Laissez-moi vous dire que, si j’avais un dollar à chaque fois que quelqu’un m’envoie un PDF rempli de « données importantes » en attendant que je le transforme magiquement en tableau, j’aurais probablement assez pour acheter une réserve de café à vie (et peut-être quelques extensions Chrome en plus). Les PDF sont partout : contrats de vente, catalogues produits, articles de recherche, factures, vous voyez le genre. Mais quand il s’agit d’utiliser réellement les données contenues dans ces fichiers ? Eh bien, c’est là que les choses deviennent intéressantes — comprenez : douloureuses.
J’en ai bavé moi aussi : copier, coller, reformater, et parfois simplement abandonner quand la mise en page partait en vrille ou que les images et les liens disparaissaient dans la nature. Mais la bonne nouvelle, c’est que le monde du scraping de PDF a radicalement changé, surtout avec l’essor des outils propulsés par l’IA. Si vous en avez assez de passer des heures à ressaisir des chiffres ou de perdre votre sang-froid à cause de tableaux cassés, vous êtes au bon endroit. Plongeons dans l’univers du scraping de PDF, voyons pourquoi c’est important, et comment des outils comme rendent enfin la tâche indolore.
Qu’est-ce que le scraping de PDF ? Comprendre les bases de l’extraction de données PDF
Commençons simplement : le scraping de PDF, c’est une façon élégante de dire « extraire automatiquement des données structurées à partir de fichiers PDF ». Un Extracteur Web de PDF est un outil (logiciel, extension ou service) qui récupère ce qui vous intéresse — texte, tableaux, images, liens, tout ce que vous voulez — et le place dans un format réellement exploitable, comme Excel, Google Sheets ou une base de données.
Mais voilà le piège : les PDF ne ressemblent pas à des pages web ou à des fichiers Excel. Ils s’apparentent plutôt à des impressions numériques, conçues pour s’afficher de la même manière partout, pas pour être facilement disséquées par une machine. Certains PDF contiennent du texte sélectionnable, d’autres ne sont que des images numérisées (ce qui nécessite de l’OCR, la reconnaissance optique de caractères), et la mise en forme peut être extrêmement variable. Scraper un PDF, ce n’est donc pas seulement copier du texte : c’est décoder un puzzle de mises en page, de polices et parfois même de métadonnées cachées.
Que peut-on extraire d’un PDF ?
- Texte brut (paragraphes, titres, etc.)
- Tableaux (pensez : données financières, spécifications produit, enquêtes)
- Images et graphiques (diagrammes, logos, signatures numérisées)
- Hyperliens et références (URL intégrées, citations)
- Données de formulaires (champs de formulaires remplissables)
- Métadonnées (auteur, titre, date de création, balises)
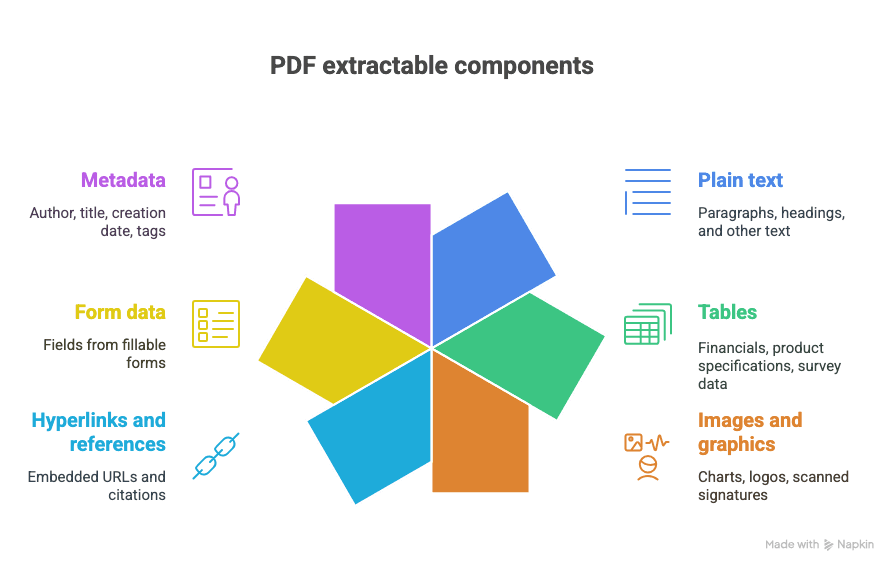
Et oui, il arrive que tout cela soit mélangé dans un seul et même document, glorieux et chaotique.
