Laisse-moi te raconter mes débuts dans le SaaS et l’automatisation, à une époque où « crawler le web » sonnait plus comme une blague de geek que comme un vrai job de data. Aujourd’hui, le crawling, c’est le nerf de la guerre : tout le monde, de Google aux comparateurs de prix, s’en sert à fond. Le web, c’est un vrai terrain de jeu qui bouge tout le temps, et tout le monde – des devs aux équipes commerciales – veut mettre la main sur ses données. Mais voilà le souci : même si Python a rendu la création de crawler web python super accessible, la plupart des gens veulent juste les infos, pas se prendre la tête avec les headers HTTP ou le JavaScript qui se charge en douce.
C’est là que ça devient fun. En tant que co-fondateur de , j’ai vu la demande de données web exploser dans tous les domaines. Les commerciaux veulent des leads frais, les responsables e-commerce surveillent les prix des concurrents, les marketeurs cherchent à comprendre le contenu qui cartonne. Mais franchement, qui a envie de devenir expert en crawler web python ? On va donc voir ensemble ce que c’est vraiment, pourquoi c’est utile, et comment les extracteur web ia comme Thunderbit changent la donne pour tout le monde, que tu sois dev ou pas.
Crawler Web Python : C’est Quoi et Pourquoi Ça Compte ?
On va clarifier un truc : crawler web et extracteur web (ou scraper) c’est pas pareil. On confond souvent, mais c’est comme comparer un robot aspirateur à un aspi balai : ça nettoie, mais pas pareil !
- Les crawler web sont les explorateurs du web. Leur job : suivre les liens, indexer les pages, un peu comme Googlebot qui fait sa tournée.
- Les extracteur web sont les spécialistes de la récolte. Ils vont chercher les infos précises : prix, contacts, contenus, etc.

Quand on parle de crawler web python, on pense à utiliser Python pour créer ces robots qui parcourent (et parfois extraient) des données du web. Python, c’est le langage chouchou : simple à prendre en main, blindé de bibliothèques, et franchement, qui veut coder un crawler en assembleur ?
Pourquoi Le Crawling et Le Scraping Sont Devenus Incontournables ?
Pourquoi tout le monde s’y met ? Parce que la donnée web, c’est l’or noir du digital – sauf qu’il suffit de coder (ou de cliquer) pour la récupérer.
Voici quelques exemples concrets côté business :
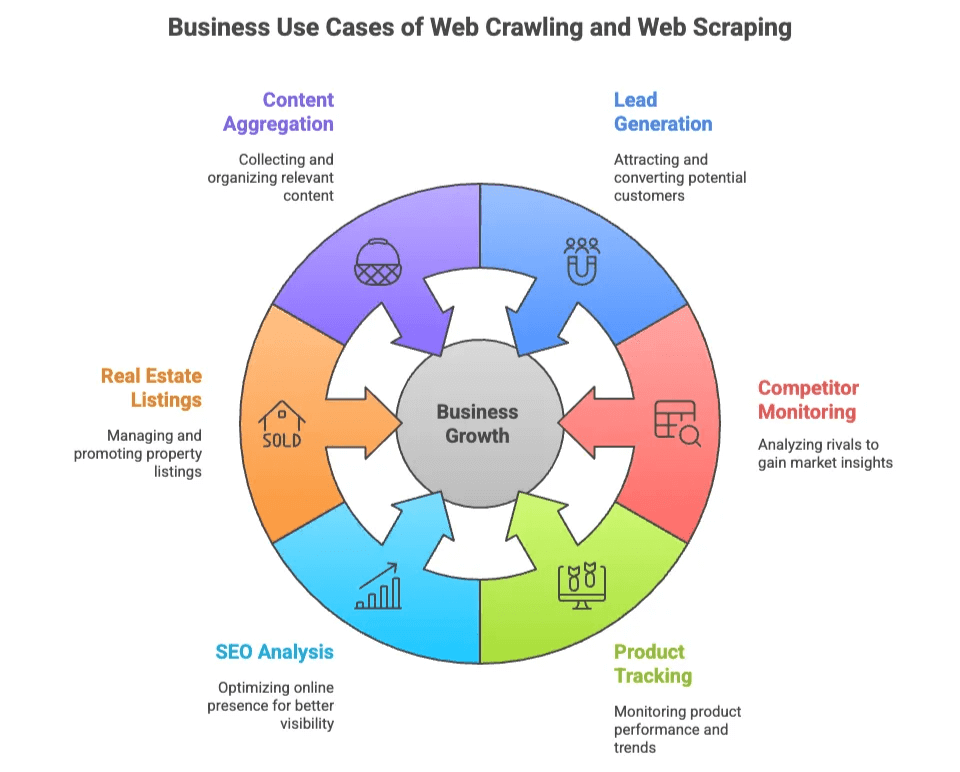
| Cas d'usage | Pour qui ? | Valeur ajoutée |
|---|---|---|
| Génération de leads | Commerciaux, Marketing | Constituer des listes ciblées à partir d’annuaires, réseaux sociaux |
| Veille concurrentielle | E-commerce, Opérations | Suivre les prix, stocks et nouveautés des concurrents |
