Si tu t’es déjà lancé dans l’automatisation d’un navigateur – que ce soit pour extraire des listes de produits, tester un parcours d’achat ou juste éviter de faire du copier-coller à la main – tu as sûrement entendu parler du match Playwright vs Puppeteer. Après plusieurs années à bidouiller l’automatisation SaaS, je peux te dire que choisir entre ces deux outils, c’est un peu comme choisir entre Batman et Iron Man : chacun a ses super-pouvoirs, ses petits défauts, et peut te sauver la mise (ou te casser les pieds) selon la mission.
Mais attention : l’automatisation des navigateurs évolue à la vitesse de l’éclair. De plus en plus d’entreprises collectent des données, automatisent leurs process et montent des systèmes intelligents. Et avec l’arrivée d’outils boostés à l’IA comme , même ceux qui ne codent pas peuvent s’y mettre. Alors, comment choisir l’outil qui te correspond ? On va décortiquer les vraies différences, les points communs et les alternatives no-code – sans le blabla marketing.
Playwright vs Puppeteer : c’est quoi et pourquoi c’est important ?
On commence par la base. Puppeteer est la bibliothèque Node.js open source de Google pour piloter Chrome ou Chromium. Imagine un robot qui clique, scrolle, tape et extrait des données – comme un humain, mais sans jamais se fatiguer. Lancé en 2017, il est vite devenu la référence pour extraire des sites dynamiques bourrés de JavaScript ().
Playwright, c’est la réponse de Microsoft à Puppeteer. Lancé en 2020 par certains des mêmes ingénieurs, Playwright va plus loin : il gère non seulement Chrome, mais aussi Firefox et Safari (WebKit), et plusieurs langages de programmation (). En clair : Playwright, c’est le petit frère surdoué de Puppeteer, qui fait tout pareil, mais sur plus de navigateurs et dans plus de langages.
Pourquoi ces outils sont-ils devenus incontournables ? Parce que les sites web modernes sont blindés de JavaScript, de scroll infini et d’éléments interactifs qui rendent les extracteurs classiques inutilisables. Les équipes commerciales, marketing, e-commerce ou opérations ont toutes besoin de solutions fiables pour extraire des données, tester des parcours ou automatiser des tâches web répétitives. C’est là que Playwright et Puppeteer font la différence.
Les points communs : Playwright vs Puppeteer pour l’automatisation
Même s’ils sont rivaux, Playwright et Puppeteer partagent pas mal de points forts :
- Origines JavaScript : Les deux sont avant tout des bibliothèques JavaScript/TypeScript (même si Playwright va plus loin, on y revient).
- Automatisation du navigateur : Ils permettent de piloter un navigateur : ouvrir des pages, cliquer, remplir des formulaires, faire des captures d’écran, etc.
- Gestion du contenu dynamique : Ils savent interagir avec des sites riches en JavaScript, parfaits pour extraire des applications web modernes.
- Actions utilisateur simulées : Besoin de te connecter, de scroller ou de cliquer sur « Charger plus » ? Les deux outils imitent le comportement humain.
- Mode headless ou visible : Exécution invisible sur un serveur (headless) ou visible en temps réel (headful) – à toi de choisir.
- Exécution de scripts : Possibilité d’exécuter du JavaScript personnalisé dans la page pour extraire exactement ce qu’il te faut.
- Contrôle réseau : Intercepter les requêtes, simuler des appareils ou des localisations – super pratique pour extraire du contenu régional ou mobile.
En résumé, ce sont de vrais couteaux suisses de l’automatisation web. Si tu veux extraire des données structurées d’un site dynamique, l’un ou l’autre fera le job – à condition d’être à l’aise avec le code.
