

Pour beaucoup de développeurs, l’aventure du web scraping commence par une envie toute simple : récupérer des infos produits sur un site concurrent, par exemple. Rapidement, BeautifulSoup s’impose comme la référence incontournable, mais les débuts peuvent paraître un peu techniques. Après quelques essais, réussir à faire un pip install beautifulsoup4 et à extraire un titre HTML, c’est souvent le déclic qui donne envie d’aller plus loin avec Python.
Si tu te lances dans l’extraction de données web, BeautifulSoup sera sûrement le premier outil dont tu entendras parler. Ce n’est pas un hasard : il est à la fois simple, puissant, et reste la référence pour l’extraction de données web en Python depuis plus de dix ans. Dans ce guide, je t’explique comment installer BeautifulSoup avec pip, je te montre les bases avec des exemples concrets, et je t’explique pourquoi il est toujours aussi apprécié des développeurs et analystes de données. Mais on parlera aussi de ses limites — et pourquoi de plus en plus d’équipes (surtout les non-développeurs) préfèrent aujourd’hui des solutions boostées à l’IA comme Thunderbit.
BeautifulSoup : c’est quoi et pourquoi c’est toujours un incontournable ?
BeautifulSoup vs. Extracteur Web IA : Comparaison complète Get Started Free
Revenons à la base : BeautifulSoup, c’est un « parseur HTML » super accessible pour Python. Tu lui donnes du HTML ou du XML, et il te renvoie une structure arborescente facile à explorer, à fouiller et à manipuler en Python. C’est un peu comme avoir des lunettes à rayons X pour décortiquer les pages web : toutes les balises et attributs deviennent des données exploitables.
Pourquoi BeautifulSoup reste-t-il aussi populaire ?
Même avec l’arrivée de frameworks plus récents, BeautifulSoup reste le point de départ pour la majorité des débutants Python. Il est téléchargé plus de 150 millions de fois chaque mois sur PyPI. Ce n’est pas juste un effet de mode : sur Stack Overflow, il y a plus de 32 000 questions taguées “beautifulsoup”, preuve d’une communauté active et d’un vrai soutien pour les nouveaux venus.
Quelques exemples d’utilisation :
- Extraire des infos produits sur des sites e-commerce (noms, prix, avis…)
- Récupérer des titres d’articles ou du contenu de blog pour l’analyse ou l’agrégation
- Analyser des tableaux ou annuaires pour obtenir des données structurées (ex : listes d’entreprises)
- Générer des leads en collectant des emails ou numéros de téléphone
- Surveiller des changements (prix, nouvelles offres d’emploi, etc.)
BeautifulSoup est particulièrement efficace sur les pages web statiques — là où les données sont directement dans le HTML. Il est flexible, tolère même le HTML mal fichu, et ne t’impose pas de structure rigide. C’est pour ça qu’en 2025, il reste le « premier amour » de beaucoup de scrapeurs Python (plus d’infos sur sa popularité).
Installer BeautifulSoup avec pip : la méthode la plus simple
C’est quoi pip et pourquoi l’utiliser ?
Si tu débutes avec Python, pip est le gestionnaire de paquets qui te permet d’installer des bibliothèques depuis le Python Package Index (PyPI). C’est un peu comme l’App Store, mais pour le code Python. Installer BeautifulSoup avec pip, c’est la méthode la plus rapide et la plus fiable pour commencer.
Petit rappel : le nom du paquet à installer est beautifulsoup4 (et pas beautifulsoup). Pense toujours à mettre le « 4 » pour avoir la version la plus récente.
