Les données, c’est de l’or, et elles survivent bien plus longtemps que les systèmes qui les hébergent.
- , pionnier du web et créateur du World Wide Web
Chaque jour, Google gère de recherches : ce n’est pas juste pour répondre à des questions du quotidien, c’est surtout une source inépuisable d’informations — tendances du marché, mouvements des concurrents, données sur les consommateurs. Que tu sois commercial, spécialiste ou marketeur, tu peux exploiter ces données pour bâtir des stratégies vraiment efficaces.
Si tu utilises encore le copier-coller pour récupérer ces infos, il est temps de passer à la vitesse supérieure.
Dans cet article, on va t’expliquer ce qu’est une page de résultats Google (SERP), quelles données tu peux y trouver, et surtout te montrer trois façons d’extraire ces infos, dont la plus simple : l’extracteur Web IA sans code .
C’est quoi une page de résultats Google (SERP) ?
La (Search Engine Results Page) s’affiche dès que tu tapes une requête sur un moteur de recherche comme , ou . C’est le point de départ de toute navigation web, la porte d’entrée avant de cliquer sur un lien.
Ce qui rend la SERP unique, c’est qu’elle évolue en temps réel : les algorithmes, les fonctionnalités, les tendances de recherche et les contenus changent sans cesse, ce qui fait varier les résultats. En plus, Google personnalise les résultats selon ton historique et ta localisation : deux personnes peuvent donc voir des SERP différentes au même moment. Pas évident d’extraire ces données efficacement quand on n’est pas expert technique.
