Résumé exécutif
posait une question de politique : parmi les sites web les plus visités au monde, combien indiquent aux crawlers IA ce qu’ils peuvent ou non faire ?
Cette suite pose la question opérationnelle sous-jacente : dans quelle mesure robots.txt constitue-t-il une infrastructure fiable pour porter cette politique ?
La réponse est inconfortable. robots.txt fonctionne encore parce qu’il est public, peu coûteux, lisible par machine et déjà compris des crawlers. Mais on lui demande bien plus que ce pour quoi il a été conçu. En 2026, ce même fichier en texte brut peut contenir des contrôles de crawl pour le SEO, des index de sitemaps, des extensions héritées des moteurs de recherche, des options de refus d’entraînement IA, du vocabulaire de politique injecté par Cloudflare, des réserves de droits d’auteur et un langage juridique destiné à de futurs litiges.
C’est de la dette de configuration.
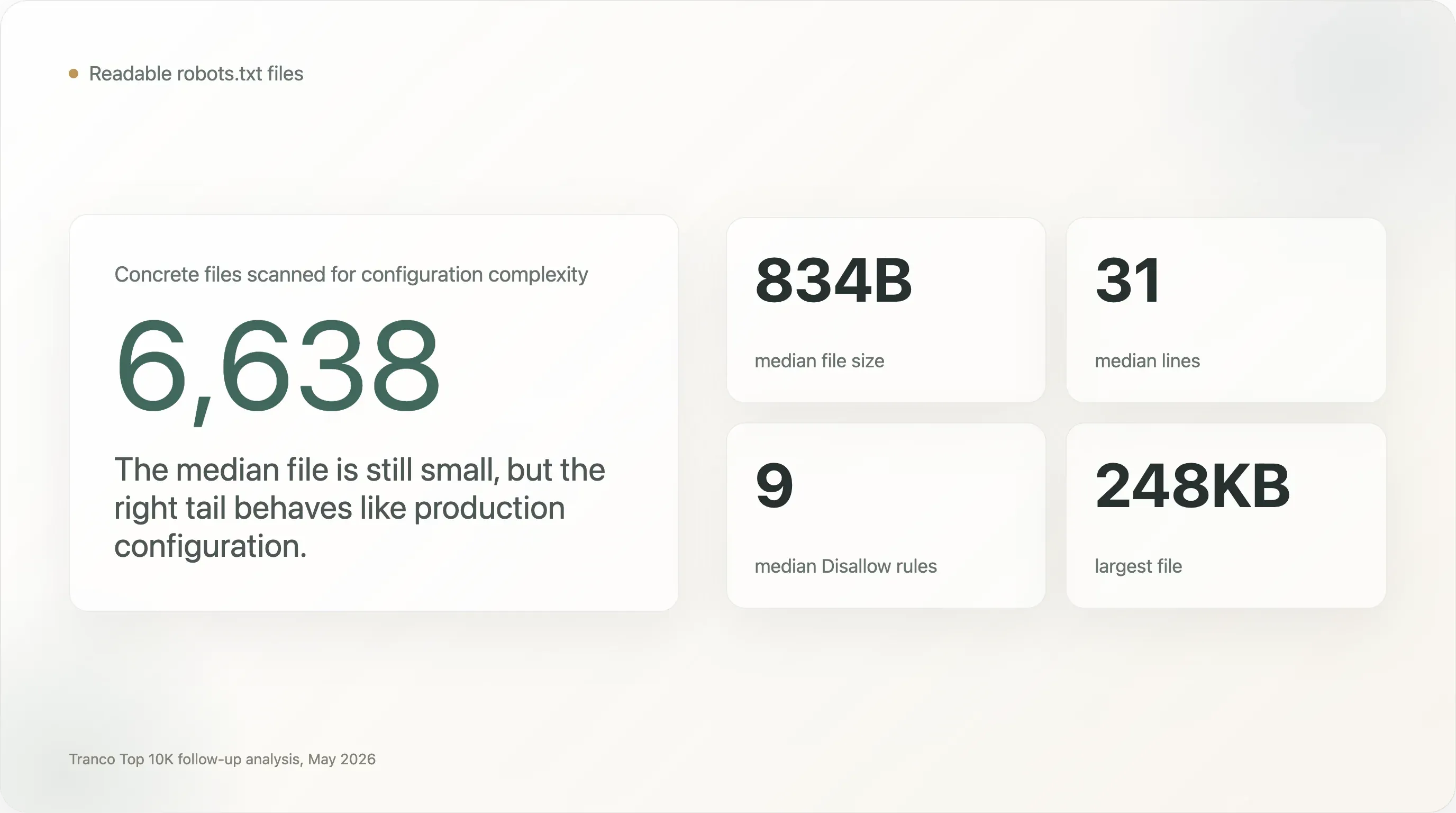
Le jeu de données derrière ce rapport est le même crawl du Tranco Top 10 000 utilisé dans l’étude originale sur les crawlers IA. Sur les 10 000 domaines, 6 638 ont renvoyé un robots.txt lisible ; 610 autres ont renvoyé un 404, qui est traité par le protocole comme une autorisation implicite. Cela donne 7 248 sites analysables pour les décisions d’accès des bots et 6 638 fichiers concrets pour l’analyse de la complexité de configuration.
Six enseignements ressortent :
-
La plupart des fichiers
robots.txtsont minuscules, mais la queue droite est extrêmement complexe. La taille médiane d’un fichier n’est que de 834 octets et 31 lignes. Mais 1 005 fichiers font au moins 5 Ko, 273 au moins 20 Ko et 28 au moins 100 Ko. Le plus grand fichier de l’échantillon atteint 248 Ko. -
Des centaines de grands sites utilisent des fichiers qui ressemblent davantage à une configuration de production qu’à des notes de politique. Le fichier médian comporte 9 directives
Disallow. Mais 707 sites ont au moins 100 règlesDisallow, 13 en ont au moins 1 000, 240 nomment au moins 50 user-agents et 110 en nomment au moins 100. -
La dérive du protocole n’est pas théorique. Parmi les 6 638 fichiers lisibles, 685 contiennent
Crawl-delay, 303Host, 200Clean-param, 9Request-rate, 5Visit-timeet 271 un langage de typeContent-Signalà la Cloudflare. Tout cela ne relève pas d’une norme unique et propre. Ce sont des couches successives de folklore des crawlers. -
Googlebot est traité comme un citoyen spécial. 562 domaines analysables bloquent au moins un crawler de recherche traditionnel. Dans 404 de ces cas, Googlebot est autorisé alors qu’au moins un autre crawler de recherche est bloqué. La discrimination envers les crawlers IA n’est pas apparue dans un écosystème neutre ;
robots.txtcodifiait déjà une hiérarchie entre moteurs de recherche. -
La politique IA rend cette dette plus visible. 1 377 fichiers lisibles contiennent un langage lié à la politique IA ; 719 contiennent du vocabulaire sur le copyright, les conditions d’utilisation, la licence ou l’autorisation ; et 501 contiennent les deux. Le fichier est devenu à la fois interface machine et artefact juridique. C’est utile, mais fragile.
-
Les fichiers les plus risqués ne sont pas toujours les plus anti-IA. Le e-commerce, le voyage, les réseaux sociaux, la finance, le monde académique et l’actualité produisent tous des fichiers complexes pour des raisons différentes : contrôle du budget de crawl, chemins hérités, contenu généré par les utilisateurs, réserves de droits et exceptions spécifiques aux bots. Les règles IA s’ajoutent à une base déjà confuse.
