

Longtemps réservé à quelques initiés, le web scraping s’est imposé comme un réflexe dès qu’on touche à la vente, aux opérations ou à l’analyse de marché. Entre 2019 et 2023, le volume mondial de données a bondi de près de 193 % ; on comprend, dès lors, que 81 % des entreprises fassent de la donnée le socle de leurs arbitrages. Le revers tient en un chiffre : pour 95 % des organisations, traiter des données non structurées — un HTML chaotique, par exemple — relève du casse-tête. Trop d’équipes s’épuisent encore à recopier à la main des informations glanées sur le web.
Extraire des données de n’importe quel site web grâce à l’IA Get Started Free
BeautifulSoup répond précisément à ce besoin. Ce tutoriel pratique vous en donne le mode d’emploi appliqué au web scraping, autour d’un exemple Python que vous adapterez ensuite à votre contexte métier. Et parce que l’efficacité prime sur l’effort brut, je vous montrerai aussi comment marier BeautifulSoup à Thunderbit, notre extracteur Web IA : de quoi fluidifier votre flux de travail et récupérer des données plus propres et mieux structurées, quel que soit votre niveau en code.
Qu’est-ce que BeautifulSoup et pourquoi l’utiliser pour le web scraping ?
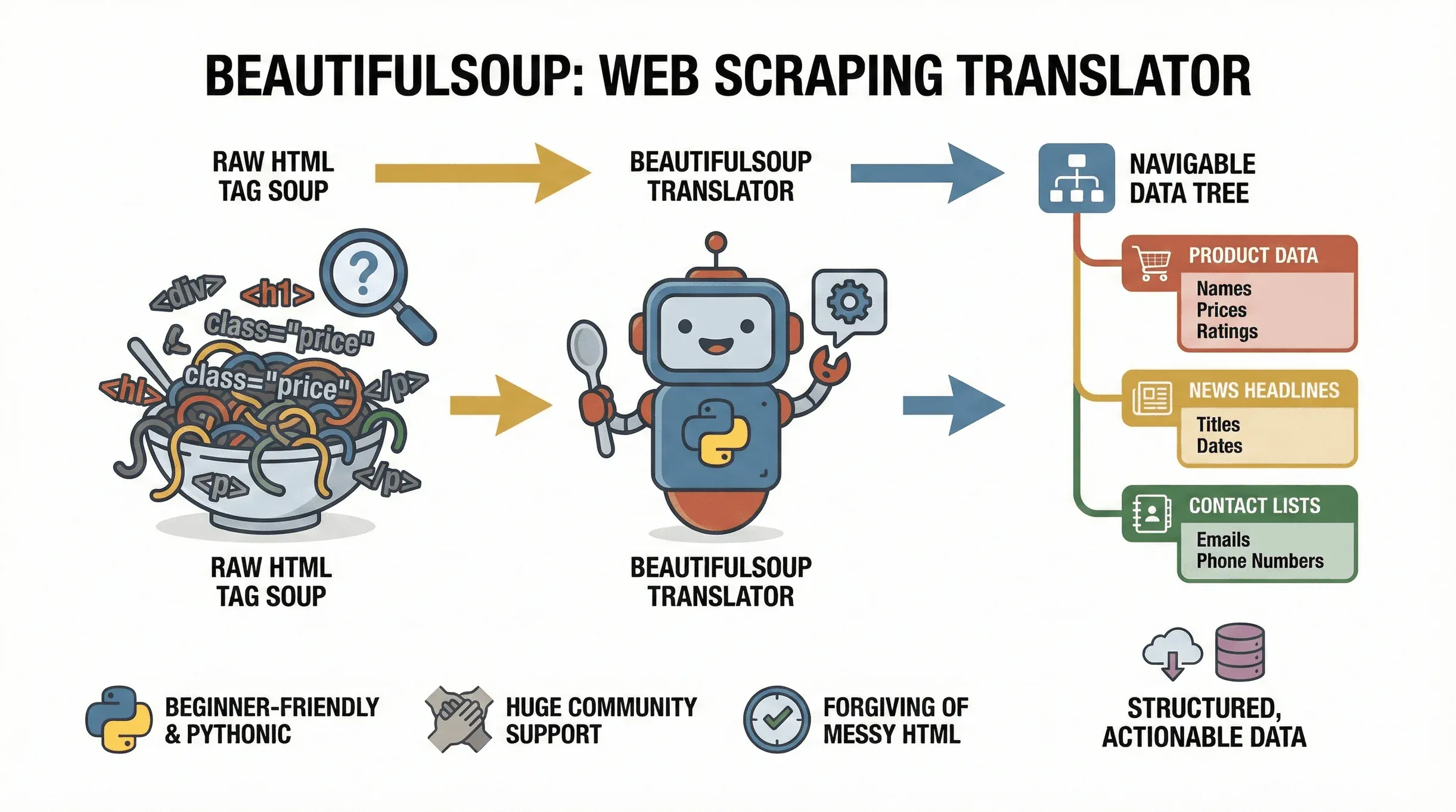 Un peu de contexte pour commencer. BeautifulSoup est une bibliothèque Python dédiée à l’analyse des documents HTML et XML. Son rôle s’apparente à celui d’une interprète : la « soupe de balises » d’une page devient sous ses doigts une arborescence navigable, où trouver, extraire et manipuler les données voulues n’a plus rien de laborieux. Le projet vit toujours — la version 4.14.3 de
Un peu de contexte pour commencer. BeautifulSoup est une bibliothèque Python dédiée à l’analyse des documents HTML et XML. Son rôle s’apparente à celui d’une interprète : la « soupe de balises » d’une page devient sous ses doigts une arborescence navigable, où trouver, extraire et manipuler les données voulues n’a plus rien de laborieux. Le projet vit toujours — la version 4.14.3 de beautifulsoup4 est arrivée sur PyPI fin 2025 —, si bien que tout ce qui suit reste d’actualité. Prix affichés sur une boutique en ligne, gros titres de la presse, annuaires professionnels pour alimenter vos leads : dans chacun de ces cas, c’est vers BeautifulSoup qu’on se tourne pour convertir des pages web en données structurées et exploitables.
