Internet regorge de données, et soyons clairs : personne n’a envie de passer des heures à copier-coller à la main des milliers de fiches produits ou d’annonces d’emploi. C’est pour ça que l’extraction de données web est devenue une compétence essentielle pour les pros de la vente, de l’opérationnel, de l’e-commerce et bien d’autres domaines. Avec sa syntaxe simple et ses bibliothèques ultra puissantes, Python s’est imposé comme le langage incontournable pour créer un extracteur web. D’ailleurs, plus de bossent aujourd’hui avec Python, loin devant les autres langages.
Mais il y a un hic : même si Python est super efficace pour le scraping, les débutants peuvent vite se sentir largués, et même les plus aguerris galèrent parfois avec les sites dynamiques, les protections anti-bots ou des données mal fichues. C’est pour ça que j’ai préparé ce guide étape par étape. On va partir de zéro, réaliser ensemble un exemple extracteur web Python, et voir comment combiner Python avec des outils boostés à l’IA comme pour extraire des données plus intelligemment, sans se prendre la tête. Que tu veuilles automatiser la génération de leads, surveiller les prix de la concurrence ou juste organiser des données web dans un tableur, tu trouveras ici des étapes concrètes (et quelques astuces de terrain).
Web Scraping Python 101 : Démarrage express
On commence par la base. L’extraction de données web (web scraping), c’est simplement automatiser la collecte d’infos sur des sites. Plutôt que de tout copier à la main, un extracteur visite la page, lit le code HTML et récupère ce qui t’intéresse : prix, contacts, avis, etc. Pour les pros, ça veut dire un accès direct à des données pour la prospection, la veille tarifaire ou l’analyse de marché ().
Étape 1 : Installer Python
Télécharge Python 3 depuis le . Sous Windows, lance l’installateur et coche « Ajouter Python au PATH ». Sur Mac, tu peux passer par avec brew install python, ou télécharger direct. Après l’installation, ouvre ton terminal (ou l’invite de commandes) et tape :
1python --versionou
1python3 --versionSi tu vois un truc du genre Python 3.11.0, c’est tout bon.
Étape 2 : Créer un environnement virtuel
Un environnement virtuel te permet d’isoler les dépendances de ton projet et d’éviter les embrouilles avec d’autres projets Python. Dans ton dossier projet, lance :
1# Sur macOS/Linux
2python3 -m venv .venv
3# Sur Windows
4py -m venv .venvActive-le avec :
- macOS/Linux :
source .venv/bin/activate - Windows :
.venv\Scripts\activate
Tous les paquets installés seront alors propres à ce projet ().
Étape 3 : Installer les bibliothèques indispensables
Il te faut quelques paquets clés :
- Requests : pour récupérer les pages web.
- BeautifulSoup (bs4) : pour analyser le HTML.
- Scrapy : pour des extractions plus costaudes et à grande échelle.
Installe-les avec :
1pip install requests beautifulsoup4 scrapy- Requests simplifie les requêtes HTTP.
- BeautifulSoup permet de cibler et d’extraire des données dans le HTML.
- Scrapy est un framework complet pour crawler plein de sites, gérer les erreurs et exporter les données.
Pour débuter, Requests + BeautifulSoup suffisent largement. Scrapy, c’est pour passer à la vitesse supérieure.
Étape 4 : Organiser ton projet
Range tes fichiers ! Crée un dossier pour ton projet, et mets-y tes scripts, fichiers de données et environnement virtuel. Tu te remercieras plus tard.
Exemple extracteur web Python : Script de base et structure du code
On va construire ensemble un extracteur simple. On va récupérer une page web, l’analyser et extraire des données. Voici un exemple minimal, commenté, qui extrait les paragraphes de :
1import requests
2from bs4 import BeautifulSoup
3URL = "https://example.com"
4response = requests.get(URL)
5response.raise_for_status() # Lève une erreur si le statut n’est pas 200 OK
6soup = BeautifulSoup(response.text, "html.parser")
7# Trouver toutes les balises paragraphe
8paragraphs = soup.find_all('p')
9for idx, p in enumerate(paragraphs, start=1):
10 print(f"Paragraphe {idx} : {p.get_text()}")Ce qui se passe ici :
- On importe les bibliothèques.
