
La semaine dernière, j’ai passé tout un après-midi à essayer de faire remplir un formulaire fournisseur à un agent IA sur un portail protégé par connexion. Trois heures plus tard, j’avais un message d’erreur « Connection Refused », mon VPS n’avait plus de mémoire, et j’envisageais sérieusement de tout faire à la main.
Franchement, c’est un peu le kit de démarrage d’OpenClaw browser automation. L’outil peut naviguer sur des pages, extraire des données, remplir des formulaires et enchaîner des workflows complexes à partir d’instructions en anglais courant — c’est vraiment impressionnant. Mais l’écart entre « ça a l’air génial » et « ça fonctionne vraiment sur ma machine » est là où la plupart des gens bloquent.
J’ai beaucoup travaillé des deux côtés de cette frontière, à la fois en développant des outils d’automatisation chez Thunderbit et en testant ce que l’écosystème open source peut offrir. Ce guide est celui que j’aurais voulu avoir : un vrai pas-à-pas de configuration, le choix du mode navigateur qui piège tout le monde, une méthode native Windows (car WSL ne devrait pas être un prérequis), un guide de survie anti-bot, de vrais exemples de résultats, les erreurs courantes avec de vrais correctifs, et un regard honnête sur les cas où OpenClaw est le bon outil — et ceux où il est trop lourd.
Essayez Thunderbit pour extraire des données web sans effort
Extrayez des données de n’importe quel site avec l’IA Get Started Free
Qu’est-ce qu’OpenClaw Browser Automation ?
OpenClaw est une plateforme d’agents IA gratuite et open source (licence MIT) capable de contrôler un navigateur à votre place. Au lieu d’écrire des scripts Selenium ou du code Puppeteer, vous décrivez ce que vous voulez en langage naturel — « Va sur cette page et extrait tous les noms et prix des produits » — puis l’IA détermine comment procéder. Elle s’appuie sur un système de captures numérotées : l’agent identifie les éléments de la page, leur attribue des numéros de référence et interagit avec eux étape par étape.
L’architecture repose sur trois éléments — c’est pour cela que la configuration demande plus qu’une simple extension :
- Gateway (VPS/serveur) : le « cerveau » qui traite vos instructions et se connecte aux LLM. Il écoute par défaut sur le port 18789.
- Node Host (machine locale) : un relais qui permet au Gateway d’envoyer des instructions de navigation à votre Chrome local. Il est connecté via un tunnel sécurisé comme Tailscale.
- Extension Chrome (Browser Relay) : elle donne à l’agent un contrôle direct sur les onglets de votre navigateur réel.
D’autres ports interviennent aussi : Control Service (18791), CDP Relay (18792) et CDP de navigateur géré (18800–18899, avec prise en charge jusqu’à 100 profils parallèles).
Oui, ça fait beaucoup d’éléments. Mais une fois que vous comprenez le rôle de chacun, tout devient logique. Imaginez une voiture télécommandée : le Gateway est la télécommande, le Node Host est le signal radio, et l’Extension Chrome est la voiture elle-même.

Pourquoi OpenClaw Browser Automation est important pour les équipes métier
Les travailleurs du savoir passent jusqu’à 60 % de leur temps sur des tâches administratives routinières au lieu de se concentrer sur des missions à forte valeur ajoutée, dont 1,8 heure par jour rien que pour chercher et rassembler de l’information. Smartsheet a constaté que plus de 40 % des salariés consacrent au moins un quart de leur semaine à des tâches manuelles et répétitives. La simple saisie manuelle coûte aux entreprises américaines environ 8 500 $ par employé et par an.
C’est précisément le problème qu’OpenClaw browser automation cherche à résoudre. En pratique, cela correspond à des workflows métiers très concrets :
| Cas d’usage | Ce que fait OpenClaw | Résultat métier |
|---|---|---|
| Génération de leads | Extrait les coordonnées depuis des annuaires et pages d’entreprise | Pipeline commercial alimenté plus vite |
| Veille tarifaire concurrentielle | Parcourt chaque jour les pages produits et récupère les prix | Intelligence concurrentielle en temps réel |
| Remplissage de formulaires / saisie | Complète des formulaires web répétitifs (CRM, portails, demandes) | Heures gagnées chaque semaine |
| Veille de contenu | Surveille blogs concurrents, offres d’emploi et communiqués de presse | Signaux faibles plus tôt |
| QA / tests | Parcourt les parcours web pour vérifier leur bon fonctionnement | Moins d’expériences utilisateur cassées |
Le marché des agents IA a atteint 7,38 milliards de dollars en 2025, soit presque le double des 3,7 milliards de 2023, et 88 % des organisations utilisent désormais l’automatisation IA dans au moins une fonction. On n’est plus du tout sur un marché de niche.
Chromium sandboxé, Browser Relay ou Chrome Remote Debugging : choisir le bon mode
Choisir le mauvais mode navigateur est, selon mon expérience, la plus grande source de frustration pour les nouveaux utilisateurs d’OpenClaw. J’ai vu des gens passer des heures à déboguer des problèmes de connexion qui auraient pu être évités en choisissant le bon mode dès le départ. OpenClaw propose trois façons de se connecter, avec de vrais compromis à la clé :
- Sandbox Chromium (profil géré) : OpenClaw lance son propre navigateur headless sur le serveur. Pas de session de connexion, configuration rapide, mais détection plus facile par les systèmes anti-bot.
- Browser Relay (session existante) : un node host sur votre machine locale relaie les instructions du VPS vers votre vrai navigateur Chrome. Compatible avec les sessions connectées et les cookies, en conservant l’empreinte de votre navigateur réel.
- Chrome Remote Debugging (Remote CDP) : connexion à des navigateurs distants via une URL WebSocket. Accès complet à la session, mais configuration plus complexe. Compatible avec des services cloud comme Browserless ou Browserbase.
