Craigslist attire encore environ réparties sur quelque 700 sites locaux — et il n’a toujours pas d’API publique. Si vous voulez des données structurées à partir d’annonces de location, de voitures d’occasion, d’offres d’emploi ou de missions ponctuelles, le scraping reste pratiquement la seule option.
Cela dit, le système anti-bot maison de Craigslist est particulièrement sévère. Il n’utilise ni Cloudflare ni DataDome — il s’appuie sur son propre limiteur de débit basé sur nginx, affiné depuis plus de dix ans. Faites une mauvaise requête et vous obtiendrez un simple 403 avant même votre deuxième café. J’ai passé beaucoup de temps à tester différentes approches face aux défenses de Craigslist, et ce guide en est le résultat : un tutoriel Python 2025 à jour, valable pour toutes les catégories, qui couvre la méthode d’extraction JSON-LD (le plus gros progrès par rapport aux anciens guides), des stratégies anti-bannissement réalistes, le cadre juridique, et une alternative sans code pour ceux qui veulent simplement les données sans écrire une seule ligne.
Que signifie extraire Craigslist avec Python ?
Le web scraping de Craigslist consiste à utiliser des scripts Python pour visiter automatiquement les pages Craigslist, en extraire les données structurées qui vous intéressent — titres, prix, descriptions, images, emplacements, dates de publication — puis les enregistrer dans un tableur, une base de données ou un fichier JSON.
Python est le langage de référence pour cela grâce à son écosystème de bibliothèques. Entre requests, BeautifulSoup, lxml et curl_cffi, vous pouvez créer un scraper Craigslist fonctionnel en moins de 100 lignes. La communauté est énorme, donc lorsque Craigslist change quelque chose (et cela arrive), quelqu’un a déjà trouvé la parade.
Le point essentiel à retenir : Craigslist . La seule interface programmatique officielle est la Bulk Posting Interface (BAPI), en écriture uniquement — elle permet aux annonceurs payants approuvés de publier des annonces, pas d’en récupérer. Tout produit « API Craigslist » que vous voyez sur des plateformes tierces n’est qu’un scraper non officiel, pas un endpoint autorisé. Si vous voulez des données en volume, il faut les extraire.
Pourquoi scraper Craigslist ? Cas d’usage concrets
Craigslist n’est pas seulement un endroit où trouver un canapé d’occasion. C’est un gigantesque jeu de données mis à jour en continu, couvrant des dizaines de secteurs. Voici qui en profite réellement :
| Cas d’usage | Qui en bénéficie | Ce que vous extrayez |
|---|---|---|
| Suivi des prix des appartements et locations | Agents immobiliers, locataires, entreprises PropTech | Prix, surface, chambres, quartier, latitude/longitude |
| Analyse du marché des voitures d’occasion | Concessions, applications grand public, chercheurs | Prix, marque, modèle, année, kilométrage, état |
| Études sur le marché de l’emploi | Recruteurs, économistes du travail, analystes RH | Intitulé, rémunération, type de contrat, date de publication |
| Génération de leads | Équipes commerciales, prestataires de services | Coordonnées, nom de l’entreprise, zone de service |
| Tarification concurrentielle | Prestataires locaux, opérations e-commerce | Prix des services, descriptions, zones desservies |
L’exemple académique le plus cité est le — environ 500 000 annonces de voitures d’occasion américaines avec 26 variables, qui a servi de base à des dizaines d’articles, dont une étude ResearchGate de 2024 sur la dynamique du marché des voitures d’occasion aux États-Unis. Des hedge funds ont acheté des données agrégées de locations Craigslist pour analyser les tendances des loyers. Et les équipes commerciales scrappent régulièrement les catégories services et gigs pour la génération de prospects.
Le calcul est simple : 8 heures de copier-coller manuel contre environ 10 minutes avec un scraper bien conçu.
