Redfin met à jour après leur publication. Une telle fraîcheur est une vraie aubaine pour toute personne qui monte un pipeline de données immobilières — et c’est exactement pour ça que tant de scrapers ciblent Redfin… avant de se faire bloquer en quelques minutes.
Je travaille depuis des années sur des outils d’extraction de données chez , et je peux vous le dire franchement : l’écart entre « extraire Redfin » et « extraire Redfin sans se faire bloquer » est là où la plupart des tutos s’effondrent. Ils vous montrent le code BeautifulSoup, passent sous silence le moment où Cloudflare avale vos requêtes, puis vous laissent devant une page 403 en vous demandant ce qui a bien pu se passer. Ce guide, lui, est différent. Je vais vous présenter trois approches concrètes — l’analyse HTML, l’API cachée de Redfin et une solution sans code avec Thunderbit — tout en détaillant sérieusement les défenses anti-bot qui comptent vraiment. À la fin, vous saurez exactement quelle méthode colle à votre niveau, à votre volume et à votre tolérance pour la maintenance.
Qu’est-ce que Redfin et pourquoi ses données sont-elles si importantes ?
Redfin est une agence immobilière pilotée par la technologie, avec des agents salariés qui récupèrent directement les annonces depuis les flux MLS. La plateforme couvre et attire près de 50 millions de visiteurs par mois. Contrairement aux portails qui se contentent d’agréger du contenu, les données de Redfin sont vérifiées par des agents, et son AVM propriétaire, Redfin Estimate, couvre avec une erreur médiane de seulement 1,96 % pour les biens en vente.
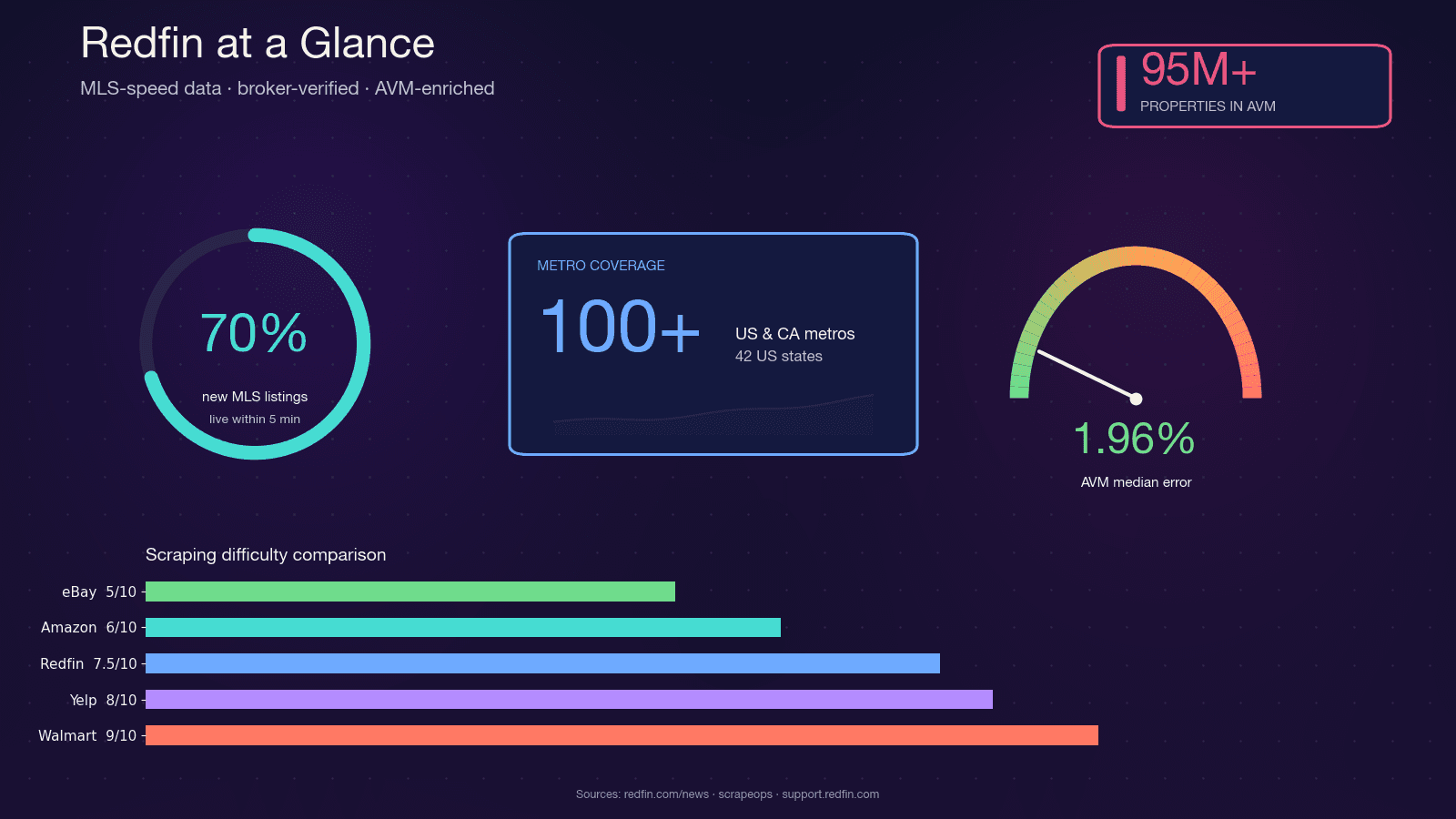
Cette combinaison — fraîcheur au rythme du MLS, qualité validée par le courtage et AVM précis — explique pourquoi investisseurs immobiliers, agents, startups proptech et analystes veulent tous un accès programmatique aux données Redfin. Python s’impose naturellement : son écosystème de scraping (requests, BeautifulSoup, Selenium, Playwright) est mature, la communauté est immense, et l’intégration avec pandas et Jupyter est directe pour l’analyse.