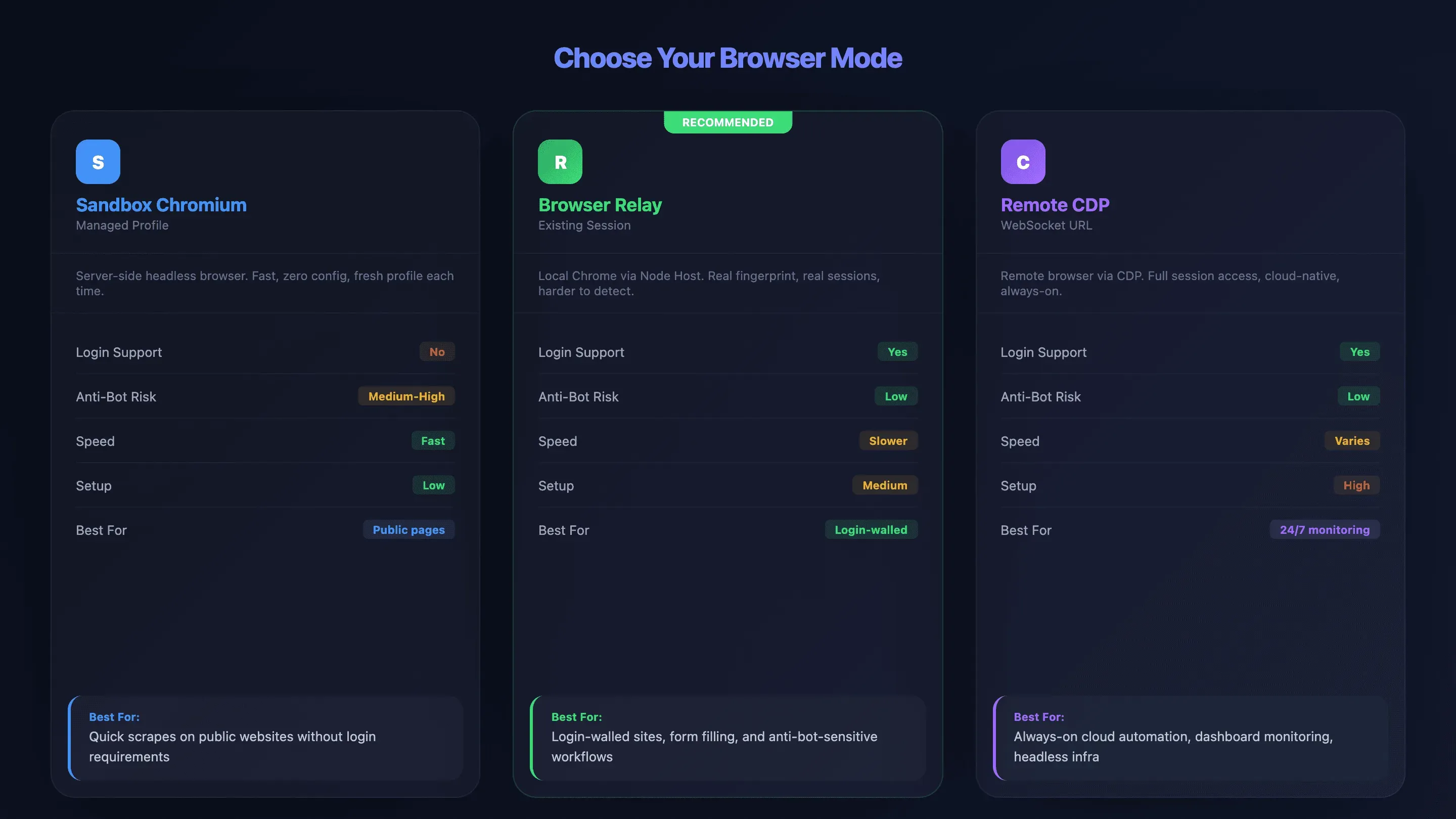
Tableau comparatif : les trois modes navigateur
| Critère | Sandbox Chromium | Browser Relay | Remote CDP |
|---|---|---|---|
| Prise en charge de la connexion | ❌ Non (profil vierge) | ✅ Oui (vraies sessions) | ✅ Oui (pré-authentifié) |
| Risque anti-bot | ⚠️ Moyen à élevé | ✅ Faible (empreinte réelle) | ✅ Faible (géré par le fournisseur) |
| Vitesse | ✅ Rapide | ⚠️ Plus lent (relais réseau) | ⚠️ Variable |
| Complexité de configuration | Faible | Moyenne | Élevée |
| Fonctionnalités complètes | ✅ Oui (toutes) | ⚠️ Limitées (pas de batch, pas d’interception de téléchargement) | Dépend du fournisseur |
| Idéal pour | Pages publiques, extractions rapides | Sites avec connexion, remplissage de formulaires | Infra cloud, surveillance en continu |
Arbre de décision : quel mode choisir ?
Répondez à ces questions dans l’ordre :
- « Avez-vous besoin d’être connecté ? » — Non → Sandbox Chromium. Oui → question suivante.
- « Le site est-il fortement protégé contre les bots ? » — Oui → Browser Relay (l’empreinte de votre vrai navigateur réduit la détection). Non → Browser Relay ou Remote CDP.
- « Avez-vous besoin d’une session persistante, toujours active (par exemple pour surveiller un tableau de bord 24/7) ? » — Oui → Remote CDP avec un fournisseur cloud. Non → Browser Relay.
Correspondance avec des scénarios réels :
- Extraire des annonces Amazon publiques → Sandbox Chromium
- Remplir un formulaire CRM derrière connexion → Browser Relay
- Surveiller en continu un tableau de bord analytique interne → Remote CDP avec Browserless/Browserbase
Faire le bon choix ici vous évitera des heures de débogage. Vraiment.