| Suivi de produits | E-commerce, Retail | Surveiller les catalogues, avis et notes |
| Analyse SEO | Marketing, Contenu | Étudier mots-clés, balises et backlinks pour optimiser le référencement |
| Annonces immobilières | Agents, Investisseurs | Centraliser les biens et contacts propriétaires de plusieurs sources |
| Agrégation de contenu | Recherche, Médias | Collecter articles, actualités ou posts de forums pour analyse |
L’avantage ? Que tu sois tech ou pas, tu y trouves ton compte. Les devs font des crawler web python sur-mesure pour les gros besoins, les équipes business veulent juste des données fiables, sans se prendre la tête avec les sélecteurs CSS.
Les Bibliothèques Python Incontournables : Scrapy, BeautifulSoup, Selenium
Si Python cartonne pour le crawling web, c’est grâce à trois bibliothèques stars, chacune avec ses fans (et ses petits défauts).
| Bibliothèque | Facilité d’utilisation | Vitesse | Support du contenu dynamique | Scalabilité | Idéal pour |
|---|---|---|---|---|---|
| Scrapy | Moyenne | Rapide | Limité | Élevée | Crawls massifs et automatisés |
| BeautifulSoup | Facile | Moyenne | Aucun | Faible | Petits projets, parsing simple |
| Selenium | Plus complexe | Lent | Excellente | Moyenne | Pages interactives, JavaScript |
Petit tour d’horizon.
Scrapy : Le Framework Ultime du Crawling Python
Scrapy, c’est le couteau suisse du crawling web python. Un vrai framework pour crawler à grande échelle : des milliers de pages, des requêtes en parallèle, export de données nickel…
Pourquoi les devs l’adorent :
- Tout est géré au même endroit : crawling, parsing, export.
- Support natif de la concurrence, du scheduling, des pipelines.
- Parfait pour les gros projets où il faut crawler et extraire à la chaîne.
Mais… Scrapy, ça s’apprend. Comme le dit un dev : « c’est trop lourd si tu veux juste extraire trois pages » (). Il faut piger les sélecteurs, l’asynchrone, parfois même les proxys et l’anti-bot.
Workflow Scrapy basique :
- Tu crées un Spider (la logique du crawler)
- Tu configures les pipelines (traitement des données)
- Tu lances le crawl et tu exportes
Si tu veux cartographier le web comme Google, Scrapy est fait pour toi. Pour juste choper quelques emails, c’est clairement overkill.
BeautifulSoup : Le Parsing Simple et Efficace
BeautifulSoup, c’est le « hello world » du parsing web. Léger, il sert à analyser HTML et XML, parfait pour débuter ou pour des petits scripts.
Pourquoi on l’aime :
- Ultra simple à utiliser.
- Idéal pour extraire des données de pages statiques.
- Parfait pour des scripts rapides.
