Google a supprimé son API Flights en 2018, mais les prix des billets continuent de bouger — pour une seule liaison intérieure. Si vous voulez accéder à ces données de façon programmatique, le scraping est pratiquement la seule option.
J’ai passé beaucoup de temps à tester différentes méthodes pour extraire les données de vols depuis Google, et le paysage a radicalement changé — surtout après le déploiement de SearchGuard par Google en janvier 2025. Dans ce guide, je vous montre comment créer un scraper Python fonctionnel pour Google Flights avec Playwright, comment gérer les protections anti-bot qui font échouer la plupart des tentatives, puis comment aller plus loin avec un suivi automatisé des prix et des alertes. Si vous préférez éviter le code, je présente aussi un raccourci no-code avec qui permet d’obtenir le même résultat en environ deux minutes.
Pourquoi scraper Google Flights avec Python ?
Google Flights domine la recherche de vols. Sa visibilité mobile aux États-Unis , dépassant tous les grands OTA. Le marché du metasearch voyage qui le soutient est évalué à , avec une croissance annuelle composée de 30,2 %. Pourtant, depuis l’arrêt définitif de l’API QPX Express le , il n’existe plus de solution officielle pour accéder à ces données par programme.
En parallèle, les prix des vols peuvent fluctuer pour un même itinéraire, avec un écart moyen d’environ 20 $ entre le tarif le plus bas et le plus élevé. Des compagnies comme Delta utilisent 77 paliers tarifaires pour le pricing dynamique. Le prix moyen d’un aller-retour aux États-Unis début 2026 se situe à 408 $, avec des tarifs aériens .
Plateforme dominante, pas d’API, prix très instables : voilà pourquoi le scraping de Google Flights avec Python est devenu l’un des projets les plus populaires sur GitHub et dans les forums voyage.
Voici pour qui c’est utile, et pourquoi :
| Type d’utilisateur | Cas d’usage | Principal avantage |
|---|---|---|
| Voyageurs individuels | Suivre les prix d’itinéraires précis dans le temps | Économiser en moyenne 50 $ par vol |
| Agences de voyage | Veille tarifaire concurrentielle | Suivi en temps réel de la parité des tarifs |
| Équipes voyages en entreprise | Optimisation des coûts sur plusieurs trajets | 10 à 30 % d’économies sur les déplacements pro |
| Développeurs | Créer des applications de comparaison de tarifs | Accès programmatique aux données de prix |
| Chercheurs | Analyse de la volatilité des tarifs aériens | Recherche académique et études de marché |
Sur les forums, les utilisateurs sont très directs sur les raisons qui les poussent vers le scraping : « Google Flights API was discontinued and I should use web scraping instead » revient régulièrement. Et le retour sur investissement est bien réel — après analyse de plus de 5 milliards de cotations de prix par jour, tandis que les données Expedia 2026 montrent qu’une réservation 8 à 15 jours à l’avance permet d’économiser environ .
Quelles données peut-on extraire de Google Flights ?
Une page de résultats Google Flights contient un ensemble de champs étonnamment riche. Voici ce qu’on peut généralement récupérer :
- Nom de la compagnie aérienne (et logo)
- Heure de départ et code aéroport
- Heure d’arrivée et code aéroport
- Durée totale du vol
- Nombre d’escales et détails des correspondances (aéroport, durée, statut de nuit)
- Prix du billet (selon la devise)
- Émissions de CO2 (kg CO2e, avec écart en pourcentage par rapport aux vols typiques)
- Classe de voyage, numéro de vol, modèle d’avion
- Espace pour les jambes
- Services inclus (Wi‑Fi, prises électriques, streaming multimédia)
- Indicateur de niveau de prix (bas / habituel / élevé)
- Alertes de retard ("Souvent retardé de plus de 30 min")
La disponibilité des données varie selon la liaison, la date et le type de billet (aller simple ou aller-retour). Voici à quoi ressemble un enregistrement de vol extrait, en JSON :
1{
2 "search_date": "2026-04-16",
3 "route": "SFO-JFK",
4 "departure_date": "2026-05-15",
5 "flights": [
6 {
7 "airline": "United Airlines",
8 "flight_number": "UA123",
9 "departure_time": "08:00",
10 "departure_airport": "SFO",
11 "arrival_time": "16:35",
12 "arrival_airport": "JFK",
13 "duration_minutes": 335,
14 "stops": 0,
15 "price_usd": 287,
16 "price_level": "low",
17 "co2_kg": 156,
18 "co2_vs_typical": "-12%",
19 "travel_class": "Economy"
20 }
21 ]
22}Préparer votre environnement Python
Avant d’écrire la moindre ligne de scraping, il faut mettre en place quelques éléments.
