La plupart des tutoriels sur l’extraction de données eBay ont une durée de vie d’environ trois mois. Je le sais, parce que l’équipe de Thunderbit voit régulièrement des développeurs enchaîner des extraits de code cassés, des sélecteurs CSS obsolètes et des dépôts GitHub “fonctionnels” qui ont discrètement cessé de marcher deux refontes eBay plus tôt.
eBay héberge — le plus grand ensemble de données sur les prix longue traîne du web ouvert après Amazon. Ces données alimentent tout, de la tarification pour les revendeurs à l’intelligence concurrentielle. Mais y accéder de manière programmatique reste une cible mouvante : l’interface React d’eBay change les noms de classes CSS, les tests A/B exposent des structures DOM différentes selon les utilisateurs, et Akamai Bot Manager se place entre vous et le HTML. Ce guide vous donne du code Python qui fonctionne aujourd’hui, explique pourquoi les scrapers cassent afin que vous puissiez en construire de plus robustes, compare honnêtement l’API eBay et le scraping, et présente une issue sans code quand Python ne vaut pas la mise en place.
Que signifie extraire eBay avec Python ?
Extraire des données eBay avec Python consiste à écrire des scripts qui téléchargent automatiquement les pages eBay, analysent le HTML (ou le JSON caché), puis en extraient des données structurées — titres, prix, infos vendeur, dates de vente, variantes — dans un format réellement exploitable, comme un CSV, un tableur ou une base de données.
Vous pouvez extraire plusieurs types de pages eBay :
- Résultats de recherche (par exemple toutes les annonces “AirPods Pro”)
- Pages produit individuelles (caractéristiques complètes, images, infos vendeur)
- Annonces vendues/terminées (prix et dates de transaction réels)
- Profils vendeurs et avis
Python est le langage de référence pour ce travail. Son écosystème — Requests, BeautifulSoup, lxml, pandas — permet de récupérer facilement les pages, d’analyser le HTML et de manipuler les données. Il existe toutefois une vraie différence entre extraire le HTML du site et utiliser l’API officielle d’eBay — j’y reviens juste après.
Pourquoi extraire eBay ? Cas d’usage concrets pour les équipes business
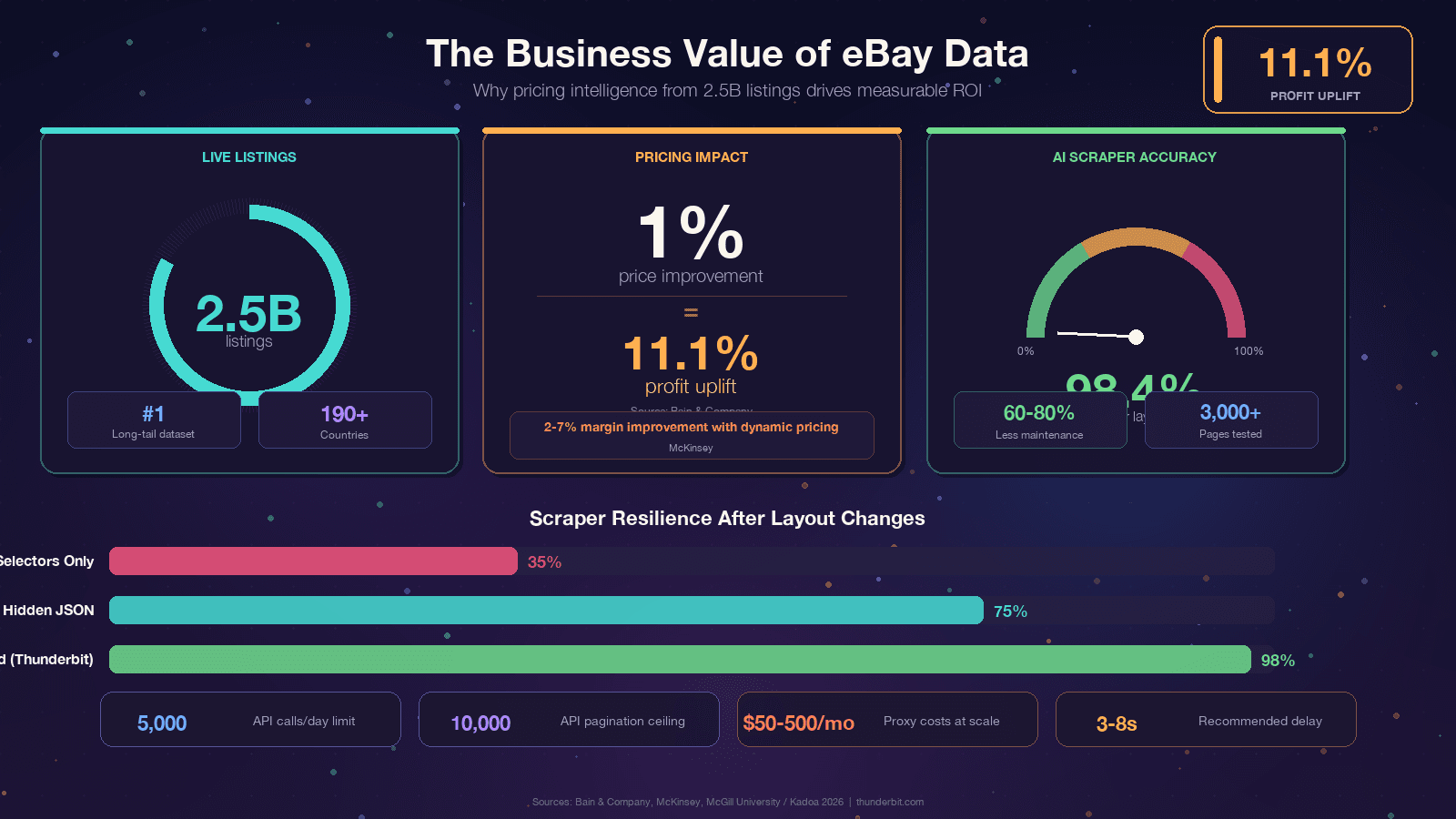
Si vous lisez ceci, vous avez probablement déjà une raison. Cela dit, il vaut la peine d’ancrer le sujet dans une valeur métier concrète, car le ROI des données eBay est vraiment impressionnant. Bain a constaté qu’une sur des milliers d’entreprises. McKinsey attribue à la tarification dynamique dans le retail.
