Si votre extracteur Glassdoor marchait très bien en 2022 et qu’aujourd’hui il ne vous renvoie plus que des erreurs 403, vous n’êtes clairement pas seul. De forum en forum, on retrouve toujours la même question : « Quelqu’un sait pourquoi ce scraper ne marche plus ? »
La réponse courte : Glassdoor a tout bouleversé. Recruit Holdings a intégré Glassdoor à Indeed en juillet 2025, supprimé et renforcé sa défense anti-bots au point que les scrapers basés sur Selenium classique ou requests sont bloqués avant même le chargement du premier octet HTML. En février 2026, les connexions Glassdoor passent entièrement par Indeed Login — ce qui rend carrément obsolète tout tutoriel qui repose sur un formulaire de connexion propre à Glassdoor. Pourtant, la plateforme garde encore sur . Ces données ont une vraie valeur pour le benchmarking RH, la veille concurrentielle et la prospection commerciale — à condition de pouvoir y accéder pour de bon. Ce guide est la version qui fonctionne après tous ces changements, et couvre au même endroit les trois types de données Glassdoor (offres d’emploi, avis ET salaires). Je vais vous montrer l’approche Python avec du code 2025 qui tient la route, expliquer précisément ce qui vous bloque et comment contourner ces protections, puis présenter une alternative sans code pour celles et ceux qui veulent éviter la partie technique.
Pourquoi extraire Glassdoor avec Python en 2025 ?
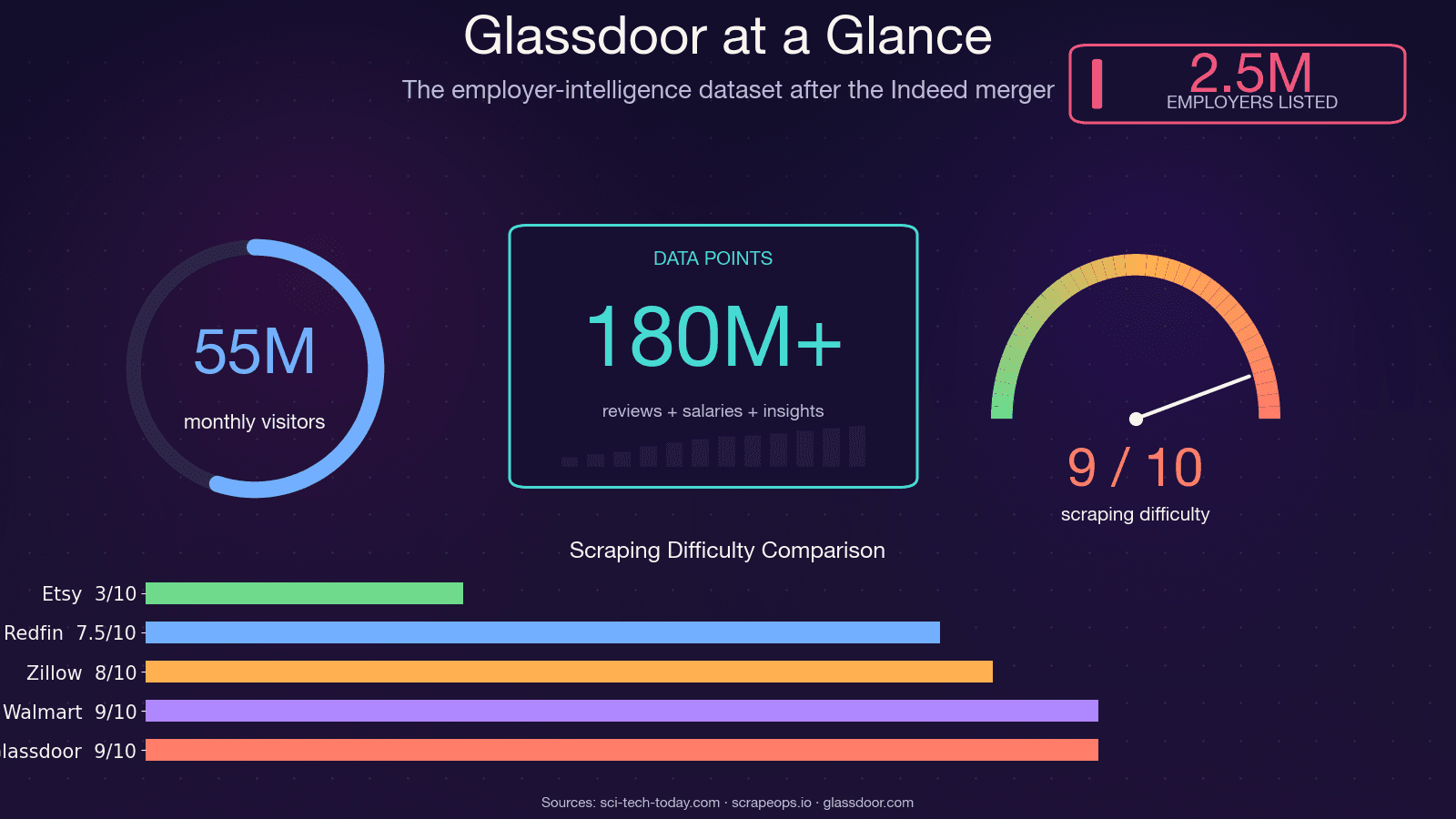
Glassdoor, ce n’est pas juste un site d’offres d’emploi. C’est l’un des ensembles de données d’intelligence employeur les plus riches du web — utilisé par environ et consulté par près de 55 millions de visiteurs uniques chaque mois. Les données derrière ces pages nourrissent des décisions bien réelles dans plusieurs équipes.