Avant de commencer
- Niveau de difficulté : intermédiaire (aisance avec le CLI requise)
- Temps nécessaire : 45 à 75 minutes pour la configuration complète ; 10 à 15 minutes par étape
- Ce qu’il vous faut : un VPS (2 Go de RAM minimum, 4 Go recommandés), Node.js v22.12.0+, un compte Tailscale (gratuit), un navigateur Chrome et de la patience
Étape 1 : lancer OpenClaw sur un VPS (ou en local)
Le VPS est l’endroit où vit le « cerveau » d’OpenClaw. Deux options pour le faire tourner :
Option A : hébergement VPS en un clic
Plusieurs fournisseurs proposent des images OpenClaw préconfigurées :
| Fournisseur | Prix de départ | Remarques |
|---|---|---|
| Hostinger | À partir de 6,99 $/mois | Image préconfigurée |
| Tencent Cloud Lighthouse | À partir d’environ 0,08 $/an (promo) | 2 cœurs / 4 Go recommandés |
| Hetzner | À partir de 4,09 $/mois (CX22) | Le meilleur rapport qualité-prix ; installation manuelle |
| DigitalOcean | À partir de 4 $/mois | Installation manuelle |
| Vultr | À partir de 3,50 $/mois | Installation manuelle |
Option B : installation manuelle en ligne de commande
# Installation via npm (nécessite Node.js v22.12.0+)
npm install -g openclaw
# Lancer l’assistant d’onboarding
openclaw onboard
# Générer un jeton Gateway (conservez-le — vous en aurez besoin pour le node host)
openclaw doctor --generate-gateway-token
# Valider la configuration
openclaw doctor --fix
Spécifications minimales : 2 Go de RAM (crash à 1 Go), 4 Go recommandés. Chaque instance de navigateur headless consomme 400 à 800 Mo au repos. Si vous utilisez Docker, définissez shm_size: '2gb' — c’est essentiel pour la stabilité.
Après cette étape, OpenClaw devrait être en cours d’exécution et vous devriez avoir sauvegardé un jeton Gateway en lieu sûr. (Je le garde dans un gestionnaire de mots de passe. Ne le perdez pas.)
Étape 2 : configurer Tailscale pour relier le VPS et la machine locale
Tailscale crée un tunnel privé et chiffré entre votre VPS et votre appareil local, afin que les instructions de navigation ne soient pas exposées à Internet. Vu qu’OpenClaw avait 512 vulnérabilités signalées par Kaspersky au début de 2026, sauter cette étape serait une mauvaise idée.
# Sur le VPS
curl -fsSL https://tailscale.com/install.sh | sh
sudo tailscale up --ssh=true
# Notez l’IP Tailscale du VPS (100.x.x.x)
# Configurer Gateway pour écouter sur le réseau Tailscale
openclaw config set gateway.listen "100.x.x.x:18789"
Installez Tailscale sur votre machine locale depuis tailscale.com/download. Les deux appareils doivent utiliser le même compte Tailscale.
Alternatives si Tailscale ne vous convient pas :
| Critère | Tailscale | Cloudflare Tunnel | WireGuard |
|---|---|---|---|
| Temps de configuration | 5 min | 10–15 min | 20–30 min |
| Coût | Gratuit (usage personnel) | Gratuit | Gratuit |
| Traversée NAT | Automatique | Automatique | Manuelle |
Vous devriez maintenant pouvoir pinguer l’IP Tailscale de votre VPS depuis votre machine locale. Sinon, vérifiez que les deux appareils utilisent bien le même compte Tailscale.
Étape 3 : installer le Node Host sur votre appareil local
Le node host relaie les instructions du Gateway du VPS vers votre Chrome local — c’est le traducteur entre le serveur et le navigateur.
# Installer le package du node host
npm install -g @openclaw/node-host
# Définir le jeton Gateway de l’étape 1
export OPENCLAW_GATEWAY_TOKEN="your-token-here"
# Démarrer le node host en pointant vers l’IP Tailscale de votre VPS
openclaw node install --host 100.x.x.x --port 18789
# Approuver la connexion côté VPS
openclaw node approve <node-id>
Vous devriez voir une confirmation indiquant que le nœud est connecté et approuvé. Si l’étape d’approbation bloque, redémarrez le processus Gateway sur le VPS.
Étape 4 : installer l’extension Chrome OpenClaw
L’extension donne à l’agent un contrôle direct sur les onglets du navigateur. Vous pouvez aussi la récupérer depuis le Chrome Web Store en recherchant « OpenClaw Browser Relay ».
# Installer les fichiers de l’extension
openclaw browser extension install
# Ou manuellement :
# 1. Ouvrir chrome://extensions
# 2. Activer le « Mode développeur » (interrupteur en haut à droite)
# 3. Cliquer sur « Charger l’extension non empaquetée » → sélectionner le dossier de l’extension
# 4. Épingler à la barre d’outils
# 5. Vérifier que le badge affiche « ON »
Si le badge affiche « ON », tout va bien. S’il reste sur « OFF », passez à la section dépannage ci-dessous.
Étape 5 : lancer votre premier workflow OpenClaw Browser Automation
Ouvrez un onglet cible, puis depuis l’interface de chat OpenClaw, essayez quelque chose de simple :
Va sur https://books.toscrape.com et extrais le titre et le prix de chaque livre sur la page
Déroulé attendu : instruction envoyée → l’agent prend une capture (identifie les éléments de la page avec des références numérotées) → l’agent extrait les données → le résultat structuré est renvoyé en JSON ou CSV.
Un conseil d’expérience : commencez avec des prompts très simples. Trop détailler ce que vous voulez peut, en réalité, embrouiller l’IA — ajoutez des précisions seulement si l’agent interprète mal votre première instruction.
Pour 20 livres sur la première page, comptez environ 30 à 60 secondes. Les données structurées reviennent ? Votre configuration OpenClaw Browser Automation fonctionne.
OpenClaw Browser Automation sous Windows : la voie native
La plupart des guides OpenClaw partent du principe que vous êtes sur macOS ou Linux. Si vous êtes sur Windows, vous l’avez déjà remarqué. Un utilisateur sur un forum l’a dit très justement : « beaucoup de solutions semblaient cohérentes en théorie, mais aucune n’était conçue pour Windows en natif ».