Les cas d’usage que je vois le plus souvent :
| Cas d’usage | Données nécessaires | Résultat métier |
|---|---|---|
| Surveillance des prix et repricing | Prix des annonces actives, livraison, état | Tarification compétitive, protection des marges |
| Analyse concurrentielle | Assortiment produits, promotions, conditions de livraison | Positionnement stratégique, identification des manques d’assortiment |
| Études de marché et détection de tendances | Vitesse de mise en vente, tendances de catégorie, signaux de demande | Identification de nouveaux produits, prévision de la demande |
| Tarification revendeur / estimation | Prix vendus, dates de vente, état | Valeur de marché juste, décisions d’achat |
| Analyse de sentiment | Avis, notes, politique de retour | Lecture de la qualité produit, satisfaction client |
| Génération de leads | Profils vendeurs, infos boutique, coordonnées | Prospection B2B auprès de vendeurs à fort GMV |
Le point commun est simple : eBay possède les données, mais elles sont enfermées dans des pages web.
Le scraping permet d’en faire un avantage concurrentiel.
API officielle eBay vs scraping Python : lequel choisir ?
C’est la question à laquelle j’aimerais que davantage de tutoriels répondent franchement. eBay propose des API officielles — principalement la — et beaucoup se demandent s’il vaut mieux les utiliser ou extraire directement le site. La réponse dépend entièrement des données dont vous avez besoin.
| Critère | API eBay Browse/Finding | Scraping Python |
|---|---|---|
| Annonces vendues/terminées | Limité — la Marketplace Insights API existe, mais l’accès est souvent refusé | Accès complet via les paramètres d’URL LH_Sold=1&LH_Complete=1 |
| Limites de requêtes | 5 000 appels/jour sur le niveau de base | Géré par vous-même (dépend des proxys) |
| Champs disponibles | Prédéfinis (titre, prix, catégorie, bases vendeur) | Tout ce qui est visible sur la page (avis, spécifications complètes, variantes) |
| Complexité de mise en place | OAuth 2.0, inscription de l’application, clés API | pip install + code |
| Stabilité | Endpoints stables | Casse quand le HTML change |
| Coût | Offre gratuite disponible, payante selon le volume | Code gratuit, mais coûts de proxy à grande échelle |
| Données de variantes/MSKU | Partielles — souvent seulement le SKU parent | Complètes (via l’analyse du JSON caché) |
| Profondeur de pagination | Plafond dur de 10 000 éléments | Théoriquement illimité |
Petite précision : l’ancienne Finding API (qui incluait findCompletedItems) a été . Si vous utilisez ebaysdk-python ou une bibliothèque qui s’appuie sur le module Finding, elle est actuellement cassée en production.
Ma recommandation : utilisez la Browse API pour des requêtes de catalogue stables, à volume modéré, sur les annonces actives. Utilisez le scraping Python lorsque vous avez besoin des prix vendus, des avis, des variantes ou de tout champ non exposé par l’API. Beaucoup d’équipes combinent les deux.
Outils et bibliothèques nécessaires pour extraire eBay avec Python
Avant d’écrire du code, voici la boîte à outils. Vous n’avez pas besoin d’un navigateur headless pour la plupart des pages eBay — les données sont intégrées dans le HTML rendu côté serveur.
| Bibliothèque | Rôle |
|---|---|
requests ou httpx | Client HTTP pour télécharger les pages eBay |
curl_cffi | Client HTTP avec empreinte TLS de vrai navigateur (essentiel pour contourner Akamai) |
beautifulsoup4 | Analyseur HTML pour extraire via sélecteurs CSS |
lxml | Moteur d’analyse rapide pour BeautifulSoup |
jmespath | Langage de requête pour analyser des blocs JSON imbriqués |
pandas | Manipulation de données et export CSV/Excel |
gspread | Intégration Google Sheets |
Installez tout en une seule commande :
1pip install requests httpx curl_cffi beautifulsoup4 lxml jmespath pandas gspreadUtilisez Python 3.11+ — pandas 3.0 exige au moins Python 3.10, et Python 3.11 apporte un gain de vitesse de 10 à 60 % sur les tâches liées aux I/O.
Une bibliothèque mérite une mention spéciale : curl_cffi est probablement la mise à niveau la plus importante pour un scraper eBay en 2026. eBay utilise , et le principal vecteur de détection d’Akamai est l’empreinte TLS. Un simple requests envoie une empreinte JA3 typique de Python, immédiatement repérée. curl_cffi imite la négociation TLS d’un vrai navigateur Chrome, ce qui permet de gérer environ 90 % des cibles protégées par Akamai sans navigateur headless.
Tutoriel pas à pas : comment extraire les résultats de recherche eBay avec Python
C’est le cœur du tutoriel. Nous allons extraire les pages de résultats de recherche eBay pour les annonces produits.
