

Certaines personnes collectionnent des timbres. D’autres collectionnent des baskets. Mais si vous travaillez dans la vente, le marketing, l’e-commerce ou les opérations en 2026, il y a de fortes chances que vous collectionniez quelque chose d’un peu plus… numérique : des données web. Et pas qu’un peu : les entreprises dépensent désormais en moyenne 5 millions de dollars par an pour la collecte de données web, et le web scraping est devenu un outil standard dans tous les services, de la stratégie au service client (source).
Avec cette explosion de la demande, deux noms reviennent sans cesse dans les tutoriels Python de scraping et les projets de données métier : Playwright et Selenium. Tous deux ont commencé comme outils d’automatisation de navigateur pour les tests, mais ils sont aujourd’hui les frameworks de référence pour quiconque veut transformer le web en données structurées et exploitables. Mais voilà le piège : choisir entre les deux n’est pas qu’une décision technique — c’est choisir le bon outil pour vos besoins réels en scraping. Et si vous n’êtes pas développeur, ou si vous voulez simplement des résultats rapidement, il existe une voie encore plus simple (indice : elle ne nécessite pas d’écrire une seule ligne de Python). Entrons dans le vif du sujet.
Des outils de test aux champions du web scraping : Playwright et Selenium expliqués
Posons le décor. Selenium existe depuis 2004, et c’est la valeur sûre de l’automatisation de navigateur. Conçu à l’origine pour les testeurs QA, il permet de contrôler des navigateurs comme Chrome, Firefox et même Internet Explorer (pour ceux qui aiment vivre dangereusement). Playwright, à l’inverse, a fait une entrée remarquée en 2020, soutenu par Microsoft, avec une approche moderne de l’automatisation de navigateur — on peut le voir comme le petit frère de Selenium, plus jeune et plus rapide.
Les deux outils vous permettent d’écrire des scripts (souvent en Python) qui ouvrent un navigateur, accèdent à un site, cliquent sur des boutons, remplissent des formulaires et — surtout pour nous — extraient des données. Bien qu’ils soient nés pour les tests automatisés, ils sont devenus l’épine dorsale du web scraping pour tout, du suivi des prix à la génération de leads (source). Leur popularité ne se limite pas aux développeurs : de plus en plus d’utilisateurs métiers se retroussent les manches pour créer leurs propres scrapers, ou du moins essaient.
Mais voici le vrai changement de perspective : quand vous faites du scraping, vos priorités changent. Vous vous souciez moins de la couverture des tests que de récupérer les données de manière fiable, éviter les blocages et ne pas passer votre week-end à déboguer des erreurs Python. C’est là que les vraies différences entre Playwright et Selenium entrent en jeu.
Différences clés : Playwright vs Selenium pour le web scraping

Allons droit au but : Playwright et Selenium peuvent tous deux extraire des données de sites web, mais ils brillent dans des situations différentes.
- Selenium est le vétéran. Il fonctionne avec presque tous les navigateurs et langages, dispose d’une communauté immense et convient parfaitement au scraping de sites anciens et statiques avec des mises en page prévisibles.
- Playwright est le petit nouveau doté de fonctionnalités modernes. Il est conçu pour les sites d’aujourd’hui, dynamiques et riches en JavaScript, avec des outils intégrés pour gérer les connexions, les fenêtres contextuelles, le défilement infini, et bien plus encore. Il est aussi plus rapide et plus simple à configurer, surtout pour les utilisateurs Python.
Mais ne vous contentez pas de me croire sur parole : voyons cela fonctionnalité par fonctionnalité.