Voici comment différents services exploitent concrètement les données Glassdoor :
| Cas d’usage | Type de données requis | Qui en bénéficie |
|---|---|---|
| Benchmark salarial | Répartition des salaires, taille des échantillons | RH, rémunération globale, opérations |
| Suivi des recrutements concurrents | Offres d’emploi, rythme de publication | Sales, stratégie, VC / développement corporate |
| Suivi de la marque employeur | Texte des avis, évolution des notes, approbation du CEO | RH, marketing, communication |
| Génération de leads (entreprises en croissance) | Offres d’emploi + informations société | Équipes commerciales, SDR |
| Recherche marché / académique | Les trois | Analystes, consultants, chercheurs |
Quand le BLS n’a pas pu publier ses chiffres sur l’emploi pendant la fermeture du gouvernement en octobre 2025, l’équipe Economic Research de Glassdoor a à partir de son propre dataset. C’est dire à quel point cette donnée est désormais prise au sérieux par les analystes institutionnels.
Python reste l’outil de référence parce que son écosystème est imbattable — Playwright pour l’automatisation du navigateur, parsel/lxml pour le parsing, curl_cffi pour contourner les empreintes TLS, et une énorme communauté qui partage des méthodes réellement utilisables. Le problème n’est pas Python. Le problème, c’est que Glassdoor est devenu beaucoup plus difficile à extraire.
Si vous cherchez une solution sans code pour extraire les données Glassdoor, Thunderbit peut vous aider à récupérer les offres d’emploi, avis et pages de salaires sans construire ni maintenir une stack Python sur mesure.
Quelles données Glassdoor peut-on vraiment extraire ?
La plupart des tutoriels ne couvrent que les offres d’emploi. Mais la vraie demande — à en croire les discussions sur les forums, les issues GitHub et les questions Reddit que je suis — se concentre surtout sur les deux types de données que personne n’enseigne : les avis et les salaires. Voici le détail complet de ce que vous pouvez extraire dans les trois catégories.
Offres d’emploi
Le type de donnée le plus accessible. Vous pouvez récupérer : le titre du poste, le nom de l’entreprise, la localisation, l’estimation du salaire, la note de l’entreprise, la date de publication, le badge de candidature simplifiée et le lien de l’offre. Les offres restent partiellement accessibles sans connexion, même si Glassdoor peut afficher une popup de connexion après plusieurs pages.
Avis d’entreprise
C’est là que ça devient vraiment intéressant pour l’analyse de la marque employeur. Les champs récupérables incluent : la note globale, les sous-notes (équilibre vie pro/vie perso, culture et valeurs, diversité et inclusion, opportunités de carrière, rémunération et avantages, direction), le texte des points positifs, le texte des points négatifs, l’intitulé du poste du contributeur, la date de l’avis et le statut d’emploi. Le texte complet des avis est protégé par connexion — vous verrez un extrait, mais le contenu intégral des pros/cons demande une authentification.
Données salariales
Le type de donnée le plus demandé et le plus frustrant. Vous pouvez extraire : l’intitulé du poste, la fourchette du salaire de base, la fourchette de rémunération totale, le nombre de rapports de salaire et la localisation. Mais les pages salaire sont entièrement verrouillées derrière la connexion, et Glassdoor ajoute parfois un parcours du type « contribuer pour débloquer », où il faut soumettre son propre salaire avant de voir celui des autres. Aucun tutoriel concurrent ne donne du code fonctionnel pour ça — on va corriger ce point.
Ce qui nécessite une connexion et ce qui ne la nécessite pas
Ce tableau vous évite de découvrir trop tard quelles pages vont vous renvoyer des données vides :
| Type de donnée | Disponible sans connexion ? | Remarques |
|---|---|---|
| Titres des offres et infos de base | Oui, en grande partie | Une popup peut apparaître après plusieurs pages |