- Niveau : Débutant à intermédiaire
- Temps requis : environ 30 minutes pour une première extraction fonctionnelle
- Ce qu’il vous faut : Python 3.11+, les bibliothèques ci-dessus, un terminal et une URL de recherche eBay cible
Étape 1 : préparer votre projet Python
Créez un dossier de projet et installez les dépendances :
1mkdir ebay-scraper && cd ebay-scraper
2python -m venv venv
3source venv/bin/activate # Windows: venv\Scripts\activate
4pip install requests curl_cffi beautifulsoup4 lxml pandasCréez un fichier appelé scrape_ebay.py. C’est votre espace de travail.
Étape 2 : construire l’URL de recherche eBay
La structure de l’URL de recherche eBay est simple. Le paramètre clé est _nkw (mot-clé) :
1import urllib.parse
2keyword = "airpods pro"
3base_url = "https://www.ebay.com/sch/i.html"
4params = {
5 "_nkw": keyword,
6 "_ipg": "120", # nombre d’éléments par page : 60, 120 ou 240 (240 peut déclencher des alertes bot)
7 "_pgn": "1", # numéro de page
8}
9url = f"{base_url}?{urllib.parse.urlencode(params)}"
10print(url)
11# https://www.ebay.com/sch/i.html?_nkw=airpods+pro&_ipg=120&_pgn=1Autres paramètres utiles :
LH_BIN=1— uniquement les annonces Acheter maintenant_sacat=175673— catégorie spécifique_sop=12— tri par meilleure correspondance (10 = prix + livraison la plus basse, 13 = plus récemment publié)LH_Complete=1&LH_Sold=1— annonces vendues/terminées (couvertes dans une section dédiée plus bas)
Étape 3 : envoyer une requête et gérer la réponse
C’est ici que curl_cffi montre toute sa valeur. Un simple requests.get() renvoie souvent une erreur 403 d’Akamai. Avec curl_cffi, on se fait passer pour un vrai navigateur Chrome :
1from curl_cffi import requests as cffi_requests
2import random, time
3USER_AGENTS = [
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
5 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (X11; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0",
7]
8HEADERS = {
9 "User-Agent": random.choice(USER_AGENTS),
10 "Accept-Language": "en-US,en;q=0.9",
11 "Accept-Encoding": "gzip, deflate, br",
12}
13def fetch_page(url, max_retries=5):
14 delay = 2
15 for attempt in range(max_retries):
16 try:
17 r = cffi_requests.get(url, impersonate="chrome124", headers=HEADERS, timeout=30)
18 if r.status_code == 200:
19 return r.text
20 if r.status_code in (403, 429, 503):
21 retry_after = r.headers.get("Retry-After")
22 sleep_for = float(retry_after) if retry_after else delay + random.uniform(0, 1)
23 print(f" Statut {r.status_code}, nouvelle tentative dans {sleep_for:.1f}s...")
24 time.sleep(sleep_for)
25 delay *= 2
26 continue
27 r.raise_for_status()
28 except Exception as e:
29 print(f" Erreur de requête : {e}, nouvelle tentative...")
30 time.sleep(delay)
31 delay *= 2
32 raise RuntimeError(f"Échec après {max_retries} tentatives : {url}")Le backoff exponentiel avec jitter est important : des intervalles de sommeil fixes constituent eux aussi une empreinte bot.
Étape 4 : extraire les annonces produit depuis la page de recherche
eBay est actuellement en transition entre deux mises en page de résultats de recherche. Un scraper robuste doit gérer les deux :
| Champ | Ancienne mise en page | Nouvelle mise en page |
|---|---|---|
| Conteneur de carte | li.s-item | li.s-card ou div.su-card-container |
| Titre | .s-item__title | .s-card__title |
| URL | a.s-item__link[href] | a.su-link[href] |
| Prix | span.s-item__price | .s-card__price |
Le code d’analyse qui prend en charge les deux mises en page :
1from bs4 import BeautifulSoup
2def parse_search_results(html):
3 soup = BeautifulSoup(html, "lxml")
4 cards = soup.select("li.s-item, li.s-card, div.su-card-container")
5 results = []
6 for card in cards:
7 # Titre — essayer les deux mises en page
8 title_el = card.select_one(".s-item__title, .s-card__title")
9 title = title_el.get_text(strip=True) if title_el else None
10 # Ignorer la fausse carte de remplacement “Shop on eBay”
11 if not title or "Shop on eBay" in title:
12 continue
13 # Prix
14 price_el = card.select_one("span.s-item__price, .s-card__price")
15 price = price_el.get_text(strip=True) if price_el else None
16 # URL
17 link_el = card.select_one("a.s-item__link[href], a.su-link[href]")
18 url = link_el["href"].split("?")[0] if link_el else None
19 # Image
20 img_el = card.select_one("img.s-item__image-img, .s-card__image img")
21 image = None
22 if img_el:
23 image = img_el.get("src") or img_el.get("data-src")
24 # Livraison
25 ship_el = card.select_one("span.s-item__shipping, span.s-item__logisticsCost, .s-card__attribute-row")
26 shipping = ship_el.get_text(strip=True) if ship_el else None
27 results.append({
28 "title": title,
29 "price": price,
30 "url": url,
31 "image": image,
32 "shipping": shipping,
33 })
34 return resultsLe piège de la première carte fantôme est un classique. Sur beaucoup de pages de recherche eBay, le premier li.s-item est un espace réservé caché, avec le titre “Shop on eBay” et aucun vrai prix. Filtrez-le systématiquement.
Étape 5 : gérer la pagination pour extraire plusieurs pages
eBay pagine via le paramètre _pgn. Le lien de la page suivante utilise a.pagination__next :
1import urllib.parse
2def scrape_ebay_search(keyword, max_pages=5):
3 all_results = []
4 for page_num in range(1, max_pages + 1):
5 params = {"_nkw": keyword, "_ipg": "120", "_pgn": str(page_num)}
6 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
7 print(f"Extraction de la page {page_num} : {url}")
8 html = fetch_page(url)
9 results = parse_search_results(html)
10 if not results:
11 print(f" Aucun résultat sur la page {page_num}, arrêt.")