Tableau comparatif des fonctionnalités : Playwright vs Selenium
| Fonctionnalité | Selenium | Playwright |
|---|---|---|
| Langages pris en charge | Python, Java, C#, JS, Ruby, etc. | Python, JS/TS, Java, C# |
| Navigateurs pris en charge | Chrome, Firefox, Edge, Safari, IE, Opera | Chromium (Chrome/Edge), Firefox, WebKit |
| Complexité de configuration | Nécessite un driver de navigateur, configuration manuelle | Une commande installe tout |
| Vitesse/performances | Plus lent, plus gourmand en ressources | Généralement plus rapide sur les pages riches en JavaScript ; conçu pour l’asynchrone et le parallèle |
| Gestion du contenu dynamique | Attentes manuelles, plus de code requis | Auto-attente, gère facilement les sites riches en JavaScript |
| Contournement anti-bot | Plus facilement détectable, nécessite des modules additionnels | Mode furtif intégré, meilleure imitation des utilisateurs |
| Outils de débogage | Basique (Selenium IDE, captures d’écran) | Inspector, enregistrement vidéo, génération de code |
| Soutien de la communauté | Immense, mature, avec beaucoup de tutoriels | En forte croissance, documentation moderne, développeurs actifs |
| Workflow de scraping en Python | Plus de configuration, plus de code répétitif | Plus fluide, moins de code, plus simple pour les débutants |
Choisir le bon outil : quand utiliser Playwright ou Selenium pour le web scraping
Alors, lequel choisir pour votre prochain projet de scraping ? Voici mon avis, après des années à construire des outils d’automatisation et à aider des équipes à extraire des données du far west du web.
- Selenium est votre allié si :
- Le site que vous scrappez est ancien — pensez HTML statique, JavaScript minimal et pas de fenêtres contextuelles sophistiquées.
- Vous devez prendre en charge des navigateurs atypiques (bonjour, Internet Explorer) ou vous intégrer à des systèmes hérités.
- Vous voulez le confort d’une immense communauté et d’innombrables réponses sur Stack Overflow.
- Vous connaissez déjà Selenium grâce à des projets de test.
- Playwright est la meilleure option si :
