

Je n’oublierai jamais la première fois où j’ai vu quelqu’un copier-coller manuellement des données d’un site web dans un tableur pendant des heures. C’était comme regarder quelqu’un essayer de vider une piscine avec une cuillère à café. Aujourd’hui, l’automatisation des processus a explosé — surtout quand il s’agit de web scraping. Mais à mesure que de plus en plus d’équipes cherchent à automatiser ces tâches répétitives, une nouvelle question revient sans cesse : faut-il utiliser le RPA traditionnel (Robotic Process Automation) ou passer directement aux agents IA et aux extracteurs Web IA ?
Si vous travaillez dans la vente, l’e-commerce ou les opérations, vous avez sans doute déjà ressenti cette confusion. Les chiffres le confirment : 53 % des organisations ont déjà entamé leur parcours RPA, et 19 % supplémentaires prévoient de le faire bientôt. Pendant ce temps, les agents IA et les extracteurs Web IA avancent à toute vitesse, promettant de gérer même les sites les plus chaotiques et les plus dynamiques en quelques clics. Alors, comment choisir ? Voyons ensemble ce que signifie réellement l’automatisation des processus, en quoi le RPA et les agents IA diffèrent, et pourquoi l’avenir du web scraping ressemble de plus en plus à l’approche pilotée par l’IA de Thunderbit.
Démystifier l’automatisation des processus : qu’est-ce que cela signifie vraiment ?
Automatisez le web scraping avec l’IA Get Started Free
Commençons par les bases : l’automatisation des processus n’est qu’une façon élégante de dire « laissons le logiciel faire les tâches fastidieuses ». Voyez-la comme le tunnel de lavage automatique du monde de l’entreprise : les machines prennent en charge les tâches répétitives et manuelles, afin que les humains puissent se concentrer sur ce qui nécessite vraiment un cerveau (ou au moins une bonne tasse de café).
Dans l’entreprise, l’automatisation des processus sert à fluidifier les opérations quotidiennes, réduire les erreurs et libérer du temps pour vos équipes. Dans le cas du web scraping, cela consiste à utiliser des outils pour collecter des données sur des sites web — comme des prix produits, des coordonnées ou des avis — sans avoir à cliquer vous-même sur chaque page. Au lieu de passer des heures à copier-coller, vous configurez un « robot » numérique ou un agent pour le faire à votre place. C’est un peu comme un répondeur automatique, mais pour l’ensemble d’Internet.
Les avantages sont évidents : récupération des données plus rapide, meilleure précision et informations toujours à jour. Et pour avoir passé des années à créer des produits SaaS et d’automatisation, je peux vous le dire : une fois qu’on automatise un processus de web scraping, on n’a plus jamais envie de revenir à la saisie manuelle.
Décryptage du RPA : qu’est-ce que le Robotic Process Automation ?
Le Robotic Process Automation (RPA) est le vétéran de l’automatisation des processus. Le RPA utilise des « robots » logiciels qui imitent les actions humaines sur un ordinateur — cliquer sur des boutons, naviguer sur des sites web, copier-coller des données entre différentes applications. Ces robots suivent des instructions explicites, fondées sur des règles et excellent dans la gestion de tâches répétitives et structurées.
Cas d’usage typiques du RPA dans le web scraping
- Se connecter à un site web et extraire des données de champs spécifiques
- Copier des données de formulaires web vers des bases de données internes
- Télécharger des rapports depuis des portails web selon un calendrier
Le RPA a longtemps été un cheval de bataille dans des secteurs comme la finance, l’e-commerce et les opérations. Par exemple, un distributeur peut l’utiliser pour extraire chaque nuit les prix de ses concurrents, ou une équipe financière pour mettre à jour des tableurs avec les derniers cours boursiers.
Les atouts du RPA
- Fiabilité : les robots ne se fatiguent pas et ne font pas de fautes de frappe. Ils peuvent travailler 24 h/24 et 7 j/7 et sont 4 à 5 fois plus rapides que les humains.
- Conformité : chaque étape est documentée, ce qui simplifie grandement les audits.