Pourquoi extraire Redfin avec Python ?
Les cas d’usage sont aussi variés que les personnes qui ont besoin de ces données. Voici comment différents profils exploitent généralement les données Redfin extraites :
| Audience | Objectif principal | Exemple d’utilisation |
|---|---|---|
| Agents immobiliers | Génération de leads, veille de marché | Nouvelles annonces et annonces expirées dans une zone de service ; annuaire d’agents pour comparer la concurrence |
| Investisseurs immobiliers | Deal flow, analyse du cap rate | Repérage du rendement locatif, détection de biens sous-évalués, alertes quotidiennes sur les nouvelles annonces |
| Startups proptech | Pipelines de données produit | Données d’entraînement pour AVM, tableaux de bord de marché, moteurs d’acquisition iBuyer |
| Analystes de données | Études de marché, BI | Tendances de prix médians par ZIP code, séries temporelles des jours sur le marché, ratio prix de vente / prix affiché |
| Grossistes / rénovateurs-revendeurs | Suivi des biens en difficulté | Détection des baisses de prix, saisies, comparables hors marché |
La tendance générale confirme cela : utilisent désormais l’analytique prédictive pour repérer les opportunités et gérer les risques. Le marché de la PropTech devrait atteindre , avec un CAGR de 16,4 %. Les données immobilières structurées ne sont plus un bonus : elles sont devenues indispensables.
Tous les champs de données Redfin que vous pouvez extraire (référence complète)
Avant d’écrire la moindre ligne de code, il faut savoir ce qui est réellement disponible. J’ai audité les pages de résultats de recherche, les fiches détaillées et les profils d’agents de Redfin — puis j’ai recoupé ces informations avec des wrappers open source de l’API Stingray comme et . Le total atteint 117 champs distincts selon les types de page.
Ce tableau vaut le coup d’être mis en favoris. Connaître votre schéma de données avant de coder vous évite des heures de chasse aux sélecteurs.
Champs de la page de résultats de recherche
Ce sont les champs légers disponibles sur les cartes d’annonces — souvent extractibles sans rendu JavaScript complet :
| Champ | Type de données | Remarques |
|---|---|---|
| ID du bien | Number | Identifiant interne Redfin, extrait de /home/{id} dans l’URL |
| Prix affiché | Number | |
| Adresse complète | Text | |
| Chambres / Salles de bain / Surface | Number | Trois valeurs successives |
| Type de bien | Single Select | SFH, Condo, Townhouse, Multi |
| Statut | Text | Active, Pending, Contingent |
| Jours sur le marché | Number | |
| Indicateur de baisse de prix | Number | Écart par rapport au prix initial |
| Photo principale | Image URL | Une photo par carte |
| Badge Hot Home | Boolean | |
| Date/heure de l’open house | Text | |
| Attribution du courtage | Text |
Champs de la page détaillée du bien
La page détail est là où se trouve la vraie richesse. Beaucoup de ces champs nécessitent du rendu JavaScript ou l’API Stingray :
| Champ | Type de données | Remarques |
|---|---|---|
| Redfin Estimate (en vente) | Number | Via /stingray/api/home/details/avm |
| Redfin Estimate (hors marché) | Number | Via /stingray/api/home/details/owner-estimate ; erreur médiane de 7,52 % |
| Année de construction / rénovation | Number | |
| Taille du terrain | Number | |
| Charges HOA | Number | Mensuelles, si applicable |
| Taxe foncière (annuelle) | Number | |
| Valeur fiscale estimée | Number | |
| Tableau de l’historique des ventes | Table | Prix, date, type d’événement |
| Description du bien | Text | Paragraphe marketing |
| URL des photos (carrousel) | Image URLs | 20+ par annonce |
| Nom, téléphone, e-mail de l’agent | Text / Phone / Email | Le téléphone est souvent masqué |
| Notes d’écoles (élémentaire/collège/lycée) | Number | Avec le nom du district |
| Score marche / transport / vélo | Number | |
| Scores de risque climatique | Number | Inondation, feu, chaleur, vent |
| Biens similaires actifs / vendus / proches | URLs | Données du carrousel |
| Parking, garage, chauffage, climatisation | Text | Groupes d’équipements |
Champs du profil d’agent
| Champ | Type de données | Remarques |
|---|---|---|
| Nom de l’agent, photo, agence, bio | Text / Image | |
| Téléphone, formulaire de contact | Phone / Text | Révélation au clic |
| Nombre d’annonces actives | Number | |
| Ventes sur les 12 derniers mois / volume total | Number | |
| Ratio moyen prix affiché / prix de vente | Number | |
| Note étoilée / nombre d’avis | Number | |
| Années d’expérience / numéro de licence | Text / Number |
Lorsque vous utilisez la fonction AI Suggest Fields de Thunderbit sur une page Redfin, l’outil détecte automatiquement la plupart de ces colonnes et attribue les bons types de données — sans mappage manuel de sélecteurs CSS. J’y reviens plus loin.
Décryptage des défenses anti-bot de Redfin (pas juste « utilisez un proxy »)
C’est un point que je veux marteler, parce que la plupart des tutoriels esquivent le sujet du blocage pour enchaîner avec « achetez des proxies chez notre sponsor ». Ce n’est pas utile. Si vous ne comprenez pas ce que Redfin fait pour détecter les scrapers, vous allez brûler vos crédits proxy tout en restant bloqué. , et — « moins agressif que le WAF d’entreprise de Zillow, avec limitation de débit personnalisée et challenges JavaScript. »
Redfin s’appuie sur une pile à plusieurs couches : Cloudflare en bordure (challenge JavaScript, Turnstile, empreinte TLS/JA3) plus un limiteur de débit spécifique à l’application Redfin. Il n’y a pas de directive Crawl-delay dans robots.txt, parce que l’application des règles se fait au niveau du WAF.
