
Le web, c’est un vrai terrain de jeu visuel : chaque jour, des milliards d’images débarquent en ligne, que ce soit pour remplir les vitrines des boutiques en ligne ou pour faire le buzz avec des mèmes. Si tu bosses dans la vente, le marketing ou la recherche, tu as sûrement déjà galéré à récupérer des images une par une. Je suis passé par là aussi, à enchaîner les « clic droit, enregistrer sous », en me demandant s’il n’y avait pas un moyen plus rapide. Bonne nouvelle : il y en a un ! Les extracteurs d’images Python et les solutions no-code comme changent la donne pour télécharger des images en masse depuis n’importe quel site.
Dans ce guide, je t’explique comment utiliser Python pour extraire des images, comment gérer les sites dynamiques un peu tordus, et pourquoi le combo Python + Thunderbit, c’est le top. Que tu veuilles monter un catalogue produit, faire de la veille concurrentielle ou juste en avoir marre du copier-coller, tu trouveras ici des astuces concrètes, des exemples de code et un peu d’humour pour la route.
C’est quoi, un Extracteur d’Images Python ?
Un extracteur d’images Python, c’est un script ou un outil qui va automatiquement sur les sites web, repère les fichiers image (souvent dans les balises <img>) et les télécharge direct sur ton ordi. Fini la corvée de sauvegarde manuelle : Python gère tout, de la récupération des pages à l’enregistrement des fichiers en masse ().
Qui utilise les extracteurs d’images Python ? Franchement, tout le monde qui a besoin de récupérer plein d’images vite fait :
- Équipes e-commerce : Télécharger les photos produits des fournisseurs pour monter des catalogues.
- Marketeurs : Récupérer des images des réseaux sociaux pour des campagnes ou analyser les tendances.
- Chercheurs : Constituer des jeux de données pour des projets IA/ML ou des études.
- Agents immobiliers : Rassembler des photos de biens pour les annonces ou l’analyse du marché.
Imagine un extracteur d’images Python comme un assistant digital qui ne fatigue jamais—il ne s’arrête pas et ne se laisse pas distraire par les vidéos de chats.
Pourquoi Utiliser Python pour Extraire des Images ?
 Python, c’est le couteau suisse de l’extraction web. Voilà pourquoi il cartonne pour récupérer des images :
Python, c’est le couteau suisse de l’extraction web. Voilà pourquoi il cartonne pour récupérer des images :
- Énorme choix de bibliothèques : Requests, BeautifulSoup, Selenium… tu peux tout faire, du site statique à la page blindée de JavaScript ().
- Facile à prendre en main : La syntaxe est claire, et il y a des tutos partout.
- Flexible et évolutif : Tu peux extraire une page ou des milliers, automatiser les téléchargements, et même traiter les images après.
- Un vrai gain de temps et d’argent : Un test a montré que récupérer 100 images avec Python prend 12 minutes, contre 2 heures à la main ().
Petit aperçu des usages pros :
| Cas d'usage | Problème manuel | Avantage de l'extracteur Python |
|---|---|---|
| Création de catalogue | Heures de copier-coller | Télécharger des milliers d’images en quelques minutes |
| Analyse concurrentielle | Détails manqués, lent | Comparer en masse les images côte à côte |
| Recherche de tendances | Jeux de données incomplets | Rassembler de grands échantillons variés |
| Constitution de jeux IA/ML | Étiquetage fastidieux | Automatiser la collecte et la préparation |
| Annonces immobilières | Données dispersées, obsolètes | Centraliser et mettre à jour facilement les photos |
Les Outils Incontournables pour Extraire des Images avec Python
Voici les outils Python à connaître pour extraire des images :
| Bibliothèque | Fonction principale | Idéal pour | Avantages | Inconvénients |
|---|---|---|---|---|
| Requests | Récupère pages web et images via HTTP | Sites statiques | Simple, rapide | Pas d’analyse HTML, pas de JS |
| BeautifulSoup | Analyse le HTML pour trouver les balises <img> | Extraire les URLs d’images | Facile à utiliser, tolérant | Ne gère pas le JS |
| Scrapy | Framework complet de scraping/crawling | Projets à grande échelle | Asynchrone, export intégré | Courbe d’apprentissage plus raide |
| Selenium | Automatise le navigateur (gère JS, scroll) | Sites dynamiques/JS | Exécute le JS, simule l’utilisateur | Plus lent, configuration plus lourde |
| Pillow (PIL) | Traite les images après téléchargement | Vérification/édition d’images | Redimensionner, convertir, vérifier | Pas pour l’extraction elle-même |
Quand utiliser quoi ?