- Déploiement rapide : pour des tâches simples et répétitives, le RPA se met en place rapidement — pas besoin d’intégrations complexes.
Les limites du RPA
Mais voici le revers de la médaille : le RPA est très strict sur les règles. Si un site web change sa mise en page ou sa structure, le robot peut casser. C’est un peu comme apprendre à conduire en mémorisant chaque virage ; si la route change, on est perdu. Le RPA a aussi du mal avec :
- Le contenu dynamique : le défilement infini, les pop-ups ou les mises en page changeantes exigent une logique supplémentaire et de la maintenance.
- Les données non structurées : si les informations ne sont pas toujours au même endroit, le RPA s’y perd.
- La maintenance : les mises à jour fréquentes des sites impliquent des reprogrammations fréquentes.
Autrement dit, si le RPA est excellent pour des tâches routinières et bien définies, ce n’est pas exactement l’outil le plus flexible du coffre.
Voici le nouveau venu : qu’est-ce qu’un agent IA ?
Place à l’agent IA — une nouvelle génération d’automatisation qui apporte adaptabilité et intelligence. Dans le contexte du web scraping, un agent IA est un programme autonome à qui l’on donne un objectif (« récupérez-moi tous les noms de produits et les prix de ce site ») et qui détermine lui-même comment l’atteindre.
En quoi les agents IA diffèrent-ils du RPA ?
- Apprentissage et adaptation : les agents IA utilisent le machine learning et le traitement du langage naturel pour comprendre, décider et agir. Ils peuvent gérer des données non structurées, apprendre de nouveaux schémas et ajuster leurs actions si nécessaire.
- Compréhension contextuelle : au lieu de suivre des règles rigides, les agents IA interprètent le contenu de la page web — ils reconnaissent des motifs, comprennent le contexte et peuvent même analyser des images ou du texte libre.
- Instructions en langage naturel : vous pouvez souvent simplement expliquer à un agent IA ce que vous voulez en français courant, et il se charge de trouver les étapes.
Voyez le RPA comme un employé consciencieux qui suit les consignes à la lettre, tandis qu’un agent IA ressemble davantage à un assistant autonome capable d’improviser et de s’adapter à de nouvelles situations.
L’extracteur Web IA : la prochaine évolution
Les extracteurs Web IA vont encore plus loin. Ils s’appuient sur des modèles avancés pour détecter automatiquement les champs de données, gérer la pagination et le défilement infini, et même extraire des données depuis des sous-pages — avec une configuration minimale. C’est là que des outils comme Thunderbit ouvrent la voie, en rendant l’automatisation des processus accessible à tout le monde, pas seulement aux développeurs.
Automatisation des processus pour le web scraping : pourquoi c’est important
Pourquoi s’embêter à automatiser le web scraping ? Parce que la collecte manuelle de données est lente, sujette aux erreurs et difficile à faire évoluer. L’automatisation apporte :
- Gain de temps : les robots peuvent extraire des centaines de pages en quelques minutes — là où il fallait auparavant des jours ou des semaines.
- Réduction des coûts : les coûts de processus diminuent de 30 à 60 % lorsque vous remplacez la saisie manuelle par l’automatisation.
- Précision : l’automatisation fournit des données plus cohérentes et sans erreur.
- Scalabilité : les extracteurs automatisés peuvent gérer des milliers de produits ou des millions d’enregistrements.
- Avantage concurrentiel : des données plus rapides et plus fraîches permettent de meilleures décisions et des réactions plus rapides.
Voici un tableau rapide des cas d’usage courants du web scraping et des bénéfices liés à l’automatisation de chacun :
| Cas d’usage du web scraping | Ce qui est collecté et pourquoi | Bénéfice de l’automatisation |
|---|---|---|
| Surveillance des prix des concurrents | Prix des produits, stock | Veille tarifaire en temps réel, des heures de vérification manuelle économisées |
| Génération de leads | Noms, e-mails, numéros de téléphone | Alimente le pipeline commercial 24 h/24 et 7 j/7, libère les commerciaux pour vendre |
| Étude de marché | Avis, notes | Agrège rapidement les opinions et identifie les tendances |
| Agrégation de catalogues produits | Détails produits | Maintient les bases de données à jour, accélère la mise sur le marché |
| Annonces immobilières | Prix, emplacements | Fournit des informations quotidiennes sur le marché, permet des rapports complets |
| Extraction de données financières | Cours boursiers, rapports | Mises à jour en temps réel, passage à l’échelle sur des milliers de points de données |
| Suivi de conformité | Utilisation de la marque, politiques | Application cohérente, alertes instantanées, pistes d’audit |
En résumé : l’automatisation est rapidement rentabilisée.