Prérequis :
- Niveau requis : intermédiaire
- Temps nécessaire : environ 1 à 2 heures pour suivre tout le tutoriel
- À prévoir : Python 3.7+, notions de base en Python, un navigateur basé sur Chrome
Installer les bibliothèques nécessaires
Nous utilisons Playwright pour l’automatisation du navigateur (Google Flights est rendu à 100 % en JavaScript — les requêtes HTTP statiques ne renvoient rien d’exploitable), plus quelques outils complémentaires :
1pip install playwright playwright-stealth pandas
2playwright install chromium- Playwright — automatisation de navigateur en mode headless, gère le rendu JavaScript et les mécanismes d’attente intégrés
- playwright-stealth — atténue plusieurs signaux classiques de détection de bot
- pandas — pour l’analyse des données et l’export CSV par la suite
Pourquoi choisir Playwright plutôt que Selenium ou requests
Google Flights ne fonctionne pas avec requests + BeautifulSoup seuls — le contenu est entièrement généré par JavaScript. Il faut un vrai navigateur.
| Fonctionnalité | Playwright | Selenium | requests + BS4 |
|---|---|---|---|
| Rendu JS | Support complet | Support complet | Aucun |
| Vitesse | 42 % plus rapide au total | Référence | N/A pour ce cas |
| Support asynchrone | Natif | Séquentiel uniquement | N/A |
| Utilisation mémoire | 30 % de moins | Plus élevée | Minimale |
| Contournement de détection bot | Bon (avec stealth) | Plus facilement détecté | N/A |
Playwright est plus rapide, plus moderne et gère mieux l’asynchrone. Pour Google Flights en particulier, c’est clairement le meilleur choix.
Étape par étape : scraper Google Flights avec Python
C’est le cœur du tutoriel. Nous allons construire le scraper pas à pas.
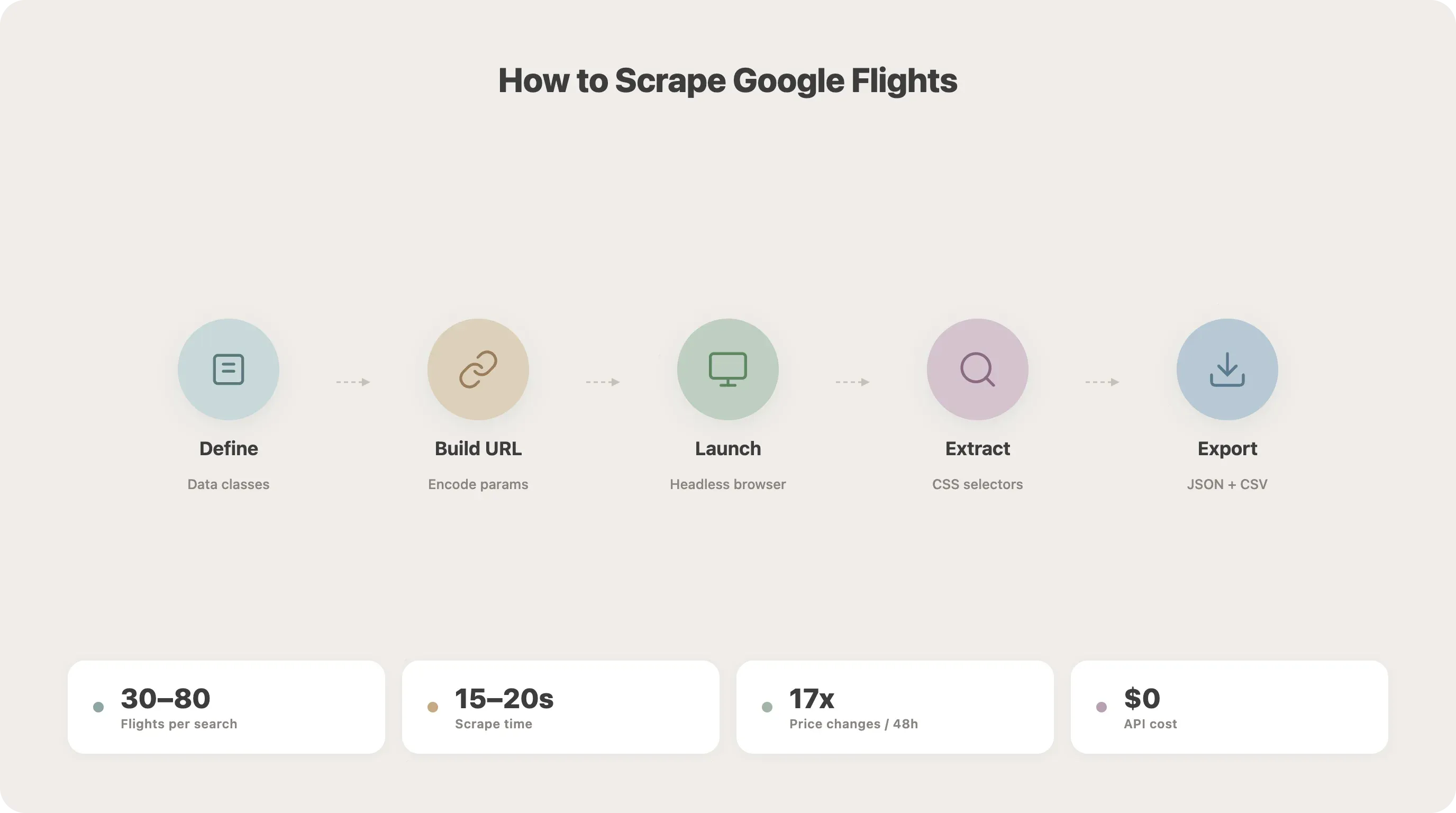
Étape 1 : définir vos classes de données
Commencez par structurer vos paramètres de recherche et vos données de vol avec les dataclasses Python. Cela garde le code lisible et facilite les évolutions ultérieures.