Voici ce qui fonctionne vraiment.
Option A : Chrome Remote Debugging sous Windows (chemin natif recommandé)
L’approche Windows native la plus fiable. Ouvrez PowerShell et lancez Chrome avec le débogage à distance activé :
& "C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
Si Chrome n’est pas à cet emplacement, essayez :
# Vérifier d’autres emplacements
Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse
# Ou vérifier AppData
& "$env:LOCALAPPDATA\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
Puis configurez OpenClaw pour se connecter via Remote CDP en définissant cdpUrl sur ws://localhost:9222 dans votre fichier de configuration openclaw.json.
Option B : Docker Desktop comme solution de secours sous Windows
Si la voie native vous pose problème, Docker Desktop sur Windows peut exécuter un conteneur Chromium headless :
docker run -d --name openclaw-browser -p 9222:9222 --shm-size=2g browserless/chrome
# Puis pointez OpenClaw vers : cdpUrl: "ws://localhost:9222"
Cela ajoute une couche de complexité, mais c’est plus stable pour certains utilisateurs. Ça fonctionne, même si ce n’est pas très élégant.
Catalogue des erreurs spécifiques à Windows
| Erreur | Cause | Correctif (PowerShell) |
|---|---|---|
| Le port 9222 est déjà utilisé | Une autre session DevTools est ouverte | `Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess |
| Binaire Chrome introuvable | Mauvais chemin | Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse |
| Connexion Tailscale refusée | Pare-feu Windows bloquant | New-NetFirewallRule -DisplayName "OpenClaw" -Direction Inbound -LocalPort 18789 -Protocol TCP -Action Allow |
| Erreurs de permission npm | PowerShell non lancé en administrateur | Lancez PowerShell en tant qu’administrateur, ou utilisez nvm-windows |
Toutes les commandes ci-dessus sont en PowerShell, pas en bash. Vous pouvez les copier-coller directement.
Guide de survie anti-bot pour OpenClaw Browser Automation
La détection des bots est la première source de frustration pour les utilisateurs d’OpenClaw Browser Automation. Le Chromium par défaut d’OpenClaw n’a aucun mécanisme d’invisibilisation intégré — les sites le détectent via l’indicateur WebDriver, les dimensions d’écran, le fingerprint des polices et la réputation de l’IP. J’ai vu des agents se faire bloquer en quelques secondes sur certains sites.
Mais il existe une progression par paliers. Commencez par la solution la plus simple et n’allez plus loin que si nécessaire.
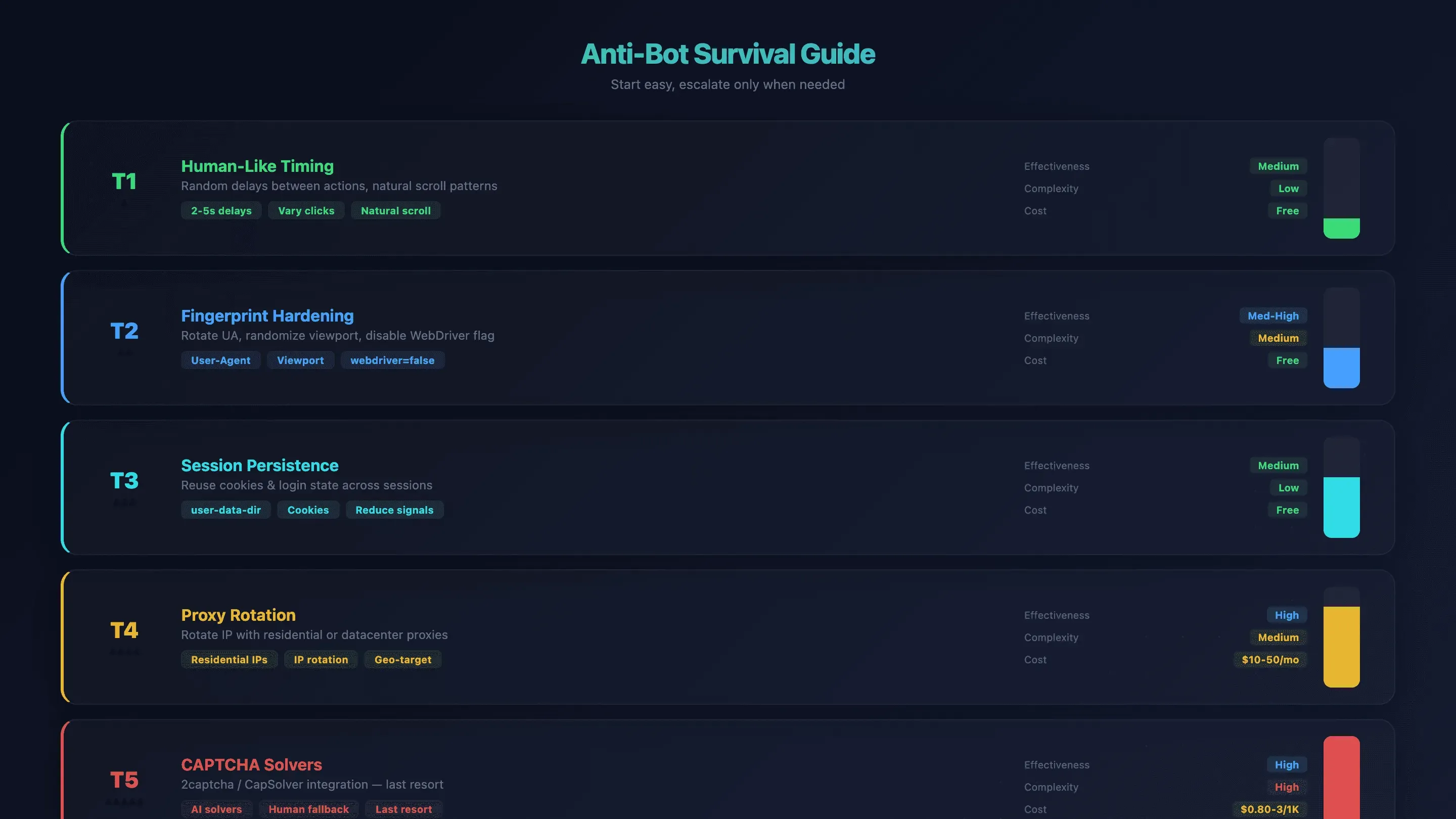
Niveau 1 : timing et comportement plus humains
Ajoutez des délais aléatoires entre les actions dans vos prompts. Au lieu d’enchaîner les clics à vitesse machine, demandez à l’agent : « attends 2 à 5 secondes entre chaque clic ». L’IA varie déjà un peu le rythme, mais des instructions explicites aident.
