

Google Shopping traite plus de 1,2 milliard de recherches produits chaque mois. C’est un volume de données énorme sur les prix, les tendances produits et les vendeurs — directement accessible dans votre navigateur, agrégé depuis des milliers de marchands.
Récupérer ces données depuis Google Shopping pour les mettre dans un tableur ? Là, ça se complique. J’ai passé pas mal de temps à tester différentes approches — des extensions no-code jusqu’aux scripts Python complets — et l’expérience va du « waouh, c’était simple » à « je débugue des CAPTCHA depuis trois jours, j’abandonne ». La plupart des guides sur le sujet partent du principe que vous êtes développeur Python, alors qu’en réalité, beaucoup de personnes qui ont besoin de données Google Shopping sont des équipes e-commerce, des analystes pricing et des marketeurs qui veulent juste les chiffres, sans écrire une ligne de code. Ce guide présente donc trois méthodes, de la plus simple à la plus technique, pour que vous puissiez choisir celle qui colle à votre niveau et au temps dont vous disposez.
Qu’est-ce que les données Google Shopping ?
Google Shopping est un moteur de recherche de produits. Tapez « casque sans fil à réduction de bruit » et Google affiche des annonces provenant de dizaines de boutiques en ligne — titres de produits, prix, vendeurs, notes, images, liens. Bref, un catalogue en direct, mis à jour en continu, de tout ce qui se vend sur Internet.
Pourquoi extraire des données Google Shopping ?
Une seule fiche produit ne vous apprend pas grand-chose. Des centaines, mises en ordre dans un tableur, font ressortir les tendances beaucoup plus clairement.
Voici les cas d’usage les plus fréquents que j’ai observés :
| Cas d’usage | Qui en profite | Ce que vous cherchez |
|---|---|---|
| Analyse des prix concurrents | Équipes e-commerce, analystes pricing | Prix des concurrents, tendances de promo, évolution des prix dans le temps |
| Détection des tendances produits | Équipes marketing, chefs de produit | Nouveaux produits, catégories en hausse, volume d’avis |
| Veille publicitaire | Responsables PPC, équipes growth | Annonces sponsorisées, vendeurs qui enchérissent, fréquence des annonces |
| Recherche de vendeurs / leads | Équipes commerciales, B2B | Marchands actifs, nouveaux vendeurs entrant dans une catégorie |
| Suivi du MAP | Brand managers | Revendeurs qui ne respectent pas les politiques de prix minimum affiché |
| Suivi des stocks et de l’assortiment | Category managers | Disponibilité des stocks, manques dans l’assortiment produits |
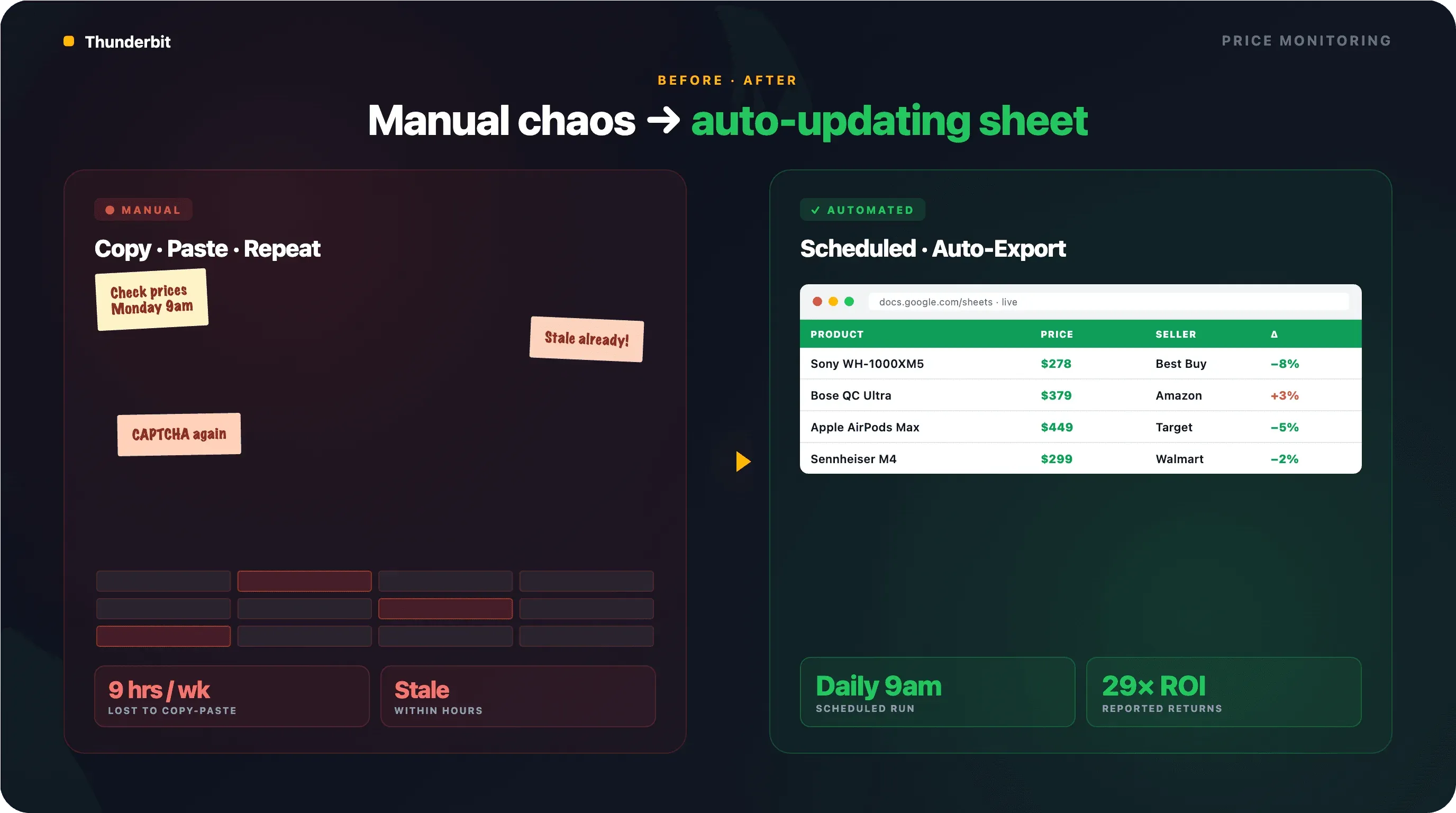