Pourquoi un tel engouement ? La facilité d’accès y est pour beaucoup, en particulier pour qui débute. Le HTML mal formé — et le web n’en manque pas — ne l’effraie pas, et sa syntaxe « pythonique » vous conduit du néant au premier scraping en quelques lignes. S’y ajoutent des millions de téléchargements, un support solide et une communauté nombreuse : au moindre blocage, une recherche Google vous remet le plus souvent sur les rails.
Quelques cas d’usage typiques :
- Extraire noms de produits, prix et notes depuis des pages e-commerce
- Récupérer titres d’actualité, auteurs et dates de publication sur des sites d’information
- Analyser des tableaux ou des annuaires (listes d’entreprises ou de contacts)
- Collecter des e-mails ou des numéros de téléphone depuis des sites d’annonces
- Surveiller des mises à jour (changements de prix, nouvelles offres d’emploi, etc.)
Dès lors que vos données vivent dans du HTML statique, BeautifulSoup fera un allié de premier choix.
Les avantages uniques de BeautifulSoup pour le web scraping
Les bibliothèques Python de scraping foisonnent : pourquoi préférer BeautifulSoup ? Quatre atouts le détachent du lot :
- Simplicité : léger et vite assimilé, il vous dispense de déployer tout un framework ou d’empiler du code répétitif. Indiqué pour les tâches rapides et ponctuelles, comme pour les premiers pas.
- Tolérance : un HTML cassé ou approximatif ne lui pose aucun problème, et c’est plus fréquent qu’on ne le croit.
- Flexibilité : aucune architecture de crawl rigide ne vous enferme. Vous lui donnez du HTML, il en ressort ce qu’il vous faut.
- Intégration : il coopère sans heurt avec d’autres bibliothèques Python —
requestspour récupérer les pages,csvpour sauvegarder,pandaspour l’analyse.
Face aux autres outils, comment se situe-t-il ?
| Outil | Idéal pour | Avantages | Inconvénients |
|---|---|---|---|
| BeautifulSoup | Analyse de HTML statique, débutants | Simple, mise en route rapide, tolérant, flexible | Pas adapté aux sites très chargés en JavaScript |
| Scrapy | Tâches à grande échelle, asynchrones | Puissant, scalable, crawl intégré | Courbe d’apprentissage plus raide, plus de configuration |
| Selenium | Contenu JavaScript/dynamique | Interagit avec le JS, remplit des formulaires, clique sur des boutons | Plus lent, plus lourd, plus gourmand en ressources |
Débuter ou analyser vite des pages statiques : sur ce terrain, BeautifulSoup reste le couteau suisse du scraping (medium.com). Les sites complexes ou dynamiques demanderont de lui adjoindre Selenium ou Scrapy ; pour ancrer les fondamentaux, aucune porte d’entrée ne le vaut.