Pourquoi requests + BeautifulSoup échouent sur Redfin
Si vous lancez un simple requests.get() sur une page de bien immobilier Redfin avec les en-têtes par défaut, voilà ce qui se passe en général :
- HTTP 403 — le challenge JavaScript de Cloudflare n’a pas été résolu, donc vous récupérez la page de challenge au lieu de l’annonce.
- Page intermédiaire de challenge — le corps HTML contient le widget Turnstile de Cloudflare, pas les données du bien.
- HTTP 200 avec HTML partiel — vous obtenez une coquille avec un gros blob JSON embarqué sous
root.__reactServerState.InitialContext, mais sans cartes de recherche pré-rendues, sans historique des prix, sans notes d’écoles.
Redfin utilise son propre (pas Next.js), et la clé d’hydratation est spécifique à Redfin — root.__reactServerState.InitialContext, avec les données d’annonce imbriquées dans ReactServerAgent.cache.dataCache. Ce n’est ni __NEXT_DATA__ ni window.__INITIAL_STATE__.
La cause la plus fréquente des 403 silencieux ? L’absence des en-têtes Sec-Fetch-*. Redfin/Cloudflare vérifie explicitement Sec-Fetch-Site, Sec-Fetch-Mode, Sec-Fetch-Dest et Sec-Fetch-User. S’ils manquent, vous êtes immédiatement repéré.
Le plan d’atténuation : délais, en-têtes, proxies et sessions
Voici le détail complet, défense par défense, avec les solutions adaptées :
| Défense Redfin | Fonctionnement | Signal de détection | Stratégie d’atténuation |
|---|---|---|---|
| Challenge JavaScript Cloudflare | Interstitiel qui émet le cookie cf_clearance | 403 + corps HTML Cloudflare | curl_cffi avec impersonate="chrome120" ; initialiser la session via la page d’accueil ; proxy résidentiel US |
| Cloudflare Turnstile | CAPTCHA interactif sur les sessions à risque | 403 + widget Turnstile | Navigateur headless avec stealth + proxy résidentiel |
| Erreur 1020 Cloudflare (ban ASN) | Bloque les IP/ASN signalés au niveau WAF | Corps 403 « Error 1020 Access Denied » | Basculer vers un proxy résidentiel/mobile ; jamais de datacenter ASN |
| Empreinte TLS/JA3 | Détecte les piles TLS non navigateur | 403 silencieux même avec des en-têtes parfaits | Impersonation curl_cffi ou vrai navigateur |
| Empreinte HTTP/2 | Vérifie les paramètres HTTP/2, l’ordre HPACK | Blocage silencieux | curl_cffi parle HTTP/2 comme Chrome |
| Validation des en-têtes (UA, Sec-Fetch-*) | Jeu d’en-têtes cohérent avec un navigateur | 403 dès la première requête | Ensemble complet d’en-têtes Chrome, y compris Sec-Fetch-Site/Mode/Dest/User, et Referer réaliste |
| Continuité cookie/session | Suit cf_clearance, RF_BROWSER_ID | Challenges sur les accès directs à une URL profonde | Session persistante ; passer d’abord par la page d’accueil |
| Limite de débit applicative | Limiteur de requêtes par IP | 429 | Délai de 2 à 5 s avec jitter ; backoff exponentiel |
| Réputation des IP datacenter | Bloque les ASN connus des datacenters | 1020/403 immédiat | Uniquement des proxies résidentiels ou mobiles US |
| Détection de concurrence | Plusieurs requêtes parallèles depuis une IP | Escalade soudaine vers Turnstile | ≤ 2 requêtes concurrentes par IP |
Seuils pratiques issus des tests communautaires :
- Cadence sûre : 1 requête toutes les 2 à 3 secondes par IP
- Au-delà de 20 à 30 requêtes/minute depuis une IP datacenter, un challenge apparaît généralement en quelques minutes
- Les limites de débit souples se relâchent en 5 à 15 minutes si l’activité cesse
- Les bans d’IP datacenter (AWS, GCP, Azure, OVH) peuvent durer de quelques heures à plusieurs jours
Le requests Python standard (urllib3 + OpenSSL) produit une — et se fait bloquer silencieusement même avec des en-têtes parfaits. La solution courante du secteur est curl_cffi avec impersonate="chrome120", qui reproduit fidèlement TLS + HTTP/2 de Chrome.
