

En 2026, plus de la moitié du trafic internet provient de robots, et derrière cette statistique se cachent des crawlers open source qui tournent sans relâche : surveillance des prix, veille concurrentielle, constitution de jeux de données pour entraîner des modèles d'IA. Quiconque a passé quelques années dans le SaaS et l'automatisation le sait : le choix d'un crawler auto-hébergé n'est jamais anodin. Bien choisi, il épargne à votre équipe des mois de galère technique et de débogage nocturne. Mal choisi, il devient un puits sans fond. Que vous ayez besoin d'extraire quelques pages produit ou de parcourir des millions d'URL pour un projet de recherche, les neuf alternatives open source à Firecrawl réunies ici couvrent tous les cas de figure — quelle que soit votre échelle, votre pile technique ou votre tolérance à la complexité.
Reste un constat : aucun outil ne convient à tout le monde. Certaines équipes ont besoin de la puissance brute de Scrapy ou de la robustesse d'archivage d'Heritrix ; d'autres jugeront la maintenance des bibliothèques open source trop lourde à porter. Voici donc un tour d'horizon des neuf meilleures alternatives open source à Firecrawl pour 2026, avec les points forts de chacune, pour vous aider à identifier l'outil réellement adapté à vos besoins — et vous épargner l'interminable phase d'essais et d'erreurs.
Comment choisir la meilleure alternative open source à Firecrawl pour votre entreprise
Avant d'entrer dans le détail de la liste, un mot sur la méthode. Le paysage du crawling web open source n'a jamais été aussi varié, et votre décision dépendra de quelques critères déterminants :
- Facilité d'utilisation : préférez-vous une interface en pointer-cliquer, ou êtes-vous à l'aise avec Python, Go ou JavaScript ?
- Scalabilité : un seul site suffit-il, ou devez-vous crawler des millions de pages sur des centaines de domaines ?
- Type de contenu : votre cible repose-t-elle sur du HTML statique, ou s'appuie-t-elle massivement sur JavaScript et le chargement dynamique ?
- Besoins d'intégration : que comptez-vous faire des données — un export Excel, un envoi en base de données, une intégration dans un pipeline d'analyse ?
- Maintenance : disposez-vous des ressources pour entretenir du code sur mesure, ou voulez-vous un outil qui s'adapte tout seul aux changements de site ?
Voici un repère synthétique pour vous aider à trancher :
| Scénario | Meilleur(s) outil(s) |
|---|---|
| Sans code, navigation hors ligne | HTTrack |
| Crawl à grande échelle, multi-domaines | Scrapy, Apache Nutch, StormCrawler |
| Sites dynamiques / très chargés en JS | Puppeteer |
| Automatisation de formulaires / connexion requise | MechanicalSoup |
| Téléchargement / archivage de sites statiques | Wget, HTTrack, Heritrix |
| Développeur Go, haute performance | Colly |
Entrons maintenant dans le détail des neuf meilleures alternatives open source à Firecrawl pour 2026.
1. Scrapy : le meilleur choix pour le crawling Python à grande échelle

Scrapy fait figure de référence absolue dans le crawling web open source. Écrit en Python, c'est le framework vers lequel se tournent les développeurs dès qu'il faut crawler à grande échelle : des millions de pages, des actualisations fréquentes, une logique de site complexe.
Pourquoi Scrapy ?
- Échelle massive : Scrapy encaisse des milliers de requêtes par seconde, et des entreprises l'emploient pour extraire des milliards de pages chaque mois (Zyte).
- Extensible et modulaire : vous écrivez des spiders sur mesure, ajoutez des middlewares pour les proxies, gérez les connexions et exportez en JSON, CSV ou directement en base de données.
- Communauté active : une profusion de plugins, une documentation fournie et des réponses en pagaille sur Stack Overflow.
- Éprouvé en production : des équipes e-commerce, médias et recherche s'en servent partout dans le monde.
Limites : la courbe d'apprentissage rebute les non-développeurs, et il faudra maintenir vos spiders au fil des évolutions des sites. Mais pour un contrôle total doublé d'une scalabilité réelle, Scrapy reste difficile à détrôner.
2. Apache Nutch : le meilleur choix pour les moteurs de recherche d'entreprise
Apache Nutch est l'ancêtre des crawlers open source, pensé pour un crawling à l'échelle d'internet et de niveau entreprise. Si votre ambition est de bâtir votre propre moteur de recherche ou de crawler des millions de domaines, Nutch est taillé pour ça.
Pourquoi Apache Nutch ?
- Scalabilité portée par Hadoop : adossé à Hadoop, Nutch crawle des milliards de pages réparties sur des clusters de serveurs (Common Crawl s'en sert pour crawler le web public).