Configuration de votre environnement Python pour BeautifulSoup
On démarre ? Voici comment préparer le terrain.
-
Installez Python : téléchargez la dernière version depuis python.org.
-
Créez un environnement virtuel (facultatif, mais recommandé) :
python -m venv venv source venv/bin/activate # Sous Windows : venv\Scripts\activate -
Installez BeautifulSoup et ses dépendances :
pip install beautifulsoup4 requests lxml html5libbeautifulsoup4: la bibliothèque principalerequests: pour récupérer les pages weblxmlouhtml5lib: des analyseurs HTML plus rapides et/ou plus fiables
-
En cas de pépin :
- Erreur « pip not found » ? Tentez
pip3oupy -m pip. - Sur Mac/Linux,
sudopeut être nécessaire pour les permissions. - Sous Windows, assurez-vous que Python figure bien dans votre PATH.
- Erreur « pip not found » ? Tentez
Un test express confirmera que l’installation tient la route :
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
Voir <title>Example Domain</title> s’afficher : tout est en place (Thunderbit Blog).
Exemple Python Beautiful Soup, pas à pas
Passons à un véritable exemple Python BeautifulSoup. Objectif : récupérer les derniers titres d’un site d’information public. Le déroulé tient en cinq temps.
1. Récupérer la page web
import requests
from bs4 import BeautifulSoup
url = "https://www.bbc.com/news"
response = requests.get(url)
html = response.text
2. Analyser le HTML
soup = BeautifulSoup(html, "html.parser")
3. Inspecter la structure HTML
Un clic droit sur la page, puis « Inspecter », ouvre les outils de développement : c’est là que vous repérez les balises hébergeant les titres. Sur bon nombre de sites d’actualité, ceux-ci se logent dans des balises <h3> associées à des classes précises.
Vous pourriez par exemple tomber sur :
<h3 class="gs-c-promo-heading__title">Titre du titre</h3>
4. Extraire les données
headlines = soup.find_all("h3", class_="gs-c-promo-heading__title")
for h in headlines:
print(h.get_text(strip=True))
Tous les titres de la page défilent alors à l’écran, un par un.
5. Enregistrer les données en CSV
Conservons ces titres pour une analyse ultérieure :
import csv
with open("headlines.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(["titre"])
for h in headlines:
writer.writerow([h.get_text(strip=True)])
Résultat : un fichier CSV prêt à ouvrir dans Excel ou Google Sheets.
Comprendre la structure HTML pour extraire efficacement les données
Une règle avant la première ligne de code : inspectez toujours le HTML de la page. La marche à suivre :
- Ouvrez les outils de développement : clic droit sur la page, puis « Inspecter ».
- Repérez les données : survolez les éléments pour identifier les balises qui contiennent les informations recherchées (titres, prix, auteurs, etc.).
- Notez les balises et les classes : cherchez des identifiants uniques comme
class="product-title"ouid="main-content". - Testez vos sélecteurs : servez-vous des méthodes
.find(),.find_all()ou.select()de BeautifulSoup pour cibler ces éléments.
Un dernier réflexe : soup.prettify() restitue une version lisible du HTML dans votre console Python.
Extraire et structurer des données avec BeautifulSoup
Prenons le cas où titres et auteurs d’une page de blog vous intéressent :
articles = soup.find_all("article")
data = []
for article in articles:
title = article.find("h2").get_text(strip=True)
author = article.find("span", class_="author").get_text(strip=True)
data.append({"title": title, "author": author})
En sortie, une liste de dictionnaires — le format rêvé pour un export CSV ou une analyse plus fine.
Le même principe vaut pour les liens, les images ou n’importe quel attribut :
for link in soup.find_all("a"):
print(link.get("href"))
Ou pour les images :
for img in soup.find_all("img"):
print(img.get("src"))
Enregistrer les données extraites : de Python vers Excel ou CSV
Vos données une fois structurées, l’export ne demande presque rien. Le module csv s’en charge :
import csv
with open("articles.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["title", "author"])
writer.writeheader()
for row in data:
writer.writerow(row)
Les adeptes de pandas préféreront ceci :
import pandas as pd
df = pd.DataFrame(data)
df.to_csv("articles.csv", index=False)
df.to_excel("articles.xlsx", index=False)
Un réflexe à conserver : l’encodage UTF-8, systématiquement, pour ne pas buter sur des caractères mal restitués — les données internationales y étant particulièrement sensibles.