Avec plus de de parts de marché, comprendre la SERP Google et savoir l’exploiter, c’est devenu incontournable pour toute boîte.
Quelles infos trouve-t-on sur une SERP Google ?
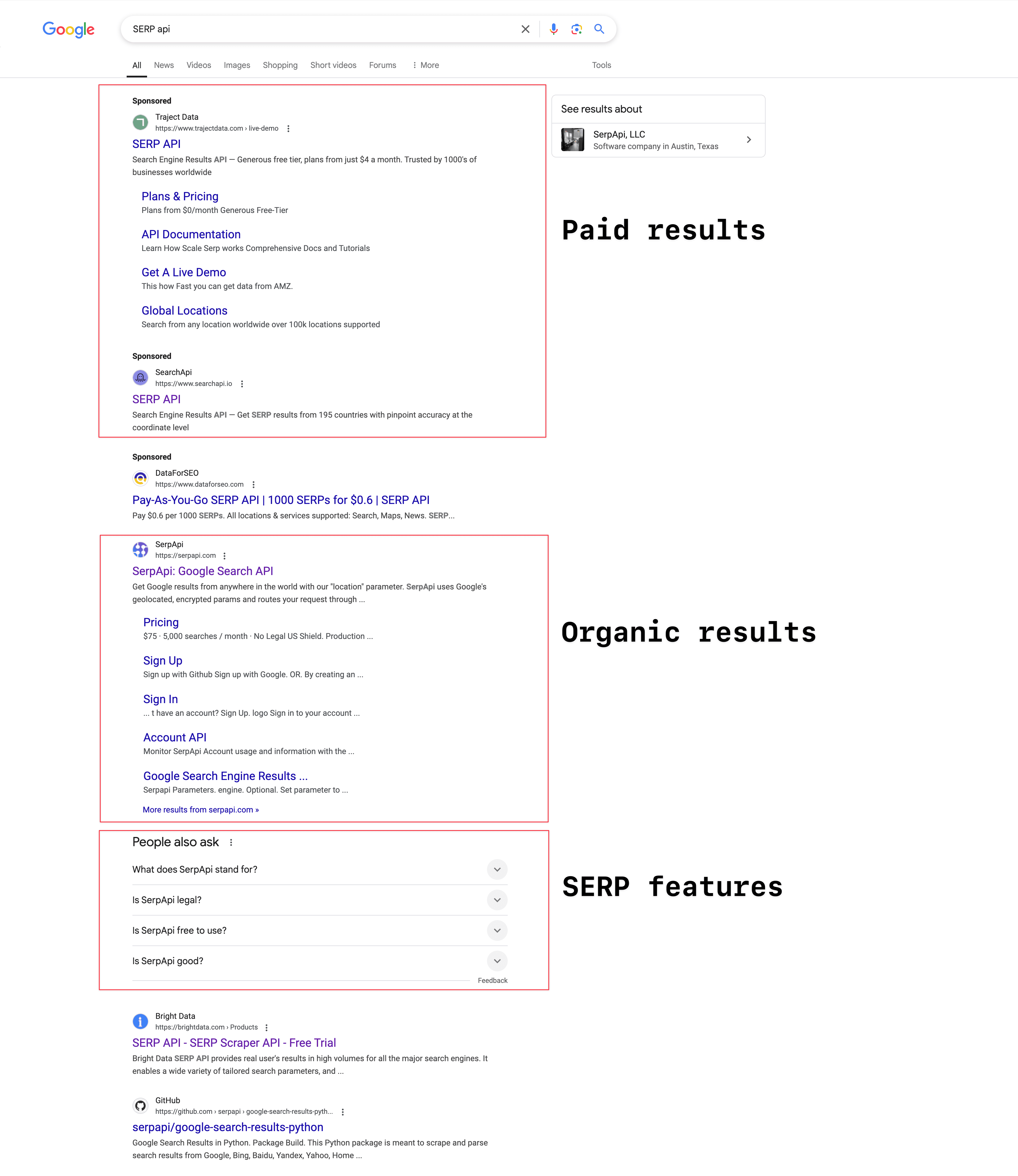
Structure d’une SERP Google
La structure de la SERP varie selon la recherche, mais en général, elle se divise en trois grandes zones :
-
Résultats sponsorisés : Ce sont les pubs, signalées par « Annonce » ou « Sponsorisé ». Les sites paient Google pour être placés en haut ou en bas des résultats naturels. Toutes les SERP n’en affichent pas, ça dépend de la requête. En 2023, Google a généré 264,59 milliards de dollars de revenus publicitaires d’après .
-
Résultats organiques : Ce sont les résultats naturels, classés selon leur pertinence. Chaque résultat affiche un titre, une méta-description et une URL.
-
Fonctionnalités SERP : Google enrichit la SERP avec plein d’éléments pour améliorer l’expérience utilisateur, et ces fonctionnalités changent tout le temps. On retrouve par exemple les extraits optimisés, les aperçus IA, les « Autres questions posées » (PAA), les panneaux de connaissance, les packs locaux (pour les recherches géolocalisées), des vidéos, images ou résultats shopping.
Types de données
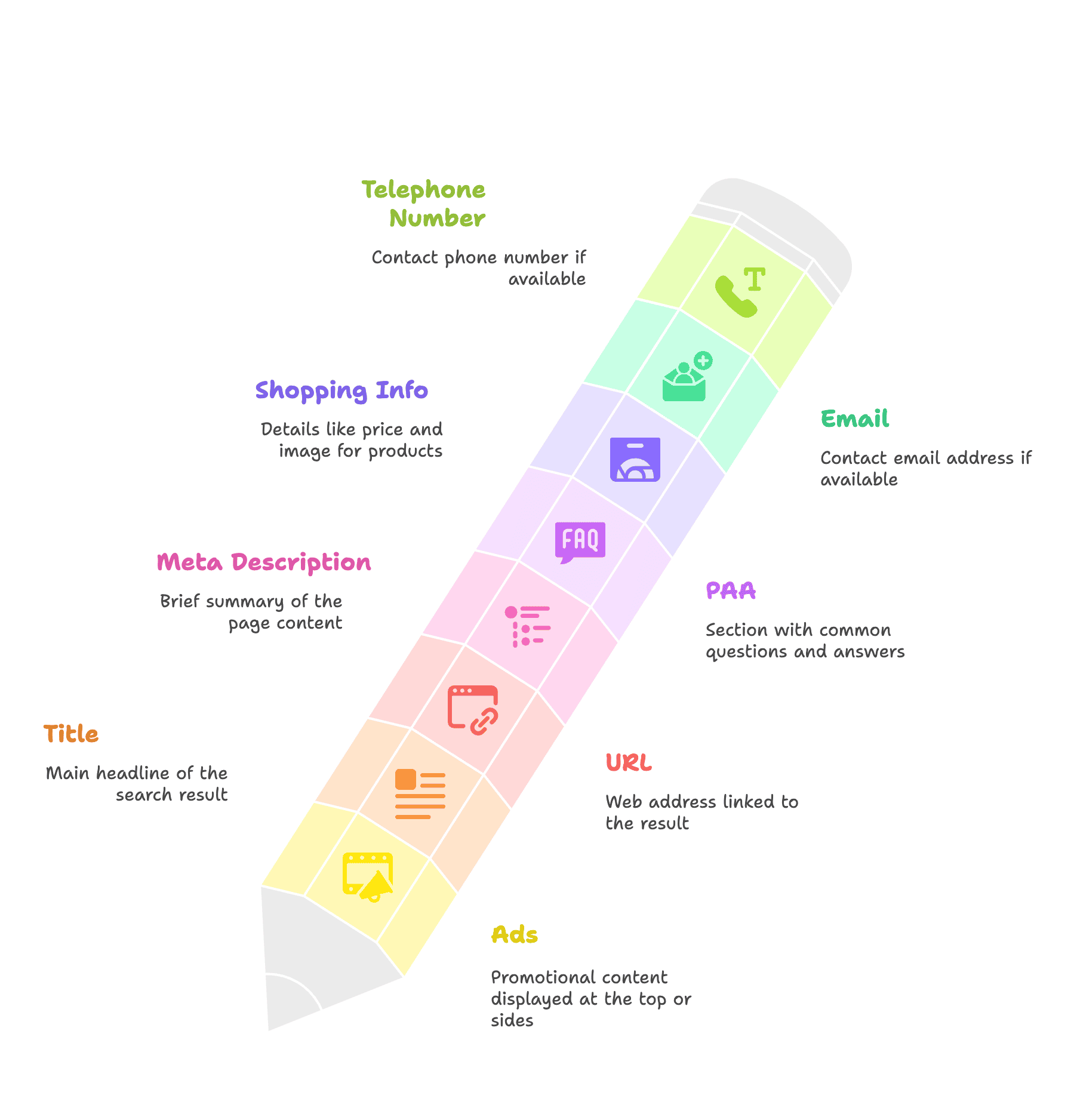
Comprendre la structure de la SERP, c’est savoir quelles infos tu peux extraire, comme :
- Annonces
- Titre
- URL
- Méta-description
- Boîte PAA
- Infos shopping : prix, image
- Numéro de téléphone
À quoi servent les données SERP ?