| Descriptions complètes des offres | Partiellement | Souvent verrouillées après 2 à 3 consultations |
| Avis d’entreprise (texte complet) | Non — connexion requise | Un extrait est visible, le texte complet est protégé |
| Données salariales | Non — connexion requise | Peut aussi exiger un parcours « contribuer pour débloquer » |
Pourquoi votre ancien scraper Glassdoor est probablement cassé
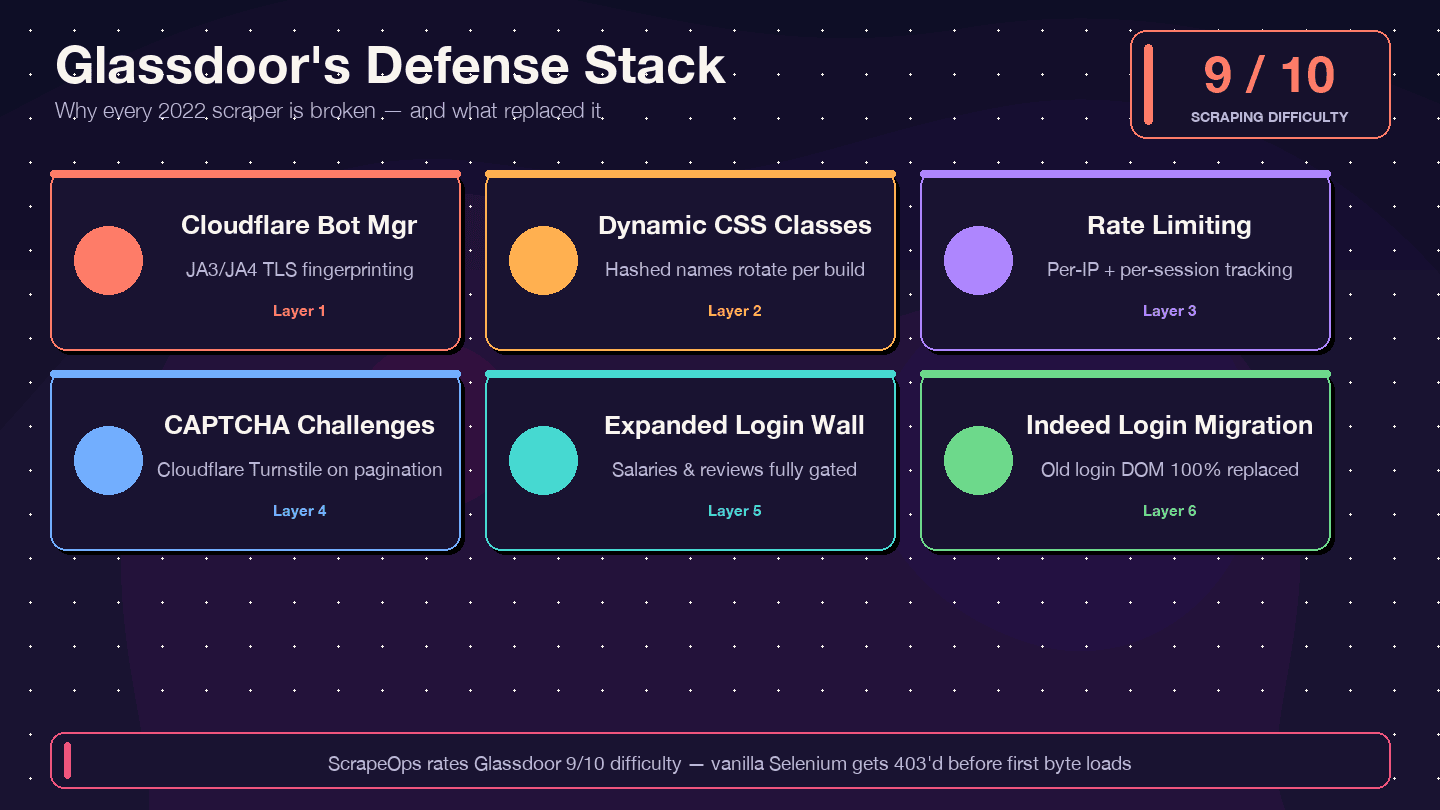
Je vais être direct : si vous copiez du code venu d’un tutoriel 2021–2023, il ne fonctionnera pas. Le scraper Selenium Glassdoor historique le plus étoilé sur GitHub (, environ 1,4k étoiles) cumule plus de 12 issues ouvertes non résolues — dont « Glassdoor new UI design », « Cloudflare anti-bot protection » et « NoSuchElementException ». Le dépôt est pratiquement abandonné. . et une difficulté de contournement de 8/10.
Voici ce qui a changé et pourquoi l’ancien code casse :
| Couche de défense | Ce qui a changé | Impact sur les anciens scrapers |
|---|---|---|
| Cloudflare Bot Management | Fingerprinting JA3/JA4 renforcé depuis 2024 | Les scripts requests/Selenium basiques sont bloqués immédiatement avec 403 |
| Noms de classes CSS dynamiques | Classes randomisées à chaque build | Les anciens sélecteurs CSS des tutoriels ne renvoient plus rien sans erreur |
| Limitation de débit + suivi de session | Limites plus strictes par IP et par session | Les scrapers sont bloqués après moins de pages |
| Défis CAPTCHA (probablement Cloudflare Turnstile) | Plus fréquents, surtout à la pagination | Les navigateurs headless déclenchent les défis |
| Mur de connexion élargi | Davantage de pages exigent une authentification | Les pages salaire et avis renvoient des données vides |
| Migration vers Indeed Login (févr. 2026) | Le formulaire Glassdoor a été entièrement remplacé | Tout code ciblant l’ancien DOM de connexion est mort |
contient un avertissement clair : « Glassdoor est connu pour son taux de blocage élevé ; si vous obtenez des valeurs None en exécutant le code Python, il est probable que vous soyez bloqué. » Et un le dit sans détour : « Les requêtes HTTP simples avec requests ou httpx sont bloquées instantanément. »
Les contre-mesures que je vais vous montrer — Patchright (un fork furtif de Playwright), les sélecteurs d’attributs data-test, la rotation de proxys résidentiels et les sessions persistantes authentifiées — sont justement pensées pour gérer chacune de ces couches.
API Glassdoor vs scraping Python : choisissez d’abord la bonne approche
Beaucoup de discussions posent la même question : « Est-ce que je devrais simplement utiliser l’API Glassdoor ? » — et la réponse est : non, ce n’est pas vraiment une option.
. Le portail développeur existe encore techniquement mais . Il n’y a jamais eu d’endpoint public pour les avis — le scraper de MatthewChatham a justement été créé « parce que Glassdoor n’a pas d’API pour les avis ». Et il n’existe aucune voie de migration pour les avis ou les salaires via l’API Publisher d’Indeed.
Voici la comparaison honnête :
| Critère | API Glassdoor Partner v1 | Scraping Python | Thunderbit (sans code) |
|---|---|---|---|
| Accès | Fermé aux nouveaux candidats | Ouvert (à implémenter soi-même) | Extension Chrome |
| Offres d’emploi | Limité / en fin de vie | Disponible avec effort | Disponible |
| Avis d’entreprise | N’a jamais existé publiquement | Oui (connexion requise) | Oui (via Browser Mode) |
| Données salariales | N’a jamais existé publiquement | Oui (connexion requise) | Oui |
| Limites de débit | Non documentées | Vous contrôlez le rythme | Basées sur des crédits |
| Effort de configuration | Impossible d’enregistrer de nouvelles applis | Quelques heures à quelques jours | Environ 2 minutes |
| Maintenance | N/A | Élevée (les changements HTML cassent le code) | Faible (l’IA réadapte les champs) |
Si vous avez besoin des avis ou des salaires — et c’est le cas de la plupart des lecteurs — le scraping Python ou un outil sans code reste votre seule option réaliste.