- On récupère la page avec
requests.get. - On analyse le HTML avec BeautifulSoup.
- On trouve toutes les balises
<p>et on affiche leur texte.
Pièges classiques :
- Oublier de vérifier
response.status_code(toujours s’assurer d’un statut 200 OK). - Essayer d’utiliser
.get_text()sur un objetNone(si l’élément n’existe pas). - Oublier d’activer l’environnement virtuel (tes imports peuvent planter).
Cette structure — import, récupération, analyse, extraction, affichage — c’est la base de la plupart des extracteurs Python.
Utiliser Python pour extraire des pages web : Étapes détaillées
On va détailler le process pour une vraie mission de scraping.
1. Inspecter le site web
Ouvre ton navigateur, fais un clic droit sur la donnée voulue et choisis « Inspecter ». Ça ouvre les outils développeur et te montre le HTML. Repère les balises, classes ou identifiants uniques qui ciblent tes données ().
2. Récupérer la page
Utilise Requests pour choper le HTML :
1headers = {"User-Agent": "Mozilla/5.0"}
2response = requests.get(URL, headers=headers)
3response.raise_for_status()Ajouter un User-Agent permet d’éviter certains blocages anti-bots.
3. Analyser le HTML
1soup = BeautifulSoup(response.text, "html.parser")4. Localiser et extraire les données
Imaginons que tu veux extraire des offres d’emploi, chacune dans un <div class="job-card"> :
1job_cards = soup.find_all('div', class_='job-card')
2for card in job_cards:
3 title = card.find('h2', class_='title').get_text(strip=True)
4 company = card.find('h3', class_='company').get_text(strip=True)
5 print(title, company)Tu peux utiliser .find(), .find_all() ou .select() avec des sélecteurs CSS pour des requêtes plus pointues.
5. Gérer plusieurs éléments (listes)
Parcours la liste des conteneurs (produits, offres, etc.) et extrait les champs nécessaires. Stocke-les dans une liste de dictionnaires pour faciliter l’export.
6. Dépannage
- Si tu obtiens des résultats vides, vérifie tes sélecteurs : la classe a peut-être changé ou le contenu est chargé en JavaScript.
- Affiche
response.text[:500]pour voir le HTML reçu.
Exemple extracteur web Python : Stockage et export des données
Une fois tes données extraites, il faut les sauvegarder. Voici les options les plus courantes :
Afficher dans la console
Pratique pour tester, mais pas pour des projets sérieux.
Écrire dans un fichier CSV
1import csv
2data = [
3 {"Name": "Alice", "Age": 25},
4 {"Name": "Bob", "Age": 30},
5]
6with open("output.csv", "w", newline="", encoding="utf-8") as f:
7 writer = csv.DictWriter(f, fieldnames=["Name", "Age"])
8 writer.writeheader()
9 writer.writerows(data)Exporter vers Excel
Si tu as installé pandas et openpyxl :
1import pandas as pd
2df = pd.DataFrame(data)
3df.to_excel("output.xlsx", index=False)Stocker dans une base de données
Pour des besoins simples, SQLite est intégré à Python :
1import sqlite3
2conn = sqlite3.connect("scraped_data.db")
3cursor = conn.cursor()
4cursor.execute("CREATE TABLE IF NOT EXISTS people (name TEXT, age INTEGER)")
5for row in data:
6 cursor.execute("INSERT INTO people VALUES (?, ?)", (row["Name"], row["Age"]))
7conn.commit()
8conn.close()Quand utiliser quoi ?
- CSV : Parfait pour les tableurs et le partage.
- Excel : Pour des rapports formatés, plusieurs feuilles.
- Base de données : Pour des projets volumineux ou récurrents.
Pense toujours à encoding="utf-8" pour éviter les soucis de caractères ().
Thunderbit et Python : Passe à la vitesse supérieure pour l’extraction
 Parlons maintenant de , l’extension Chrome d’extraction web boostée à l’IA qui change la donne pour les pros de la donnée.