Trois façons d’extraire Redfin avec Python (et laquelle choisir)
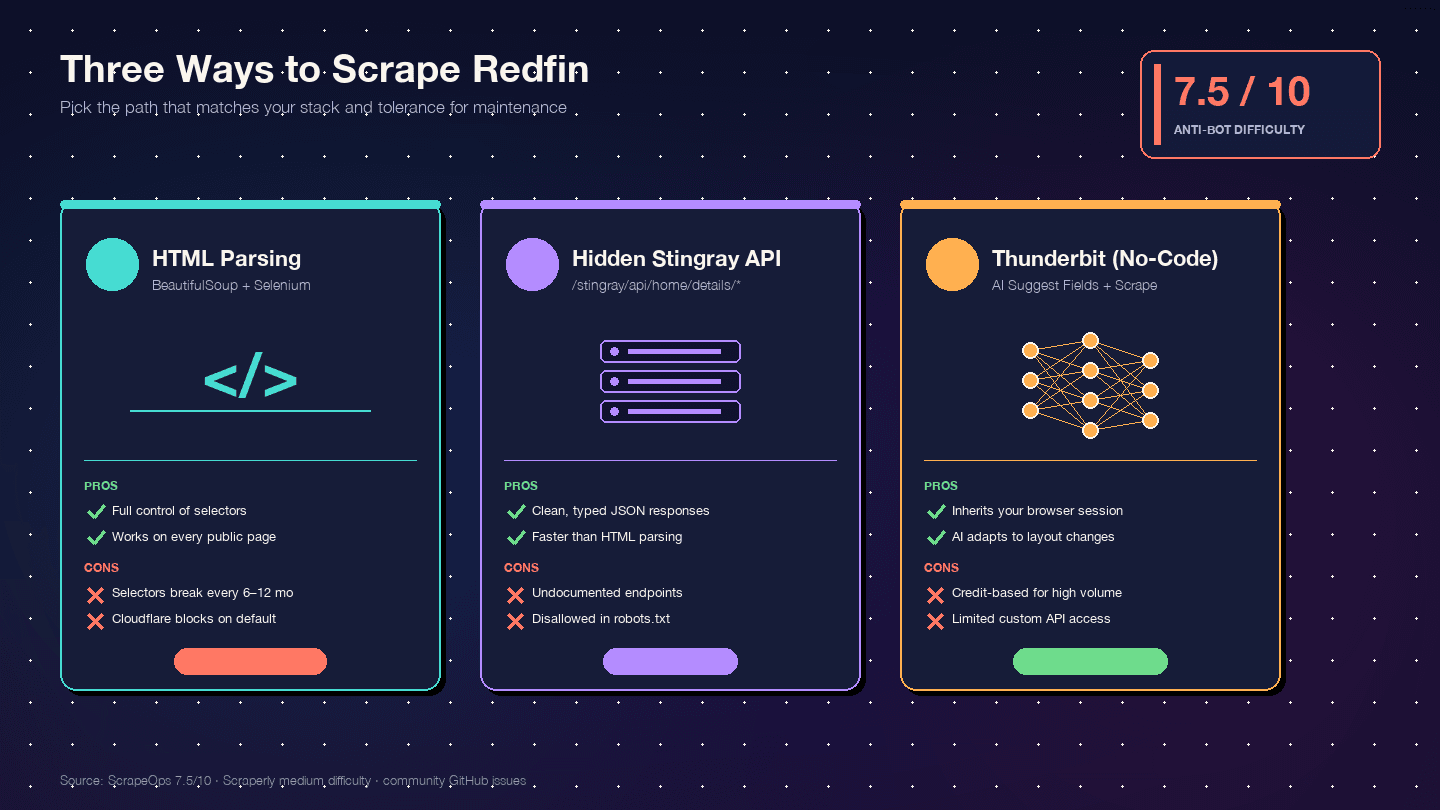
Je n’ai pas trouvé un seul autre tutoriel qui compare clairement ces trois approches côte à côte. Voici la matrice de décision :
| Critère | Analyse HTML (BS4 + Selenium) | API cachée Stingray | Thunderbit (sans code) |
|---|---|---|---|
| Difficulté de mise en place | Moyenne (env Python + driver navigateur) | Élevée (reverse engineering des endpoints) | Faible (installation d’une extension Chrome) |
| Risque anti-bot | Élevé (les requêtes DOM sont très visibles) | Moyen (les requêtes de type API sont plus discrètes) | Le plus faible (utilise votre vraie session navigateur) |
| Qualité de la structure des données | Moyenne (HTML non structuré → parsing manuel) | Excellente (JSON déjà structuré) | Élevée (l’IA détecte automatiquement champs et types) |
| Charge de maintenance | Élevée — chaque changement de mise en page casse les sélecteurs | Moyenne — les endpoints peuvent changer sans prévenir | La plus faible — l’IA s’adapte aux changements de mise en page |
| Échelle | Faible à moyenne (centaines avec proxies) | Moyenne à élevée (milliers, requêtes plus propres) | Moyenne (50 pages par lot via scraping cloud) |
| Idéal pour | Développeurs voulant un contrôle total | Développeurs ayant besoin de JSON propre | Non-développeurs, projets rapides, données récurrentes sans ressources dev |
L’aspect maintenance mérite d’être souligné. Redfin a publié deux générations de cartes DOM — l’ancienne (homecardV2Price) et la version actuelle (span.bp-Homecard__Price--value). L’historique des issues GitHub montre des cassures de sélecteurs CSS tous les 6 à 12 mois environ. Quand ça arrive, un scraper BeautifulSoup casse du jour au lendemain. Un détecteur de champs basé sur l’IA, lui, s’adapte.
Avant de commencer
- Niveau de difficulté : Intermédiaire (approches 1 et 2), débutant (approche 3)
- Temps nécessaire : environ 30 minutes pour l’approche 1 ou 2 ; environ 5 minutes pour l’approche 3
- Ce qu’il vous faut :
- Python 3.8+ avec pip (approches 1 et 2)
- Navigateur Chrome (toutes les approches)
- (approche 3)
- Proxies résidentiels US pour le scraping à grande échelle (approches 1 et 2)
Approche 1 : extraire Redfin avec Python via l’analyse HTML (BeautifulSoup + Selenium)
C’est la voie du « contrôle total ». Vous écrivez les sélecteurs, vous gérez le navigateur, vous traitez les erreurs.
C’est l’approche la plus formatrice. C’est aussi la plus fragile.
Étape 1 : configurer votre environnement Python
Créez un environnement virtuel et installez les bibliothèques nécessaires :
1python -m venv redfin-scraper
2source redfin-scraper/bin/activate # Sous Windows : redfin-scraper\Scripts\activate
3pip install requests beautifulsoup4 selenium webdriver-manager pandas curl_cfficurl_cffi est essentiel ici : c’est ce qui permet à vos requêtes HTTP d’imiter l’empreinte TLS d’un vrai Chrome, au lieu de l’empreinte standard de requests que Cloudflare bloque immédiatement.
Étape 2 : configurer les en-têtes et la session du navigateur
C’est là que la plupart des débutants se plantent. Vous avez besoin du jeu complet d’en-têtes Chrome, y compris les en-têtes Sec-Fetch-* que Redfin/Cloudflare vérifie explicitement :
1from curl_cffi import requests as curl_requests
2HEADERS = {
3 "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/120.0.0.0 Safari/537.36",
6 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
7 "Accept-Language": "en-US,en;q=0.9",
8 "Accept-Encoding": "gzip, deflate, br",
9 "Sec-Fetch-Site": "none",
10 "Sec-Fetch-Mode": "navigate",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-User": "?1",
13}
14session = curl_requests.Session(impersonate="chrome120")
15session.headers.update(HEADERS)
16# Réchauffez la session — récupérez les cookies cf_clearance et RF_BROWSER_ID
17session.get("https://www.redfin.com/")L’étape de réchauffement de la session est cruciale — accéder d’un coup à une URL profonde d’un bien (sans cookies préalables, sans Referer) vous fait sanctionner par Cloudflare.