1from dataclasses import dataclass, field
2from typing import Optional, List
3@dataclass
4class SearchParams:
5 origin: str # e.g., "SFO"
6 destination: str # e.g., "JFK"
7 departure_date: str # e.g., "2026-05-15"
8 return_date: Optional[str] = None
9 trip_type: str = "one-way" # "one-way" or "round-trip"
10 travel_class: str = "economy"
11@dataclass
12class FlightData:
13 airline: str = ""
14 departure_time: str = ""
15 arrival_time: str = ""
16 duration: str = ""
17 stops: str = ""
18 price: str = ""
19 co2_emissions: str = ""Chaque champ correspond directement à ce que nous allons extraire de la page. Avec cette structure dès le départ, vous évitez de manipuler des dictionnaires brouillons plus tard.
Étape 2 : comprendre la structure d’URL de Google Flights
Google Flights encode les paramètres de recherche dans l’URL tfs via un Protobuf encodé en Base64. Vous pouvez soit reverse-engineer cet encodage, soit choisir une approche plus simple : construire une URL de requête en langage naturel.
La méthode la plus simple consiste à utiliser ce format de recherche :
1https://www.google.com/travel/flights?q=flights+from+SFO+to+JFK+on+2026-05-15&curr=USDPour plus de contrôle, vous pouvez générer l’URL par programme :
1def build_flights_url(origin: str, destination: str, date: str) -> str:
2 base = "https://www.google.com/travel/flights"
3 query = f"flights from {origin} to {destination} on {date}"
4 return f"{base}?q={query.replace(' ', '+')}&curr=USD"L’autre option — décoder le Protobuf à la main — offre un contrôle plus précis, mais casse dès que Google modifie son format interne. Des bibliothèques comme sur GitHub utilisent le décodage Protobuf pour éviter complètement l’analyse HTML, mais c’est une approche plus avancée.
Étape 3 : lancer le navigateur et ouvrir Google Flights
Voici la configuration Playwright. Nous utilisons playwright-stealth pour réduire dès le départ le risque de détection.
1import asyncio
2from playwright.async_api import async_playwright
3from playwright_stealth import Stealth
4async def scrape_flights(params: SearchParams) -> List[FlightData]:
5 async with Stealth().use_async(async_playwright()) as pw:
6 browser = await pw.chromium.launch(
7 headless=True,
8 args=[
9 "--disable-blink-features=AutomationControlled",
10 "--disable-dev-shm-usage",
11 "--no-first-run",
12 ]
13 )
14 context = await browser.new_context(
15 viewport={"width": 1920, "height": 1080},
16 user_agent=(
17 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
18 "AppleWebKit/537.36 (KHTML, like Gecko) "
19 "Chrome/125.0.0.0 Safari/537.36"
20 ),
21 locale="en-US",
22 timezone_id="America/New_York",
23 )
24 # Pre-set cookie consent to skip the popup
25 await context.add_cookies([{
26 "name": "SOCS",
27 "value": "CAESHwgBEhJnd3NfMjAyNTAyMjctMF9SQzIaBXpoLUNOIAEaBgiAy6O-Bg",
28 "domain": ".google.com",
29 "path": "/"
30 }])
31 page = await context.new_page()Nous tournons en headless pour la production (passez à headless=False pour le débogage), nous définissons une fenêtre et un user-agent réalistes, et nous pré-renseignons le cookie SOCS pour éviter la fenêtre de consentement — nous y revenons dans la section anti-bot.
Étape 4 : ouvrir les résultats de recherche
Chargez l’URL construite et attendez l’apparition des résultats :
1 url = build_flights_url(
2 params.origin, params.destination, params.departure_date
3 )
4 await page.goto(url, wait_until="networkidle")
5 # Wait for flight results to load
6 await page.wait_for_selector(
7 "li.pIav2d", timeout=15000
8 )Si cette étape expire, c’est généralement soit parce que la fenêtre de consentement bloque la page (voir le correctif avec cookie à l’étape 3), soit parce que Google envoie un CAPTCHA. Nous abordons les deux cas dans la partie anti-bot.
