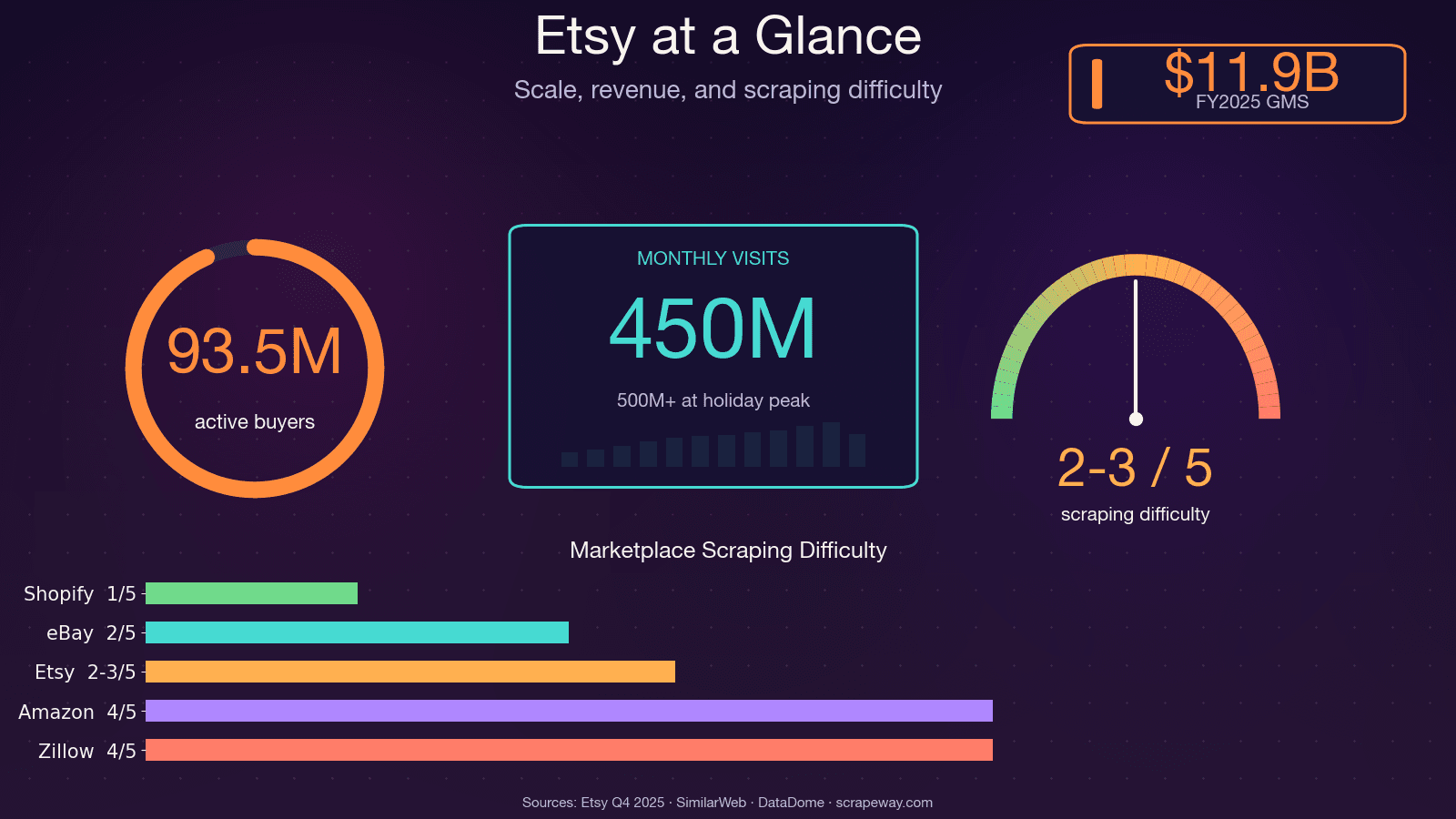
Etsy compte plus de 100 millions d’annonces actives, 5,6 millions de vendeurs et environ 450 millions de visites mensuelles. Autant dire qu’il y a là une énorme quantité de données publiques sur les prix, les tendances, les avis et les concurrents — et si vous avez déjà essayé de les collecter à la main, vous savez à quel point c’est pénible.
J’ai passé un week-end à essayer de cataloguer manuellement les produits d’un concurrent pour une étude de marché. Au 30e produit, je remettais en question toutes les décisions qui m’avaient mené à ce tableau Excel. Le fait est qu’Etsy contient des données extrêmement utiles pour l’analyse des prix, le développement produit, l’identification de niches et le benchmarking des vendeurs — mais seulement si vous pouvez réellement les récupérer à grande échelle. C’est précisément l’objet de ce guide : un tutoriel unique qui explique comment extraire Etsy avec Python sur les quatre grands types de pages (résultats de recherche, pages produit, pages boutique et avis), avec en plus des conseils honnêtes sur les défenses anti-bot d’Etsy et une alternative sans code pour celles et ceux qui préfèrent éviter totalement le scripting.
Que signifie extraire Etsy avec Python ?
Le web scraping, en termes simples, consiste à écrire du code qui visite des pages web et en extrait automatiquement les données qui vous intéressent — noms de produits, prix, descriptions, images, notes, avis, informations sur la boutique — puis à les organiser dans un format structuré comme un tableur ou une base de données.