- Pour la plupart des sites statiques :
requests + BeautifulSoupfont le job. - Pour les sites dynamiques (scroll infini, galeries JS) :
Seleniumest ton allié. - Pour les gros projets récurrents :
Scrapyapporte structure et rapidité. - Pour le traitement d’images :
Pillowte permet de nettoyer après la collecte.
Tutoriel : Télécharger des Images d’un Site Web avec Python
On passe à la pratique ! Voici comment utiliser Python pour télécharger des images depuis un site statique.
Préparer ton environnement Python
Vérifie que tu as Python 3. Crée un environnement virtuel (optionnel mais conseillé) :
1python3 -m venv venv
2source venv/bin/activate # Sous Windows : venv\Scripts\activateInstalle les bibliothèques nécessaires :
1pip install requests beautifulsoup4Repérer et Extraire les URLs d’Images
Ouvre le site cible dans ton navigateur. Clique droit puis « Inspecter » pour repérer les balises <img>—c’est ce qu’on vise.
Exemple de script pour récupérer et analyser les URLs d’images :
1import requests
2from bs4 import BeautifulSoup
3from urllib.parse import urljoin
4import os
5url = "https://example.com"
6response = requests.get(url)
7soup = BeautifulSoup(response.text, "html.parser")
8img_tags = soup.find_all("img")
9img_urls = [urljoin(url, img.get("src")) for img in img_tags if img.get("src")]Astuce : Certains sites utilisent data-src ou srcset pour charger les images en différé. Pense à vérifier ces attributs aussi.
Télécharger et Enregistrer les Images
On enregistre maintenant ces images dans un dossier :
1os.makedirs("images", exist_ok=True)
2for i, img_url in enumerate(img_urls):
3 try:
4 img_resp = requests.get(img_url, headers={"User-Agent": "Mozilla/5.0"})
5 if img_resp.status_code == 200:
6 file_ext = img_url.split('.')[-1].split('?')[0]
7 file_name = f"images/img_{i}.{file_ext}"
8 with open(file_name, "wb") as f:
9 f.write(img_resp.content)
10 print(f"Downloaded {file_name}")
11 except Exception as e:
12 print(f"Failed to download {img_url}: {e}")Conseils d’organisation :
- Nomme les fichiers selon les IDs produits ou titres de page si tu peux.
- Utilise des sous-dossiers pour différentes catégories ou sources.
- Vérifie les doublons avant d’enregistrer (compare les URLs ou utilise des empreintes).
Erreurs Fréquentes et Dépannage
- Images manquantes ? Elles sont peut-être chargées via JavaScript—regarde la section suivante.
- Requêtes bloquées ? Ajoute un User-Agent réaliste et des pauses (
time.sleep()) entre les téléchargements. - Doublons ? Garde une liste des URLs ou noms de fichiers déjà vus.
- Erreurs de permission ? Vérifie que ton script a le droit d’écrire dans le dossier cible.
Extraire des Images sur des Pages Dynamiques ou JavaScript
Certains sites aiment compliquer la vie : images chargées en JavaScript, scroll infini, boutons « charger plus »… Voilà comment t’en sortir avec Selenium.
Utiliser Selenium pour le Contenu Dynamique
Commence par installer Selenium et un driver de navigateur (ex : ChromeDriver) :
1pip install seleniumTélécharge et ajoute-le à ton PATH.