Étape 5 : charger tous les résultats de vols
Google Flights masque des résultats supplémentaires derrière le bouton « Show more flights ». Il faut cliquer dessus plusieurs fois jusqu’à ce que tous les vols soient visibles :
1 # Click "Show more flights" until all results are loaded
2 while True:
3 try:
4 more_button = page.locator(
5 'button:has-text("Show more flights")'
6 )
7 if await more_button.is_visible(timeout=3000):
8 await more_button.click()
9 await page.wait_for_timeout(2000)
10 else:
11 break
12 except Exception:
13 breakCette boucle clique sur le bouton, attend 2 secondes le rendu des nouveaux résultats, puis s’arrête quand le bouton n’est plus visible. D’après mes tests, la plupart des itinéraires comportent 1 à 3 pages de résultats.
Étape 6 : extraire les données de vol avec des sélecteurs CSS
Nous allons maintenant parser les données réelles de la page chargée. Voici les sélecteurs (vérifiés en avril 2026 — la section maintenance explique pourquoi cette date compte) :
1 flights = []
2 cards = await page.query_selector_all("li.pIav2d")
3 for card in cards:
4 flight = FlightData()
5 # Airline name
6 airline_el = await card.query_selector(
7 "div.sSHqwe span:not([class])"
8 )
9 if airline_el:
10 flight.airline = (await airline_el.inner_text()).strip()
11 # Departure time
12 dep_el = await card.query_selector(
13 'span[aria-label*="Departure time"]'
14 )
15 if dep_el:
16 flight.departure_time = (await dep_el.inner_text()).strip()
17 # Arrival time
18 arr_el = await card.query_selector(
19 'span[aria-label*="Arrival time"]'
20 )
21 if arr_el:
22 flight.arrival_time = (await arr_el.inner_text()).strip()
23 # Duration
24 dur_el = await card.query_selector("div.gvkrdb")
25 if dur_el:
26 flight.duration = (await dur_el.inner_text()).strip()
27 # Stops
28 stops_el = await card.query_selector("div.EfT7Ae span")
29 if stops_el:
30 flight.stops = (await stops_el.inner_text()).strip()
31 # Price
32 price_el = await card.query_selector(
33 "div.FpEdX span"
34 )
35 if price_el:
36 flight.price = (await price_el.inner_text()).strip()
37 # CO2 emissions
38 co2_el = await card.query_selector("div.O7CXue")
39 if co2_el:
40 flight.co2_emissions = (
41 await co2_el.get_attribute("aria-label") or ""
42 ).strip()
43 flights.append(flight)
44 await browser.close()
45 return flightsAttention : des classes comme pIav2d, sSHqwe et FpEdX sont générées par le Closure Compiler de Google et peuvent changer à n’importe quel build. Les sélecteurs basés sur aria-label sont plus stables. Je présente plus bas une stratégie complète de maintenance.
Étape 7 : enregistrer les résultats en JSON ou CSV
Enfin, sauvegardez les données extraites avec un horodatage (indispensable pour le suivi des prix plus tard) :
1import json
2from datetime import datetime
3from dataclasses import asdict
4async def main():
5 params = SearchParams(
6 origin="SFO",
7 destination="JFK",
8 departure_date="2026-05-15"
9 )
10 flights = await scrape_flights(params)
11 output = {
12 "search_date": datetime.now().isoformat(),
13 "params": asdict(params),
14 "flights": [asdict(f) for f in flights],
15 }
16 with open("flights.json", "w") as f:
17 json.dump(output, f, indent=2)
18 # Also save as CSV
19 import pandas as pd
20 df = pd.DataFrame([asdict(f) for f in flights])
21 df["search_date"] = datetime.now().isoformat()
22 df["route"] = f"{params.origin}-{params.destination}"
23 df.to_csv("flights.csv", index=False)
24 print(f"Scraped {len(flights)} flights")
25asyncio.run(main())Exécutez ce script et vous devriez obtenir un fichier flights.json et un fichier flights.csv contenant vos résultats. Lors de mes tests, une recherche SFO-JFK renvoie généralement 30 à 80 options de vol et prend environ 15 à 20 secondes.
Guide de survie anti-bot pour scraper Google Flights
La plupart des tutoriels s’arrêtent ici. La plupart des scrapers échouent ici. Google a déployé , ce qui a cassé presque tous les scrapers de SERP du jour au lendemain. Google le décrit comme « le fruit de dizaines de milliers d’heures-homme et de millions de dollars d’investissement ». Google Flights est noté pour le scraping.
Aucun article concurrent n’entre vraiment dans le détail, alors que c’est la première raison pour laquelle les scrapers cessent de fonctionner. Voici ce à quoi vous faites face, et comment y répondre.

Ajouter des délais aléatoires entre les requêtes
La défense la plus simple contre le rate limiting. Deux lignes de code, efficacité moyenne :
1import time
2import random
3time.sleep(random.uniform(3, 7))Ajoutez cela entre les navigations de page. Des intervalles fixes (par exemple exactement 5 secondes à chaque fois) sont suspects — il faut varier.