Les différences majeures : Playwright vs Puppeteer pour le scraping et les tests
Allons dans le détail. Voici où Playwright et Puppeteer se distinguent :
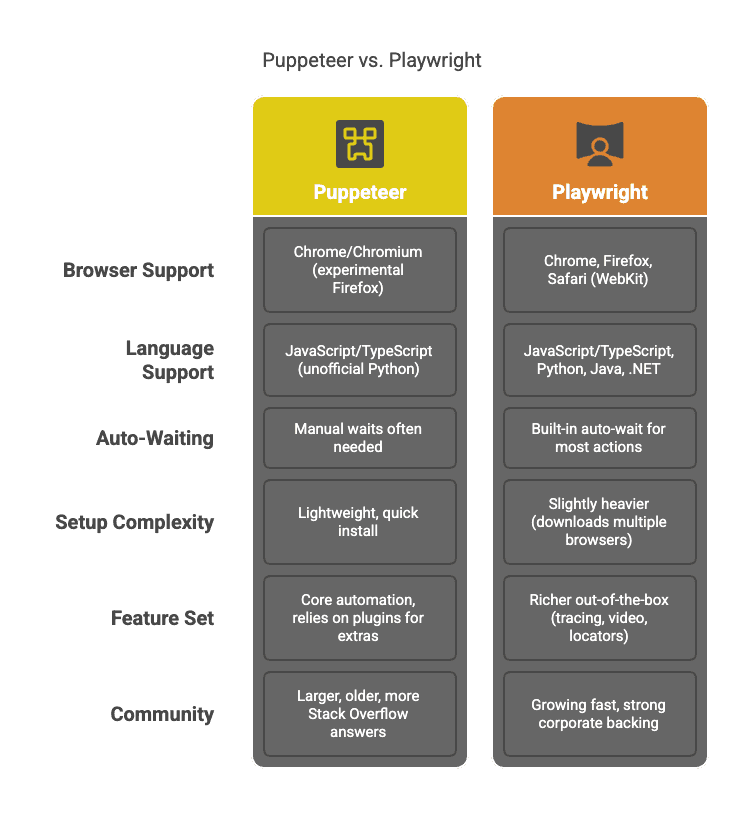
Quelques points à retenir :
- Compatibilité navigateurs : Puppeteer se concentre sur Chrome. Playwright permet d’automatiser Chrome, Firefox et Safari avec une seule API (). Si tu dois tester ou extraire sur plusieurs navigateurs (pour éviter la détection ou vérifier les différences), Playwright est le choix évident.
- Langages supportés : Puppeteer s’adresse aux fans de Node.js. Playwright parle aussi Python, Java et .NET ().
- Attente automatique : L’auto-wait de Playwright est un vrai plus pour les sites dynamiques. Plus besoin de multiplier les
waitForSelector: Playwright attend que les éléments soient prêts avant d’agir (). Puppeteer offre plus de contrôle manuel, mais aussi plus de risques d’erreurs. - Fonctionnalités : Playwright propose plus d’outils intégrés : interception réseau, test runner, tracing, etc. Puppeteer est plus simple, mais nécessite des plugins pour les cas avancés.
- Communauté : Puppeteer existe depuis plus longtemps, donc plus de ressources et de discussions en ligne. Mais la communauté Playwright grandit vite.
Quand choisir Puppeteer : les cas d’usage idéaux
Puppeteer est parfait si :
- Tu ne cibles que Chrome/Chromium : La plupart des besoins d’automatisation ne nécessitent pas d’autres navigateurs.
- Tu veux une installation rapide et légère : Un simple
npm installet c’est parti. - Tu aimes la simplicité : L’API est directe, tu contrôles chaque étape.
- Tu crées des scripts ponctuels : Pour des tâches rapides, la légèreté de Puppeteer est un vrai plus.
- Ton équipe maîtrise Node.js : Si tu vis en JavaScript, Puppeteer est naturel.
Exemples : extraire les prix d’un site marchand, automatiser une connexion, ou lancer des tests Chrome en CI.
Quand choisir Playwright : les cas d’usage idéaux
Playwright s’impose quand :
- Tu as besoin du multi-navigateurs : Extraire ou tester sur Chrome, Firefox et Safari avec un seul script ().
- Tu veux une automatisation avancée : L’auto-wait, l’API Locator et le tracing rendent Playwright robuste pour les sites complexes.
- Tu préfères Python, Java ou .NET : Support natif, pas besoin de rester sur Node.js.
- Tu fais du scraping à grande échelle : Playwright gère efficacement plusieurs contextes navigateurs, idéal pour le scraping ou les tests en parallèle.
- Tu veux anticiper l’avenir : Playwright évolue vite, soutenu par Microsoft et l’équipe d’origine de Puppeteer.
Exemples : extraire des parcours multi-étapes avec connexion et popups, tester des apps web sur plusieurs navigateurs, ou bâtir des pipelines de données fiables et scalables.