La conclusion principale : robots.txt reste la surface de politique des crawlers la plus importante du Web public, mais c’est une base fragile pour une gouvernance IA à forts enjeux, à moins que l’écosystème ne standardise l’identité des crawlers, le vocabulaire d’usage de l’IA et l’auditabilité des politiques.
Méthodologie
Ce rapport réutilise le jeu de données de l’analyse Thunderbit originale sur la politique des crawlers IA dans les domaines du Tranco Top 10 000.
Les éléments d’entrée étaient :
tranco_top10k.csv— la liste originale des 10 000 domaines Tranco.out/fetch_meta.csv— le statut de récupération, le nombre d’octets, le schéma, le résultat de redirection et les métadonnées d’erreur.out/sites.csv— domaine, rang, catégorie, langue et statutrobots.txt.out/site_meta.csv— une ligne analytique par site, incluant la classe de modèle, les indicateurs de blocage IA, la taille du fichier et les champs de synthèse de la politique des bots.out/bot_status.csv— une ligne par domaine et crawler, indiquant si ce bot est bloqué et si une règle spécifique existe.raw_robots/— les corpsrobots.txtmis en cache pour les 6 638 sites ayant renvoyé le statut200.
Pour cette suite, chaque fichier robots.txt lisible a été analysé pour :
- la taille du fichier et le nombre de lignes ;
- les lignes actives hors commentaires ;
- les nombres d’instructions
User-agent,Disallow,AllowetSitemap; - les instructions héritées ou non essentielles comme
Crawl-delay,Host,Clean-param,Request-rateetVisit-time; - le vocabulaire de l’ère IA, notamment
Content-Signal,llms.txt, AI, LLM, machine learning, TDM et2019/790; - le vocabulaire juridique comme copyright, conditions d’utilisation, licence, autorisation et formulations de réserve de droits ;
- le traitement des crawlers de recherche pour Googlebot, Bingbot, DuckDuckBot, Slurp, Baiduspider et YandexBot.
Le rapport définit aussi un simple score de dette de configuration pour le triage. Il combine la taille du fichier, le nombre de user-agents, le nombre de Disallow, le nombre de Allow, le nombre d’instructions non standard et le mélange de langage de politique IA et juridique. Ce score n’est pas censé mesurer la conformité universelle. C’est un moyen d’identifier les fichiers susceptibles d’être difficiles à maintenir, à relire ou à interpréter.
Tous les tableaux et graphiques dérivés sont inclus dans le dossier de livraison.
Enseignement 1 : le fichier médian est simple ; la queue ne l’est pas
Le fichier robots.txt typique sur le grand Web reste petit.
Sur les 6 638 fichiers lisibles :
| Métrique | Médiane | P90 | P95 | P99 | Max |
|---|---|---|---|---|---|
| Taille du fichier | 834 octets | 6,7 Ko | 15,8 Ko | 76,0 Ko | 248,3 Ko |
| Lignes | 31 | 238 | 332 | 1 008 | 4 998 |
| Lignes actives | 23 | 198 | 282 | 837 | 4 998 |
Directives User-agent | 1 | 21 | 39 | 137 | 823 |
Directives Disallow | 9 | 103 | 176 | 422 | 4 997 |
Directives Allow | 1 | 17 | 33 | 69 | 890 |
Cette distribution compte, car on parle souvent de robots.txt comme s’il s’agissait d’une simple déclaration :
1User-agent: *
2Disallow: /private/Ce modèle mental est faux pour une minorité significative des sites à fort trafic.
Dans ce jeu de données :
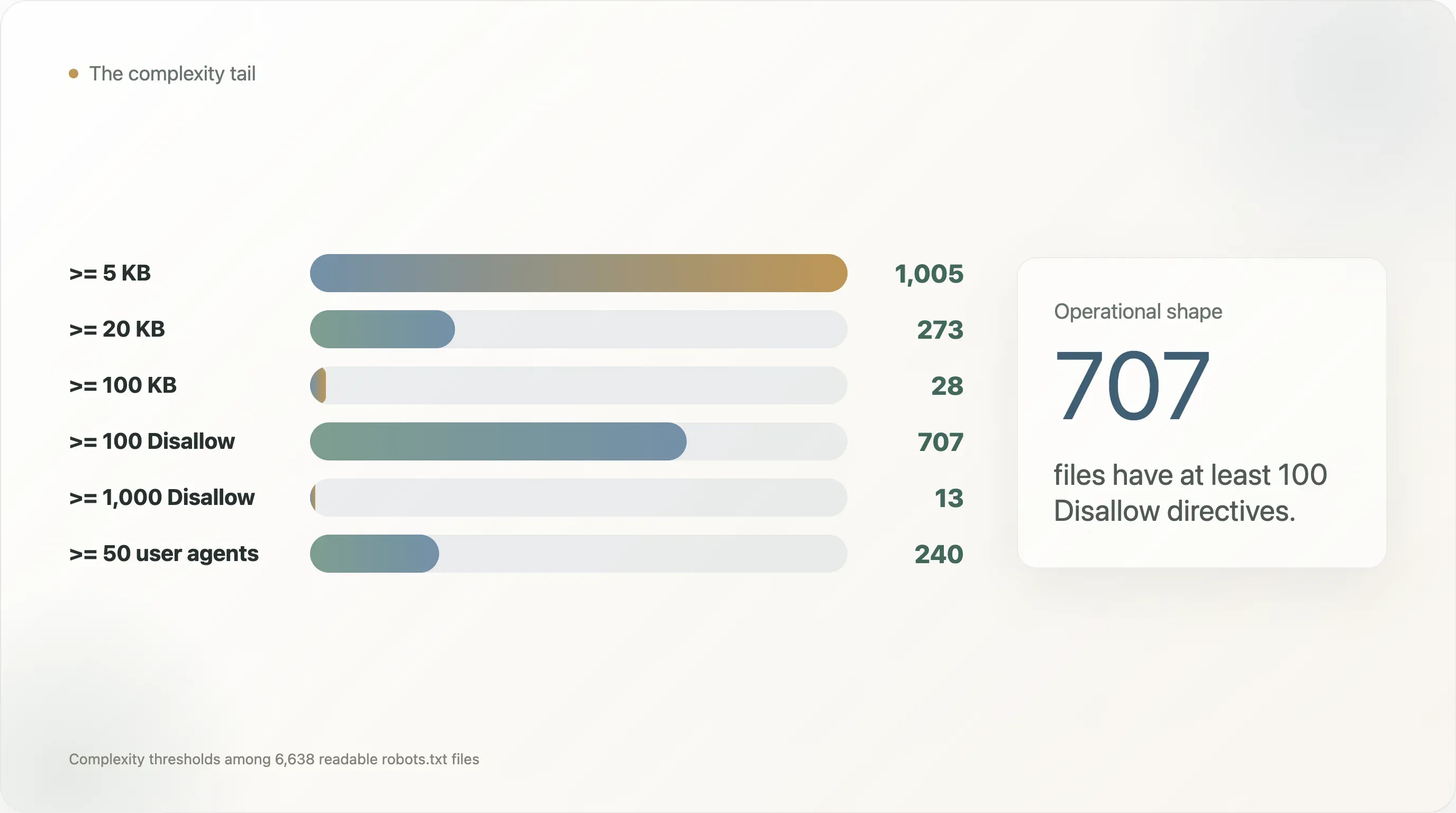
| Seuil de complexité | Sites |
|---|---|
robots.txt supérieur ou égal à 5 Ko | 1 005 |
| Supérieur ou égal à 20 Ko | 273 |
| Supérieur ou égal à 100 Ko | 28 |
Au moins 50 directives User-agent | 240 |
Au moins 100 directives User-agent | 110 |
Au moins 100 directives Disallow | 707 |
Au moins 1 000 directives Disallow | 13 |
Au moins 100 directives Allow | 40 |
Les fichiers les plus volumineux et les plus complexes ne sont pas des curiosités académiques. Ils appartiennent à de vrais services à fort trafic :
| Domaine | Rang | Catégorie | Octets | User-agent | Disallow | Allow |
|---|---|---|---|---|---|---|
linkedin.com | 17 | social | 114 341 | 76 | 4 184 | 281 |
runescape.com | 5 226 | unknown | 113 393 | 1 | 4 997 | 0 |
academia.edu | 832 | academia | 57 384 | 63 | 2 044 | 227 |
etsy.com | 286 | ecommerce | 51 320 | 3 | 1 621 | 120 |
thepaper.cn | 9 395 | news | 56 867 | 1 | 1 496 | 0 |
opentable.com | 4 137 | unknown | 70 494 | 32 | 1 683 | 176 |
alfabank.ru | 2 625 | finance | 73 158 | 2 | 1 566 | 133 |
Ces fichiers ressemblent davantage à des tables de routage de production qu’à des slogans de politique. Ils encodent des années de lancements de produits, de chemins hérités, de motifs de paramètres bloqués, d’exceptions de crawl, d’expérimentations SEO, de décisions CDN et, désormais, de règles pour les crawlers IA.