12 break
13 all_results.extend(results)
14 print(f" {len(results)} annonces trouvées (total : {len(all_results)})")
15 # Pause polie — 3 à 8 secondes avec jitter
16 time.sleep(random.uniform(3, 8))
17 return all_resultsLe jitter aléatoire de 3 à 8 secondes n’est pas optionnel.
eBay et Akamai détectent les rafales continues de plus de 1 requête/seconde depuis une même IP.
Étape 6 : exporter vos données en CSV ou JSON
1import pandas as pd
2results = scrape_ebay_search("airpods pro", max_pages=3)
3df = pd.DataFrame(results)
4df.to_csv("ebay_airpods.csv", index=False)
5df.to_json("ebay_airpods.json", orient="records", indent=2)
6print(f"Export de {len(df)} annonces vers CSV et JSON.")Vous devriez maintenant disposer d’un tableau propre des annonces eBay. Sur ma machine, l’extraction de 3 pages (360 annonces) a pris environ 45 secondes, pauses incluses.
Comment extraire les pages de détail produit eBay avec Python
Les résultats de recherche donnent un aperçu. Les pages de détail produit contiennent les éléments utiles : descriptions complètes, notes du vendeur, caractéristiques de l’article, carrousels d’images et données de variantes.
Analyser une page d’annonce individuelle
Les pages d’articles eBay se trouvent à l’URL /itm/<ITEM_ID>. La voie d’extraction la plus stable est JSON-LD — eBay intègre un bloc de schéma Product qui survit à presque tous les changements de CSS :
1import json
2def parse_item_page(html):
3 soup = BeautifulSoup(html, "lxml")
4 item = {}
5 # 1. JSON-LD — voie d’extraction la plus stable
6 for tag in soup.find_all("script", type="application/ld+json"):
7 try:
8 data = json.loads(tag.string or "")
9 except (json.JSONDecodeError, TypeError):
10 continue
11 if isinstance(data, dict) and data.get("@type") == "Product":
12 item["title"] = data.get("name")
13 item["brand"] = (data.get("brand") or {}).get("name")
14 item["images"] = data.get("image")
15 offers = data.get("offers") or {}
16 item["price"] = offers.get("price")
17 item["currency"] = offers.get("priceCurrency")
18 break
19 # 2. Fallback CSS pour les champs absents du JSON-LD
20 def first_text(selectors):
21 for sel in selectors:
22 el = soup.select_one(sel)
23 if el and el.get_text(strip=True):
24 return el.get_text(strip=True)
25 return None
26 item.setdefault("title", first_text([
27 "h1.x-item-title__mainTitle",
28 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
29 ]))
30 item["condition"] = first_text([
31 ".x-item-condition-text .ux-textspans",
32 ])
33 item["seller"] = first_text([
34 ".x-sellercard-atf__info__about-seller a .ux-textspans",
35 ])
36 item["shipping"] = first_text([
37 "div.ux-labels-values--shipping .ux-textspans--BOLD",
38 ])
39 # 3. Caractéristiques de l’article
40 specifics = {}
41 for dl in soup.select(".ux-layout-section-evo__item--table-view dl.ux-labels-values"):
42 k = dl.select_one(".ux-labels-values__labels-content .ux-textspans")
43 v = dl.select_one(".ux-labels-values__values-content .ux-textspans")
44 if k and v:
45 specifics[k.get_text(strip=True).rstrip(":")] = v.get_text(strip=True)
46 item["specifics"] = specifics
47 return itemLe schéma ici — JSON-LD d’abord, sélecteurs CSS en secours — est la clé pour construire des scrapers qui ne cassent pas tous les trimestres. J’y reviens plus bas.
Extraire les variantes de produit eBay (données MSKU)
Certaines annonces eBay proposent plusieurs variantes — différentes couleurs, tailles ou capacités de stockage. Le DOM visible n’affiche qu’une fourchette de prix, par exemple “899 $ à 1 099 $”, jusqu’à ce que l’utilisateur clique sur une option. Le prix réel par variante se trouve dans un objet JavaScript caché appelé MSKU.
C’est l’un des cas où l’API eBay ne fournit qu’une partie des données (le SKU parent), ce qui rend le scraping plus pertinent.
1import re, json
2def extract_variants(html):
3 # Le caractère non gourmand est essentiel — le .+ gourmand engloutit toute la page
4 m = re.search(r'"MSKU"\s*:\s*(\{.+?\})\s*,\s*"QUANTITY"', html, re.DOTALL)
5 if not m:
6 return []
7 try:
8 msku = json.loads(m.group(1))
9 except json.JSONDecodeError:
10 return []
11 item_labels = {str(k): v["displayLabel"] for k, v in msku.get("menuItemMap", {}).items()}
12 skus = []
13 for combo_key, variation_id in msku.get("variationCombinations", {}).items():
14 option_ids = combo_key.split("_")
15 options = [item_labels.get(oid, oid) for oid in option_ids]
16 var = msku.get("variationsMap", {}).get(str(variation_id), {})
17 bin_model = var.get("binModel", {})
18 price_spans = bin_model.get("price", {}).get("textSpans", [{}])
19 price = price_spans[0].get("text") if price_spans else None
20 qty = var.get("quantity")
21 skus.append({
22 "options": options,
23 "price": price,
24 "quantity_available": qty,
25 "variation_id": variation_id,
26 })
27 return skusC’est dans cette regex (.+?) non gourmande que la plupart des scrapers eBay se font piéger. Le .+ gourmand avale tout jusqu’au dernier "QUANTITY" de la page, ce qui produit un JSON invalide. J’ai vu ce bug dans au moins trois tutoriels “fonctionnels”.