78 % des retailers américains utilisent désormais des outils de tarification alimentés par l’IA. Les entreprises qui investissent dans la veille concurrentielle sur les prix ont annoncé des retours allant jusqu’à 29x. Amazon met à jour ses prix environ toutes les 10 minutes. Si vous vérifiez encore les prix concurrents à la main, les chiffres ne jouent clairement pas en votre faveur.
Extraire des données Google Shopping avec l’IA Get Started Free
Thunderbit est une extension Chrome d’AI Web Scraper qui aide les utilisateurs métier à extraire des données de sites web grâce à l’IA. Elle est particulièrement utile pour les équipes e-commerce, les analystes prix et les marketeurs qui veulent des données Google Shopping structurées sans coder.
Quelles données peut-on réellement extraire de Google Shopping ?
Avant de choisir un outil ou d’écrire la moindre ligne de code, il est utile de savoir précisément quels champs sont disponibles — et lesquels demandent un peu plus de travail.
Champs disponibles dans les résultats de recherche Google Shopping
Lorsque vous lancez une recherche sur Google Shopping, chaque fiche produit de la page de résultats contient :
| Champ | Type | Exemple | Remarques |
|---|---|---|---|
| Titre du produit | Texte | "Sony WH-1000XM5 Wireless Headphones" | Toujours présent |
| Prix | Nombre | 278,00 $ | Peut afficher le prix remisé + le prix d’origine |
| Vendeur / boutique | Texte | "Best Buy" | Plusieurs vendeurs possibles par produit |
| Note | Nombre | 4,7 | Sur 5 étoiles ; pas toujours affichée |
| Nombre d’avis | Nombre | 12 453 | Parfois absent pour les produits récents |
| URL de l’image produit | URL | https://... | Peut renvoyer un placeholder base64 au chargement initial |
| Lien produit | URL | https://... | Renvoie vers la page produit Google ou directement vers la boutique |
| Infos de livraison | Texte | "Livraison gratuite" | Pas toujours présent |
| Mention sponsorisée | Booléen | Oui/Non | Indique un emplacement payant — utile pour la veille publicitaire |
Champs disponibles sur les pages détail produit (sous-pages)
Si vous cliquez sur la fiche détail d’un produit dans Google Shopping, vous pouvez accéder à des données plus riches :
| Champ | Type | Remarques |
|---|---|---|
| Description complète | Texte | Nécessite d’ouvrir la page produit |
| Tous les prix des vendeurs | Nombre (multiple) | Comparaison côte à côte entre plusieurs marchands |
| Spécifications | Texte | Varie selon la catégorie de produit (dimensions, poids, etc.) |
| Texte des avis individuels | Texte | Contenu complet des avis clients |
| Résumé des points forts/faibles | Texte | Google en génère parfois automatiquement |
Pour accéder à ces champs, il faut visiter chaque sous-page produit après l’extraction des résultats de recherche. Les outils dotés d’une fonction de scraping de sous-pages s’en chargent automatiquement — je vous montre le workflow plus bas.
