY pour les développeurs ayant des besoins sur mesure et beaucoup de volume. APIs de scraping pour les équipes de taille moyenne sans ingénieur scraping. pour les utilisateurs métier qui veulent des données dans Google Sheets cet après-midi.
Si vous voulez essayer la voie no-code, propose une offre gratuite — vous pouvez scraper quelques pages Walmart et voir les résultats par vous-même. Si vous partez sur Python, les modèles de code de cet article ont été testés en production. Dans tous les cas, vous avez maintenant une carte des défenses de Walmart et trois voies pour les contourner.
Pour aller plus loin sur les techniques de web scraping, consultez nos guides sur , et . Vous pouvez aussi regarder des tutoriels sur la .
FAQ
Est-il légal de scraper des données produit Walmart ?
Les conditions d’utilisation de Walmart interdisent le scraping automatisé sans consentement écrit. L’arrêt hiQ c. LinkedIn de la 9e Cour d’appel (2022) a établi que le CFAA fédéral a peu de chances de s’appliquer au scraping de pages publiques, mais la même affaire s’est conclue par un contre le scraper. Scraper des pages produit publiques à un rythme modeste pour une recherche personnelle n’a pas le même profil de risque qu’une extraction à l’échelle commerciale. Consultez un avocat si vous construisez une activité sur les données Walmart.
Pourquoi mon scraper Walmart est-il constamment bloqué ?
Les causes les plus courantes sont : l’utilisation de requests ou httpx classiques (qui émettent une empreinte TLS spécifique à Python que l’Akamai repère immédiatement), des en-têtes manquants ou incorrects, aucune rotation de proxy, un rythme de requêtes inférieur à 3–6 secondes par page, et l’absence de cookies de session (_px3, _abck, locDataV3). Passez à curl_cffi avec impersonate="chrome124", utilisez des proxies résidentiels et mettez en place les schémas de détection de blocage et de retry décrits dans cet article.
Quelles données puis-je scraper sur Walmart avec Python ?
Noms des produits, prix (actuels et remises), images, descriptions courtes et longues, notes, nombre d’avis, disponibilité du stock, noms des vendeurs, informations fabricant, variantes (taille, couleur) et position dans la catégorie. Avec la méthode __NEXT_DATA__, toutes ces données sont disponibles en JSON structuré. L’interception d’API interne peut en plus renvoyer la tarification par variante, les stocks en temps réel et les avis paginés.
Ai-je besoin de proxies pour scraper Walmart ?
Oui, pour tout usage en production ou répété. — même avec des en-têtes parfaits, une IP non résidentielle sera repérée par le système de réputation d’IP d’Akamai. Des proxies résidentiels ou mobiles sont nécessaires. Les IP de datacenter sont grillées presque immédiatement. Comptez environ 3 à 17 $ pour 1 000 pages selon votre fournisseur et votre forfait proxy.
Puis-je scraper Walmart sans écrire de code ?
Oui. est une extension Chrome alimentée par l’IA qui scrape Walmart en deux clics : « AI Suggest Fields » pour détecter automatiquement les colonnes de données produit, puis « Scrape » pour extraire les données. Elle gère les défis anti-bot dans le cloud et exporte directement vers Excel, Google Sheets, Airtable ou Notion — gratuitement. Elle convient particulièrement aux analystes, PM et utilisateurs métier qui ont besoin de données rapidement sans construire de pipeline personnalisé. Pour du scraping à gros volume ou très personnalisé, Python ou une API de scraping reste plus adapté.
En savoir plus