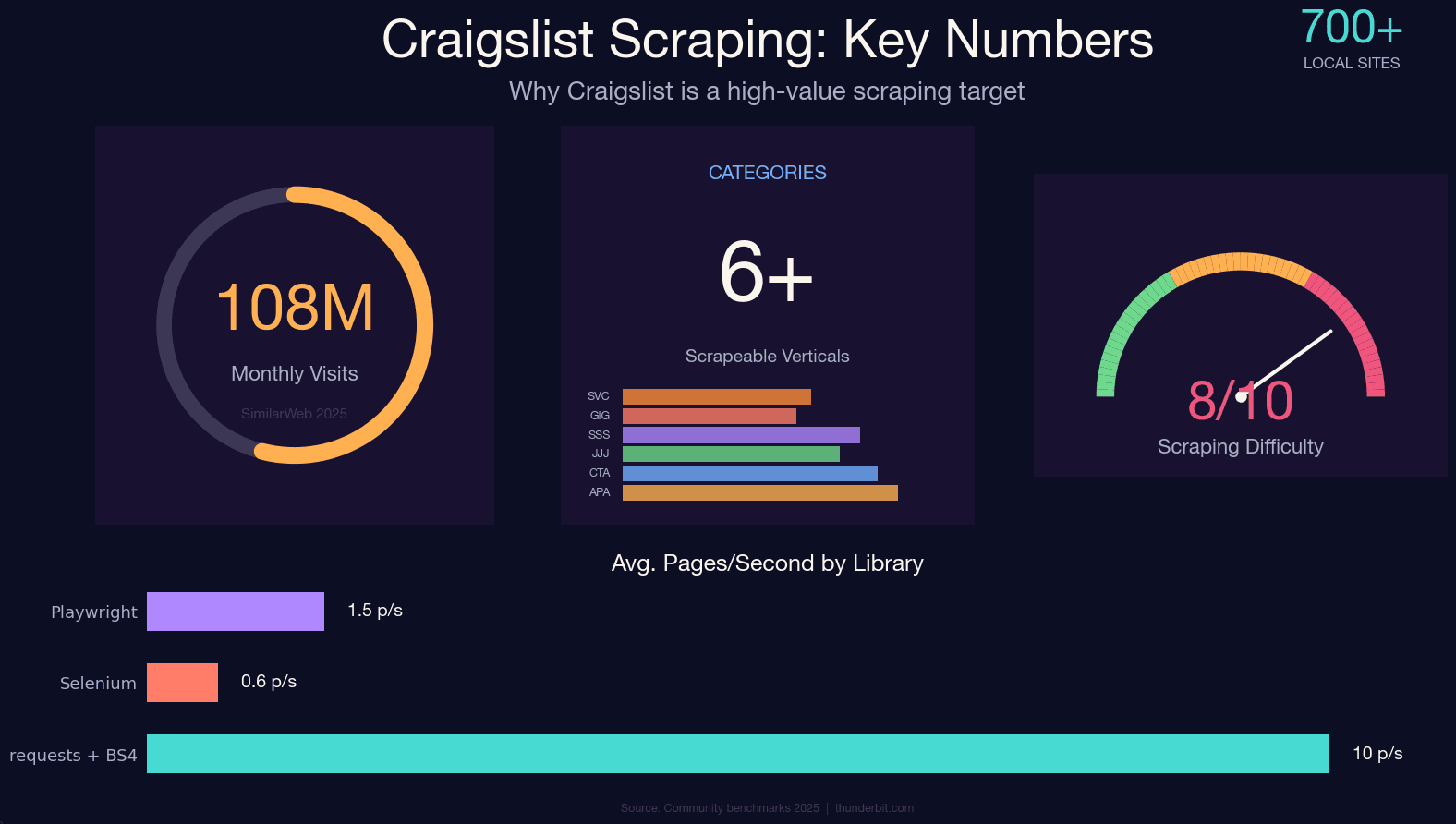
Scraper Craigslist avec Python : toutes les catégories, pas seulement les voitures
La plupart des guides que j’ai trouvés ne couvrent que les voitures à vendre — ce qui revient à écrire un tutoriel Google qui ne parlerait que de la recherche d’images. Craigslist compte des dizaines de catégories, et les structures d’URL varient selon chacune.
La structure est toujours la suivante : https://{ville}.craigslist.org/search/{category_slug}
Changez le sous-domaine de ville et le slug, et vous scrappez un secteur entièrement différent. Voici un tableau de référence des catégories les plus populaires (vérifié en avril 2025) :
| Catégorie | Slug d’URL | Champs typiques à extraire |
|---|---|---|
| Appartements / Logement | /search/apa | Prix, surface, chambres, emplacement, politique animaux |
| Voitures et camionnettes | /search/cta | Prix, marque, modèle, année, kilométrage |
| Emplois | /search/jjj | Intitulé, entreprise, salaire, type de contrat |
| Services | /search/bbb | Titre, description, numéro de téléphone, zone |
| Missions ponctuelles | /search/ggg | Titre, rémunération, date, catégorie |
| À vendre (général) | /search/sss | Titre, prix, état, emplacement |
Vous pouvez aussi empiler des paramètres de requête pour filtrer :
| Paramètre | Rôle | Exemple |
|---|---|---|
query | Mot-clé en texte intégral | ?query=studio |
min_price / max_price | Fourchette de prix | &min_price=1500&max_price=3000 |
hasPic | Uniquement les annonces avec images | &hasPic=1 |
postedToday | Dernières 24 heures | &postedToday=1 |
sort | Ordre d’affichage | &sort=priceasc |
s | Décalage de pagination (120 par page) | ?s=120 |
Ainsi, une URL comme https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1 vous donne les appartements à New York entre 1 500 $ et 3 000 $ avec photos. Tous les scripts Python de ce guide fonctionnent sur ces catégories — il suffit de changer le slug.
