Si vous avez déjà essayé de constituer une liste de prospection ciblée, d’explorer de nouveaux marchés ou de comparer vos concurrents, vous savez à quel point Google Maps est une mine d’or. Mais voici l’élément clé : avec plus de 1,5 milliard de recherches « près de moi » chaque mois et 76 % des internautes effectuant une recherche locale visitant un commerce dans les 24 heures (), la demande de données commerciales à jour et géolocalisées n’a jamais été aussi forte.
Que vous travailliez dans la vente, le marketing ou les opérations, extraire des données structurées depuis Google Maps peut faire toute la différence entre un appel à froid et un prospect qualifié, plus chaud et plus susceptible de convertir.
J’ai passé des années dans le SaaS et l’automatisation, et j’ai vu de mes propres yeux comment des équipes utilisent Python (et désormais des outils dopés à l’IA comme ) pour transformer Google Maps en actif stratégique.
Dans ce guide, je vais vous expliquer exactement comment extraire des données Google Maps avec Python en 2026 — étape par étape, avec du code, des conseils de conformité et une comparaison avec les solutions sans code. Que vous soyez expert Python ou que vous cherchiez simplement la voie la plus rapide vers des données exploitables, vous êtes au bon endroit.
Que signifie extraire Google Maps avec Python ?
Commençons par les bases : extraire Google Maps avec Python consiste à récupérer de manière programmatique des informations sur des entreprises — comme leur nom, adresse, note, avis, numéro de téléphone et coordonnées — depuis Google Maps, afin de les analyser, les filtrer et les exporter à des fins professionnelles.

Il existe deux grandes façons de procéder :
- L’API Google Maps Places : la méthode officielle et sous licence. Vous utilisez une clé API pour interroger les serveurs de Google et obtenir des données JSON structurées. C’est stable, prévisible et (dans la plupart des cas) conforme, mais cela implique des quotas et des coûts.
- Le web scraping du HTML : vous automatisez un navigateur (avec des outils comme Playwright ou Selenium) pour charger Google Maps, effectuer des recherches et analyser la page rendue. C’est plus flexible, mais fragile — Google modifie souvent la structure de son site, et le scraping du HTML peut enfreindre ses conditions d’utilisation.
Champs de données typiques que vous pouvez extraire :
- Nom de l’entreprise
- Catégorie / type
- Adresse complète (avec ville, État, code postal, pays)
- Latitude et longitude
- Numéro de téléphone
- URL du site web
- Note et nombre d’avis
- Niveau de prix
- Statut de l’entreprise (ouverte / fermée)
- Horaires d’ouverture
- Place ID (identifiant unique de Google)
- URL Google Maps
Pourquoi est-ce important ? Parce que ces champs alimentent tout, de la génération de leads à la planification territoriale, en passant par l’analyse concurrentielle et les études de marché. L’essentiel est de cibler les bonnes données pour vos objectifs métier — ne vous contentez pas d’extraire au hasard.
Pourquoi les équipes commerciales et marketing extraient-elles des données de Google Maps avec Python ?
Entrons dans le concret. Pourquoi tant d’équipes commerciales et marketing sont-elles obsédées par les données Google Maps en 2026 ?
- Génération de leads : constituez des listes ultra-ciblées d’entreprises locales, avec coordonnées et notes, pour vos campagnes de prospection.
- Planification territoriale : cartographiez les territoires commerciaux, zones de livraison ou périmètres d’intervention selon la densité réelle d’entreprises et leurs types.
- Suivi des concurrents : suivez dans le temps les emplacements, notes et avis des concurrents pour repérer tendances et opportunités.
- Études de marché : analysez les catégories d’entreprises, horaires d’ouverture et sentiment des avis pour orienter vos stratégies go-to-market.
- Choix d’emplacement : dans l’immobilier et le retail, évaluez les emplacements potentiels selon les commodités à proximité, le trafic piéton et la concurrence.
Impact concret : selon le , 92 % des équipes commerciales prévoient d’augmenter leurs investissements dans l’IA et la donnée, et les équipes qui utilisent des données locales ciblées voient des taux de conversion jusqu’à 8 fois supérieurs à ceux qui s’appuient sur des listes froides génériques (). Une étude sur la génération de leads pour les franchises a montré 15 $ de nouveaux revenus pour chaque dollar dépensé dans des listes de leads basées sur Google Maps.