Les limites communes : les coûts cachés de Playwright et Puppeteer
C’est là que le costume de super-héros montre ses faiblesses. Playwright et Puppeteer partagent certains inconvénients, surtout à grande échelle :
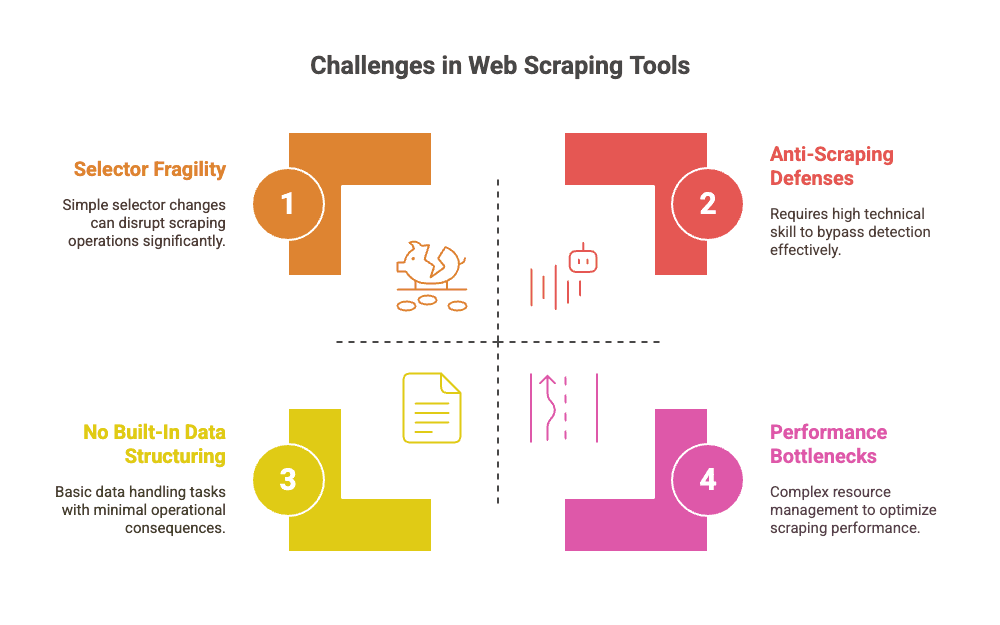
- Sélecteurs fragiles : Les sites changent. Une classe CSS modifiée, une mise en page revue, et ton script tombe en rade (). La maintenance devient un jeu sans fin.
- Maintenance manuelle : Les devs passent beaucoup de temps à corriger les sélecteurs, adapter la logique, contourner les anti-bots ().
- Problèmes de performance : Lancer de vrais navigateurs consomme des ressources. Pour des milliers de pages, il faut gérer des fermes de navigateurs, la parallélisation, et éviter les fuites mémoire ().
- Structuration des données absente : Ces outils livrent des données brutes. À toi de nettoyer, parser et exporter en CSV/Excel.
- Défenses anti-scraping : Par défaut, aucun des deux n’est furtif. Il faut des plugins ou du code maison pour éviter la détection, gérer les proxies ou résoudre les CAPTCHAs ().
- Courbe d’apprentissage pour les non-développeurs : Si tu n’es pas à l’aise avec le code, ces outils restent complexes.
En résumé : Playwright et Puppeteer sont puissants, mais leur coût (en temps et en maintenance) grimpe vite avec l’ampleur des besoins.
Playwright vs Puppeteer pour le scraping : comparaison concrète
Prenons un exemple classique : extraire des données produits sur un site e-commerce avec plusieurs pages et liens de détails.