Étape par étape : installation de BeautifulSoup
1. Vérifie ta version de Python
BeautifulSoup demande Python 3.7 ou plus. Pour vérifier :
python --version
ou
python3 --version
2. Installe BeautifulSoup4 avec pip
Ouvre ton terminal ou invite de commandes et tape :
pip install beautifulsoup4
Si tu as plusieurs versions de Python, essaie :
pip3 install beautifulsoup4
Sous Windows, tu peux aussi utiliser :
py -m pip install beautifulsoup4
3. (Optionnel mais conseillé) Installe un parseur
BeautifulSoup fonctionne de base avec "html.parser" (inclus dans Python), mais pour de meilleures perfs et une compatibilité maximale, installe aussi lxml et html5lib :
pip install lxml html5lib
4. (Optionnel) Installe Requests
BeautifulSoup ne télécharge pas les pages web, il ne fait qu’analyser le HTML. La plupart des gens utilisent la bibliothèque Requests pour récupérer les pages :
pip install requests
5. Vérifie que tout marche
Teste dans Python :
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
Si tu vois <title>Example Domain</title>, c’est tout bon !
Installer BeautifulSoup dans un environnement virtuel
Je te conseille toujours d’utiliser un environnement virtuel pour tes projets Python. Ça permet de garder tes dépendances bien rangées et d’éviter les conflits.
Comment faire :
python -m venv venv
# Sous Windows :
venv\Scripts\activate
# Sous macOS/Linux :
source venv/bin/activate
pip install beautifulsoup4 requests lxml html5lib
Tout ce que tu installes reste dans le dossier du projet. Fini les « pourquoi mon paquet a disparu ? ».
Autres méthodes d’installation (Conda, etc.)
Si tu utilises Anaconda, installe BeautifulSoup avec :
conda install beautifulsoup4
Et pour le parseur :
conda install lxml
Assure-toi juste que ton environnement conda est bien activé.
BeautifulSoup Python : premiers pas avec des exemples concrets
Passons à la pratique. Voici comment utiliser BeautifulSoup dans un script Python.
Exemple 1 : Récupérer une page web et extraire le titre
from bs4 import BeautifulSoup
import requests
url = "https://en.wikipedia.org/wiki/Python_(programming_language)"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# Récupérer le titre de la page
title_text = soup.title.string
print("Titre de la page :", title_text)
Ce script télécharge la page Wikipédia de Python, analyse le HTML et affiche le titre. Simple, non ?
Exemple 2 : Extraire tous les liens hypertextes
links = soup.find_all('a')
for link in links[:10]: # Affiche les 10 premiers liens
href = link.get('href')
text = link.get_text()
print(f"{text}: {href}")
Ça affiche le texte et l’URL des 10 premiers liens de la page.
Exemple 3 : Extraire les titres (headlines)
headings = soup.find_all('h2')
for h in headings:
print(h.get_text().strip())
Pour récupérer tous les titres <h2>, ce code suffit.
Exemple 4 : Utiliser les sélecteurs CSS
items = soup.select("ul.menu > li")
for item in items:
print(item.get_text())
La méthode select() permet d’utiliser des sélecteurs CSS comme sur le web.
Exemple 5 : Récupérer des attributs et des balises imbriquées
first_link = soup.find('a')
print(first_link['href']) # Accès direct (erreur si absent)
print(first_link.get('href')) # Accès sécurisé (renvoie None si absent)
Exemple 6 : Extraire tout le texte d’une page
text_content = soup.get_text()
print(text_content)
Ça récupère tout le texte brut de la page — super pratique pour une analyse rapide.
Tâches courantes avec BeautifulSoup pour débuter
Voici quelques opérations classiques avec BeautifulSoup :
-
Trouver un élément unique :
soup.find('div', class_='price') -
Trouver tous les éléments :
soup.find_all('p', class_='description') -
Récupérer le texte d’un élément :
element.get_text() -
Obtenir la valeur d’un attribut :
element.get('href') -
Utiliser des sélecteurs CSS :
soup.select('table.data > tr') -
Gérer les éléments manquants :
price = soup.find('span', class_='price') if price: print(price.get_text())
La syntaxe est claire, accessible aux débutants, et tolérante — même si le HTML est un peu fouillis (voir la doc).