Mais… BeautifulSoup ne crawl pas, il parse. Il faut l’associer à requests pour récupérer les pages, et coder soi-même la navigation ou la pagination ().
Pour s’initier au crawling web, c’est top. Mais il ne gère pas le JavaScript ni les gros volumes.
Selenium : Pour Les Sites Dynamiques et JavaScript
Selenium, c’est le boss de l’automatisation de navigateur. Il pilote Chrome, Firefox ou Edge, clique sur les boutons, remplit les formulaires, et surtout, gère les pages dynamiques.

Ses points forts :
- Peut « voir » et interagir avec les pages comme un humain.
- Gère le contenu dynamique et les données chargées en AJAX.
- Indispensable pour les sites qui demandent une connexion ou des actions utilisateur.
Mais… Selenium est lent et gourmand. Il lance un navigateur complet pour chaque page, donc sur de gros volumes, ta machine va vite saturer (). Et la maintenance, c’est pas la joie : drivers à gérer, temps d’attente…
Selenium, c’est le must pour les sites « bunker » qui bloquent les extracteur web classiques.
Les Galères du Crawler Python au Quotidien
Parlons vrai : coder un crawler web python, c’est souvent galère. J’ai passé des heures à déboguer des sélecteurs ou à contourner l’anti-bot. Les gros obstacles :
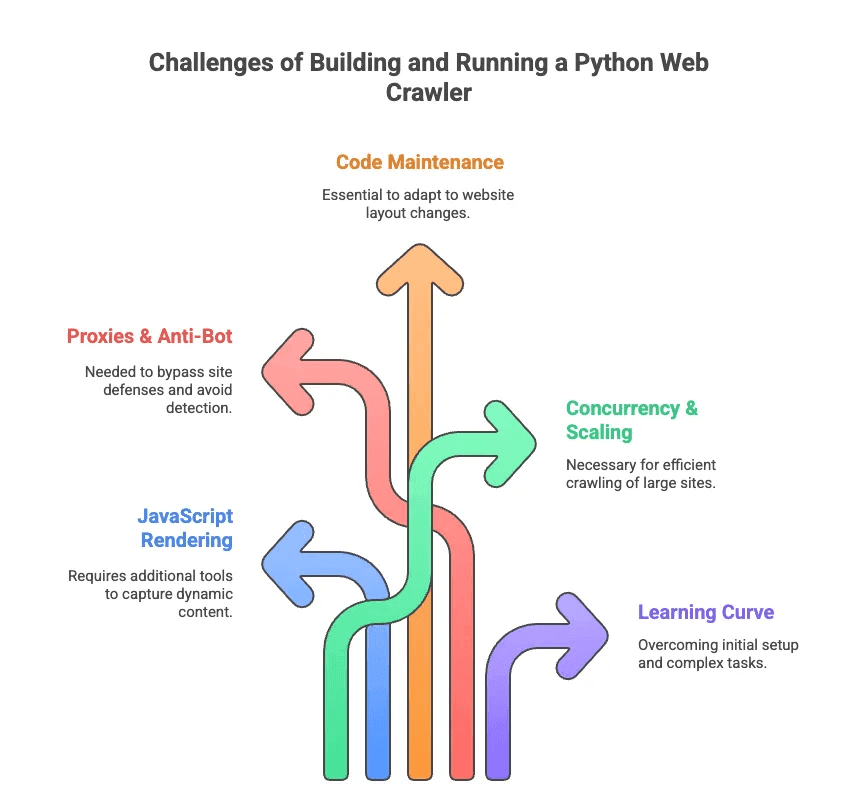
- Rendu JavaScript : La plupart des sites modernes chargent le contenu à la volée. Scrapy et BeautifulSoup ne voient rien sans outils en plus.
- Proxys & Anti-bot : Les sites n’aiment pas être crawlés. Il faut tourner les proxys, changer d’user-agent, parfois résoudre des CAPTCHAs.
- Maintenance du code : Les sites changent souvent. Ton scraper peut casser du jour au lendemain, et il faut tout revoir.