- Le site est moderne, dynamique et bourré de JavaScript (pensez e-commerce, réseaux sociaux ou tout ce qui fait tourner le ventilateur de votre ordinateur).
- Vous devez vous connecter, naviguer entre des onglets, gérer le défilement infini ou des fenêtres contextuelles.
- Vous voulez démarrer vite, avec moins de configuration et moins de code.
- Vous êtes fatigué d’écrire
time.sleep(5)partout et souhaitez que l’outil gère le timing pour vous.
Voici une règle simple : si votre premier essai de scraping avec Selenium se résume à beaucoup de “pourquoi ça ne charge pas ?”, il est probablement temps d’essayer Playwright.
Selenium pour le web scraping : forces et limites
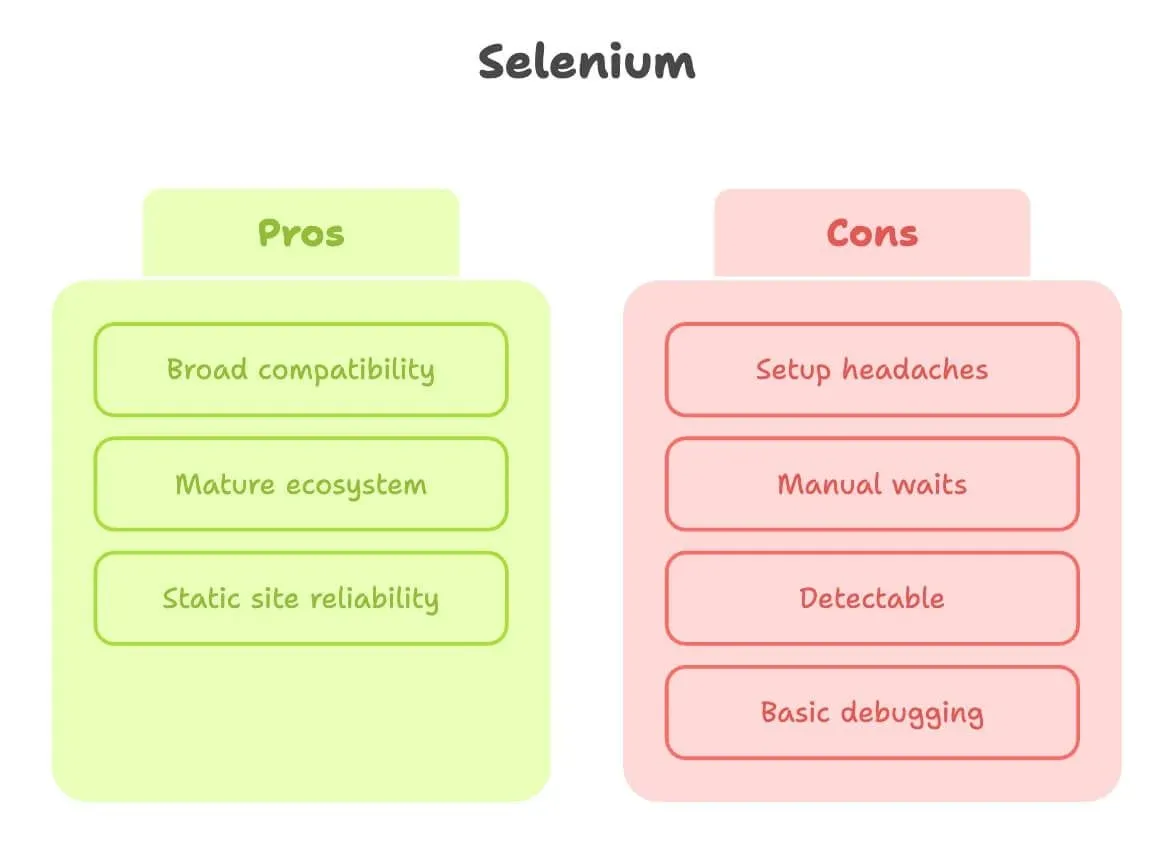
Rendons à Selenium ce qui lui revient. C’est le grand-père de l’automatisation de navigateur, et pour beaucoup de tâches de scraping, il fait simplement le travail.
Forces :
- Large compatibilité : fonctionne avec presque tous les navigateurs et langages.
- Écosystème mature : une tonne de tutoriels, de Q&R et de plugins.
- Très bon pour les sites statiques : si la page change peu, Selenium est solide comme un roc.
Limites :
- Configuration pénible : il faut télécharger et configurer un driver de navigateur (comme ChromeDriver), puis le maintenir à jour. Les débutants restent souvent bloqués à cette étape (source).
- Attentes manuelles : contenu dynamique ? Vous allez écrire beaucoup d’attentes explicites ou, pire, des
sleepau hasard. - Détection plus facile : de nombreux sites peuvent repérer les navigateurs pilotés par Selenium et les bloquer, surtout si vous exécutez tout cela sur un serveur cloud.
- Débogage basique : pas d’enregistrement vidéo intégré ni d’inspecteur interactif.
En bref, Selenium est parfait pour les sites simples et stables — mais peut donner l’impression de pousser un rocher en montée sur des pages modernes et interactives.
Playwright pour le web scraping : forces et limites
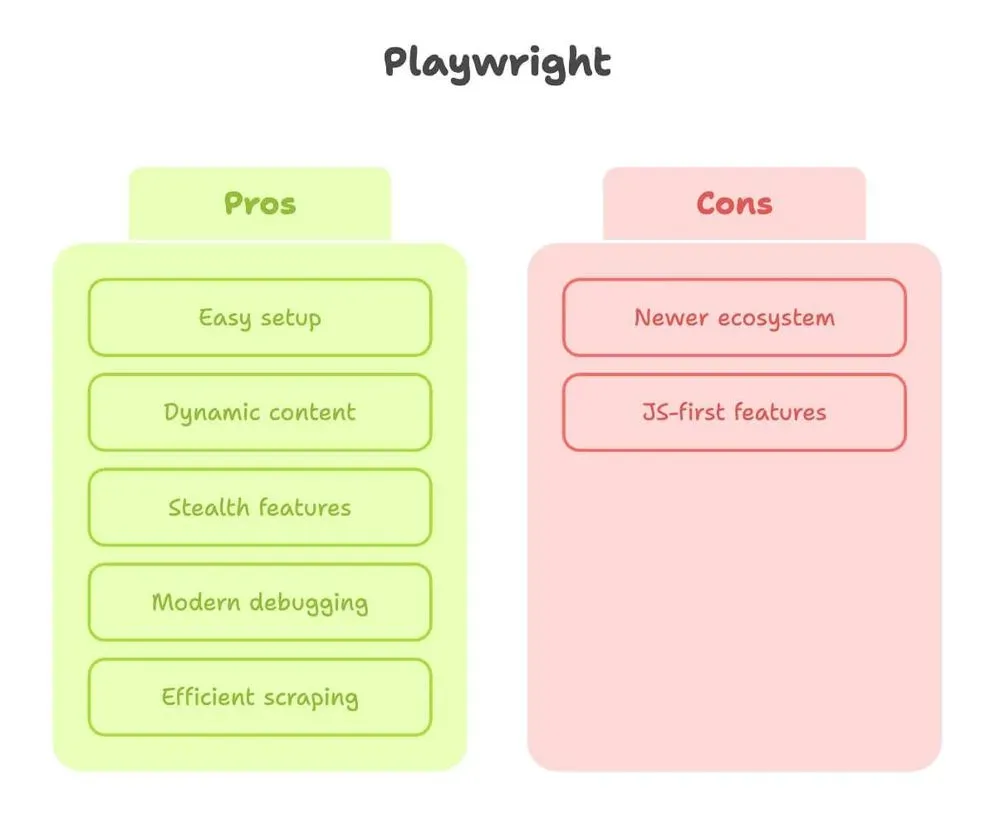
Passons maintenant à Playwright. Après avoir beaucoup travaillé avec les deux outils, je peux dire que Playwright donne l’impression d’avoir été conçu par des personnes qui ont réellement souffert du web scraping.