Commencez toujours par la page d’accueil.
Étape 3 : extraire les résultats de recherche Redfin
Une fois la session réchauffée, vous pouvez récupérer une page de recherche par ville et analyser les cartes d’annonces. Sélecteurs actuels (2024–2026) :
1import time
2import random
3from bs4 import BeautifulSoup
4base_url = "https://www.redfin.com/city/17151/CA/San-Francisco"
5listings = []
6for page_num in range(1, 6): # Pages 1-5
7 url = f"{base_url}/page-{page_num}" if page_num > 1 else base_url
8 resp = session.get(url)
9 if resp.status_code != 200:
10 print(f"Bloqué à la page {page_num} : HTTP {resp.status_code}")
11 break
12 soup = BeautifulSoup(resp.text, "html.parser")
13 cards = soup.select("[data-rf-test-id='property-card'], a.bp-Homecard")
14 for card in cards:
15 price_el = card.select_one("span.bp-Homecard__Price--value")
16 addr_el = card.select_one("a.bp-Homecard__Address")
17 stats = card.select("span.bp-Homecard__LockedStat--value")
18 listing = {
19 "price": price_el.text.strip() if price_el else None,
20 "address": addr_el.text.strip() if addr_el else None,
21 "beds": stats[0].text.strip() if len(stats) > 0 else None,
22 "baths": stats[1].text.strip() if len(stats) > 1 else None,
23 "sqft": stats[2].text.strip() if len(stats) > 2 else None,
24 "url": "https://www.redfin.com" + addr_el["href"] if addr_el else None,
25 }
26 listings.append(listing)
27 # Délai aléatoire entre 2 et 5 secondes
28 time.sleep(random.uniform(2, 5))
29print(f"{len(listings)} annonces extraites")Vous devriez obtenir une liste croissante de dictionnaires, chacun contenant le prix, l’adresse, les chambres/salles de bain/surface et l’URL détaillée d’une annonce de San Francisco. Si vous obtenez 0 carte, vérifiez le code HTTP — un 403 signifie que Cloudflare vous a repéré, et que vous avez probablement besoin de proxies résidentiels.
Étape 4 : extraire les pages détaillées des biens
Les résultats de recherche vous donnent les bases. Les pages détaillées vous donnent le Redfin Estimate, l’année de construction, les charges HOA, l’historique des ventes, les informations d’agent et les photos. Ces pages nécessitent du rendu JavaScript, donc il faut passer à Selenium :
1from selenium import webdriver
2from selenium.webdriver.chrome.service import Service
3from webdriver_manager.chrome import ChromeDriverManager
4from selenium.webdriver.common.by import By
5import time
6options = webdriver.ChromeOptions()
7options.add_argument("--headless=new")
8options.add_argument("--disable-blink-features=AutomationControlled")
9options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
10 "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
11driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
12for listing in listings[:10]: # Enrichir les 10 premières
13 driver.get(listing["url"])
14 time.sleep(random.uniform(3, 6)) # Attendre le rendu JS
15 try:
16 estimate_el = driver.find_element(By.CSS_SELECTOR, "[data-rf-test-name='avmLdpPrice']")
17 listing["redfin_estimate"] = estimate_el.text.strip()
18 except:
19 listing["redfin_estimate"] = None
20 try:
21 year_built = driver.find_element(By.XPATH, "//span[contains(text(),'Year Built')]/following-sibling::span")
22 listing["year_built"] = year_built.text.strip()
23 except:
24 listing["year_built"] = None
25driver.quit()Après cette étape, vos 10 premières annonces devraient être enrichies avec la valeur Redfin Estimate et l’année de construction. Les sélecteurs XPath sont plus robustes que le CSS pour ces champs imbriqués d’équipements, mais ils restent fragiles — toute restructuration du DOM peut les casser.
Étape 5 : gérer les blocages et les erreurs
Implémentez une logique de tentative avec backoff exponentiel :
1import time
2def fetch_with_retry(session, url, max_retries=3):
3 for attempt in range(max_retries):
4 resp = session.get(url)
5 if resp.status_code == 200:
6 return resp
7 elif resp.status_code in (403, 429, 503):
8 wait = (2 ** attempt) + random.uniform(1, 3)
9 print(f"Bloqué ({resp.status_code}). Nouvelle tentative dans {wait:.1f}s...")
10 time.sleep(wait)
11 else:
12 print(f"Statut inattendu : {resp.status_code}")
13 break
14 return NoneSignes que vous êtes bloqué : HTTP 403 avec HTML Cloudflare dans le corps de réponse, HTTP 429 (limite de débit explicite), corps de réponse vide, ou « Error 1020 Access Denied » dans le contenu de la page. Si cela arrive souvent, il est temps d’ajouter des proxies résidentiels ou de passer à l’approche API.
Approche 2 : extraire Redfin avec Python via l’API Stingray cachée
C’est mon approche préférée. Le frontend de Redfin communique avec une API JSON interne sous /stingray/api/home/details/*, et les réponses reviennent sous forme de JSON propre et typé — sans parsing HTML.
Comment découvrir les endpoints cachés de l’API Redfin
Ouvrez Chrome DevTools → onglet Network → filtrez sur Fetch/XHR → naviguez vers n’importe quelle page de bien Redfin. Vous verrez des requêtes vers des endpoints comme :
api/home/details/initialInfo— résout l’URL → propertyId, listingIdapi/home/details/aboveTheFold— prix, chambres, salles de bain, surface, photos, statut, agent, MLS#api/home/details/belowTheFold— équipements, HOA, taxes, parking, année de construction, terrain, historiqueapi/home/details/avm— Redfin Estimate pour les biens en venteapi/home/details/owner-estimate— Redfin Estimate hors marchéapi/home/details/descriptiveParagraph— description marketing
Pour les pages de location, le rentalId (UUID de 36 caractères) est extrait de l’URL de la balise <meta property="og:image">.