La queue n’est pas seulement une histoire d’IA. Parmi les 273 fichiers d’au moins 20 Ko, 131 contiennent un langage de politique IA et 142 non. Parmi les 707 fichiers comptant au moins 100 directives Disallow, seuls 207 contiennent un langage de politique IA. Autrement dit, l’IA n’a pas créé le problème des gros fichiers. Elle est arrivée après des années d’exploitation web ordinaire qui avaient déjà rempli le fichier de règles de chemin, de références de sitemap et d’exceptions de crawl.
Cela compte, car la maintenabilité dépend de la forme, pas seulement de l’intention. Un petit fichier avec un blocage IA direct peut être facile à auditer. Un fichier e-commerce ou de voyage de 70 Ko peut être difficile à auditer même s’il ne dit rien sur l’IA. Le risque n’est pas que tout gros fichier soit faux. Le risque est que la politique effective devienne trop difficile à vérifier pour les personnes responsables.
Le risque opérationnel est simple : à mesure que robots.txt grandit, il devient plus difficile pour un éditeur, un ingénieur plateforme, un juriste ou un responsable SEO de répondre à la question de base : que permet réellement ce fichier ?
Cette question n’a plus rien d’évident. Selon un parsing de type RFC, un crawler peut faire correspondre un groupe de user-agent plus spécifique au lieu de User-agent: * ; des correspondances de chemin plus longues peuvent l’emporter sur les plus courtes ; les directives Allow et Disallow interagissent selon une logique de priorité ; et des règles génériques de refus total peuvent capturer par accident de nouveaux crawlers qui n’existaient pas lorsque le fichier a été écrit.
Pour un fichier de 30 lignes, un humain peut encore raisonner là-dessus. Pour un fichier de 4 000 lignes avec des dizaines de bots nommés, personne ne le devrait.
Enseignement 2 : robots.txt porte bien plus que des règles de crawl
Le débat sur les crawlers IA a rendu robots.txt visible politiquement, mais le fichier sous-jacent accumulait déjà des responsabilités sans rapport entre elles.
Un robots.txt moderne d’un grand site peut inclure :
- des contrôles de chemin pour les crawlers ;
- la découverte des sitemaps ;
- des extensions spécifiques aux moteurs de recherche ;
- des indices de cadence de crawl ;
- des indices de canonicalisation de l’hôte ;
- des indices de nettoyage des paramètres d’URL ;
- du vocabulaire de politique injecté par le CDN ;
- du texte de réserve de copyright ;
- des refus d’entraînement IA ;
- des commentaires juridiques lisibles par des humains.
Le jeu de données montre clairement cette superposition.
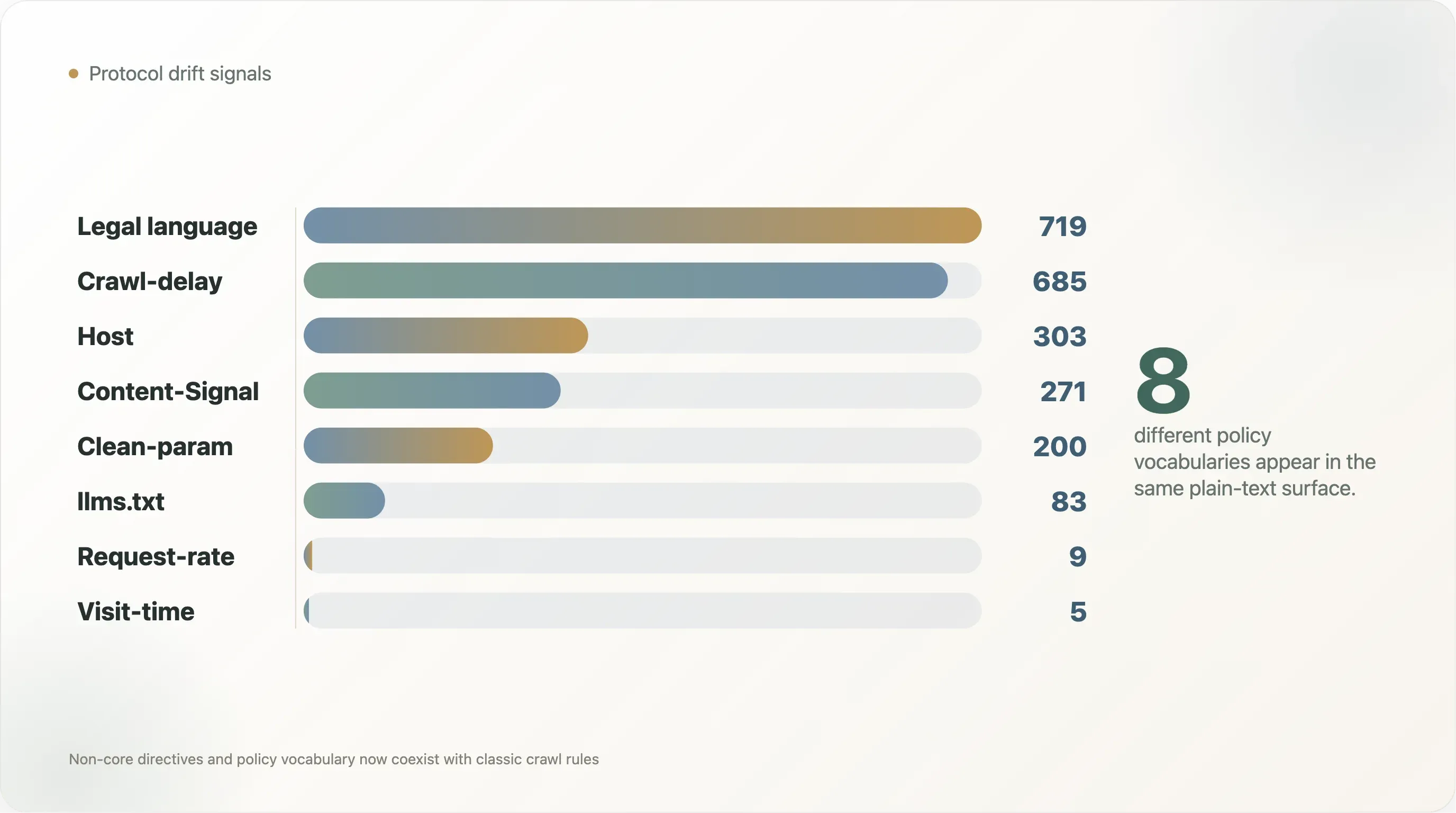
| Signal | Fichiers | Part des fichiers lisibles |
|---|---|---|
Crawl-delay | 685 | 10,3 % |
Host | 303 | 4,6 % |
Clean-param | 200 | 3,0 % |
Content-Signal | 271 | 4,1 % |
Request-rate | 9 | 0,1 % |
Visit-time | 5 | 0,1 % |
Mention de llms.txt | 83 | 1,3 % |
| Langage sur le copyright, les conditions, la licence ou l’autorisation | 719 | 10,8 % |
| Langage de politique IA | 1 377 | 20,7 % |
Certaines de ces directives sont bien reconnues par des crawlers spécifiques. D’autres sont des conventions héritées. D’autres sont propres à un fournisseur. D’autres encore ne sont pas vraiment des directives de crawl, mais du langage juridique ou produit inséré dans des commentaires.