Forces :
- Configuration facile : un
pip install, une commande, et vous êtes prêt. Pas d’histoire de driver. - Gestion du contenu dynamique : auto-attente des éléments, donc pas besoin de deviner quand la page est prête (source).
- Fonctionnalités furtives : imite mieux les vrais utilisateurs, avec un mode furtif intégré et la prise en charge de plusieurs contextes (pratique pour scraper comme plusieurs “utilisateurs” en même temps).
- Débogage moderne : Inspector, enregistrement vidéo, et même génération de code à partir de vos clics manuels.
- Plus rapide et plus efficace : surtout pour extraire beaucoup de pages ou exécuter en parallèle.
Limites :
- Écosystème plus récent : un peu moins de tutoriels, même si l’écart se réduit vite.
- Certaines fonctions sont d’abord pensées pour JavaScript : la plupart des choses marchent en Python, mais il arrive qu’une fonctionnalité soit mieux documentée en JS.
En résumé : Playwright est mon choix par défaut pour tout site un tant soit peu dynamique, ou quand je veux des résultats rapides sans me battre avec la configuration.
Contournement anti-bot : quel scraper Python gère le mieux les sites modernes ?
Abordons l’éléphant dans la pièce : le blocage. En web scraping, le plus dur n’est pas d’écrire le code — c’est de s’assurer que le site ne vous claque pas la porte au nez.
- Selenium : prêt à l’emploi, il est plus facile à détecter. Les sites peuvent repérer l’indicateur
webdriver, les user agents en mode headless et d’autres signaux révélateurs. Il existe des contournements (comme undetected-chromedriver), mais ils demandent une configuration supplémentaire et courent toujours après les technologies anti-bot (source). - Playwright : dispose de fonctionnalités furtives intégrées, comme le masquage automatique des empreintes d’automatisation, la prise en charge de plusieurs contextes de navigateur et l’attente d’interactions proches de celles d’un vrai utilisateur. Ce n’est pas magique, mais vous avez moins de chances d’être bloqué du premier coup.
Mais voici la vérité : aucun des deux outils n’est totalement immunisé contre les mesures anti-bot. Pour le scraping à forts enjeux (pensez aux lancements de baskets ou aux sites de billetterie), vous devrez quand même utiliser des proxies, faire tourner les adresses IP et peut-être même résoudre des CAPTCHA. Playwright rend simplement les choses un peu moins pénibles.
Expérience développeur : configuration, courbe d’apprentissage et débogage
Parlons de la vraie expérience du démarrage — surtout si vous débutez ou si vous voulez simplement faire le travail sans doctorat en Python.
- Selenium :
- Configuration : installez Python, installez Selenium, téléchargez le bon driver de navigateur, ajoutez-le à votre PATH, et priez pour que les versions soient compatibles. (J’ai vu bien plus de personnes bloquées à l’étape du driver qu’au scraping lui-même.)
- Courbe d’apprentissage : beaucoup de ressources, mais aussi beaucoup de code hérité et de tutoriels obsolètes.
- Débogage : surtout des
printet des captures d’écran. Selenium IDE existe, mais reste basique.
- Playwright :
- Configuration :
pip install playwright, puisplaywright install. Terminé. - Courbe d’apprentissage : documentation moderne, nombreux exemples, et une API plus “humaine” — vous pouvez sélectionner des éléments par texte, par rôle, ou même par placeholder.