Python est le langage de référence pour ce type de travail. Il est facile à prendre en main, bénéficie d’une immense communauté et propose un écosystème de bibliothèques particulièrement riche pour le scraping : Requests (pour récupérer les pages), BeautifulSoup (pour analyser le HTML), Selenium et Playwright (pour l’automatisation de navigateur), et pandas (pour organiser et exporter les données). Python figure régulièrement parmi les 3 langages les plus populaires dans l’enquête annuelle de Stack Overflow auprès des développeurs, et ses bibliothèques de scraping comptent parmi les plus téléchargées sur PyPI.
Quand vous extraisez Etsy, vous récupérez les données contenues dans le HTML (et parfois dans du JSON caché) qu’Etsy sert à votre navigateur. Parmi les données que vous pouvez extraire :
- Noms des produits, prix, descriptions, images et variantes
- Informations sur le vendeur/la boutique (nom, nombre de ventes, localisation, note)
- Notes et texte intégral des avis
- Listes des résultats de recherche, catégories et signaux de tendance
Pourquoi extraire Etsy ? Cas d’usage concrets qui créent du ROI
Le scraping d’Etsy n’est pas seulement un exercice technique — c’est un avantage concurrentiel. Que vous soyez vendeur, chef de produit ou analyste de données, disposer de données Etsy structurées à portée de main peut avoir un impact direct sur vos résultats.
| Cas d’usage | Ce que vous extrayez | Qui en profite | Impact business |
|---|---|---|---|
| Analyse de prix concurrentiels | Résultats de recherche + prix des produits | Ops e-commerce, vendeurs | La tarification dynamique peut augmenter le chiffre d’affaires de 5 à 22 % en moyenne |
| Découverte de niches et de tendances | Résultats de recherche, annonces en tendance | Fondateurs, analystes | Repérer tôt les niches porteuses (par ex. « preppy pajamas » a vu sa recherche grimper de +1 112 %) |
| Développement et amélioration produit | Avis, détails produit | Équipes produit | Une marque d’ustensiles de cuisine a récupéré la 1re place de Best Seller en 60 jours grâce aux données de sentiment des avis |
| SEO et recherche de mots-clés | Résultats de recherche, titres/tags produit | Équipes marketing | Identifier des mots-clés à forte demande et faible concurrence |
| Benchmarking des vendeurs | Pages boutique, nombre de ventes | Équipes commerciales, analystes | Construire des listes de prospects qualifiés pour 0,01 à 0,10 $/enregistrement au lieu d’acheter des listes |
| Suivi des stocks et de la disponibilité | Disponibilité des produits | Ops e-commerce | Réagir plus vite aux changements de stock des concurrents |
Chacun de ces cas d’usage nécessite des données provenant de différents types de pages Etsy — c’est exactement pourquoi ce tutoriel couvre les quatre.
Gain de temps : manuel vs automatisé
- Recherche Etsy manuelle : 30 à 45 minutes par produit (50 à 75 heures pour 100 produits)
- Scraping automatisé : 100 annonces en 2 à 5 minutes
- Le scraping alimenté par l’IA est avec une précision pouvant atteindre 99,5 %
API Etsy vs web scraping : que choisir ?
Avant d’écrire la moindre ligne de code, une question mérite d’être posée : faut-il utiliser l’API officielle d’Etsy ou extraire directement le site ? C’est une question que je vois revenir sans cesse sur les forums, et la réponse dépend des données dont vous avez besoin.
Ce que l’API Etsy peut faire — et ne peut pas faire
Etsy propose une API v3 avec authentification OAuth 2.0. Elle permet d’accéder aux données de votre propre boutique — annonces, commandes, reçus. Mais elle présente de vraies limites :
- Données des concurrents : l’API est surtout limitée à votre propre boutique. Vous ne pouvez pas récupérer les prix, ventes ou annonces d’un autre vendeur.
- Avis : il n’existe pas de point d’accès robuste pour récupérer en masse le texte complet des avis.
- Limites de débit : 10 requêtes/seconde, 10 000 requêtes/jour par défaut. Le plafond d’offset est de 12 000 enregistrements.
- Usage IA/ML : rejeté explicitement lors de l’examen de l’application.
- Documentation : les plaintes de la communauté sont nombreuses — exemples médiocres, endpoints obsolètes, support lent.
Quand le web scraping est la meilleure option
Si vous avez besoin d’intelligence concurrentielle, d’analyse du sentiment des avis, d’analyse croisée entre boutiques ou de données au-delà de ce que l’API expose, le scraping est la bonne voie. En contrepartie, vous devrez faire face aux défenses anti-bot d’Etsy (nous y reviendrons) et consacrer du temps à la configuration.
Tableau comparatif : API vs scraping vs sans code
| Critère | API officielle Etsy | Scraping web en Python | Thunderbit (sans code) |
|---|---|---|---|
| Accès aux prix des produits | ✅ (champs limités) | ✅ HTML/JSON-LD complet | ✅ L’IA extrait tout champ visible |
| Données d’avis | ❌ Indisponibles en masse | ✅ Via endpoint/HTML des avis | ✅ Scraping des sous-pages |
| Données des boutiques concurrentes | ❌ Votre boutique uniquement | ✅ Toute boutique publique | ✅ Toute boutique publique |
| Authentification requise | ✅ OAuth 2.0 | ⚠️ Cookies pour les données connectées | ⚠️ Scraping via navigateur pour la connexion |
| Risque anti-bot | Aucun | ÉLEVÉ (DataDome) | Pris en charge (natif navigateur) |
| Temps de configuration | Moyen (clés API, OAuth) | Élevé (code + proxies) | ~2 minutes |
Si vous avez besoin de données concurrentielles, d’avis ou d’analyses entre plusieurs boutiques, l’API ne suffit tout simplement pas. C’est le constat honnête.