Comment extraire les annonces eBay vendues et terminées avec Python
C’est le cas d’usage qui justifie le scraping plutôt que l’API. Les données d’articles vendus — ce qui a réellement été vendu, à quel prix et à quelle date — constituent la référence absolue pour les études de marché, la tarification des revendeurs et les estimations. La Browse API d’eBay ne fournit pas cela explicitement. La le fait techniquement, mais l’accès relève d’une “Limited Release” souvent .
Les paramètres d’URL nécessaires sont LH_Complete=1 (annonces terminées) et LH_Sold=1 (uniquement les articles effectivement vendus). Vous devez fournir les deux. Si vous ne passez que LH_Sold=1, eBay revient silencieusement aux annonces actives dans certaines catégories — c’est l’erreur la plus fréquente.
1def scrape_sold_listings(keyword, max_pages=3):
2 all_sold = []
3 for page_num in range(1, max_pages + 1):
4 params = {
5 "_nkw": keyword,
6 "_ipg": "120",
7 "_pgn": str(page_num),
8 "LH_Complete": "1",
9 "LH_Sold": "1",
10 }
11 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
12 print(f"Extraction des annonces vendues, page {page_num}...")
13 html = fetch_page(url)
14 soup = BeautifulSoup(html, "lxml")
15 cards = soup.select("li.s-item")
16 for card in cards:
17 title_el = card.select_one(".s-item__title")
18 title = title_el.get_text(strip=True) if title_el else None
19 if not title or "Shop on eBay" in title:
20 continue
21 # N’inclure que les articles effectivement vendus (prix POSITIVE vert)
22 sold_tag = card.select_one(
23 ".s-item__title--tag .POSITIVE, .s-item__caption--signal.POSITIVE"
24 )
25 if sold_tag is None:
26 continue # Annonce terminée non vendue — à ignorer
27 price_el = card.select_one("span.s-item__price")
28 price = price_el.get_text(strip=True) if price_el else None
29 # Extraire la date de vente
30 sold_date = None
31 import re, datetime as dt
32 card_text = card.get_text()
33 m = re.search(r"Sold\s+([A-Z][a-z]{2}\s+\d{1,2},\s*\d{4})", card_text)
34 if m:
35 sold_date = dt.datetime.strptime(m.group(1), "%b %d, %Y").strftime("%Y-%m-%d")
36 link_el = card.select_one("a.s-item__link[href]")
37 url = link_el["href"].split("?")[0] if link_el else None
38 all_sold.append({
39 "title": title,
40 "sold_price": price,
41 "sold_date": sold_date,
42 "url": url,
43 })
44 if not cards:
45 break
46 time.sleep(random.uniform(3, 8))
47 return all_soldLa différence clé dans le HTML : les articles vendus affichent le prix en vert (dans un conteneur .POSITIVE), alors que les annonces terminées non vendues affichent le prix en rouge barré. Filtrez toujours sur cette classe .POSITIVE.
Pourquoi les scrapers eBay cassent-ils ? Et comment construire des scrapers robustes
Si votre scraper eBay ne fonctionne plus, vous êtes loin d’être seul. C’est le problème numéro un dans tous les fils de discussion sur le scraping eBay que j’ai lus. La question n’est pas de savoir si votre scraper cassera, mais quand.
Pourquoi cela arrive :
- eBay utilise un rendu basé sur React avec des noms de classes générés dynamiquement qui changent à chaque déploiement
- Les tests A/B servent des structures DOM différentes selon les utilisateurs (la double mise en page
s-item/s-carden est un exemple vivant) - Les refontes périodiques modifient l’imbrication HTML même quand les données restent identiques
- Les anciens sélecteurs comme
#itemTitleet#prcIsumont été supprimés il y a des années, mais ils apparaissent encore dans des tutoriels