Trois façons d’extraire des données Google Shopping (choisissez votre méthode)

Trois méthodes, classées de la plus simple à la plus technique. Choisissez celle qui correspond à votre situation et passez directement à la suite :
| Méthode | Niveau requis | Temps de mise en place | Gestion anti-bot | Idéal pour |
|---|---|---|---|---|
| Sans code (Thunderbit extension Chrome) | Débutant | ~2 minutes | Gérée automatiquement | Opérations e-commerce, marketing, recherches ponctuelles |
| Python + SERP API | Intermédiaire | ~30 minutes | Gérée par l’API | Développeurs ayant besoin d’un accès programmatique et reproductible |
| Python + Playwright (automatisation navigateur) | Avancé | ~1 heure ou plus | À gérer soi-même | Pipelines sur mesure, gestion de cas limites |
Méthode 1 : extraire des données Google Shopping sans code (avec Thunderbit)
- Difficulté : Débutant
- Temps requis : ~2 à 5 minutes
- Ce qu’il vous faut : navigateur Chrome, extension Chrome Thunderbit (la version gratuite suffit), une requête de recherche Google Shopping
Le chemin le plus rapide pour passer de « j’ai besoin des données Google Shopping » à « voici mon tableur ». Pas de code, pas de clé API, pas de configuration de proxy. J’ai accompagné des collègues non techniques des dizaines de fois sur ce workflow — personne n’est resté bloqué.
Étape 1 : installer Thunderbit et ouvrir Google Shopping
Installez Thunderbit AI Web Scraper depuis le Chrome Web Store et créez un compte gratuit.
Ensuite, allez sur Google Shopping. Vous pouvez soit accéder directement à shopping.google.com, soit utiliser l’onglet Shopping dans une recherche Google classique. Recherchez le produit ou la catégorie qui vous intéresse — par exemple, « casque sans fil à réduction de bruit ».
Vous devriez voir une grille de produits avec les prix, les vendeurs et les notes.
Étape 2 : cliquer sur « AI Suggest Fields » pour détecter automatiquement les colonnes
Cliquez sur l’icône de l’extension Thunderbit pour ouvrir la barre latérale, puis cliquez sur « AI Suggest Fields ». L’IA analyse la page Google Shopping et propose des colonnes : Titre du produit, Prix, Vendeur, Note, Nombre d’avis, URL de l’image, Lien produit.
Passez les champs suggérés en revue. Vous pouvez renommer les colonnes, supprimer celles dont vous n’avez pas besoin, ou ajouter des champs personnalisés. Si vous voulez être précis — par exemple, « extraire uniquement le prix numérique sans le symbole monétaire » — vous pouvez ajouter un invite IA de champ à cette colonne.
Vous devriez voir un aperçu de la structure des colonnes dans le panneau Thunderbit.
Étape 3 : cliquer sur « Scrape » et vérifier les résultats
Appuyez sur le bouton bleu « Scrape ». Thunderbit récupère toutes les fiches produits visibles dans un tableau structuré.
Plusieurs pages ? Thunderbit gère automatiquement la pagination — en cliquant d’une page à l’autre ou en faisant défiler pour charger davantage de résultats, selon la mise en page. Si vous avez beaucoup de résultats, vous pouvez choisir entre Cloud Scraping (plus rapide, jusqu’à 50 pages à la fois, via l’infrastructure distribuée de Thunderbit) ou Browser Scraping (utilise votre propre session Chrome — utile si Google affiche des résultats selon la région ou si une connexion est requise).