- Crawling par lots : fournissez-lui une liste d'URL de départ et laissez-le travailler — idéal pour les tâches planifiées de grande envergure.
- Intégration : s'articule avec Solr, Elasticsearch et les pipelines big data.
Limites : configuration ardue (clusters Hadoop, fichiers Java à paramétrer), et l'outil penche davantage vers le crawling brut que vers l'extraction de données structurées. Disproportionné pour les petits projets, mais imbattable à l'échelle du web.
3. Heritrix : le meilleur choix pour l'archivage web et la conformité

Heritrix est le crawler de l'Internet Archive, conçu spécifiquement pour l'archivage web et la préservation numérique.
Pourquoi Heritrix ?
- Exhaustivité de niveau archivistique : il capture chaque page, chaque ressource et chaque lien — parfait pour la conformité juridique ou les instantanés historiques.
- Sortie WARC : tout est stocké dans des fichiers Web ARChive standardisés, prêts à être rejoués ou analysés.
- Administration web : vous configurez et supervisez vos crawls depuis une interface navigateur.
Limites : outil lourd (gourmand en espace disque et en mémoire), il n'exécute pas JavaScript et produit des archives brutes plutôt que des tableaux structurés. Tout indiqué pour les bibliothèques, les centres d'archives ou les secteurs réglementés.
4. Colly : le meilleur choix pour les développeurs Go en quête de performance
Colly est le favori des développeurs Go : un scraper web rapide, léger et hautement concurrent.
Pourquoi Colly ?
- Ultra-rapide : la concurrence native de Go permet à Colly d'extraire des milliers de pages en sollicitant à peine le CPU et la RAM (Oxylabs).
- API limpide : vous définissez des callbacks pour les éléments HTML, tandis que les cookies et le robots.txt sont gérés automatiquement.
- Excellent sur les sites statiques : parfait pour les pages rendues côté serveur, les API, ou lorsque vous voulez intégrer l'extraction au cœur d'un backend Go.
Limites : pas de rendu JavaScript natif (pour les sites dynamiques, il faudra l'associer à un outil comme Chromedp), et la maîtrise de Go reste un prérequis.
5. MechanicalSoup : le meilleur choix pour l'automatisation simple de formulaires

MechanicalSoup est une bibliothèque Python qui jette un pont entre les simples requêtes HTTP et l'automatisation complète du navigateur.
Pourquoi MechanicalSoup ?
- Automatisation de formulaires : connectez-vous sans effort, remplissez des formulaires et conservez vos sessions — idéal pour récupérer des données protégées par une authentification.
- Léger : bâti sur Requests et BeautifulSoup, il est rapide à prendre en main et simple à déployer.
- Parfait pour les sites interactifs : s'il s'agit de soumettre des formulaires de recherche ou d'extraire des données après connexion, MechanicalSoup s'impose (Apify Blog).
Limites : aucune exécution JavaScript, donc inutilisable sur les sites qui en dépendent fortement. À réserver aux pages statiques ou rendues côté serveur, avec des interactions élémentaires.
6. Puppeteer : le meilleur choix pour les sites dynamiques et très chargés en JavaScript
Puppeteer est l'outil polyvalent par excellence pour extraire des données sur les sites modernes saturés de JavaScript. Cette bibliothèque Node.js vous donne la main sur un navigateur Chrome sans interface graphique.
Pourquoi Puppeteer ?
- Maîtrise du contenu dynamique : extrayez des données depuis les SPA, le défilement infini et les pages qui chargent leur contenu via AJAX (Browserless Guide).
- Simulation d'utilisateur : cliquez sur des boutons, remplissez des formulaires, capturez des écrans et résolvez même certains CAPTCHA (à l'aide de plugins).
- Automatisation puissante : excellent pour les tests, la surveillance et l'extraction de tout ce qu'un véritable utilisateur peut voir.
Limites : gourmand en ressources (il fait tourner de vraies instances de Chrome), plus lent que les scrapers purement HTTP, et sa montée en charge réclame du matériel solide ou une orchestration cloud.
7. Wget : le meilleur choix pour les téléchargements rapides en ligne de commande

Wget est l'outil en ligne de commande classique pour télécharger des sites et des fichiers statiques.
Pourquoi Wget ?
- Simplicité : téléchargez des sites entiers ou des répertoires complets avec une seule commande — sans écrire une ligne de code.
- Vitesse : écrit en C, il est rapide et économe.
- Excellent pour le contenu statique : parfait pour les sites de documentation, les blogs ou les téléchargements de fichiers en masse (HuggingFace Guide).
Limites : ni exécution JavaScript ni gestion de formulaires, et il récupère des pages brutes plutôt que des données structurées. Voyez-le comme un aspirateur numérique dédié aux sites statiques.