- Débogage : Inspector vous permet de suivre votre script pas à pas, de regarder le navigateur et même d’enregistrer des vidéos de vos sessions de scraping (source).
- Configuration :
Si vous voulez voir des résultats rapidement et passer moins de temps sur la configuration et le dépannage, Playwright est le grand gagnant. Selenium reste très bon si vous êtes déjà à l’aise avec ses particularités ou si vous avez besoin de sa compatibilité très large.
Pas à pas : créer votre premier scraper web Python avec Playwright ou Selenium
Voyons concrètement à quoi ressemble la création d’un scraper avec chaque outil — pas de code, seulement les étapes.
Playwright (Python) :
- Installer Playwright et les navigateurs :
pip install playwright+playwright install - Lancer le navigateur : démarrez un navigateur Chromium, Firefox ou WebKit (mode headless ou visible).
- Aller sur la page : utilisez
page.goto("<https://example.com>") - Attendre le contenu : Playwright attend automatiquement que les éléments se chargent.
- Extraire les données : utilisez des sélecteurs simples et lisibles (comme
get_by_text,locator("span.price")). - Gérer la pagination ou les sous-pages : bouclez sur les pages ou cliquez à travers les liens — Playwright facilite l’exécution de plusieurs pages en parallèle.
- Exporter les données : enregistrez dans Excel, Google Sheets, Airtable, Notion, CSV ou JSON.
- Déboguer : utilisez Inspector ou l’enregistrement vidéo si quelque chose tourne mal.
Selenium (Python) :
- Installer Selenium :
pip install selenium - Télécharger le driver du navigateur : (par exemple ChromeDriver pour Chrome), puis l’ajouter à votre PATH.
- Lancer le navigateur : démarrez Chrome, Firefox ou un autre navigateur.
- Aller sur la page :
driver.get("<https://example.com>") - Attendre le contenu : ajoutez manuellement des attentes explicites (
WebDriverWait) ou, si vous aimez vivre dangereusement,time.sleep. - Extraire les données : utilisez
find_elementoufind_elements(sélecteurs CSS/XPath). - Gérer la pagination ou les sous-pages : bouclez sur les URL ou cliquez sur les boutons, mais vous devrez gérer vous-même le timing et la navigation.
- Exporter les données : enregistrez dans Excel, Google Sheets, Airtable, Notion, CSV ou JSON.
- Déboguer : surtout manuellement — observer le navigateur, afficher le HTML ou prendre des captures d’écran.
Vous voyez la différence ? Playwright est simplement un peu plus en mode “clé en main” pour les sites modernes.
Au-delà du code : le web scraping sans code avec Thunderbit AI Web Scraper
Extraire des données de n’importe quel site web grâce à l’IA Get Started Free
Soyons honnêtes. Tout le monde n’a pas envie de devenir un gourou Python juste pour obtenir un tableau de prix produits ou une liste de prospects. Peut-être travaillez-vous dans la vente, le marketing, l’immobilier ou les opérations, et vous voulez simplement les données — tout de suite. C’est là qu’intervient Thunderbit.
En tant que cofondateur de Thunderbit, j’ai pu constater à quel point de nombreux utilisateurs métiers veulent simplement éviter le code et aller droit à l’essentiel. Nous avons donc créé une extension Chrome propulsée par l’IA qui vous permet de scraper n’importe quel site en deux clics — sans Python, sans drivers, sans débogage.
Comment fonctionne Thunderbit
- Allez sur le site que vous souhaitez scraper.
- Cliquez sur “AI Suggest Fields”. L’IA de Thunderbit analyse la page et recommande les champs de données (comme le nom du produit, le prix, l’image, la note).
- Cliquez sur “Scrape”. Vous obtenez instantanément un tableau de données structuré.
- Exportez vers Excel, Google Sheets, Airtable, Notion, CSV ou JSON. C’est fait.
Pas besoin de jouer avec les sélecteurs, pas d’essais-erreurs, pas de code. C’est aussi simple que commander à emporter — et, soyons francs, probablement plus rapide que d’attendre que votre repas arrive.