Étude de cas : extraire des données d’un site d’actualité avec BeautifulSoup
Déroulons un exemple concret : récupérer titres, auteurs et dates de publication sur un site d’actualité.
Disons que vous souhaitez extraire des données d’articles depuis CNN :
import requests
from bs4 import BeautifulSoup
import csv
url = "https://edition.cnn.com/world"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
articles = soup.find_all("article")
data = []
for article in articles:
title_tag = article.find("h3")
date_tag = article.find("span", class_="date")
author_tag = article.find("span", class_="author")
title = title_tag.get_text(strip=True) if title_tag else ""
date = date_tag.get_text(strip=True) if date_tag else ""
author = author_tag.get_text(strip=True) if author_tag else ""
data.append({"title": title, "date": date, "author": author})
with open("cnn_articles.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["title", "date", "author"])
writer.writeheader()
for row in data:
writer.writerow(row)
Le script attrape les derniers articles, en tire titre, date et auteur, puis dépose le tout dans un CSV — à condition que le balisage de CNN colle encore aux balises indiquées. Or les grands sites d’information revoient régulièrement noms de classes et structure DOM ; réinspectez donc la page avant tout lancement en production. Le schéma robuste, c’est l’ossature elle-même — <article> en conteneur, puis un find sur les balises enfants ; des noms de classes tels que "date" et "author" ne valent qu’à titre d’illustration et se calent sur ce que la page renvoie au moment voulu.
Améliorer votre flux de travail : combiner BeautifulSoup avec Thunderbit
Voyons à présent comment fluidifier davantage ce flux. Thunderbit est une extension Chrome d’extraction Web IA qui débarrasse la collecte de données de ses tâtonnements. Avec elle, vous pouvez :
- Utiliser « AI Suggest Fields » : Thunderbit lit la page et propose de lui-même les champs à extraire — plus besoin de fouiller le HTML ni de retoucher des sélecteurs.
- Extraire des sous-pages : les liens vers les fiches produit ou article individuelles sont suivis automatiquement, ce qui enrichit votre jeu de données.
- Exporter instantanément : un clic suffit pour envoyer vos données vers Excel, Google Sheets, Airtable ou Notion.
- Gérer la pagination : l’extraction se poursuit sur plusieurs pages, défilement infini compris.
- Planifier des extractions : des tâches récurrentes maintiennent vos données au frais.
Voici un flux hybride que j’apprécie particulièrement :
- Démarrez avec Thunderbit : ouvrez votre site cible, cliquez sur l’icône Thunderbit et laissez « AI Suggest Fields » repérer les bonnes colonnes (titre, auteur, date).
- Exportez les données : téléchargez les résultats en CSV ou envoyez-les dans Google Sheets.
- Passez à BeautifulSoup pour un traitement sur mesure : pour les opérations plus poussées (nettoyage de texte, déduplication, fusion avec d’autres sources), importez le CSV dans Python et appuyez-vous sur BeautifulSoup ou pandas.
De cette combinaison, vous tirez le meilleur des deux mondes : la rapidité de Thunderbit et sa détection de champs par IA, la souplesse de BeautifulSoup pour votre logique maison.
Essayer gratuitement Thunderbit AI Web Scraper
Vitesse et qualité des données : pourquoi utiliser Thunderbit et BeautifulSoup ensemble ?