C’est cela, la dérive du protocole.
Crawl-delay est un bon exemple. Beaucoup d’opérateurs de sites le connaissent, mais sa prise en charge est inégale selon les crawlers majeurs. Host et Clean-param ont historiquement été associés au comportement de Yandex. Content-Signal fait partie du vocabulaire de politique de l’ère IA chez Cloudflare. llms.txt est un format de découverte adjacent proposé, pas une norme universellement respectée. Pourtant, tout cela apparaît dans le même type de fichier, souvent à côté des règles classiques User-agent et Disallow.
Les chiffres montrent aussi comment les anciennes et nouvelles conventions coexistent désormais. Crawl-delay apparaît dans 685 fichiers, soit plus du double des 271 fichiers contenant Content-Signal. Host apparaît dans 303 fichiers et Clean-param dans 200, reflétant surtout les conventions de l’ère des moteurs de recherche. llms.txt, malgré de nombreux débats dans les cercles de recherche IA, n’est mentionné que dans 83 fichiers lisibles. Le Web réel ne converge pas vers un seul vocabulaire. Il empile les vocabulaires.
Le problème n’est pas qu’une extension particulière soit fausse. Le problème est que le fichier est devenu un conteneur sans version pour plusieurs systèmes de gouvernance qui se chevauchent.
Cela crée trois formes de dette :
- Dette sémantique. Différents crawlers peuvent interpréter le même fichier différemment.
- Dette de responsabilité. Les équipes SEO, juridique, infrastructure, sécurité et produit peuvent toutes avoir des raisons de modifier le fichier, mais aucune n’en possède nécessairement l’ensemble de la politique.
- Dette d’audit. Un site peut publier une politique qui paraît intentionnelle alors que seul un parseur peut déterminer son comportement effectif.
L’IA rend cela plus important parce que les enjeux ont changé. Quand un indice de cadence de crawl hérité est ignoré, le résultat peut être du trafic supplémentaire. Quand un refus d’entraînement IA est ambigu, le résultat peut devenir une preuve dans un litige sur le copyright ou la licence.
Enseignement 3 : le fichier est devenu à la fois interface machine et artefact juridique
Le rapport original sur les crawlers IA montrait que 17,0 % des sites analysables avaient rédigé des règles explicites propres à l’IA. Cette suite examine la charge textuelle ajoutée par ces politiques.
Parmi les 6 638 fichiers robots.txt lisibles :
- 1 377 contiennent un langage de politique IA ;
- 719 contiennent du vocabulaire sur le copyright, les conditions d’utilisation, la licence, les droits ou l’autorisation ;
- 271 contiennent
Content-Signal; - 83 mentionnent
llms.txt.
Le chevauchement est là où l’histoire devient plus intéressante :
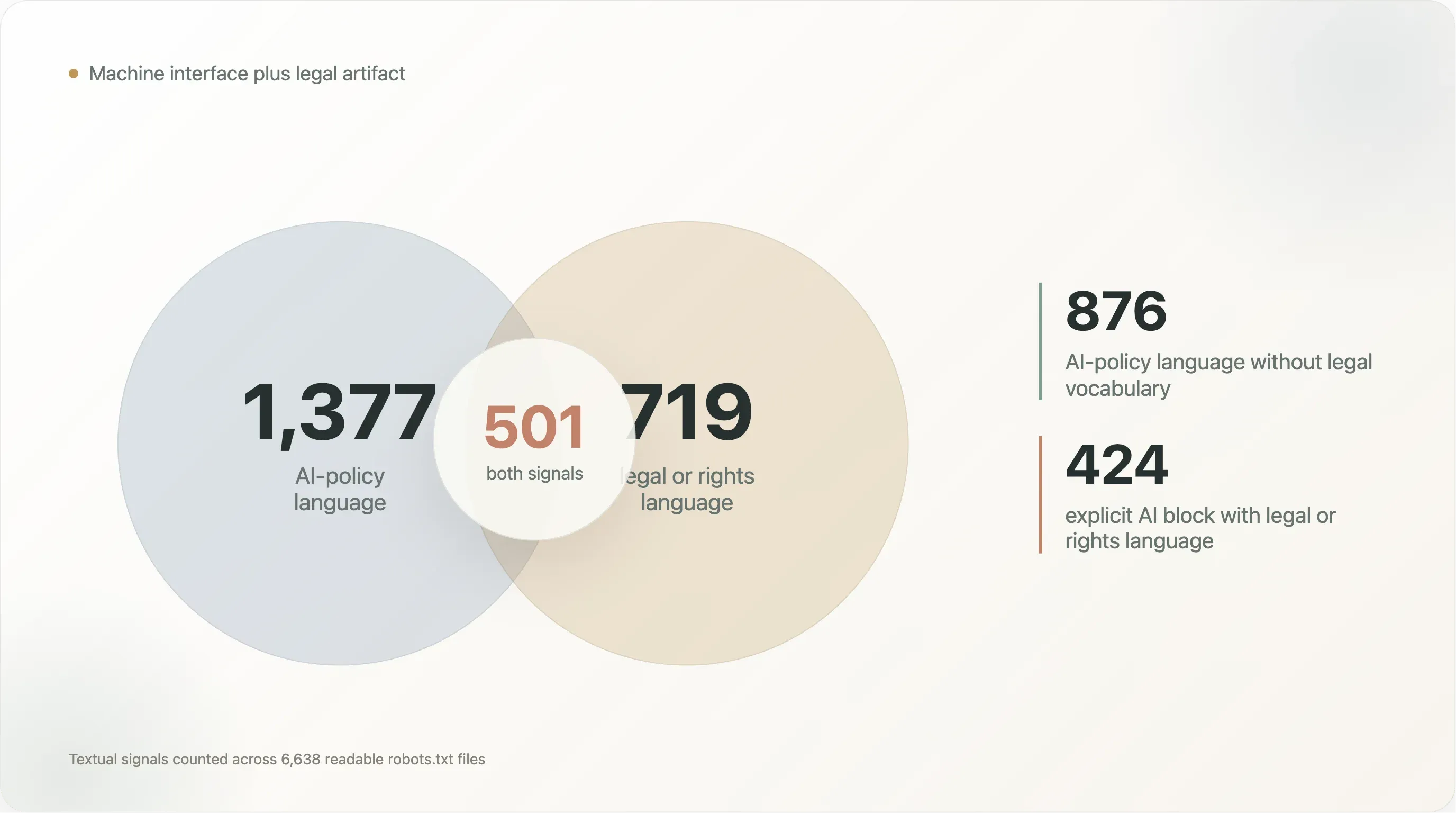
| Motif textuel | Fichiers |
|---|---|
| Langage de politique IA et langage juridique/de droits | 501 |
| Langage de politique IA sans langage juridique/de droits | 876 |
| Langage juridique/de droits sans langage de politique IA | 218 |
Content-Signal avec langage juridique/de droits | 242 |
| Blocage IA explicite avec langage juridique/de droits | 424 |
C’est un nouveau type de fichier.
