Quelque part autour de ma cinquantième opération de copier-coller d’un titre de poste depuis Indeed vers un tableur, j’ai commencé à remettre mes choix de carrière en question. Si vous avez déjà essayé d’extraire programmaticalement des données structurées depuis Indeed, vous connaissez déjà la suite : l’erreur 403 n’est pas un bug — c’est une fonctionnalité du système de défense d’Indeed.
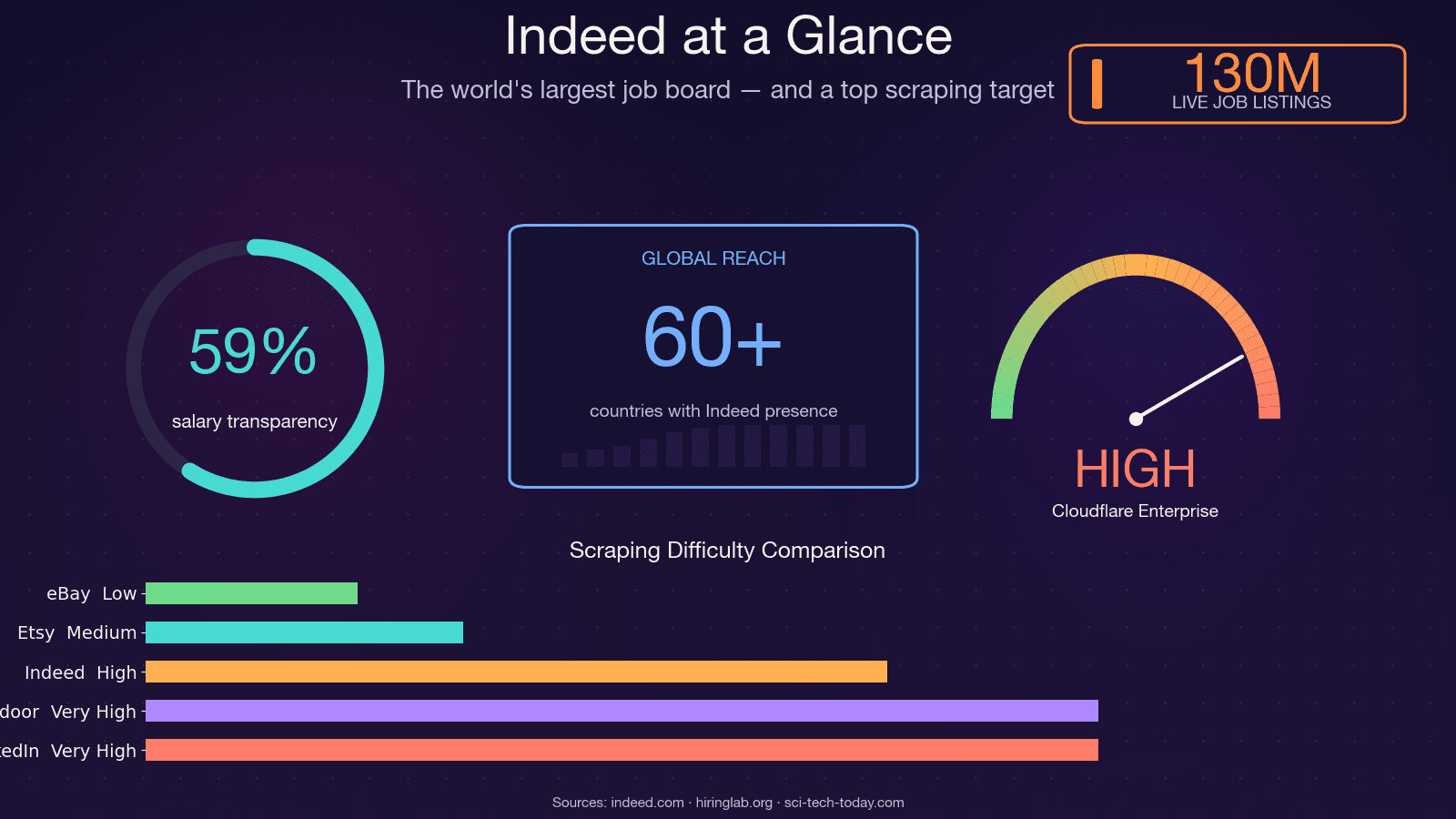
Indeed est le plus grand site d’emploi au monde, avec environ , à tout moment, et une présence dans . Cela en fait l’une des sources de données sur le marché de l’emploi les plus riches de la planète — et aussi l’une des plus difficiles à extraire. Le scraper open source JobFunnel (des milliers d’étoiles sur GitHub) a littéralement été en décembre 2025, après des années perdues dans la course à l’armement contre les anti-bots. Les mots mêmes du mainteneur : « Tous les utilisateurs peuvent extraire quelques offres, mais se heurtent rapidement à un captcha, puis l’extraction échoue, ne renvoyant aucune offre. » Un autre contributeur a signalé avoir reçu un CAPTCHA . Bref, ce n’est pas une cible de scraping triviale. Dans ce guide, je vais passer en revue toutes les méthodes pratiques pour extraire Indeed avec Python, vous montrer comment survivre au vrai parcours du combattant des 403, et — pour celles et ceux qui préfèrent éviter complètement le débogage — présenter une alternative sans code avec .
Que signifie extraire Indeed avec Python ?
Le web scraping, dans son essence, consiste à extraire automatiquement des données structurées depuis des pages web. Quand on parle d’extraire Indeed avec Python, cela signifie écrire un script qui visite les pages de résultats et les pages de détail des offres Indeed, lit le HTML sous-jacent (ou les données embarquées) et récupère des champs comme le titre du poste, l’entreprise, le lieu, le salaire et la description dans un format exploitable — un CSV, une base de données, une feuille Google.