RPA vs agent IA : comment automatisent-ils le web scraping ?
Passons au concret. Comment le RPA et les agents IA abordent-ils réellement le web scraping ? Regardons cela côte à côte :
| Étape | Approche RPA | Approche agent IA |
|---|---|---|
| Configuration initiale | L’utilisateur enregistre chaque action et définit chaque champ | L’utilisateur fournit l’URL et décrit les données souhaitées ; l’IA détermine automatiquement les champs |
| Flexibilité | Fragile — casse lors des changements du site | Adaptative — gère les changements de mise en page et les nouveaux schémas |
| Données structurées | Fonctionne bien | Fonctionne bien |
| Données non structurées | Difficultés | Excellente performance — peut analyser le texte, les images et le contexte |
| Pagination/défilement | Nécessite un script explicite | Détecte et gère automatiquement |
| Maintenance | Élevée — mise à jour requise à chaque changement | Faible — l’IA s’adapte aux changements mineurs |
| Compétences techniques nécessaires | Modérées — configuration requise | Faibles — pas de code, invites en langage naturel |
| Scalabilité | Limitée par les licences des robots | Natif cloud, mise à l’échelle facile |
Dans quels cas chacun brille-t-il ?
- Le RPA excelle lorsque vous avez un site stable et prévisible ainsi que des données structurées — pensez aux portails internes ou aux systèmes legacy.
- Les agents IA brillent lorsque vous devez gérer des sites dynamiques, complexes ou fréquemment modifiés, ou lorsque votre équipe n’est pas composée de développeurs.
RPA pour le web scraping : l’approche traditionnelle
Prenons un exemple concret. Avec un RPA (comme UiPath ou Automation Anywhere), vous :
- Enregistrez votre navigation sur le site : ouvrir le navigateur, vous connecter, cliquer sur les pages, copier les données.
- Le robot rejoue ces actions, boucle sur les pages et copie les données dans votre tableur ou votre base de données.
Défis courants :
- Changements du site : une nouvelle bannière ou un bouton renommé peut casser le robot.
- Pagination : le défilement infini ou les boutons « Charger plus » exigent un script supplémentaire.
- Contenu dynamique : les robots ont besoin d’attentes explicites pour laisser le contenu se charger.
- Mesures anti-bot : les CAPTCHA et les blocages d’IP peuvent stopper le RPA net.
- Montée en charge : faire tourner de nombreux robots en parallèle peut devenir coûteux et complexe.
Le RPA est excellent pour les sites internes et prévisibles — mais pour le far west du web public, il peut vite devenir un cauchemar de maintenance.
Un point mérite d’être signalé : à partir de la mi-2026, la frontière entre « RPA » et « agent IA » devient floue côté éditeurs aussi. La Automation Suite de UiPath intègre désormais des capacités d’IA agentique — Agent Builder, Maestro, GenAI Activities — et Automation Anywhere suit une trajectoire similaire. Donc, lorsque vous évaluez aujourd’hui un « outil RPA », vérifiez s’il s’agit vraiment du type rigide en enregistrement et restitution, ou s’il embarque déjà une extraction pilotée par l’IA. Les deux camps convergent rapidement.
Extracteur Web IA : la nouvelle génération d’automatisation des processus
Voyons maintenant comment un extracteur Web IA gère la même tâche :
- Ouvrez le site, cliquez sur « AI Suggest Fields » et laissez l’IA analyser la page.
- L’IA propose un tableau des données qu’elle peut extraire — noms de produits, prix, notes, etc.
- Vous ajustez ou validez les suggestions, puis cliquez sur « Scrape ».