Choisissez votre approche Python avant d’écrire une ligne de code
Une question que je vois tout le temps sur Reddit et Stack Overflow : « Dois-je utiliser Requests + BeautifulSoup, Selenium, une API de proxy, ou autre chose ? » La bonne réponse dépend de votre niveau, de votre budget et de votre cas d’usage.
| Approche | Idéale pour | Courbe d’apprentissage | Gère le JS ? | Gestion anti-bot | Coût |
|---|---|---|---|---|---|
| Requests + BeautifulSoup | Développeurs voulant garder le contrôle | Moyenne | ❌ | Manuelle (headers, proxies) | Gratuit + coût des proxies |
| Selenium / Playwright | Pages riches en JS, flux de connexion | Élevée | ✅ | Partielle (empreinte navigateur) | Gratuit + coût des proxies |
| Services d’API de proxy | Passage à l’échelle + contournement anti-bot | Moyenne | ✅ (via API) | ✅ Intégré | 49 $+/mois |
| Thunderbit (sans code) | Non-développeurs, extraction rapide | Très faible | ✅ (natif navigateur) | ✅ (session navigateur) | Offre gratuite disponible |
Si vous voulez un contrôle total et que Python vous convient, optez pour Requests + BeautifulSoup. Si vous avez besoin du rendu JS ou de flux de connexion, utilisez Selenium. Si vous voulez contourner l’anti-bot à grande échelle, envisagez un service de proxy. Et si vous voulez des données Etsy sans écrire ni maintenir de code, Thunderbit mérite un coup d’œil — j’y reviens plus loin.
Comment Etsy se défend : comprendre la protection anti-bot DataDome
La plupart des guides de scraping vous disent simplement « utilisez un proxy » et passent à autre chose. Ce n’est pas suffisant pour Etsy. Etsy utilise DataDome, l’un des systèmes anti-bot les plus agressifs du web. présente Etsy comme un succès, en notant que les scrapers représentaient autrefois environ 1 % des coûts informatiques d’Etsy.
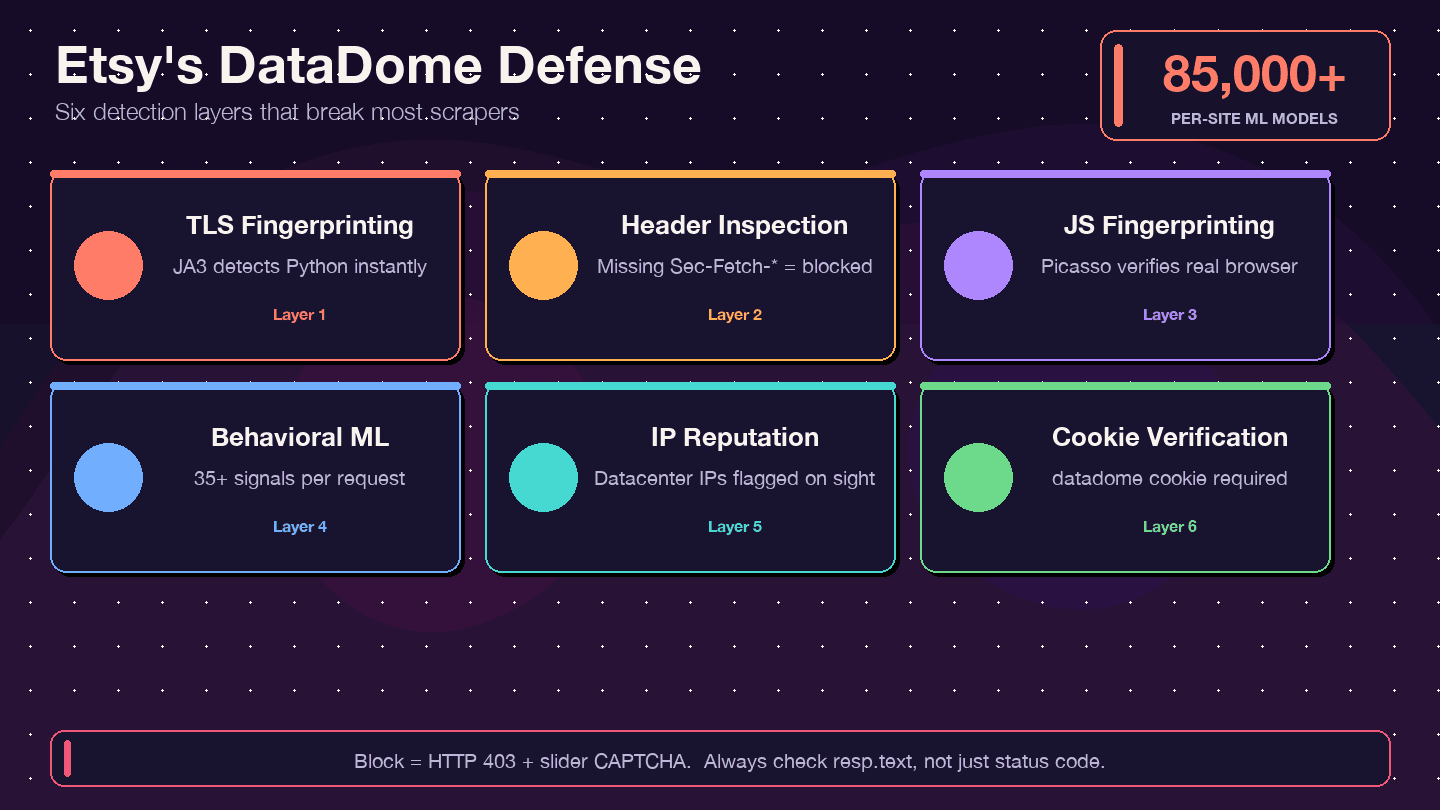
Qu’est-ce que DataDome et comment ça fonctionne ?