Les limites de BeautifulSoup pour le web scraping aujourd’hui
Parlons maintenant des points faibles. BeautifulSoup est top pour les pages statiques et les petits projets, mais il a ses limites.
Voici les principaux inconvénients :
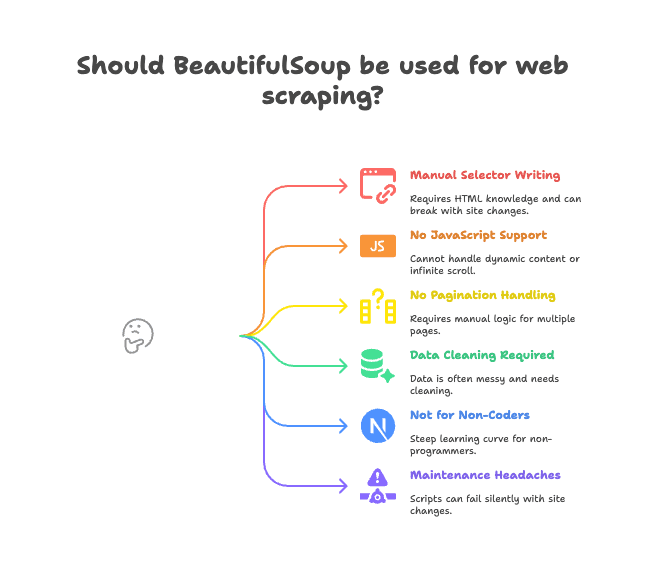
- Sélecteurs à écrire à la main : Il faut lire le HTML et écrire les bons chemins de balises/classes. Si le site change, ton script casse.
- Pas de support JavaScript : BeautifulSoup ne voit que le HTML envoyé par le serveur. Si le site charge des données via JavaScript (scroll infini, contenu dynamique), ça ne marchera pas (plus d’infos).
- Pas de gestion native de la pagination ou des sous-pages : Pour extraire plusieurs pages ou cliquer sur des détails produits, il faut tout coder soi-même.
- Nettoyage des données à faire soi-même : Les données récupérées sont souvent brutes — espaces en trop, caractères spéciaux, formats incohérents.
- Peu adapté aux non-développeurs : Si tu bosses en vente, marketing ou opérations sans coder, la courbe d’apprentissage est raide.
- Maintenance pénible : Si la structure du site change, ton script peut planter sans prévenir ou rater des données.
Pour beaucoup d’équipes, ces « petits » soucis deviennent vite de vrais freins à la productivité. J’ai vu plus d’un projet s’arrêter parce que le script de scraping demandait des corrections tout le temps.
Pourquoi de plus en plus d’équipes passent à Thunderbit pour l’extraction de données web
Essayez l’Extracteur Web IA Thunderbit Extrayez n’importe quel site web avec l’IA. Aucun code requis. Get Started Free
Quelle alternative ? C’est là que Thunderbit entre en scène. Thunderbit, ce n’est pas juste une bibliothèque Python : c’est une extension Chrome qui agit comme un assistant intelligent pour extraire des données web.
Comment ça marche ?
- Ouvre le site web à extraire.
- Clique sur « Suggérer les champs avec l’IA » — l’IA de Thunderbit analyse la page et propose les bonnes colonnes (ex : « Nom du produit », « Prix », « Localisation »).
- Tu peux ajuster les noms et types de colonnes si besoin.
- Clique sur « Extraire » : Thunderbit collecte, nettoie et structure les données pour toi.
- Exporte en un clic vers Excel, Google Sheets, Notion, Airtable ou ton outil préféré.
Aucun code. Aucun sélecteur. Zéro maintenance.
Les points forts de Thunderbit :
- Reconnaissance intelligente des champs : L’IA repère les données importantes, même si le HTML est compliqué.
- Gestion automatique des sous-pages et de la pagination : Thunderbit peut cliquer sur les pages produits ou gérer les liens « page suivante » tout seul.