Exemple de script Selenium :
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3import time
4import os
5driver = webdriver.Chrome()
6driver.get("https://example.com/gallery")
7# Faire défiler jusqu’en bas pour charger plus d’images
8last_height = driver.execute_script("return document.body.scrollHeight")
9while True:
10 driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
11 time.sleep(2) # Attendre le chargement des images
12 new_height = driver.execute_script("return document.body.scrollHeight")
13 if new_height == last_height:
14 break
15 last_height = new_height
16img_elements = driver.find_elements(By.TAG_NAME, "img")
17img_urls = [img.get_attribute("src") for img in img_elements if img.get_attribute("src")]
18os.makedirs("dynamic_images", exist_ok=True)
19for i, img_url in enumerate(img_urls):
20 # (Logique de téléchargement comme précédemment)
21 pass
22driver.quit()Astuces :
- Utilise
WebDriverWaitpour attendre l’apparition des images. - Pour les sites où il faut cliquer pour afficher les images, utilise
element.click().
Alternatives : Des outils comme Playwright (bindings Python) sont parfois plus rapides et fiables pour les sites costauds ().
Alternative No-Code : Extraire les Images d’un Site avec Thunderbit
Tout le monde n’a pas envie de coder ou de bidouiller des navigateurs. C’est là que entre en scène : une extension Chrome d’extraction web IA, sans code, qui rend la collecte d’images aussi simple qu’une commande à emporter.
Comment Extraire des Images avec Thunderbit
- Installe Thunderbit : Ajoute l’.
- Ouvre ton site cible : Va sur la page avec les images à extraire.
- Lance Thunderbit : Clique sur l’icône de l’extension pour ouvrir la barre latérale.
- AI Suggest Fields : Clique sur « AI Suggest Fields »—l’IA de Thunderbit analyse la page et repère automatiquement les images, créant une colonne « Image » pour toi ().
- Lance l’extraction : Clique sur « Scrape ». Thunderbit collecte toutes les images, même sur les sous-pages ou avec scroll infini.
- Exporte : Télécharge les URLs ou fichiers images direct vers Excel, Google Sheets, Notion, Airtable ou CSV—sans frais cachés, même avec la version gratuite.