DataDome ne se contente pas de vérifier votre adresse IP. Il déploie une détection multicouche :
- Empreinte TLS (JA3) : la bibliothèque
requestsde Python a une signature TLS distinctive que DataDome peut repérer instantanément. - Inspection des en-têtes/protocoles HTTP : vérifie la présence d’en-têtes navigateur complets et cohérents — des en-têtes absents ou mal ordonnés sont un signal d’alerte.
- Empreinte JavaScript (protocole Picasso) : exécute des défis JS dans le navigateur pour vérifier que vous êtes bien un utilisateur réel.
- ML comportemental : analyse plus de 35 signaux par requête, avec plus de 85 000 modèles par site.
- Évaluation de la réputation IP : les IP de datacenter sont immédiatement signalées.
- Vérification des cookies : le cookie
datadomedoit être présent et valide.
Signes que vous êtes bloqué (et comment vérifier)
L’un des pièges les plus courants : vous recevez une réponse 200 OK, mais le HTML correspond en réalité à une page CAPTCHA, et non aux données attendues. Autres signes :
- Erreurs 403 Forbidden
- Boucles de redirection
- Le corps de la réponse contient un objet JavaScript
ddou un HTML CAPTCHA à curseur
Vérifiez toujours le corps de la réponse, pas seulement le code de statut. Test rapide :
1if "captcha" in resp.text.lower() or "datadome" in resp.text.lower():
2 print("Bloqué ! Une page CAPTCHA a été renvoyée à la place des données.")En-têtes et cookies qui réduisent la détection
Vous ne pouvez pas garantir que vous ne serez jamais bloqué, mais des en-têtes réalistes et une bonne gestion des cookies aident beaucoup :
1session = requests.Session()
2session.headers.update({
3 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/133.0.0.0 Safari/537.36",
4 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
5 "Accept-Language": "fr-FR,fr;q=0.9",
6 "Accept-Encoding": "gzip, deflate, br",
7 "Sec-Ch-Ua": '\"Chromium\";v=\"133\", \"Not-A.Brand\";v=\"99\", \"Google Chrome\";v=\"133\"',
8 "Sec-Ch-Ua-Mobile": "?0",
9 "Sec-Ch-Ua-Platform": '\"Windows\"',
10 "Sec-Fetch-Dest": "document",
11 "Sec-Fetch-Mode": "navigate",
12 "Sec-Fetch-Site": "none",
13 "Upgrade-Insecure-Requests": "1",
14})Autres points importants :
- Conservez les cookies entre les requêtes avec
requests.Session(). - Ajoutez des délais aléatoires (2 à 7 secondes) entre les requêtes.
- Simulez une chaîne de référents : visitez d’abord la page d’accueil, puis la recherche, puis les pages produit.
- À grande échelle, la rotation de proxies résidentiels est indispensable. Les IP de datacenter sont signalées presque immédiatement.
Ces techniques réduisent la détection mais ne l’éliminent pas. Pour du scraping à fort volume, vous aurez probablement besoin d’un service de proxy ou d’une approche basée sur navigateur.
Préparer votre environnement Python pour extraire Etsy
Avant de commencer :
- Niveau de difficulté : intermédiaire
- Temps nécessaire : environ 30 à 60 minutes (configuration + première extraction)
- Ce qu’il vous faut : Python 3.8+, pip, un éditeur de code, le navigateur Chrome (pour inspecter via DevTools)
Installer les dépendances
Créez un dossier de projet, configurez un environnement virtuel et installez les bibliothèques nécessaires :
1mkdir etsy-scraper && cd etsy-scraper
2python -m venv venv
3source venv/bin/activate # Sous Windows : venv\Scripts\activate
4pip install requests beautifulsoup4 lxml pandas- requests — récupère les pages web
- beautifulsoup4 — analyse le HTML
- lxml — analyseur HTML plus rapide (facultatif mais recommandé)
- pandas — structure et exporte les données vers CSV/Excel
Si vous avez besoin d’automatisation de navigateur plus tard (pour la connexion ou les pages riches en JS), installez aussi :
1pip install seleniumComprendre la structure des pages Etsy avant de coder
Voici une astuce qui fait gagner énormément de temps : Etsy intègre des données produit structurées dans des balises <script type="application/ld+json"> sur la plupart des pages. Ces données JSON-LD sont déjà organisées — nom du produit, prix, note, images — donc vous n’avez pas besoin de vous battre avec des sélecteurs CSS fragiles pour chaque champ.
Ouvrez n’importe quelle page produit Etsy, faites un clic droit, « Afficher le code source de la page », puis recherchez application/ld+json. Vous trouverez un bloc avec @type: Product contenant la plupart des données utiles. Les pages de résultats de recherche utilisent @type: ItemList.
Les sélecteurs CSS restent utiles comme solution de secours (pour les données absentes du JSON-LD, comme les détails d’expédition ou le texte des avis), mais le JSON-LD doit être votre premier réflexe.