Les bibliothèques Python généralement utilisées sont Requests (pour les appels HTTP), BeautifulSoup (pour l’analyse HTML) et Selenium ou Playwright (pour l’automatisation du navigateur). Mais Indeed n’est pas un simple site statique. C’est un hybride : HTML rendu côté serveur avec un bloc d’état JSON embarqué, protégé par Cloudflare Bot Management. Cela signifie que votre scraper doit gérer du contenu rendu par JavaScript, des noms de classes CSS qui changent, et des protections anti-bot agressives — avant même d’analyser un seul titre de poste.
Il n’existe d’ailleurs pas d’API Indeed officielle, gratuite et en lecture seule en 2026. L’ancienne Publisher Jobs API a été dépréciée vers 2020, et ce qu’il reste est réservé aux employeurs (Job Sync, Sponsored Jobs). Le scraping ou le recours à un fournisseur de données tiers sont donc les seules options réalistes.
Pourquoi extraire les données d’offres Indeed ?
Le cas d’usage est simple : parcourir manuellement des milliers d’annonces est impraticable, et les données qu’elles contiennent ont une vraie valeur.
| Cas d’usage | Qui en bénéficie | Exemple |
|---|---|---|
| Génération de leads | Équipes commerciales et recrutement | Constituer des listes d’entreprises qui recrutent avec leurs coordonnées |
| Étude du marché de l’emploi | Analystes, équipes RH | Identifier les compétences émergentes, les repères salariaux par région |
| Veille concurrentielle | Employeurs, agences d’intérim | Suivre les tendances de recrutement et les offres de rémunération des concurrents |
| Automatisation de la recherche d’emploi personnelle | Candidats | Regrouper les offres correspondant à vos critères, tous lieux confondus |
| Données d’entraînement pour modèles ML | Data scientists | Construire des modèles de prédiction salariale à partir de données historiques |
Les propres recherches du Hiring Lab d’Indeed que les données d’offres suivent de près le BLS JOLTS et peuvent servir de proxy quasi temps réel des conditions du marché du travail américain. Les hedge funds utilisent la vitesse de publication des offres comme signal de données alternatives. Les équipes RH se servent des fourchettes de salaire extraites pour benchmarker les rémunérations. Et les recruteurs bâtissent des listes de prospects à partir des entreprises qui recrutent activement.
Point pratique important : les données salariales sur Indeed s’améliorent, mais restent incomplètes. À la mi-2025, environ incluent une information salariale, mais seulement donnent un montant exact — le reste correspond à des fourchettes. Toute analyse salariale fondée sur les données Indeed doit tenir compte de cette rareté.
Choisir votre méthode pour extraire Indeed avec Python
Il n’existe pas une seule « bonne » façon d’extraire Indeed. La meilleure approche dépend de votre niveau, du volume de données nécessaire et du niveau de maintenance que vous êtes prêt à accepter. J’ai testé les quatre grandes approches, et voici la comparaison :
| Critère | BS4 + Requests | Selenium | JSON caché (window.mosaic) | Sans code (Thunderbit) |
|---|---|---|---|---|
| Difficulté | Débutant | Intermédiaire | Intermédiaire-avancé | Aucune (2 clics) |
| Vitesse | Rapide | Lente (rendu du navigateur) | Rapide | Rapide (scraping cloud) |
| Contenu rendu en JS | Non | Oui | Oui (données embarquées) | Oui |
| Résistance aux anti-bots | Faible | Moyenne (détectable) | Moyenne à élevée | Élevée (prise en charge automatique) |
| Maintenance lors des changements HTML | Élevée (les sélecteurs cassent) | Élevée | Moyenne (structure JSON plus stable) | Aucune (l’IA s’adapte) |
| Idéal pour | Prototypes rapides | Pages dynamiques, contenu derrière connexion | Données structurées en masse | Non-développeurs, résultats rapides |
Ce guide passe en revue chacune de ces méthodes. Si vous êtes développeur Python, vous voudrez lire les sections BS4, JSON caché et Selenium. Si vous n’êtes pas codeur (ou si vous êtes simplement fatigué de déboguer des 403), passez directement à la section Thunderbit.
Avant de commencer
- Difficulté : Débutant à intermédiaire (sections Python) ; aucune (section Thunderbit)
- Temps nécessaire : ~20 à 60 minutes pour la configuration Python et la première extraction ; ~2 minutes avec Thunderbit
- Ce qu’il vous faut : Python 3.9+, un éditeur de code, le navigateur Chrome et (pour la voie sans code) l’
Configurer votre environnement Python pour le scraping d’Indeed
Avant d’écrire le moindre code de scraping, préparez votre environnement.
Installer les bibliothèques requises
Créez un environnement virtuel et installez les paquets nécessaires :
1python -m venv indeed_env
2source indeed_env/bin/activate # Sous Windows : indeed_env\Scripts\activate
3# Pour l’approche HTTP + parsing
4pip install requests beautifulsoup4 lxml httpx
5# Pour l’approche JSON caché (recommandée)
6pip install curl_cffi parsel tenacity
7# Pour l’approche d’automatisation navigateur
8pip install seleniumQuelques remarques :
curl_cffiest le choix par défaut en 2026 pour les sites protégés par Cloudflare. Il imite les empreintes TLS réelles d’un navigateur, ce querequestsethttpxne peuvent pas faire. J’explique pourquoi c’est crucial dans la section anti-bot.- Selenium 4.6+ inclut Selenium Manager, donc vous n’avez plus besoin de télécharger manuellement ChromeDriver — il gère automatiquement le binaire du navigateur.
- Utilisez
lxmlcomme moteur d’analyse pour BeautifulSoup. C’est environ que lehtml.parserde la bibliothèque standard.
Créer la structure de votre projet
Restez simple :
1indeed_scraper/
2├── scraper.py
3├── requirements.txt
4└── output/Tous les exemples de code ci-dessous s’appuient sur scraper.py.