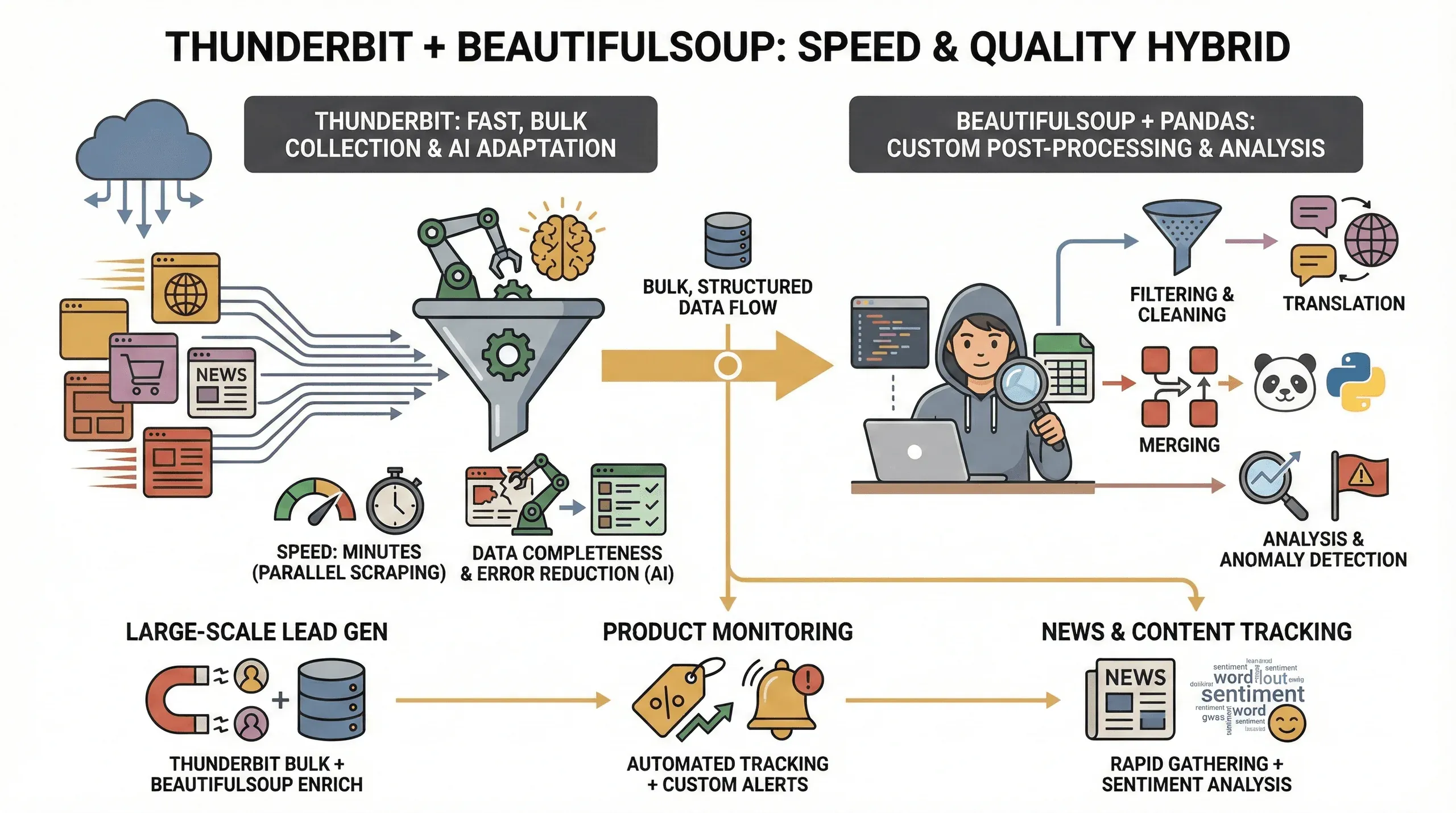 Mobiliser les deux outils, pour quel bénéfice ? Mon constat de terrain :
Mobiliser les deux outils, pour quel bénéfice ? Mon constat de terrain :
- Vitesse : en parallélisant des dizaines de pages (jusqu’à 50 à la fois en mode cloud), Thunderbit fait passer l’obtention des données de plusieurs heures à quelques minutes.
- Complétude des données : son IA encaisse les changements de mise en page et livre des données structurées même sur les sites récalcitrants, d’où moins de champs oubliés.
- Moins d’erreurs : finis les scripts qui rendent l’âme au premier changement de nom de classe — l’IA relit la page à chaque passage.
- Post-traitement sur mesure : pour les besoins avancés — filtrage, traduction, fusion de jeux de données —, BeautifulSoup et pandas vous laissent la main.
Trois terrains où cette approche hybride donne le meilleur d’elle-même :
- La génération de leads à grande échelle : Thunderbit ramasse le gros de la moisson, BeautifulSoup nettoie et enrichit derrière.
- Le suivi de produits : Thunderbit prend en charge le scraping répétitif, BeautifulSoup analyse les tendances ou débusque les anomalies.
- Le suivi d’actualités et de contenus : Thunderbit collecte les articles à toute vitesse, puis Python enchaîne sur l’analyse de sentiments ou l’extraction de mots-clés.
Résoudre les problèmes courants du web scraping avec BeautifulSoup
Essayer l’extension Chrome Thunderbit Extrayez n’importe quel site web avec l’IA en 2 clics. Get Started Free
Le scraping réserve parfois des surprises. Voici les écueils les plus fréquents et la façon de les désamorcer :
- Contenu dynamique : dès qu’un site charge ses données via JavaScript (défilement infini, AJAX), BeautifulSoup seul passe à côté. Selenium ou le mode navigateur de Thunderbit prennent alors le relais.