- Concurrence & Scalabilité : Pour crawler des milliers de pages, il faut gérer l’asynchrone, les erreurs, les pipelines…
- Courbe d’apprentissage : Pour les non-devs, même installer Python et les dépendances, c’est déjà un défi. Oublie la pagination ou la gestion des connexions sans coup de main.
Comme le dit un ingénieur, coder un scraper sur-mesure, c’est parfois « avoir un doctorat en configuration de sélecteurs » – pas vraiment ce que cherche un commercial ou un marketeur ().
Extracteur Web IA vs. Crawler Python : La Révolution Pour Les Pros
Et si tu pouvais avoir les données sans te prendre la tête ? C’est là que les extracteur web ia entrent en jeu. Ces outils – comme – sont pensés pour les métiers, pas pour les codeurs. L’IA lit la page, te propose les données à extraire, et gère tout le sale boulot (pagination, sous-pages, anti-bot) en coulisses.
Petit comparatif :
| Fonctionnalité | Crawler Web Python | Extracteur Web IA (Thunderbit) |
|---|---|---|
| Mise en place | Code, bibliothèques, config | Extension Chrome en 2 clics |
| Maintenance | Mises à jour manuelles, débogage | L’IA s’adapte aux changements |
| Contenu dynamique | Nécessite Selenium ou plugins | Rendu navigateur/cloud intégré |
| Anti-bot | Proxys, user-agents | IA & contournement cloud |
| Scalabilité | Élevée (avec effort) | Élevée (cloud, scraping parallèle) |
| Facilité d’utilisation | Pour développeurs | Pour tous |
| Export des données | Code ou scripts | 1 clic vers Sheets, Airtable, Notion |
Avec Thunderbit, plus besoin de te soucier des requêtes HTTP, du JavaScript ou des proxys. Clique sur « IA : suggérer les champs », laisse l’IA faire le taf, puis lance l’extraction. C’est comme avoir un assistant data – sans le costard.
Thunderbit : L’Extracteur Web IA Nouvelle Génération Pour Tous
Concrètement, Thunderbit est une qui rend la collecte de données aussi simple que commander un plat sur une appli. Ce qui fait la différence :
- Détection intelligente des champs : L’IA de Thunderbit lit la page et te propose direct les colonnes à extraire – fini de galérer avec les sélecteurs CSS ().
- Support des pages dynamiques : Fonctionne aussi bien sur les pages statiques que sur celles blindées de JavaScript, grâce au mode navigateur ou cloud.
- Sous-pages & pagination : Besoin de détails sur chaque produit ou profil ? Thunderbit clique et collecte tout, tout seul ().
- Templates adaptatifs : Un seul modèle d’extracteur s’adapte à plusieurs structures de pages – pas besoin de tout refaire si le site change.
- Contournement anti-bot : L’IA et l’infra cloud passent les défenses anti-scraping sans souci.
- Export des données : Envoie tes données direct vers Google Sheets, Airtable, Notion ou télécharge-les en CSV/Excel – même en version gratuite ().
- Nettoyage IA des données : Résume, catégorise ou traduit tes données à la volée – fini les tableurs en vrac.
Exemples concrets :
- Commerciaux : extraient des listes de prospects depuis des annuaires ou LinkedIn en quelques minutes.
- Responsables e-commerce : surveillent les prix et nouveautés des concurrents sans prise de tête.
- Agents immobiliers : centralisent les annonces et contacts propriétaires de plusieurs sites.
- Marketeurs : analysent contenus, mots-clés et backlinks pour le SEO – sans écrire une ligne de code.
Le workflow Thunderbit est tellement simple que même mes potes pas du tout techniques l’utilisent – et kiffent. Installe l’extension, ouvre le site cible, clique sur « IA : suggérer les champs » et c’est parti. Pour les sites connus comme Amazon ou LinkedIn, il y a même des templates prêts à l’emploi – un clic et c’est dans la boîte ().
Quand Choisir un Crawler Python ou un Extracteur Web IA ?
