

En 2025, le web ressemble à un immense terrain de jeu qui ne cesse de se transformer : un jour, tu surveilles les prix de tes concurrents, le lendemain tu te retrouves face à des labyrinthes de JavaScript dynamique et des systèmes anti-bots qui n’ont rien à envier à un film d’action. Après avoir passé des années à créer des outils d’automatisation pour les équipes commerciales et opérationnelles, je peux te le dire sans détour : l’extraction de données web n’est plus juste un bonus, c’est devenu un vrai super-pouvoir pour toute boîte. Avec 90 % des entreprises qui s’appuient sur l’analytique pour prendre leurs décisions, et un volume de données en ligne qui a explosé de 193 % en quatre ans, savoir transformer le chaos du web en infos utiles, c’est ce qui fait la différence entre ceux qui mènent la danse et ceux qui suivent.

Soyons clairs : l’extraction web, ça n’a plus rien à voir avec ce que c’était. Fini le temps où trois lignes de Python suffisaient pour choper du HTML statique. Aujourd’hui, il faut jongler avec du contenu dynamique, des scrolls infinis et des protections anti-bots qui te donnent l’impression d’être dans Mission Impossible. Que tu sois novice ou que tu veuilles muscler ton jeu, ce guide va te filer les meilleures pratiques, outils et méthodes pour dompter l’extraction Python en 2025 — et te montrer comment l’IA, avec des solutions comme Thunderbit, peut vraiment booster tes projets.
Utilisez l’IA pour extraire des données de n’importe quel site web Get Started Free
De Débutant à Expert : Les Bases de l’Extraction Python
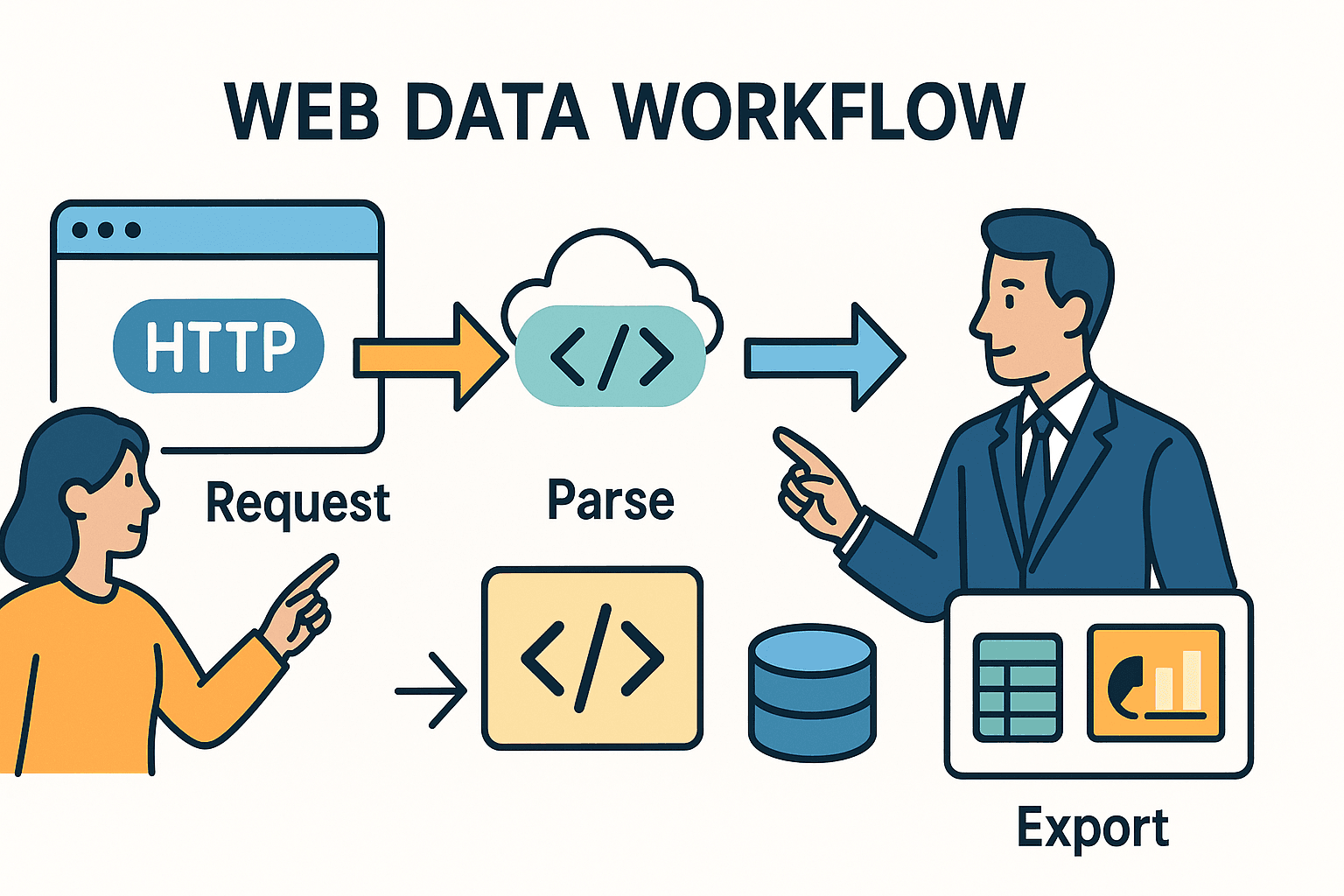
On commence par la base. L’extraction web, c’est juste automatiser ce que tu ferais à la main dans ton navigateur : tu charges une page, tu repères les infos qui t’intéressent, et tu les sauvegardes. En Python, ça tient en trois étapes :
- Envoyer une requête HTTP (comme quand tu tapes une URL dans ton navigateur).
- Analyser le HTML pour trouver les infos que tu veux.
- Exporter ou traiter ces données — vers un tableur, une base de données ou un dashboard, par exemple.