Extraction des données via l’API Stingray
Il y a une particularité importante : les réponses JSON de Stingray sont préfixées par la chaîne littérale {}&& comme mesure anti-CSRF. Il faut la retirer avant de parser :
1import json
2from curl_cffi import requests as curl_requests
3session = curl_requests.Session(impersonate="chrome120")
4session.headers.update(HEADERS)
5# Réchauffer la session
6session.get("https://www.redfin.com/")
7# Récupérer une page bien immobilier pour obtenir les cookies et l'ID du bien
8property_url = "https://www.redfin.com/CA/San-Francisco/123-Main-St-94102/home/12345678"
9page_resp = session.get(property_url)
10# Appeler ensuite l’API Stingray
11api_url = "https://www.redfin.com/stingray/api/home/details/aboveTheFold?propertyId=12345678"
12api_resp = session.get(api_url, headers={"Referer": property_url})
13# Retirer le préfixe anti-CSRF
14payload = json.loads(api_resp.text.replace("{}&&", "", 1))
15# Extraire les données structurées
16listing_data = payload.get("payload", {})
17print(json.dumps(listing_data, indent=2))La réponse inclut des champs typés : prix en entier, chambres/salles de bain en nombres, URL de photos en tableaux, informations d’agent en objets imbriqués. Pas de parsing BeautifulSoup, pas de sélecteurs CSS, pas d’approximation.
Avantages et limites de l’approche API cachée
Avantages :
- JSON déjà structuré — nettement plus propre que l’analyse HTML
- Plus rapide par requête (payloads plus petits, pas de rendu)
- Risque de blocage plus faible (les requêtes de type API avec des en-têtes corrects paraissent plus naturelles)
Limites :
- Les endpoints peuvent changer sans prévenir — aucune documentation officielle
robots.txtinterdit explicitement/stingray/pour l’agent utilisateur générique- Nécessite du reverse engineering pour découvrir de nouveaux endpoints
- Exige toujours un réchauffement de session et des en-têtes adaptés pour éviter Cloudflare
L’alternative sans code : extraire Redfin avec Thunderbit
Si vous avez besoin de données Redfin sans vouloir maintenir des scripts Python — ou si vous voulez juste des résultats en cinq minutes — commencez ici. Nous avons conçu précisément pour ça : extraire des données structurées depuis n’importe quel site, sans écrire de code.
Étape 1 : installer Thunderbit et ouvrir Redfin
Installez l’ depuis le Chrome Web Store. Ouvrez Redfin et allez sur une page de résultats — par exemple les maisons à vendre à San Francisco.
Étape 2 : cliquer sur « AI Suggest Fields »
Cliquez sur l’icône Thunderbit dans la barre d’outils de votre navigateur, puis sur « AI Suggest Fields ». L’IA lit la page Redfin et propose automatiquement des colonnes comme « Address », « Price », « Beds », « Baths », « SqFt », « Property Type » et « Listing Photo » — avec les bons types de données attribués automatiquement.
Vous pouvez supprimer les colonnes inutiles ou en ajouter de personnalisées via « + Add Column » en décrivant simplement ce que vous voulez en anglais courant (par exemple « nom de l’agent » ou « jours sur le marché »).
Vous verrez un aperçu du tableau avec les colonnes déjà configurées, prêt à être rempli.
Étape 3 : cliquer sur « Scrape » et laisser les données arriver
Cliquez sur le bouton « Scrape ». Thunderbit traite les annonces visibles et remplit votre tableau. Pour les résultats paginés, la pagination est gérée automatiquement — aucune boucle à écrire.
Lors de mes tests, un tableau de 50 lignes se remplit en environ 45 secondes. Des données structurées, prêtes à exporter.
Comment Thunderbit gère les protections anti-bot de Redfin
Comme Thunderbit s’exécute dans votre propre navigateur, il hérite de vos cookies Redfin existants, de votre session et de votre empreinte navigateur. Pour Cloudflare, ça ressemble à un utilisateur normal qui navigue sur Redfin — parce que techniquement, c’en est un. Pas de navigateur headless, pas d’IP datacenter, pas d’empreinte TLS incohérente. Pour les pages publiques, le mode de scraping cloud de Thunderbit peut traiter 50 pages à la fois.
C’est une posture radicalement différente de l’envoi de requêtes requests depuis un script Python sur un serveur.
Votre session navigateur est déjà digne de confiance.
Extraire les sous-pages Redfin avec Thunderbit
Après avoir extrait les résultats de recherche, cliquez sur « Scrape Subpages » pour que l’IA visite chaque URL de détail et enrichisse votre tableau avec des champs supplémentaires — Redfin Estimate, année de construction, charges HOA, informations d’agent, photos du bien et historique des ventes.
C’est l’équivalent de la boucle Selenium de 40 lignes de l’approche 1 — sauf qu’il faut un clic et zéro maintenance.
Quand Redfin fait passer son DOM de homecardV2Price à span.bp-Homecard__Price--value, l’IA s’adapte. Vos sélecteurs Python, non.
Au-delà du CSV : exporter les données Redfin vers Google Sheets, Airtable et Notion
La plupart des tutos s’arrêtent à df.to_csv(). C’est très bien pour une analyse ponctuelle. Mais si vous travaillez dans une équipe immobilière, vous avez besoin de données vivantes et collaboratives — pas de fichiers statiques qui dorment sur le bureau de quelqu’un.