Pourquoi le scraping de PDF est important : cas d’usage concrets et bénéfices pour l’entreprise
Alors, pourquoi s’embêter à scraper des PDF ? Parce que tout le monde les utilise, et que les données qu’ils contiennent sont souvent cruciales pour l’entreprise. C’est là que le scraping de PDF prend tout son sens :
| Cas d’usage | Effort manuel | Avec un Extracteur Web PDF | Gain de temps et réduction des erreurs |
|---|---|---|---|
| Extraction de prospects commerciaux | Des heures à copier des contacts depuis des propositions ou des PDF d’événements, avec le risque d’en oublier | Récupère instantanément tous les prospects dans un tableur | 80 à 90 % plus rapide, moins d’erreurs |
| Données produit e-commerce | Des jours à saisir les spécifications produits depuis des PDF fournisseurs, avec des cauchemars de mise en forme | Extraction en masse vers CSV ou Sheets | Plus de 95 % de temps gagné, données cohérentes |
| Analyse de données de recherche | Des semaines à retranscrire des tableaux d’articles académiques, avec un fort risque de fautes de frappe | Extrait tableaux, références et même le texte numérisé | 80 % de temps gagné, précision accrue |
Mettons quelques chiffres sur la table :
- sont créés chaque année.
- utilisent le PDF comme format principal de partage d’informations.
- L’administration manuelle numérique (comme la saisie de données depuis des PDF) consomme .
- Les outils automatisés peuvent réduire les taux d’erreur de .
Si vous travaillez dans la vente, l’e-commerce ou la recherche, automatiser l’extraction de données PDF n’est pas juste un plus : c’est un avantage concurrentiel.
Méthodes traditionnelles de scraping de PDF : défis et limites
Soyons honnêtes : les anciennes méthodes pour extraire des données de PDF ne sont… pas terribles. Voici ce que la plupart d’entre nous ont essayé — et pourquoi c’est si frustrant :

1. Copier-coller manuel
- Points douloureux : la mise en forme se détraque, les tableaux deviennent un chaos, les images et les liens disparaissent, et il ne vous reste qu’un mal de tête.
- Coût en main-d’œuvre : élevé. Si vous avez 5 000 PDF, même à raison d’une minute chacun, cela représente plus de 80 heures de votre vie que vous ne récupérerez jamais.
- Taux d’erreur : 5 à 10 %. Fautes de frappe, lignes oubliées, suppressions accidentelles… vécu, testé, approuvé.
2. Convertir en Word/Excel puis nettoyer
- Points douloureux : cela fonctionne parfois pour des documents simples, mais les mises en page complexes ou les tableaux se retrouvent souvent déstructurés. Il faut ensuite tout nettoyer.
- Images/liens : généralement perdus au passage.
- Extraction ciblée : inutile d’y penser : vous récupérez tout le document, pas seulement ce qu’il vous faut.
3. Scripts personnalisés (Python, etc.)
- Points douloureux : il faut savoir coder (ou avoir quelqu’un sous la main à tout moment). Chaque nouveau format de PDF oblige à ajuster le script. Les PDF numérisés ? Bonne chance.
- Maintenance : élevée. À chaque fois qu’un fournisseur modifie son modèle de facture, votre script casse.
- Passage à l’échelle : réservé aux courageux (ou aux profils techniques).