Le truc, c’est que les outils à utiliser (et les galères à gérer) dépendent de la complexité du site et de ce que tu veux en faire.
Extraction Python 101 : Comment ça marche ?
Imagine que l’extraction, c’est comme envoyer un bibliothécaire chercher un journal, puis découper juste les articles qui t’intéressent. La bibliothèque requests de Python, c’est ton bibliothécaire — il va chercher le HTML. BeautifulSoup, c’est tes ciseaux — il te permet de découper et d’extraire les bonnes infos.
Mais si le journal est écrit à l’encre invisible (coucou JavaScript !) ou que les articles sont éparpillés sur des dizaines de pages ? Là, il te faut des outils plus costauds — ou un peu de magie IA.
Comparatif des Outils Essentiels
Petit tour d’horizon des outils Python pour l’extraction web, et quand les sortir du placard :
| Outil/Bibliothèque | À utiliser quand... | Avantages | Inconvénients |
|---|---|---|---|
| Requests + BeautifulSoup | Extraction de pages statiques ou petits besoins | Simple, rapide, parfait pour débuter. Contrôle total. | Ne gère pas le JavaScript ni les extractions massives. |
| Scrapy | Projets volumineux, multi-pages/sites | Puissant, crawling intégré, asynchrone, pipelines, gestion d’erreurs solide. | Prise en main plus technique, config un peu lourde. |
| Selenium/Playwright | Pages dynamiques, logins, actions utilisateur | Peut extraire tout ce qu’un navigateur affiche. Gère le contenu dynamique, les scrolls, etc. | Plus lent, gourmand en ressources, déploiement plus lourd. |
| Thunderbit (IA) | Données non structurées, PDF, images, sans coder | L’IA détecte automatiquement les champs, gère les sous-pages, exporte vers Excel/Sheets, sans code. | Moins personnalisable pour les cas particuliers, usage basé sur crédits. |
Pour la plupart des pros, commencer avec requests et BeautifulSoup c’est nickel pour les sites simples et statiques. Pour des besoins plus costauds, Scrapy est ton meilleur pote. Et si tu tombes sur du contenu dynamique, des anti-bots ou des données non structurées, les outils IA comme Thunderbit peuvent vraiment te sauver la mise.