Exporter avec Python (gspread + API Airtable)
Google Sheets via gspread :
1import gspread
2import pandas as pd
3from gspread_dataframe import set_with_dataframe
4df = pd.DataFrame(listings)
5gc = gspread.service_account(filename="service_account.json")
6sh = gc.open("Redfin Listings")
7ws = sh.worksheet("Sheet1")
8ws.clear()
9set_with_dataframe(ws, df, include_index=False, resize=True)
10# Afficher les photos directement dans la feuille via la formule IMAGE()
11image_col = df.columns.get_loc("image_url") + 1
12for row_idx, url in enumerate(df["image_url"], start=2):
13 ws.update_cell(row_idx, image_col, f'=IMAGE("{url}")')Attention : Google Sheets a une limite stricte de 10 millions de cellules par feuille de calcul, et l’API autorise . Utilisez ws.batch_update() plutôt que des boucles cellule par cellule pour tout volume supérieur à quelques dizaines de lignes.
Airtable via pyairtable :
Changement important en 2024 : Airtable a . Vous devez désormais utiliser des Personal Access Tokens (PAT) — tout tuto qui montre encore api_key=... est obsolète.
1from pyairtable import Api
2api = Api("patXXXXXXXXXXXXXX.yyyyyyyyyyyyyyyyyyyy")
3table = api.table("appBaseId123", "Redfin Listings")
4records = [
5 {
6 "Address": row["address"],
7 "Price": row["price"],
8 "Beds": row["beds"],
9 "Photo": [{"url": row["image_url"]}], # Airtable récupère et réhéberge
10 }
11 for row in listings
12]
13created = table.batch_create(records, typecast=True)La limite de débit d’Airtable est de , avec un verrouillage de 30 secondes en cas de dépassement. Le champ pièce jointe accepte des payloads [{"url": ...}] — les serveurs d’Airtable récupèrent l’URL, la réhébergent sur leur CDN et génèrent automatiquement les vignettes.
Exporter avec Thunderbit (1 clic vers Sheets, Airtable, Notion)
Thunderbit propose un export natif en 1 clic vers Google Sheets, Airtable et Notion — et voici la partie dont je suis vraiment fier : les photos de biens sont téléversées et affichées en images intégrées dans Notion et Airtable. Pas besoin de bricoler des formules =IMAGE(), ni de subir des liens CDN cassés. Vous cliquez sur « Export to Airtable », et votre équipe obtient une base visuelle de biens immobiliers avec des vignettes consultables sur mobile.
Pour les équipes immobilières qui font du tri visuel d’annonces, c’est la différence entre un outil vraiment utile et une pile de lignes CSV.
Est-il légal d’extraire des données Redfin ? Ce que disent les CGU, robots.txt et la jurisprudence
Je ne suis pas avocat, et ceci n’est pas un conseil juridique. Mais après des années dans l’extraction de données, je peux vous dire une chose : « est-ce légal ? » est la question que tout le monde pose, et que la plupart des tutoriels évitent.
Le robots.txt de Redfin
Le de Redfin est détaillé. Points clés :
- Bots complètement bloqués :
peer39_crawler/1.0,AmazonAdBot,FireCrawlAgent— Redfin nomme explicitement ce service de scraping bien connu de l’ère LLM - Points saillants des règles
User-agent: *avecDisallow:/stingray/(tout l’espace de noms de l’API interne),/myredfin/,/api/v1/rentals/,/api/v1/properties/,/owner-estimate/ - Aucune directive
Crawl-delay:pour quelque agent utilisateur que ce soit - Plus de 50 sitemaps déclarés — les sitemaps sont la façon la plus propre, la moins agressive pour le WAF, d’énumérer des URLs
Les conditions d’utilisation de Redfin
La stipule : « Vous ne pouvez pas crawler ou interroger automatiquement les Services, à quelque fin que ce soit ni par quelque moyen que ce soit... sauf si vous avez reçu une autorisation écrite expresse préalable. »
Il s’agit d’un accord de type browsewrap — l’acceptation se fait par l’usage continu, et non par une case à cocher. Les tribunaux américains se montrent historiquement prudents pour imposer le browsewrap à des utilisateurs qui n’en avaient pas réellement connaissance (voir Nguyen v. Barnes & Noble, 9e circuit, 2014).
Jurisprudence pertinente, en bref
- Van Buren v. United States (Cour suprême, 2021) : la clause du CFAA « exceeds authorized access » suit un test « portes ouvertes ou fermées ». Utiliser une porte ouverte à une fin non souhaitée n’est pas du piratage fédéral.
- hiQ Labs v. LinkedIn (9e circuit, 2022) : extraire des données publiquement accessibles ne constitue pas une violation du CFAA. Mais hiQ a tout de même payé 500 000 $ dans un accord transactionnel sur la base d’une rupture de contrat — car hiQ avait créé des comptes LinkedIn et cliqué sur « I agree ».
- Meta Platforms v. Bright Data (N.D. Cal., janv. 2024) : le tribunal a accordé un jugement sommaire à Bright Data — l’extraction hors connexion de données publiques ne faisait pas de Bright Data un « utilisateur » lié par les CGU de Meta.
- X Corp. v. Bright Data (N.D. Cal., mai 2024) : le juge Alsup a rejeté les demandes de X, estimant que les prétentions fondées sur le droit étatique visant à contrôler la copie de contenus publics étaient préemptées par le Copyright Act.