Avant de commencer
- Niveau : intermédiaire (vous devez être à l’aise avec Python et le terminal)
- Temps nécessaire : environ 30 à 60 minutes pour l’installation complète ; environ 10 minutes par type de données ensuite
- Ce qu’il vous faut :
- Python 3.10+ (3.11 ou 3.12 recommandé)
- Google Chrome installé
- Un compte Glassdoor (gratuit — nécessaire pour les salaires et les avis)
- Des proxys résidentiels rotatifs (pour aller au-delà de quelques pages)
- Optionnel : si vous voulez passer par une solution sans code
Outils et bibliothèques pour extraire Glassdoor avec Python en 2025
Le paysage des outils a énormément changé. Voici ce qui fonctionne vraiment face aux défenses actuelles de Glassdoor.
Pourquoi Patchright est le meilleur choix pour Glassdoor
est un fork furtif de Playwright qui corrige la fuite CDP Runtime.Enable — la raison technique précise pour laquelle Playwright standard échoue sur les sites protégés par Cloudflare. Il utilise exactement la même API que Playwright, donc si vous connaissez Playwright, vous connaissez Patchright. La version 1.58.2 (mars 2026) est actuelle et activement maintenue.
Par rapport aux alternatives :
- Playwright standard : détecté sur la page de connexion Glassdoor à cause de la fuite Runtime.Enable
- Selenium + undetected-chromedriver : la dernière version d’undetected-chromedriver date de février 2024 — c’est désormais une solution héritée. a montré qu’il « a échoué sur tous les domaines de notre test »
- requests + BeautifulSoup : ne peuvent pas rendre JavaScript et sont bloqués immédiatement par le fingerprinting TLS de Cloudflare
- : excellent pour le chemin rapide (10 à 20 fois plus rapide qu’un navigateur) lorsque les pages exposent
__NEXT_DATA__dans le HTML initial, mais incapable de gérer la connexion ou les interstitiels de vérification
Bibliothèques complémentaires
- parsel (1.11.0) ou lxml (6.0.4) : parsing HTML/XPath rapide
- csv ou pandas : export des données
- asyncio : scraping asynchrone pour aller plus vite dans la pagination
Proxys : uniquement résidentiels
La couche Cloudflare de Glassdoor challenge agressivement les ASN des datacenters. . Le tarif d’entrée tourne autour de (promotionnel) ou 3,00 $/GB chez . Pour un scraping en production, prévoyez un budget de 3 à 8 $/GB selon le volume.
Des délais aléatoires entre les requêtes (minimum 3 à 8 secondes, 5 à 15 secondes pour les exécutions plus longues) sont indispensables, quelle que soit la qualité du proxy.
Étape 1 : configurer votre environnement Python
Créez le dossier de projet et installez la pile recommandée :
1mkdir glassdoor-scraper && cd glassdoor-scraper
2python3.11 -m venv .venv
3source .venv/bin/activate
4pip install --upgrade pip
5# Stack principale
6pip install patchright==1.58.2 parsel==1.11.0
7# Installer les binaires du navigateur
8patchright install chromium
9# Optionnel : chemin rapide pour l’extraction de __NEXT_DATA__
10pip install "curl_cffi==0.15.0"Vous devriez voir Patchright télécharger un binaire Chromium. Si patchright install chromium échoue, vérifiez que vous avez assez d’espace disque (~300 Mo) et que votre version de Python est bien 3.10+.
Étape 2 : lancer Patchright et accéder à Glassdoor
Voici le schéma de lancement de base qui fonctionne face à la couche Cloudflare de Glassdoor :
1from patchright.sync_api import sync_playwright
2import random, time
3with sync_playwright() as p:
4 browser = p.chromium.launch(
5 headless=False, # le mode headless reste plus facilement détectable
6 channel="chrome", # utiliser le vrai Chrome, pas le Chromium embarqué
7 )
8 context = browser.new_context(
9 viewport={"width": 1440, "height": 900},
10 locale="en-US",
11 timezone_id="America/New_York",
12 user_agent=(
13 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
14 "AppleWebKit/537.36 (KHTML, like Gecko) "
15 "Chrome/134.0.0.0 Safari/537.36"
16 ),
17 )
18 page = context.new_page()
19 page.goto(
20 "https://www.glassdoor.com/Job/new-york-data-engineer-jobs-"
21 "SRCH_IL.0,8_IC1132348_KO9,22.htm"
22 )
23 # Masquer l’overlay de connexion — le contenu reste dans le DOM
24 page.add_style_tag(content="""
25 #HardsellOverlay, .LoginModal { display: none !important; }
26 body { overflow: auto !important; position: initial !important; }
27 """)
28 page.wait_for_selector("[data-test='jobListing']")
29 print("Page chargée — les offres sont visibles.")Quelques points à retenir ici. Le flag channel="chrome" indique à Patchright d’utiliser votre binaire Chrome installé plutôt que son Chromium embarqué — cela donne une empreinte navigateur plus authentique. La technique add_style_tag masque la modale de connexion de Glassdoor (appelée #HardsellOverlay) sans cliquer. que « tout le contenu est toujours là, il est simplement recouvert par l’overlay » — le HTML contient les données, que la modale soit affichée ou non.
Vous devriez voir une fenêtre Chrome s’ouvrir, aller vers la page de recherche d’emploi Glassdoor et afficher les cartes d’offres sans que la popup de connexion ne bloque l’écran.
Étape 3 : extraire les offres d’emploi Glassdoor
Identifier des sélecteurs stables
Glassdoor randomise les noms de classes CSS à chaque build — donc le sélecteur .jobCard_xyz123 d’un tutoriel 2023 ne renverra plus rien aujourd’hui, sans même signaler d’erreur. Utilisez plutôt les attributs data-test, qui correspondent à la convention QA interne de Glassdoor et restent stables entre les déploiements.