Essayez gratuitement l’Extracteur Web IA Thunderbit
Cartographier le Terrain : Les Bonnes Pratiques pour l’Extraction Complexe
Comment passer de « Je veux ces données » à un extracteur qui tourne sans accroc ? Voilà ma méthode testée et approuvée :
1. Inspecter et Comprendre le Site Cible
Avant de taper la moindre ligne de code, ouvre les outils développeur de ton navigateur (F12 ou clic droit > Inspecter). Repère les données dans le HTML. Elles sont dans un tableau ? Une série de <div> ? Y a-t-il un appel API caché qui balance du JSON ? Parfois, la solution la plus simple est juste sous ton nez.
Astuce : Si tu vois une requête réseau qui ramène du JSON quand tu cliques sur « page suivante » ou « charger plus », tu peux souvent zapper le HTML et appeler direct cette API avec Python.
2. Prototyper sur une Seule Page
Commence petit. Utilise requests pour charger une page, puis BeautifulSoup pour extraire quelques champs. Affiche le résultat. Si tu bloques ou que les données manquent, tente d’ajouter des headers (genre un User-Agent de navigateur), ou vérifie si le contenu est chargé par JavaScript (dans ce cas, direction étape 3).
3. Gérer le Dynamisme et la Pagination
Si les données ne sont pas dans le HTML, c’est sûrement du JavaScript qui les charge. Voilà quoi faire :
- Automatisation du navigateur : Utilise Selenium ou Playwright pour ouvrir la page, attendre le contenu, puis récupérer le HTML rendu.
- Appels API : Check les requêtes XHR dans l’onglet Réseau. Si tu trouves une URL qui renvoie du JSON, reproduis cet appel avec
requests. - Pagination : Pour les données sur plusieurs pages, boucle sur les numéros de page ou suis les liens « Suivant ». Pour le scroll infini, utilise Selenium pour descendre ou simule les appels API déclenchés par le scroll.
4. Gestion des Erreurs et Respect des Sites
Les sites n’aiment pas toujours les extracteurs. Pour éviter de te faire bloquer :
- Respecte
robots.txt: Va toujours checkerexample.com/robots.txtpour voir les chemins interdits ou les délais de crawl. - Limite la fréquence : Ajoute un
time.sleep()entre les requêtes. Sirobots.txtditCrawl-delay: 5, attends au moins 5 secondes. - User-Agent personnalisé : Identifie poliment ton extracteur (ex :
"MyScraper/1.0 (ton@email.com)"). - Gestion des échecs : Encadre tes requêtes avec try/except. Réessaie en cas d’échec, ralentis si tu prends un HTTP 429 (Trop de requêtes).
5. Extraction et Nettoyage des Données
Utilise BeautifulSoup ou les sélecteurs Scrapy pour extraire les champs. Nettoie les espaces, convertis les prix en chiffres, parse les dates, vérifie que tout est complet. Pour les gros volumes, passe par pandas pour nettoyer et dédupliquer.
6. Extraction sur les Sous-pages
Souvent, les infos clés sont sur les pages de détail. Récupère la liste des liens, puis visite chaque page pour extraire plus d’infos. En Python, ça veut dire boucler sur les URLs et charger chaque page. Avec Thunderbit, la fonction « Extraire les sous-pages » fait tout ça pour toi : l’IA visite chaque sous-page et enrichit ton jeu de données.
7. Export et Automatisation
Exporte tes données propres vers CSV, Excel, Google Sheets ou une base de données. Pour les tâches récurrentes, programme ton script avec cron, Airflow, ou (avec Thunderbit) lance une extraction cloud en langage naturel (« chaque lundi à 9h »).
Comment extraire des données de site web vers Excel avec l’IA Get Started Free
Thunderbit : Quand l’IA Boost Votre Workflow Python
Soyons honnêtes : parfois, même le meilleur code Python ne suffit pas face à des données non structurées, protégées ou vraiment tordues. C’est là que Thunderbit entre en scène.