Conseils pratiques
- N’extrayez que des données accessibles publiquement — n’ouvrez jamais de compte puis ne scrapez pas derrière (ça crée un risque contractuel de type clickwrap)
- Respectez les limites de débit — des volumes agressifs peuvent soutenir des accusations de trespass to chattels
- Ne republiez pas à grande échelle les données brutes ou les photos — l’affaire (déposée en juillet 2025, dommages potentiels supérieurs à 1 milliard de dollars) rappelle que le droit d’auteur sur les photos est sérieux
- L’approche navigateur de Thunderbit — qui s’exécute dans votre propre session authentifiée — se rapproche davantage d’une « navigation manuelle à la vitesse d’une machine » que d’un bot headless en datacenter, ce qui est la posture la plus défendable en dehors d’une API sous licence
Conseils et pièges courants
Quelques leçons durement acquises en construisant des outils d’extraction et en observant des milliers d’utilisateurs scraper des sites immobiliers :
- Réchauffez toujours votre session. Ouvrez
redfin.com/avant toute URL profonde. Les accès directs à une URL profonde sont le déclencheur n°1 des challenges Cloudflare. - Faites tourner les User-Agent de manière réaliste. N’en utilisez pas un seul — alternez 5 à 10 User-Agent récents Chrome/Firefox. Mais n’allez pas trop loin non plus : un User-Agent différent à chaque requête paraît suspect.
- Dédupliquez par ID de bien. La pagination de Redfin se chevauche parfois. Extrayez le
/home/{id}de chaque URL d’annonce et dédupliquez avant l’enrichissement. - Évitez si possible les heures de pointe. De mon expérience, les heures tardives / tôt le matin aux États-Unis subissent moins de contrôle WAF.
- Si vous recevez un 429, ralentissez de façon exponentielle. Ne réessayez pas immédiatement — c’est ainsi qu’on passe d’une limitation souple à un bannissement IP dur.
- Pour les gros projets (1 000+ pages), prévoyez des proxies résidentiels. Les IP datacenter (AWS, GCP, Azure, OVH) sont blacklistées par le système de réputation ASN de Cloudflare. Vous toucherez l’Error 1020 presque instantanément.
Choisir la bonne méthode pour extraire Redfin
Alors, quelle approche choisir ? Cela dépend de votre profil et de vos besoins.
Analyse HTML (BeautifulSoup + Selenium) : idéale pour les développeurs qui veulent un contrôle total, qui sont à l’aise avec la maintenance des sélecteurs CSS et qui ne craignent pas de reconstruire leur scraper quand Redfin modifie son DOM. Prévoyez de revoir votre code tous les 6 à 12 mois.
API Stingray cachée : idéale pour les développeurs qui veulent du JSON propre et structuré, et qui savent faire du reverse engineering sur des endpoints non documentés. Moins de maintenance que l’analyse HTML, mais les endpoints peuvent changer sans prévenir. N’oubliez pas que /stingray/ est explicitement interdit dans robots.txt.
Thunderbit (sans code) : idéale pour les non-développeurs, les projets rapides et les équipes qui ont besoin de données Redfin en continu sans ressources techniques. L’IA s’adapte aux changements de mise en page, l’extraction des sous-pages enrichit les données en un clic, et l’export vers , Airtable ou Notion est intégré. Si vous êtes une équipe immobilière qui a besoin d’une base de données vivante — et non d’un simple CSV ponctuel — c’est la voie la plus simple.
Quelle que soit la méthode choisie : comprenez les défenses anti-bot de Redfin avant de commencer, identifiez précisément les champs dont vous avez besoin, choisissez un format d’export adapté au workflow de votre équipe, et restez du bon côté des .
Prêt à essayer l’approche sans code ? vous permet de tester l’extraction de Redfin et d’obtenir des résultats en quelques minutes. Pour les approches Python, les extraits de code ci-dessus constituent une base fonctionnelle — ajoutez simplement des proxies et un peu de patience.
FAQ
Redfin propose-t-il une API publique ?
Non. Redfin ne propose pas d’API publique officielle. L’API cachée Stingray (/stingray/api/home/details/*) renvoie du JSON structuré et alimente le frontend de Redfin, mais elle n’est ni officielle ni documentée, peut changer sans préavis et est explicitement interdite par le robots.txt de Redfin. Des wrappers open source comme sur PyPI offrent un accès Python, mais utilisez-les en connaissance des risques.
Peut-on extraire Redfin sans Python ?
Oui. est une extension Chrome IA qui hérite de votre session navigateur pour mieux résister aux protections anti-bot — installez-la, ouvrez Redfin, cliquez sur « AI Suggest Fields », puis exportez vers Excel, Google Sheets, Airtable ou Notion. Il existe aussi d’autres outils no-code et des fournisseurs de jeux de données préconstruits si vous voulez explorer d’autres options.
À quelle fréquence Redfin modifie-t-il la mise en page de son site ?
L’historique des issues GitHub de la communauté montre des cassures de sélecteurs CSS environ tous les 6 à 12 mois. Redfin a publié deux générations de cartes DOM — l’ancienne (homecardV2Price, homeAddressV2) et la version actuelle (bp-Homecard__Price--value, bp-Homecard__Address). Les scrapers mûrs testent les deux séquences.
Les outils basés sur l’IA comme Thunderbit parce qu’ils détectent les champs par leur contenu plutôt que par les sélecteurs CSS.
Quel type de proxy est le meilleur pour extraire Redfin ?
Des proxies résidentiels US pour les gros volumes — les benchmarks communautaires situent le taux de réussite autour de 80 %. Les proxies datacenter se heurtent presque immédiatement à l’Error 1020 de Cloudflare ; les plages IP AWS, GCP, Azure et OVH sont blacklistées. Les proxies mobiles ont le meilleur taux de réussite, mais coûtent 5 à 10 fois plus cher.
Pour un scraping personnel à petite échelle (<100 pages), des en-têtes corrects + l’impersonation curl_cffi + des délais de 2 à 5 secondes peuvent suffire sans proxy.
Peut-on extraire des biens vendus ou hors marché depuis Redfin ?
Oui. Les données des biens vendus et le Redfin Estimate hors marché (erreur médiane ) sont disponibles sur les pages détail avec les mêmes approches de scraping. Les champs diffèrent des annonces actives : les pages hors marché exposent le prix de vente, la date de vente, l’historique du bien et l’endpoint owner-estimate, mais pas le prix affiché actuel, les jours sur le marché ni les informations d’open house. L’endpoint Stingray pour les estimations hors marché est api/home/details/owner-estimate et non api/home/details/avm.
En savoir plus