Rotation du User-Agent
Envoyer la même chaîne user-agent à chaque requête est un indice évident. Alternez parmi une liste :
1import random
2USER_AGENTS = [
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/125.0.0.0 Safari/537.36",
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_5) AppleWebKit/605.1.15 Safari/605.1.15",
5 "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:126.0) Gecko/20100101 Firefox/126.0",
7]
8user_agent = random.choice(USER_AGENTS)Contourner la détection du mode headless
Google vérifie le drapeau navigator.webdriver et d’autres signaux d’automatisation. La bibliothèque playwright-stealth couvre la plupart de ces éléments, mais il faut aussi ajouter les arguments de lancement vus à l’étape 3. Les drapeaux clés :
1args=[
2 "--disable-blink-features=AutomationControlled",
3 "--disable-dev-shm-usage",
4 "--no-first-run",
5]Cela vous fait passer les détections de base. SearchGuard va plus loin — il surveille la vitesse de la souris, le timing clavier et les patterns de défilement — mais pour des volumes modérés, le mode stealth avec des délais réalistes suffit généralement.
Rotation des proxys : datacenter vs résidentiels
Dès que vous dépassez quelques recherches, il vous faut des proxys. La différence compte :
Les proxys résidentiels coûtent environ lorsqu’on scrape des sites protégés. Tarifs 2026 chez différents fournisseurs : Smartproxy à partir de 7 $/Go, Bright Data 8,40 $/Go, Oxylabs 8 $/Go.
Ajoutez un proxy à Playwright comme ceci :
1browser = await pw.chromium.launch(
2 proxy={"server": "http://proxy-host:port",
3 "username": "user", "password": "pass"}
4)Gérer la fenêtre de consentement des cookies
Les utilisateurs signalent régulièrement la fenêtre « I agree to terms » comme un blocage : « first google will show you the 'I agree to terms and conditions' popup. » La solution la plus propre consiste à pré-définir le cookie SOCS (comme montré à l’étape 3). Si cela ne suffit pas, cliquez dessus :
1try:
2 accept_btn = page.locator('button:has-text("Accept all")')
3 if await accept_btn.is_visible(timeout=3000):
4 await accept_btn.click()
5 await page.wait_for_timeout(1000)
6except Exception:
7 pass # No popup presentÀ noter : le texte du bouton varie selon la langue — « Alle akzeptieren » en allemand, « Tout accepter » en français.
Référence rapide anti-bot
| Technique | Difficulté | Efficacité | Code nécessaire ? |
|---|---|---|---|
| Délais aléatoires (2–7 s) | Faible | Moyenne | 2 lignes |
| Rotation du user-agent | Faible | Moyenne | 5 lignes |
| Contournement du headless | Moyenne | Élevée | Arguments de lancement Playwright |
| Plugin playwright-stealth | Moyenne | 60–80 % sur les sites basiques | pip install |
| Rotation de proxys (datacenter) | Moyenne | Moyenne | Configuration |
| Rotation de proxys (résidentiels) | Moyenne | 85–95 % de réussite | Configuration |
| Pré-réglage du consentement cookie (SOCS) | Faible | Requis | 1 ligne |
Pour des cadences sûres recommandées : gardez 10 à 20 secondes entre les requêtes avec rotation d’IP. Les seuils de Google sont d’environ 100 requêtes/minute par IP avant un 429, et des volumes soutenus au-delà de 1 000 requêtes/jour par IP peuvent déclencher des bannissements temporaires.
Pourquoi vos sélecteurs Google Flights cassent sans cesse (et comment y remédier)
C’est de loin le problème n°1. Les discussions de forum sont pleines de variations du type « tout ce que je récupère, ce sont 14 listes vides. » Tous les tutoriels donnent des sélecteurs. Aucun n’explique pourquoi ils cassent.
Pourquoi les sélecteurs Google Flights changent
La raison tient à trois facteurs :
-
Obfuscation via Closure Compiler. Google utilise pour générer des noms de classes comme
BVAVmfetYMlIzviagoog.setCssNameMapping(). Ils changent à chaque build — parfois chaque semaine. -
Tests A/B. Différents utilisateurs voient simultanément des structures HTML différentes. Votre scraper peut fonctionner chez vous mais échouer pour quelqu’un dans une autre région.
-
Différences de locale. Les utilisateurs européens voient parfois des libellés, des mises en page et même des champs différents de ceux des utilisateurs américains.