Étape 1 : extraire les résultats de recherche Etsy avec Python
Les résultats de recherche sont le point de départ de la plupart des projets de scraping Etsy — que vous surveilliez une niche, suiviez les prix des concurrents ou construisiez une base de données produits.
Construire l’URL de recherche
Les URL de recherche Etsy suivent ce modèle :
1https://www.etsy.com/search?q={mot-clé}&ref=pagination&page={numéro_de_page}Pour les requêtes multi-mots, encodez les espaces dans l’URL (par ex. handmade+jewelry ou handmade%20jewelry). Le paramètre ref=pagination rend la requête plus proche d’une navigation réelle dans un navigateur.
Autres paramètres utiles : order (most_relevant, price_asc, price_desc, date_desc), min_price, max_price, ship_to, free_shipping=true. Chaque page renvoie 48 éléments.
Envoyer la requête et analyser le HTML
1import requests
2from bs4 import BeautifulSoup
3import json
4import time
5import random
6headers = {
7 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
8 "Accept-Language": "fr-FR,fr;q=0.9",
9 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
10}
11def scrape_etsy_search(query, max_pages=3):
12 all_products = []
13 for page in range(1, max_pages + 1):
14 url = f"https://www.etsy.com/search?q=\{query\}&ref=pagination&page=\{page\}"
15 resp = requests.get(url, headers=headers, timeout=30)
16 if "captcha" in resp.text.lower():
17 print(f"Blocage à la page \{page\}. Essayez d’ajouter des délais ou des proxies.")
18 break
19 soup = BeautifulSoup(resp.text, "lxml")
20 for script in soup.find_all("script", type="application/ld+json"):
21 data = json.loads(script.string)
22 if data.get("@type") == "ItemList":
23 for item in data.get("itemListElement", []):
24 all_products.append({
25 "name": item.get("name"),
26 "url": item.get("url"),
27 "image": item.get("image"),
28 "price": item.get("offers", {}).get("price"),
29 "currency": item.get("offers", {}).get("priceCurrency"),
30 "position": item.get("position"),
31 })
32 time.sleep(random.uniform(2, 5))
33 return all_productsExtraire les données des annonces depuis le JSON-LD
Le tableau itemListElement vous donne le nom, l’URL, l’image, le prix et la devise de chaque annonce. Si vous avez aussi besoin des notes en étoiles ou du nombre de résultats (pas toujours présents dans le JSON-LD), utilisez des sélecteurs CSS en secours :
- Carte d’annonce :
.v2-listing-card - Titre :
h3.v2-listing-card__title - Prix :
span.currency-value - Lien :
a.listing-link(href)
Gérer la pagination
Bouclez sur les pages et ajoutez un délai aléatoire entre chaque requête. Etsy renvoie généralement jusqu’à 20 à 250 pages selon la requête.
1results = scrape_etsy_search("handmade+jewelry", max_pages=5)
2print(f"{len(results)} produits extraits.")Pour une extraction sur 5 pages, cela m’a pris environ 20 secondes lors de mes tests — contre plus de 30 minutes de copier-coller manuel.
Étape 2 : extraire les pages produit Etsy avec Python
Une fois que vous avez une liste d’URL de produits issues de la recherche, l’étape suivante consiste à récupérer les détails de chaque fiche produit.
Récupérer la page produit
1def scrape_etsy_product(url):
2 resp = requests.get(url, headers=headers, timeout=30)
3 soup = BeautifulSoup(resp.text, "lxml")
4 for script in soup.find_all("script", type="application/ld+json"):
5 data = json.loads(script.string)
6 if data.get("@type") == "Product":
7 offers = data.get("offers", {})
8 price = offers.get("price") or offers.get("lowPrice")
9 rating_data = data.get("aggregateRating", {})
10 return {
11 "name": data.get("name"),
12 "description": data.get("description", "")[:500],
13 "brand": data.get("brand", {}).get("name") if isinstance(data.get("brand"), dict) else data.get("brand"),
14 "category": data.get("category"),
15 "price": price,
16 "currency": offers.get("priceCurrency"),
17 "availability": offers.get("availability"),
18 "rating": rating_data.get("ratingValue"),
19 "review_count": rating_data.get("reviewCount"),
20 "images": data.get("image", []),
21 "sku": data.get("sku"),
22 "material": data.get("material"),
23 }
24 return NoneGérer les variations de prix
Certains produits ont un seul offers.price. D’autres (avec variantes comme la taille ou la couleur) utilisent offers.lowPrice et offers.highPrice. Le code ci-dessus gère les deux en basculant de price vers lowPrice.
Extraire des champs supplémentaires via des sélecteurs CSS
Pour les données absentes du JSON-LD — informations de livraison, options de variantes, détails complets du vendeur — vous devrez utiliser des sélecteurs CSS :
- Titre :
h1[data-buy-box-listing-title] - Variantes :
select[data-selector-id]oudiv[data-option-set] - Livraison :
div.wt-text-captionà proximité de la section livraison
Le compromis : le JSON-LD est plus propre et plus stable face aux changements de mise en page. Les sélecteurs CSS sont plus fragiles mais couvrent davantage de champs.
Étape 3 : extraire les pages boutique Etsy avec Python
C’est la section que la plupart des guides concurrents passent complètement sous silence — alors qu’elle est sans doute la plus précieuse pour les équipes commerciales et les analystes concurrentiels.