Un fichier robots.txt traditionnel s’adresse aux crawlers. Un fichier robots.txt avec préambule juridique s’adresse à au moins quatre publics à la fois :
- les opérateurs de crawlers, qui ont besoin d’instructions lisibles par machine ;
- les fournisseurs de recherche et d’IA, qui ont besoin de signaux de politique ;
- les juristes, qui veulent une réserve explicite de droits ;
- les futurs auditeurs, tribunaux ou journalistes, qui peuvent lire les commentaires comme preuve d’intention.
Cette conception multi-public explique pourquoi certains fichiers ressemblent désormais à des documents de politique. Mais elle affaiblit aussi la séparation nette entre ce qu’un crawler peut parser et ce qu’un juriste humain veut déclarer.
Les 876 fichiers avec langage de politique IA mais sans vocabulaire juridique sont surtout des fichiers de politique machine : noms de bots, blocs Disallow et langage de modèle. Les 501 fichiers qui combinent langage IA et langage juridique sont différents. Ils essaient d’être à la fois des instructions pour les crawlers et des réserves de droits. Les 218 fichiers contenant un langage juridique sans vocabulaire IA montrent que ce schéma ne commence pas avec les LLMs ; robots.txt servait déjà à énoncer des conditions, des limites d’autorisation et des revendications de droits.
Par exemple, un commentaire peut dire que l’apprentissage automatique est interdit, alors que le bloc de directives réel ne fait qu’interdire un sous-ensemble de user-agents connus. Un site peut affirmer des droits de manière globale mais ne nommer que quelques crawlers. Un modèle de CDN peut injecter du vocabulaire lié à l’IA dans un fichier dont l’opérateur n’a jamais rédigé manuellement le langage juridique. Un site peut écrire une règle large User-agent: * qui bloque involontairement de futurs crawlers.
Du point de vue de la gouvernance, robots.txt est devenu attractif précisément parce qu’il est public et lisible par machine. Mais plus il porte de politique, plus ses limites comptent :
- il n’existe pas de couche d’authentification prouvant qu’une politique donnée a été revue par le détenteur des droits plutôt qu’héritée de l’infrastructure ;
- il n’existe pas d’historique natif des versions ;
- il n’existe pas de champ structuré pour l’usage prévu, comme l’entraînement, la recherche, l’indexation, le résumé, la mise en cache ou l’évaluation de modèles ;
- il n’existe pas de registre universel des identités de crawlers IA ;
- il n’existe aucun mécanisme d’exécution.
Cela ne rend pas le fichier inutile. Cela le rend fragile.
La meilleure lecture est que robots.txt devient une couche de notification : une déclaration publique et vérifiable de préférence et d’intention. Ce n’est pas, à lui seul, un système complet de gestion des droits.
Enseignement 4 : la recherche était déjà inégale avant l’arrivée de l’IA
L’un des constats les plus forts du rapport original était que de nombreux éditeurs distinguent les crawlers d’entraînement IA des crawlers de recherche. Ils bloquent CCBot, GPTBot ou Google-Extended tout en préservant la visibilité dans Google Search.
Cette suite ajoute un autre point : les crawlers de recherche traditionnels ne sont pas traités de manière égale non plus.
Nous avons examiné six crawlers de recherche :
- Googlebot ;
- Bingbot ;
- DuckDuckBot ;
- Slurp ;
- Baiduspider ;
- YandexBot.
Parmi les 7 248 sites analysables :
| Traitement des crawlers de recherche | Sites |
|---|---|
| Bloque au moins un crawler de recherche | 562 |
| Autorise Googlebot mais bloque au moins un autre crawler de recherche | 404 |
| Bloque les six crawlers de recherche vérifiés | 152 |
Les nombres de bots bloqués ne sont pas répartis de manière uniforme :
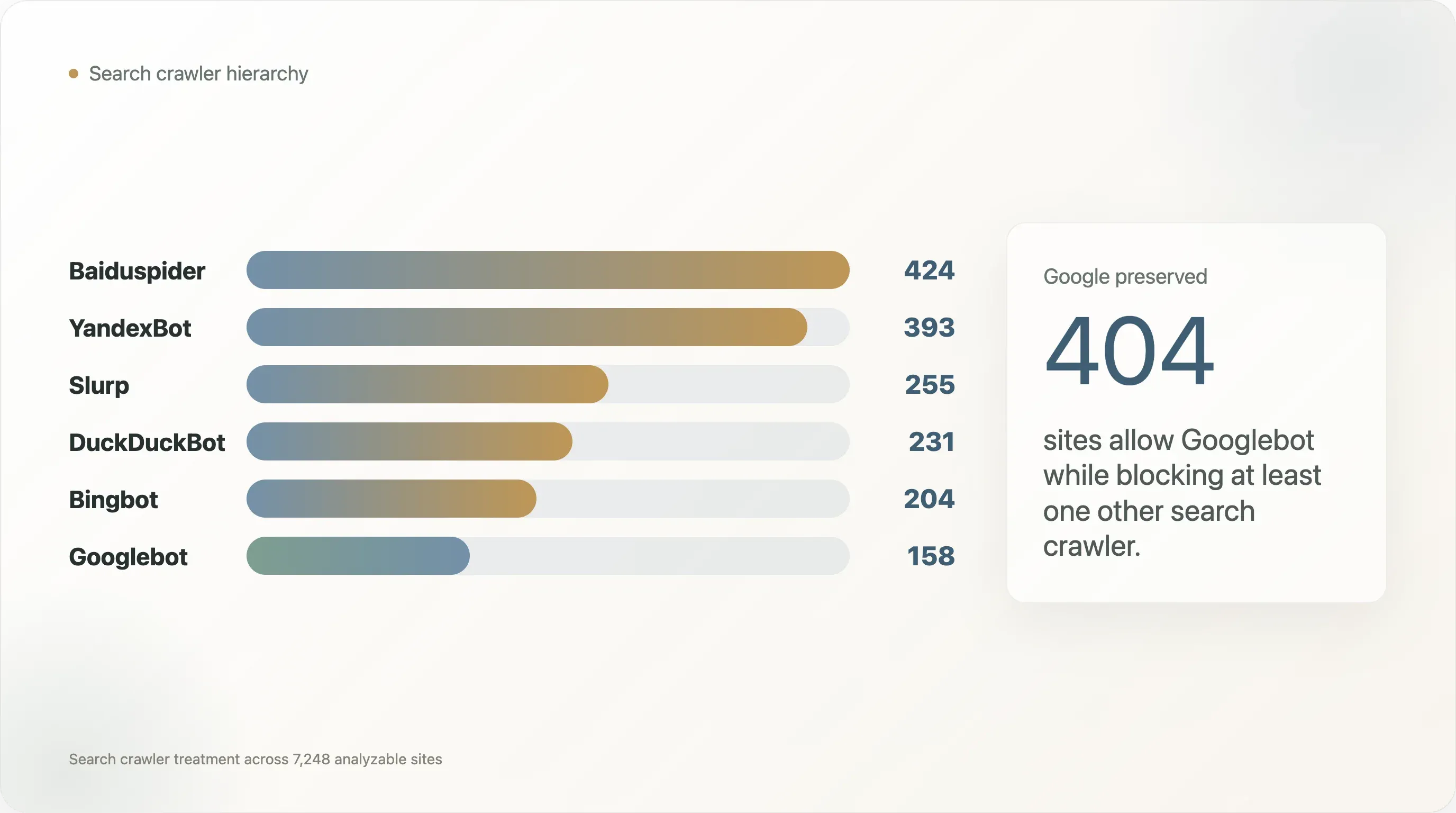
| Crawler de recherche | Sites qui le bloquent |
|---|---|
| Baiduspider | 424 |
| YandexBot | 393 |
| Slurp | 255 |
| DuckDuckBot | 231 |
| Bingbot | 204 |
| Googlebot | 158 |
Googlebot est le crawler le moins bloqué de cet ensemble. Baiduspider et YandexBot sont beaucoup plus souvent bloqués, et dans la plupart de ces cas Googlebot reste autorisé. Parmi les 404 sites qui autorisent Googlebot tout en bloquant un autre crawler de recherche, 269 bloquent Baiduspider et 240 bloquent YandexBot.