Écrire des sélecteurs robustes
Préférez des sélecteurs fondés sur le sens plutôt que sur l’apparence :
1# Fragile — breaks on every build
2price_el = await card.query_selector("div.BVAVmf > div.YMlIz")
3# More resilient — tied to accessibility labels
4dep_el = await card.query_selector('span[aria-label*="Departure time"]')
5# Also resilient — text-based matching
6more_btn = page.locator('button:has-text("Show more flights")')Hiérarchie de stabilité des sélecteurs (du plus stable au moins stable) :
- attributs
aria-label— liés à l’accessibilité, rarement modifiés - attributs
data-*— ajoutés explicitement pour la fonctionnalité - attributs
role— les rôles ARIA sont sémantiques - sélecteurs basés sur le texte — correspondent au contenu visible
- correspondance partielle sur les classes — par exemple
[class*="price"] - noms de classes obfusqués complets — à éviter autant que possible
Ajouter une fonction de validation
Ne laissez pas des sélecteurs cassés produire silencieusement des données vides. Détectez le problème tôt :
1import logging
2logger = logging.getLogger(__name__)
3def validate_flight(data: FlightData) -> bool:
4 required = ["airline", "price", "departure_time",
5 "arrival_time", "duration"]
6 valid = True
7 for field_name in required:
8 if not getattr(data, field_name, ""):
9 logger.warning(
10 f"Missing '{field_name}' — selectors may need updating"
11 )
12 valid = False
13 return validExécutez cette vérification sur chaque vol extrait. Si vous commencez à voir des avertissements, il est temps d’inspecter la page et de mettre à jour les sélecteurs.
Stratégie de maintenance des sélecteurs
- Vérifiez les sélecteurs tous les mois, ou immédiatement si la qualité des données baisse
- Gardez les sélecteurs dans un dictionnaire de configuration séparé pour faciliter les mises à jour
- Les sélecteurs de cet article ont été vérifiés pour la dernière fois en avril 2026
- Envisagez la bibliothèque comme alternative — elle utilise le décodage Protobuf au lieu des sélecteurs CSS, ce qui contourne ce problème (même si elle reste fragile lorsque Google change ses formats de données internes)
D’un scraping ponctuel à un tracker automatisé des prix Google Flights
La plupart des tutoriels s’arrêtent à « enregistrer en JSON ». Le titre de cet article mentionne « Price Alerts ». Il est temps de tenir la promesse.
![]()
Planifier l’exécution automatique de votre scraper
Option 1 : bibliothèque Python schedule (la plus simple, multiplateforme) :
1import schedule
2import time
3def run_scraper():
4 asyncio.run(main())
5schedule.every().day.at("06:00").do(run_scraper)
6schedule.every().day.at("18:00").do(run_scraper)
7while True:
8 schedule.run_pending()
9 time.sleep(60)Option 2 : tâche cron (Linux/Mac) :
1# Run at 6 AM and 6 PM daily
20 6,18 * * * cd /path/to/scraper && python scraper.pyOption 3 : Planificateur de tâches Windows — créez une tâche de base qui exécute python scraper.py selon la fréquence souhaitée.
Le compromis : toutes ces solutions exigent une machine toujours allumée. Si vous lancez cela sur un laptop qui se met en veille, vous manquerez des exécutions.
Stocker l’historique des prix
Au lieu d’écraser un fichier JSON, faites des insertions dans une base SQLite :
1import sqlite3
2from datetime import datetime
3def init_db():
4 conn = sqlite3.connect("flights.db")
5 conn.execute("""
6 CREATE TABLE IF NOT EXISTS flights (
7 id INTEGER PRIMARY KEY AUTOINCREMENT,
8 scrape_date TEXT NOT NULL,
9 route TEXT NOT NULL,
10 airline TEXT,
11 departure_time TEXT,
12 arrival_time TEXT,
13 duration TEXT,
14 stops TEXT,
15 price_usd REAL,
16 co2_emissions TEXT
17 )
18 """)
19 conn.execute(
20 "CREATE INDEX IF NOT EXISTS idx_route_date "
21 "ON flights(route, scrape_date)"
22 )
23 conn.commit()
24 return conn
25def save_flight(conn, route: str, flight: FlightData):
26 price_num = float(
27 flight.price.replace("$", "").replace(",", "")
28 ) if flight.price else None
29 conn.execute(
30 "INSERT INTO flights "
31 "(scrape_date, route, airline, departure_time, "
32 "arrival_time, duration, stops, price_usd, co2_emissions) "
33 "VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)",
34 (datetime.now().isoformat(), route, flight.airline,
35 flight.departure_time, flight.arrival_time,
36 flight.duration, flight.stops, price_num,
37 flight.co2_emissions)
38 )
39 conn.commit()Après une semaine de scrapes deux fois par jour, vous aurez suffisamment de données pour commencer à repérer des tendances.