Faire correspondre vos objectifs métier aux champs Google Maps :
| Objectif métier | Champs Google Maps nécessaires |
|---|---|
| Liste de leads locaux | nom, adresse, téléphone, site web, catégorie |
| Planification territoriale | nom, lat/lng, statut d’activité, horaires d’ouverture |
| Benchmark concurrentiel | nom, note, userRatingCount, priceLevel, avis |
| Choix d’emplacement | catégorie, lat/lng, densité d’avis, openingDate |
| Analyse des avis / menu | avis, editorialSummary, photos, types |
| Prospection par email / téléphone | nationalPhoneNumber, websiteUri (puis enrichissement si nécessaire) |
Configurer votre extracteur Google Maps Python : outils et prérequis
Avant de commencer l’extraction, vous devez configurer votre environnement Python et rassembler les bons outils. Voici ce qu’il vous faut en 2026 :
1. Installer Python et les bibliothèques requises
Version Python recommandée : 3.10 ou plus récente.
Installer les bibliothèques clés :
1pip install \
2 requests==2.33.1 httpx==0.28.1 \
3 beautifulsoup4==4.14.3 lxml==6.0.3 \
4 pandas==2.3.3 \
5 selenium==4.43.0 playwright==1.58.0 \
6 googlemaps==4.10.0 google-maps-places==0.8.0 \
7 schedule==1.2.2 APScheduler==3.11.2 \
8 python-dotenv==1.2.2 tenacity==9.1.4
9playwright install chromiumÀ quoi elles servent :
requests,httpx: requêtes HTTP (appels API)beautifulsoup4,lxml: analyse HTML (pour le web scraping)pandas: nettoyage, analyse et export des donnéesselenium,playwright: automatisation du navigateur (pour le scraping HTML)googlemaps,google-maps-places: clients API Google Mapsschedule,APScheduler: planification des tâchespython-dotenv: chargement sécurisé des clés API depuis des fichiers.envtenacity: logique de réessai pour la gestion des erreurs
2. Obtenir une clé API Google Maps (pour le scraping basé sur l’API)
- Rendez-vous sur .
- Créez ou sélectionnez un projet.
- Activez la facturation (obligatoire, même pour l’offre gratuite).
- Activez « Places API (New) » dans APIs & Services > Library.
- Allez dans Credentials > Create Credentials > API Key.
- Restreignez votre clé à certaines API et IP pour plus de sécurité.
- Stockez votre clé API dans un fichier
.env(ne la validez jamais dans le code) :
1GOOGLE_MAPS_API_KEY=your_actual_api_key_hereRemarque : depuis mars 2025, Google ne propose plus de crédit universel de 200 $ par mois. À la place, vous disposez de seuils mensuels gratuits par niveau d’API (voir la ).
Comment extraire des données de Google Maps avec Python : guide étape par étape
Décortiquons les deux approches principales — basée sur l’API et basée sur le scraping HTML — afin que vous puissiez choisir celle qui correspond à vos besoins.
Approche 1 : utiliser l’API Google Maps Places (recommandé)
Étape 1 : installer et importer les bibliothèques nécessaires
1import os
2import httpx
3import pandas as pd
4from dotenv import load_dotenvÉtape 2 : charger votre clé API en toute sécurité
1load_dotenv()
2API_KEY = os.environ["GOOGLE_MAPS_API_KEY"]Étape 3 : construire votre requête de recherche
Vous utiliserez l’endpoint Text Search pour trouver les entreprises correspondant à vos critères.
1URL = "https://places.googleapis.com/v1/places:searchText"
2FIELD_MASK = ",".join([
3 "places.id", "places.displayName", "places.formattedAddress",
4 "places.location", "places.rating", "places.userRatingCount",
5 "places.priceLevel", "places.types",
6 "places.nationalPhoneNumber", "places.websiteUri",
7 "nextPageToken",
8])Étape 4 : effectuer la requête API
1def text_search(query, lat, lng, radius=3000, min_rating=4.0):
2 body = {
3 "textQuery": query,
4 "minRating": min_rating, # filtre côté serveur
5 "includedType": "restaurant",
6 "openNow": False,
7 "pageSize": 20,
8 "locationBias": {
9 "circle": {
10 "center": {"latitude": lat, "longitude": lng},
11 "radius": radius,
12 }
13 },
14 }
15 headers = {
16 "Content-Type": "application/json",
17 "X-Goog-Api-Key": API_KEY,
18 "X-Goog-FieldMask": FIELD_MASK, # définissez-le toujours !
