Le web scraping n’est plus réservé aux codeurs et aux data scientists. Avec l’essor des outils sans code, presque tout le monde peut collecter des données sur des sites web — à condition de choisir le bon outil. ParseHub est l’un des noms les plus connus dans ce domaine et promet de rendre le web scraping accessible à tous. Mais tient-il vraiment cette promesse, surtout pour les débutants ? Et existe-t-il une meilleure alternative, plus simple, pour celles et ceux qui veulent des résultats rapides sans courbe d’apprentissage abrupte ?
Si vous envisagez parsehub pour votre prochain projet de données, ou si vous l’avez déjà essayé avant d’être frustré, vous êtes au bon endroit. J’ai passé des heures à analyser les avis utilisateurs, à tester des fonctionnalités et à comparer ParseHub avec des options plus récentes et plus conviviales — en particulier , l’extension Chrome propulsée par l’IA qui devient vite l’une des préférées des utilisateurs métier, des marketeurs et de toute personne qui veut extraire des données en quelques clics. Dans cet article, je vais détailler ce que propose ParseHub, pour qui il est le plus adapté, où il montre ses limites et pourquoi Thunderbit pourrait être le meilleur choix pour la plupart des utilisateurs non techniques en 2025.
Qu’est-ce que ParseHub ?
ParseHub est une entreprise basée à Toronto, fondée en 2013, qui s’est forgé une réputation d’outil de web scraping sans code puissant. L’idée de base est simple : au lieu d’écrire du code, vous utilisez une interface visuelle pour sélectionner les données souhaitées sur n’importe quel site web. L’application de bureau ParseHub (disponible sur Windows, Mac et Linux) vous permet d’ouvrir une page, de cliquer sur les éléments à extraire, puis de laisser l’outil faire le gros du travail — extraction des données et export dans des formats comme CSV ou JSON.
Principaux produits et fonctionnalités :
- Extraction visuelle par pointage-clic : sélectionnez directement les éléments de données sur la page.
- Prise en charge du contenu dynamique : gère AJAX, formulaires, connexions et défilement infini.
- Planification dans le cloud : lancez des extractions à intervalle régulier depuis les serveurs de ParseHub.
- Rotation automatique des IP : aide à éviter les blocages par les sites web.
- Sélecteurs avancés : utilisez XPath ou des expressions régulières pour les extractions complexes.
- API REST et webhooks : intégrez l’outil à d’autres applications ou automatisez des workflows.
- Multiplateforme : fonctionne sur Windows, Mac et Linux.
L’objectif de ParseHub est de rendre l’extraction de données web accessible aux non-codeurs, tout en offrant assez de puissance pour les utilisateurs plus avancés qui veulent automatiser des tâches de scraping complexes.
Pour qui ParseHub est-il conçu ?
ParseHub se présente comme une solution sans code pour toute personne ayant besoin de données web sans vouloir écrire de scripts. En pratique, son public principal comprend :
- Les marketeurs qui suivent les prix des concurrents ou les fiches produits.
- Les chercheurs qui collectent des avis, des actualités ou des données académiques.
- Les analystes de données qui ont besoin de données structurées provenant du web.
- Les utilisateurs métier qui veulent automatiser des tâches répétitives de collecte de données.
Les développeurs utilisent parfois ParseHub pour des tâches rapides ou pour automatiser des extractions récurrentes, mais son vrai point fort se situe auprès des débutants et des utilisateurs intermédiaires — des personnes qui ont besoin de données mais peu ou pas d’expérience en programmation. Si vous êtes marketeur, agent immobilier ou dirigeant de petite entreprise et que vous souhaitez simplement envoyer des données dans un tableur, ParseHub est censé être un bon choix.