Lors de mes tests, l’extraction de 50 fiches produit a pris environ 30 secondes. La même tâche faite manuellement — ouvrir chaque fiche, copier le titre, le prix, le vendeur, la note — m’aurait pris plus de 20 minutes.
Étape 4 : enrichir les données avec le scraping de sous-pages
Après votre première extraction, cliquez sur « Scrape Subpages » dans le panneau Thunderbit. L’IA visite la page détail de chaque produit et ajoute des champs supplémentaires — description complète, tous les prix des vendeurs, spécifications et avis — au tableau d’origine.
Aucune configuration supplémentaire n’est nécessaire : l’IA comprend la structure de chaque page détail et récupère les données pertinentes. J’ai pu construire une matrice complète d’analyse concurrentielle des prix (produit + tous les prix vendeurs + spécifications) pour 40 produits en moins de 5 minutes de cette façon.
Essayez Thunderbit pour extraire Google Shopping
Étape 5 : exporter vers Google Sheets, Excel, Airtable ou Notion
Cliquez sur « Export » et choisissez votre destination — Google Sheets, Excel, Airtable ou Notion. C’est gratuit. Les exports CSV et JSON sont aussi disponibles.
Deux clics pour extraire, un clic pour exporter. L’équivalent en Python ? Environ 60 lignes de code, de la configuration de proxy, la gestion des CAPTCHA et de la maintenance continue.
Méthode 2 : extraire des données Google Shopping avec Python + une SERP API
- Difficulté : Intermédiaire
- Temps requis : ~30 minutes
- Ce qu’il vous faut : Python 3.10+, bibliothèques
requestsetpandas, une clé SERP API (ScraperAPI, SerpApi ou équivalent)
Si vous avez besoin d’un accès programmatique et reproductible aux données Google Shopping, une SERP API est l’approche Python la plus fiable. Mesures anti-bot, rendu JavaScript, rotation de proxies — tout cela est géré en arrière-plan. Vous envoyez une requête HTTP, vous récupérez du JSON structuré.
Étape 1 : configurer votre environnement Python
Installez Python 3.12 (le choix le plus sûr en production pour 2025–2026) et les packages nécessaires :
pip install requests pandas
Créez un compte chez un fournisseur de SERP API. SerpApi propose 100 recherches gratuites par mois ; ScraperAPI offre 5 000 crédits gratuits. Récupérez votre clé API dans le tableau de bord.
Étape 2 : configurer votre requête API
Voici un exemple minimal avec l’endpoint Google Shopping de ScraperAPI :
import requests
import pandas as pd
API_KEY = "YOUR_API_KEY"
query = "wireless noise cancelling headphones"
resp = requests.get(
"https://api.scraperapi.com/structured/google/shopping",
params={"api_key": API_KEY, "query": query, "country_code": "us"}
)
data = resp.json()
L’API renvoie un JSON structuré avec des champs comme title, price, link, thumbnail, source (vendeur) et rating.
Étape 3 : analyser la réponse JSON et extraire les champs
products = data.get("shopping_results", [])
rows = []
for p in products:
rows.append({
"title": p.get("title"),
"price": p.get("price"),
"seller": p.get("source"),
"rating": p.get("rating"),
"reviews": p.get("reviews"),
"link": p.get("link"),
"thumbnail": p.get("thumbnail"),
})
df = pd.DataFrame(rows)
Étape 4 : exporter en CSV ou JSON
df.to_csv("google_shopping_results.csv", index=False)
Adapté aux traitements par lots : bouclez sur 50 mots-clés et construisez un dataset complet en une seule exécution du script. Le compromis, c’est le coût — les SERP APIs facturent à la requête, et à partir de milliers de requêtes par jour, la facture grimpe vite. J’y reviens plus bas.