Les exemples sont très connus :
| Domaine | Crawlers de recherche bloqués alors que Googlebot est autorisé |
|---|---|
facebook.com | Baiduspider, YandexBot |
apple.com | Baiduspider |
twitter.com | DuckDuckBot, Slurp, Baiduspider, YandexBot |
netflix.com | DuckDuckBot, Slurp |
x.com | DuckDuckBot, Slurp, Baiduspider, YandexBot |
tiktok.com | Baiduspider |
baidu.com | Bingbot, DuckDuckBot, Slurp, YandexBot |
washingtonpost.com | YandexBot |
wsj.com | YandexBot |
bilibili.com | DuckDuckBot, Slurp, YandexBot |
temu.com | Slurp |
t-mobile.com | Baiduspider, YandexBot |
Cela importe pour le débat sur l’IA, car cela montre que robots.txt n’était déjà pas un protocole neutre d’accès universel avant l’arrivée des crawlers LLM. Le Web public avait déjà une hiérarchie :
- Googlebot est souvent préservé, car le trafic de recherche Google est trop précieux pour être risqué.
- Les crawlers régionaux ou concurrents sont plus faciles à bloquer.
- Certains sites traitent l’accès des crawlers de recherche comme une décision marché par marché ou fournisseur par fournisseur.
Les crawlers IA sont entrés dans un écosystème où l’accès différencié était déjà la norme.
Cela rend la transition de politique plus facile à comprendre. Un éditeur qui écrit « bloquer Google-Extended, autoriser Googlebot » n’invente pas une nouvelle forme de discrimination. Il applique un ancien schéma à une nouvelle classe de crawler : préserver la distribution, restreindre l’extraction.
La question ouverte est de savoir si ce vieux schéma passe à l’échelle. Avec la recherche, il n’y avait qu’une poignée de crawlers économiquement importants. Avec l’IA, l’identité des crawlers se fragmente entre fournisseurs de modèles, bots de récupération, courtiers de données, crawlers académiques, agents de navigation synthétiques et fetchers au niveau de l’infrastructure. Le nombre de user-agents nommés continuera d’augmenter à moins que l’écosystème ne se rassemble autour d’un plus petit ensemble de signaux fondés sur l’usage.
C’est ainsi que la dette de configuration s’accumule.
Enseignement 5 : la complexité varie selon les secteurs, mais pas comme les taux de blocage de l’IA
Le rapport original montrait un large écart sectoriel dans le blocage de l’IA : l’actualité bloque à des taux élevés ; les télécoms, les administrations et les SaaS bloquent à des taux faibles.
La complexité de configuration découpe le Web autrement.
Parmi les catégories sélectionnées ayant suffisamment de fichiers robots.txt lisibles pour une comparaison utile :
| Catégorie | n | Octets médians | Octets P90 | Disallow médian | Disallow P90 | User-agent médian | User-agent P90 |
|---|---|---|---|---|---|---|---|
| ecommerce | 215 | 1 738 | 10 388 | 37 | 164 | 3 | 49 |
| travel | 63 | 2 074 | 27 368 | 41 | 779 | 5 | 34 |
| news | 647 | 1 534 | 7 039 | 19 | 114 | 6 | 68 |
| finance | 121 | 1 002 | 8 337 | 17 | 132 | 2 | 23 |
| academia | 253 | 839 | 3 959 | 14 | 75 | 1 | 11 |
| government | 151 | 1 227 | 3 263 | 13 | 46 | 1 | 4 |
| SaaS | 368 | 485 | 12 606 | 4 | 56 | 1 | 10 |
| dev tools | 119 | 273 | 9 255 | 3 | 58 | 1 | 10 |
P90 Disallow by category chart here<<<<<<<<<<<<<<<<<<<<<<<<<
L’actualité est politiquement complexe parce qu’elle écrit des règles IA explicites et du texte juridique. Mais le e-commerce et le voyage sont opérationnellement complexes parce qu’ils ont de grands catalogues, une navigation à facettes, des pages de résultats de recherche, des filtres, des parcours de compte utilisateur et des URL paramétrées.
Cette distinction est importante.
Le voyage en est l’exemple le plus clair. Cette sous-catégorie ne compte que 63 fichiers lisibles, mais son robots.txt P90 atteint 27,4 Ko et son nombre P90 de Disallow est de 779, bien au-dessus de l’actualité. Cela ne veut pas dire que les sites de voyage ont une politique IA plus avancée. Cela signifie qu’ils ont davantage de surfaces sur lesquelles les opérateurs de crawlers peuvent gaspiller du budget par accident : recherches par date, pages de disponibilité, pagination des avis, parcours de réservation, combinaisons de filtres et chemins d’inventaire localisés.
Le SaaS est l’autre surprise. Son fichier médian ne fait que 485 octets, mais le fichier P90 grimpe à 12,6 Ko. La plupart des sites SaaS sont ouverts et légers ; un plus petit ensemble porte de longs fichiers de contrôle de chemin, souvent parce que la documentation, les pages de connexion, les routes d’application et les pages marketing cohabitent sous le même domaine.
L’actualité se situe au milieu sur le plan opérationnel mais presque au sommet sur le plan politique. Son nombre P90 de User-agent est de 68, supérieur à celui du e-commerce, du voyage, de la finance, du monde académique, des administrations, du SaaS et des dev tools dans ce tableau. C’est un signe de politique spécifique aux bots, pas seulement d’hygiène des chemins.
Le robots.txt d’un éditeur peut être complexe à cause de la politique de droits. Celui d’une place de marché peut l’être à cause de la gestion du budget de crawl. Celui d’une université peut l’être parce que des milliers de chemins hérités se sont accumulés sous un seul domaine. Celui d’une plateforme sociale peut l’être parce qu’elle doit exposer certaines surfaces tout en en supprimant d’autres à grande échelle.
La politique IA se superpose à tout cela. Elle ne remplace pas les raisons existantes pour lesquelles un fichier est complexe.
Cela aide à expliquer pourquoi la gouvernance du robots.txt à l’ère de l’IA ne peut pas être résolue par une liste de blocage universelle. Les fichiers sous-jacents ont des rôles différents :
- les sites e-commerce gèrent des chemins dupliqués et des surfaces d’inventaire ;
- les sites de voyage gèrent des annonces, des calendriers, des avis et des pages de recherche dynamiques ;
- les sites d’actualité gèrent le copyright, les archives et la posture de licence ;
- les sites SaaS et d’outillage pour développeurs veulent souvent de la visibilité IA ;
- les administrations ont souvent besoin d’un accès public, mais peuvent malgré tout avoir des systèmes sensibles à exclure ;
- les plateformes sociales gèrent du contenu généré par les utilisateurs, des surfaces de profil et des préoccupations anti-abus.