8. HTTrack : le meilleur choix pour la navigation hors ligne (sans code)
HTTrack est le cousin accessible de Wget, doté d'une interface graphique pour mirrorer des sites web.
Pourquoi HTTrack ?
- Interface conviviale : un assistant pas à pas le met à la portée des profils non techniques.
- Navigation hors ligne : il réajuste les liens pour vous permettre de consulter les sites copiés en local.
- Excellent pour l'archivage : idéal pour les chercheurs, les marketeurs ou quiconque souhaite figer un site sans coder (Reddit DataHoarder).
Limites : aucune prise en charge du contenu dynamique, des performances en berne sur les gros sites, et une vocation étrangère à l'extraction de données structurées.
9. StormCrawler : le meilleur choix pour le crawling distribué en temps réel

StormCrawler est le crawler distribué moderne destiné aux équipes qui ont besoin de données web continues, en temps réel et à grande échelle.
Pourquoi StormCrawler ?
- Crawling en temps réel : appuyé sur Apache Storm, il traite les données en flux — idéal pour la veille d'actualité ou les moteurs de recherche (Wikipedia).
- Modulaire et scalable : ajoutez des modules de parsing, d'indexation et de traitement sur mesure selon vos besoins.
- Adopté par Common Crawl : il alimente le jeu de données d'actualités de l'une des plus vastes archives du web ouvert.
Limites : il exige des compétences en développement Java et un cluster Storm, ce qui le réserve aux équipes rodées aux systèmes distribués. Surdimensionné pour les petits projets.
Comparaison des alternatives open source à Firecrawl : quel concurrent gratuit répond à vos besoins ?
Voici une comparaison côte à côte des neuf outils :
| Outil | Meilleur cas d’usage | Principaux avantages | Inconvénients | Langage / configuration |
|---|---|---|---|---|
| Scrapy | Crawling à grande échelle et fréquent | Puissant, scalable, grande communauté | Courbe d’apprentissage raide, Python requis | Framework Python |
| Apache Nutch | Crawling d’entreprise, à l’échelle du web | Propulsé par Hadoop, éprouvé à grande échelle | Configuration complexe, orienté lots | Java/Hadoop |
| Heritrix | Crawling d’archivage et de conformité | Capture complète du site, sortie WARC | Lourd, pas de JS, archives brutes | Application Java, interface web |
| Colly | Développeurs Go, extraction haute performance | Rapide, API simple, concurrence | Pas de JS, Go requis | Bibliothèque Go |
| MechanicalSoup | Automatisation de formulaires, scraping avec connexion | Léger, gestion des sessions | Pas de JS, échelle limitée | Bibliothèque Python |
| Puppeteer | Sites dynamiques / riches en JS | Contrôle total du navigateur, automatisation | Gourmand en ressources, Node.js requis | Bibliothèque Node.js |
| Wget | Téléchargement de sites statiques, accès hors ligne | Simple, rapide, CLI | Pas de JS, pages brutes | Outil en ligne de commande |
| HTTrack | Utilisateurs non techniques, archivage de sites | Interface graphique, navigation hors ligne facile | Pas de JS, lent sur les gros sites | Application de bureau (GUI) |
| StormCrawler | Crawling distribué, en temps réel | Scalable, modulaire, temps réel | Expertise Java/Storm nécessaire | Cluster Java/Storm |
Faut-il créer votre propre solution ou utiliser une alternative open source existante à Firecrawl ?
Soyons honnêtes : développer son propre crawler paraît stimulant — jusqu'au jour où l'on se retrouve enseveli sous la maintenance, les proxies et les déboires anti-bot. Les outils open source listés plus haut concentrent des années d'expérience accumulée et de savoir-faire communautaire. Les retours du secteur convergent : s'appuyer sur des solutions existantes reste le moyen le plus rapide et le plus fiable d'obtenir des résultats, sans réinventer la roue (IveerData).
- Optez pour l'open source si : vos besoins coïncident avec l'existant, vous voulez réduire le temps de développement et le support communautaire vous séduit.
- Développez votre propre solution si : vos besoins sont véritablement uniques, votre expertise interne est solide et l'extraction de données constitue le cœur de votre activité.
Cela dit, l'open source n'est pas « gratuit » dès lors qu'on additionne le temps d'ingénierie, la maintenance des serveurs et les mises à jour incessantes pour déjouer les protections anti-scraping. Si vous voulez la puissance d'un crawler sans toucher au code, une autre voie existe.
Bonus : quand l'open source devient trop complexe, essayez Thunderbit
Aussi remarquables soient-ils pour les développeurs, les outils ci-dessus partagent les mêmes contraintes : ils réclament des compétences en programmation, peinent face aux protections anti-bot dynamiques fondées sur l'IA et exigent une maintenance permanente.