Méthode 3 : extraire des données Google Shopping avec Python + Playwright (automatisation navigateur)
- Difficulté : Avancé
- Temps requis : ~1 heure ou plus (plus la maintenance continue)
- Ce qu’il vous faut : Python 3.10+, Playwright, proxies résidentiels, de la patience
L’approche « contrôle total ». Vous lancez un vrai navigateur, vous allez sur Google Shopping, et vous extrayez les données de la page rendue. C’est la plus flexible, mais aussi la plus fragile — les systèmes anti-bot de Google sont agressifs, et la structure de la page change plusieurs fois par an.
Avertissement honnête : j’ai parlé à des utilisateurs qui ont passé des semaines à lutter contre les CAPTCHA et les blocages IP avec cette méthode. Ça fonctionne, mais il faut accepter une maintenance régulière.
Étape 1 : installer Playwright et les proxies
pip install playwright
playwright install chromium
Vous aurez besoin de proxies résidentiels. Les IP de datacenter sont bloquées presque immédiatement — un utilisateur de forum l’a dit sans détour : « Toutes les IP AWS seront bloquées ou déclencheront un CAPTCHA après 1/2 résultats. » Des services comme Bright Data, Oxylabs ou Decodo proposent des pools de proxies résidentiels à partir d’environ 1 à 5 $/GB.
Configurez Playwright avec un user-agent crédible et votre proxy :
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(
headless=True,
proxy={"server": "http://your-proxy:port", "username": "user", "password": "pass"}
)
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ..."
)
page = context.new_page()
Étape 2 : accéder à Google Shopping et gérer les protections anti-bot
Construisez l’URL Google Shopping et ouvrez-la :
query = "wireless noise cancelling headphones"
url = f"https://www.google.com/search?udm=28&q={query}&gl=us&hl=en"
page.goto(url, wait_until="networkidle")
Gérez la fenêtre de consentement cookies de l’UE si elle apparaît :
try:
page.click("button#L2AGLb", timeout=3000)
except:
pass
Ajoutez des délais réalistes entre les actions — 2 à 5 secondes d’attente aléatoire entre les chargements de page. Les systèmes de détection de Google repèrent les schémas de requêtes trop rapides et trop réguliers.
Étape 3 : faire défiler, paginer et extraire les données produits
Google Shopping charge les résultats de manière dynamique. Faites défiler pour déclencher le chargement progressif, puis récupérez les fiches produit :
import time, random
# Faire défiler pour charger tous les résultats
for _ in range(3):
page.evaluate("window.scrollBy(0, 1000)")
time.sleep(random.uniform(1.5, 3.0))
# Extraire les fiches produit
cards = page.query_selector_all("[jsname='ZvZkAe']")
results = []
for card in cards:
title = card.query_selector("h3")
price = card.query_selector("span.a8Pemb")
# ... extraire les autres champs
results.append({
"title": title.inner_text() if title else None,
"price": price.inner_text() if price else None,
})
Point crucial : les sélecteurs CSS ci-dessus sont approximatifs et changeront. Google fait souvent tourner les noms de classes. Trois ensembles de sélecteurs différents ont été documentés rien qu’entre 2024 et 2026. Appuyez-vous plutôt sur des attributs plus stables comme jsname, data-cid, les balises <h3> et img[alt] que sur les noms de classes.
Étape 4 : enregistrer en CSV ou JSON
import json
from datetime import datetime
filename = f"shopping_{datetime.now().strftime('%Y%m%d_%H%M')}.json"
with open(filename, "w") as f:
json.dump(results, f, indent=2)
Prévoyez de maintenir ce script régulièrement. Quand Google modifie la structure de la page — ce qui arrive plusieurs fois par an — vos sélecteurs cassent et vous repartez dans le débogage.
Le plus gros casse-tête : les CAPTCHA et les blocages anti-bot
Forum après forum, la même histoire revient : « J’ai passé quelques semaines, puis j’ai abandonné face aux méthodes anti-bot de Google. » Les CAPTCHA et les blocages IP sont la première raison pour laquelle les gens abandonnent les scrapers Google Shopping faits maison.