La même règle de crawler IA ne signifie pas la même chose dans chaque environnement.
Enseignement 6 : un indice de dette de configuration identifie le risque de revue, pas une faute morale
Cette analyse a créé un simple score de dette de configuration pour identifier les fichiers robots.txt susceptibles d’être difficiles à examiner.
Le score pondère :
- la taille du fichier ;
- le nombre de directives
User-agent; - le nombre de directives
Disallow; - le nombre de directives
Allow; - le nombre de directives non essentielles ;
- la présence d’un langage de politique IA ;
- le mélange de blocage IA explicite et de langage juridique ou de copyright.
Ce n’est pas un score de conformité. Un fichier très complexe peut être tout à fait intentionnel. Un fichier simple peut malgré tout être erroné. Le but est le triage : si un fichier est volumineux, chargé en politique, spécifique aux bots et rempli d’exceptions, il mérite une discipline de revue plus forte.
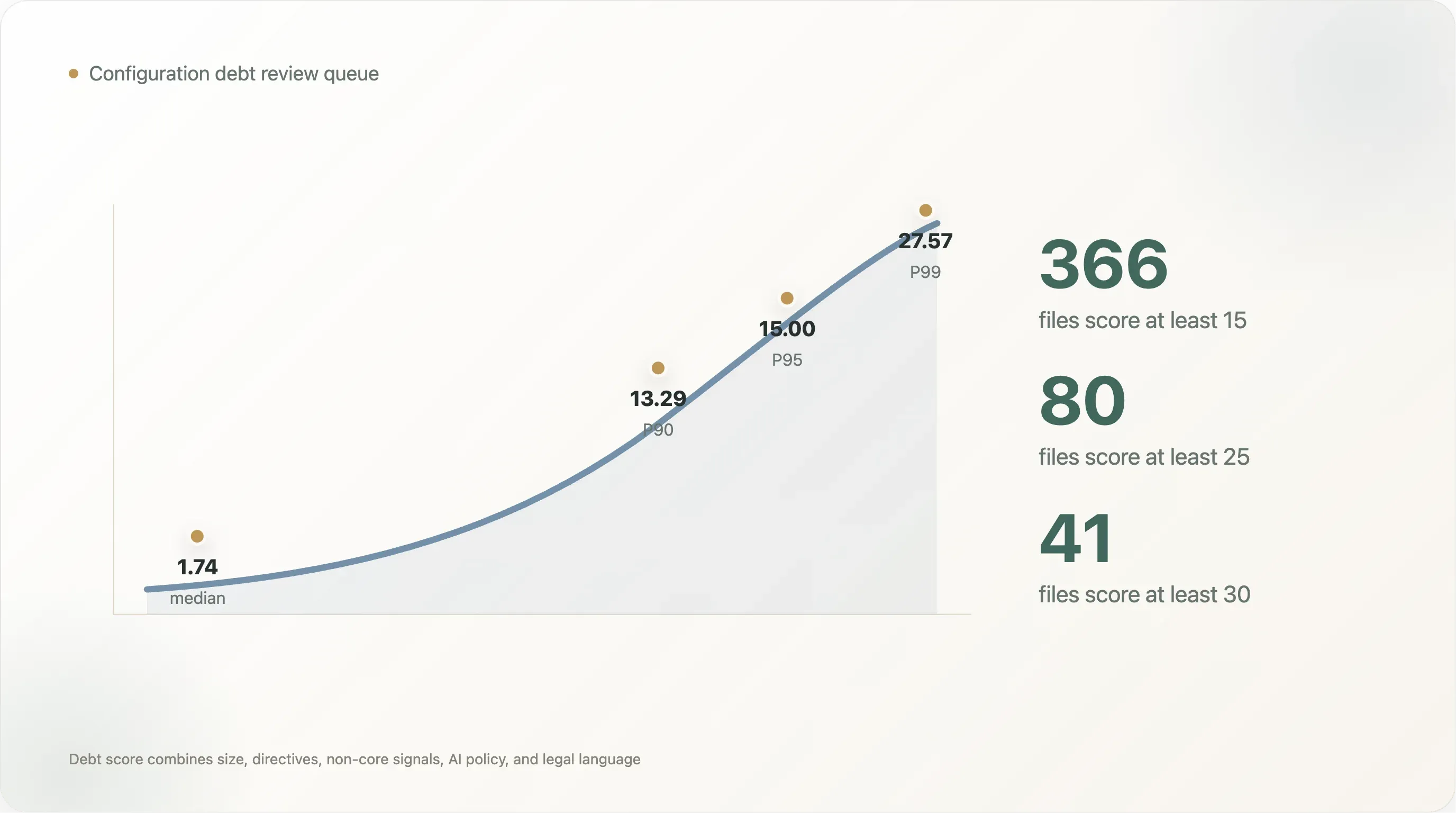
La distribution du score est abrupte. Le fichier lisible médian obtient 1,74. Le score P90 est de 13,29, le P95 de 15,00 et le P99 de 27,57. Seuls 366 fichiers obtiennent au moins 15, 80 au moins 25 et 41 au moins 30. C’est la file de revue pratique : tous les sites n’ont pas besoin d’un projet de gouvernance, mais la queue supérieure, si.
La vue par catégorie montre aussi pourquoi une simple étiquette « bloqueur d’IA » est trop plate :
| Catégorie | Score médian | Score P90 |
|---|---|---|
| travel | 4,92 | 28,94 |
| search | 2,97 | 24,23 |
| social | 2,25 | 15,00 |
| news | 4,91 | 14,92 |
| finance | 1,67 | 12,61 |
| SaaS | 0,98 | 11,85 |
| ecommerce | 3,88 | 10,87 |
| government | 1,57 | 6,38 |
Le voyage et la recherche ont les scores P90 les plus élevés parce qu’une minorité de fichiers deviennent très volumineux et très chargés en règles. L’actualité a l’un des scores médians les plus élevés parce que le langage de politique et le traitement spécifique aux bots y sont plus fréquents dans l’ensemble de la catégorie. Le e-commerce a un nombre médian de Disallow élevé, mais son score de dette P90 est inférieur à celui du voyage, car la complexité y est davantage concentrée dans les règles de chemin que dans les signaux politiques et juridiques mélangés.
Les fichiers les plus élevés dans ce jeu de données incluent :
| Domaine | Pourquoi son score est élevé |
|---|---|
linkedin.com | Fichier très volumineux, milliers de règles de chemin, nombreux user-agents nommés, langage explicite de politique IA |
lnkd.in | Même surface de politique que l’infrastructure de raccourcissement de liens de LinkedIn |
fragrantica.com | Des centaines de blocs de user-agents nommés plus un langage de politique IA |
sovcombank.ru | Des centaines de blocs de user-agents et un langage juridique/de politique |
academia.edu | Grande matrice allow/disallow et politique explicite de blocage IA |
opentable.com | Grand ensemble de règles de chemin, nombreuses directives sitemap, surface de politique liée à l’IA |
etsy.com | Grand fichier de contrôle de chemins e-commerce avec plus de 1 600 règles Disallow |
runescape.com | Presque 5 000 directives Disallow sous un seul groupe de user-agent |
Il ne faut pas se moquer de ces fichiers parce qu’ils sont complexes. La complexité reflète souvent des besoins métiers réels. Mais ils montrent aussi pourquoi la politique robots.txt mérite la même rigueur d’ingénierie que les autres configurations de production :
- la responsabilité doit être explicite ;
- les changements doivent être revus ;
- les sections générées doivent être signalées ;
- les commentaires juridiques doivent, si possible, être séparés des directives machine ;
- des cas de test doivent vérifier l’accès attendu des crawlers critiques ;
- l’historique des versions doit être conservé ;
- les anciens noms de bots doivent être retirés ou documentés ;
- l’entraînement IA, la récupération IA, l’indexation de recherche et l’archivage doivent être traités comme des finalités distinctes.