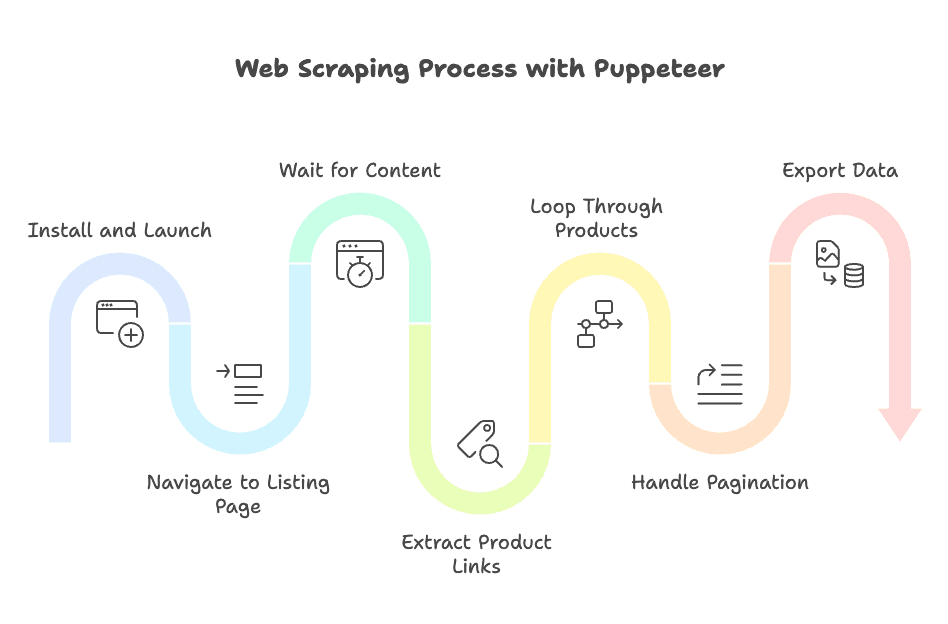
Avec Puppeteer
- Installation et lancement :
npm install puppeteer, puis lancement du navigateur headless. - Navigation vers la page de liste : Utilise
page.goto(). - Attente du contenu : Appel manuel à
waitForSelectorpour s’assurer que les produits sont chargés. - Extraction des liens produits : Utilise
$$evalpour récupérer les URLs. - Boucle sur les produits : Pour chaque lien, ouvre une nouvelle page, attends les sélecteurs, extrais les données, ferme la page.
- Gestion de la pagination : Vérifie manuellement le bouton « Suivant », clique et recommence.
- Export des données : Écris ta propre logique pour sauvegarder en CSV, JSON ou base de données.
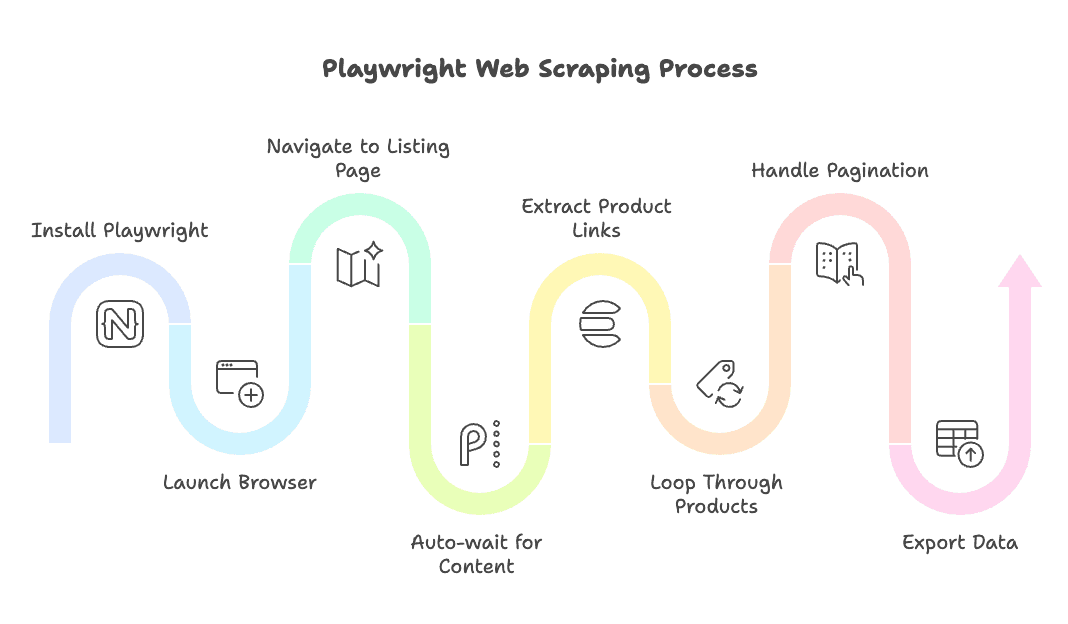
Avec Playwright
- Installation et lancement :
npm install playwright, puis lancement du navigateur (Chrome, Firefox ou Safari). - Navigation vers la page de liste : Utilise
page.goto(). - Attente automatique du contenu : Les actions Playwright (
page.click(),page.textContent(), etc.) attendent automatiquement les éléments. - Extraction des liens produits : Utilise l’API Locator ou
$$eval. - Boucle sur les produits : Ouvre de nouvelles pages ou réutilise-en une, extrais les données avec les attentes intégrées.