19 }
20 r = httpx.post(URL, json=body, headers=headers, timeout=30)
21 r.raise_for_status()
22 return r.json()Étape 5 : gérer la pagination et collecter les résultats
1def collect_all_results(query, lat, lng, radius=3000, min_rating=4.0):
2 results = []
3 next_page_token = None
4 while True:
5 data = text_search(query, lat, lng, radius, min_rating)
6 places = data.get('places', [])
7 results.extend(places)
8 next_page_token = data.get('nextPageToken')
9 if not next_page_token:
10 break
11 return resultsÉtape 6 : exporter les données avec Pandas
1df = pd.DataFrame(collect_all_results("coffee shops in Brooklyn", 40.6782, -73.9442))
2df.to_csv("brooklyn_coffee_shops.csv", index=False)Conseils pratiques :
- Définissez toujours l’en-tête
X-Goog-FieldMaskpour contrôler les coûts. Si vous demandez des avis ou des photos, votre prix par 1 000 requêtes peut passer de 5 $ à 25 $ (). - Utilisez des filtres côté serveur (comme
minRating,includedType,locationBias) pour éviter de gaspiller des crédits sur des résultats hors sujet. - Mettez en cache les valeurs
place_idpour la déduplication et les mises à jour futures.
Approche 2 : extraire le HTML de Google Maps par web scraping (pour usage ponctuel / pédagogique)
Avertissement : Google Maps est une application monopage. Vous devez utiliser l’automatisation du navigateur (Playwright ou Selenium), et le scraping du HTML peut enfreindre les conditions d’utilisation de Google. Réservez cette méthode à la recherche, pas à la production.
Étape 1 : installer Playwright et lancer un navigateur
1from playwright.sync_api import sync_playwright
2import time, re
3def scrape_maps(query, max_results=100):
4 with sync_playwright() as pw:
5 browser = pw.chromium.launch(headless=True)
6 ctx = browser.new_context(
7 user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
8 locale="en-US",
9 )
10 page = ctx.new_page()
11 page.goto("https://www.google.com/maps", timeout=60_000)
12 page.fill("#searchboxinput", query)
13 page.click('button[aria-label="Search"]')
14 page.wait_for_selector('div[role="feed"]')
15 feed = page.locator('div[role="feed"]')
16 prev = 0
17 while True:
18 feed.evaluate("el => el.scrollBy(0, el.scrollHeight)")
19 time.sleep(2)
20 count = page.locator('div[role="feed"] > div > div[jsaction]').count()
21 if count == prev or count >= max_results:
22 break
23 prev = count
24 if page.locator("text=You've reached the end of the list").count():
25 break
26 rows = []
27 cards = page.locator('div[role="feed"] > div > div[jsaction]')
28 for i in range(cards.count()):
29 c = cards.nth(i)
30 name = c.locator("div.fontHeadlineSmall").inner_text() if c.locator("div.fontHeadlineSmall").count() else ""
31 rating_el = c.locator('span[role="img"]').first
32 raw = rating_el.get_attribute("aria-label") if rating_el.count() else ""
33 m = re.search(r"([\d.]+)\s+stars?\s+([\d,]+)\s+Reviews", raw or "")
34 rating = float(m.group(1)) if m else None
35 reviews = int(m.group(2).replace(",", "")) if m else None
36 rows.append({"name": name, "rating": rating, "reviews": reviews})
37 browser.close()
38 return rowsConseils :
- Google randomise les classes CSS toutes les quelques semaines, donc ce code peut nécessiter des mises à jour régulières.
- Utilisez des délais réalistes et évitez d’extraire trop vite pour réduire le risque de blocage.
- N’essayez jamais de contourner les CAPTCHA ou le système SearchGuard de Google — cela peut vous exposer à un risque juridique.