- L’agent IA gère automatiquement la pagination, suit les liens des sous-pages et exporte les données vers Excel, Google Sheets, Airtable ou Notion.
Avantages clés :
- Configuration minimale : pas de code, pas de balisage manuel — décrivez simplement ce que vous voulez.
- Gestion des sous-pages et de la pagination : l’IA détecte et suit automatiquement les liens.
- Analyse intelligente des données : l’IA peut nettoyer, mettre en forme et même catégoriser les données pendant l’extraction.
- Exports simples : exportez en un clic vers vos outils préférés.
Pour les utilisateurs non techniques — et même pour les utilisateurs techniques qui apprécient leur temps —, c’est une vraie révolution. C’est comme passer d’un téléphone à clapet à un smartphone du jour au lendemain.
Essayer gratuitement l’Extracteur Web IA Thunderbit
Zoom sur Thunderbit : l’extracteur Web IA en tant qu’agent IA
Parlons maintenant de l’outil dans lequel j’ai investi — et passé beaucoup de nuits tardives : Thunderbit. Thunderbit est une extension Chrome d’extracteur Web IA qui évolue vers un véritable agent IA pour l’automatisation web. Notre objectif ? Rendre le web scraping si simple que votre grand-mère pourrait le faire (et peut-être même y prendre plaisir).
Qu’est-ce qui rend Thunderbit différent ?
- AI Suggest Fields : cliquez sur un bouton, et l’IA lit la page et suggère les meilleures colonnes à extraire.
- Extraction de sous-pages : Thunderbit peut visiter chaque sous-page (comme les pages de détail produit) et enrichir votre tableau de données — sans configuration supplémentaire.
- Détection de la pagination : qu’il s’agisse d’un bouton « Suivant » ou d’un défilement infini, l’IA de Thunderbit comprend le fonctionnement et continue l’extraction.
- Export instantané des données : exportez vos données vers Excel, Google Sheets, Airtable ou Notion en un clic — sans frais supplémentaires.
- Aucune compétence en code requise : tout est conçu pour les utilisateurs métiers, pas seulement pour les développeurs.
- Extraction dans le cloud ou dans le navigateur : choisissez entre une extraction cloud (rapide, parallèle) ou dans votre propre navigateur (parfait pour les sites nécessitant une connexion).
- Utilitaires IA gratuits : extrayez des e-mails, des numéros de téléphone ou des images depuis n’importe quel site en un seul clic.
- Scheduled Scraper : configurez des extractions récurrentes en langage naturel — « tous les jours à 9 h » — et laissez Thunderbit s’occuper du reste.
Thunderbit est conçu pour être « l’assistant IA de données web » dans votre navigateur. Il ne s’agit pas seulement d’extraire des données — il s’agit d’automatiser tout le processus, de l’extraction à l’export, avec le moins de friction possible. Et oui, nous n’en sommes qu’au début. L’avenir appartient aux agents IA capables non seulement de lire le web, mais aussi d’agir dessus.
Vous voulez essayer ? Téléchargez Thunderbit depuis le Chrome Web Store.
Choisir le bon outil : quand utiliser le RPA, un agent IA, ou les deux
Alors, comment choisir entre RPA et agents IA (comme Thunderbit) pour votre automatisation du web scraping ? Voici une checklist rapide :
| Facteur de décision | RPA | Agent IA / Extracteur Web IA |
|---|---|---|
| Les données sont très structurées et le site est stable | ✅ | |
| Les données sont désordonnées, non structurées, ou le site change souvent | ✅ | |
| Besoin de gérer du contenu dynamique (défilement infini, pop-ups) | ✅ | |
| L’équipe possède des compétences en code / IT | ✅ | ✅ |
| L’équipe est non technique | ✅ | |
| La conformité / l’audit exige des étapes strictes et répétables | ✅ | |
| Besoin de monter rapidement en charge ou d’extraire de nombreux sites | ✅ | |
| Extraction ponctuelle ou ad hoc | ✅ | |
| Processus continu et répétitif | ✅ | ✅ |
| Envie de combiner les forces | Approche hybride possible | Approche hybride possible |
Astuce pro : de nombreuses organisations combinent désormais les deux approches — elles utilisent le RPA pour les workflows internes structurés et les agents IA pour les données web externes et dynamiques. L’avenir est hybride.