Tarifs de ParseHub
Le prix est un facteur important dans le choix d’un Extracteur Web, surtout si vous débutez ou travaillez en petite équipe. Voici comment se répartissent les formules de ParseHub :

- Formule gratuite :
- Jusqu’à 5 projets publics (vos extracteurs sont visibles par la communauté)
- Jusqu’à 200 pages par exécution (environ 200 pages en 40 minutes)
- Assistance limitée, données conservées 14 jours
- Idéale pour de petits projets ponctuels ou pour tester l’outil
- Formule Standard (189 $/mois) :
- 20 projets privés
- Jusqu’à 10 000 pages par exécution (200 pages en environ 10 minutes)
- Planification, rotation des IP, enregistrement des fichiers sur Dropbox/S3
- Assistance standard
- Formule Professional (599 $/mois) :
- 120 projets privés
- Pages illimitées par exécution (200 pages en moins de 2 minutes)
- Conservation des données pendant 30 jours, assistance prioritaire
- Entreprise (ParseHub Plus) :
- Tarification personnalisée
- Extraction « clé en main » par l’équipe ParseHub
- Responsable de compte dédié, fonctionnalités personnalisées
La formule gratuite est suffisamment généreuse pour de petits projets, mais si vous devez extraire des milliers de pages ou garder des projets privés, il faudra passer à une formule payante — et les offres payantes restent clairement onéreuses par rapport à d’autres outils.
Avis des utilisateurs sur ParseHub
Pour mieux comprendre les performances de ParseHub, j’ai étudié les avis publiés sur et . Les notes globales sont solides — 4,3/5 sur G2 et 4,5/5 sur Capterra — mais les commentaires écrits racontent une histoire plus nuancée.
Ce que les utilisateurs apprécient
- Aucun code requis : le grand avantage de ParseHub est qu’il n’est pas nécessaire d’écrire du code. Les utilisateurs aiment pouvoir pointer et cliquer pour sélectionner les données, ce qui rend le web scraping accessible aux non-programmeurs.
- Puissant pour les tâches complexes : les utilisateurs avancés apprécient des fonctionnalités comme les expressions régulières, XPath et la gestion du contenu dynamique. ParseHub peut gérer des tâches de scraping difficiles qui seraient pénibles à faire manuellement.
- Formule gratuite : de nombreux avis soulignent que l’offre gratuite est un excellent moyen de tester l’outil ou de gérer de petits projets.
- Prise en charge multiplateforme : les utilisateurs Mac et Linux apprécient que ParseHub ne soit pas réservé à Windows.
- Support réactif : plusieurs utilisateurs mentionnent une équipe d’assistance utile, surtout pour le dépannage.
- Débogage visuel : la possibilité de voir des captures d’écran de chaque étape aide à comprendre ce qui ne va pas.
Les limites de ParseHub
1. Courbe d’apprentissage abrupte
Malgré son positionnement sans code, ParseHub n’est pas aussi adapté aux débutants qu’il le prétend. Beaucoup d’utilisateurs disent qu’il est difficile à apprendre, surtout au-delà des bases. Un avis résume très bien la situation : « Il était difficile à apprendre et à mettre en œuvre. Créer un extracteur pour un site donné prend 1 à 3 heures quand on débute. » C’est un gros investissement en temps si vous voulez simplement récupérer des données rapidement.
L’interface peut sembler lourde et peu intuitive, surtout pour les tâches complexes. Certains utilisateurs disent avoir dû recommencer plusieurs fois pour obtenir le bon résultat, et les tutoriels ne couvrent que les bases. Si vous souhaitez extraire un site compliqué, vous devrez peut-être entrer dans des notions avancées comme XPath ou la logique de navigation entre les pages — des sujets qui peuvent intimider les personnes non techniques.
2. Pas idéal pour les tout nouveaux débutants
Même les utilisateurs qui ont fini par maîtriser ParseHub reconnaissent que la courbe d’apprentissage est « assez longue ». Pour les vrais débutants, le processus peut être écrasant. La documentation est correcte pour les projets simples, mais en cas de blocage, vous pouvez vous retrouver sans guide clair. Un avis regrettait l’absence d’une base de connaissances plus complète pour les techniques avancées, tandis qu’un autre expliquait avoir eu besoin du support pour « montrer les astuces ».
3. Dépannage et gestion des erreurs
Le web scraping est naturellement délicat, et lorsqu’un problème survient dans ParseHub, la cause n’est pas toujours claire. Les messages d’erreur peuvent être vagues, et les utilisateurs doivent souvent deviner quoi ajuster. Ce processus d’essais-erreurs peut être frustrant et chronophage. Certains ont décrit ParseHub comme « la plus grande perte de temps » après avoir passé des heures à essayer de faire fonctionner un projet avant d’abandonner, épuisés.