Analyser les tendances de prix et définir des alertes
Trouvez l’option la moins chère dans votre historique :
1import pandas as pd
2import sqlite3
3conn = sqlite3.connect("flights.db")
4df = pd.read_sql_query(
5 "SELECT * FROM flights WHERE route = 'SFO-JFK'", conn
6)
7summary = df.groupby("scrape_date")["price_usd"].agg(
8 ["min", "max", "mean"]
9)
10cheapest = df.loc[df["price_usd"].idxmin()]
11print(
12 f"Cheapest: ${cheapest['price_usd']:.0f} on "
13 f"{cheapest['scrape_date']} ({cheapest['airline']})"
14)Déclenchez une alerte e-mail lorsque le prix passe sous votre seuil :
1import smtplib
2from email.mime.text import MIMEText
3def send_price_alert(route, price, threshold, recipient):
4 msg = MIMEText(
5 f"Price drop alert! {route}: ${price:.0f} "
6 f"(below your ${threshold:.0f} threshold)"
7 )
8 msg["Subject"] = f"Flight Deal: {route} at ${price:.0f}"
9 msg["From"] = "alerts@example.com"
10 msg["To"] = recipient
11 with smtplib.SMTP_SSL("smtp.gmail.com", 465) as server:
12 server.login("alerts@example.com", "your_app_password")
13 server.send_message(msg)
14# After each scrape, check for deals
15min_price = df["price_usd"].min()
16threshold = 250
17if min_price < threshold:
18 send_price_alert("SFO-JFK", min_price, threshold,
19 "you@email.com")Fréquence recommandée : deux fois par jour suffisent pour un suivi personnel des prix (un horaire aléatoire réduit le risque de détection). Toutes les 4 à 6 heures si vous surveillez un besoin professionnel. Toutes les heures uniquement pendant les périodes de promotion, et temporairement.
Le chemin le plus simple : le Scheduled Scraper de Thunderbit
Si gérer cron, un serveur allumé en permanence et des configurations de proxy vous semble trop lourd à maintenir, le couvre le même cas d’usage sans toute cette infrastructure. Vous décrivez l’intervalle de scraping en langage naturel, vous fournissez vos URLs Google Flights, et le scraper s’exécute automatiquement sur l’infrastructure cloud de Thunderbit — avec gestion anti-bot intégrée et export direct vers . Ce n’est pas un remplacement complet de l’approche Python (vous perdez en personnalisation), mais pour le cas précis « je veux un tableau de suivi des prix », c’est la voie la plus rapide. Vous pouvez l’essayer avec le .
Quand Python est excessif : des solutions no-code pour scraper Google Flights
Après avoir tout construit ci-dessus, soyons honnêtes : c’est beaucoup de pièces mobiles. Tout le monde n’a pas besoin d’un tel niveau de contrôle. Les sélecteurs cassent, les proxys doivent tourner, les cron jobs doivent être surveillés. Si votre objectif est simplement « obtenir régulièrement les prix des vols dans un tableur », il existe des options plus rapides.
Comparaison : Python maison vs services d’API vs Thunderbit
| Approche | Temps de mise en place | Code requis | Gestion anti-bot | Planification | Coût |
|---|---|---|---|---|---|
| Playwright DIY (ce tutoriel) | 1 à 2 heures | Python (intermédiaire) | Configuration manuelle | Manuelle (cron) | Gratuit + coûts des proxys |
| Endpoint Google Flights de SerpApi | 15 min | Appels API uniquement | Géré | Via API | Environ 50 $+/mois |
| Extension Chrome Thunderbit | 2 min | Aucun | Scraping cloud | Planificateur intégré | Forfait gratuit disponible |
À propos de SerpApi : Google , alléguant que leur volume de requêtes avait augmenté de 25 000 % en deux ans. Cette incertitude juridique mérite d’être prise en compte si vous évaluez des fournisseurs d’API.
Comment Thunderbit scrape Google Flights
Ouvrez vos résultats Google Flights dans Chrome, cliquez sur le bouton « AI Suggest Fields » de Thunderbit — l’IA lit la page et propose des colonnes comme compagnie aérienne, prix, heure de départ, escales — vérifiez les champs proposés, puis cliquez sur « Scrape ». Les résultats apparaissent dans un tableau que vous pouvez exporter vers Excel, Google Sheets, Airtable ou Notion — le tout sur le .
Pour le cas d’usage du suivi des prix en particulier, le Scheduled Scraper et le de Thunderbit (capable de traiter 50 pages en parallèle) remplacent toute l’infrastructure cron + proxy + serveur.
Python vous donne un contrôle total et une personnalisation illimitée. Thunderbit vous apporte la vitesse et zéro maintenance. Choisissez selon votre objectif réel. Si vous voulez en savoir plus sur les approches no-code, consultez notre guide sur les .

Le scraping de Google Flights est-il légal ? Ce qu’il faut savoir
Les utilisateurs de forums posent souvent la question : « scraper Google Flights directement viole les conditions d’utilisation de Google ». La préoccupation est légitime — surtout puisqu’il n’existe plus d’API officielle.
Violation des CGU vs responsabilité juridique
Les conditions d’utilisation de Google (mises à jour le 22 mai 2024) stipulent que les utilisateurs ne doivent pas « accéder aux Services ou à tout contenu ou les utiliser via des moyens automatisés (tels que robots, spiders ou scrapers) ». Violer les CGU constitue une rupture contractuelle (domaine civil) — ce n’est pas la même chose que violer la loi pénale.
Le précédent juridique important : hiQ v. LinkedIn (neuvième circuit, 2022) a établi que le scraping de données publiques ne viole pas le Computer Fraud and Abuse Act (CFAA). Toutefois, l’affaire s’est conclue par un accord, et la plainte déposée par Google contre SerpApi en décembre 2025 repose sur une autre théorie juridique — la section 1201 du DMCA (contournement de mesures techniques de protection) — potentiellement plus sérieuse.