Comme le dit : « Le vrai défi du scraping eBay consiste à gérer les changements de sélecteurs CSS. eBay met régulièrement à jour son frontend, ce qui casse les scrapers dépendants de noms de classes spécifiques. »
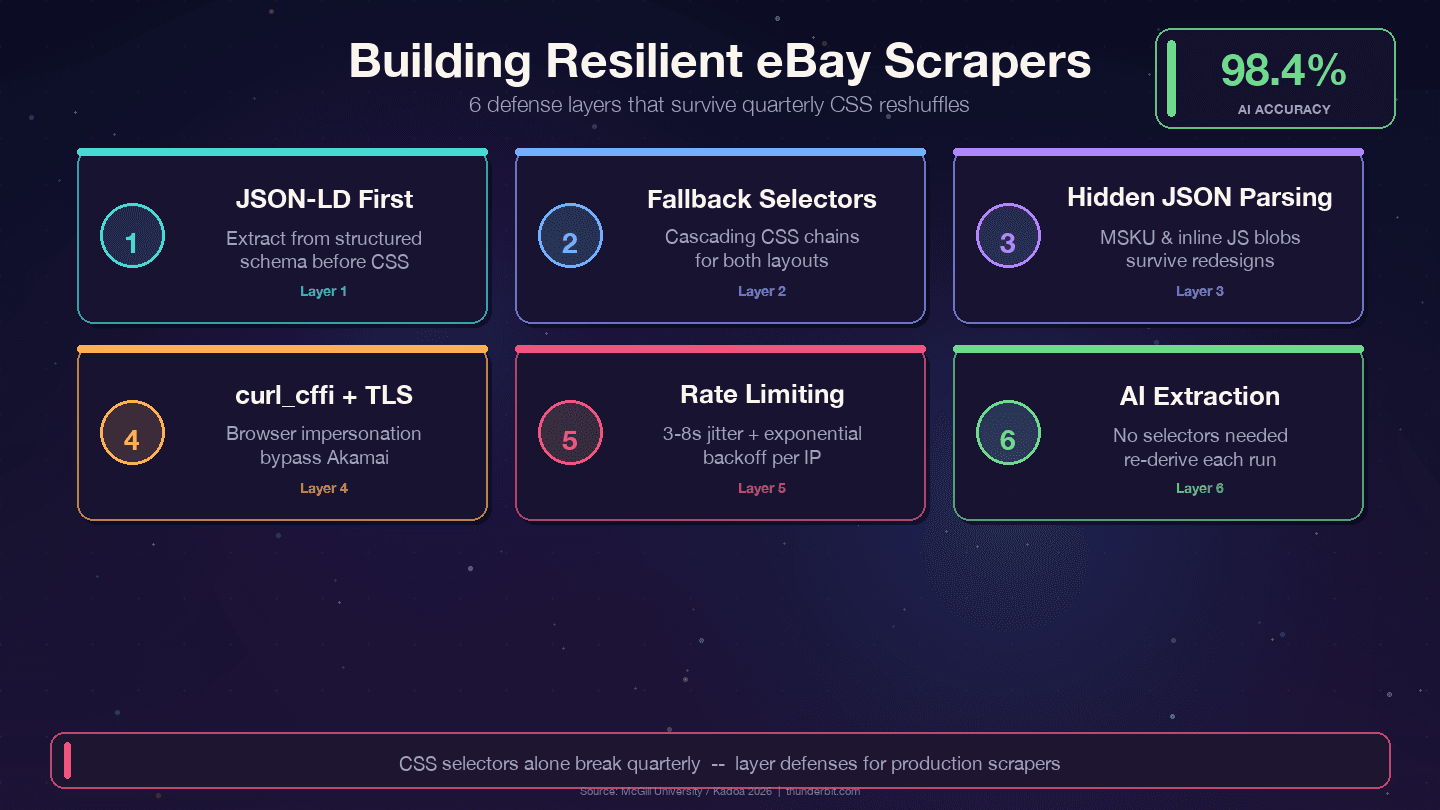
Stratégies de défense pour des scrapers eBay durables
Quatre stratégies qui survivent aux remaniements trimestriels d’eBay :
1. Priorisez le JSON-LD plutôt que les sélecteurs CSS. eBay intègre des données structurées Product sur chaque page d’article. La couche de données change beaucoup moins que la couche de présentation — les designers refondent les classes CSS tous les trimestres, mais les noms de champs côté backend comme price, name et seller sont reliés à des API internes et sont rarement renommés.
2. Utilisez des sélecteurs de secours en cascade. Ne dépendez jamais d’un seul sélecteur CSS. Proposez toujours des alternatives :
1def first_text(soup, selectors):
2 for sel in selectors:
3 el = soup.select_one(sel)
4 if el and el.get_text(strip=True):
5 return el.get_text(strip=True)
6 return None
7title = first_text(soup, [
8 "h1.x-item-title__mainTitle",
9 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
10 "[data-testid='x-item-title'] h1",
11])3. Analysez les blocs JSON cachés. L’objet de variantes MSKU et les données JavaScript inline résistent mieux aux changements CSS car ils sont générés côté serveur. Extraire ces données via regex dans des balises <script> demande plus d’effort au départ, mais réduit fortement la maintenance.
4. Journalisez les échecs de sélecteurs. Ajoutez une supervision pour savoir quand un sélecteur cesse de fonctionner, et pas seulement que vos données sont vides :
1if title is None:
2 print(f"AVERTISSEMENT : échec du sélecteur de titre pour {url}")5. Utilisez curl_cffi avec impersonation de navigateur. Cela gère l’empreinte TLS d’Akamai sans navigateur headless.
L’alternative alimentée par l’IA : plus de maintenance des sélecteurs
Si vous en avez assez de corriger les sélecteurs tous les quelques mois, il existe une approche fondamentalement différente. Des outils comme utilisent l’IA pour lire la page à chaque exécution et déduire la logique d’extraction à la volée. Une étude de l’Université McGill a comparé des scrapers IA et des scrapers basés sur des sélecteurs sur 3 000 pages et a constaté que , avec des benchmarks sectoriels indiquant .
| Approche | Casse quand eBay modifie le HTML ? | Effort de maintenance |
|---|---|---|
| Sélecteurs CSS codés en dur | Oui, tous les trimestres | Élevé — corrections continues |
| Extraction JSON / JSON-LD cachée | Rarement | Faible |
| Scraping basé sur l’IA (Thunderbit) | Non — l’IA redéduit les sélecteurs à chaque exécution | Aucun |
Je détaillerai le flux Thunderbit plus loin. Pour l’instant, retenez ceci : si vous construisez un scraper que vous comptez faire tourner pendant des mois, misez sur une extraction d’abord en JSON avec des sélecteurs de secours. Si vous ne voulez pas maintenir de sélecteurs du tout, l’approche IA mérite vraiment qu’on s’y intéresse.
Automatiser des extractions eBay récurrentes pour le suivi des prix
Une extraction ponctuelle est utile. Mais la surveillance des prix, le suivi des stocks et l’analyse concurrentielle exigent une collecte récurrente des données. Tous les articles comparatifs que j’ai lus mentionnent le suivi des prix comme cas d’usage, mais presque aucun n’explique comment l’automatiser réellement.