Évitez le scraping à l’aveugle : comment cibler précisément les données dont vous avez besoin
Extraire tout est la recette idéale pour perdre du temps et se retrouver avec des jeux de données trop volumineux. Voici comment cibler uniquement les données qui comptent :
- Générez des listes d’URL ciblées : utilisez les filtres de recherche de Google Maps (catégorie, localisation, note, ouvert maintenant) pour affiner les résultats avant l’extraction.
- Utilisez la recherche par expression : recherchez des types d’entreprises ou des mots-clés précis (par exemple, « boulangerie vegan à Austin »).
- Filtres de localisation : indiquez une ville, un quartier ou même des coordonnées et un rayon pour une précision maximale.
- Filtrage côté serveur (API) : utilisez
minRating,includedTypeetlocationBiasdans le corps de votre requête API. - Filtrage côté client (Python) : après extraction, utilisez pandas pour filtrer les entreprises avec une note supérieure à 4,0, plus de 50 avis ou des catégories spécifiques.
Exemple : filtrer uniquement les restaurants de Manhattan avec une note supérieure à 4,0
1df = pd.DataFrame(results)
2filtered = df[(df['rating'] >= 4.0) & (df['types'].apply(lambda x: 'restaurant' in x))]
3filtered.to_csv("manhattan_top_restaurants.csv", index=False)Utiliser des bibliothèques Python pour organiser et exporter les données Google Maps
Une fois vos données extraites, il est temps de les nettoyer, de les analyser et de les exporter pour votre équipe.
Nettoyer et structurer les données avec Pandas
1import pandas as pd
2df = pd.read_json("brooklyn_restaurants.json")
3df = (
4 df.dropna(subset=["name", "address"])
5 .drop_duplicates(subset=["place_id"])
6 .assign(
7 name=lambda d: d["name"].str.strip(),
8 phone=lambda d: d["phone"].astype(str)
9 .str.replace(r"\D", "", regex=True)
10 .str.replace(r"^1?(\d\{10\})$", r"+1\1", regex=True),
11 rating=lambda d: pd.to_numeric(d["rating"], errors="coerce"),
12 user_ratings_total=lambda d: pd.to_numeric(
13 d["user_ratings_total"], errors="coerce"
14 ).fillna(0).astype("int32"),
15 )
16)Analyser et résumer les données
Exemple : note moyenne par quartier
1by_neighborhood = (
2 df.groupby("neighborhood", as_index=False)
3 .agg(avg_rating=("rating", "mean"),
4 n_places=("place_id", "nunique"),
5 median_reviews=("user_ratings_total", "median"))
6 .sort_values("avg_rating", ascending=False)
7)Exporter vers Excel ou CSV
1df.to_csv("brooklyn_top.csv", index=False)
2df.to_excel("brooklyn_top.xlsx", index=False, sheet_name="Top Rated")Gros volumes de données ? Utilisez le format Parquet pour gagner en vitesse et en efficacité de stockage :
1df.to_parquet("brooklyn_top.parquet", compression="zstd")Thunderbit : l’alternative dopée à l’IA à l’extracteur Google Maps Python
Si vous vous dites : « Tout cela demande beaucoup de configuration pour une simple liste de leads », vous n’êtes pas seul. C’est précisément pour cela que nous avons créé — un extracteur Web sans code, propulsé par l’IA, qui rend l’extraction de données Google Maps (et bien plus encore) aussi simple que quelques clics.
Pourquoi Thunderbit ?
- Aucun code ni clé API requis : ouvrez simplement , allez sur Google Maps et cliquez sur « AI Suggest Fields ».
- Détection de champs par IA : l’IA de Thunderbit lit la page et propose automatiquement les bonnes colonnes — nom, adresse, note, téléphone, site web, etc.
- Scraping des sous-pages : vous voulez enrichir votre tableau avec les données du site web de chaque entreprise ? Thunderbit peut visiter chaque sous-page et extraire des informations supplémentaires automatiquement.
- Export vers Excel, Google Sheets, Airtable ou Notion : fini les manipulations avec pandas — cliquez sur « Export » et vos données sont prêtes pour votre équipe.
- Scraping programmé : configurez des tâches récurrentes pour surveiller les concurrents ou actualiser automatiquement votre liste de leads.
