

Soyons francs : personne ne se réveille le matin en se disant qu’il a hâte de copier-coller 500 lignes de prix produits dans un tableur. (Si c’est votre cas, je salue votre endurance et je vous conseille une bonne attelle de poignet.) Que vous travailliez dans la vente, les opérations ou que vous cherchiez simplement à garder une longueur d’avance sur la concurrence, vous avez sans doute déjà fait face à la galère de l’extraction de données depuis des sites web. Aujourd’hui, tout tourne autour des données web, et la demande d’extraction automatisée explose : le marché des logiciels d’extraction web devrait dépasser 11 milliards de dollars d’ici 2032.
J’ai passé des années dans les tranchées du SaaS et de l’automatisation, et j’ai tout vu : des macros Excel héroïques aux scripts Python bricolés à la va-vite à 2 heures du matin. Dans ce guide, je vais vous montrer comment utiliser un analyseur HTML Python pour extraire des données concrètes du monde réel (oui, nous allons récupérer ensemble les notes des films IMDb), et je vous montrerai aussi pourquoi, en 2026, il existe une meilleure approche : des outils propulsés par l’IA comme Thunderbit, qui vous permettent de vous passer du code pour aller directement à l’essentiel : les analyses.
Qu’est-ce qu’un analyseur HTML et pourquoi en utiliser un en Python ?
Commençons par le début : que fait vraiment un analyseur HTML ? Voyez-le comme votre bibliothécaire personnel pour le web. Il lit le code HTML brouillon d’une page et l’organise en une structure propre, en forme d’arbre. Vous pouvez ainsi extraire uniquement les données dont vous avez besoin — titres, prix, liens — sans vous perdre dans une mer de balises et de div.
Python est le langage de référence pour ce travail, et pour de bonnes raisons. Il est lisible, facile à prendre en main et dispose d’un immense écosystème de bibliothèques pour l’extraction et l’analyse de données web. En fait, Python est de loin le langage le plus utilisé pour l’extraction web, grâce à sa courbe d’apprentissage douce et à la force de sa communauté.
La palette des analyseurs HTML Python
Voici les principaux outils que vous rencontrerez pour analyser du HTML en Python :
- BeautifulSoup : le grand classique, idéal pour débuter. Toujours maintenu activement —
beautifulsoup44.14.3 a été publié sur PyPI fin 2025 — donc ce guide ne vous dirige pas vers une bibliothèque obsolète. - lxml : rapide et puissant, avec des requêtes avancées.
- html5lib : très tolérant face au HTML mal formé, un peu comme votre navigateur.
- PyQuery : permet d’utiliser des sélecteurs à la jQuery en Python.
- HTMLParser : l’analyseur intégré à Python — toujours là, mais un peu minimaliste.
Chacun a ses particularités, mais ils vous aident tous à transformer du HTML brut en données structurées.
Cas d’usage clés : comment les entreprises tirent parti des analyseurs HTML Python
L’extraction de données web ne concerne pas seulement les techniciens ou les data scientists. C’est devenue une activité métier essentielle, en particulier dans la vente et les opérations. Voici pourquoi :
| Cas d’usage (secteur) | Données généralement extraites | Résultat métier |
|---|---|---|
| Suivi des prix (retail) | Prix concurrents, niveaux de stock | Tarification dynamique, marges améliorées (source) |
| Veille produit concurrentielle | Annonces, avis, disponibilité | Identifier les manques, générer des leads (source) |
| Génération de leads (vente B2B) | Noms d’entreprises, e-mails, contacts | Prospection automatisée, croissance du pipeline (source) |
| Sentiment du marché (marketing) | Publications sociales, avis, notes | Retours en temps réel, détection des tendances (source) |
| Agrégation immobilière | Annonces, prix, infos des agents | Analyse de marché, stratégie tarifaire (source) |
| Intelligence recrutement | Profils de candidats, salaires | Sourcing de talents, benchmarking salarial (source) |
En bref : si vous copiez encore des données à la main, vous laissez du temps et de l’argent sur la table.