Voici la référence des sélecteurs pour les champs des offres d’emploi :
| Champ | Sélecteur |
|---|---|
| Conteneur de carte d’offre | [data-test="jobListing"] |
| Titre du poste | [data-test="job-title"] |
| Lien de l’offre | a[data-test="job-link"] |
| Nom de l’entreprise | [data-test="employer-name"] |
| Localisation | [data-test="emp-location"] |
| Fourchette salariale | [data-test="detailSalary"] |
| Note de l’entreprise | [data-test="rating"] |
| Date de publication | [data-test="job-age"] |
| Pagination suivante | [data-test="pagination-next"] |
Extraire les données des offres
1from parsel import Selector
2import csv, random, time
3def scrape_jobs(page, max_pages=5):
4 all_jobs = []
5 for page_num in range(1, max_pages + 1):
6 html = page.content()
7 sel = Selector(text=html)
8 cards = sel.css('[data-test="jobListing"]')
9 if not cards:
10 print(f"Page {page_num} : aucune carte trouvée — blocage possible ou sélecteur modifié.")
11 break
12 for card in cards:
13 job = {
14 "title": card.css('[data-test="job-title"]::text').get("").strip(),
15 "company": card.css('[data-test="employer-name"]::text').get("").strip(),
16 "location": card.css('[data-test="emp-location"]::text').get("").strip(),
17 "salary": card.css('[data-test="detailSalary"]::text').get("").strip(),
18 "rating": card.css('[data-test="rating"]::text').get("").strip(),
19 "link": card.css('a[data-test="job-link"]::attr(href)').get(""),
20 "posted": card.css('[data-test="job-age"]::text').get("").strip(),
21 }
22 if job["link"] and not job["link"].startswith("http"):
23 job["link"] = "https://www.glassdoor.com" + job["link"]
24 all_jobs.append(job)
25 print(f"Page {page_num} : {len(cards)} offres extraites")
26 # Pagination
27 next_btn = page.query_selector('[data-test="pagination-next"]')
28 if next_btn and page_num < max_pages:
29 next_btn.click()
30 time.sleep(random.uniform(3, 8))
31 page.wait_for_selector("[data-test='jobListing']")
32 else:
33 break
34 return all_jobsEnregistrer en CSV
1def save_to_csv(jobs, filename="glassdoor_jobs.csv"):
2 if not jobs:
3 print("Aucune offre à enregistrer.")
4 return
5 keys = jobs[0].keys()
6 with open(filename, "w", newline="", encoding="utf-8") as f:
7 writer = csv.DictWriter(f, fieldnames=keys)
8 writer.writeheader()
9 writer.writerows(jobs)
10 print(f"{len(jobs)} offres enregistrées dans {filename}")À propos des limites de pagination : Glassdoor plafonne les résultats de recherche à environ 30 pages, quel que soit le volume total. Si vous avez besoin de couvrir davantage de données, utilisez des filtres (localisation, type de poste, fourchette de salaire) pour réduire chaque requête plutôt que d’essayer de dépasser ce plafond.
Dans mes tests, l’extraction de 5 pages d’offres d’emploi (environ 75 postes) a pris autour de 45 secondes avec des délais aléatoires. Le faire manuellement aurait demandé au moins 20 minutes de copier-coller.
Étape 4 : extraire les avis Glassdoor
C’est la section qu’aucun autre tutoriel ne propose avec du code réellement fonctionnel. Les avis sont là où se cache la vraie intelligence employeur — analyse de sentiment, signaux culturels, alertes managériales.
Aller sur la page des avis
Les URL d’avis suivent ce format : /Reviews/{Company}-Reviews-E{id}.htm. Vous pouvez trouver l’ID de l’employeur en recherchant une entreprise sur Glassdoor et en regardant l’URL.
1def navigate_to_reviews(page, company_reviews_url):
2 page.goto(company_reviews_url)
3 page.add_style_tag(content="""
4 #HardsellOverlay, .LoginModal { display: none !important; }
5 body { overflow: auto !important; position: initial !important; }
6 """)
7 page.wait_for_selector('[data-test="review"]', timeout=15000)L’endpoint BFF caché (la méthode la plus propre)
Voici la découverte la plus importante de mes recherches : les avis Glassdoor disposent d’une API JSON interne fonctionnelle qui évite complètement le parsing HTML. Le documente cet endpoint, et il est bien plus fiable que le scraping du DOM.
1import json, re, requests
2def get_review_ids(page):
3 """Extraire employerId et dynamicProfileId depuis le HTML de la page d’avis."""
4 html = page.content()
5 sel = Selector(text=html)
6 script_text = sel.xpath(
7 "//script[contains(text(), 'profileId')]/text()"
8 ).get("")
9 employer_match = re.search(r'"employer"\s*:\s*(\{[^}]+\})', script_text)
10 if employer_match:
11 meta = json.loads(employer_match.group(1))
12 return meta.get("id"), meta.get("profileId")
13 return None, None
14def fetch_reviews_bff(page, employer_id, profile_id, max_pages=5):
15 """Appeler l’endpoint BFF interne de Glassdoor pour obtenir des avis structurés."""