Sélecteurs HTML Craigslist 2025 : ancien vs nouveau (et le raccourci JSON)
La principale raison pour laquelle les scrapers Craigslist cassent, ce sont les changements de structure HTML. Si vous suivez un tutoriel de 2022 qui vous dit de cibler .result-row ou .result-info, votre scraper est déjà hors service.
Craigslist a réécrit le balisage de ses résultats de recherche en 2023–2024. Les anciennes classes existent encore, imbriquées dans de nouveaux conteneurs, mais les cibler au niveau supérieur du DOM renvoie une liste vide. Voici ce qui a changé :
| Élément | Sélecteur ancien (avant 2024) | Sélecteur actuel (2025) |
|---|---|---|
| Conteneur d’annonce | .result-info | .cl-search-result |
| Lien du titre | .result-title | .posting-title a |
| Prix | .result-price | .priceinfo |
| Métadonnées (zone) | .result-hood | .meta |
Mais voici l’idée vraiment importante — celle qui distingue un scraper à jour en 2025 du reste : vous n’avez pas besoin d’analyser le HTML pour les résultats de recherche.
Craigslist intègre désormais chaque annonce visible dans une balise <script id="ld_searchpage_results"> sous forme de données structurées JSON-LD. Un simple appel requests.get() renvoie le schéma schema.org complet ItemList avec chaque annonce de la page — titre, prix, devise, emplacement, URL de l’image, lien vers la page détail. Aucun rendu JavaScript n’est nécessaire. Aucun sélecteur CSS fragile non plus.
L’approche JSON-LD est plus rapide, plus stable, et bien moins susceptible de casser lorsque Craigslist modifie son interface. C’est celle qu’utilisent tous les dépôts GitHub activement maintenus, et c’est celle que nous utiliserons dans le tutoriel ci-dessous.
Seule réserve : le bloc JSON-LD est — appartements (apa), ventes (sss), voitures (cta), logement (hhh). Il est souvent absent ou incomplet pour les emplois (jjj), missions (ggg), communauté (ccc) et services (bbb), car ces annonces n’ont pas de pricing schema.org/Offer. Pour ces catégories, revenez au chemin HTML .cl-search-result.
Choisir votre stack Python : Requests + BS4 vs Selenium vs Playwright
C’est la question qui revient dans tous les forums de scraping : « Quelle bibliothèque dois-je utiliser ? » Pour Craigslist en particulier, la réponse est plus tranchée que pour la plupart des sites.
| Critère | requests + BeautifulSoup | Selenium | Playwright |
|---|---|---|---|
| Vitesse | 5–15 pages/sec (limité par le réseau) | 0,3–1 page/sec | 0,5–2 pages/sec |
| Contenu rendu en JS | Non | Oui | Oui |
| Mémoire | ~30–60 Mo | ~400–700 Mo | ~300–500 Mo |
| Complexité d’installation | Faible | Moyenne | Moyenne |
| Résistance anti-bot | Faible (headers/proxies requis) | Moyenne (vrai navigateur) | Moyenne à élevée |
| Meilleur usage sur Craigslist | Résultats de recherche (JSON-LD) | Pages détail avec contenu dynamique | Scraping asynchrone à grande échelle |
| Courbe d’apprentissage | Débutant | Intermédiaire | Intermédiaire |
Les pages Craigslist sont rendues côté serveur. Le bloc JSON-LD est présent dans le HTML initial. Il n’y a pas de défi JavaScript sur les pages de lecture. Tous les utilisent requests + BeautifulSoup ou Scrapy. Aucun n’utilise Selenium ou Playwright. Ce n’est pas un hasard : un framework d’automatisation de navigateur ajoute des centaines de Mo de mémoire, une pénalité de vitesse de 10 à 100×, et une empreinte plus visible, sans avantage réel.
Ma recommandation :
- requests + BS4 : commencez ici. C’est l’association idéale pour la méthode d’extraction JSON-LD et elle couvre 95 % des besoins de scraping Craigslist.
- Selenium : seulement si vous devez interagir avec du contenu dynamique sur certaines pages détail (rare sur Craigslist).