Efficacité : moyenne | Complexité : faible | Coût : gratuit
Niveau 2 : durcissement de l’empreinte navigateur
Faites tourner les user-agents, randomisez la taille du viewport et laissez OpenClaw désactiver automatiquement l’indicateur navigator.webdriver (via --disable-blink-features=AutomationControlled).
# Définir des en-têtes personnalisés
openclaw browser set headers --headers-json '{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36"}'
# Randomiser le viewport
openclaw browser set viewport 1366 768
# Définir le fuseau horaire et la locale
openclaw browser set timezone America/New_York
openclaw browser set locale en-US
Pour une détection encore plus poussée, la communauté recommande Camoufox (un navigateur anti-détection basé sur Firefox avec spoofing du fingerprint au niveau du moteur C++).
Efficacité : moyenne à élevée | Complexité : moyenne | Coût : gratuit
Niveau 3 : persistance de session
Utilisez user-data-dir pour conserver les cookies et l’état de connexion entre les sessions. Cela réduit les signaux de « navigateur neuf » qui déclenchent les systèmes anti-bot.
openclaw config set browser.profiles.persistent.userDataDir "/path/to/chrome-profile"
openclaw config set browser.profiles.persistent.cdpPort 18802
Efficacité : moyenne | Complexité : faible | Coût : gratuit
Niveau 4 : rotation des proxys
Quand le timing et l’empreinte ne suffisent pas, faites tourner votre adresse IP. Les proxys résidentiels sont plus difficiles à détecter ; les proxys de datacenter sont plus rapides et moins chers.
export OPENCLAW_BROWSER_PROXY="http://user:pass@proxy.example.com:8080"
Remarque : la configuration du proxy au niveau navigateur reste une fonctionnalité demandée (GitHub Issue #8079). Pour l’instant, les proxys doivent être définis au niveau du système ou de l’environnement.
| Fournisseur | Résidentiel | Datacenter | Idéal pour |
|---|---|---|---|
| Bright Data | 4 à 8,40 $/Go | 0,43 à 0,60 $/Go | Entreprise, qualité maximale |
| Oxylabs | 6 à 8 $/Go | 0,48 à 5 $/Go | Extraction à grande échelle |
| Decodo (Smartproxy) | 4 à 5,50 $/Go | 0,70 à 5 $/Go | Budgets intermédiaires |
| IPRoyal | 5 à 7 $/Go | -- | Budget serré |
| DataImpulse | 1 $/Go | -- | Coût minimal |
Efficacité : élevée | Complexité : moyenne | Coût : 10 à 50 $/mois
Niveau 5 : solveurs de CAPTCHA
Solution de dernier recours. Intégrez des services comme 2captcha ou CapSolver.
| Service | reCAPTCHA v2 | Cloudflare Turnstile | Latence |
|---|---|---|---|
| 2Captcha | 2,99 $/1K | 2,99 $/1K | 15–45 s (résolution humaine) |
| CapSolver | 0,80 à 1,50 $/1K | 0,80 à 1 $/1K | 0,5–10 s (IA) |
FlareSolverr (contournement Cloudflare open source) est documenté comme peu fiable en 2025–2026 en raison du renforcement des défenses de Cloudflare.
Efficacité : élevée | Complexité : élevée | Coût : 0,80 à 3 $/1K résolutions
Tableau récapitulatif anti-bot
| Technique | Efficacité | Complexité | Coût |
|---|---|---|---|
| Timing humain | Moyenne | Faible | Gratuit |
| Durcissement du fingerprint | Moyenne à élevée | Moyenne | Gratuit |
| Persistance de session | Moyenne | Faible | Gratuit |
| Rotation des proxys | Élevée | Moyenne | 10 à 50 $/mois |
| Solveurs de CAPTCHA | Élevée | Élevée | 0,80 à 3 $/1K résolutions |
Pour les utilisateurs qui se heurtent sans cesse à des protections anti-bot et qui veulent juste les données : le scraping cloud de Thunderbit gère l’anti-bot nativement pour les sites publics — pas de configuration de proxy, pas de réglage de fingerprint. C’est une approche fondamentalement différente (l’IA lit le site à chaque fois via une infrastructure cloud gérée) qui contourne toute la course à l’armement anti-bot pour les tâches standard d’extraction de données.
Résultat réel : ce qu’OpenClaw Browser Automation produit concrètement
Avant d’investir 45 à 75 minutes dans la configuration, vous voulez sans doute voir à quoi ressemble le résultat final. C’est normal — voici trois exemples de workflows avec des résultats réels.
Exemple 1 : web scraping — extraction de données produit
Prompt : « Va sur https://books.toscrape.com et extrait le titre et le prix de chaque livre sur la page »
Résultat (5 premières lignes) :
| Titre | Prix |
|---|---|
| A Light in the Attic | £51.77 |
| Tipping the Velvet | £53.74 |
| Soumission | £50.10 |
| Sharp Objects | £47.82 |
| Sapiens: A Brief History of Humankind | £54.23 |
Temps écoulé : environ 45 secondes pour 20 lignes (une page). La pagination a nécessité une instruction de suivi : « Clique sur le bouton Next et répète l’opération sur 5 pages. » Total : environ 100 lignes en 3 minutes.