Construire l’URL de la boutique et récupérer la page
1def scrape_etsy_shop(shop_name):
2 url = f"https://www.etsy.com/shop/\{shop_name\}"
3 resp = requests.get(url, headers=headers, timeout=30)
4 soup = BeautifulSoup(resp.text, "lxml")
5 # Métadonnées de boutique depuis le HTML (pas dans le JSON-LD)
6 sales_el = soup.select_one("div.shop-sales-reviews a")
7 rating_el = soup.find("input", {"name": "initial-rating"})
8 location_el = soup.select_one("div.shop-location")
9 shop_data = {
10 "name": shop_name,
11 "sales": sales_el.text.strip() if sales_el else None,
12 "rating": rating_el["value"] if rating_el else None,
13 "location": location_el.text.strip() if location_el else None,
14 }
15 # Annonces depuis le JSON-LD
16 listings = []
17 for script in soup.find_all("script", type="application/ld+json"):
18 data = json.loads(script.string)
19 if data.get("@type") == "ItemList":
20 for item in data.get("itemListElement", []):
21 listings.append({
22 "name": item.get("name"),
23 "url": item.get("url"),
24 "price": item.get("offers", {}).get("price"),
25 })
26 shop_data["listings"] = listings
27 return shop_dataCe que vous pouvez extraire des pages boutique
Le JSON-LD des pages boutique est de type @type: ItemList — il couvre les annonces produit, mais pas les métadonnées au niveau de la boutique comme le nombre de ventes, la localisation ou la note. Pour ces éléments, vous devez utiliser des sélecteurs CSS :
| Point de donnée | Sélecteur | Remarques |
|---|---|---|
| Nom de la boutique | h1 ou titre meta | Généralement présent dans le titre de la page |
| Ventes totales | div.shop-sales-reviews a | Texte du type « 12 345 ventes » |
| Note en étoiles | valeur de input[name="initial-rating"] | De 1 à 5 |
| Localisation | div.shop-location | Ville, pays |
| Membre depuis | div.shop-info | Texte de date |
Les données de boutique sont particulièrement utiles pour construire des listes de prospects, comparer les concurrents ou identifier les meilleurs vendeurs d’une niche.
Étape 4 : extraire les avis Etsy avec Python
Les avis font partie des données les plus précieuses — et les plus délicates — sur Etsy. Le texte complet, les notes et les dates des avis ne figurent pas dans le HTML initial de la page ; ils sont chargés via un endpoint API interne.
Méthode 1 : découvrir l’endpoint API interne des avis d’Etsy
Ouvrez une page produit dans Chrome, lancez les DevTools (F12), allez dans l’onglet Network, puis faites défiler jusqu’à la section des avis. Vous verrez une requête POST vers quelque chose comme :
1https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviewsCet endpoint renvoie des fragments HTML contenant les cartes d’avis. Pour l’utiliser, vous avez besoin de :
- listing_id — l’identifiant numérique de la fiche produit dans l’URL
- shop_id — à extraire du HTML de la page produit via une expression régulière
- csrf_nonce — à extraire d’une balise
<meta>de la page
Extraire les identifiants et le jeton CSRF
1import re
2def get_review_params(product_url):
3 resp = requests.get(product_url, headers=headers)
4 html = resp.text
5 listing_id = product_url.split("/")[-1].split("?")[0]
6 shop_id_match = re.search(r'"shopId"\s*:\s*(\d+)', html)
7 shop_id = shop_id_match.group(1) if shop_id_match else None
8 soup = BeautifulSoup(html, "lxml")
9 csrf_meta = soup.find("meta", {"name": "csrf_nonce"})
10 csrf = csrf_meta["content"] if csrf_meta else None
11 return listing_id, shop_id, csrfExtraire les avis avec pagination
1def scrape_reviews(listing_id, shop_id, csrf, max_pages=5):
2 session = requests.Session()
3 session.headers.update(headers)
4 all_reviews = []
5 for page in range(1, max_pages + 1):
6 payload = {
7 "specs": {
8 "deep_dive_reviews": {
9 "module_path": "neu/specs/deep_dive_reviews",
10 "listing_id": listing_id,
11 "shop_id": shop_id,
12 "page": page,
13 }
14 }
15 }
16 resp = session.post(
17 "https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews",
18 json=payload,
19 headers={"x-csrf-token": csrf, "Content-Type": "application/json"},
20 )
21 data = resp.json()
22 html_fragment = data.get("output", {}).get("deep_dive_reviews", "")
23 review_soup = BeautifulSoup(html_fragment, "lxml")
24 for card in review_soup.select("div.review-card"):
25 rating_el = card.find("input", {"name": "rating"})
26 text_el = card.select_one("div.wt-text-body")
27 user_el = card.select_one("a[data-review-username]")
28 date_el = card.select_one("p.wt-text-body-small")
29 all_reviews.append({
30 "rating": rating_el["value"] if rating_el else None,
31 "text": text_el.text.strip() if text_el else None,
32 "reviewer": user_el.text.strip() if user_el else None,
33 "date": date_el.text.strip() if date_el else None,
34 })
35 time.sleep(random.uniform(2, 5))
36 return all_reviewsMéthode 2 : analyser les avis depuis le HTML (solution de secours)
Si l’approche API échoue (par exemple à cause de problèmes de jeton CSRF), vous pouvez analyser la première page d’avis directement depuis le HTML de la page produit. Limite : seul le premier lot d’avis se trouve dans le HTML statique. Pour aller plus loin, il faut l’API ou un outil d’automatisation du navigateur comme Selenium.