Découverte de la boîte à outils des analyseurs HTML Python : comparaison des bibliothèques populaires
Passons à la pratique. Voici une comparaison rapide des bibliothèques d’analyse HTML Python les plus populaires, pour vous aider à choisir l’outil adapté à votre besoin :
| Bibliothèque | Facilité d’utilisation | Vitesse | Flexibilité | Besoin de maintenance | Idéal pour |
|---|---|---|---|---|---|
| BeautifulSoup | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ | Modéré | Débutants, HTML sale |
| lxml | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Modéré | Vitesse, XPath, gros documents |
| html5lib | ⭐⭐⭐ | ⭐ | ⭐⭐⭐⭐⭐ | Faible | Analyse proche du navigateur, HTML cassé |
| PyQuery | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | Modéré | Fans de jQuery, sélecteurs CSS |
| HTMLParser | ⭐⭐⭐ | ⭐⭐⭐ | ⭐ | Faible | Tâches simples, intégré au langage |
BeautifulSoup : le choix idéal pour débuter
BeautifulSoup, c’est le « hello world » de l’analyse HTML. Sa syntaxe est intuitive, la documentation est excellente, et il pardonne très bien le HTML moche ou mal formé (voir plus). Son inconvénient ? Il n’est pas le plus rapide, surtout sur des pages volumineuses ou complexes, et il ne prend pas en charge nativement des sélecteurs avancés comme XPath.
lxml : rapide et puissant
Si vous avez besoin de vitesse ou souhaitez utiliser des requêtes XPath, lxml est votre allié (détails). Il repose sur des bibliothèques C, ce qui le rend extrêmement rapide, mais son installation peut être un peu plus délicate et sa prise en main plus exigeante.
Autres options : html5lib, PyQuery et HTMLParser
- html5lib : analyse le HTML comme votre navigateur — parfait pour le balisage cassé ou bizarre, mais lent (comparaison).
- PyQuery : vous permet d’utiliser des sélecteurs à la jQuery en Python, pratique si vous venez du front-end (voir la documentation).
- HTMLParser : l’option intégrée à Python — rapide et toujours disponible, mais moins riche en fonctionnalités.
Étape 1 : configurer votre environnement d’analyse HTML Python
Avant d’analyser quoi que ce soit, vous devez configurer votre environnement Python. Voici comment faire :
-
Installez Python : téléchargez-le sur python.org si ce n’est pas déjà fait.
-
Installez pip : il est généralement inclus à partir de Python 3.4+, mais vous pouvez vérifier en lançant
pip --versiondans votre terminal. -
Installez les bibliothèques (utilisons BeautifulSoup et requests pour ce tutoriel) :
pip install beautifulsoup4 requests lxmlbeautifulsoup4est l’analyseur.requestsvous permet de récupérer des pages web.lxmlest un analyseur rapide que BeautifulSoup peut utiliser en interne.
-
Vérifiez l’installation :
python -c "import bs4, requests, lxml; print('Tout est bon !')"
Conseils de dépannage :
- Si vous obtenez des erreurs d’autorisation, essayez
pip install --user ... - Sur Mac/Linux, vous aurez peut-être besoin de
python3etpip3à la place. - Si vous voyez « ModuleNotFoundError », vérifiez l’orthographe et votre environnement Python.
Étape 2 : analyser votre première page web avec Python
Mettez les mains dans le cambouis et extrayons les 250 meilleurs films IMDb. Nous allons récupérer les titres, les années et les notes.