4. Convertisseurs en ligne
- Points douloureux : pratiques pour un besoin ponctuel, mais il faut envoyer des documents sensibles sur un serveur tiers (bonjour les problèmes de conformité). Contrôle limité sur ce qui est extrait.
- Mise en forme : aléatoire. Vous pouvez passer plus de temps à corriger qu’à gagner du temps.
En résumé : les méthodes traditionnelles sont lentes, sujettes aux erreurs et passent mal à l’échelle. C’est pour cela que tant d’équipes finissent par « faire avec » — au prix d’une énorme perte de productivité.
Solutions modernes pour le scraping de PDF : du code aux outils no-code
Heureusement, on n’est plus coincés dans les âges sombres. Le marché a explosé avec des options de scraping de PDF plus intelligentes, plus rapides et plus simples à utiliser.
1. Bibliothèques de code (pour les développeurs)
- Exemples : , , .
- Points forts : très flexibles, automatisables pour de gros volumes, gratuites (open source).
- Points faibles : configuration longue, compétences en programmation requises, fragiles (cassent avec de nouveaux formats), support OCR/images limité.
2. Convertisseurs PDF en ligne
- Exemples : , , .
- Points forts : aucune installation, simples pour les non-techniciens, rapides pour les petits besoins.
- Points faibles : personnalisation limitée, enjeux de confidentialité, erreurs de mise en forme, limites de taille/nombre de pages.
3. Extracteurs PDF propulsés par l’IA
- Exemples : , Nanonets, Docparser.
- Points forts : aucun code nécessaire, gère texte/tableaux/images/liens, l’IA suggère quoi extraire, prise en charge des traitements par lots, intégration avec Sheets/Notion/Airtable.
- Points faibles : certains imposent des limites de crédits/pages, peuvent nécessiter une connexion Internet, et les documents complexes demandent parfois un petit temps d’apprentissage.
Comparer les outils de scraping de PDF : quelle approche correspond à vos besoins ?
| Outil/Méthode | Configuration | Idéal pour | Extrait | Personnalisable ? | Coût |
|---|---|---|---|---|---|
| Tabula (Tabula-py) | Moyenne (interface/code) | Tableaux dans les PDF | Tableaux | Partiellement | Gratuit |
| PDFMiner | Code requis | PDF riches en texte | Texte | Oui (code) | Gratuit |
| PyPDF2 | Code requis | Texte simple / métadonnées | Texte, métadonnées | Oui (code) | Gratuit |
| Smallpdf / convertisseur en ligne | Aucune (web) | Conversions rapides | Document complet (Word/Excel) | Non | Freemium |
| Thunderbit | Installation en 2 clics | Utilisateurs métier, équipes | Texte, tableaux, images, liens | Oui (prompts IA) | Freemium (16,5 $/mois pour Pro) |
Découvrez Thunderbit : l’extension Chrome Extracteur Web IA pour PDF
Parlons maintenant de l’outil qui m’a rendu la vie — et celle de nombreux utilisateurs métier — beaucoup plus simple : .
Qu’est-ce qui distingue Thunderbit ?
- Extraction en 2 clics : ouvrez un PDF dans Chrome, cliquez sur l’extension Thunderbit, et laissez l’IA faire le reste.
- Suggestions de champs pilotées par l’IA : la fonction « AI Suggest Fields » de Thunderbit lit votre PDF et recommande les colonnes que vous voulez probablement (comme « Nom », « Email », « Prix », etc.).
- Gestion des images, liens et tableaux : pas seulement du texte brut — Thunderbit peut extraire des images, des hyperliens et même appliquer l’OCR sur des documents numérisés.
- Prompts personnalisés : vous n’avez besoin que des numéros de téléphone ou des spécifications produit ? Ajoutez une instruction personnalisée et Thunderbit se concentrera uniquement dessus.