Comment Google bloque les scrapers (et quoi faire)
| Défi anti-bot | Ce que fait Google | Contournement |
|---|---|---|
| Empreinte IP | Bloque les IP de datacenter après quelques requêtes | Proxies résidentiels ou scraping via navigateur |
| CAPTCHA | Déclenché par des schémas de requêtes rapides ou automatisés | Limitation du rythme (10–20 s entre les requêtes), délais aléatoires, services de résolution de CAPTCHA |
| Rendu JavaScript | Les résultats Shopping se chargent dynamiquement via JS | Navigateur headless (Playwright) ou API qui rend le JS |
| Détection du user-agent | Bloque les user-agents de bots courants | Rotation de chaînes user-agent réalistes et à jour |
| Empreinte TLS | Détecte des signatures TLS non navigatrices | Utiliser curl_cffi avec imitation de navigateur ou un vrai navigateur |
| Blocage des IP AWS/cloud | Bloque les plages IP connues des fournisseurs cloud | Éviter totalement les IP de datacenter |
En janvier 2025, Google a rendu l’exécution JavaScript obligatoire pour les résultats SERP et Shopping, brisant de nombreux scrapers HTML statiques — y compris des pipelines utilisés par SemRush et SimilarWeb. Puis, en septembre 2025, Google a abandonné les anciennes URLs des pages détail produit, les redirigeant vers une nouvelle surface « Immersive Product » chargée via AJAX asynchrone. Tout tutoriel écrit avant fin 2025 est désormais en grande partie obsolète.
Comment chaque méthode gère ces difficultés
Les SERP APIs gèrent tout en arrière-plan — proxies, rendu, résolution des CAPTCHA. Vous n’avez pas à y penser.
Thunderbit Cloud Scraping s’appuie sur une infrastructure cloud distribuée entre les États-Unis, l’UE et l’Asie pour gérer automatiquement le rendu JavaScript et les mesures anti-bot. Le mode Browser Scraping utilise votre propre session Chrome authentifiée, ce qui contourne complètement la détection, car cela ressemble à un utilisateur normal.
Le Playwright maison vous laisse toute la charge — gestion des proxies, réglage des délais, résolution des CAPTCHA, maintenance des sélecteurs et surveillance constante des ruptures.
Le vrai coût pour extraire des données Google Shopping : comparaison honnête
« 50 $ pour environ 20 000 requêtes… c’est un peu cher pour mon projet hobby. » Ce type de remarque revient tout le temps dans les forums. Mais la discussion oublie souvent le coût le plus important.
Tableau comparatif des coûts
| Approche | Coût initial | Coût par requête (estim.) | Charge de maintenance | Coûts cachés |
|---|---|---|---|---|
| Python maison (sans proxy) | Gratuit | 0 $ | ÉLEVÉE (ruptures, CAPTCHA) | Votre temps de débogage |
| Python maison + proxies résidentiels | Code gratuit | ~1 à 5 $/GB | MOYENNE-ÉLEVÉE | Frais du fournisseur de proxies |
| SERP API (SerpApi, ScraperAPI) | Offre gratuite limitée | ~0,50 à 5,00 $/1 000 requêtes | FAIBLE | Coût qui grimpe vite à grande échelle |
| Extension Chrome Thunderbit | Offre gratuite (6 pages) | Basé sur des crédits, ~1 crédit/ligne | TRÈS FAIBLE | Offre payante pour les gros volumes |
| Thunderbit Open API (Extract) | Basé sur des crédits | ~20 crédits/page | FAIBLE | Paiement à l’extraction |
Le coût caché que tout le monde ignore : votre temps
Une solution maison gratuite qui vous fait perdre 40 heures en débogage n’est pas gratuite. À 50 $/heure, cela représente 2 000 $ de main-d’œuvre — pour un scraper qui pourrait recasser le mois suivant lorsque Google modifie son DOM.

L’analyse Technology Outlook de McKinsey indique que le point d’équilibre construire/acheter n’apparaît qu’au-delà de 3,6 millions de requêtes par jour. En dessous de ce seuil, développer en interne « consomme du budget sans générer de ROI ». Pour la plupart des équipes e-commerce qui effectuent quelques centaines à quelques milliers de recherches par semaine, un outil sans code ou une SERP API est nettement plus rentable qu’une solution maison.
Comment mettre en place un suivi automatisé des prix Google Shopping
La plupart des guides traitent l’extraction comme une tâche ponctuelle. Le vrai besoin des équipes e-commerce, c’est la surveillance continue et automatisée. Vous n’avez pas seulement besoin des prix d’aujourd’hui — vous avez besoin de ceux d’hier, de la semaine dernière et de demain.