Commercial / Prospection
Avec des requêtes bien ciblées, les équipes commerciales peuvent générer des leads et repérer des opportunités que d’autres ratent. Google permet de trouver des contacts potentiels sur les réseaux sociaux, y compris des emails et numéros de téléphone. On t’explique plus bas comment extraire des leads Instagram à partir de la SERP.
Études de marché
Pour les marketeurs, les résultats SERP sont une vraie mine d’or. Par exemple, pour surveiller la concurrence, tu peux extraire les annonces et infos produits des concurrents et ajuster ta propre stratégie publicitaire.
La SERP est aussi un super indicateur de tendances. L’analyse des mots-clés permet de repérer de nouvelles opportunités. Si tu vois un pic soudain sur un mot-clé, c’est peut-être un marché qui décolle. Par exemple, si tu tiens une boutique de fringues et que « mode éthique » explose, c’est sûrement le moment d’ajouter des produits dans ce style.
Analyse SEO
La SERP, c’est la base du boulot des pros du SEO. En étudiant les données, ils peuvent affiner leur stratégie de mots-clés et optimiser le contenu pour grimper dans les résultats.
Prenons les PAA : en extrayant ces questions et en suivant leur évolution, tu peux anticiper les sujets qui intéressent les internautes et adapter ton contenu.
Analyse de contenu
Pour les journalistes, extraire les résultats Google Actualités permet de repérer les tendances et les sujets qui buzzent, pour orienter la rédaction. On a d’ailleurs un guide complet pour extraire des articles avec un extracteur web.