- Playwright : si vous passez à des milliers de pages avec concurrence asynchrone — mais honnêtement, sur Craigslist, le goulot d’étranglement est le limiteur de débit, pas la bibliothèque.
Nous avons déjà couvert la comparaison ainsi qu’un panorama des dans des articles séparés si vous voulez un décryptage complet.
L’alternative sans code : extraire Craigslist sans écrire de Python
Petite parenthèse avant le code — cette section s’adresse à ceux qui ne sont pas développeurs. Agents immobiliers, équipes commerciales, responsables opérations : si vous voulez juste les données et que vous ne souhaitez pas coder en Python, il existe un chemin plus rapide.
est un extracteur Web IA sous forme d’extension Chrome. Il peut extraire Craigslist en environ 2 clics, sans code. Voici le flux :
- Ouvrez n’importe quelle page de résultats Craigslist (appartements, voitures, emplois — quelle que soit la catégorie).
- Cliquez sur « AI Suggest Fields » dans la barre latérale Thunderbit. L’IA lit la page et détecte automatiquement les colonnes comme le titre, le prix, l’emplacement et le lien.
- Cliquez sur « Scrape » — les données sont extraites en quelques secondes.
- Utilisez le scraping de sous-pages pour visiter la page détail de chaque annonce et enrichir vos données avec les descriptions complètes, numéros de téléphone, images et attributs.
- Exportez directement vers Google Sheets, Excel, Airtable ou Notion — totalement gratuit.
Pour des besoins récurrents — par exemple un suivi quotidien des prix des appartements ou des instantanés hebdomadaires d’offres d’emploi — le Scheduled Scraper de Thunderbit vous permet de décrire la planification en langage naturel, puis l’exécution se fait automatiquement. Pas de cron, pas de configuration serveur.
Thunderbit gère également les protections anti-bot via son mode Cloud Scraping, donc pas besoin de proxies rotatifs ni d’headers complexes. Si vous voulez essayer, téléchargez la et voyez par vous-même.
Si vous voulez un contrôle total et une personnalisation poussée, poursuivez avec le pas-à-pas Python.
Étape par étape : comment scraper Craigslist avec Python (tutoriel complet)
- Difficulté : intermédiaire
- Temps nécessaire : ~30 minutes (installation + premier scraping)
- Ce qu’il vous faut : Python 3.8+, navigateur Chrome (pour inspecter les pages), un terminal
Étape 1 : préparer votre environnement Python
Installez les bibliothèques nécessaires :
1pip install requests beautifulsoup4 lxmllxml est optionnelle mais accélère sensiblement l’analyse BeautifulSoup. Si vous rencontrez ensuite des problèmes de fingerprint TLS (nous y revenons dans la section anti-bannissement), vous pouvez aussi installer curl_cffi :
1pip install curl_cffiVotre bloc d’imports :
1import requests
2from bs4 import BeautifulSoup
3import json
4import csv
5import time
6import randomVous disposez maintenant d’un environnement Python propre avec toutes les dépendances installées.
Étape 2 : construire l’URL Craigslist pour n’importe quelle catégorie
Générez dynamiquement l’URL cible à partir de la ville + du slug de catégorie + des filtres optionnels :
1from urllib.parse import urlencode
2BASE = "https://{city}.craigslist.org/search/{slug}"
3def build_url(city, slug, **params):
4 return f"{BASE.format(city=city, slug=slug)}?{urlencode(params)}"
5# Exemple : appartements à New York, 1500–3000 $, avec photos
6url = build_url("newyork", "apa", min_price=1500, max_price=3000, hasPic=1)
7print(url)
8# https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1Remplacez "apa" par "cta" (voitures), "jjj" (emplois), "bbb" (services), ou n’importe quel slug du tableau de catégories ci-dessus. Remplacez "newyork" par "sfbay", "chicago", "losangeles", etc.
Étape 3 : récupérer la page et extraire le JSON embarqué
Envoyez une requête GET avec des headers corrects, puis analysez le bloc JSON-LD :
1HEADERS = {
2 "User-Agent": (
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/124.0.0.0 Safari/537.36"
6 ),
7 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept-Encoding": "gzip, deflate, br",
10 "Referer": "https://www.craigslist.org/",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-Mode": "navigate",
13 "Sec-Fetch-Site": "same-origin",
14 "Upgrade-Insecure-Requests": "1",
15}
16session = requests.Session()
17r = session.get(url, headers=HEADERS, timeout=20)
18r.raise_for_status()
19soup = BeautifulSoup(r.text, "html.parser")
20tag = soup.select_one("script#ld_searchpage_results")
21data = json.loads(tag.text) if tag else {"itemListElement": []}Si tag vaut None, le bloc JSON-LD n’est pas présent pour cette catégorie — revenez à l’analyse HTML (voir le tableau des sélecteurs plus haut). Pour les appartements, voitures et catégories à vendre, le bloc JSON-LD est généralement bien présent.