Comment Thunderbit Complète Python
Thunderbit, c’est une extension Chrome boostée à l’IA qui lit les pages web (ou PDF, images, etc.) et te rend des données structurées — sans coder. Voilà comment je l’utilise en complément de Python :
- Pour les données non structurées : Si je tombe sur un PDF, une image ou un site au HTML imprévisible, je laisse l’IA de Thunderbit bosser. Elle extrait les tableaux des PDF, le texte des images, et propose même les champs automatiquement.
- Pour l’extraction multi-étapes et sous-pages : La fonction « Extraire les sous-pages » de Thunderbit fait gagner un temps fou. J’extrais une page de liste, puis l’IA visite chaque page de détail et fusionne les résultats — plus besoin de boucles imbriquées ou de galérer avec l’état.
- Pour l’export : Thunderbit exporte direct vers Excel, Google Sheets, Notion ou Airtable. Je peux ensuite intégrer ces données dans mon pipeline Python pour analyse ou reporting.
Exemple Concret : Python + Thunderbit en Action
Imaginons que je surveille des annonces immobilières. J’utilise Python et Scrapy pour collecter les URLs d’annonces sur plusieurs sites. Mais sur l’un d’eux, les specs détaillées ne sont que dans des PDF à télécharger. Plutôt que de coder un parseur PDF, je balance ces fichiers dans Thunderbit, laisse l’IA extraire les tableaux, puis j’exporte en CSV. Ensuite, je fusionne tout dans Python pour une analyse de marché complète.
Autre exemple : je construis une liste de prospects pour la vente. J’utilise Python pour extraire les URLs d’entreprises, puis les extracteurs d’emails et de téléphones de Thunderbit (gratuits !) pour choper les contacts sur chaque site — sans me prendre la tête avec des regex.
Extraire des données non structurées avec Thunderbit IA
Construire un Workflow d’Extraction Durable : Du Script à la Pipeline
Un script à l’arrache, c’est bien pour un besoin ponctuel, mais la plupart des extractions pros sont récurrentes. Voilà comment je monte une stack d’extraction solide et évolutive :
Le Cadre CCCD : Crawler, Collecter, Nettoyer, Déboguer
- Crawler : Récupère toutes les URLs cibles (sitemaps, pages de recherche, listes).
- Collecter : Extrait les données de chaque URL (avec Python, Thunderbit, ou les deux).
- Nettoyer : Normalise, déduplique et valide les données.
- Déboguer/Surveiller : Log chaque exécution, gère les erreurs, mets des alertes en cas de souci.
Visualise ça comme une chaîne :
URLs → [Crawler] → [Extracteur] → [Nettoyeur] → [Exporteur] → [Plateforme métier]
Planification et Surveillance
- Avec Python : Utilise des cron jobs, Airflow ou des planificateurs cloud pour lancer les scripts régulièrement. Log les sorties, envoie des alertes email ou Slack en cas de pépin.
- Avec Thunderbit : Utilise le planificateur intégré — tape juste « chaque lundi à 9h » et Thunderbit lance l’extraction dans le cloud et balance les données où tu veux.
Documentation et Transmission
Garde ton code sous Git, documente ton workflow, et assure-toi qu’au moins une autre personne sait comment lancer ou mettre à jour la pipeline. Pour les workflows mixtes Python/Thunderbit, note qui fait quoi et où vont les exports (ex : « Thunderbit extrait le site C vers Google Sheets, Python fusionne tout chaque semaine »).
Éthique et Conformité : Extraire Responsable en 2025
Un grand pouvoir d’extraction implique de grandes responsabilités. Voilà comment rester dans les clous, côté légal et éthique :
Robots.txt et Limitation de Fréquence
- Vérifie robots.txt : Passe toujours en revue le robots.txt du site pour les chemins interdits et les délais de crawl. Utilise le module
robotparserde Python pour automatiser la vérif. - Extraction polie : Ajoute des pauses entre les requêtes, surtout si un
Crawl-delayest indiqué. N’inonde jamais un site de requêtes. - User-Agent : Identifie honnêtement ton extracteur. N’usurpe pas Googlebot ou un autre navigateur.