- Aucune maintenance : l’IA de Thunderbit s’adapte aux changements du site, vous n’avez donc pas à corriger en permanence des scripts cassés.
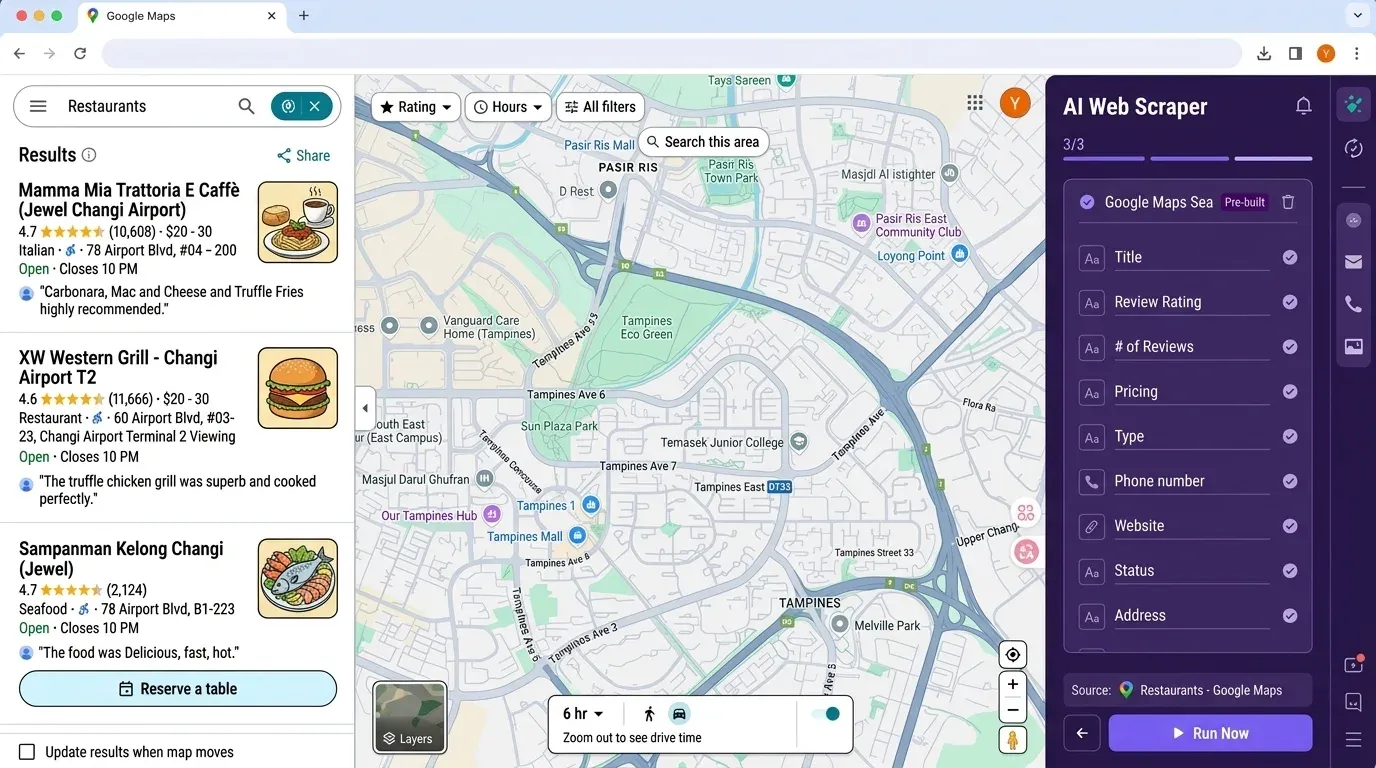
Flux de travail Thunderbit vs Python :
| Étape | Extracteur Python | Thunderbit |
|---|---|---|
| Installer les outils | 30 à 60 min (Python, pip, bibliothèques) | 2 min (extension Chrome) |
| Configurer la clé API | 10 à 30 min (Cloud Console) | Aucun besoin |
| Sélection des champs | Code manuel, masques de champs | AI Suggest Fields (1 clic) |
| Extraction des données | Écrire / exécuter des scripts, gérer les erreurs | Cliquer sur « Scrape » |
| Export | pandas vers CSV / Excel | Export vers Excel / Sheets / Notion |
| Maintenance | Mises à jour manuelles en cas de changement du site | Adaptation automatique par l’IA |
Bonus : Thunderbit est utilisé par plus de , et l’offre gratuite vous permet d’extraire jusqu’à 6 pages (ou 10 avec un bonus d’essai) sans frais.