Mettre en place un scraping planifié avec Thunderbit
Le Scheduled Scraper de Thunderbit vous permet de décrire l’intervalle dans un langage courant — « tous les jours à 9 h » ou « tous les lundis et jeudis à midi » — et l’IA le transforme en plan récurrent. Saisissez vos URLs Google Shopping, cliquez sur « Schedule », et c’est terminé.
Chaque exécution exporte automatiquement vers Google Sheets, Airtable ou Notion. Le résultat : un tableur qui se remplit tout seul chaque jour avec les prix concurrents, prêt pour des tableaux croisés dynamiques ou des alertes.
Pas de cron. Pas de gestion de serveur. Pas de casse-tête avec Lambda. (J’ai vu des posts de développeurs qui ont passé des jours à essayer de faire tourner Selenium sur AWS Lambda — le planificateur de Thunderbit évite tout cela.)
Pour en savoir plus sur la mise en place de workflows de suivi des prix, nous avons un guide dédié.
Planifier avec Python (pour les développeurs)
Si vous utilisez l’approche SERP API, vous pouvez planifier les exécutions avec des cron jobs (Linux/Mac), le Planificateur de tâches Windows, ou des planificateurs cloud comme AWS Lambda ou Google Cloud Functions. Des bibliothèques Python comme APScheduler fonctionnent aussi.
Le compromis : vous êtes désormais responsable de la surveillance du script, de la gestion des échecs, de la rotation des proxies selon un calendrier et de la mise à jour des sélecteurs lorsque Google change la page. Pour la plupart des équipes, le temps d’ingénierie consacré à maintenir un scraper Python planifié dépasse le coût d’un outil dédié.
Conseils et bonnes pratiques pour extraire des données Google Shopping
Quelle que soit la méthode, quelques réflexes vous éviteront bien des ennuis.
Respectez les limites de débit
N’attaquez pas Google avec des centaines de requêtes rapides — vous serez bloqué, et votre IP risque de rester signalée un moment. Méthodes maison : espacez les requêtes de 10 à 20 secondes avec un jitter aléatoire. Les outils et APIs gèrent cela pour vous.
Choisissez la méthode selon votre volume
Petit guide de décision :
- < 10 requêtes/semaine → offre gratuite Thunderbit ou offre gratuite SerpApi
- 10 à 1 000 requêtes/semaine → offre payante SERP API ou offre payante Thunderbit
- 1 000+ requêtes/semaine → plan entreprise SERP API ou Thunderbit Open API
Nettoyez et validez vos données
Les prix incluent des symboles monétaires, des formats locaux (1.299,00 € vs 1 299,00 $) et parfois des caractères parasites. Utilisez les invites IA de champ de Thunderbit pour normaliser à l’extraction, ou nettoyez ensuite avec pandas :
df["price_num"] = df["price"].str.replace(r"[^\d.]", "", regex=True).astype(float)
Vérifiez les doublons entre résultats organiques et sponsorisés — ils se recoupent souvent. Dédupliquez avec le triplet (titre, prix, vendeur).
Connaissez le cadre juridique
L’extraction de données produits publiques est généralement considérée comme légale, mais le cadre juridique évolue rapidement. L’évolution la plus importante récemment : Google a poursuivi SerpApi en décembre 2025 au titre du DMCA § 1201 pour contournement du système anti-scraping « SearchGuard » de Google. Il s’agit d’un nouvel axe d’application qui contourne les défenses établies dans des affaires antérieures comme hiQ v. LinkedIn et Van Buren v. United States.
Quelques règles pratiques :
- N’extrayez que des données publiques — ne vous connectez pas pour accéder à du contenu restreint
- N’extrayez pas d’informations personnelles (noms des auteurs d’avis, détails de compte)
- Gardez à l’esprit que les conditions d’utilisation de Google interdisent l’accès automatisé — utiliser une SERP API ou une extension navigateur réduit les zones grises juridiques, sans les supprimer complètement
- Pour des opérations dans l’UE, gardez le RGPD à l’esprit, même si les fiches produits relèvent majoritairement de données commerciales non personnelles
- Pensez à consulter un juriste si vous construisez un produit commercial à partir de données extraites
Pour aller plus loin sur les aspects juridiques du web scraping, nous avons traité le sujet séparément.