Gérer les données nécessitant une connexion : extraire votre propre boutique Etsy
C’est un angle qu’aucun autre tutoriel ne couvre, mais qui répond à un besoin bien réel — notamment pour les vendeurs Etsy qui veulent extraire leurs propres commandes, revenus et statistiques.
Le problème : requests seul ne peut pas accéder à votre tableau de bord Etsy, car il ne transporte pas vos cookies de session de connexion.
Option 1 : Selenium avec connexion manuelle et capture des cookies
Utilisez Selenium pour ouvrir un navigateur, vous connecter manuellement (ou automatiser la connexion), puis poursuivre le scraping une fois authentifié :
1from selenium import webdriver
2driver = webdriver.Chrome()
3driver.get("https://www.etsy.com/signin")
4# Connectez-vous manuellement dans la fenêtre du navigateur, puis :
5input("Appuyez sur Entrée après la connexion...")
6cookies = driver.get_cookies()
7# Utilisez maintenant driver.get() pour naviguer dans votre tableau de bord et extraire les donnéesVous pouvez aussi enregistrer les cookies de la session Selenium et les réutiliser avec requests.Session() pour un scraping plus rapide et plus léger après la connexion initiale.
Option 2 : exporter les cookies du navigateur pour les utiliser avec Requests
Utilisez une extension de navigateur (comme « EditThisCookie ») pour exporter les cookies de votre session Etsy active, puis chargez-les dans une session Requests :
1import requests
2session = requests.Session()
3# Ajoutez les cookies exportés depuis votre navigateur
4session.cookies.set("uaid", "YOUR_UAID_VALUE", domain=".etsy.com")
5session.cookies.set("user_prefs", "YOUR_USER_PREFS_VALUE", domain=".etsy.com")
6# ... ajoutez les autres cookies de session selon le besoin
7resp = session.get("https://www.etsy.com/your/orders", headers=headers)La voie simple : le mode de scraping navigateur de Thunderbit
Comme s’exécute dans votre navigateur Chrome, il hérite automatiquement de votre session Etsy active. Pas de code d’authentification, pas d’export de cookies — il suffit d’ouvrir votre tableau de bord Etsy et d’extraire les données. C’est réellement utile pour récupérer commandes, revenus, statistiques et autres données réservées aux vendeurs, sans écrire une seule ligne de script.
Exporter et exploiter vos données Etsy extraites
Enregistrer en CSV ou JSON
1import pandas as pd
2df = pd.DataFrame(results)
3df.to_csv("etsy_products.csv", index=False, encoding="utf-8")
4df.to_json("etsy_products.json", orient="records", indent=2)Bonnes pratiques : ajoutez des horodatages dans vos noms de fichiers, utilisez l’encodage UTF-8 et gérez les caractères spéciaux dans les noms de produits (les vendeurs Etsy adorent les emojis et les caractères accentués).
Exporter vers Google Sheets, Airtable ou Notion
Pour les utilisateurs Python, des bibliothèques comme gspread (Google Sheets) ou l’API Airtable permettent d’envoyer les données de manière programmatique. Mais si vous utilisez , tous les exports — vers Google Sheets, Excel, Airtable et Notion — sont gratuits et se font en un clic. Pas de clés API, pas de configuration OAuth.
Passez du code : comment extraire Etsy avec Thunderbit (alternative sans code)
Tout le monde n’a pas envie d’écrire des scripts Python, de maintenir une configuration de proxy ou de déboguer des sélecteurs CSS à 2 h du matin. Si c’est votre cas, voici comment obtenir des données Etsy avec .
Installer l’extension Chrome Thunderbit
Rendez-vous sur le et installez Thunderbit. Créez un compte gratuit — l’offre gratuite vous donne et tous les exports sont gratuits.
Utiliser « AI Suggest Fields » sur n’importe quelle page Etsy
Accédez à une page Etsy de recherche, de produit ou de boutique. Cliquez sur « AI Suggest Fields » dans la barre latérale Thunderbit. L’IA analyse la page et vous recommande des colonnes — nom du produit, prix, note, images, nom de la boutique, tags, informations de livraison. Ajustez ou ajoutez des colonnes selon vos besoins.
Cliquer sur Scrape et exporter
Cliquez sur « Scrape » pour extraire les données de la page en cours. Pour les résultats sur plusieurs pages, utilisez le scraping par pagination de Thunderbit. Pour enrichir une liste d’URL produit avec les détails de chaque page (descriptions, avis, livraison), utilisez le scraping des sous-pages — Thunderbit visite chaque lien et récupère automatiquement les données supplémentaires.
Exportez vers Excel, Google Sheets, Airtable ou Notion — gratuitement.
Quand Thunderbit est meilleur que Python pour le scraping Etsy
- Aucune configuration de proxy ni de code anti-bot nécessaire. Thunderbit fonctionne dans votre vrai navigateur Chrome, il hérite donc de votre session et ressemble à un utilisateur normal pour DataDome.
- L’IA s’adapte automatiquement aux changements de mise en page. Pas de sélecteurs cassés à réparer quand Etsy met à jour son interface.
- Parfait pour les recherches ponctuelles, l’analyse concurrentielle ou les membres d’équipe non techniques. Si vous avez juste besoin d’un jeu de données rapide, pas besoin d’environnement Python.
- Le scraping des sous-pages permet d’enrichir une liste d’URL produit avec des données détaillées sans écrire de boucles imbriquées.