- Mesures anti-bot : certains sites refoulent les requêtes automatisées. Un en-tête User-Agent personnalisé, quelques pauses entre les requêtes ou l’extraction cloud de Thunderbit franchissent les blocages les plus simples.
- Changements de structure HTML : un script qui casse d’un coup trahit presque toujours une évolution du HTML. Réinspectez la page, actualisez vos sélecteurs ; l’IA de Thunderbit, elle, s’adapte à la volée.
- Données manquantes : avant tout appel à
.get_text(), vérifiez que l’élément existe. Pour les attributs,.get()vaut mieux que[]: vous évitez ainsi lesKeyError. - Problèmes d’encodage : l’UTF-8 à l’enregistrement gère correctement les caractères spéciaux.
Un point non négociable pour finir : respectez toujours le robots.txt et les conditions d’utilisation du site. Un scraping responsable, c’est aussi un robot qui sait se tenir.
Conclusion et points clés à retenir
Dans un monde piloté par la donnée, savoir scraper avec BeautifulSoup compte parmi les compétences qui rapportent le plus. Récapitulons :
- BeautifulSoup offre le point de départ idéal pour analyser du HTML statique et en tirer des données structurées avec Python.
- La configuration se règle en un rien de temps : Python, pip, quelques bibliothèques.
- Inspecter le HTML conditionne le ciblage des bonnes données.
- Exporter vers CSV/Excel rend vos données immédiatement exploitables pour l’analyse métier.
- L’association avec Thunderbit apporte détection de champs par IA, scraping accéléré et exports simplifiés — un vrai atout pour les profils métier et les non-développeurs.
- Les workflows hybrides (Thunderbit en volume, BeautifulSoup sur mesure) conjuguent vitesse, qualité des données et flexibilité.
Envie de passer la vitesse supérieure ? Mettez les deux outils à l’épreuve : partez d’un simple script BeautifulSoup, puis mesurez le temps que vous gagnez avec l’extracteur Web IA de Thunderbit. Et pour d’autres guides pratiques, faites un tour sur le Thunderbit Blog.
Bon scraping — et que vos données restent toujours propres, structurées et prêtes à l’emploi.
Essayer Thunderbit AI Web Scraper Get Started Free
FAQ
1. Qu’est-ce que BeautifulSoup et à quoi sert-il ?
BeautifulSoup est une bibliothèque Python conçue pour analyser des documents HTML et XML. Elle vous aide à extraire des données de pages web et à les convertir en formats structurés comme des listes ou des tableaux, ce qui la rend idéale pour les projets de web scraping.
2. Comment BeautifulSoup se compare-t-il à Selenium et Scrapy ?
BeautifulSoup est léger et simple à manier pour les pages HTML statiques. Selenium convient davantage aux sites dynamiques et riches en JavaScript, tandis que Scrapy est un framework complet pour le scraping asynchrone à grande échelle. BeautifulSoup reste le meilleur choix pour les débutants et les tâches rapides.
3. Puis-je utiliser BeautifulSoup et Thunderbit ensemble ?
Absolument. Thunderbit identifie et extrait rapidement des champs depuis des pages web grâce à l’IA, et vous pouvez vous appuyer sur BeautifulSoup pour un post-traitement sur mesure ou une analyse plus poussée des données exportées.
4. Quels sont les défis courants du web scraping avec BeautifulSoup ?
Les difficultés fréquentes touchent à la gestion du contenu dynamique, aux mesures anti-bot et à l’adaptation aux changements de structure HTML. Les fonctionnalités IA ou le mode navigateur de Thunderbit aident à surmonter bon nombre de ces obstacles.
5. Comment exporter vers Excel ou CSV les données extraites avec BeautifulSoup ?
Vous pouvez recourir au module csv intégré à Python ou à la bibliothèque pandas pour écrire vos données extraites dans des fichiers CSV ou Excel. Adoptez toujours l’encodage UTF-8 pour gérer les caractères spéciaux et garantir la compatibilité avec les tableurs.
Prêt à vous y essayer ? Téléchargez l’extension Chrome de Thunderbit et commencez dès aujourd’hui à faire du scraping plus finement. Pour plus de tutoriels et d’astuces, rendez-vous sur le Thunderbit Blog.
En savoir plus