Surmonter les défis courants de l’automatisation du web scraping
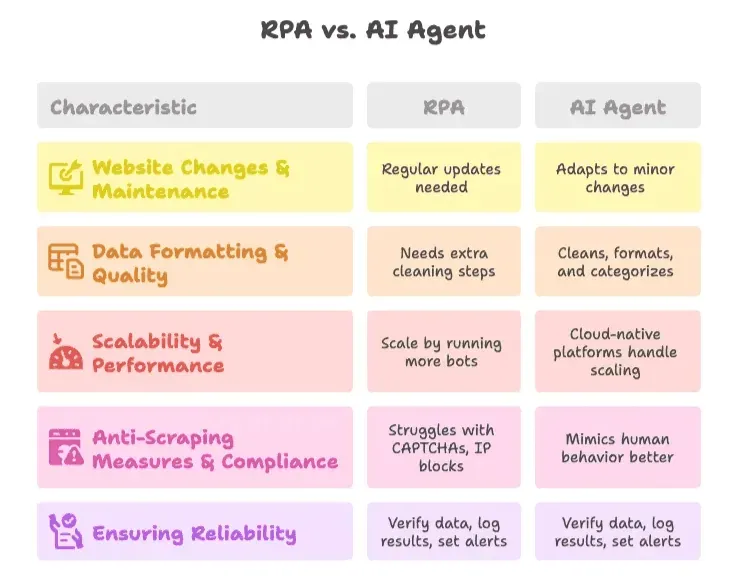
1. Changements du site web et maintenance
- RPA : nécessite des mises à jour régulières lorsque les sites changent. Utilisez des scripts modulaires et la surveillance pour détecter les problèmes tôt.
- Agent IA : plus résilient — l’IA s’adapte aux changements mineurs, mais il faut tout de même vérifier les résultats périodiquement.
2. Mise en forme et qualité des données
- RPA : ajoutez des étapes supplémentaires de nettoyage des données, ou intégrez des scripts / Excel.
- Agent IA : l’IA peut nettoyer, mettre en forme et même catégoriser les données pendant l’extraction. Utilisez des instructions spécifiques à chaque champ pour de meilleurs résultats.
3. Scalabilité et performances
- RPA : faites évoluer en lançant davantage de robots, mais surveillez les limites de débit et les coûts d’infrastructure.
- Agent IA : des plateformes cloud-native comme Thunderbit gèrent la montée en charge pour vous.
4. Mesures anti-scraping et conformité
- RPA : peut avoir du mal avec les CAPTCHA et les blocages d’IP. Limitez-vous aux sites pour lesquels vous êtes autorisé.
- Agent IA : certains agents IA peuvent mieux imiter le comportement humain, mais respectez toujours les conditions d’utilisation des sites et les lois sur la confidentialité des données.
5. Garantir la fiabilité
- Bonne pratique : vérifiez toujours les données extraites, journalisez les résultats et configurez des alertes en cas d’anomalies. Effectuez régulièrement des contrôles manuels, surtout pour les processus critiques.
L’avenir de l’automatisation des processus : les agents IA mènent la danse
Découvrez d’autres analyses sur l’extraction Web IA Get Started Free
Voici où les choses deviennent vraiment passionnantes. Le monde passe de l’automatisation à l’autonomie. Les agents IA ne se contentent plus de suivre des instructions : ils commencent à prendre des décisions, à s’adapter à de nouveaux scénarios et même à suggérer des actions à partir des données qu’ils collectent.
- 82 % des organisations prévoient d’intégrer des agents IA d’ici 2027, selon l’étude 2026 AI Advantage de Capgemini — une forte hausse par rapport à 2024, lorsque les agents IA étaient encore principalement expérimentaux.
- D’ici 2028, 33 % des applications logicielles d’entreprise intégreront de l’IA agentique, selon Gartner — contre moins de 1 % en 2024.