Comment extraire Indeed avec Python en utilisant BeautifulSoup
C’est l’approche la plus accessible pour débuter : utilisez requests pour récupérer la page, puis BeautifulSoup pour analyser le HTML. C’est la plus rapide à mettre en place, mais aussi la plus fragile sur Indeed.
Étape 1 : construire l’URL de recherche Indeed
Les URL de recherche Indeed suivent un modèle prévisible :
1https://www.indeed.com/jobs?q=<query>&l=<location>&start=<offset>Par exemple, pour chercher « data analyst » à « Austin, TX » à partir de la première page :
1from urllib.parse import urlencode
2params = {
3 "q": "data analyst",
4 "l": "Austin, TX",
5 "start": 0,
6}
7url = f"https://www.indeed.com/jobs?{urlencode(params)}"
8print(url)
9# https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX&start=0Indeed pagine par incréments de 10, avec un plafond strict de 1 000 résultats (start <= 990). Tout offset supérieur à 990 renvoie silencieusement la même page.
Étape 2 : envoyer une requête HTTP avec les bons en-têtes
Indeed bloque immédiatement les requêtes avec les chaînes d’agent utilisateur Python par défaut. Il vous faut des en-têtes réalistes :
1import requests
2headers = {
3 "User-Agent": (
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
5 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36"
6 ),
7 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept-Encoding": "gzip, deflate, br",
10 "Referer": "https://www.indeed.com/",
11}
12response = requests.get(url, headers=headers, timeout=30)
13print(response.status_code)Si vous obtenez un 200, vous êtes dedans — pour l’instant. Si vous obtenez un 403, Cloudflare vous a repéré. (J’explique comment survivre à cela plus bas.)
Étape 3 : analyser les offres à partir du HTML
Utilisez BeautifulSoup pour sélectionner les éléments des cartes d’offres. Ciblez les attributs data-testid — ils sont plus stables que les noms de classes CSS randomisés d’Indeed :
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(response.text, "lxml")
3cards = soup.find_all("div", attrs={"data-testid": "slider_item"})
4jobs = []
5for card in cards:
6 title_el = card.find("h2", class_="jobTitle")
7 title = title_el.get_text(strip=True) if title_el else None
8 company = card.find(attrs={"data-testid": "company-name"})
9 location = card.find(attrs={"data-testid": "text-location"})
10 link = title_el.find("a")["href"] if title_el and title_el.find("a") else None
11 jobs.append({
12 "title": title,
13 "company": company.get_text(strip=True) if company else None,
14 "location": location.get_text(strip=True) if location else None,
15 "url": f"https://www.indeed.com\{link\}" if link else None,
16 })
17print(f"Found {len(jobs)} jobs")Étape 4 : gérer la pagination
Bouclez sur les pages en incrémentant le paramètre start :
1import time, random
2all_jobs = []
3for page in range(0, 50, 10): # 5 premières pages
4 params["start"] = page
5 url = f"https://www.indeed.com/jobs?{urlencode(params)}"
6 response = requests.get(url, headers=headers, timeout=30)
7 # ... analyser comme ci-dessus ...
8 all_jobs.extend(jobs)
9 time.sleep(random.uniform(3, 6))Limites de cette approche
Soyons clairs : BS4 + Requests est la méthode la plus faible pour Indeed en 2026. requests utilise la bibliothèque TLS standard de Python, qui produit une immédiatement identifiée par Cloudflare comme « pas un navigateur ». Elle ne prend pas non plus en charge HTTP/2, pourtant utilisé par Indeed. Vous serez probablement bloqué après quelques pages. Et les sélecteurs CSS ? Indeed fait tourner fréquemment les noms de classes comme css-1m4cuuf et jobsearch-JobComponent-embeddedBody-1n0gh5s — donc tout sélecteur qui les cible est une bombe à retardement.
Utilisez cette méthode pour un prototype rapide sur une seule page. Pour quoi que ce soit à plus grande échelle, utilisez l’approche JSON caché.
Comment extraire Indeed avec Python en utilisant les données JSON cachées
C’est la méthode que je recommande à la plupart des développeurs Python. Au lieu d’analyser des éléments HTML fragiles, vous extrayez des données structurées depuis une variable JavaScript intégrée dans le code source d’Indeed : window.mosaic.providerData["mosaic-provider-jobcards"].
Chaque champ qui compte — titre du poste, entreprise, lieu, salaire, identifiant de l’offre, date de publication, indicateur de télétravail — est déjà présent dans ce bloc JSON. Aucune exécution JavaScript n’est nécessaire. Le schéma est , ce qui le rend bien plus résilient que les sélecteurs DOM.
Étape 1 : récupérer le HTML de la page
Utilisez curl_cffi au lieu de requests — il imite les empreintes TLS réelles d’un navigateur, ce qui est crucial pour survivre à Cloudflare :
1from curl_cffi import requests as cffi_requests
2response = cffi_requests.get(
3 "https://www.indeed.com/jobs?q=python+developer&l=Remote&start=0",
4 impersonate="chrome124",
5 headers={
6 "Accept-Language": "en-US,en;q=0.9",
7 "Referer": "https://www.indeed.com/",
8 },
9 timeout=30,
10)
11print(response.status_code, len(response.text))Pourquoi curl_cffi ? C’est un binding Python de curl-impersonate, qui reproduit exactement le ClientHello TLS, le frame HTTP/2 SETTINGS et l’ordre des en-têtes des vrais navigateurs. C’est le seul client HTTP Python activement maintenu qui contourne en un seul appel. Les cibles d’imitation prises en charge incluent chrome120, chrome124, chrome131, ainsi que des variantes Safari et Edge.