Parlons maintenant de , l’extension Chrome d’extraction web boostée à l’IA qui change la donne pour les pros de la donnée.
Pourquoi Thunderbit sort du lot ?
- Suggestion de champs par IA : L’IA de Thunderbit analyse la page et propose direct les colonnes à extraire — plus besoin de fouiller dans le HTML ou d’écrire des sélecteurs.
- Workflow en point & clic : Ouvre l’extension, laisse l’IA suggérer les champs, clique sur « Extraire » et c’est plié.
- Extraction de sous-pages : Thunderbit peut aller tout seul sur les pages de détail (produits, profils, etc.) pour enrichir ton jeu de données.
- Export partout : Télécharge tes données en CSV, Excel, ou exporte-les direct vers Google Sheets, Notion ou Airtable ().
Comment Thunderbit complète Python ?
Imaginons que tu dois extraire des données d’un site e-commerce complexe, blindé de JavaScript et qui demande une connexion. Les scripts Python classiques peuvent galérer, mais Thunderbit — qui tourne dans ton navigateur — gère ça sans souci. Une fois les données extraites, exporte-les et utilise Python pour l’analyse, le reporting ou l’automatisation.
Exemple d’utilisation :
- Utilise Thunderbit pour extraire les fiches produits (images, prix, avis) d’un site dynamique.
- Exporte en CSV.
- Analyse les tendances, fusionne avec d’autres jeux de données ou automatise des alertes avec Python.
Cette combinaison te permet de relever tous les défis du scraping, peu importe ton niveau en code.
Assurer la fiabilité et la stabilité de ton extracteur web Python
L’extraction web, ce n’est pas juste récupérer des données, c’est surtout obtenir les bonnes données, de façon fiable. Voici comment rendre tes scripts solides :
1. Gérer les changements de site
Les sites changent souvent de structure HTML. Privilégie les identifiants uniques ou les classes stables plutôt que la position des balises.
2. Gérer les erreurs
Encadre tes requêtes et ton parsing avec des blocs try/except :
1import time
2for attempt in range(3):
3 try:
4 response = requests.get(url, timeout=10)
5 response.raise_for_status()
6 break
7 except Exception as e:
8 if attempt < 2:
9 time.sleep(5)
10 else:
11 print(f"Échec après 3 tentatives : {e}")3. Alterner User-Agent et utiliser des proxies
Beaucoup de sites bloquent les scripts détectés comme bots. Change régulièrement ton User-Agent et, pour de gros volumes, utilise des proxies pour éviter les blocages d’IP ().
4. Respecter robots.txt et l’éthique
Vérifie toujours le fichier robots.txt et les conditions d’utilisation du site. N’extrais que des données publiques, évite les infos perso et ne surcharge pas les serveurs ().
5. Journaliser et surveiller
Utilise le module logging de Python pour suivre les erreurs et les succès. Si ton extracteur tourne en automatique, mets en place des alertes en cas d’échec ou de résultats vides.