Essayer gratuitement Thunderbit AI Web Scraper
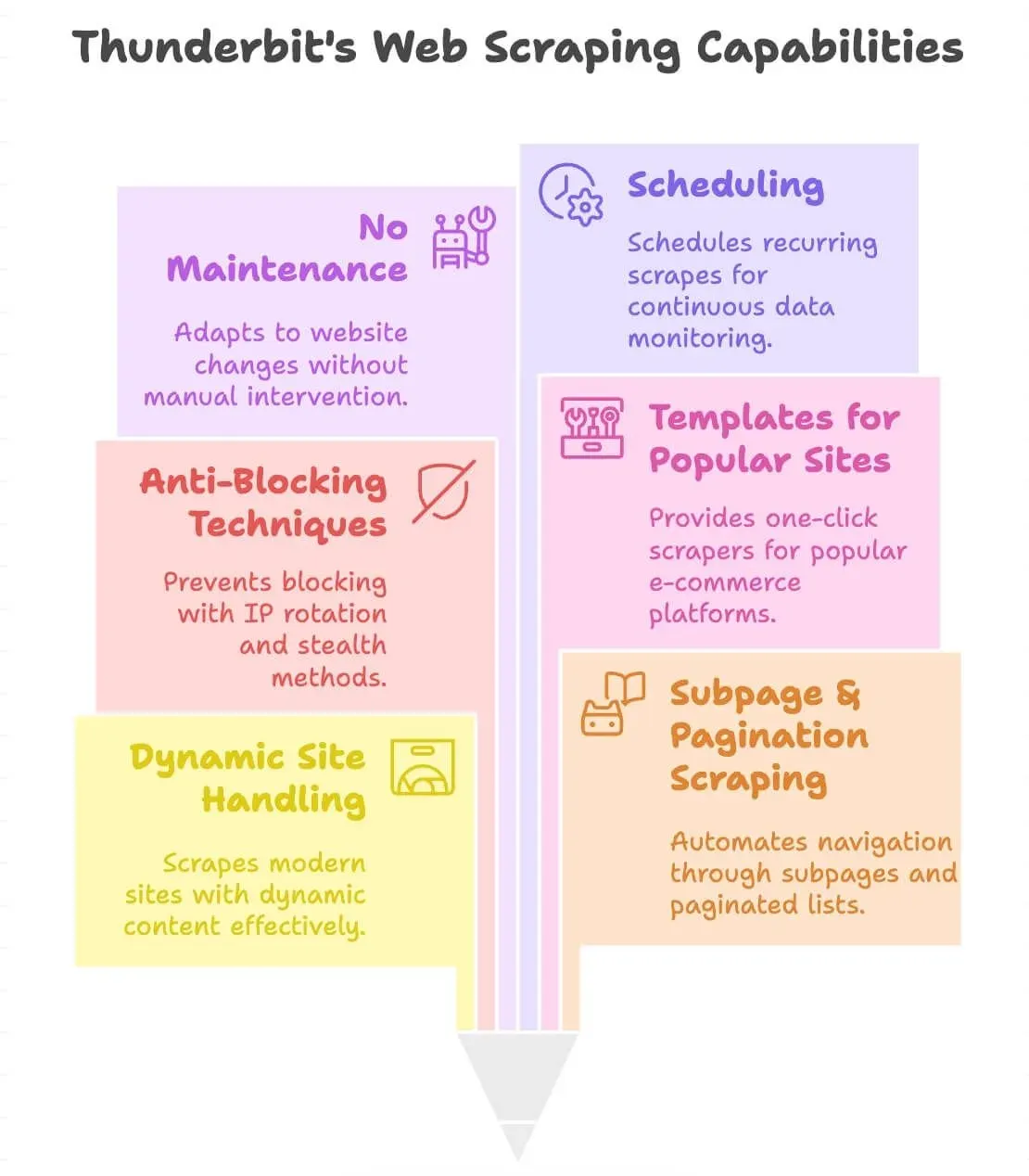
Ce qui rend Thunderbit différent
- Gère les sites dynamiques : extrait des données sur les sites e-commerce modernes, les annuaires, et même les sites avec défilement infini ou fenêtres contextuelles.
- Scraping des sous-pages et de la pagination : clique automatiquement à travers les fiches produit ou les listes paginées pour récupérer toutes les données nécessaires.
- Anti-blocage intégré : utilise la rotation d’IP côté serveur et des techniques furtives, afin de réduire les risques de blocage.