Étape 2 : extraire le JSON avec une expression régulière
Le bloc JSON est intégré dans une balise <script>. Récupérez-le avec une regex :
1import re, json
2MOSAIC_RE = re.compile(
3 r'window\.mosaic\.providerData\["mosaic-provider-jobcards"\]=(\{.+?\});',
4 re.DOTALL,
5)
6match = MOSAIC_RE.search(response.text)
7if match:
8 data = json.loads(match.group(1))
9 results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
10 print(f"Found {len(results)} jobs in hidden JSON")
11else:
12 print("Hidden JSON not found — possible block or page change")Étape 3 : analyser les champs d’offres depuis le JSON
Chaque élément de results contient plus de données que ce qui est visible à l’écran :
1jobs = []
2for job in results:
3 jobs.append({
4 "jobkey": job["jobkey"],
5 "title": job["title"],
6 "company": job.get("company"),
7 "location": job.get("formattedLocation"),
8 "remote": job.get("remoteLocation"),
9 "salary": (job.get("salarySnippet") or {}).get("text"),
10 "posted": job.get("formattedRelativeTime"),
11 "job_type": job.get("jobTypes"),
12 "easy_apply": job.get("indeedApplyEnabled"),
13 "url": f"https://www.indeed.com/viewjob?jk={job['jobkey']}",
14 })Le JSON inclut souvent des estimations salariales, des attributs de taxonomie (tags de compétences) et des évaluations d’entreprise qui ne sont pas toujours visibles dans le HTML rendu.
Étape 4 : extraire plusieurs pages
Utilisez tierSummaries dans le JSON pour comprendre le nombre total de résultats, puis bouclez :
1import time, random
2all_jobs = []
3for start in range(0, 50, 10): # 5 premières pages
4 url = f"https://www.indeed.com/jobs?q=python+developer&l=Remote&start=\{start\}&sort=date"
5 response = cffi_requests.get(
6 url,
7 impersonate="chrome124",
8 headers={"Accept-Language": "en-US,en;q=0.9", "Referer": "https://www.indeed.com/"},
9 timeout=30,
10 )
11 match = MOSAIC_RE.search(response.text)
12 if match:
13 data = json.loads(match.group(1))
14 results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
15 all_jobs.extend([{
16 "jobkey": j["jobkey"],
17 "title": j["title"],
18 "company": j.get("company"),
19 "location": j.get("formattedLocation"),
20 "salary": (j.get("salarySnippet") or {}).get("text"),
21 "url": f"https://www.indeed.com/viewjob?jk={j['jobkey']}",
22 } for j in results])
23 time.sleep(random.uniform(3, 7))
24print(f"Total: {len(all_jobs)} jobs scraped")Pourquoi le JSON caché est plus résilient
La structure window.mosaic.providerData change moins souvent que les noms de classes CSS. Vous obtenez des données propres et structurées sans avoir à analyser un HTML brouillon. Cela dit, vous devez toujours gérer les anti-bots (en-têtes, délais, proxies) — nous y revenons juste après.
Comment extraire Indeed avec Python en utilisant Selenium
Selenium est l’approche d’automatisation du navigateur. Elle est utile lorsque vous devez interagir avec la page — cliquer dans les panneaux de détail des offres, gérer du contenu derrière connexion, ou extraire des descriptions chargées dynamiquement qui ne figurent pas dans le HTML initial.
Quand utiliser Selenium plutôt qu’un client HTTP
- Indeed charge une partie du contenu dynamiquement (descriptions complètes dans le panneau de droite)
- Vous devez extraire des pages qui nécessitent un état de session ou une connexion
- Vous faites du scraping à petite échelle, où la vitesse n’est pas critique
Visite guidée rapide
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3from selenium.webdriver.chrome.options import Options
4import time
5options = Options()
6options.add_argument("--disable-blink-features=AutomationControlled")
7# options.add_argument("--headless=new") # Le mode headless est plus détectable — à utiliser avec prudence
8driver = webdriver.Chrome(options=options)
9driver.get("https://www.indeed.com/jobs?q=data+engineer&l=New+York")
10time.sleep(3)
11cards = driver.find_elements(By.CSS_SELECTOR, "[data-testid='slider_item']")
12for card in cards:
13 try:
14 title = card.find_element(By.CSS_SELECTOR, "h2.jobTitle").text
15 company = card.find_element(By.CSS_SELECTOR, "[data-testid='company-name']").text
16 location = card.find_element(By.CSS_SELECTOR, "[data-testid='text-location']").text
17 print(f"\{title\} | \{company\} | \{location\}")
18 except Exception:
19 continue
20driver.quit()Limites
Selenium est lent — chaque page nécessite un rendu complet du navigateur. Chrome en mode headless est (Cloudflare vérifie navigator.webdriver, les chaînes de l’éditeur WebGL, le nombre de plugins, etc.). Même undetected-chromedriver ne fait que retarder la détection ; il ne l’empêche pas définitivement. Et, comme avec BS4, vos sélecteurs casseront lorsque Indeed mettra à jour son interface.
Pour la plupart des usages, l’approche JSON caché vous donne les mêmes données plus rapidement et avec moins de maintenance. Réservez Selenium aux cas limites où vous avez réellement besoin d’un navigateur.
Comment éviter les erreurs 403 lors du scraping d’Indeed avec Python
C’est la section la plus importante. Si vous êtes arrivé ici après une recherche Google frustrante, vous êtes au bon endroit.