Rester conforme : conditions d’utilisation de Google Maps et éthique du scraping
C’est là que la plupart des tutoriels Python deviennent dangereusement obsolètes. Voici ce que vous devez savoir en 2026 :
- Les CGU de Google Maps Platform §3.2.3 interdisent strictement le scraping, la mise en cache ou l’export des données en dehors des API officielles (). La seule exception : les valeurs de latitude/longitude peuvent être mises en cache pendant 30 jours maximum ; les Place ID peuvent être conservés indéfiniment.
- Les utilisateurs des API sont liés par contrat : si vous utilisez une clé API, vous avez accepté les conditions de Google — même si vous n’extrayez que des données publiques.
- Contourner les barrières techniques (CAPTCHA, SearchGuard) peut désormais constituer une violation potentielle de la section 1201 du DMCA, avec des sanctions pénales possibles ().
- RGPD et lois sur la vie privée : si vous collectez des données personnelles (emails, téléphones, noms d’avis) depuis Google Maps, vous devez disposer d’une base légale et respecter les demandes de suppression. La CNIL française a infligé une amende de 200 000 € à KASPR en 2024 pour le scraping de contacts LinkedIn ().
- Bonnes pratiques :
- privilégiez l’API Places lorsque c’est possible ;
- limitez le débit des requêtes (≤10 QPS pour l’API, 1–2 requêtes/s pour le scraping HTML) ;
- ne contournez jamais les CAPTCHA ni les blocages techniques ;
- ne redistribuez pas de données personnelles extraites ;
- respectez les demandes d’opposition et de suppression ;
- vérifiez toujours les lois locales — RGPD, CCPA et autres sont activement appliquées.
En résumé : si la conformité est une préoccupation, restez sur l’API et réduisez au minimum les données que vous collectez. Pour la plupart des utilisateurs métier, un outil sans code comme Thunderbit réduit votre exposition au risque (pas de clé API, pas de redistribution).
Planifier et automatiser l’extraction Google Maps avec Python
Si vous avez besoin de données toujours à jour — par exemple pour un suivi hebdomadaire des concurrents ou une mise à jour mensuelle de vos listes de leads — l’automatisation est votre alliée.
Planification simple avec schedule
1import schedule, time
2from my_scraper import run_job
3schedule.every().day.at("03:00").do(run_job, query="restaurants in Brooklyn")
4schedule.every(6).hours.do(run_job, query="coffee shops in Manhattan")
5while True:
6 schedule.run_pending()
7 time.sleep(30)Planification de niveau production avec APScheduler
1from apscheduler.schedulers.background import BackgroundScheduler
2from apscheduler.triggers.cron import CronTrigger
3sched = BackgroundScheduler(timezone="America/New_York")
4sched.add_job(
5 run_job,
6 CronTrigger(hour=3, minute=15, jitter=600), # 3h15 ± 10 min
7 kwargs={"query": "restaurants in Brooklyn"},
8 id="brooklyn_daily",
9 max_instances=1,
10 coalesce=True,
11 misfire_grace_time=3600,
12)
13sched.start()Conseils pour une automatisation sûre
- Ajoutez un aléa temporel à votre planification pour éviter des schémas prévisibles.
- Pour le scraping HTML, ne dépassez jamais 1 à 2 requêtes par seconde.
- Pour l’API, surveillez votre quota et configurez des alertes de facturation.
- Journalisez toujours les erreurs et conservez un fichier « dead-letter » pour les requêtes en échec.
Bonus Thunderbit : avec Thunderbit, vous pouvez programmer des extractions récurrentes directement dans l’interface — sans code, sans cron, sans configuration de serveur.
Points clés à retenir : extraire des données Google Maps de manière efficace, ciblée et conforme
Récapitulons l’essentiel :
- Google Maps est la source n°1 de données de localisation d’entreprises, alimentant tout, de la génération de leads aux études de marché.