Étape 4 : transformer les annonces en enregistrements structurés
Itérez sur les éléments JSON et extrayez les champs nécessaires :
1listings = []
2for entry in data["itemListElement"]:
3 item = entry["item"]
4 offers = item.get("offers", {}) or {}
5 addr = (offers.get("availableAtOrFrom") or {}).get("address", {})
6 listings.append({
7 "name": item.get("name"),
8 "url": offers.get("url"),
9 "price": offers.get("price"),
10 "currency": offers.get("priceCurrency"),
11 "locality": addr.get("addressLocality"),
12 "region": addr.get("addressRegion"),
13 "image": item.get("image"),
14 })
15print(f"Found {len(listings)} listings")Vous devriez voir quelque chose comme « Found 120 listings » (Craigslist affiche 120 résultats par page). Certaines annonces peuvent avoir None pour le prix si l’auteur ne l’a pas indiqué — gérez cela proprement dans la suite de votre logique.
Étape 5 : scraper les pages détail pour des données plus riches
Les résultats de recherche ne donnent qu’un résumé. Pour obtenir les descriptions complètes, les attributs (chambres, surface, politique animaux), les coordonnées lat/long et les images, il faut visiter l’URL détail de chaque annonce.
1def fetch_detail(url, session):
2 r = session.get(url, headers=HEADERS, timeout=20)
3 r.raise_for_status()
4 s = BeautifulSoup(r.text, "html.parser")
5 body = s.select_one("#postingbody")
6 mp = s.select_one("#map")
7 return {
8 "description": body.get_text("\n", strip=True) if body else None,
9 "attributes": [x.get_text(" ", strip=True)
10 for x in s.select("p.attrgroup span, div.attrgroup .attr")],
11 "lat": mp.get("data-latitude") if mp else None,
12 "lng": mp.get("data-longitude") if mp else None,
13 "images": [img["src"] for img in s.select("div.gallery img")],
14 }
15for item in listings:
16 item.update(fetch_detail(item["url"], session))
17 time.sleep(random.uniform(3, 6)) # indispensable : jitter anti-bannissementLe time.sleep(random.uniform(3, 6)) n’est pas facultatif. Supprimez-le et vous risquez un 403 en quelques dizaines de requêtes. Les pages détail sont rendues côté serveur avec des sélecteurs stables (#titletextonly, #postingbody, #map) qui n’ont presque pas changé depuis 2017 — l’une des rares choses fiables chez Craigslist.
Étape 6 : gérer la pagination pour tout extraire
Craigslist utilise le paramètre de décalage ?s=120 pour la pagination. Chaque page affiche 120 résultats, et le décalage maximal est généralement 2999.
1def iter_all(city, slug, max_pages=25, **filters):
2 for page in range(max_pages):
3 offset = page * 120
4 url = build_url(city, slug, s=offset, **filters)
5 r = session.get(url, headers=HEADERS, timeout=20)
6 r.raise_for_status()
7 soup = BeautifulSoup(r.text, "html.parser")
8 tag = soup.select_one("script#ld_searchpage_results")
9 if not tag:
10 break
11 data = json.loads(tag.text)
12 items = data.get("itemListElement", [])
13 if not items:
14 break
15 for entry in items:
16 item = entry["item"]
17 offers = item.get("offers", {}) or {}
18 yield {
19 "name": item.get("name"),
20 "url": offers.get("url"),
21 "price": offers.get("price"),
22 }
23 time.sleep(random.uniform(2.5, 5.0))N’essayez pas de scrapper des milliers de pages à toute vitesse. Le limiteur de débit de Craigslist fonctionne par IP, et le débit soutenable sur une seule IP plafonne autour de 0,3–0,5 requête/seconde, quelle que soit la bibliothèque utilisée. Cette limite est imposée par Craigslist, pas par Python.
Étape 7 : exporter vos données Craigslist en CSV, JSON ou Google Sheets
Enregistrez vos résultats :
1# CSV
2with open("craigslist.csv", "w", newline="", encoding="utf-8") as f:
3 w = csv.DictWriter(f, fieldnames=listings[0].keys())
4 w.writeheader()
5 w.writerows(listings)
6# JSON
7with open("craigslist.json", "w", encoding="utf-8") as f:
8 json.dump(listings, f, indent=2, ensure_ascii=False)Si vous préférez éviter complètement le code d’export, Thunderbit permet l’export gratuit vers Google Sheets, Excel, Airtable ou Notion directement depuis le navigateur. Mais pour les pipelines Python, CSV et JSON restent les sorties standards. Vous pouvez aussi envoyer les données directement dans pandas pour l’analyse ou dans une base de données avec sqlite3.