Option 1 : Cron jobs (Linux/macOS) ou Planificateur de tâches (Windows)
L’approche la plus simple. Enveloppez votre script Python dans un cron job. Utilisez toujours le chemin absolu vers le Python de votre environnement virtuel — cron s’exécute dans un environnement minimal :
1crontab -e
2# Tous les jours à 08:15
315 8 * * * /Users/me/ebay/venv/bin/python /Users/me/ebay/scrape_ebay.py >> /Users/me/ebay/scrape.log 2>&1Sous Windows, utilisez PowerShell :
1$A = New-ScheduledTaskAction -Execute "C:\Users\me\ebay\venv\Scripts\python.exe" -Argument "C:\Users\me\ebay\scrape_ebay.py"
2$T = New-ScheduledTaskTrigger -Daily -At 8:15am
3Register-ScheduledTask -TaskName "eBayScraper" -Action $A -Trigger $TCela nécessite une machine toujours allumée, et vous gérez vous-même les proxys et les mécanismes anti-bot.
Option 2 : fonctions cloud (serverless)
AWS Lambda ou Google Cloud Functions permettent d’exécuter des scrapers sans serveur dédié. La mise en place est plus lourde — il faut empaqueter les dépendances, gérer les timeouts (Lambda est limité à 15 minutes) et toujours gérer les proxys. Mais il n’y a pas de maintenance serveur.
Option 3 : planification sans code avec Thunderbit
La fonctionnalité vous permet de décrire l’intervalle en langage naturel (par exemple, “tous les jours à 8h”), d’ajouter des URL eBay, puis de cliquer sur Planifier. L’exécution se fait dans le cloud avec une gestion anti-bot intégrée.
| Approche | Effort de mise en place | Besoin d’un serveur ? | Gère l’anti-bot ? |
|---|---|---|---|
| Cron + script Python | Moyen | Oui (machine toujours allumée) | Vous gérez les proxys |
| Fonction cloud (Lambda) | Élevé | Non (serverless) | Vous gérez les proxys |
| Scheduled Scraper Thunderbit | Faible (description en langage naturel) | Non (cloud) | Intégré |
Pour stocker les données d’extraction récurrentes, une base SQLite locale est la bonne solution pour l’historique des prix. Utilisez ON CONFLICT ... DO UPDATE (et non INSERT OR REPLACE, qui ) :
1CREATE TABLE IF NOT EXISTS listings (
2 item_id TEXT PRIMARY KEY,
3 title TEXT NOT NULL,
4 price REAL,
5 last_price REAL,
6 first_seen_at TEXT DEFAULT (datetime('now')),
7 last_seen_at TEXT DEFAULT (datetime('now'))
8);
9CREATE TABLE IF NOT EXISTS price_history (
10 item_id TEXT NOT NULL,
11 observed_at TEXT NOT NULL DEFAULT (datetime('now')),
12 price REAL NOT NULL,
13 PRIMARY KEY (item_id, observed_at)
14);Vous ne voulez pas coder ? Comment extraire eBay en 2 minutes avec Thunderbit
J’ai passé 2 000 mots sur du code Python. Maintenant, je veux être honnête sur les cas où vous n’en avez pas besoin.
Si vous êtes un utilisateur métier qui fait une étude de marché ponctuelle, un revendeur qui compare des ventes, ou une équipe e-commerce qui a besoin de données aujourd’hui sans sprint de développement, Python est excessif. La configuration, la maintenance des sélecteurs, la gestion des proxys — tout cela est beaucoup trop lourd pour “j’ai juste besoin de ces 200 annonces dans un tableur”.
Comment Thunderbit extrait eBay (étape par étape)
- Installez l’ — sans carte bancaire.
- Ouvrez une page de résultats de recherche eBay ou une page produit dans Chrome.
- Cliquez sur “AI Suggest Fields” dans la barre latérale Thunderbit. L’IA lit la page et propose des colonnes : Titre, Prix, État, Livraison, Vendeur, Note.
- Cliquez sur “Scrape.” L’extension parcourt la pagination et remplit le tableau de données. Pour eBay en particulier, Thunderbit propose des qui fonctionnent en un clic.
- Exportez vers Google Sheets, Airtable, Notion, CSV, JSON ou Excel — gratuitement.
Le tout prend moins de 2 minutes.
Je l’ai chronométré.
Enrichissement des sous-pages : récupérer les données de la fiche détaillée sans code supplémentaire
Après l’extraction d’une page de résultats, Thunderbit peut ouvrir la page détaillée de chaque annonce et ajouter des champs supplémentaires — spécifications complètes, infos vendeur, description, toutes les images. Cela remplace les plus de 20 lignes de code Python pour le scraping de sous-pages que nous avons écrites plus haut par un simple clic.
Quand Python reste le bon choix
Python prend l’avantage lorsque vous avez besoin de :
- Scraping à grande échelle (dizaines de milliers de pages par exécution)
- Logique d’analyse ou de transformation très personnalisée
- Intégration à des pipelines de données existants (Airflow, dbt, Kafka)
- Contrôle fin du TLS/de la session pour des travaux anti-bot avancés
- Économie unitaire — à des millions de lignes, une stack maintenue coûte souvent moins cher qu’un SaaS à crédits
Pour la plupart des projets ponctuels ou de taille moyenne, Thunderbit est plus rapide et plus simple. Pour des pipelines de production à grande échelle, Python offre un contrôle total.
Conseils pour éviter le blocage lorsque vous extrayez eBay avec Python
eBay et Akamai, c’est du sérieux. Ce qui fonctionne réellement en pratique :
- Utilisez
curl_cffiavecimpersonate="chrome124"— c’est l’amélioration la plus importante par rapport à un simplerequests - Faites tourner les chaînes User-Agent à partir d’une liste de navigateurs récents (Chrome 143, Firefox 124, Safari 26)
- Ajoutez des délais aléatoires de — des intervalles fixes sont une empreinte
- Utilisez des proxys résidentiels ou rotatifs pour dépasser quelques dizaines de pages. Les IP de datacenters (AWS, GCP, DigitalOcean) sont rapidement repérées par Akamai.