- Gestion de la pagination : Un simple
page.click('a.next-page')– l’auto-wait gère la navigation. - Export des données : À toi de structurer et sauvegarder les résultats.
En résumé : Les deux outils font le job, mais l’auto-wait et le support multi-navigateurs de Playwright rendent les scripts plus courts et moins fragiles. Puppeteer demande plus d’intervention, mais offre une transparence totale à ceux qui veulent tout contrôler.
L’essor du scraping boosté à l’IA : Thunderbit comme alternative no-code
C’est là que ça devient vraiment intéressant. Le retour que j’entends le plus souvent côté business : « Je veux juste les données. Pourquoi je devrais apprendre JavaScript ou surveiller mes scripts chaque semaine ? »
C’est exactement pour ça qu’on a créé . Thunderbit est une qui permet à n’importe qui – même le moins technique de l’équipe – d’extraire des sites en quelques clics. Pas de code, pas de sélecteurs, pas de galère de maintenance.
Comment ça marche ?
- Suggestion de champs par l’IA : L’IA de Thunderbit lit la page et propose les données à extraire – « Nom du produit », « Prix », « Note » – sans avoir à inspecter le HTML ou deviner les sélecteurs.
- Gestion automatique des sous-pages et de la pagination : Besoin d’extraire des pages de détails ou de parcourir 50 pages de résultats ? L’IA de Thunderbit s’en occupe ().
- Export partout : Télécharge les résultats vers Excel, Google Sheets, Airtable ou Notion en un clic.
- Structuration et enrichissement des données : Thunderbit peut résumer, catégoriser ou traduire les données à la volée ().
- Scraping en masse et planifié : Extrais des centaines d’URLs d’un coup, ou programme des extractions récurrentes – sans serveur ni cron job.
Thunderbit s’adresse aux utilisateurs métiers qui veulent des résultats, pas du code. Et oui, c’est gratuit pour les petits besoins.
Thunderbit vs Playwright vs Puppeteer : tableau comparatif
Voici un aperçu côte à côte des différences :
| Aspect | Puppeteer | Playwright | Thunderbit (IA No-Code) |
|---|---|---|---|
| Temps d’installation | Rapide pour dev Node.js | Rapide, multi-langage | Instantané (extension Chrome) |
| Navigateurs supportés | Chrome/Chromium | Chrome, Firefox, Safari | Basé sur Chrome |
| Langages supportés | JavaScript/TypeScript | JS, Python, Java, .NET | Aucun code requis |
| Facilité d’utilisation | Réservé aux devs | Réservé aux devs | Pour tous (point & clic) |
| Auto-wait | Attentes manuelles | Auto-wait intégré | Géré par l’IA, pas d’attente visible |
| Sous-pages/Pagination | Script manuel | Script manuel | Automatique via IA |
| Structuration des données | Parsing/export manuel | Parsing/export manuel | Structuré, prêt à l’export |
| Maintenance | Élevée (sélecteurs fragiles) | Élevée (sélecteurs fragiles) | Faible (l’IA s’adapte) |
| Scalabilité | Nécessite infra dev | Nécessite infra dev | Intégrée, assistée par le cloud |
| Coût | Gratuit (hors temps/dev/infra) | Gratuit (hors temps/dev/infra) | Freemium (gratuit pour petit usage) |
Pour aller plus loin, jette un œil au ou découvre comment Thunderbit gère .
Grâce à l’IA, Thunderbit t’épargne les scripts cassés, la maintenance manuelle et la complexité du code. C’est une vraie solution no-code pour les pros qui veulent des données, vite et bien.
Monter en puissance : quel outil pour ton entreprise ?
Alors, lequel choisir ? Voici mon avis sans filtre :
- Si tu as des développeurs, besoin de contrôle total et d’intégrer le scraping à tes systèmes : Playwright ou Puppeteer sont de bons choix. Playwright est plus flexible et tourné vers l’avenir, surtout pour le multi-navigateurs ou Python.
- Si tu veux donner la main à des équipes non techniques, réduire la maintenance et obtenir des résultats rapidement : Thunderbit change la donne (oui, je l’ai dit !). Parfait pour les équipes commerciales, marketing, e-commerce ou opérations qui veulent juste les données dans Excel ou Google Sheets.