Comment éviter de se faire bannir en scrappant Craigslist avec Python
La plupart des tutoriels survolent cette partie. Le système anti-bot de Craigslist est conçu sur mesure, pas acheté sur étagère, et il a quelques particularités.

Utilisez des headers de requête réalistes
Craigslist vérifie l’ordre et l’exhaustivité des headers. Une requête sans Sec-Fetch-Dest ou avec un User-Agent obsolète sera signalée avant même d’atteindre le contenu. Le jeu complet de headers Chrome 120+ (montré à l’étape 3) est le minimum. Faites tourner le User-Agent par session parmi 5 à 10 chaînes récentes Chrome/Firefox desktop — mais ne le changez pas en cours de session, cela paraît artificiel.
L’absence des headers Sec-Fetch-* est la raison la plus fréquente des blocages instantanés chez les scrapers débutants.
Ajoutez des délais aléatoires entre les requêtes
Le consensus de (ScrapingBee, Scraperly, Oxylabs, Multilogin) converge vers 2 à 5 secondes aléatoires entre les pages de recherche et 3 à 6 secondes entre les pages détail. Des intervalles fixes ressemblent à un bot. Utilisez time.sleep(random.uniform(2, 5)) — jamais time.sleep(2).
Faites tourner des proxies (si vous scrappez à grande échelle)
Craigslist bloque à l’avance certaines plages IP AWS, GCP et Azure. Les proxies de datacenter sont souvent morts dès le premier essai. Au-delà de quelques centaines de pages, il vous faut des proxies résidentiels rotatifs, renouvelés toutes les 20 à 30 requêtes. Les proxies mobiles présentent le plus faible risque de détection, mais coûtent 8 à 30 $/Go.
| Type de proxy | Risque de détection sur Craigslist | Coût (2025) |
|---|---|---|
| Datacenter | Très élevé — souvent bloqué dès la première requête | 0,50–2 $/Go |
| Résidentiel rotatif | Faible — recommandé | 5–15 $/Go |
| Mobile | Le plus faible | 8–30 $/Go |
Le mode Cloud Scraping de Thunderbit gère automatiquement la rotation des proxies si vous préférez ne pas vous en occuper.
Gérez les CAPTCHA avec souplesse
Les CAPTCHA sur Craigslist sont rares dans les parcours de lecture — ils apparaissent surtout pour publier ou répondre. Si vous en voyez un : stoppez pendant au moins 60 secondes, changez d’IP, videz les cookies et ralentissez le rythme. Des CAPTCHA récurrents indiquent que votre cadence est trop agressive, pas qu’il faut les forcer avec un solveur.
Respectez les limites de débit et implémentez un backoff
Craigslist renvoie un 403 (et non un 429) lorsque sa limite est atteinte. Un 403 signifie que l’IP courante est sur liste de blocage — ne retentez pas à l’aveugle. Changez d’IP, modifiez le User-Agent et attendez.
1from requests.adapters import HTTPAdapter
2from urllib3.util.retry import Retry
3retry = Retry(
4 total=5,
5 backoff_factor=1.5, # 1,5 ; 3 ; 6 ; 12 ; 24 s
6 status_forcelist=[429, 500, 502, 503, 504],
7 allowed_methods={"GET"},
8 respect_retry_after_header=True,
9)
10adapter = HTTPAdapter(max_retries=retry)
11session.mount("https://", adapter)Autre conseil : les retours d’expérience de la communauté citent régulièrement la plage 2 h–6 h du matin, heure locale de la ville ciblée comme la plus sûre, avec environ 30 à 40 % de blocages en moins qu’en journée.
Fingerprinting TLS — le piège caché
La couche anti-bot de Craigslist inspecte le ClientHello TLS. La bibliothèque Python requests (basée sur OpenSSL) a une empreinte JA3 qui ne correspond à aucun navigateur réel. Un User-Agent parfait associé à une empreinte TLS non navigateur est un désaccord détectable. La solution consiste à utiliser avec impersonate="chrome124", qui reproduit la poignée de main TLS de Chrome :
1from curl_cffi import requests as cffi_requests
2r = cffi_requests.get(url, headers=HEADERS, impersonate="chrome124")Si vous obtenez des 403 inexpliqués avec des IP résidentielles propres et des headers corrects, le fingerprint TLS est très probablement en cause.
robots.txt de Craigslist, conditions d’utilisation et scraping éthique
La plupart des guides ignorent complètement ce point ou glissent une phrase dans la FAQ. Étant donné que Craigslist a obtenu un contre un scraper (RadPad, 2017), il mérite plus qu’une note de bas de page.