- Les plateformes no-code et low-code rendent le développement d’agents IA accessible à tout le monde, pas seulement à l’IT.
Chez Thunderbit, nous construisons pour cet avenir. Notre vision est de rendre l’automatisation des processus si intuitive que n’importe qui puisse automatiser le web scraping, la collecte de données et même l’exécution de workflows en quelques clics et avec une simple instruction en langage naturel. Nous ne nous contentons pas d’extraire des données — nous construisons les agents IA qui alimenteront la prochaine vague d’automatisation des entreprises.
Vous voulez voir où va l’avenir ? Consultez davantage de contenus sur le blog Thunderbit, ou plongez dans des sujets comme Qu’est-ce que le data scraping et comment le faire en 2025 et Comment extraire n’importe quel site web avec l’IA.
Conclusion
L’automatisation des processus ne consiste plus seulement à remplacer le travail manuel — il s’agit de permettre aux équipes d’en faire plus, plus vite et avec moins de friction. Le RPA et les agents IA ont chacun leur place, mais la tendance est claire : les extracteurs Web IA comme Thunderbit rendent l’automatisation plus intelligente, plus résiliente et accessible à tous.
Si vous copiez-collez encore vos données à la main, il est temps de reposer la cuillère à café et de laisser les robots faire le gros du travail. Et si vous êtes prêt à voir ce que les agents IA peuvent faire pour votre entreprise, essayez Thunderbit. Votre futur vous — et votre équipe — vous en remerciera.
Commencez à automatiser le web scraping avec Thunderbit
FAQ
1. Quelle est la différence entre le RPA et les agents IA dans l’automatisation des processus ?
Le RPA (Robotic Process Automation) suit des instructions strictes, fondées sur des règles, pour automatiser des tâches répétitives, ce qui le rend idéal pour des environnements stables et structurés. Les agents IA, en revanche, peuvent interpréter le contexte, s’adapter aux changements et gérer des données non structurées grâce au machine learning et au traitement du langage naturel — parfaits pour des tâches de web scraping dynamiques et complexes.
2. Pourquoi l’automatisation des processus est-elle importante pour le web scraping ?
Le web scraping manuel est lent, sujet aux erreurs et difficile à faire évoluer. Automatiser le web scraping permet de gagner du temps, de réduire les coûts, d’améliorer la précision et de prendre des décisions en temps réel en collectant en continu des données fraîches depuis les sites web sans intervention manuelle.
3. Quand devrais-je utiliser le RPA plutôt qu’un extracteur Web IA comme Thunderbit ?
Le RPA convient mieux aux sites prévisibles avec des données structurées et lorsque des exigences strictes de documentation de conformité s’appliquent. Si votre équipe possède des compétences techniques et que les sites cibles ne changent pas fréquemment, le RPA peut être un choix fiable.
4. Qu’est-ce qui différencie Thunderbit des outils de scraping traditionnels ?
Thunderbit utilise l’IA pour détecter automatiquement les champs, gérer la pagination, extraire depuis des sous-pages et exporter les données en un clic — sans code. Il est conçu pour les utilisateurs métiers et prend en charge l’extraction dans le navigateur ou dans le cloud, ce qui rend l’automatisation des processus accessible aux non-développeurs.
5. Peut-on utiliser ensemble le RPA et les agents IA ?
Oui — et de plus en plus, vous n’avez même plus besoin de les assembler vous-même. Beaucoup d’équipes utilisent encore le RPA traditionnel pour les workflows internes stables et structurés, puis ajoutent un extracteur Web IA comme Thunderbit pour le web public plus chaotique. Mais les principales plateformes RPA (UiPath, Automation Anywhere) ont déployé des capacités d’IA agentique en 2025–2026, si bien que l’approche « hybride » devient la norme plutôt qu’un projet d’intégration sur mesure.
Lectures complémentaires :
- Qu’est-ce que le list crawling et comment le faire avec l’IA
- Comment extraire des données de site web vers Excel avec l’IA
- Les meilleurs outils et logiciels de web scraping en 2025
- Qu’est-ce que l’automatisation des processus ?
Essayez l’Extracteur Web IA Get Started Free