Bonnes pratiques pour un scraping responsable
- Limitez le rythme des requêtes — délais de 10 à 20 secondes avec rotation d’IP
- Ne scrapez pas de données personnelles — les prix des vols sont des informations publiques et agrégées
- Ne contournez pas les CAPTCHA par programme (c’est la zone de risque liée au DMCA)
- Utilisez les données pour de la recherche personnelle, pas pour construire un produit commercial concurrent sans licence appropriée
- Privilégiez les API officielles lorsqu’elles sont disponibles
Sources de données alternatives
Si le scraping vous paraît trop risqué pour votre cas d’usage, il existe des options API légitimes :
| Fournisseur | Coût | Forfait gratuit | Remarques |
|---|---|---|---|
| SerpApi | 75 à 3 750 $+/mois | 250 recherches/mois | JSON Google Flights direct (sous surveillance juridique) |
| Kiwi Tequila | Gratuit (modèle d’affiliation) | Illimité | Idéal pour les startups et les tests |
| Amadeus | Paiement à l’usage | 2 000 requêtes/mois | Plus de 400 compagnies, possibilité de réservation |
| Skyscanner | Personnalisé | Sur approbation | 52 marchés, 30 langues |
Nous avons aussi rédigé une analyse plus détaillée sur les si vous souhaitez une vision complète.
Conclusion et points clés
C’était dense. Voici l’essentiel :
- Python + Playwright est l’approche la plus flexible pour scraper Google Flights, mais elle demande une maintenance continue
- Les protections anti-bot (délais, rotation du user-agent, proxys résidentiels) ne sont pas optionnelles — elles sont indispensables pour la fiabilité, surtout après SearchGuard
- Les sélecteurs cassent souvent — utilisez
aria-labelet des sélecteurs basés sur le texte autant que possible, validez vos sorties et prévoyez une maintenance régulière - Automatisez avec
scheduleou cron pour transformer un scraping ponctuel en vrai tracker de prix avec historique et alertes e-mail - propose une alternative no-code avec planification intégrée, scraping cloud et gestion anti-bot — idéal si votre but est un tableau de suivi des prix plutôt qu’un projet de développement
- Respectez le cadre légal — limitez le rythme, ne scrapez que des données publiques et envisagez des API alternatives pour un usage commercial
Récupérez le code de ce tutoriel, ou installez l’ pour aller plus vite. Dans tous les cas, vous suivrez les prix des vols au lieu d’actualiser manuellement Google Flights.
Pour d’autres techniques de scraping en Python, consultez nos guides sur et .
FAQ
1. Peut-on scraper Google Flights sans Python ?
Oui. Des services API comme SerpApi et Kiwi Tequila fournissent des données structurées sur les vols via des appels API (sans automatisation de navigateur). Pour une approche entièrement no-code, peut extraire directement les résultats Google Flights depuis votre navigateur avec des champs suggérés par l’IA et un export en un clic.
2. Google bloque-t-il le scraping des vols ?
Google utilise des mécanismes de détection de bots (SearchGuard), des CAPTCHA et du rate limiting. Avec des mesures anti-bot adaptées — délais aléatoires, rotation du user-agent, proxys résidentiels et réglages de navigateur stealth — vous pouvez maintenir un scraping fiable à volume modéré. Voir la section anti-bot ci-dessus pour les techniques et seuils précis.
3. À quelle fréquence faut-il scraper Google Flights pour suivre les prix ?
Deux fois par jour (à des heures aléatoires) suffisent pour un suivi personnel et maintiennent le risque de détection bas. Pour un usage professionnel, toutes les 4 à 6 heures avec rotation de proxys. Évitez le scraping horaire sauf pendant de courtes périodes de promotions tarifaires — cela augmente fortement les chances d’être bloqué.
4. Existe-t-il une API Google Flights gratuite ?
L’API officielle Google QPX Express a été . Il n’existe pas de remplacement officiel gratuit. L’option gratuite la plus proche est l’ (modèle d’affiliation, recherches illimitées). SerpApi propose 250 recherches gratuites par mois. Pour la plupart des utilisateurs, le scraping ou un outil no-code comme Thunderbit est la solution la plus pratique.
5. Pourquoi mes sélecteurs CSS Google Flights renvoient-ils sans cesse des données vides ?
Google utilise Closure Compiler pour générer des noms de classes obfusqués qui changent à chaque build. Les tests A/B et les différences de locale font aussi varier la structure HTML entre utilisateurs. La solution : utiliser des attributs aria-label et des sélecteurs basés sur le texte plutôt que sur les classes, ajouter une fonction de validation pour repérer les cassures tôt, et vérifier les sélecteurs chaque mois. Voir la section dédiée à la maintenance des sélecteurs pour une stratégie détaillée.
En savoir plus