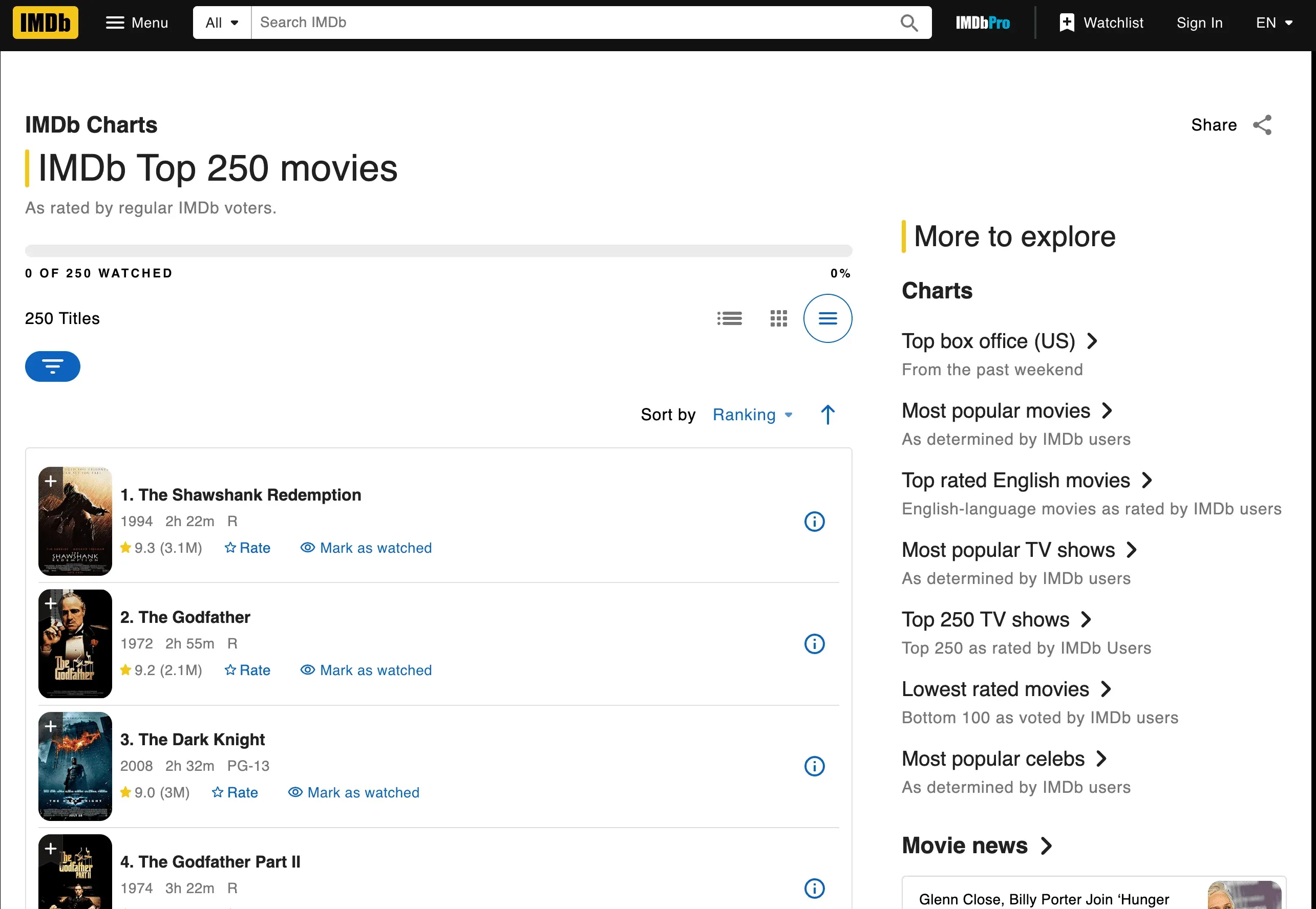
Récupérer et analyser la page
Voici un script pas à pas. Petite précision avant de le copier : IMDb a refondu la page Top 250 en juin 2023, donc les anciens sélecteurs td.titleColumn / td.ratingColumn que vous verrez encore dans de vieux tutoriels ne correspondent plus à rien. Le balisage actuel utilise des classes préfixées par ipc- générées par leur système de composants, et IMDb a reconfiguré la page plusieurs fois depuis (notamment mi-2025), donc prévoyez de réinspecter avec les DevTools à chaque retour sur cet exemple.
import requests
from bs4 import BeautifulSoup
url = "https://www.imdb.com/chart/top/"
headers = {"User-Agent": "Mozilla/5.0"} # IMDb renvoie un balisage réduit sans vrai User-Agent
resp = requests.get(url, headers=headers)
soup = BeautifulSoup(resp.text, "html.parser")
# Chaque ligne est un élément de liste dans le conteneur du classement
rows = soup.select("li.ipc-metadata-list-summary-item")
for i, row in enumerate(rows[:3], start=1):
title_el = row.select_one("h3.ipc-title__text")
year_el = row.select_one("span.cli-title-metadata-item")
rating_el = row.select_one("span.ipc-rating-star--rating")
title = title_el.get_text(strip=True) if title_el else None
# Le texte du h3 revient sous la forme « 1. The Shawshank Redemption » — on retire le préfixe du rang
if title and ". " in title:
title = title.split(". ", 1)[1]
year = year_el.get_text(strip=True) if year_el else None
rating = rating_el.get_text(strip=True) if rating_el else None
print(f"{i}. {title} ({year}) -- Note : {rating}")
Que se passe-t-il ici ?