Pourquoi Indeed bloque votre scraper
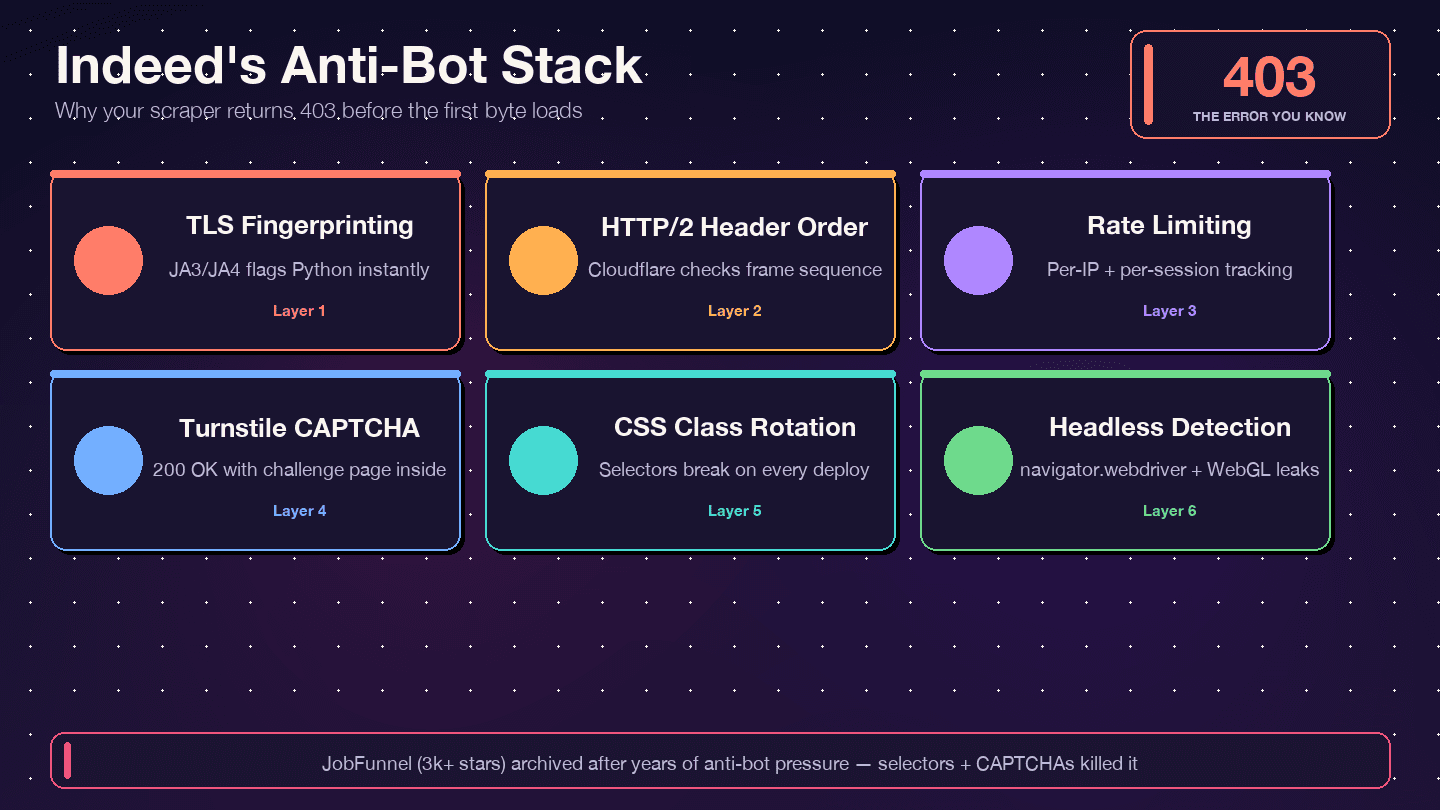
Indeed utilise — pas DataDome, pas PerimeterX. Les en-têtes de réponse le confirment : server: cloudflare, cf-ray, et le cookie de gestion des bots __cf_bm. Cloudflare inspecte votre empreinte TLS (JA3/JA4), l’ordre des en-têtes HTTP/2, les schémas de requête et les signaux de comportement du navigateur. Si l’un de ces éléments paraît non humain, vous obtenez un 403, un 429, un 503, ou — le cas le plus vicieux — un 200 OK avec une page de défi Turnstile à la place des vraies données.
Faire tourner l’User-Agent et les en-têtes de requête
Un seul User-Agent statique est le moyen le plus rapide de se faire bloquer. Faites tourner une liste de chaînes récentes et réalistes. Important : les champs de version mineure de Chrome sont depuis la réduction de l’User-Agent — n’inventez pas de versions mineures non nulles, sinon les anti-bots vous repéreront.
1import random
2USER_AGENTS = [
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
4 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
5 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 "
6 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
7 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
8 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36 Edg/145.0.3800.97",
9 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0",
10 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 "
11 "(KHTML, like Gecko) Version/17.4 Safari/605.1.15",
12]
13headers = {
14 "User-Agent": random.choice(USER_AGENTS),
15 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
16 "Accept-Language": "en-US,en;q=0.9",
17 "Accept-Encoding": "gzip, deflate, br, zstd",
18 "Referer": "https://www.indeed.com/",
19 "Sec-Fetch-Dest": "document",
20 "Sec-Fetch-Mode": "navigate",
21 "Sec-Fetch-Site": "same-origin",
22}Vérifiez aussi que vos Client Hints sec-ch-ua correspondent à la version du User-Agent. Un sec-ch-ua: "Chrome";v="131" à côté d’un User-Agent affirmant Chrome 145 est un signal d’alerte immédiat.
Ajouter des délais aléatoires entre les requêtes
Des intervalles fixes sont repérés par la détection de motifs. Utilisez une variation aléatoire :
1import time, random
2# Entre chaque requête
3time.sleep(random.uniform(3, 6))
4# En cas de nouvelle tentative après blocage
5def backoff_sleep(attempt):
6 base = 4
7 sleep_time = base * (2 ** attempt) + random.uniform(0, 2)
8 time.sleep(min(sleep_time, 60))Le consensus observé sur et est de 3 à 6 secondes entre les requêtes par adresse IP, avec un plafond d’environ 100 requêtes par IP et par session avant de tourner.
Utiliser la rotation de proxies
C’est le facteur de réussite le plus déterminant. Les proxies de datacenter provenant d’AWS/GCP ont un taux de réussite d’environ 5 à 15 % sur les cibles Cloudflare Enterprise — donc pratiquement inutilisables sur Indeed. Les proxies résidentiels, combinés à un bon fingerprint TLS, montent à 80–95 % de réussite.