16 all_reviews = []
17 cookies = {c["name"]: c["value"] for c in page.context.cookies()}
18 for pg in range(1, max_pages + 1):
19 payload = {
20 "applyDefaultCriteria": True,
21 "employerId": employer_id,
22 "dynamicProfileId": profile_id,
23 "employmentStatuses": ["REGULAR", "PART_TIME"],
24 "language": "eng",
25 "onlyCurrentEmployees": False,
26 "page": pg,
27 "pageSize": 10,
28 "sort": "DATE",
29 "textSearch": "",
30 }
31 resp = requests.post(
32 "https://www.glassdoor.com/bff/employer-profile-mono/employer-reviews",
33 json=payload,
34 cookies=cookies,
35 headers={"Content-Type": "application/json"},
36 )
37 if resp.status_code != 200:
38 print(f"BFF a renvoyé {resp.status_code} à la page {pg}")
39 break
40 data = resp.json()
41 reviews = data.get("data", {}).get("employerReviews", {}).get("reviews", [])
42 total_pages = data.get("data", {}).get("employerReviews", {}).get("numberOfPages", 1)
43 for r in reviews:
44 all_reviews.append({
45 "title": r.get("summary", ""),
46 "rating": r.get("ratingOverall"),
47 "pros": r.get("pros", ""),
48 "cons": r.get("cons", ""),
49 "author_role": r.get("jobTitle", {}).get("text", ""),
50 "date": r.get("reviewDateTime", ""),
51 "recommend": r.get("isRecommend"),
52 })
53 print(f"Page avis {pg}/{total_pages} : {len(reviews)} avis récupérés")
54 if pg >= total_pages:
55 break
56 time.sleep(random.uniform(3, 6))
57 return all_reviewsL’endpoint BFF donne du JSON propre avec tous les champs d’avis — aucun parsing HTML, aucun sélecteur CSS à casser. Il vous faut des cookies de session provenant d’un contexte Playwright authentifié (voir l’étape 6 ci-dessous), et il faut d’abord extraire employerId et dynamicProfileId depuis le HTML de la page d’avis.
Sélecteurs HTML de secours pour les avis
Si l’endpoint BFF change ou si vous préférez le parsing DOM, voici les sélecteurs data-test stables :
| Champ | Sélecteur |
|---|---|
| Conteneur d’avis | [data-test="review"] |
| Titre | [data-test="review-title"] |
| Note globale | [data-test="overall-rating"] |
| Points positifs | [data-test="pros"] |
| Points négatifs | [data-test="cons"] |
| Date | [data-test="review-date"] |
| Rôle de l’auteur | [data-test="author-jobTitle"] |
Étape 5 : extraire les données salariales Glassdoor
Les pages salaire sont entièrement protégées par connexion. Vous devez disposer d’une session authentifiée (étape 6) avant que ce code ne renvoie de vraies données.
Aller sur la page des salaires
Les URL salaire suivent ce format : /Salary/{Company}-Salaries-E{id}.htm, avec pagination _P{n}.htm.
1def scrape_salaries(page, salary_url, max_pages=3):
2 all_salaries = []
3 for pg in range(1, max_pages + 1):
4 url = salary_url if pg == 1 else salary_url.replace(".htm", f"_P{pg}.htm")
5 page.goto(url)
6 page.add_style_tag(content="""
7 #HardsellOverlay { display: none !important; }
8 body { overflow: auto !important; position: initial !important; }
9 """)
10 time.sleep(random.uniform(3, 7))
11 html = page.content()
12 sel = Selector(text=html)
13 items = sel.css('[data-test="salary-item"]')
14 if not items:
15 print(f"Page salaire {pg} : aucun élément — verrou de connexion ou blocage possible.")
16 break
17 for item in items:
18 salary = {
19 "job_title": item.css('[class*="SalaryItem_jobTitle__"]::text').get("").strip(),
20 "salary_range": item.css('[class*="SalaryItem_salaryRange__"]::text').get("").strip(),
21 "count": item.css('[class*="SalaryItem_salaryCount__"]::text').get("").strip(),
22 }
23 all_salaries.append(salary)
24 print(f"Page salaire {pg} : {len(items)} entrées extraites")
25 return all_salariesRemarquez le motif [class*="SalaryItem_jobTitle__"] basé sur un préfixe. La page salaire de Glassdoor utilise des noms de classes CSS module hachés (par exemple SalaryItem_jobTitle__XWGpT) dont le suffixe aléatoire change à chaque déploiement. Le préfixe, lui, reste stable. Ne hardcodez jamais le nom complet de la classe.
Étape 6 : franchir le mur de connexion Glassdoor
C’est l’étape clé qui débloque les salaires et le texte complet des avis. L’approche : se connecter une fois manuellement dans un navigateur visible, enregistrer l’état de session authentifié, puis le réutiliser pour toutes les exécutions suivantes.
Enregistrer votre session authentifiée
Lancez ce script une seule fois. Il ouvre une fenêtre Chrome, va sur la page de connexion Glassdoor (qui redirige désormais vers Indeed Login) et attend que vous vous connectiez manuellement :
1import asyncio
2from pathlib import Path
3from patchright.async_api import async_playwright
4STATE_FILE = Path("glassdoor_state.json")
5async def login_and_save():
6 async with async_playwright() as p:
7 browser = await p.chromium.launch(headless=False, channel="chrome")
8 context = await browser.new_context(
9 viewport={"width": 1366, "height": 800},
10 locale="en-US",
11 )
12 page = await context.new_page()
13 await page.goto("https://www.glassdoor.com/profile/login_input.htm")
14 print("Connectez-vous dans la fenêtre du navigateur, puis appuyez sur Entrée ici...")
15 input()
16 await context.storage_state(path=str(STATE_FILE))
17 print(f"Session enregistrée dans {STATE_FILE}")
18 await browser.close()
19asyncio.run(login_and_save())Après vous être connecté et avoir appuyé sur Entrée, Patchright enregistre tous les cookies et le local storage dans glassdoor_state.json. Ce fichier contient votre gdId, GSESSIONID, cf_clearance et les jetons d’authentification.
Réutiliser la session pour scraper
Toutes les exécutions suivantes chargent l’état enregistré — plus besoin de se connecter manuellement :
1async def scrape_with_auth(target_url):
2 async with async_playwright() as p:
3 browser = await p.chromium.launch(headless=True, channel="chrome")
4 context = await browser.new_context(
5 storage_state="glassdoor_state.json"
6 )
7 page = await context.new_page()
8 await page.goto(target_url)
9 await page.add_style_tag(
10 content="#HardsellOverlay{display:none!important}"
11 )
12 await page.wait_for_load_state("networkidle")
13 html = await page.content()
14 await browser.close()
15 return htmlLa session enregistrée dure en général 20 à 30 minutes d’utilisation active avant que Glassdoor ne redemande une vérification. Pour les longues exécutions, ajoutez un contrôle : si une page censée contenir des données renvoie zéro résultat, relancez le script de connexion pour rafraîchir votre fichier de session.