- Nous utilisons
requests.get()pour récupérer la page (avec unUser-Agentcrédible — IMDb sert parfois une version très réduite aux clientspython-requestssans navigateur réel). BeautifulSoupanalyse le HTML.- Nous récupérons chaque ligne de film via
li.ipc-metadata-list-summary-item, puis nous extrayons le titre (h3.ipc-title__text), l’année (span.cli-title-metadata-item) et la note (span.ipc-rating-star--rating) avecselect_one(). - Nous récupérons le texte du titre, de l’année et de la note, en supprimant le numéro de rang initial (
"1. ") intégré au texte du titre par IMDb.
Si vous voulez quelque chose de plus robuste que de courir après des changements de noms de classes tous les quelques mois, IMDb fournit aussi un bloc <script type="application/ld+json"> sur la même page avec les mêmes données au format structuré — vous pouvez l’analyser avec json.loads(soup.find("script", type="application/ld+json").string) et parcourir le tableau itemListElement. C’est l’approche que je privilégierais en production ; la version avec sélecteurs CSS ci-dessus est plus simple à expliquer, mais aussi plus fragile.
Résultat :
1. The Shawshank Redemption (1994) -- Note : 9.3
2. The Godfather (1972) -- Note : 9.2
3. The Dark Knight (2008) -- Note : 9.0
Extraire des données : trouver les titres, les notes et plus encore
Comment ai-je su quelles balises et quelles classes utiliser ? J’ai inspecté le code HTML de la page IMDb (clic droit > Inspecter dans votre navigateur). Cherchez des motifs — ici, chaque ligne de film se trouve dans un <li class="ipc-metadata-list-summary-item">, avec le titre dans <h3 class="ipc-title__text"> et la note dans <span class="ipc-rating-star--rating">. Un point important à retenir : IMDb a modifié ce balisage plus d’une fois (la mise en page td.titleColumn qu’on trouve encore dans certains guides ne fonctionne plus depuis la refonte de juin 2023), donc traitez toujours ces chaînes de classes comme illustratives et réinspectez la page avant d’exécuter le script.
Astuce pro : si vous extrayez des données d’un autre site, commencez toujours par inspecter la structure HTML et identifier des noms de classes ou des balises uniques.
Enregistrer et exporter vos résultats
Enregistrons nos données dans un fichier CSV :
import csv
movies = []
for i in range(len(title_cells)):
title_cell = title_cells[i]
rating_cell = rating_cells[i]
title = title_cell.a.text
year = title_cell.span.text.strip("()")
rating = rating_cell.strong.text if rating_cell.strong else rating_cell.text
movies.append([title, year, rating])
with open('imdb_top250.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['Title', 'Year', 'Rating'])
writer.writerows(movies)
Conseils de nettoyage :
- Utilisez
.strip()pour supprimer les espaces inutiles. - Gérez les données manquantes avec des vérifications
if. - Pour exporter vers Excel, vous pouvez ouvrir le CSV dans Excel ou utiliser
pandaspour écrire des fichiers.xlsx.
Étape 3 : gérer les changements HTML et les défis de maintenance
Ici, les choses deviennent sérieuses. Les sites web adorent modifier leur mise en page — parfois juste pour mettre les extracteurs à l’épreuve (du moins, c’est l’impression que l’on a). Si IMDb remplace class="titleColumn" par class="movieTitle", votre script renverra soudainement des résultats vides. Vécu, débogué, réglé.
Quand les scripts cassent : les problèmes du monde réel
Problèmes fréquents :
- Sélecteurs introuvables : votre code ne trouve pas la balise ou la classe indiquée.
- Résultats vides : la structure de la page a changé, ou le contenu se charge désormais via JavaScript.
- Erreurs HTTP : le site a ajouté des protections anti-bot.
Étapes de dépannage :
- Vérifiez que le HTML que vous analysez correspond bien à ce que vous voyez dans votre navigateur.
- Mettez à jour vos sélecteurs pour qu’ils correspondent à la nouvelle structure.
- Si le contenu se charge de manière dynamique, vous devrez peut-être passer à un outil d’automatisation du navigateur (comme Selenium) ou trouver un point de terminaison d’API.