Le dernier point est le plus important. La grammaire actuelle est d’abord centrée sur le user-agent : elle demande aux opérateurs de site de nommer les bots. Le besoin à l’ère de l’IA est centré sur la finalité : il demande aux opérateurs de site de dire quels usages sont autorisés.
Ce n’est pas la même chose.
Ce décalage explique pourquoi les listes de blocage toujours plus longues vieilliront mal. Un éditeur peut ajouter aujourd’hui GPTBot, ClaudeBot, CCBot, Google-Extended, Bytespider, Applebot-Extended et PerplexityBot, mais le prochain nom de crawler, d’agent de récupération ou de courtier de jeux de données peut apparaître demain. Une politique fondée sur la finalité permettrait au site de dire « indexation de recherche oui, entraînement IA non, récupération déclenchée par l’utilisateur peut-être » sans transformer robots.txt en carnet d’adresses de bots.
Ce que cela signifie pour la gouvernance de l’IA
Le débat public présente souvent robots.txt comme soit pertinent, soit obsolète. Les données suggèrent une réponse plus pratique :
robots.txt est pertinent, mais surchargé.
Il est pertinent parce que les grands sites l’utilisent, que les crawlers peuvent le parser et que les choix de politique sont visibles pour les chercheurs, journalistes, fournisseurs et tribunaux. Le rapport original a montré que 17,0 % des grands sites analysables avaient des règles IA délibérées et spécifiques. Ce n’est pas du bruit symbolique.
Il est surchargé parce que le fichier doit désormais exprimer bien plus que l’accès des bots :
- « Ne vous entraînez pas sur ce contenu. »
- « Vous pouvez utiliser ce contenu pour l’indexation de recherche. »
- « Vous pouvez utiliser ce contenu pour une récupération en temps réel. »
- « Vous ne pouvez pas créer de jeux de données mis en cache. »
- « Cette réserve juridique s’applique au titre du droit européen sur le text and data mining. »
- « Ce site géré par un CDN envoie
Content-Signal: ai-train=no. » - « Ce site veut Googlebot mais pas YandexBot. »
- « Ce site possède 1 000 chemins URL hérités qui ne devraient pas être explorés. »
La grammaire n’a pas été conçue pour autant de rôles.
Trois changements réduiraient cette dette :
-
L’identité des crawlers a besoin d’un registre. Les opérateurs de site ne devraient pas avoir à maintenir une liste sans cesse croissante de
GPTBot,ClaudeBot,anthropic-ai,CCBot,Google-Extended,Applebot-Extended,Bytespider,OAI-SearchBot,ChatGPT-Useret bien d’autres. Sans registre, la politique sera toujours en retard sur le comportement des crawlers. -
L’usage de l’IA a besoin d’un vocabulaire structuré. L’entraînement, la récupération, l’indexation, le résumé, la revente de jeux de données, l’évaluation de modèles et la navigation déclenchée par l’utilisateur sont des usages différents. Les exprimer via des noms de user-agents propres à chaque fournisseur est fragile.
-
La politique doit être auditable. Le Web a besoin d’un moyen de distinguer les réserves de droits rédigées manuellement des valeurs par défaut héritées du CDN, des modèles CMS générés, des règles héritées obsolètes et des blocages globaux accidentels. La distinction compte pour la confiance et pour le contentieux.
Rien de cela ne signifie qu’il faut remplacer robots.txt du jour au lendemain. La meilleure voie est le layering : conserver robots.txt comme surface de découverte et de compatibilité, tout en standardisant à côté une politique lisible par machine pour les usages spécifiques à l’IA.
llms.txt est une tentative en ce sens, mais son adoption dans ce jeu de données reste minuscule : seuls 83 fichiers lisibles le mentionnent. Content-Signal est plus visible parce que Cloudflare peut le distribuer via l’infrastructure, et les 271 fichiers Content-Signal de ce scan correspondaient tous aussi à un langage de politique IA. Néanmoins, la diffusion n’est pas synonyme de consensus. Une solution durable a probablement besoin de la mécanique, peu glamour mais essentielle, de la standardisation : des champs clairs, une sémantique claire, des engagements des crawlers et des suites de tests publiques.
Conclusion
La bataille autour des crawlers IA a transformé robots.txt en artefact de gouvernance. C’est à la fois utile et risqué.
Utile, parce que le fichier est public. Les chercheurs peuvent l’auditer. Les éditeurs peuvent le modifier. Les crawlers peuvent le respecter. Les tribunaux peuvent le lire. Les fournisseurs d’infrastructure peuvent le déployer à grande échelle.
Risqué, parce qu’il porte trop de choses.
Le fichier robots.txt médian dans le Tranco Top 10 000 est encore assez petit pour être compris. Mais la longue traîne du Web à fort trafic regorge de fichiers volumineux, anciens, superposés, spécifiques à un fournisseur et chargés juridiquement. Des centaines de sites maintiennent désormais des configurations robots.txt qu’on comprend mieux comme des systèmes de politique de production que comme de simples indices pour crawlers.
La leçon centrale n’est pas que robots.txt a échoué. C’est que le Web l’a promu sans le refactoriser.
Si la politique d’accès à l’IA doit reposer sur des déclarations publiques lisibles par machine, l’étape suivante n’est pas une liste de blocage encore plus longue. C’est une meilleure infrastructure de politique : des permissions fondées sur la finalité, une identité stable des crawlers, des modèles révisables et des journaux d’audit.
En attendant, la couche de gouvernance de l’IA du Web public continuera de reposer sur un fichier texte qui n’a jamais été conçu pour porter autant de poids.
Notes de reproductibilité
Le dossier de livraison comprend :
source_data/analysis.json— les métriques agrégées originales.source_data/site_meta.csv— le tableau analytique original par site.source_data/bot_status.csv— le tableau original de politique par domaine et bot.source_data/fetch_meta.csv— les métadonnées de récupération originales.source_data/sites.csv— le tableau original des domaines, catégories et statuts.derived_data/robots_complexity_by_site.csv— les métriques de complexité par site générées pour ce rapport.derived_data/search_bot_treatment.csv— la matrice de traitement des crawlers de recherche.derived_data/category_complexity_summary.csv— le résumé de complexité par catégorie.derived_data/top_config_debt_sites.csv— les sites les mieux classés selon le score de triage décrit ci-dessus.derived_data/summary_metrics.json— toutes les métriques principales citées dans ce rapport.
Les corrections de méthodologie, problèmes de jeu de données et analyses de suivi sont les bienvenus à support@thunderbit.com. Ce rapport est publié de manière indépendante de toute position commerciale que Thunderbit pourrait avoir ; nous construisons un extracteur Web alimenté par l’IA, et nous avons un intérêt structurel à ce que robots.txt reste un contrat lisible par machine et pertinent sur le Web public. Les données de ce rapport se suffisent à elles-mêmes. — L’équipe de recherche Thunderbit, mai 2026.