Données Personnelles et Conformité
- RGPD/CCPA : Si tu extrais des données perso (noms, emails, téléphones), traite-les selon les lois sur la vie privée. Ne collecte que l’essentiel, sécurise les données, et sois prêt à les supprimer sur demande.
- Conditions d’Utilisation : N’extrais pas derrière un login sans autorisation. Beaucoup de ToS interdisent l’accès automatisé — les enfreindre peut te valoir un ban, voire pire.
- Données publiques uniquement : Limite-toi aux données accessibles publiquement. N’essaie pas de choper des infos privées, protégées par copyright ou sensibles.
Checklist de Conformité
- Vérification de robots.txt pour les règles et délais
- Limitation de fréquence et User-Agent personnalisé
- Extraction uniquement de données publiques et non sensibles
- Gestion des données personnelles conforme à la législation
- Respect des ToS et du copyright du site
Erreurs Courantes et Astuces de Débogage : Rendre Votre Extraction Robuste
Même les meilleurs extracteurs se prennent des murs. Voilà les galères les plus fréquentes — et comment je les gère :
| Type d’erreur | Symptôme/Message | Astuce de débogage |
|---|---|---|
| HTTP 403/429/500 | Bloqué, limité, ou erreur serveur | Vérifie les headers, ralentis, change d’IP ou utilise des proxies. Respecte les délais de crawl. |
| Données manquantes/NoneType | Données absentes dans le HTML | Affiche et inspecte le HTML. Structure modifiée ou page de blocage ? |
| Données générées par JS | Données absentes dans le HTML statique | Utilise Selenium/Playwright ou trouve l’appel API sous-jacent. |
| Problèmes de parsing/encodage | Erreurs Unicode, caractères bizarres | Mets le bon encodage, utilise .text ou html.unescape(). |
| Doublons/Incohérences | Données répétées ou incohérentes | Déduplique par ID ou URL unique. Vérifie la complétude des champs. |
| Anti-bot/CAPTCHA | Page CAPTCHA ou login requis | Ralentis, utilise l’automatisation navigateur, ou passe à Thunderbit/IA pour les cas complexes. |
Workflow de débogage :
- Affiche le HTML brut si ça coince.
- Compare ce que voit ton script avec le navigateur via les DevTools.
- Log chaque étape : URLs, codes de statut, nombre d’éléments extraits.
- Teste sur un petit échantillon avant de passer à l’échelle.
Projets Avancés : Passez à la Vitesse Supérieure avec Python
Envie de te lancer ? Voici quelques idées de projets concrets :
1. Tableau de Bord de Suivi des Prix E-commerce
Surveille les prix et stocks sur Amazon, eBay et Walmart. Gère les anti-bots, le contenu dynamique, et exporte chaque jour vers Google Sheets pour analyser les tendances. Utilise les modèles instantanés de Thunderbit pour démarrer vite.
2. Agrégateur d’Offres d’Emploi
Récupère les annonces d’Indeed et de sites spécialisés. Analyse les titres, boîtes, localisations et dates de publication. Gère la pagination et déduplique par ID d’offre. Programme une extraction quotidienne et exporte vers Airtable.
3. Extracteur de Contacts pour la Prospection
À partir d’une liste d’URLs d’entreprises, récupère emails et numéros de téléphone sur les pages d’accueil et de contact. Utilise des regex en Python ou les extracteurs gratuits de Thunderbit pour un résultat immédiat. Exporte vers Excel pour l’équipe commerciale.
4. Comparateur d’Annonces Immobilières
Extrait les annonces de Zillow et Realtor.com pour une région donnée. Normalise adresses et prix, compare les tendances, et visualise les résultats dans Google Sheets.
5. Suivi des Mentions sur les Réseaux Sociaux
Surveille les mentions de marque sur Reddit via leur API JSON. Agrège le nombre de posts, analyse le sentiment, et exporte les données temporelles pour le marketing.
Conclusion : Les Points Clés de l’Extraction Python en 2025
En résumé :
- L’extraction web est plus stratégique que jamais pour l’intelligence business, la vente et l’opérationnel. Le web est une mine d’or — à condition de savoir l’exploiter.