Alors, coder un crawler web python ou passer par Thunderbit ? Voilà mon avis sans filtre :
| Scénario | Crawler Web Python | Extracteur Web IA (Thunderbit) |
|---|---|---|
| Besoin de logique personnalisée ou de très grande échelle | ✔️ | Peut-être (mode cloud) |
| Intégration poussée avec d’autres systèmes | ✔️ (via code) | Limité (via export) |
| Utilisateur non technique, besoin rapide | ❌ | ✔️ |
| Changements fréquents de structure de site | ❌ (mises à jour manuelles) | ✔️ (IA s’adapte) |
| Sites dynamiques/JavaScript | ✔️ (avec Selenium) | ✔️ (natif) |
| Petit budget, petits projets | Peut-être (gratuit mais chronophage) | ✔️ (offre gratuite, sans blocage) |
Prends un crawler web python si :
- Tu es dev et tu veux tout contrôler.
- Tu dois crawler des millions de pages ou faire des pipelines de données sur-mesure.
- Tu acceptes la maintenance et le débogage régulier.
Choisis Thunderbit si :
- Tu veux les données tout de suite, sans coder.
- Tu bosses en vente, e-commerce, marketing ou immobilier et tu veux juste le résultat.
- Tu veux pas t’embêter avec les proxys, sélecteurs ou l’anti-bot.
Toujours pas sûr ? Petite checklist :
- À l’aise avec Python et le web ? Teste Scrapy ou Selenium.
- Tu veux juste des données propres, vite fait ? Thunderbit est fait pour toi.
Conclusion : Libère la Donnée Web – Choisis l’Outil Qui Te Va
Le crawling et le scraping web, c’est devenu la base à l’ère de la data. Mais soyons honnêtes : tout le monde n’a pas envie de devenir expert en crawling web python. Les outils comme Scrapy, BeautifulSoup ou Selenium sont puissants, mais ça prend du temps et ça demande de la maintenance.
C’est pour ça que l’arrivée des extracteur web ia comme est aussi excitante. On a conçu Thunderbit pour rendre la donnée web accessible à tous – pas juste aux devs. Grâce à la détection intelligente, au support des pages dynamiques et au zéro code, chacun peut extraire ce qu’il lui faut en quelques minutes.
Que tu sois dev passionné ou pro qui veut juste des résultats, il y a un outil pour toi. Regarde tes besoins, ton niveau technique et tes délais. Et si tu veux voir à quel point l’extraction web peut être simple, – ton futur toi (et ton tableur) te diront merci.
Envie d’aller plus loin ? Va checker d’autres guides sur le , comme ou . Bon crawling – et bon scraping !
FAQ
1. Quelle est la différence entre un Crawler Web Python et un Extracteur Web ?
Un crawler web python explore et indexe les pages en suivant les liens – parfait pour cartographier un site. Un extracteur web va chercher les infos précises sur ces pages, comme les prix ou les emails. Les crawlers explorent, les extracteurs récoltent ce qui t’intéresse. Les deux sont souvent combinés en Python pour des workflows d’extraction complets.
2. Quelles bibliothèques Python utiliser pour créer un Crawler Web ?
Les plus connues sont Scrapy, BeautifulSoup et Selenium. Scrapy est rapide et scalable pour les gros projets ; BeautifulSoup est parfait pour débuter et pour les pages statiques ; Selenium gère les sites blindés de JavaScript mais est plus lent. Le choix dépend de ton niveau, du type de contenu et de la taille du projet.
3. Existe-t-il une solution plus simple pour extraire des données web sans coder un crawler Python ?
Oui – Thunderbit est une extension Chrome boostée à l’IA qui permet à n’importe qui d’extraire des données web en deux clics. Pas de code, pas de prise de tête. Elle détecte automatiquement les champs, gère la pagination et les sous-pages, et exporte les données vers Sheets, Airtable ou Notion. Idéal pour les équipes commerciales, marketing, e-commerce ou immobilier qui veulent des données propres – vite fait.
En savoir plus :