- Nettoyage et formatage des données : Téléphones, emails, images… tout est standardisé automatiquement.
- Accessible aux non-développeurs : Si tu sais naviguer sur le web, tu peux utiliser Thunderbit.
- Export gratuit des données : Exporte vers Excel, Google Sheets, Airtable, Notion… sans limite pour les exports de base.
- Extraction planifiée : Programme tes extractions, Thunderbit s’occupe du reste.
Pour les pros, c’est une nouvelle façon de faire de l’extraction de données web. Plus besoin de scripts Python : il suffit de pointer, cliquer, et récupérer ses données.
Essayez gratuitement l’Extracteur Web IA Thunderbit
Thunderbit vs. BeautifulSoup : lequel choisir ?
Comparons :
| Fonctionnalité | BeautifulSoup (code Python) | Thunderbit (IA sans code) |
|---|---|---|
| Installation | Nécessite Python, pip, du code | Extension Chrome, installation en 2 clics |
| Vitesse d’accès aux données | Plusieurs heures pour un premier script | Quelques minutes par site |
| Gère le JavaScript | Non (outils supplémentaires requis) | Oui (fonctionne dans le navigateur) |
| Pagination/Sous-pages | À coder manuellement | Intégré, option à activer |
| Nettoyage des données | À coder soi-même | Automatique, via l’IA |
| Options d’export | À développer (CSV/Excel) | Export en un clic vers Sheets, Notion, etc. |
| Idéal pour | Développeurs, bidouilleurs | Utilisateurs métiers, non-codeurs |
| Coût | Gratuit (mais coûte du temps) | Freemium (gratuit pour petits besoins) |
Quand utiliser BeautifulSoup :
- Tu es à l’aise avec Python et tu veux tout contrôler.
- Tu extrais des sites statiques ou tu as besoin de logique personnalisée.
- Tu intègres le scraping dans un workflow Python plus large.
Quand utiliser Thunderbit :
- Tu veux des résultats rapides, sans coder.
- Tu dois extraire des sites dynamiques (JavaScript).
- Tu bosses en vente, marketing, opérations, ou tu ne veux pas coder.
- Tu veux exporter directement vers tes outils métiers.
Honnêtement, même en tant que développeur, il m’arrive d’utiliser Thunderbit pour récupérer vite fait des données sans lancer tout un projet Python. C’est un vrai gain de temps dans le navigateur.
Bonnes pratiques pour installer et utiliser BeautifulSoup
Si tu choisis BeautifulSoup, voici quelques conseils pour éviter les galères :
- Utilise toujours un environnement virtuel : Garde tes dépendances propres et évite les soucis de compatibilité.
- Mets pip et tes paquets à jour régulièrement :
pip install --upgrade pipetpip list --outdated. - Installe les parseurs recommandés :
pip install lxml html5libpour de meilleures perfs. - Structure ton code : Sépare la récupération et l’analyse pour faciliter le débogage.
- Respecte robots.txt et les limites de requêtes : N’abuse pas des sites — utilise
time.sleep()entre les requêtes. - Utilise des sélecteurs stables et explicites : Évite les chemins trop précis qui cassent facilement.
- Teste sur du HTML sauvegardé : Télécharge une page et teste ton code hors ligne pour éviter les requêtes répétées.
- Profite de la communauté : Stack Overflow est une mine d’or pour le dépannage.
Résoudre les problèmes d’installation de BeautifulSoup
Un souci ? Voici une checklist rapide :
- “ModuleNotFoundError: No module named bs4”
- As-tu installé
beautifulsoup4dans le bon environnement ? Essaiepython -m pip install beautifulsoup4.