Comment extraire les résultats de recherche Google ?
Tu as compris l’intérêt des données SERP, mais comment les récupérer ?
Le copier-coller manuel, c’est possible, mais dès que tu veux du volume, ça devient vite ingérable. Heureusement, avec l’IA, il existe aujourd’hui des extracteurs web capables de collecter des données à grande échelle. Voici trois méthodes automatisées :
Utiliser Thunderbit, l’Extracteur Web IA
est un extracteur Web IA sans code qui te permet d’extraire n’importe quelle donnée d’un site. Tu peux utiliser nos ou personnaliser les colonnes selon tes besoins. Prenons un exemple concret de prospection commerciale, Génération de leads, et voyons comment trouver des prospects qualifiés avec Thunderbit.
-
Étape 1 : Ajoute Thunderbit comme extension Chrome et connecte-toi avec ton compte Google ou une adresse email.
-
Étape 2 : Tape ta requête de recherche.
Pour affiner tes résultats, les sont super pratiques.
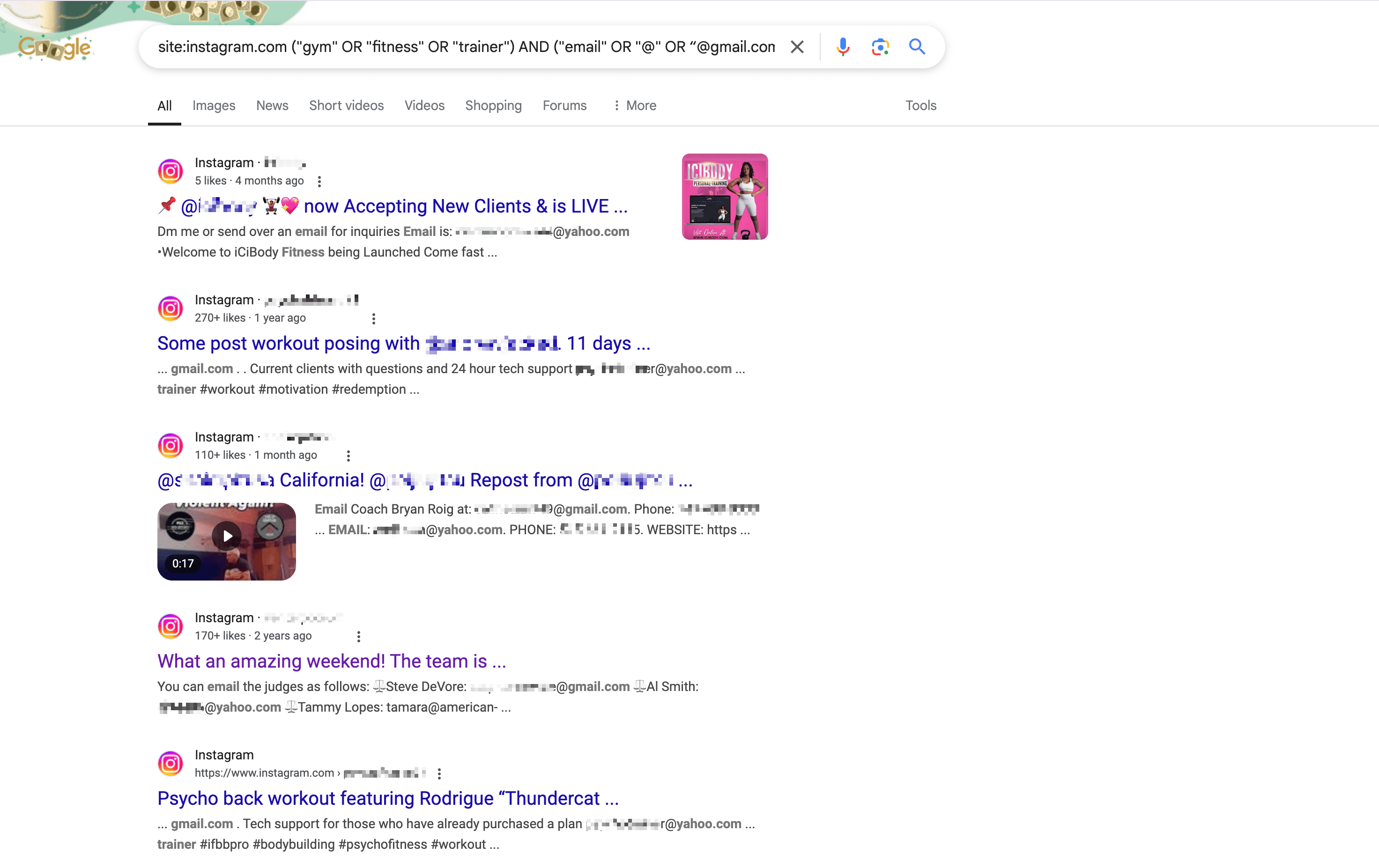
Par exemple, voici une requête générée par pour trouver les emails de personnes liées aux salles de sport à Los Angeles sur Instagram :
1site:instagram.com ("gym" OR "fitness" OR "trainer") AND ("email" OR "@" OR “@gmail.com“ or ”@yahoo.com“ ) AND ("Los Angeles" OR "LA" OR "California")Tape cette requête sur Google et valide : tu verras alors toutes les infos recherchées dans les résultats affichés.
-
Étape 3 : Lance Thunderbit et démarre l’extraction
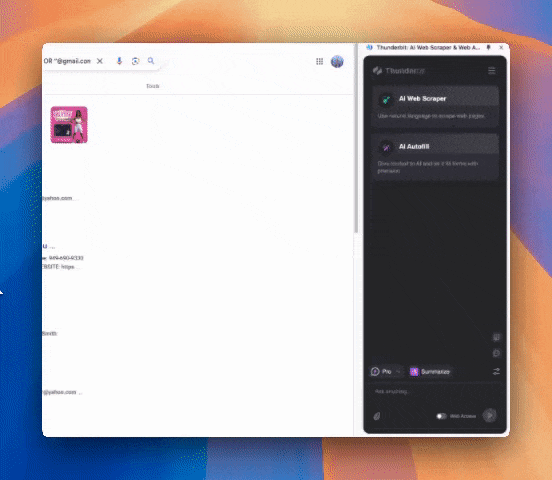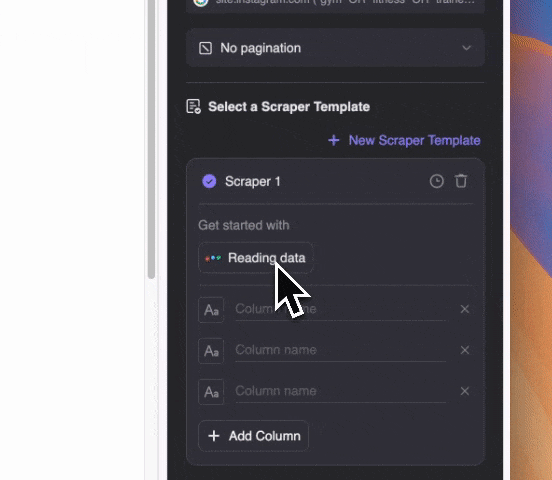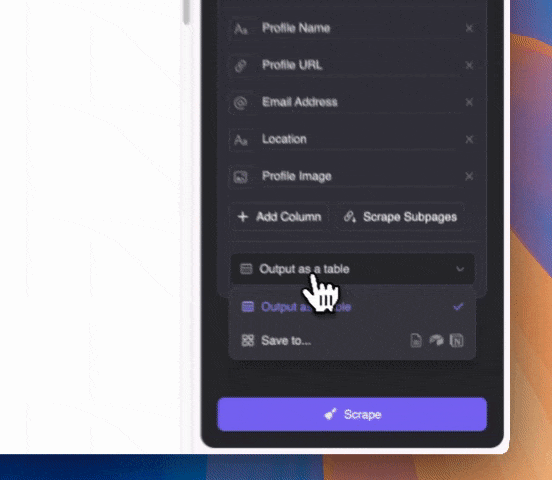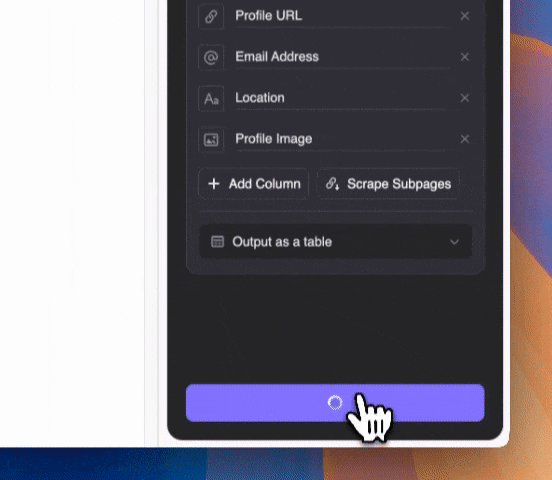 Décris en langage courant les types de contenus à extraire (tu peux aussi cliquer sur « Ajouter une instruction détaillée » pour plus de précision). Choisis d’exporter sous forme de tableau ou directement vers Notion, Airtable ou Google Sheets.