- Python est ton couteau suisse : Commence simple avec
requestsetBeautifulSoup, passe à la vitesse supérieure avec Scrapy, et automatise le navigateur pour les sites dynamiques. - Les outils IA comme Thunderbit sont tes alliés secrets pour les données non structurées, complexes ou sans code. Combine Python et IA pour une efficacité maximale.
- Les bonnes pratiques sont cruciales : Inspecte d’abord, code de façon modulaire, gère les erreurs, nettoie tes données et automatise ton workflow.
- La conformité, c’est non négociable : Vérifie toujours robots.txt, respecte la vie privée et extrais de façon responsable.
- Reste agile : Le web bouge — surveille tes extracteurs, débogue régulièrement, et adapte-toi en continu.
L’avenir de l’extraction web est hybride, éthique et orienté business. Que tu sois débutant ou expert, continue d’apprendre, reste curieux, et laisse les données guider tes prochains succès.
Annexe : Ressources et Outils pour l’Extraction Python
Voici ma sélection de ressources pour apprendre et débloquer les situations :
- Documentation Requests – HTTP pour les humains, clair et complet.
- Docs BeautifulSoup – Apprends à parser le HTML comme un chef.
- Documentation Scrapy – Pour l’extraction à grande échelle et en prod.
- Selenium avec Python / Playwright pour Python – Pour l’automatisation du navigateur et le contenu dynamique.
- Extension Chrome Thunderbit – L’extracteur web IA le plus simple pour les pros.
- Blog Thunderbit – Tutoriels, cas concrets et bonnes pratiques pour l’extraction IA.
- Guide légal AIMultiple – Pour rester à jour sur la conformité et l’éthique.
- Stack Overflow / Reddit r/webscraping** – Communauté et entraide pour le débogage.
Et pour voir comment Thunderbit peut te simplifier la vie, va jeter un œil à notre chaîne YouTube pour des démos et tutos détaillés.
FAQ
1. Quelle est la meilleure bibliothèque Python pour l’extraction web en 2025 ?
Pour les pages statiques et les petits besoins, requests + BeautifulSoup reste le combo gagnant. Pour l’extraction à grande échelle ou multi-pages, Scrapy est top. Pour le contenu dynamique, utilise Selenium ou Playwright. Pour les données non structurées ou complexes, les outils IA comme Thunderbit sont précieux.
2. Comment gérer les sites dynamiques ou blindés de JavaScript ?
Utilise des outils d’automatisation comme Selenium ou Playwright pour rendre la page et extraire les données. Sinon, inspecte l’onglet Réseau pour repérer les appels API qui renvoient du JSON — souvent plus simple et fiable à extraire.
3. L’extraction web, c’est légal ?
L’extraction de données publiques est généralement autorisée aux États-Unis, mais vérifie toujours le robots.txt, respecte les conditions d’utilisation du site et conforme-toi aux lois sur la vie privée comme le RGPD/CCPA. N’extrais jamais d’infos privées, protégées ou sensibles.
4. Comment automatiser et planifier mes extractions ?
Pour les scripts Python, utilise des cron jobs, Airflow ou des planificateurs cloud. Pour une automatisation sans code, Thunderbit propose une planification intégrée : décris juste ta fréquence en français et laisse-le tourner dans le cloud.
5. Que faire si mon extracteur ne marche plus ?
Vérifie d’abord si la structure du site a changé ou si tu es bloqué (HTTP 403/429). Inspecte le HTML, mets à jour tes sélecteurs, ralentis tes requêtes et check les protections anti-bots. Si ça coince toujours, tente les fonctionnalités IA de Thunderbit ou passe à l’automatisation navigateur.
Bonne extraction — que tes données soient toujours propres, conformes et prêtes à l’emploi ! Pour voir comment Thunderbit peut s’intégrer à ton workflow, télécharge l’extension Chrome et teste-la. Et pour encore plus d’astuces, le Blog Thunderbit est là pour toi.
Essayez gratuitement l’Extracteur Web IA Thunderbit Get Started Free