- Entre les deux ? Beaucoup d’équipes combinent les deux : Thunderbit pour les tâches rapides et le prototypage, Playwright/Puppeteer pour les systèmes en production.
Petit pense-bête :
- À l’aise avec le code ? Playwright ou Puppeteer.
- Besoin du multi-navigateurs ou multi-langage ? Playwright.
- Envie de no-code, d’une mise en route express et de moins de maintenance ? Thunderbit.
- Extraction de millions de pages par mois ? Pense au coût infra : Thunderbit gère des milliers de pages, mais à très grande échelle, le code peut être plus rentable (si tu as les ressources dev).
- Besoin d’exporter vers des outils métiers ? Thunderbit s’intègre directement à Sheets, Airtable, Notion, etc.
Conclusion : bien choisir son outil d’automatisation web
L’automatisation des navigateurs n’a jamais été aussi accessible. Playwright et Puppeteer sont d’excellents outils pour les développeurs qui veulent contrôle et flexibilité. Playwright, avec son support multi-navigateurs et multi-langages, est idéal pour les nouveaux projets, tandis que la simplicité et la communauté de Puppeteer restent imbattables pour Chrome.
Mais à mesure que le web se complexifie et que les besoins métiers grandissent, les outils boostés à l’IA comme changent la donne (oui, encore !). Avec Thunderbit, tu extrais n’importe quel site en deux clics, gères sous-pages et pagination automatiquement, et exportes des données structurées où tu veux – sans code, sans prise de tête.
Si tu en as marre de réparer des scripts cassés ou que tu veux juste obtenir tes données et passer à autre chose, teste . Et si tu es un développeur qui aime bidouiller, Playwright et Puppeteer restent les Batman et Iron Man de l’automatisation web.
Au final, le meilleur outil est celui qui colle à ton équipe, ton workflow et ta tolérance à la maintenance. Fais le bon choix – et que tes sélecteurs ne cassent jamais !
Envie d’en savoir plus sur le scraping web, l’automatisation par IA ou comment démarrer avec Thunderbit ? Parcours notre , avec des guides sur , , et .
Et si un jour tu débogues un sélecteur cassé à 2h du matin, rappelle-toi : il existe une meilleure solution.
FAQ : Playwright vs Puppeteer vs Thunderbit
1. Quelle est la différence entre Playwright et Puppeteer ?
Playwright est la bibliothèque d’automatisation de Microsoft, compatible avec Chrome, Firefox et Safari, et plusieurs langages comme Python et Java.
Puppeteer est l’outil de Google, centré sur Chrome/Chromium et conçu pour Node.js. Les deux servent à automatiser les navigateurs pour le scraping, les tests et l’automatisation d’interface.
2. Pourquoi les développeurs choisissent-ils l’un ou l’autre ?
Utilise Puppeteer si tu cherches la légèreté et ne cibles que Chrome.
Opte pour Playwright si tu as besoin du multi-navigateurs, de l’auto-wait et de fonctionnalités avancées.
3. Qu’ont-ils en commun ?
- Contrôle du navigateur par le code
- Gestion des sites dynamiques et riches en JavaScript
- Simulation d’actions utilisateur (clic, saisie, etc.)
- Exécution headless ou visible
- Nécessitent des développeurs et une maintenance manuelle des scripts
4. Quels sont les inconvénients de Playwright et Puppeteer ?
- Scripts fragiles lors des changements de site
- Maintenance élevée (sélecteurs, temps d’attente, anti-bot)
- Pas d’outils intégrés pour structurer ou exporter les données
- Nécessitent une infrastructure technique pour l’échelle
- Peu adaptés aux non-développeurs
5. Qu’est-ce qui différencie Thunderbit ?
Thunderbit est une extension Chrome boostée à l’IA qui :
- Extrait les données sans code
- Gère automatiquement sous-pages et pagination
- Suggère les champs à extraire
- Exporte vers Sheets, Airtable, Notion
- Réduit la maintenance grâce à l’IA
6. Quel outil choisir ?
- Utilise Playwright pour le scraping ou les tests complexes et multi-navigateurs
- Utilise Puppeteer pour des scripts rapides et ciblés Chrome
- Utilise Thunderbit pour des résultats rapides, sans code ni maintenance