Quelle méthode utiliser pour extraire des données Google Shopping ?
Après avoir testé les trois approches sur les mêmes catégories de produits, voici mon verdict :
Si vous êtes un utilisateur non technique et que vous avez besoin des données rapidement — utilisez Thunderbit. Ouvrez Google Shopping, cliquez deux fois, exportez. Vous aurez un tableur propre en moins de 5 minutes. L’offre gratuite vous permet de tester sans engagement, et la fonction de scraping de sous-pages vous donne des données plus riches que la plupart des scripts Python.
Si vous êtes développeur et que vous avez besoin d’un accès reproductible et programmatique — utilisez une SERP API. La fiabilité compense largement le coût par requête, et vous évitez tous les problèmes anti-bot. SerpApi a la meilleure documentation ; ScraperAPI a l’offre gratuite la plus généreuse.
Si vous voulez un contrôle maximal et que vous construisez un pipeline sur mesure — Playwright fonctionne, mais il faut y aller en connaissance de cause. Prévoyez beaucoup de temps pour la gestion des proxies, la maintenance des sélecteurs et la résolution des CAPTCHA. En 2025–2026, la pile minimale viable de contournement est curl_cffi avec imitation de Chrome + proxies résidentiels + rythme de 10 à 20 secondes. Un simple script requests avec rotation de user-agents est mort.
La meilleure méthode est celle qui vous donne des données fiables sans vous voler votre semaine. Pour la plupart des gens, ce n’est pas un script Python de 60 lignes — ce sont deux clics.
Consultez les tarifs de Thunderbit si vous avez besoin de volume, ou regardez nos tutoriels sur la chaîne YouTube Thunderbit pour voir le workflow en action.
Essayez Thunderbit pour extraire Google Shopping Get Started Free
FAQ
Est-il légal d’extraire des données Google Shopping ?
L’extraction de données produits publiques est généralement légale selon des précédents comme hiQ v. LinkedIn et Van Buren v. United States. Cependant, les conditions d’utilisation de Google interdisent l’accès automatisé, et la plainte déposée par Google contre SerpApi en décembre 2025 a introduit une nouvelle théorie de contournement au titre du DMCA § 1201. Utiliser des outils et APIs reconnus réduit les risques. Pour un usage commercial, demandez conseil à un juriste.
Peut-on extraire Google Shopping sans se faire bloquer ?
Oui, mais la méthode compte. Les SERP APIs gèrent automatiquement les protections anti-bot. Le Cloud Scraping de Thunderbit utilise une infrastructure distribuée pour éviter les blocages, tandis que le mode Browser Scraping utilise votre propre session Chrome (ce qui ressemble à une navigation normale). Les scripts Python maison nécessitent des proxies résidentiels, des délais réalistes et la gestion de l’empreinte TLS — et même dans ce cas, les blocages restent fréquents.
Quelle est la méthode la plus simple pour extraire des données Google Shopping ?
L’extension Chrome de Thunderbit. Allez sur Google Shopping, cliquez sur « AI Suggest Fields », cliquez sur « Scrape », puis exportez vers Google Sheets ou Excel. Pas de code, pas de clé API, pas de configuration de proxy. Tout le processus prend environ 2 minutes.
À quelle fréquence peut-on extraire Google Shopping pour surveiller les prix ?
Avec le Scheduled Scraper de Thunderbit, vous pouvez mettre en place un suivi quotidien, hebdomadaire ou à intervalle personnalisé en décrivant simplement la fréquence en langage courant. Avec les SERP APIs, la fréquence dépend des limites de crédits de votre formule — la plupart des fournisseurs permettent un suivi quotidien de quelques centaines de références. Les scripts maison peuvent tourner aussi souvent que votre infrastructure le permet, mais plus la fréquence augmente, plus les problèmes anti-bot s’intensifient.
Peut-on exporter les données Google Shopping vers Google Sheets ou Excel ?
Oui. Thunderbit exporte directement vers Google Sheets, Excel, Airtable et Notion gratuitement. Les scripts Python peuvent exporter en CSV ou JSON, que vous pouvez ensuite importer dans n’importe quel tableur. Pour un suivi continu, les exports programmés de Thunderbit vers Google Sheets créent un jeu de données vivant, mis à jour automatiquement.
- En savoir plus