- Exportations partout : envoyez vos données directement vers Excel, Google Sheets, Airtable ou Notion. Fini les acrobaties avec les CSV.
- Scraping en lot et de sous-pages : vous avez une liste de PDF ou de liens ? Thunderbit peut tous les traiter d’un coup.
- Fiabilité de niveau professionnel : conçu pour la précision, la confidentialité et les workflows réels.
En bref, c’est comme avoir un stagiaire numérique qui adore faire de la saisie de données (et qui ne se fatigue jamais).
Comment extraire des données d’un PDF avec Thunderbit : guide étape par étape
Prêt à voir à quel point cela peut être simple ? Voici comment j’utilise Thunderbit pour transformer des PDF en données structurées et exploitables :
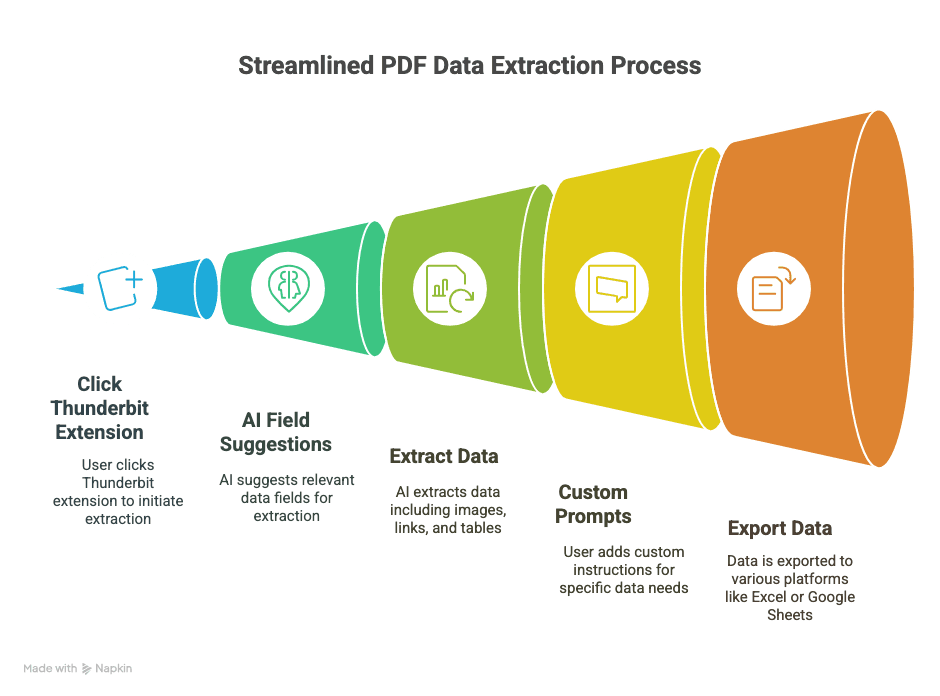
1. Installez Thunderbit
- Téléchargez .
- Inscrivez-vous (compte Google ou e-mail — quelques secondes suffisent).
2. Ouvrez votre PDF dans Chrome
- Ouvrez un PDF depuis un lien web ou faites glisser un PDF local dans un onglet Chrome.
3. Lancez Thunderbit sur le PDF
- Cliquez sur l’icône Thunderbit dans la barre d’outils de votre navigateur.
- Sélectionnez « AI Web Scraper » — Thunderbit détectera le PDF et se mettra au travail.
4. Laissez l’IA suggérer les champs
- Cliquez sur « AI Suggest Columns ».
- L’IA de Thunderbit analyse le PDF et recommande des colonnes (comme « Date », « Montant », « Nom du contact », etc.).
- Prévisualisez les données extraites dans un tableau directement dans l’extension.
5. Personnalisez si nécessaire
- Renommez les colonnes, supprimez les éléments superflus ou ajoutez les vôtres (par exemple « Durée de garantie » ou « URL du produit »).
- Pour les données délicates, sélectionnez du texte dans le PDF pour entraîner l’IA sur ce que vous voulez.