- Le scraping avec Python offre flexibilité et contrôle, mais s’accompagne de configuration, de maintenance et de contraintes de conformité — d’autant plus que les mesures anti-bot de Google et l’application du droit se renforcent.
- L’extraction basée sur l’API est l’approche la plus sûre et la plus scalable pour la plupart des équipes. Utilisez toujours des masques de champs et des filtres côté serveur pour maîtriser les coûts.
- Le scraping HTML est fragile et risqué — réservez-le aux recherches ponctuelles et ne contournez jamais les barrières techniques.
- Ciblez vos données : utilisez la recherche par expression, les filtres de localisation et les workflows pandas pour extraire uniquement ce dont vous avez besoin.
- Thunderbit est la voie la plus rapide pour les non-développeurs : propulsé par l’IA, sans configuration, export instantané et planification intégrée.
- La conformité compte : respectez les conditions de Google, les lois sur la vie privée et les limites de débit pour éviter les ennuis juridiques.
Pour plus de tutoriels et de conseils, consultez le et notre .
FAQ
1. Est-il légal d’extraire des données Google Maps avec Python en 2026 ?
L’extraction via l’API officielle Google Maps est autorisée dans le respect des conditions de Google, à condition de respecter les quotas et de ne pas redistribuer les données restreintes. Le scraping HTML de Google Maps est explicitement interdit par les CGU de Google et comporte un risque juridique, en particulier si vous contournez des barrières techniques ou collectez des données personnelles sans consentement. Vérifiez toujours les lois locales (RGPD, CCPA, etc.) et suivez les bonnes pratiques de conformité.
2. Quelle est la différence entre utiliser l’API Google Maps et faire du web scraping du HTML ?
L’API est stable, sous licence et conçue pour l’extraction de données, mais elle nécessite une clé API et est soumise à des quotas et à des coûts. Le scraping HTML utilise l’automatisation du navigateur pour extraire les données de la page rendue, mais il est fragile (la structure du site change souvent), peut enfreindre les conditions d’utilisation et présente un risque juridique plus élevé. Pour la plupart des usages professionnels, l’API est la voie recommandée.
3. Combien coûte l’extraction de données Google Maps avec Python en 2026 ?
La tarification de l’API Places de Google se fait par tranche de 1 000 requêtes, de 5 $ (Essentials) à 25 $ (Enterprise + Atmosphere), selon les champs demandés. Il existe des seuils mensuels gratuits (10 000 pour Essentials, 5 000 pour Pro, 1 000 pour Enterprise), mais une extraction à grande échelle peut vite devenir coûteuse. Utilisez toujours des masques de champs et des filtres côté serveur pour maîtriser les coûts.
4. Comment Thunderbit se compare-t-il aux extracteurs Google Maps basés sur Python ?
Thunderbit est un extracteur Web sans code, propulsé par l’IA, qui vous permet d’extraire des données Google Maps (et bien plus) sans programmation, sans clé API et sans maintenance. Il est idéal pour les équipes commerciales et marketing qui veulent des exports rapides et fiables vers Excel, Google Sheets, Airtable ou Notion. Pour les utilisateurs techniques ayant besoin d’une logique personnalisée, Python offre plus de flexibilité mais demande davantage de configuration et de gestion de la conformité.
5. Comment automatiser des extractions Google Maps récurrentes ?
Avec Python, utilisez des bibliothèques de planification comme schedule ou APScheduler pour exécuter votre extracteur à intervalles fixes (quotidiennement, hebdomadairement, etc.). Ajoutez un aléa temporel pour éviter la détection et surveillez votre quota API. Avec Thunderbit, vous pouvez programmer des extractions récurrentes directement dans l’interface — sans code ni configuration de serveur.
Prêt à transformer Google Maps en superpouvoir pour vos ventes et votre marketing ? Que vous soyez passionné de Python ou que vous cherchiez la solution sans code la plus rapide, les outils sont là en 2026. Essayez pour un scraping instantané, dopé à l’IA — ou retroussez vos manches et plongez dans l’API. Dans tous les cas, que vos listes de leads soient toujours à jour, vos exports impeccables et vos campagnes remplies de prospects locaux à fort potentiel de conversion. Bon scraping !
En savoir plus