Exemple 2 : automatisation de formulaires — remplir un formulaire web à plusieurs champs
Scénario : remplir un formulaire de demande fournisseur avec nom de l’entreprise, coordonnées et intérêt produit.
L’agent prend une capture du formulaire, identifie chaque champ par son numéro de référence et les remplit les uns après les autres. Avant : champs vides. Après : tous les champs sont renseignés, message de confirmation affiché. Les menus déroulants et cases à cocher sont gérés par le système de captures — l’agent « voit » les options et sélectionne la bonne.
Temps écoulé : environ 30 secondes pour un formulaire de 6 champs.
Exemple 3 : pagination — extraction sur plusieurs pages
Résultat initial : 20 lignes de la page 1. Après l’instruction « clique sur Next et répète pour toutes les pages » : 1 000 lignes sur 50 pages sur books.toscrape.com. L’agent repère le bouton « Next » via la capture et clique dessus en boucle.
Temps écoulé : environ 12 minutes pour l’ensemble des 1 000 lignes.
Comparaison directe : la même tâche de scraping dans Thunderbit
Pour le même exemple books.toscrape.com, voici à quoi ressemble le workflow dans Thunderbit :
- Installer l’extension Chrome Thunderbit (~30 secondes)
- Aller sur la page
- Cliquer sur « AI Suggest Fields » → l’IA détecte Title, Price, Availability, Rating
- Cliquer sur « Scrape » → 20 lignes extraites
- Utiliser les contrôles de pagination → toutes les pages sont extraites
- Exporter vers Google Sheets (gratuit)
Temps total : environ 3 minutes, de zéro aux données exportées, sans VPS, sans CLI, sans configuration.
Le point n’est pas de dire qu’un outil est « meilleur ». Le bon outil dépend de ce que vous essayez réellement de faire.
Essayez l’extension Chrome Thunderbit
Quand OpenClaw Browser Automation est trop lourd (et quoi utiliser à la place)
OpenClaw excelle dans les automatisations complexes à plusieurs étapes, pilotées par un agent — workflows derrière connexion, enchaînement d’actions navigateur avec des commandes shell, exécution 24/7 sur un VPS. Mais si l’objectif est « extraire des données produit d’une page de listing » ou « récupérer des e-mails depuis un annuaire », la pile complète VPS + Tailscale + node host est probablement trop sophistiquée.
J’ai vu des gens passer plus de 60 minutes à configurer un outil pour une tâche réalisable en 2 minutes avec une solution plus simple. Mauvais deal.
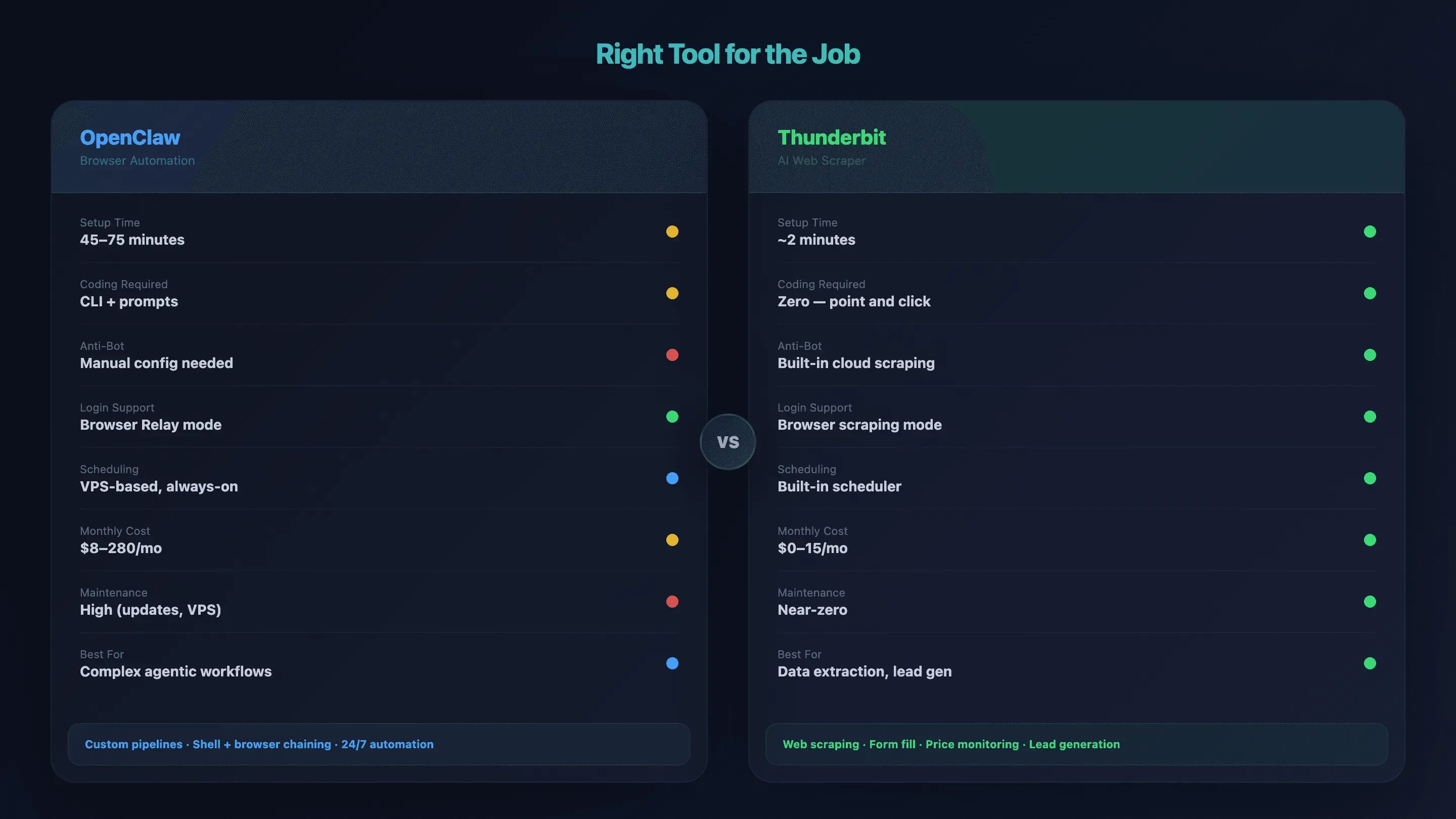
Le bon outil pour le bon besoin : tableau comparatif
| Critère | OpenClaw Browser Automation | Thunderbit |
|---|---|---|
| Temps de configuration | 45–75 min (VPS + Tailscale + node host) | ~2 min (installation de l’extension Chrome) |
| Code requis | CLI + prompts en langage naturel | Aucun — cliquez sur « AI Suggest Fields » → « Scrape » |
| Gestion anti-bot | Manuelle (proxy, fingerprint, configuration) | Scraping cloud intégré |
| Navigation derrière connexion | ✅ Browser Relay / débogage distant | ✅ Mode de scraping navigateur |
| Enrichissement des sous-pages | Script personnalisé par workflow | Scraping des sous-pages en 1 clic |
| Exécutions programmées / 24×7 | Basées sur VPS, toujours actives | Scheduled scraper intégré |
| Coût mensuel | 8 à 14 $ (usage loisir) à 110 à 280 $ (usage intensif) | 0 $ (offre gratuite) à 15 $/mois |
| Charge de maintenance | Élevée (mises à jour, VPS, débogage) | Quasi nulle — l’IA s’adapte aux changements de mise en page |
| Idéal pour | Workflows d’agent complexes, pipelines personnalisés | Extraction de données, remplissage de formulaires, génération de leads, veille tarifaire |
Orientation par cas d’usage
- Vous avez besoin de workflows agentiques multi-étapes qui enchaînent actions navigateur, commandes shell, applications de messagerie et bases de données → OpenClaw est le bon choix.