6. Choisissez votre format d’export
- Choisissez entre CSV, Google Sheets, Airtable ou Notion.
- Autorisez Thunderbit à se connecter (configuration unique).
7. Scrapez et exportez
- Cliquez sur « Scrape » ou « Export ».
- Thunderbit traite le PDF et envoie les données là où vous le souhaitez — généralement en quelques secondes.
C’est tout. Pas de code, pas de copier-coller, pas de drame.
Conseils pour une extraction précise des données PDF avec Thunderbit
- Vérifiez les champs suggérés par l’IA : elle est intelligente, mais un rapide coup d’œil permet de s’assurer que vous obtenez exactement ce qu’il vous faut.
- Gérez les tableaux complexes : pour les tableaux multi-pages ou à la mise en forme étrange, utilisez l’aperçu pour repérer les problèmes et ajuster les colonnes si nécessaire.
- Extrayez les images/liens : pensez à inclure ces champs si votre PDF en contient — Thunderbit peut les récupérer aussi.
- PDF numérisés : l’OCR intégré de Thunderbit est solide, mais plus le scan est propre, meilleurs seront les résultats.
- Prompts personnalisés : vous ne voulez que les emails ou les numéros de téléphone ? Ajoutez un prompt du type « Extraire toutes les adresses e-mail » et Thunderbit se concentrera dessus.
Scraping avancé de PDF : extraction d’images, de liens et de données personnalisées
Thunderbit ne se limite pas au texte brut. Voici comment en tirer encore plus de vos PDF :
- Images : extrayez des logos, graphiques ou tout élément visuel intégré. Thunderbit peut même appliquer l’OCR au texte présent dans les images.
- Hyperliens : récupérez toutes les URL ou références — idéal pour les articles de recherche ou les CV.
- Types de données personnalisés : utilisez des prompts IA pour extraire exactement ce qu’il vous faut (par exemple : « Trouve tous les SKU produits et leurs prix »).
- Synthèses et catégorisation : ajoutez une colonne et demandez à Thunderbit de résumer une section ou de catégoriser les données à la volée.
Analyser les données d’un PDF pour des besoins métier spécifiques
- Vente : extrayez uniquement les coordonnées d’un lot de propositions commerciales.
- E-commerce : récupérez les spécifications produits, les prix et les images depuis les catalogues fournisseurs.
- Recherche : récupérez des tableaux, des références et même des résumés d’articles académiques.
Et une fois les données en main, structurez-les pour faciliter l’analyse dans Excel, Google Sheets ou Notion — Thunderbit fait le gros du travail, et vous n’avez plus qu’à utiliser les résultats.
Exporter et utiliser vos données PDF : de l’extraction à l’action
Extraire les données, ce n’est que le début. Voici comment les mettre au service de votre activité :
- Options d’export : CSV, Excel, Google Sheets, Airtable, Notion — choisissez votre préférence.
- Conseils de mise en forme : utilisez les paramètres de type de colonne de Thunderbit (nombre, date, texte) pour des données propres et prêtes à l’analyse.
- Intégration au workflow : connectez vos données exportées à des CRM, des systèmes d’inventaire ou des tableaux de bord analytiques.
- Collaboration : partagez des feuilles Google Sheets ou des bases Airtable avec votre équipe — tout le monde travaille à partir des mêmes données à jour.
Le plus agréable ? Plus besoin de vous envoyer des tableurs par e-mail dans tous les sens ni de vous demander si une ligne a été oubliée.
Pièges courants du scraping de PDF et comment les éviter
Même avec les meilleurs outils, quelques pièges peuvent surgir. Voici ce que j’ai appris — parfois à mes dépens :
- Erreurs d’OCR : des scans flous ou des polices bizarres peuvent perturber même le meilleur OCR. Essayez d’utiliser les PDF les plus propres possible et vérifiez les champs critiques.