1PROXIES = [
2 "http://user:pass@us.residential.example:7777",
3 "http://user:pass@us.residential.example:7778",
4 "http://user:pass@us.residential.example:7779",
5]
6proxy = random.choice(PROXIES)
7response = cffi_requests.get(
8 url,
9 impersonate="chrome124",
10 headers=headers,
11 proxies={"https": proxy},
12 timeout=30,
13)Les prix des proxies résidentiels en 2026 se situent grosso modo entre , selon le fournisseur et le niveau d’engagement. Pour Indeed en particulier, commencez avec un petit pool puis montez en charge si nécessaire.
Gérer proprement les codes de statut 403, 429 et 503
Ne vous contentez pas de relancer sans réfléchir. Chaque code de statut signifie quelque chose de différent :
1def fetch_with_retry(url, proxy_pool, max_retries=5):
2 for attempt in range(max_retries):
3 proxy = random.choice(proxy_pool)
4 headers["User-Agent"] = random.choice(USER_AGENTS)
5 try:
6 r = cffi_requests.get(
7 url,
8 impersonate=random.choice(["chrome124", "chrome120", "edge101"]),
9 headers=headers,
10 proxies={"https": proxy},
11 timeout=30,
12 )
13 # Vérifier le cas vicieux « 200 avec défi »
14 if r.status_code == 200 and "cf-turnstile" not in r.text and "Just a moment" not in r.text:
15 return r
16 if r.status_code == 403:
17 print(f"403 — bloqué. Changement de proxy, tentative {attempt + 1}")
18 elif r.status_code == 429:
19 print(f"429 — limitation de débit. Ralentissement.")
20 elif r.status_code == 503:
21 print(f"503 — serveur surchargé ou défi JS.")
22 backoff_sleep(attempt)
23 except Exception as e:
24 print(f"Erreur de requête : \{e\}")
25 backoff_sleep(attempt)
26 raise RuntimeError(f"Échec après \{max_retries\} tentatives : \{url\}")Le cas « 200 avec défi » est le plus délicat. Vérifiez toujours le corps de la réponse pour détecter les marqueurs cf-turnstile ou Just a moment avant de considérer un 200 comme un succès.
L’alternative plus simple : laisser Thunderbit gérer l’anti-bot pour vous
Pour les personnes qui ne veulent ni construire ni maintenir des pools de proxies, la rotation d’en-têtes et l’imitation des empreintes TLS, le scraping cloud de gère automatiquement les CAPTCHA, la rotation des proxies et les protections anti-bot. Pas de configuration de proxy, pas de configuration curl_cffi, pas de bibliothèque de résolution de CAPTCHA. C’est la voie de moindre résistance quand vous avez juste besoin des données.
Pourquoi votre scraper Indeed se casse sans cesse (et comment le réparer)
Le mur 403 est la douleur aiguë. La douleur chronique, c’est la maintenance — les scrapers qui fonctionnent aujourd’hui cassent la semaine suivante, en renvoyant silencieusement des données vides ou périmées.
Comment Indeed casse vos sélecteurs
Indeed fait tourner ses noms de classes CSS de façon agressive. Le guide de Bright Data que des classes comme css-1m4cuuf et css-1rqpxry « semblent être générées aléatoirement — probablement à la compilation ». Les tests A/B font que différentes sessions voient des mises en page différentes. Et les restructurations du DOM se font sans préavis.
Le cas JobFunnel est instructif. Un contributeur a signalé : « CaptchaBuster a réussi à atténuer le captcha, et si l’extraction de la page échoue encore, c’est [à cause] de sélecteurs Beautiful Soup obsolètes. » Le scraper n’était pas bloqué — il analysait les mauvais éléments.
Stratégie : privilégier le JSON caché au parsing du DOM
Le bloc window.mosaic.providerData est resté stable au niveau du schéma depuis au moins 2023. Le chemin metaData.mosaicProviderJobCardsModel.results[] est en 2026. Les sélecteurs DOM cassent chaque mois. L’extraction JSON, elle, casse au pire une fois par an.
Stratégie : utiliser des attributs de données plutôt que les noms de classes
Quand vous devez interagir avec le DOM, ciblez les attributs fonctionnels :
| Sélecteur | Utilité |
|---|---|
[data-testid="slider_item"] | Conteneur de chaque carte d’offre |
[data-testid="job-title"] ou h2.jobTitle > a | Lien du titre de l’offre |
[data-testid="company-name"] | Nom de l’employeur |
[data-testid="text-location"] | Texte du lieu |
data-jk="<jobkey>" sur chaque carte | L’ancrage le plus stable — inchangé depuis 2019 |
Ajouter des assertions pour détecter des sélecteurs obsolètes
Ne laissez jamais votre scraper tourner silencieusement avec zéro résultat. Ajoutez une vérification après chaque récupération :
1results = parse_hidden_json(html)
2assert len(results) > 0, (
3 f"Indeed a renvoyé un ensemble de résultats vide pour start=\{start\} — "
4 "blocage possible, CAPTCHA ou dérive des sélecteurs. "
5 f"500 premiers caractères de la réponse : {html[:500]}"
6)Consignez les 500 à 2000 premiers caractères de la réponse brute en cas d’échec. Vous saurez ainsi immédiatement si vous avez reçu un défi Turnstile, une barrière de connexion ou un changement de schéma. Exécutez un test de fumée quotidien au niveau CI sur une requête fixe (par ex. q=python&l=remote) qui vérifie que les résultats ne sont pas nuls.
L’alternative IA : des scrapers qui ne cassent jamais
L’IA de Thunderbit relit la structure de la page à chaque exécution — elle ne dépend pas de sélecteurs codés en dur ni de motifs regex figés. Quand Indeed change son HTML, Thunderbit s’adapte automatiquement. Cela répond directement au fardeau de maintenance que les utilisateurs de forums citent constamment comme leur principale frustration. Si vous vous êtes déjà réveillé avec un message Slack disant « le scraper renvoie à nouveau des lignes vides », vous connaissez la valeur de ne pas avoir à le réparer.