- As-tu installé
- Mauvais paquet installé (
beautifulsoupau lieu debeautifulsoup4)- Désinstalle l’ancien :
pip uninstall beautifulsoup - Installe le bon :
pip install beautifulsoup4
- Désinstalle l’ancien :
- Avertissements de parseur ou erreurs Unicode
- Installe
lxmlethtml5lib, et précise le parseur :BeautifulSoup(html, "lxml")
- Installe
- Éléments introuvables
- Les données sont-elles chargées par JavaScript ? BeautifulSoup ne les verra pas. Vérifie le code source de la page, pas le DOM rendu par le navigateur.
- Erreurs pip ou permissions
- Utilise un environnement virtuel, ou essaie
pip install --user beautifulsoup4 - Mets pip à jour :
pip install --upgrade pip
- Utilise un environnement virtuel, ou essaie
- Problèmes avec Conda
- Essaie
conda install beautifulsoup4ou utilise pip dans ton environnement conda.
- Essaie
Toujours bloqué ? La doc officielle de BeautifulSoup et Stack Overflow couvrent quasiment tous les cas.
Conclusion : ce qu’il faut retenir pour installer et utiliser BeautifulSoup
-
BeautifulSoup est la bibliothèque Python la plus populaire pour le web scraping — simple, flexible, parfaite pour débuter.
-
Installe-la avec pip :
pip install beautifulsoup4 lxml html5lib requests -
Utilise un environnement virtuel pour garder ton installation propre.
-
BeautifulSoup est top pour les pages statiques et les petits projets, mais montre ses limites avec le JavaScript, la pagination et la maintenance.
-
Thunderbit est l’alternative moderne, boostée par l’IA, pour les utilisateurs métiers et non-développeurs : pas de code, pas de prise de tête, juste des données.
-
Choisis l’outil adapté à tes besoins :
- Développeurs et bidouilleurs : BeautifulSoup offre un contrôle total.
- Utilisateurs métiers et équipes : Thunderbit te donne des résultats, rapidement.
Teste les deux approches — parfois, la meilleure solution est celle qui te fait gagner le plus de temps.
Essayez gratuitement l’Extracteur Web IA Thunderbit Get Started Free
FAQ : Installer BeautifulSoup avec pip et plus encore
Q : Quelle est la différence entre beautifulsoup et beautifulsoup4 ?
R : Installe toujours beautifulsoup4 — c’est la version la plus récente et compatible. L’ancien paquet beautifulsoup n’est plus maintenu et ne marche pas avec Python 3. Pour l’import, utilise from bs4 import BeautifulSoup (plus d’infos ici).
Q : Dois-je installer lxml ou html5lib avec BeautifulSoup ?
R : Ce n’est pas obligatoire, mais c’est vivement conseillé. Ces parseurs rendent l’analyse plus rapide et plus fiable. Installe-les avec pip install lxml html5lib (pourquoi c’est important).
Q : BeautifulSoup peut-il gérer les sites web dynamiques (JavaScript) ?
R : Non — BeautifulSoup ne voit que le HTML statique. Pour le contenu généré par JavaScript, utilise des outils d’automatisation comme Selenium, ou une solution basée navigateur comme Thunderbit (plus d’infos).
Q : Comment désinstaller BeautifulSoup ?
R : Tape pip uninstall beautifulsoup4 dans ton terminal (étapes détaillées).
Q : Thunderbit est-il gratuit ?
R : Thunderbit propose un modèle freemium — gratuit pour les petits besoins, payant pour un usage intensif ou des fonctions avancées. Tu peux l’essayer gratuitement depuis ton navigateur (voir les tarifs).
Pour voir comment Thunderbit se compare à BeautifulSoup dans des cas concrets, jette un œil à notre comparatif détaillé. Et pour aller plus loin dans le web scraping, ne rate pas nos guides sur qu’est-ce que le data scraping et comment extraire des produits et avis Amazon.
Bonne extraction — et rappelle-toi, que tu sois expert Python ou que tu veuilles juste tes données dans un tableur, il existe un outil (et une communauté) pour t’aider à y arriver.