- Vous devez extraire des données de sites web, remplir des formulaires ou surveiller des prix sans toucher à un terminal → Thunderbit vous fera gagner du temps. Vous pouvez consulter la chaîne YouTube Thunderbit pour des démonstrations rapides.
- Vous avez besoin d’un script léger pour un endpoint API précis → un simple script Python avec requests peut suffire.
C’est vraiment la grille de lecture que j’utilise quand quelqu’un dans mon équipe demande : « quel outil dois-je utiliser pour ça ? »
Erreurs courantes d’OpenClaw Browser Automation et comment les corriger
Ajoutez cette section à vos favoris. Elle est organisée par symptôme pour que vous puissiez trouver un correctif rapidement avec Ctrl+F.
« Connection Refused » ou le Node Host ne se connecte pas
Causes probables (à vérifier dans cet ordre) :
- Tailscale n’est pas actif sur les deux appareils → exécutez
tailscale statussur les deux - Le Gateway n’écoute pas sur le réseau Tailscale (il est encore sur localhost) →
openclaw config set gateway.listen "100.x.x.x:18789" - Mauvaise adresse IP → revérifiez avec
tailscale ip -4 - Pare-feu bloquant le port 18789 →
sudo ufw allow 18789/tcp(Linux) ou ajoutez une règle dans le pare-feu Windows
Le badge de l’extension reste sur « OFF » ou l’onglet n’est pas détecté
- Extension non chargée en mode développeur →
chrome://extensions→ activez le mode développeur → rechargez - Node host inactif → redémarrez avec
openclaw node start - Conflit avec une instance Chrome → fermez toutes les instances Chrome, relancez puis rechargez l’extension
L’agent renvoie des données vides ou incorrectes
- Page pas complètement chargée : demandez à l’agent de « attendre 3 secondes après la navigation avant d’extraire ». Beaucoup de SPA ont besoin de temps pour rendre le contenu.
- Blocage anti-bot : vérifiez si vous voyez une page CAPTCHA au lieu du contenu réel. Passez de Sandbox Chromium à Browser Relay.
- Capture obsolète : demandez à l’agent de « prendre une nouvelle capture » — les numéros de référence deviennent obsolètes après une navigation.
« Port 9222 already in use »
Ce cas se produit souvent quand Chrome DevTools ou un autre outil d’automatisation utilise déjà ce port.
# macOS/Linux
lsof -i :9222 | grep LISTEN
kill -9 <PID>
# Windows PowerShell
Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess | Stop-Process -Force
Le VPS n’a plus de mémoire
Chaque instance de navigateur headless consomme 400 à 800 Mo de RAM. Lancer plusieurs instances à la fois peut faire planter un petit VPS.
Correctifs :
- Désactiver le chargement des images/CSS/polices :
openclaw browser network route --abort "**/*.{png,jpg,gif,css,woff2}" - Limiter le nombre d’instances simultanées à ce que votre RAM supporte
- Définir
shm_size: '2gb'dans Docker - Activer l’hibernation de session :
OPENCLAW_HIBERNATE_AFTER=300 - Passer à un VPS avec 4 Go de RAM ou plus si vous avez besoin de marge
Conseils pour faire tourner OpenClaw Browser Automation sans accroc
Quelques bonnes pratiques que j’ai retenues en faisant tourner ce type de configuration :
- Désactivez les images, feuilles de style et polices pour les tâches de scraping purement orientées données. Cela réduit fortement la consommation de ressources et accélère l’exécution.
- Réutilisez les instances de navigateur au lieu d’en lancer une nouvelle à chaque tâche. Les instances fraîches coûtent cher en RAM et déclenchent davantage de signaux anti-bot.
- Commencez avec des prompts simples. Ajoutez des détails seulement si l’agent interprète mal. Trop détailler peut davantage perturber l’IA que l’aider.
- Surveillez l’usage des ressources du VPS (CPU, RAM) et augmentez la capacité avant d’atteindre les limites. Un VPS en panne à 2 h du matin n’est jamais agréable à déboguer.