- Mises en page complexes : les tableaux à plusieurs colonnes ou imbriqués peuvent nécessiter un peu d’accompagnement manuel — utilisez la sélection manuelle ou les prompts de Thunderbit.
- Types de données : des nombres avec des virgules ou des dates dans des formats inhabituels ? Définissez le type de colonne avant l’export, ou nettoyez ensuite dans Excel/Sheets.
- Limites de taille / nombre de pages : PDF très volumineux ? Découpez-les en lots plus petits, ou utilisez le mode cloud de Thunderbit pour les traitements en série.
- « Hallucination » de l’IA : c’est rare, mais il peut arriver que l’IA devine un nom de colonne ou remplisse des données manquantes. Vérifiez toujours un échantillon, surtout pour les chiffres importants.
- Relecture manuelle : pour des données critiques, faites une validation rapide — les outils automatisés sont précis, mais un regard humain reste utile.
Et si vous vous heurtez à un mur, l’assistance et la communauté Thunderbit sont là pour vous aider.
Conclusion et points clés à retenir : faire du scraping de PDF un atout pour votre entreprise
Récapitulons. Extraire des données depuis des PDF était autrefois un cauchemar : lent, sujet aux erreurs, et franchement fastidieux. Mais avec des outils modernes comme , c’est désormais rapide, précis et — osons le dire — presque agréable.
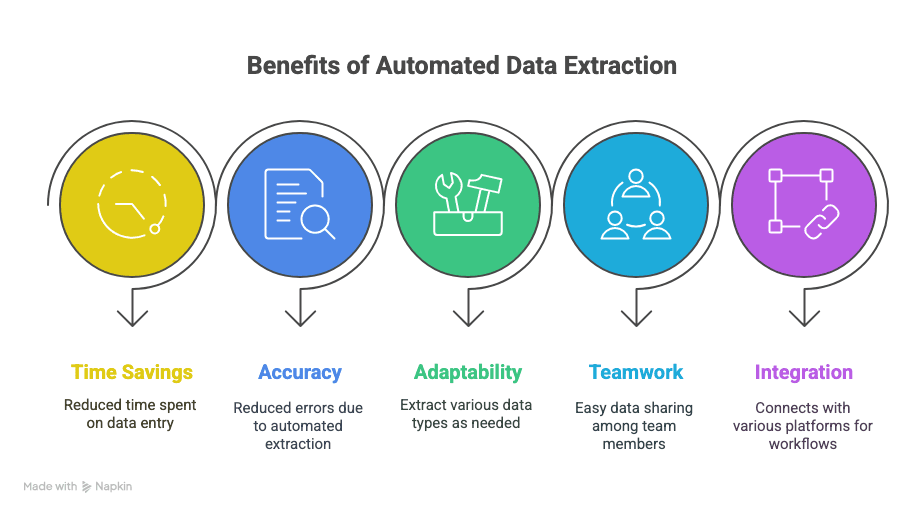
Voici ce que vous y gagnez :
- Du temps retrouvé : des heures, voire des semaines, économisées sur la saisie manuelle.
- Moins d’erreurs : l’extraction automatisée réduit les fautes de frappe et les lignes oubliées.
- De la flexibilité : extrayez exactement ce dont vous avez besoin — texte, tableaux, images, liens, tout y passe.
- De la collaboration : partagez les données instantanément avec votre équipe, où qu’elle se trouve.
- Des workflows plus intelligents : intégrez-vous à Sheets, Notion, Airtable et bien plus encore.
Prêt à essayer ? Téléchargez , lancez-la sur votre prochain PDF et voyez à quel point la vie peut être plus simple. Votre futur vous-même (et votre canal carpien) vous remerciera.
Pour plus de conseils et de guides, consultez le ou approfondissez avec .
Transformons ces maux de tête liés aux PDF en gains de productivité — un clic à la fois.
Shuai Guan, cofondateur et PDG, Thunderbit