Bonus : L’Extracteur d’Images gratuit de Thunderbit peut récupérer toutes les URLs d’images d’une page en un seul clic ().
Pourquoi Thunderbit, c’est canon :
- Pas besoin de coder ou de connaître le HTML.
- Gère tout seul le contenu dynamique, les sous-pages et la pagination.
- Export instantané et illimité (même en version gratuite).
- L’IA s’adapte aux changements de site—fini la maintenance galère.
Combiner Python et Thunderbit : Le Duo Gagnant
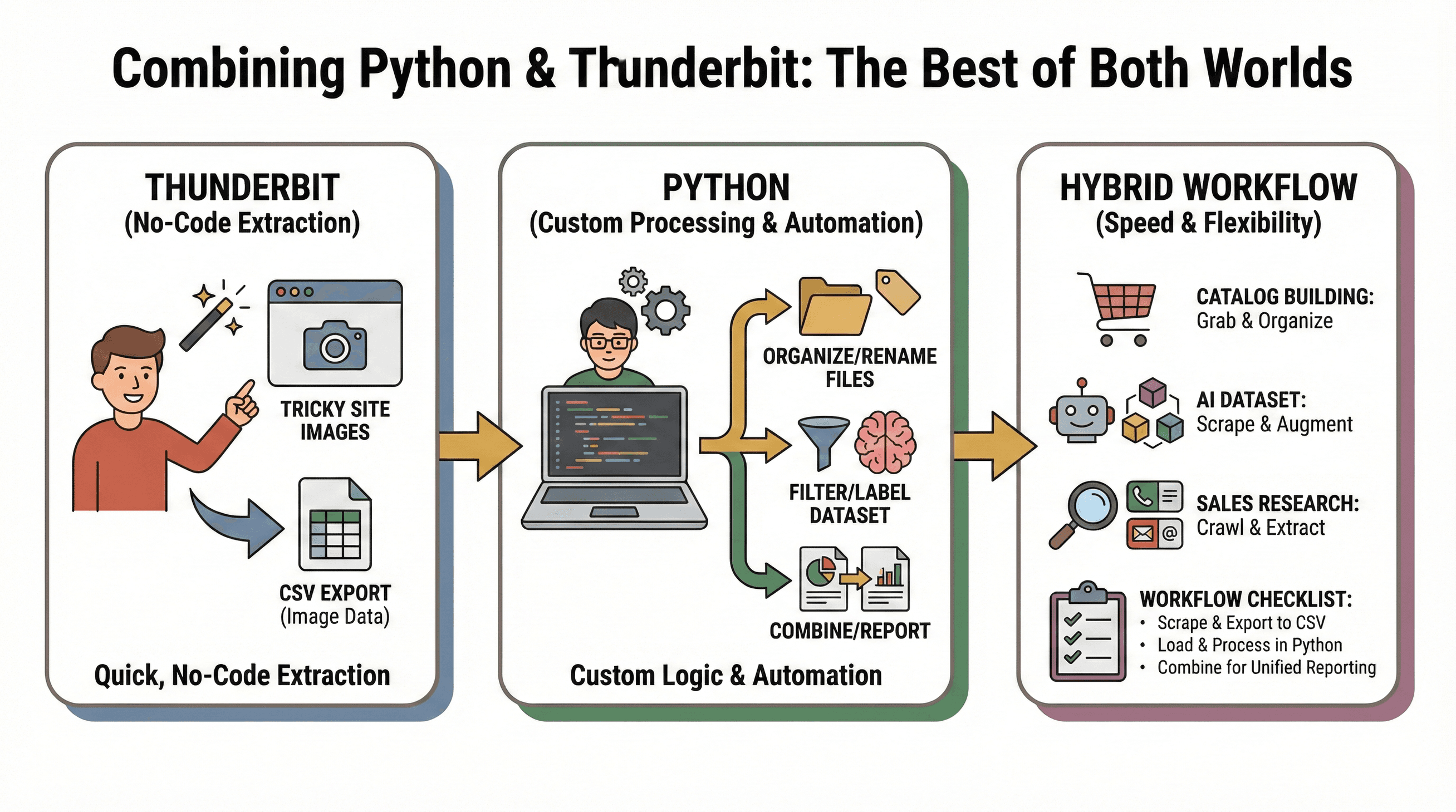 Mon combo préféré : Thunderbit pour extraire vite et sans code, puis Python pour trier ou automatiser à ta sauce.
Mon combo préféré : Thunderbit pour extraire vite et sans code, puis Python pour trier ou automatiser à ta sauce.
Exemples de scénarios :
- Création de catalogue : Thunderbit récupère les images d’un site complexe, puis Python les trie, renomme ou traite les fichiers.
- Constitution de jeux de données IA : Thunderbit extrait les images de plusieurs sources ; des scripts Python filtrent, étiquettent ou enrichissent le jeu de données.
- Veille commerciale : Python parcourt une liste d’URLs d’entreprises ; Thunderbit extrait images, emails ou numéros de téléphone de chaque site.
Checklist workflow :
- Utilise Thunderbit pour extraire les images et exporter en CSV.
- Charge le CSV dans Python pour analyse ou automatisation avancée.
- Combine les données de plusieurs sources pour un reporting unifié.
Cette approche hybride te donne rapidité, flexibilité et la capacité de relever tous les défis d’extraction d’images web.
Conseils et Bonnes Pratiques pour l’Extraction d’Images avec Python
Problèmes fréquents :
- Requêtes bloquées : Ajoute un User-Agent, des pauses, et respecte le
robots.txt. - Images manquantes : Vérifie si le contenu est chargé en JS—utilise Selenium ou Thunderbit.
- Doublons : Garde la trace des URLs déjà vues ou utilise des empreintes de fichiers.
- Fichiers corrompus : Utilise Pillow pour vérifier les images après téléchargement.
Bonnes pratiques :
- Range les images dans des dossiers clairs (par site, catégorie ou date).
- Utilise des noms de fichiers explicites (ID produit, titre de page).