Pour une démonstration, consultez la .
Python vs Thunderbit : comparaison des coûts sur 6 mois
| Facteur | Python en autonomie | Thunderbit |
|---|---|---|
| Temps de configuration | 8 à 20 heures | Moins de 5 minutes |
| Coût sur 6 mois (main-d’œuvre + proxies inclus) | 2 720 à 9 450 $ | 90 à 228 $ |
| Maintenance mensuelle | 4 à 10+ heures (les mises à jour de sélecteurs représentent 80 %+ de surcharge) | 0 à 1 heure |
| Gestion anti-bot | Proxies résidentiels à un coût de crédit 85x supérieur à la normale | Basé sur le navigateur, contourne DataDome de manière native |
| Qualité des données | Élevée (avec effort) | Élevée (pilotée par l’IA) |
Je ne dis pas que Python est le mauvais choix — si vous avez besoin d’un contrôle total, d’une logique personnalisée ou d’une intégration dans une chaîne plus large, le code reste roi. Mais pour la plupart des utilisateurs métiers qui ont simplement besoin de données Etsy, le calcul du ROI favorise un outil sans code.
Conseils juridiques et éthiques pour le scraping d’Etsy
On me demande la question de la légalité à chaque article sur le scraping, alors voici la version courte :
- Les conditions d’utilisation d’Etsy interdisent explicitement l’accès automatisé. Cela dit, Etsy mise sur l’application de mesures techniques (DataDome) plutôt que sur des actions en justice — il n’existe pas de poursuites connues spécifiques à Etsy visant des scrapers.
- N’extrayez que des données publiques. Ne contournez pas l’authentification et n’accédez pas à des tableaux de bord privés qui ne vous appartiennent pas.
- Utilisez des cadences de requêtes raisonnables. 2 à 7 secondes de délai entre les requêtes, et ne surchargez pas les serveurs d’Etsy.
- Respectez
robots.txt. Etsy autorise les pages de recherche mais restreint certains chemins. - Traitez les données personnelles de manière responsable conformément aux lois sur la protection de la vie privée comme le RGPD.
- Consultez un conseil juridique pour les projets de scraping à l’échelle commerciale.
Pour plus de contexte, consultez notre article sur les — notamment Meta c. Bright Data (2024), où l’extraction de données publiques a été confirmée.
Conclusion : points clés à retenir
Nous avons couvert beaucoup de terrain ici. Voici l’essentiel à retenir :
- Les données structurées JSON-LD d’Etsy rendent l’extraction plus propre que l’analyse brute du HTML pour la plupart des champs.
- DataDome est un véritable obstacle — utilisez des en-têtes adaptés, des délais, une bonne gestion des cookies et des proxies résidentiels pour le scraping Python à grande échelle.
- L’API Etsy est limitée. Si vous avez besoin d’avis, de boutiques concurrentes ou d’analyses entre vendeurs, le scraping est la solution pratique.
- Thunderbit offre une alternative sans code qui gère nativement l’anti-bot et l’authentification — à essayer si vous voulez des données Etsy sans maintenir de scripts.
- Extrayez toujours de manière responsable et respectez les conditions d’Etsy.
Si vous voulez démarrer sans écrire de code, . Ou utilisez le code Python de ce tutoriel pour créer votre propre scraper sur mesure — et que vos sélecteurs ne cassent jamais un vendredi après-midi.
Pour plus de guides sur le scraping, consultez notre et notre sélection des .
FAQ
1. Est-il légal d’extraire Etsy avec Python ?
L’extraction de données publiques est généralement autorisée au regard de précédents juridiques récents (par ex. Meta c. Bright Data, hiQ c. LinkedIn). Cependant, les conditions d’utilisation d’Etsy interdisent l’accès automatisé ; consultez donc toujours leurs CGU et robots.txt avant d’extraire des données. Pour un usage à grande échelle ou commercial, demandez l’avis d’un juriste.
2. Puis-je extraire Etsy sans être bloqué ?
Etsy utilise DataDome, l’un des systèmes anti-bot les plus robustes du marché. Des en-têtes réalistes, des délais entre requêtes, la persistance des cookies et la rotation de proxies résidentiels aident tous à réduire les blocages. L’approche native navigateur de Thunderbit évite la plupart des détections, puisqu’elle fonctionne dans votre vraie session Chrome.
3. Etsy dispose-t-il d’une API que je peux utiliser à la place du scraping ?
Oui — Etsy propose une API v3, mais elle est surtout limitée aux données de votre propre boutique et n’offre pas un accès robuste aux avis. La plupart des cas d’usage d’intelligence concurrentielle et d’analyse entre boutiques nécessitent du scraping.
4. Quelles bibliothèques Python me faut-il pour extraire Etsy ?
Au minimum : requests, beautifulsoup4, pandas (pour l’export) et json (intégré). Pour les pages riches en JS ou nécessitant une connexion, ajoutez selenium. Pour un parsing HTML plus rapide, utilisez lxml.
5. Comment extraire spécifiquement les avis Etsy ?
Les avis Etsy se chargent via un endpoint API interne (/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews). Vous devrez extraire l’ID de l’annonce, l’ID de la boutique et le jeton CSRF depuis la page produit, puis envoyer une requête POST à l’endpoint avec pagination. En solution de secours, vous pouvez analyser le premier lot d’avis dans le HTML de la page produit — les deux méthodes sont expliquées pas à pas dans ce tutoriel.
En savoir plus