Décris en langage courant les types de contenus à extraire (tu peux aussi cliquer sur « Ajouter une instruction détaillée » pour plus de précision). Choisis d’exporter sous forme de tableau ou directement vers Notion, Airtable ou Google Sheets.Thunderbit utilise l’IA pour extraire les données. Même si certains emails sont cachés dans d’autres textes sur la SERP, l’IA saura les repérer et les extraire avec précision.
Clique sur Extraire et laisse faire la magie !
Utiliser un extracteur web classique
Les extracteurs web traditionnels permettent aussi d’extraire en masse les données de la SERP Google. Voici comment faire avec WebScraper.io :
- Installe l’extension Web Scraper et ouvre les outils développeur Chrome.
- Clique sur « Créer un nouveau sitemap » et indique l’URL de départ (la page de résultats Google).
- Configure les sélecteurs pour cibler les données à extraire.
| Nom du sélecteur | Type | Sélecteur | Multiple ? |
|---|---|---|---|
| nom | Texte | sélectionner le nom de l’utilisateur | Non ❌ |
| profil | Texte | sélectionner la méta-description sur cette page | Non ❌ |
-
Lance l’extracteur et exporte les données.
-
Après avoir extrait les bios, il faudra encore extraire les emails dans Excel avec une formule regex :
1text=REGEXEXTRACT(A2,"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}")(en supposant que la cellule A2 contient le texte du profil)
Cette formule te permettra d’isoler toutes les adresses email recherchées.
Le souci avec cette méthode : il faut comprendre la structure des pages web, et si le site change (ce qui arrive souvent), il faudra reconfigurer les sélecteurs.
Utiliser l’API officielle Google ou des API SERP tierces
Google propose une API officielle, la , qui permet d’accéder aux résultats de recherche de façon automatisée. Il faut créer et configurer un , obtenir une clé API, puis utiliser la bibliothèque requests de Python pour interroger l’API. Mais les données accessibles sont limitées et la personnalisation reste restreinte.
Autre option : utiliser des API d’extracteurs SERP tierces (comme Zen SERP, SerpApi, ScrapingBee). Là aussi, il faut un peu de technique et du code pour récupérer les profils Instagram et extraire les emails depuis la bio. Cette méthode reste assez technique pour les non-développeurs.