4. Limites de la formule gratuite
Même si l’offre gratuite est appréciée, la limite de 200 pages est trop faible pour beaucoup d’utilisateurs. Certains aimeraient au moins 500 ou 1 000 pages. La version gratuite est aussi plus lente, et si vous devez extraire rapidement un gros site, vous devrez passer à une formule supérieure. Les utilisateurs gratuits n’ont accès qu’au support communautaire, ce qui peut poser problème si vous êtes bloqué et avez besoin d’aide rapidement.
5. Prix
Le passage du gratuit au payant est important. À 189 $/mois pour la formule Standard, ParseHub représente un investissement conséquent — surtout pour des particuliers ou de petites équipes. Certains utilisateurs estiment que le prix n’est pas justifié, sauf si vous faites du scraping à grande échelle.
Points clés de l’analyse de ParseHub
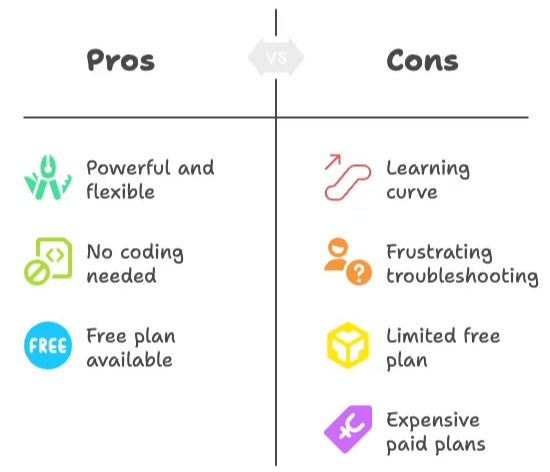
- ParseHub est puissant et flexible, surtout pour les tâches de scraping complexes.
- Aucun codage requis, mais la courbe d’apprentissage est bien réelle — surtout pour les débutants.
- Le dépannage peut être frustrant, avec des messages d’erreur vagues et peu de conseils pour les tâches avancées.
- La formule gratuite est utile pour les petits projets, mais les limites arrivent vite.
- Les formules payantes sont chères, plaçant ParseHub dans une catégorie premium.
Si vous êtes un utilisateur non technique qui veut simplement obtenir des données vite et facilement, ParseHub n’est peut-être pas aussi simple qu’il y paraît au premier abord. Le temps nécessaire pour apprendre l’outil — et la frustration quand les choses se passent mal — sont des points de douleur fréquents.
Présentation de Thunderbit : l’Extracteur Web IA le plus simple pour tous
Thunderbit est une conçue pour les utilisateurs métier, les marketeurs, les agents immobiliers, les équipes e-commerce et toute personne qui veut extraire des données de sites web — sans prise de tête technique. Voici ce qui distingue Thunderbit :
Thunderbit en un coup d’œil
- Extraction alimentée par l’IA : cliquez simplement sur « Suggérer les colonnes avec l’IA » et l’IA de Thunderbit détermine la meilleure façon d’extraire les données de n’importe quel site web. Pas besoin de manipuler des sélecteurs ou des XPath.
- Extraction en 2 clics : sélectionnez vos colonnes, cliquez sur « Extraire » et c’est terminé. Aussi simple que ça.
- Extraction de sous-pages : l’IA de Thunderbit peut visiter automatiquement des sous-pages (comme des fiches produit ou des pages de profil) et enrichir votre tableau de données.
- Modèles d’extraction instantanés : pour des sites populaires comme Amazon, Zillow, Instagram et Shopify, vous pouvez exporter les données en un clic grâce à des modèles préconfigurés.
- Export de données gratuit : exportez vos données extraites vers Excel, Google Sheets, Airtable ou Notion — sans frais supplémentaires.
- Remplissage automatique IA (totalement gratuit) : utilisez l’IA pour remplir des formulaires en ligne et automatiser des workflows. Sélectionnez simplement le contexte et appuyez sur Entrée.
- Extracteur programmé : configurez des extractions automatiques à intervalles planifiés — il suffit de décrire l’heure et de saisir les URL.
- Extracteurs d’e-mail, de téléphone et d’images : extrayez des e-mails, numéros de téléphone ou images de n’importe quel site web en un clic (gratuitement).
- Analyseur d’images/de documents : extrayez des tableaux depuis des PDF, Word, Excel ou des images. Importez votre document, laissez l’IA structurer les données, puis cliquez sur « Extraire ».