Ce que dit vraiment le robots.txt de Craigslist
Le est étonnamment court. Il contient un seul bloc User-agent: * avec seulement sept chemins interdits :
1Disallow: /reply
2Disallow: /fb/
3Disallow: /suggest
4Disallow: /flag
5Disallow: /mf
6Disallow: /mailflag
7Disallow: /eafLes sept sont des endpoints interactifs ou modifiants : répondre, signaler, suggérer, envoyer un lien par e-mail. Les pages d’annonces (/search/..., URL des annonces individuelles) ne sont pas interdites. Il n’y a pas d’instruction Crawl-delay, même si Craigslist impose de fait une limitation par blocage d’IP.
Les sous-domaines des villes publient aussi des sitemaps — par exemple https://newyork.craigslist.org/sitemap/index.xml — qui constituent le chemin officiellement découvrable vers les annonces.
Jurisprudence : les affaires importantes
Craigslist v. 3Taps (2013, règlement en 2015) : 3Taps a scrappé des annonces Craigslist puis les a revendues. Lorsque Craigslist a envoyé une mise en demeure et bloqué leurs IP, 3Taps a contourné ce blocage avec des proxies rotatifs. Le tribunal a estimé que contourner des blocages IP après révocation explicite constituait un accès « sans autorisation » au sens du CFAA. 3Taps .
Meta v. Bright Data (2024) : une décision plus récente a jugé que les conditions d’utilisation de Meta ne peuvent pas interdire le scraping, hors connexion, de données publiques accessibles. Le tribunal a considéré qu’un scraper déconnecté était « dans la même position qu’un visiteur ». C’est la décision la plus importante pour les scrapers de 2024–2025 — si vous ne créez jamais de compte Craigslist, ne vous connectez jamais et n’accédez qu’aux pages visibles publiquement, les CGU ne sont pas forcément opposables comme un contrat.
L’enseignement pratique : le risque CFAA est nettement réduit après Van Buren (2021) et hiQ v. LinkedIn (2022) pour les pages accessibles publiquement. Mais les actions de droit civil au niveau des États (trespass-to-chattels, appropriation indue) restent possibles — c’est elles qui ont conduit au règlement 3Taps et au jugement de 60,5 M$ contre RadPad.
Ceci est une information générale, pas un avis juridique. Si vous scrapez Craigslist à des fins commerciales, consultez un avocat.
Checklist pratique pour un scraping éthique
- ✅ Respectez chaque
Disallowdu robots.txt — surtout les sept endpoints d’action - ✅ Restez largement sous les 1 000 pages par période de 24 heures et par IP (les CGU de Craigslist prévoient au-delà, à titre de dommages liquidés)
- ✅ Restez déconnecté — ne créez jamais de compte Craigslist pour scraper
- ✅ Ne contournez jamais un blocage IP avec des proxies après un blocage explicite (c’est ce qui a perdu 3Taps)
- ✅ Ajoutez des délais entre les requêtes — 2 à 5 secondes minimum
- ✅ Ne scrapez pas les coordonnées personnelles pour du spam
- ✅ Ne redistribuez pas les données brutes Craigslist ni ne les présentez comme votre propre plateforme
- ✅ Utilisez les données pour la recherche légitime, l’analyse ou un usage personnel
- ✅ Préférez les sitemaps publiés au crawling à l’aveugle quand c’est possible
- ✅ Supprimez les données personnelles (e-mails, numéros de téléphone) à l’ingestion si vous stockez les données
Nous avons rédigé un guide plus approfondi sur les si vous voulez une vision complète.
Python vs sans code : quelle approche vous convient ?
| Critère | Python (requests + BS4) | Thunderbit (sans code) |
|---|---|---|
| Temps de mise en route | 30–60 min (installation, écriture du code) | 2 minutes (installation de l’extension Chrome) |
| Compétence technique requise | Python intermédiaire | Aucune |
| Personnalisation | Contrôle total sur la logique, les champs et le flux | L’IA détecte automatiquement les champs ; l’utilisateur peut ajuster |
| Échelle | Illimitée (avec proxies, planification) | Scheduled Scraper pour les tâches récurrentes |
| Gestion anti-bannissement | Manuelle (headers, délais, proxies, TLS) | Intégrée (Cloud Scraping) |
| Options d’export | CSV, JSON (à coder soi-même) | Google Sheets, Excel, Airtable, Notion — gratuit |
| Idéal pour | Développeurs, data scientists, pipelines personnalisés | Équipes commerciales, agents immobiliers, responsables opérations |
Utilisez Python si vous avez besoin d’une personnalisation totale, si vous comptez l’intégrer dans un pipeline de données plus large, ou si vous voulez comprendre précisément ce qui se passe sous le capot. Utilisez si vous voulez des résultats rapides sans écrire ni maintenir de code. Les deux approches sont valables. Tout dépend de votre cas d’usage et de votre préférence : terminal ou navigateur.