- Respectez
robots.txt— la plupart des URL de navigation filtrées sont explicitement interdites ; les pages de détail d’articles (/itm/<id>) ne le sont pas - Gérez les CAPTCHA avec souplesse — détectez-les et réessayez avec une autre IP, ou utilisez un service de résolution de CAPTCHA
- Ne surchargez pas le serveur. Le précédent indique que le “trespass to chattels” s’applique lorsque le scraping dégrade réellement les serveurs. Rester à 1 requête/seconde par IP vous maintient largement sous ce seuil.
Pour un usage commercial à fort volume, envisagez la Browse API pour les annonces actives et un scraping ciblé uniquement pour les comparables vendus et les données non exposées par l’API. Cette approche hybride est plus propre, à la fois techniquement et juridiquement.
Est-il légal d’extraire eBay avec Python ?
Je ne suis pas avocat, et cet article ne constitue pas un avis juridique. Je vais donc rester bref.
Le paysage juridique a évolué en faveur de l’extraction de données publiques. Les précédents clés :
- (9e circuit, 2022) : l’extraction de données accessibles publiquement ne viole pas le CFAA
- Van Buren v. United States (Cour suprême des États-Unis, 2021) : interprétation plus stricte de la notion “exceeds authorized access” du CFAA
- (N.D. Cal., 2024) : le scraping sans connexion ne viole pas les CGU de la plateforme, car le scraper n’est pas un “utilisateur”
Cela dit, la mise à jour interdit explicitement les “agents buy-for-me, les bots pilotés par des LLM, ou tout flux de bout en bout qui tente de passer des commandes sans revue humaine”. La ligne est claire : l’extraction en lecture seule de pages publiques est solidement défendable ; l’automatisation du checkout ne l’est pas.
Bonnes pratiques : n’extrayez que les données visibles publiquement. Ne créez pas de faux comptes et ne contournez pas les murs de connexion. Ne revendiez pas en masse des images d’annonces protégées par le droit d’auteur. Et consultez un juriste pour les projets à l’échelle commerciale.
Conclusion et points clés à retenir
Python reste la méthode la plus flexible pour extraire eBay, mais il exige une maintenance continue à mesure que le HTML du site évolue. Le cadre de décision :
- Utilisez la Browse API eBay pour des requêtes stables, de volume modéré, sur les annonces actives
- Utilisez le scraping Python pour les annonces vendues, les avis, les variantes et tout champ non exposé par l’API
- Utilisez si vous voulez les données eBay sans écrire ni maintenir de code
Le code de ce guide privilégie la robustesse : extraction JSON-LD en premier, sélecteurs CSS de secours ensuite, analyse du JSON caché pour les variantes. Cette approche en couches signifie que votre scraper ne mourra pas à la prochaine refonte du frontend d’eBay.
Si vous voulez essayer l’option sans code, vous permet de la tester dès maintenant sur des pages eBay. Et si vous voulez voir comment fonctionne le , il est à un clic.
Pour aller plus loin sur les outils de scraping web, consultez nos guides sur les , et . Vous pouvez aussi regarder des tutoriels sur la .
FAQ
1. Puis-je extraire eBay gratuitement avec Python ?
Oui. Toutes les bibliothèques (Requests, BeautifulSoup, curl_cffi, pandas) sont gratuites et open source. Les coûts apparaissent à grande échelle — les proxys résidentiels pour du scraping intensif coûtent généralement entre 50 et 500 $/mois selon la bande passante. Pour de petits projets (quelques centaines de pages), vous pouvez extraire depuis votre IP domestique avec une limitation de débit prudente.
2. Comment extraire les articles vendus et les annonces terminées eBay avec Python ?
Ajoutez LH_Complete=1&LH_Sold=1 aux paramètres de l’URL de recherche. Vous devez passer les deux — LH_Sold=1 seul revient silencieusement aux annonces actives dans certaines catégories. Filtrez les résultats en vérifiant la classe CSS .POSITIVE sur l’élément de prix, ce qui indique une vente réelle plutôt qu’une annonce expirée invendue.
3. eBay bloque-t-il le scraping web ?
eBay utilise Akamai Bot Manager, qui détecte les scrapers principalement via l’empreinte TLS et l’analyse comportementale. De simples appels requests renvoient souvent des réponses 403. L’utilisation de curl_cffi avec impersonation du navigateur, la rotation des User-Agents et l’ajout de délais aléatoires de 3 à 8 secondes entre les requêtes permettent de contourner la plupart des blocages. Les proxys résidentiels aident à grande échelle.
4. Dois-je utiliser l’API eBay ou le web scraping ?
Utilisez la Browse API pour les requêtes stables et de volume modéré sur les annonces actives (jusqu’à 5 000 appels/jour). Utilisez le scraping quand vous avez besoin de l’historique des prix vendus, des données complètes de variantes/MSKU, des avis ou de tout champ non exposé par l’API. La Marketplace Insights API fournit théoriquement les données de vente, mais l’accès est restreint et .
5. Quelle est la façon la plus simple d’extraire eBay sans coder ?
L’ utilise l’IA pour lire les pages eBay, suggérer les colonnes de données et extraire les annonces en un clic. Elle gère la pagination, l’enrichissement des sous-pages et l’export vers Google Sheets, Excel, Airtable ou Notion. Les préconfigurés rendent cela encore plus rapide pour les cas d’usage courants.
En savoir plus