- Gardez OpenClaw et l’extension Chrome à jour — mais testez d’abord les mises à jour dans un environnement de préproduction. OpenClaw publie environ 13 versions par mois, et elles ne sont pas toutes impeccables.
- Pour les tâches récurrentes (contrôles de prix quotidiens, extraction de leads hebdomadaire), le scheduled scraper de Thunderbit permet de définir des intervalles en langage courant et d’oublier complètement la maintenance d’un VPS.
Considérations éthiques et juridiques
Court mais important. Respectez robots.txt (formalisé comme standard IETF dans RFC 9309), limitez le rythme de vos requêtes, vérifiez les conditions d’utilisation des sites ciblés et traitez les données personnelles conformément au RGPD et aux lois sur la vie privée. Le précédent hiQ v. LinkedIn (2022) a établi que l’extraction de données publiquement accessibles ne viole pas le CFAA, mais cela ne veut pas dire que tout est permis. Utiliser l’automatisation de façon responsable protège à la fois votre entreprise et vous-même. Pour aller plus loin, consultez notre guide sur les implications juridiques du web scraping.
Pour conclure
OpenClaw Browser Automation est une solution puissante pour les workflows web complexes, en plusieurs étapes, pilotés en langage naturel. Voici l’essentiel :
- Choisissez le bon mode navigateur dès le départ (Sandbox, Relay, Remote CDP) — ce seul choix peut vous faire gagner des heures de débogage.
- Les utilisateurs Windows ont une voie qui fonctionne, mais il faut suivre les commandes spécifiques à Windows et surveiller les problèmes de pare-feu et de chemins d’accès.
- La gestion anti-bot est un vrai défi — commencez par les techniques les plus simples (timing, fingerprint) et montez en puissance uniquement si nécessaire.
- Voyez le résultat avant de vous engager. Si tout ce dont vous avez besoin est de structurer des données depuis une page de listing, un outil no-code comme Thunderbit vous y amène en quelques minutes, sans maintenance.
- Prévoyez la maintenance dans votre budget. OpenClaw publie environ 13 versions par mois, les coûts VPS s’accumulent, et le débogage fait partie du jeu.
Si vous voulez essayer d’abord la voie la plus simple, Thunderbit propose une offre gratuite — installez l’extension, extrayez une page et voyez si cela couvre votre besoin avant d’investir dans une configuration VPS complète. Si vous choisissez quand même OpenClaw, gardez ce guide sous la main. Vous aurez un jour besoin du catalogue d’erreurs — et que vos instances de navigateur aient toujours assez de RAM.
FAQ
Quelle est la différence entre OpenClaw Sandbox Chromium et Browser Relay ?
Sandbox Chromium exécute un navigateur headless sur le serveur — c’est rapide et facile à mettre en place, mais cela crée un profil vierge à chaque fois (pas de session de connexion) et c’est plus facilement détecté par les systèmes anti-bot. Browser Relay redirige les instructions vers votre vrai navigateur Chrome sur votre machine locale, ce qui prend en charge les connexions, conserve l’empreinte réelle de votre navigateur et rend la détection d’automatisation plus difficile. Le compromis, c’est que Browser Relay est plus lent à cause du relais réseau et qu’il a certaines limitations fonctionnelles (pas d’actions par lot, pas d’interception des téléchargements).
Puis-je utiliser OpenClaw Browser Automation sur Windows sans WSL ?
Oui, mais avec quelques réserves. La voie native Windows la plus fiable passe par Chrome Remote Debugging via PowerShell (chrome.exe --remote-debugging-port=9222). Docker Desktop sert de solution de repli si cela s’avère peu fiable. La prise en charge complète du Node Host en natif sur Windows peut encore présenter quelques aspérités — consultez la documentation à jour et préparez-vous à des problèmes propres à Windows comme les blocages du pare-feu ou les différences de chemins d’accès aux binaires. Toutes les commandes de la section Windows de ce guide sont en PowerShell, pas en bash.
Comment gérer les CAPTCHA dans OpenClaw Browser Automation ?
Commencez par réduire le risque de détection : ajoutez un timing plus humain, renforcez l’empreinte de votre navigateur et utilisez la persistance de session pour éviter les signaux de navigateur neuf. Si les CAPTCHA persistent, intégrez un service de résolution comme 2captcha (2,99 $/1K résolutions) ou CapSolver (0,80 à 1,50 $/1K, basé sur l’IA). Pour les sites publics où vous voulez simplement les données, le scraping cloud de Thunderbit gère automatiquement l’anti-bot sans aucune configuration de proxy ou de CAPTCHA.
OpenClaw Browser Automation est-il gratuit ?
OpenClaw lui-même est open source (licence MIT) et gratuit. En revanche, son exécution nécessite une infrastructure — un VPS à 4 à 15 $/mois, plus éventuellement des services comme la rotation de proxys (10 à 50 $/mois) ou des solveurs de CAPTCHA (facturation à la résolution). Le coût mensuel total varie d’environ 8 à 14 $ pour un usage loisir à 110 à 280 $ pour des charges d’automatisation intensives. À titre de comparaison, l’offre gratuite de Thunderbit couvre le scraping de base sans coûts d’infrastructure.
Que faire si mon agent OpenClaw renvoie toujours des résultats vides ?
Trois vérifications, dans cet ordre : d’abord, la page n’est peut-être pas entièrement chargée — demandez à l’agent de « attendre 3 secondes après la navigation avant d’extraire ». Ensuite, vous êtes peut-être face à une barrière anti-bot — si l’agent « voit » une page CAPTCHA au lieu du contenu réel, passez de Sandbox Chromium à Browser Relay. Enfin, les références de la capture sont peut-être périmées — demandez à l’agent de « prendre une nouvelle capture » après chaque navigation. Si rien ne marche, vérifiez l’utilisation mémoire de votre VPS — une instance de navigateur plantée renvoie souvent des résultats vides sans message clair.
Essayez Thunderbit pour une extraction de données web plus rapide Get Started Free