- Aucun code, aucune installation : tout fonctionne dans votre navigateur — pas d’application de bureau, pas de galère d’installation.
Thunderbit est conçu pour la rapidité et la simplicité. Si vous avez déjà été frustré par le processus d’installation de ParseHub ou passé des heures à dépanner, vous allez apprécier la façon dont Thunderbit fonctionne simplement.
Comment Thunderbit résout les points de friction de ParseHub
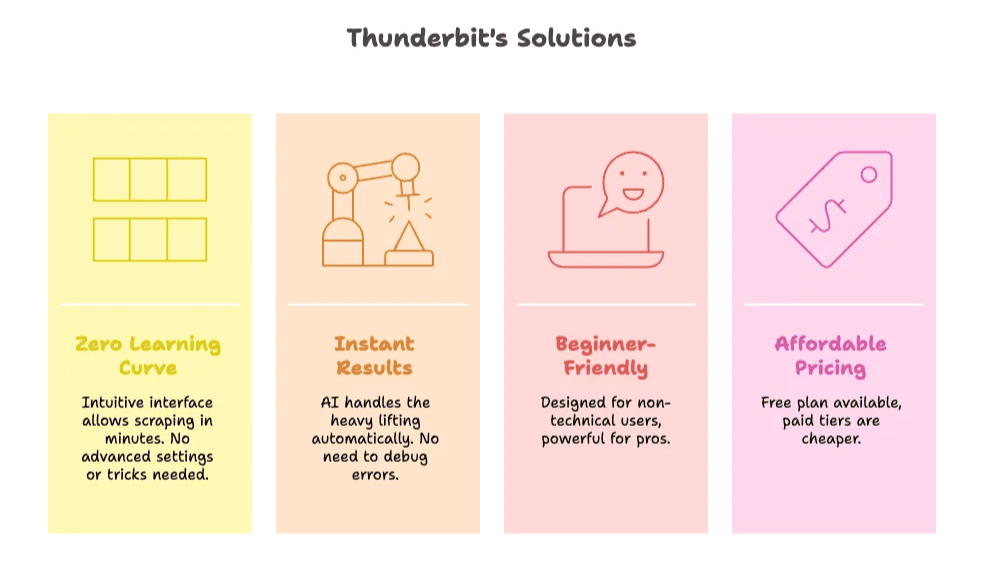
- Courbe d’apprentissage quasi nulle : l’interface de Thunderbit est si intuitive que vous pouvez passer de zéro à l’extraction en quelques minutes. Pas de tutoriels complexes, pas de réglages avancés, pas d’« astuces » à apprendre.
- Résultats immédiats : l’IA fait le gros du travail, vous n’avez donc pas à bidouiller des sélecteurs ni à déboguer des erreurs.
- Vraiment pensé pour les débutants : conçu pour les utilisateurs non techniques, mais assez puissant pour les pros.
- Tarifs abordables : les formules Thunderbit commencent gratuitement, et les offres payantes coûtent une fraction de celles de ParseHub.
Tarifs de Thunderbit
Thunderbit utilise un système simple de crédits : 1 crédit = 1 ligne de sortie. Voici la grille des formules :
| Formule | Prix mensuel | Prix annuel (par mois) | Crédits (mensuels) |
|---|---|---|---|
| Gratuit | Gratuit | Gratuit | 6 pages |
| Starter | 15 $ | 9 $ | 500 |
| Pro 1 | 38 $ | 16,5 $ | 3 000 |
| Pro 2 | 75 $ | 33,8 $ | 6 000 |
| Pro 3 | 125 $ | 68,4 $ | 10 000 |
| Pro 4 | 249 $ | 137,5 $ | 20 000 |
Vous pouvez . L’offre gratuite permet d’extraire 6 pages (quel que soit le nombre de lignes par page), et les formules payantes sont bien plus accessibles que le point d’entrée à 189 $/mois de ParseHub.