Le vrai casse-tête ? Si vous extrayez des données sur 10, 50 ou 500 sites différents, vous passerez peut-être plus de temps à corriger vos scripts qu’à analyser les données (voir des retours de développeurs).
Étape 4 : passer à l’échelle — les coûts cachés de l’analyse HTML Python manuelle
Supposons que vous vouliez extraire non seulement IMDb, mais aussi Amazon, Zillow, LinkedIn et une douzaine d’autres sites. Chacun nécessite son propre script. Et à chaque changement de site, vous retournez dans l’éditeur de code.
Les coûts cachés :
- Travail de maintenance : certains estiment que la maintenance coûte 10 fois le coût initial de développement.
- Infrastructure : il vous faudra des proxys, de la gestion d’erreurs et du monitoring.
- Performance : monter en charge implique de gérer la concurrence, les limites de requêtes et davantage encore.
- Assurance qualité : plus de scripts = plus d’endroits où quelque chose peut casser.
Pour les équipes non techniques, cela devient très vite intenable. C’est comme embaucher une équipe de stagiaires pour copier-coller des données toute la journée — sauf que les stagiaires sont des scripts Python, et qu’ils se déclarent malades à chaque changement de site.
Petite note sur les agents de codage IA
Avant d’arriver aux outils no-code, il vaut la peine de mentionner une voie intermédiaire qui n’existait pas vraiment à l’époque où la plupart des tutoriels « apprenez BeautifulSoup » ont été écrits : les agents de codage IA. Des outils comme Claude Code ou Cursor peuvent très bien prendre une description en anglais (« fetch IMDb’s Top 250, pull title / year / rating into a CSV ») et vous rédiger d’un coup un script requests + BeautifulSoup fonctionnel, y compris le nettoyage des sélecteurs que nous venons de faire à la main. Pour les parcours navigateur en langage naturel — connexion, pagination, gestion des bannières de cookies — une bibliothèque comme Browser Use peut piloter un navigateur sans interface graphique directement à partir d’une invite.
Mais ils ne font pas disparaître les difficultés. Les limites de requêtes, robots.txt, les pages de connexion et les défenses anti-bot restent votre problème, et lorsqu’un sélecteur casse silencieusement (comme ce fut le cas sur IMDb), vous devez encore comprendre ce que l’agent a généré et corriger le script. Donc, même avec un agent dans la boucle, comprendre le flux de travail de l’analyse HTML présenté dans ce tutoriel est ce qui vous permet de déboguer la sortie au lieu de fixer des listes vides.
Au-delà des analyseurs HTML Python : découvrez Thunderbit, l’alternative propulsée par l’IA
Et maintenant, voici la partie la plus excitante. Et si vous pouviez vous passer du code, vous passer de la maintenance, et obtenir simplement les données dont vous avez besoin — quelle que soit l’évolution du site ?
C’est exactement ce que nous avons construit avec Thunderbit. C’est une extension Chrome d’extracteur Web IA qui vous permet d’extraire des données structurées depuis n’importe quel site en deux clics. Pas de Python, pas de scripts, pas de casse-tête.
Analyseurs HTML Python vs Thunderbit : comparaison côte à côte
| Aspect | Analyseurs HTML Python | Thunderbit (voir les tarifs) |
|---|---|---|
| Temps de configuration | Élevé (installation, code, débogage) | Faible (installer l’extension, cliquer) |
| Facilité d’utilisation | Nécessite du code | Sans code — pointer et cliquer |
| Maintenance | Élevée (les scripts cassent souvent) | Faible (l’IA s’adapte automatiquement) |
| Passage à l’échelle | Complexe (scripts, proxys, infrastructure) | Intégré (extraction cloud, traitements par lots) |
| Enrichissement des données | Manuel (écrire plus de code) | Intégré (étiquetage, nettoyage, traduction, sous-pages) |
Pourquoi construire quand l’IA peut résoudre le problème à votre place ?
Pourquoi choisir l’IA pour l’extraction de données web ?
L’agent IA de Thunderbit lit la page, comprend sa structure et s’adapte quand les choses changent. C’est comme avoir un super stagiaire qui ne dort jamais et ne se plaint jamais quand les noms de classes changent.