- Filtre les images inutiles (pubs, icônes) en vérifiant la taille ou les dimensions.
- Vérifie toujours les droits d’auteur et les conditions d’utilisation avant d’extraire des images ().
Comparatif des Solutions d’Extraction d’Images Python : Code vs No-Code
Petit tableau comparatif pour t’aider à choisir :
| Critère | Python (Requests/BS) | Selenium (Python) | Thunderbit (No-Code) |
|---|---|---|---|
| Facilité d’utilisation | Moyenne (nécessite du code) | Plus complexe (code + automatisation navigateur) | Ultra simple (point & click, IA) |
| Contenu dynamique | Non | Oui | Oui |
| Temps de mise en place | Long (installation, code) | Long (drivers, code) | Très court (installer l’extension) |
| Scalabilité | Manuel (peut être parallélisé) | Lent (navigateur lourd) | Élevée (cloud, 50 pages à la fois) |
| Maintenance | Élevée (scripts fragiles si le site change) | Élevée | Faible (IA s’adapte automatiquement) |
| Options d’export | Personnalisé (CSV, BDD) | Personnalisé | Export instantané vers Excel, Sheets, Notion, etc. |
| Coût | Gratuit (open source) | Gratuit | Gratuit pour un usage modéré, payant pour gros volumes |
En résumé : Si tu aimes coder et tout contrôler, Python est imbattable. Pour la rapidité, la simplicité et les sites dynamiques, Thunderbit est un super allié. La plupart des équipes gagnent à mixer les deux.
Conclusion & Points Clés à Retenir
Le web déborde d’images, et les données visuelles sont plus précieuses—et plus galère à gérer—que jamais. Les extracteurs d’images Python offrent puissance et flexibilité pour automatiser les téléchargements, tandis que des outils no-code comme Thunderbit rendent l’extraction accessible à tous.
À retenir :
- Utilise Python (Requests + BeautifulSoup) pour les sites statiques et les workflows sur-mesure.
- Utilise Selenium pour les pages dynamiques et les sites JavaScript.
- Utilise Thunderbit pour une extraction rapide et sans code—parfait pour les sites coriaces ou pour exporter direct vers Excel, Google Sheets ou Notion.
- Combine les deux pour un workflow optimal : Thunderbit pour la collecte, Python pour le traitement et l’automatisation.
Prêt à passer à la vitesse supérieure ? Tente un petit script Python, ou et vois le temps que tu gagnes. Pour plus d’astuces et de tutos, va faire un tour sur le et le .
Bonne chasse aux images—et que tes dossiers restent toujours bien rangés !
FAQ
1. C’est quoi un extracteur d’images Python ?
C’est un script ou un outil qui va automatiquement sur les sites web, repère les fichiers image (souvent dans les balises <img>) et les télécharge sur ton ordi. Plus besoin de sauvegarder chaque image à la main.
2. Quelles sont les meilleures bibliothèques Python pour extraire des images ?
Les plus populaires sont Requests (pour récupérer les pages web), BeautifulSoup (pour analyser le HTML), Selenium (pour le contenu dynamique) et Pillow (pour traiter les images après téléchargement).
3. Comment extraire des images sur des sites avec beaucoup de JavaScript ou du scroll infini ?
Utilise Selenium pour automatiser un navigateur, faire défiler la page et extraire les URLs d’images une fois tout chargé. Thunderbit gère aussi le contenu dynamique grâce à son IA.
4. Existe-t-il une solution sans code pour extraire les images d’un site ?
Oui ! Thunderbit est une extension Chrome no-code qui utilise l’IA pour détecter et extraire les images de n’importe quel site. Il suffit de pointer, cliquer et exporter vers Excel, Google Sheets, Notion ou Airtable.
5. Peut-on combiner Python et Thunderbit pour l’extraction d’images ?
Carrément. Utilise Thunderbit pour une extraction rapide et sans code, puis Python pour le traitement avancé ou l’automatisation. Exporte les données de Thunderbit et continue le traitement avec des scripts Python pour profiter du meilleur des deux mondes.
En savoir plus