- Modèles pour sites populaires : scrapers en un clic pour Amazon, eBay, Shopify, Zillow, et plus encore (voir notre blog pour les détails).
- Maintenance réduite : lorsque la mise en page d’un site change, le passage “AI Suggest Fields” peut souvent redétecter les champs, ce qui vous évite généralement de reconstruire un script de sélecteurs de zéro.
- Planification : configurez des extractions récurrentes pour un suivi continu (par exemple, des vérifications de prix quotidiennes).
- Prise en charge de 55 langues : extrayez et traduisez des données depuis presque n’importe où.
Et le meilleur ? Vous n’avez rien à connaître en HTML, CSS ou Python. Si vous savez utiliser un navigateur, vous savez utiliser Thunderbit.
Quelle solution de web scraping vous convient le mieux ?
Terminons par un guide de décision rapide :
| Votre situation | Meilleur outil |
|---|---|
| Scraper un site web statique et simple ; la configuration ne vous dérange pas | Selenium |
| Scraper un site moderne et dynamique ; vous voulez des résultats rapides | Playwright |
| Besoin de prendre en charge des navigateurs ou langages hérités | Selenium |
| Vous voulez une configuration facile, un débogage moderne et moins de code | Playwright |
| Vous n’êtes pas développeur ; vous voulez des données maintenant, sans code ni configuration | Thunderbit |
| Vous devez scraper plusieurs pages, sous-pages ou planifier des tâches | Thunderbit |
| Vous voulez exporter directement vers Excel, Sheets, Notion, Airtable | Thunderbit |
| Vous détestez déboguer des erreurs Python | Thunderbit |
Si vous êtes développeur, ou si vous aimez bricoler du code, Playwright et Selenium sont deux options puissantes. Mais si votre objectif est de mettre des données dans un tableau le plus vite possible, Thunderbit vous fera économiser des heures — voire des jours — de travail.
Commencer avec Thunderbit AI Web Scraper
Conclusion : un web scraping rapide et fiable, à votre manière
Le web scraping s’est démocratisé, et pour de bonnes raisons : les entreprises ont besoin de données pour rester compétitives, et elles en ont besoin maintenant. Playwright et Selenium sont tous deux passés de simples outils de test à des frameworks de scraping essentiels, chacun avec ses propres atouts. Selenium reste la valeur sûre pour les sites statiques et les environnements hérités ; Playwright est le choix moderne et rapide pour les pages dynamiques et interactives.
Mais voici mon conseil sincère, après des années dans le SaaS, l’automatisation et l’IA : si vous n’êtes pas là pour coder, ne perdez pas votre temps à vous battre avec des drivers, des sélecteurs et des astuces anti-bot. Avec Thunderbit’s AI Web Scraper, vous pouvez passer de “j’ai besoin de ces données” à “voilà mon fichier Excel” en quelques minutes — pas en plusieurs jours.
Alors, que vous soyez un pro de Python ou un utilisateur métier qui veut simplement des résultats, il existe une solution de scraping adaptée à vos besoins — et à votre patience. Essayez-les, voyez ce qui fonctionne pour votre flux de travail, et rappelez-vous : le meilleur scraper est celui qui vous fournit les données dont vous avez besoin, avec le moins de friction possible.
Et si vous vous retrouvez un jour à 2 h du matin à déboguer une erreur de driver Selenium, sachez simplement que Thunderbit sera toujours là, prêt à scraper en deux clics. Bon scraping.
Vous voulez en savoir plus sur le scraping sans code, l’extraction de données propulsée par l’IA et la façon dont Thunderbit peut aider votre équipe ? Consultez notre blog, ou commencez dès aujourd’hui avec l’extension Chrome Thunderbit.
P.-S. Si vous ne savez toujours pas quel outil utiliser, ou si vous voulez voir Thunderbit en action, rendez-vous sur notre chaîne YouTube pour des démonstrations, des conseils et, de temps en temps, une blague sur le web scraping. (Oui, nous en avons.)
Pour aller plus loin :
- Qu’est-ce que le data scraping et comment le faire en 2025
- Comment extraire des produits et des avis Amazon en 2025 grâce à l’IA
- Les meilleurs outils et logiciels de web scraping en 2025
Essayer l’Extracteur Web IA Get Started Free