Extraire Indeed sans écrire de Python : l’alternative sans code
Tous les guides concurrents partent du principe que vous écrirez du code Python. Mais les discussions sur les forums racontent autre chose. Les utilisateurs disent des choses comme « c’est tellement difficile avec les bugs et les erreurs constants » et certains suggèrent d’embaucher quelqu’un sur Fiverr juste pour obtenir les données. Si cela vous parle, cette section est votre porte de sortie.
Comment extraire Indeed avec Thunderbit, étape par étape
Étape 1 : installez l’ depuis le Chrome Web Store. Le démarrage est gratuit.
Étape 2 : ouvrez une page de résultats Indeed dans votre navigateur — par exemple, https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX.
Étape 3 : cliquez sur l’icône Thunderbit dans la barre d’outils du navigateur, puis cliquez sur « Suggérer des champs avec l’IA ». L’IA de Thunderbit analyse la page et détecte automatiquement des colonnes comme Titre du poste, Entreprise, Lieu, Salaire, URL de l’offre et Date de publication. Vous pouvez vérifier et ajuster les champs suggérés — supprimer les colonnes inutiles ou en ajouter de personnalisées en décrivant ce que vous voulez en langage simple.
Étape 4 : cliquez sur « Extraire ». Thunderbit récupère les données de la page et les affiche dans un tableau structuré. Vous devriez voir des lignes d’offres avec les champs configurés.
Enrichir avec l’extraction des sous-pages
Après avoir extrait la page de liste, cliquez sur « Extraire les sous-pages » pour que Thunderbit visite chaque page de détail d’offre. Il récupère les descriptions complètes, les qualifications, les avantages et les liens de candidature — sans configuration supplémentaire. C’est l’équivalent d’écrire un deuxième scraper Python pour visiter chaque URL /viewjob?jk=<jobkey>, sauf qu’ici il suffit d’un clic.
Gérer automatiquement la pagination
Thunderbit gère automatiquement la pagination par clic d’Indeed. Pas besoin de construire manuellement des URL avec offset ni d’écrire des boucles de pagination. Il clique à travers les pages et agrège les résultats.
Exporter vers vos outils préférés
Exportez les données extraites vers CSV, Excel, Google Sheets, Airtable ou Notion — . Pas besoin d’écrire du code csv.writer() ou pandas.to_csv().
Quand utiliser Python plutôt que Thunderbit
| Scénario | Meilleur outil |
|---|---|
| Pipelines de données sur mesure, automatisation planifiée via cron/Airflow | Python |
| Intégration dans une base de code plus large | Python |
| Logique d’analyse hautement personnalisée | Python |
| Recherche ponctuelle ou analyse de marché | Thunderbit |
| Les membres non techniques de l’équipe ont besoin des données | Thunderbit |
| Obtenir les données maintenant sans déboguer des 403 | Thunderbit |
| Enrichissement de sous-pages sans aucune configuration | Thunderbit |
Comparaison du temps : configuration Python + débogage anti-bot = des heures à des jours (surtout la première fois). Thunderbit = moins de 2 minutes pour les mêmes données. Je ne dis pas que Python est mauvais — je dis que cela dépend de ce dont vous avez besoin.
Le scraping d’Indeed est-il légal ? Ce qu’il faut savoir
Aucun des guides de scraping Indeed les mieux classés n’aborde la légalité, ce qui est surprenant vu la fréquence à laquelle la question « Le scraping Indeed est-il légal ? » revient sur les forums. Ceci n’est pas un avis juridique, mais voici le paysage.
Les conditions d’utilisation d’Indeed
Les CGU d’Indeed () ne contiennent pas de clause générale interdisant tout scraping. La seule interdiction explicite d’automatisation se trouve à la section A.3.5, qui bannit « l’utilisation de toute automatisation, script ou bot pour automatiser le processus Indeed Apply ». Cette interdiction vise donc de manière étroite le flux Apply, et non la consultation passive des offres publiques. Le principal outil de contrôle d’Indeed est technique — défis Cloudflare, bannissements d’IP, empreintes d’appareil — et non judiciaire.
Jurisprudence pertinente
L’affaire américaine la plus citée est hiQ Labs v. LinkedIn. La 9e Cour d’appel a que l’extraction de données publiquement accessibles « ne viole probablement pas » le CFAA (Computer Fraud and Abuse Act). Cependant, hiQ a ensuite été jugée parce que ses employés avaient créé de faux profils LinkedIn et accepté les CGU.
Plus récemment, Meta v. Bright Data (N.D. Cal., janvier 2024) a produit une décision encore plus claire. Le juge Chen a que les conditions d’utilisation de Facebook et Instagram « n’interdisent pas l’extraction de données publiques lorsque l’on est déconnecté ». Meta a volontairement abandonné les autres griefs le mois suivant.
robots.txt d’Indeed
Le d’Indeed interdit largement /jobs/ et /job/ pour l’User-agent: * par défaut, mais autorise explicitement Googlebot et Bingbot à accéder à /viewjob? — les pages de détail des offres. Les crawlers d’entraînement IA (GPTBot, CCBot, anthropic-ai) sont fortement restreints. robots.txt n’a pas de valeur juridique contraignante aux États-Unis, mais le respecter reste une bonne pratique et une preuve de bonne foi.
Bonnes pratiques pour un scraping responsable
- Ne collectez que des données accessibles publiquement — ne vous connectez jamais, ne créez jamais de faux comptes
- Respectez les limites de débit : 1 requête toutes les 3 à 6 secondes par IP, avec une faible concurrence
- Ne republiez pas les données extraites comme si elles provenaient de votre propre site d’offres
- Utilisez les données pour un usage personnel ou une recherche interne, pas pour de la revente commerciale sans autorisation
- Supprimez ou hachez les données personnelles dont vous n’avez pas besoin ; fixez une limite de conservation pour les données proches de l’identifiant personnel
- Si vous opérez à grande échelle ou dans l’UE/au Royaume-Uni, consultez un juriste — les obligations de transparence de l’article 14 du RGPD s’appliquent aux données personnelles extraites
La gamme de risque va d’une automatisation de recherche d’emploi personnelle, au niveau bas, à la revente commerciale à grande échelle des données Indeed, au niveau élevé.