Conclusion
Craigslist est une source de données riche et constamment mise à jour, couvrant le logement, les voitures, les emplois, les services, les missions et bien plus encore — et comme il n’existe pas d’API publique, le scraping est la seule manière d’obtenir des données structurées à grande échelle. L’approche 2025 qui fonctionne vraiment : extraire le JSON-LD embarqué depuis les résultats de recherche (pas des sélecteurs CSS fragiles), utiliser requests + BeautifulSoup (pas Selenium), ajouter des headers réalistes avec les champs Sec-Fetch-*, randomiser les délais, et utiliser des proxies résidentiels si vous dépassez quelques centaines de pages.
La méthode JSON-LD est de loin l’amélioration la plus importante par rapport aux guides obsolètes. Elle est plus rapide, plus résistante aux changements d’interface, et ne nécessite aucun rendu JavaScript. Associez-la aux stratégies anti-bannissement ci-dessus et vous éviterez les 403 qui piègent la plupart des scrapers.
Si vous préférez éviter complètement le code, la peut scraper n’importe quelle catégorie Craigslist en quelques clics et exporter directement vers votre tableur ou base de données préféré. Si vous voulez aller plus loin, nos guides sur et sur les détaillent les fondamentaux.
FAQ
Est-il légal de scraper Craigslist ?
Les Conditions d’utilisation de Craigslist interdisent le scraping automatisé et prévoient une clause de dommages liquidés (0,25 $/page au-delà de 1 000/jour). Cependant, des décisions récentes — notamment Meta v. Bright Data (2024) et hiQ v. LinkedIn (2022) — ont réduit la responsabilité au titre du CFAA pour le scraping, hors connexion, de données publiques accessibles. Les actions de droit civil au niveau des États (trespass-to-chattels) restent un risque, surtout pour une redistribution commerciale. Respectez le robots.txt, restez déconnecté, ajoutez des délais et ne redistribuez pas les données brutes. Ceci est une information générale, pas un avis juridique.
Craigslist a-t-il une API publique ?
Non. Craigslist propose uniquement une Bulk Posting Interface (BAPI) en écriture, réservée aux annonceurs payants approuvés. Il n’existe ni API de lecture publique, ni portail développeur, ni palier rate-limité pour récupérer des données. Chaque produit « Craigslist API » que vous voyez sur des plateformes tierces est un scraper non officiel.
Pourquoi mon scraper Craigslist casse-t-il sans arrêt ?
C’est presque toujours dû à des changements de structure HTML. Craigslist a réécrit le balisage de ses résultats de recherche en 2023–2024, et les guides utilisant des sélecteurs hérités comme .result-row ou .result-info ne fonctionnent plus. Passez à la méthode JSON-LD intégrée (en analysant script#ld_searchpage_results) pour une approche bien plus robuste. Vérifiez aussi que vos headers incluent Sec-Fetch-* — leur absence déclenche des blocages instantanés.
Puis-je scraper Craigslist sans Python ?
Oui. L’extension Chrome d’IA de Thunderbit fonctionne sur n’importe quelle page Craigslist — appartements, voitures, emplois, services. Cliquez sur « AI Suggest Fields » pour détecter automatiquement les colonnes, puis sur « Scrape » pour extraire les données, et exportez gratuitement vers Google Sheets, Excel, Airtable ou Notion. Aucun code, aucune configuration, aucun proxy à gérer.
À quelle fréquence puis-je scraper Craigslist sans me faire bannir ?
Avec une seule IP résidentielle, le débit soutenable est d’environ 0,3 à 0,5 requête par seconde, avec des délais aléatoires de 2 à 5 secondes entre les pages. Restez sous 1 000 pages par période de 24 heures et par IP pour éviter à la fois les bannissements et le seuil de dommages liquidés dans les CGU de Craigslist. Scraper en heures creuses (2 h à 6 h du matin, heure locale de la ville cible) réduit les blocages d’environ 30 à 40 %. Pour des volumes plus importants, faites tourner des proxies résidentiels toutes les 20 à 30 requêtes.
En savoir plus