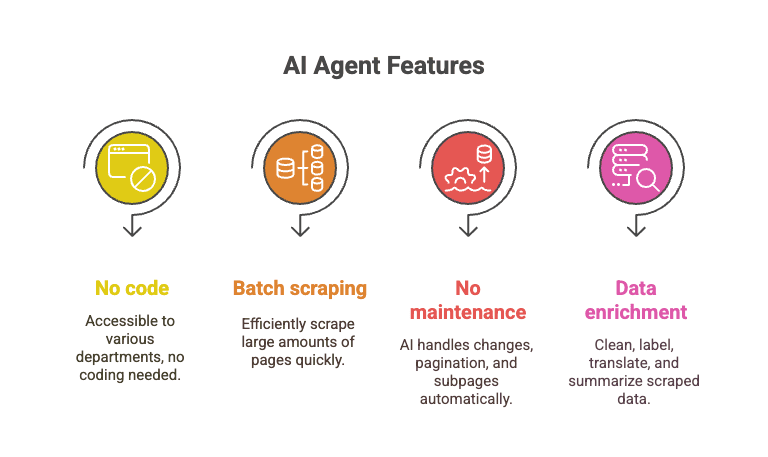
- Aucun code requis : tout le monde peut l’utiliser — ventes, opérations, marketing, et bien plus.
- Extraction par lots : extrayez plus de 10 000 pages dans le temps qu’il vous faudrait pour déboguer un seul script Python.
- Aucune maintenance : l’IA gère les changements de mise en page, la pagination, les sous-pages, et plus encore.
- Enrichissement des données : nettoyez, étiquetez, traduisez et résumez les données pendant l’extraction.
Le revers de la médaille du flux BeautifulSoup que nous venons de parcourir, c’est exactement la fragilité que nous avons rencontrée avec les sélecteurs IMDb ci-dessus : lorsque la page change d’organisation, le script renvoie silencieusement des résultats vides, et vous passez l’après-midi dans les DevTools au lieu d’analyser les données. Un extracteur IA no-code masque cette étape derrière sa propre couche d’inférence ; c’est un vrai compromis (vous faites confiance au fait que l’extraction soit correcte), pas une baguette magique.
Étape par étape : extraire les notes des films IMDb avec Thunderbit
Voyons comment Thunderbit gère la même tâche sur IMDb :
- Installez l’extension Chrome Thunderbit.
- Accédez à la page Top 250 d’IMDb.
- Cliquez sur l’icône Thunderbit.
- Cliquez sur « AI Suggest Fields ». Thunderbit lira la page et recommandera des colonnes (Titre, Année, Note).
- Vérifiez ou ajustez les colonnes si nécessaire.
- Cliquez sur « Scrape ». Thunderbit extraira instantanément les 250 lignes.
- Exportez vers Excel, Google Sheets, Notion ou CSV — à vous de choisir.
C’est tout. Pas de code, pas de débogage, pas de moment de panique du genre « pourquoi cette liste est-elle vide ? ».
Vous voulez le voir en action ? Consultez la chaîne YouTube Thunderbit pour des démonstrations, ou lisez notre guide pas à pas pour extraire des produits Amazon pour un autre exemple concret.
Conclusion : choisir le bon outil pour vos besoins en données web
Les analyseurs HTML Python comme BeautifulSoup et lxml sont puissants, flexibles et gratuits. Ils conviennent parfaitement aux développeurs qui veulent garder un contrôle total et ne craignent pas de retrousser leurs manches. Mais ils s’accompagnent d’une courbe d’apprentissage abrupte, d’une maintenance continue et de coûts cachés — surtout à mesure que vos besoins d’extraction augmentent.
Pour les utilisateurs métier, les équipes commerciales et toute personne qui veut simplement les données, pas le code, des outils propulsés par l’IA comme Thunderbit sont une vraie bouffée d’air frais. Ils vous permettent d’extraire, nettoyer et enrichir des données web à grande échelle, sans code et sans maintenance.
Mon conseil ? Utilisez Python si vous aimez écrire des scripts et avez besoin d’une personnalisation totale. Mais si vous accordez de la valeur à votre temps — et à votre santé mentale — essayez Thunderbit. Pourquoi construire et surveiller des scripts quand l’IA peut faire tout le travail lourd ?
Vous voulez en savoir plus sur l’extraction web, la collecte de données et l’automatisation par l’IA ? Parcourez davantage de tutoriels sur le blog Thunderbit, comme Comment extraire des données de site web vers Excel avec l’IA ou Les meilleurs outils et logiciels d’extraction web en 2025.