Détecter et fermer la popup de connexion
Pour les pages partiellement verrouillées (offres visibles mais modale en surimpression), la méthode d’injection CSS vue plus haut fonctionne :
1page.add_style_tag(content="""
2 #HardsellOverlay, .LoginModal { display: none !important; }
3 body { overflow: auto !important; position: initial !important; }
4""")Cela ne marche que lorsque le HTML contient déjà les données sous l’overlay. Pour les pages totalement protégées côté serveur (salaires, pages d’avis profondes), la session authentifiée de l’étape 6 est la seule solution.
Conseils pour garder votre scraper Glassdoor opérationnel
Glassdoor met souvent à jour son front-end. Voici comment rendre votre scraper plus solide.
Préférez les attributs data-test aux noms de classes
Glassdoor randomise les noms de classes CSS, mais conserve généralement des attributs data-test stables. Préférez toujours [data-test="jobListing"] à .jobCard_abc123. Quand data-test n’existe pas (comme pour certains champs salaire), utilisez le motif de correspondance par préfixe : [class*="SalaryItem_jobTitle__"].
Faites tourner les proxys et randomisez les délais
Utilisez des proxys résidentiels rotatifs — les IP de datacenter sont challengées presque immédiatement. Ajoutez des pauses aléatoires de 3 à 8 secondes entre les chargements de page (5 à 15 secondes pour les longues exécutions). Si possible, évitez les heures ouvrées aux États-Unis, quand la détection comportementale de Cloudflare est la plus agressive.
Surveillez les cassures
Ajoutez un contrôle simple à votre scraper : si une page censée contenir des données renvoie zéro enregistrement extrait, considérez cela comme un problème de sélecteur (et non comme un résultat vide) et déclenchez une alerte. Lancez un petit test de scraping chaque semaine pour repérer les cassures tôt — Glassdoor déploie des changements front-end sans prévenir.
Utilisez le chemin rapide __NEXT_DATA__ quand c’est possible
Glassdoor est une application Next.js + Apollo GraphQL. De nombreuses pages embarquent une balise <script id="__NEXT_DATA__"> contenant tout le cache GraphQL au format JSON. L’analyser est bien plus robuste que le scraping du DOM et :
1import json
2def extract_next_data(html):
3 sel = Selector(text=html)
4 raw = sel.css("script#__NEXT_DATA__::text").get()
5 if raw:
6 return json.loads(raw)["props"]["pageProps"].get("apolloCache", {})
7 return NoneCela renvoie le cache Apollo structuré avec tous les champs d’offres, d’avis et de salaires — aucun sélecteur CSS nécessaire. C’est la stratégie d’extraction la plus robuste disponible, puisqu’elle repose sur les mêmes données que l’interface React de Glassdoor.
Passez le code : extraire Glassdoor avec Thunderbit (sans Python)
Tout le monde ne lit pas ce guide en tant que développeur. Les équipes RH, les recruteurs, les analystes ops sales et les chercheurs marché ont aussi besoin des données Glassdoor — sans avoir à gérer des contextes Playwright et des proxys rotatifs.
est une extension Chrome d’AI Web Scraper capable d’extraire les mêmes données d’offres, d’avis et de salaires sans écrire une seule ligne de code. Je travaille chez Thunderbit, donc je préfère être transparent — mais si je l’inclus ici, c’est parce qu’il résout vraiment les deux problèmes les plus compliqués du scraping Glassdoor.
Comment Thunderbit fonctionne sur Glassdoor
Le flux se fait en deux clics :
- Ouvrez n’importe quelle page Glassdoor dans Chrome (recherche d’offres, avis d’entreprise, page salaire)
- Cliquez sur AI Suggest Fields dans la barre latérale Thunderbit — l’IA lit le DOM de la page et propose les colonnes (titre du poste, entreprise, note, fourchette salariale, pros, cons, etc.)
- Cliquez sur Scrape — les données sont extraites dans un tableau sans sélecteurs CSS ni code d’automatisation navigateur
Thunderbit propose un qui récupère plus de 23 champs par société en une seule exécution. Pour les offres, les avis ou les salaires, le workflow générique AI Suggest Fields fonctionne avec n’importe quelle URL Glassdoor.
Gérer le mur de connexion sans code
C’est l’avantage structurel de Thunderbit sur Glassdoor. Le Browser Mode s’exécute dans votre propre session Chrome — si vous êtes déjà connecté à Glassdoor dans Chrome, Thunderbit hérite automatiquement de vos cookies. Le mur de connexion qui bloque les scrapers côté serveur ne s’applique donc pas. Pas de gestion de cookies, pas de contexte persistant, pas de code de session.
Scraping de sous-pages pour enrichir les données
Partez d’une page de liste (par exemple 30 entreprises issues d’une recherche), laissez Thunderbit énumérer les lignes, puis activez le pour visiter la page d’avis ou de salaires de chaque entreprise et enrichir le tableau avec des descriptions complètes, le texte des avis ou les détails salariaux.
Export vers vos outils métier
Contrairement aux scripts Python qui produisent du CSV ou du JSON, Thunderbit exporte directement vers Google Sheets, Airtable, Notion ou Excel — gratuitement sur tous les plans. C’est particulièrement pratique pour les équipes qui ont besoin de partager et d’analyser les données ensemble.