1import requests
2from bs4 import BeautifulSoup
3import re
4# Identifiants SerpApi
5SERP_API_KEY = "your_serpapi_key"
6SEARCH_QUERY = "marketing consultant site:instagram.com"
7# Étape 1 : Récupérer les URLs de profils Instagram via SerpApi
8def get_instagram_profiles(query):
9 url = "https://serpapi.com/search"
10 params = {
11 "engine": "google",
12 "q": query,
13 "api_key": SERP_API_KEY
14 }
15 response = requests.get(url, params=params)
16 data = response.json()
17 profile_urls = []
18 for result in data.get("organic_results", []):
19 link = result.get("link")
20 if "instagram.com" in link:
21 profile_urls.append(link)
22 return profile_urls
23# Étape 2 : Extraire l’email depuis la bio Instagram
24def extract_email_from_bio(profile_url):
25 headers = {"User-Agent": "Mozilla/5.0"}
26 response = requests.get(profile_url, headers=headers)
27 if response.status_code != 200:
28 return None
29 soup = BeautifulSoup(response.text, "html.parser")
30 bio_section = soup.find("meta", attrs={"name": "description"})
31 if bio_section:
32 bio_content = bio_section.get("content", "")
33 emails = re.findall(r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}", bio_content)
34 return emails if emails else None
35 return None
36# Exemple d’utilisation
37if __name__ == "__main__":
38 profiles = get_instagram_profiles(SEARCH_QUERY)
39 print("Profils Instagram trouvés :", profiles)
40 for profile in profiles:
41 emails = extract_email_from_bio(profile)
42 if emails:
43 print(f"Emails trouvés dans \{profile\} : \{emails\}")
44 else:
45 print(f"Aucun email trouvé dans \{profile\}")Comparatif des 3 méthodes
Tu veux une solution simple et rapide, sans prise de tête technique ? → Choisis
Tu veux tout contrôler et tu maîtrises HTML/CSS ? → Prends un extracteur web classique
Tu as besoin d’accéder à des millions de données à moindre coût et tu as un expert technique sous la main ? → Oriente-toi vers une API SERP tierce
Est-ce légal d’extraire les résultats Google ?
La question revient souvent : La réponse dépend du pays, de l’usage, des conditions d’utilisation et du type de contenu extrait. Il n’y a pas de réponse universelle.
Les interdisent l’extraction automatisée de leurs services. Mais en général, . L’objectif de l’extraction (commercial ou non) compte aussi.
Pour rester dans les clous, lis bien les conditions d’utilisation, limite-toi aux données publiques et n’utilise jamais les données extraites à des fins douteuses. Pour des extractions à grande échelle, mieux vaut consulter un juriste spécialisé.
Conclusion
Les données sont « » et la SERP Google est un filon encore largement inexploité. Ceux qui sauront transformer ces données en actions concrètes auront toujours une longueur d’avance. Génération de leads, études de marché, optimisation SEO : les usages sont multiples.
Selon ton niveau technique, ton budget, le volume de données et tes besoins, on t’a présenté Thunderbit, l’extracteur Web IA nouvelle génération, les extracteurs classiques et les API SERP.
Si tu veux extraire tous les résultats en un clic, Thunderbit est clairement la solution la plus accessible — alors, qu’est-ce que tu attends ? .
FAQ
1. Quelles données puis-je extraire d’une page de résultats Google (SERP) ?
Tu peux extraire plein d’éléments : titres, URLs, méta-descriptions, annonces, extraits optimisés, infos shopping (prix, images), questions PAA, emails, numéros de téléphone, etc.
2. En quoi Thunderbit est-il différent des extracteurs web classiques ou des API SERP ?
est une extension Chrome IA sans code qui permet d’extraire des données structurées en langage courant — pas besoin de configurer des sélecteurs ou de coder. Les extracteurs classiques demandent une configuration technique, et les API imposent des limites d’accès et du développement.
3. Faut-il des compétences techniques pour utiliser Thunderbit sur Google ?
Non. Thunderbit a été pensé pour les non-techniciens. Il suffit de décrire les données recherchées en langage simple, l’IA s’occupe du reste.
4. Puis-je exporter les données extraites vers Google Sheets ou Notion ?
Oui. Thunderbit permet l’export direct vers Google Sheets, Airtable, Notion ou sous forme de tableau téléchargeable — tu peux donc exploiter tes données tout de suite.
5. Quels sont les cas d’usage concrets de l’extraction de données SERP ?
Les usages les plus courants : génération de leads, analyse concurrentielle, SEO, veille de tendances et planification de contenu. Par exemple, les commerciaux trouvent des contacts, les marketeurs analysent les annonces, et les experts SEO suivent la performance des mots-clés et des requêtes associées.