Conclusion et points clés à retenir
Extraire Indeed avec Python est faisable, mais ce n’est pas un projet de week-end que l’on met en place puis qu’on oublie. La protection Cloudflare d’Indeed, les sélecteurs qui changent et les mesures anti-bot agressives signifient qu’il faut aborder le sujet avec les bons outils et les bonnes attentes.
Voici ce que je retiendrais de tout cela :
- Indeed est la source de données la plus riche sur le marché de l’emploi sur le web — 350 M de visiteurs mensuels, 130 M d’annonces — mais il se défend vigoureusement contre les scrapers.
- L’extraction du JSON caché (
window.mosaic.providerData) est l’approche Python la plus résiliente. Le schéma est stable depuis des années, alors que les sélecteurs CSS cassent chaque mois. curl_cffiavec imitation du navigateur est le client HTTP par défaut en 2026 pour les sites protégés par Cloudflare.requestsethttpxclassiques sont bloqués rien qu’à cause de l’empreinte TLS.- Utilisez toujours des en-têtes rotatifs, des délais aléatoires et des proxies résidentiels pour éviter les erreurs 403. Les proxies de datacenter sont presque inutiles face à Cloudflare Enterprise.
- Ajoutez des vérifications par assertion pour savoir immédiatement quand les sélecteurs cassent ou quand vous recevez une page de défi au lieu des données d’offres.
- Pour les utilisateurs non techniques, ou pour toute personne qui veut simplement des résultats rapidement, offre une voie sans code, alimentée par l’IA, qui s’adapte automatiquement aux changements du site — pas de proxy, pas de débogage, pas de maintenance.
Si vous voulez essayer la voie sans code, afin que vous puissiez le tester sur Indeed sans engagement. Et si vous partez sur la voie Python, les exemples de code ci-dessus constituent un bon point de départ — n’oubliez pas de traiter la robustesse anti-bot comme une exigence de première classe, et non comme une réflexion après coup.
Pour en savoir plus sur les approches et outils de web scraping, consultez nos guides sur , et . Vous pouvez aussi regarder des tutoriels sur la .
FAQ
Quelles bibliothèques Python sont les meilleures pour extraire Indeed ?
Pour les requêtes HTTP, curl_cffi est le meilleur choix en 2026 — il imite les empreintes TLS réelles d’un navigateur, ce qui est essentiel pour contourner Cloudflare. httpx avec HTTP/2 constitue une bonne solution de repli pour des cibles moins protégées. Pour l’analyse HTML, BeautifulSoup4 avec lxml reste la norme. Pour l’automatisation navigateur, Playwright (avec playwright-stealth) ou undetected-chromedriver fonctionnent, même si les deux sont de plus en plus détectables. L’approche regex sur le JSON caché (window.mosaic.providerData) évite complètement les gros travaux d’analyse.
Pourquoi est-ce que je reçois sans cesse des erreurs 403 en extrayant Indeed ?
Indeed utilise Cloudflare Bot Management, qui inspecte votre empreinte TLS (JA3/JA4), l’ordre des en-têtes HTTP/2, les schémas de requête et le comportement du navigateur. Si vous utilisez requests seul, votre empreinte TLS vous identifie immédiatement comme un script Python — le 403 tombe avant même que vos en-têtes ne soient lus. Corrigez cela en passant à curl_cffi avec imitation du navigateur, en faisant tourner des User-Agents réalistes, en ajoutant des délais aléatoires (3 à 6 secondes) et en utilisant des proxies résidentiels. Vérifiez aussi le cas du « 200 avec défi Turnstile » — recherchez les marqueurs cf-turnstile dans le corps des réponses.
Puis-je extraire Indeed sans coder ?
Oui. Des outils comme vous permettent d’extraire des offres Indeed en quelques clics — installez l’extension Chrome, ouvrez une page de recherche Indeed, cliquez sur « Suggérer des champs avec l’IA », puis sur « Extraire ». L’IA de Thunderbit détecte automatiquement les champs comme le titre du poste, l’entreprise, le lieu et le salaire. Elle gère automatiquement la pagination, l’enrichissement des sous-pages (descriptions complètes) et les protections anti-bot. Exportez gratuitement vers CSV, Google Sheets, Airtable ou Notion.
À quelle fréquence Indeed modifie-t-il sa structure HTML ?
Indeed fait régulièrement tourner ses noms de classes CSS (par ex. css-1m4cuuf, chaînes hachées aléatoirement) et remanie les éléments DOM sans préavis. Les tests A/B font que différents utilisateurs peuvent voir simultanément des mises en page différentes. L’approche JSON caché (window.mosaic.providerData) est nettement plus stable — le schéma est resté cohérent depuis au moins 2023. Quand vous devez utiliser des sélecteurs DOM, ciblez les attributs data-testid et data-jk (job key) plutôt que les classes CSS.
Est-il légal d’extraire Indeed ?
L’extraction hors connexion de pages Indeed publiques est peu susceptible d’entraîner une responsabilité au titre du CFAA aux États-Unis, d’après l’arrêt hiQ v. LinkedIn de la 9e Cour d’appel (2022) et la décision Meta v. Bright Data (2024). Les CGU d’Indeed interdisent spécifiquement l’automatisation du processus Apply, pas la consultation passive des offres publiques. Cela dit, restez toujours responsable : ne vous connectez pas, ne créez pas de faux comptes, respectez les limites de débit, ne republiez pas les données comme s’il s’agissait de votre propre site d’offres, et traitez soigneusement toute donnée personnelle (noms de recruteurs, emails) au regard du RGPD/CCPA. Pour une activité commerciale à grande échelle, consultez un avocat.
En savoir plus