Python vs Thunderbit : quand utiliser quoi ?
| Scénario | Approche recommandée |
|---|---|
| Construire un pipeline de données récurrent | Python + Patchright |
| Recherche ponctuelle ou petit projet d’équipe | Thunderbit |
| Besoin de contrôle programmatique sur chaque champ | Python |
| Non-développeur ayant besoin de données Glassdoor aujourd’hui | Thunderbit |
| Scraper 1 000+ pages en une seule exécution | Python + proxys |
| Scraper 30 entreprises avec enrichissement | Les deux conviennent — Thunderbit est plus rapide à mettre en place |
Les tarifs Thunderbit commencent à gratuit (6 pages/mois), avec le pour 3 000 crédits. À raison d’1 crédit par ligne de sortie (2 crédits pour le scraping de sous-pages), cela suffit pour environ 33 exécutions de 30 entreprises enrichies par mois.
Est-il légal de scraper Glassdoor ?
Je vais rester bref et factuel. Les de Glassdoor interdisent explicitement le scraping automatisé : « Vous ne pouvez pas utiliser de robot, spider, scraper… pour accéder aux Services à quelque fin que ce soit sans notre autorisation écrite expresse. »
Le cadre juridique est toutefois plus nuancé qu’une simple clause de CGU :
- (N.D. Cal., janv. 2024) : le tribunal a estimé que si vous ne vous connectez jamais, vous n’avez jamais accepté les CGU, et le scraping public hors connexion ne les viole pas
- hiQ Labs v. LinkedIn (9e circuit) : le CFAA ne s’applique pas à la collecte automatisée de données publiquement accessibles — mais les faux comptes et le scraping connecté sont une autre histoire
- Van Buren v. United States (Cour suprême, 2021) : a restreint la notion de « dépassement d’accès autorisé » sous le CFAA
Conclusion pratique : extraire des offres d’emploi publiques sans se connecter se situe dans une zone juridique relativement plus sûre. En revanche, scraper avec une session connectée signifie que vous avez accepté les CGU à l’inscription, et celles-ci l’interdisent explicitement. Cela vaut autant pour les scripts Python que pour le Browser Mode de Thunderbit.
Quelques bonnes pratiques éthiques à suivre quoi qu’il arrive :
- Limiter fortement le débit, bien en dessous de la vitesse humaine de navigation
- Ne pas scraper ni revendre des informations personnelles identifiables de contributeurs d’avis
- Respecter les directives du robots.txt
- Récupérer uniquement les champs dont vous avez réellement besoin
Conclusion : quelle méthode vous convient le mieux ?
Ce guide a couvert les trois types de données Glassdoor — offres, avis et salaires — avec du code 2025 fonctionnel qui tient compte de la migration vers Indeed Login, de Cloudflare Bot Management et de la rotation des classes CSS modules qui a cassé tous les anciens tutoriels.
Voici la grille de décision :
| Votre situation | Meilleure option |
|---|---|
| Développeur qui construit un pipeline de données | Python + Patchright (suivez le guide pas à pas ci-dessus) |
| Recherche ponctuelle ou extractions récurrentes légères | Thunderbit (sans code, dans le navigateur) |
| Besoin uniquement d’offres d’emploi basiques à petite échelle | Vérifiez d’abord si l’accès à l’API Glassdoor est encore disponible (probablement non) |
| Besoin spécifique de données salariales ou d’avis | Il faut utiliser Python ou Thunderbit — l’API n’a jamais couvert ces données |
| Équipe de non-développeurs qui doit partager les données | Thunderbit → export vers Google Sheets |
Les protections de Glassdoor continueront d’évoluer. Les sélecteurs casseront. De nouveaux défis apparaîtront. Gardez ce guide sous la main — et si vous voulez aller plus loin dans les outils et techniques de web scraping, consultez nos articles sur les , et . Vous pouvez aussi regarder les tutoriels sur la .
FAQ
1. Peut-on scraper Glassdoor sans se connecter ?
Oui, pour la plupart des données d’offres d’emploi et les notes générales d’entreprise. Non, pour le détail complet des salaires ou le texte intégral des avis au-delà des premières pages. Le #HardsellOverlay est une modale en CSS uniquement — le HTML sous-jacent contient encore les données de la première page — mais le contenu plus profond est verrouillé côté serveur derrière le mur « give-to-get » de Glassdoor.
2. Quelle bibliothèque Python est la plus adaptée pour scraper Glassdoor en 2025 ?
Patchright (un fork furtif de Playwright) est la recommandation par défaut. Il corrige la fuite CDP Runtime.Enable que Playwright standard présente et que Cloudflare vérifie explicitement. Pour les pages qui embarquent __NEXT_DATA__ dans le HTML initial, curl_cffi avec impersonate="chrome124" est 10 à 20 fois plus rapide, mais ne peut pas gérer les pages protégées par connexion.
3. Comment éviter d’être bloqué en scrapant Glassdoor ?
Utilisez Patchright ou rebrowser-playwright (pas Playwright standard ni Selenium). Faites tourner des proxys résidentiels — les IP de datacenter sont bloquées presque immédiatement. Ajoutez des délais aléatoires de 3 à 8 secondes entre les pages. Conservez les cookies (gdId, cf_clearance, GSESSIONID) d’une requête à l’autre. Attendez-vous à une fenêtre de session de 20 à 30 minutes avant une nouvelle vérification.
4. Existe-t-il une API Glassdoor que je peux utiliser à la place du scraping ?
En pratique, non. L’ancienne API Partner est , aucun endpoint public d’avis n’a jamais existé, et il n’existe pas de voie de migration via l’API Publisher d’Indeed. Le scraping ou un outil sans code comme Thunderbit sont les seules options réalistes pour les avis et les salaires.
5. À quelle fréquence les scrapers Glassdoor cassent-ils ?
Souvent. Glassdoor déploie des changements front-end sans prévenir, et les hachages des classes CSS modules changent à chaque build. Les stratégies d’extraction les plus stables sont : (1) les sélecteurs d’attributs data-test, (2) le bloc JSON __NEXT_DATA__, et (3) l’endpoint BFF interne pour les avis. Ajoutez un contrôle de retour vide et lancez un petit test hebdomadaire pour détecter les ruptures rapidement.
En savoir plus