Comment l’IA de Thunderbit booste le web scraping Python
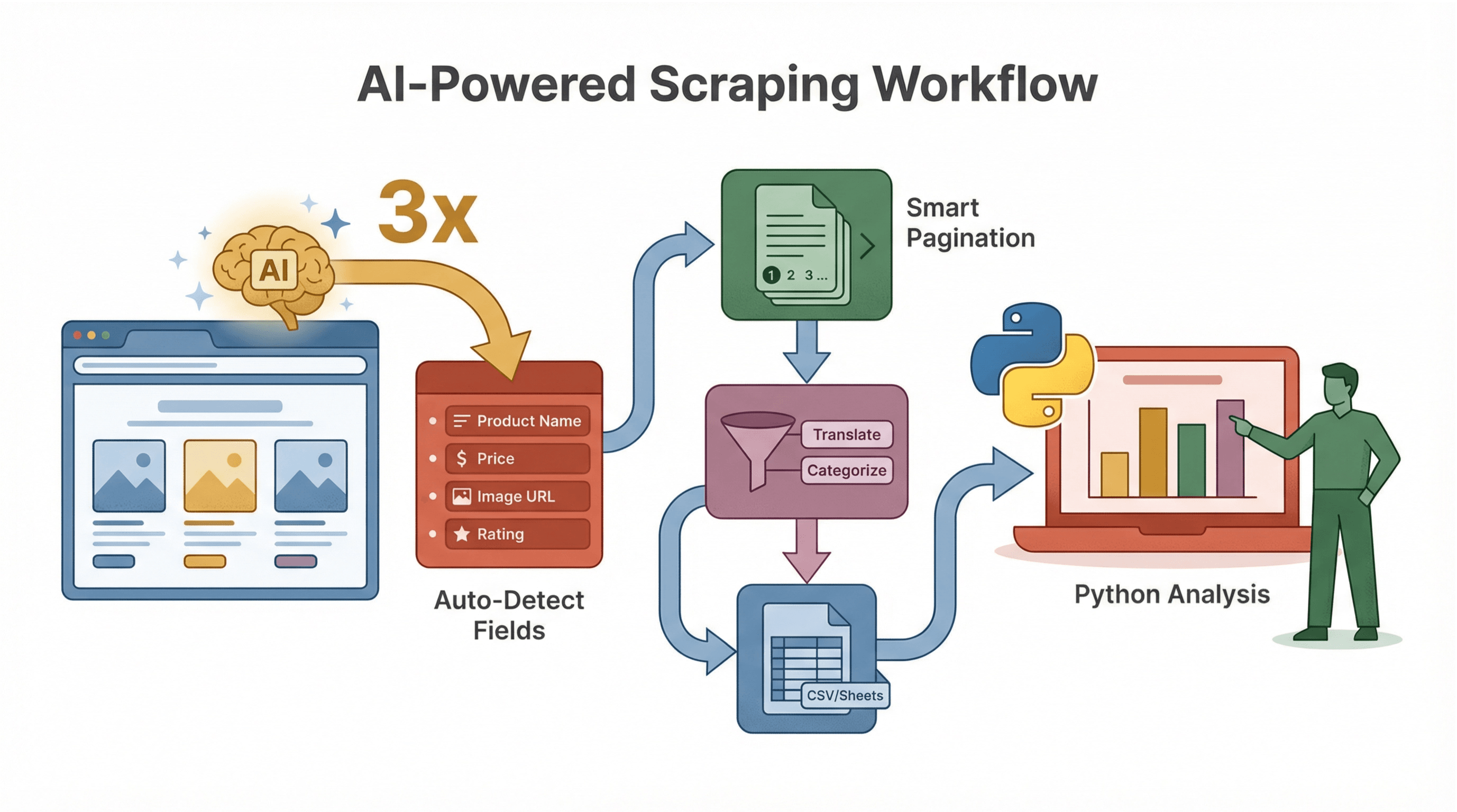 Thunderbit ne se limite pas à l’extraction : il rend tout le process plus intelligent et plus rapide.
Thunderbit ne se limite pas à l’extraction : il rend tout le process plus intelligent et plus rapide.
Schéma de données suggéré par l’IA
L’IA de Thunderbit propose instantanément les champs à extraire, plus besoin de deviner ou d’inspecter le HTML. Par exemple, sur une page produit, il détecte « Nom du produit », « Prix », « URL de l’image », etc.
Gestion des sous-pages et de la pagination
Thunderbit repère automatiquement les pages de détail ou les résultats paginés, et les extrait sans codage supplémentaire. Un vrai gain de temps pour l’e-commerce, l’immobilier ou la génération de leads.
Nettoyage et enrichissement des données par IA
Tu veux traduire, résumer ou catégoriser les données à la volée ? Thunderbit permet d’ajouter des prompts IA à chaque champ : par exemple, étiqueter les avis comme « Positif » ou « Négatif », ou extraire uniquement la partie numérique d’un prix.
Exemple de workflow
- Utilise Thunderbit pour structurer tes données (avec suggestions IA).
- Exporte en CSV ou Google Sheets.
- Analyse, visualise ou automatise le suivi avec Python.
Ce workflow est parfait pour les équipes où tout le monde ne code pas : Thunderbit gère l’extraction, Python l’analyse avancée.