Thunderbit vs ParseHub : comparaison côte à côte
Voici un tableau rapide pour comparer Thunderbit et ParseHub sur les critères qui comptent le plus pour les utilisateurs non techniques :
| Fonctionnalité | Thunderbit | ParseHub |
|---|---|---|
| Extraction visuelle sans code | ✅ – L’IA suggère les colonnes, configuration en 2 clics | ⚖️ – Interface visuelle, mais courbe d’apprentissage plus abrupte |
| Extraction alimentée par l’IA | ✅ – L’IA gère les sélecteurs, les sous-pages et la structure | ❌ – Sélection manuelle, options avancées nécessitant XPath/regex |
| Extraction de sous-pages | ✅ – L’IA visite automatiquement les sous-pages | ⚙️ – Mais nécessite une configuration manuelle |
| Modèles instantanés | ✅ – En 1 clic pour Amazon, Zillow, Instagram, Shopify, etc. | ❌ – Chaque projet doit être créé manuellement |
| Export de données gratuit | ✅ – Excel, Google Sheets, Airtable, Notion | ✅ – CSV, JSON, Excel |
| Extracteurs d’e-mail/de téléphone/d’images | ✅ – En 1 clic, totalement gratuits | ❌ |
| Analyse de fichiers/images | ✅ – Extraction de tableaux depuis PDF, Word, Excel, images | ❌ |
| Extraction planifiée | ✅ – Configuration simple en langage naturel | 💳 – Réservée aux formules payantes |
| Plateforme | 🌐 – Extension Chrome (fonctionne sur tout OS avec Chrome) | 💻 – Application de bureau (Windows, Mac, Linux) |
| Courbe d’apprentissage | 🟢 – Minime – conçue pour les vrais débutants | 🔴 – Abrupte dès qu’on dépasse les bases |
| Support | 💬 – E-mail, chat, base de connaissances en développement | 👫 – Communauté (gratuit), standard/prioritaire (payant) |
| Formule gratuite | ✅ – 6 pages par mois, toutes les fonctionnalités incluses | ✅ – 200 pages par exécution, support limité |
| Prix de départ des formules payantes | 15 $/mois (9 $/mois à l’année) | 189 $/mois |
Conclusion : Thunderbit est le meilleur choix pour les utilisateurs non techniques
Après avoir passé des heures à comparer ParseHub et Thunderbit, le verdict est clair : si vous êtes un utilisateur non technique qui veut extraire des données web rapidement, facilement et à moindre coût, est la meilleure option.
ParseHub est puissant, mais il s’accompagne d’une courbe d’apprentissage abrupte, d’un dépannage frustrant et d’un prix élevé pour les formules payantes. Pour les débutants ou les utilisateurs métier qui veulent simplement envoyer des données dans un tableur sans casse-tête technique, Thunderbit est un meilleur choix. Son flux de travail alimenté par l’IA et en 2 clics vous permet de passer d’un site web à Excel en quelques minutes, pas en quelques heures. En plus, avec des fonctions comme l’extraction de sous-pages, les modèles instantanés et l’export de données gratuit, vous avez tout ce qu’il faut — sans la complexité.
FAQ
1. Quelles sont les principales différences entre ParseHub et Thunderbit ?
ParseHub est un Extracteur Web sans code puissant, mais sa courbe d’apprentissage est abrupte et ses formules payantes sont coûteuses. , en revanche, utilise l’IA pour rendre l’extraction vraiment accessible aux débutants, avec une extraction en 2 clics, des modèles instantanés et des tarifs bien plus abordables. Pour la plupart des utilisateurs non techniques, Thunderbit est plus rapide, plus simple et moins frustrant.
2. Comment Thunderbit rend-il le web scraping plus facile pour les débutants ?
La fonctionnalité « Suggérer les colonnes avec l’IA » de Thunderbit détecte automatiquement la meilleure façon d’extraire les données d’un site web. Il vous suffit de cliquer sur « Extraire », et l’IA s’occupe du reste — inutile d’apprendre les sélecteurs, les XPath ou les réglages avancés. L’outil est conçu pour être utilisable par tout le monde, même sans aucune expérience technique.
3. Thunderbit peut-il gérer des tâches de scraping complexes comme les sous-pages ou les PDF ?
Absolument ! L’IA de Thunderbit peut visiter des sous-pages (comme des fiches produit ou des profils) et enrichir automatiquement votre tableau de données. Elle permet aussi d’extraire des tableaux depuis des PDF, Word, Excel et des images — il suffit d’importer votre document et de laisser l’IA faire le travail. Pour en savoir plus sur ces fonctionnalités, consultez le .
En savoir plus