Exemple extracteur web Python : Astuces avancées et galères fréquentes
Envie d’aller plus loin ? Voici quelques tips de pro :
Extraire du contenu dynamique
Beaucoup de sites modernes chargent les données en JavaScript. Si Requests + BeautifulSoup ne renvoient rien ou des données incomplètes, tente :
- Selenium ou Playwright : Automatise un vrai navigateur pour rendre la page, puis extrait le HTML.
- Cherche des API : Parfois, les données sont chargées via des appels API en arrière-plan (souvent en JSON). Utilise l’onglet Réseau de ton navigateur pour repérer ces endpoints — bien plus simples à extraire !
Gérer la pagination
Parcours les pages en modifiant le paramètre d’URL (ex : ?page=2). Ou utilise BeautifulSoup pour trouver le lien « Suivant » et le suivre jusqu’à la fin.
Planifier les extractions
Utilise la bibliothèque schedule de Python ou un cron job pour automatiser tes extractions. Ou opte pour la planification intégrée de Thunderbit, sans code.
Galères fréquentes
- CAPTCHAs : Ralentis tes requêtes, utilise des proxies ou des solutions humaines.
- Problèmes d’encodage : Spécifie toujours
encoding="utf-8"lors de l’écriture de fichiers. - Blocages IP : Alterne les proxies, change le User-Agent et respecte les limites de fréquence.
Conclusion & Points clés à retenir
Maîtriser l’extraction de données web avec Python, c’est à la portée de tous. Commence par l’essentiel :
- Installe ton environnement et les bibliothèques clés.
- Analyse la structure du site cible et prépare tes sélecteurs.
- Écris un script simple pour récupérer, analyser et extraire les données.
- Exporte tes résultats dans le format qui te convient.
En avançant, combine Python avec des outils IA comme pour gérer les sites complexes, dynamiques ou à gros volume. Les fonctions IA de Thunderbit — suggestions de champs, extraction de sous-pages, exports instantanés — te feront gagner un temps fou et permettront à tous, même sans coder, de profiter de la puissance du scraping.
Retiens bien : les meilleurs extracteurs sont fiables, éthiques et pensés pour un objectif précis. Que tu sois commercial, responsable e-commerce ou fan de data, l’extraction web ouvre un monde d’opportunités — commence petit, progresse et continue d’apprendre.
Envie d’aller plus loin ? Va voir le pour d’autres guides, ou teste l’ pour voir l’extraction IA en action.
FAQ
1. Quelle est la façon la plus simple de débuter le web scraping avec Python ?
Installe Python 3, puis utilise Requests et BeautifulSoup pour récupérer et analyser des pages web. Commence par des sites simples et monte en puissance au fur et à mesure.
2. Comment gérer les sites qui chargent les données en JavaScript ?
Pour les sites blindés de JavaScript, utilise des outils d’automatisation de navigateur comme Selenium ou Playwright, ou cherche des appels API dans l’onglet Réseau de ton navigateur qui renvoient des données structurées (JSON).
3. Quel est le meilleur format d’export pour des usages pros ?
Le CSV est le format le plus universel (compatible Excel, Google Sheets, etc.), mais tu peux aussi exporter en Excel, JSON ou dans des bases de données comme SQLite. Thunderbit permet aussi l’export direct vers Google Sheets, Notion et Airtable.
4. Comment éviter d’être bloqué lors du scraping ?
Change ton User-Agent, utilise des proxies pour les extractions massives, respecte les limites de fréquence et vérifie toujours le fichier robots.txt du site. N’extrais jamais de données personnelles ou sensibles.
5. Comment Thunderbit facilite-t-il l’extraction web pour les non-codeurs ?
Thunderbit utilise l’IA pour suggérer les champs de données, gérer les sous-pages et la pagination, et exporter des données structurées en quelques clics — sans aucune ligne de code. Parfait pour les pros qui veulent des résultats rapides et fiables, sans prise de tête technique.
Prêt à automatiser ta collecte de données ? Teste gratuitement et laisse l’IA révolutionner ta façon d’extraire des données web.
Pour aller plus loin