Thunderbit est ma recommandation de prédilection pour quiconque souhaite s'affranchir de ces limites. Il réconcilie la puissance d'extraction et la simplicité d'usage.
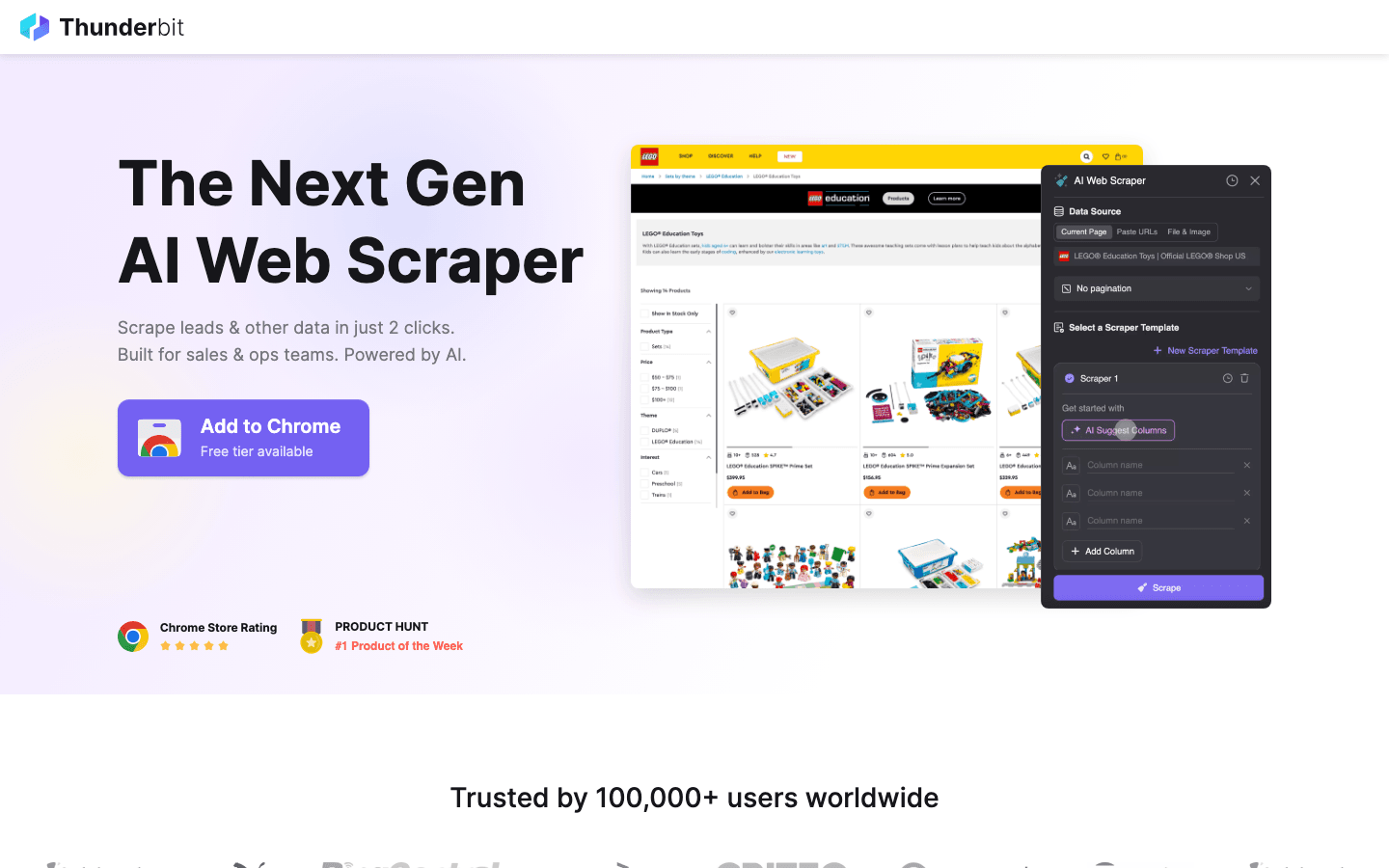
Pourquoi envisager Thunderbit plutôt que l'open source ?
- Aucun code requis : à la différence de Scrapy ou de Puppeteer, Thunderbit est une extension Chrome propulsée par l'IA. Un clic sur « AI Suggest Fields » et le scraper se construit tout seul.
- À l'aise sur les cas difficiles : contenu dynamique, défilement infini et pagination sont pris en charge automatiquement par l'IA, ce qui vous épargne des heures de scripts maison.
- Export instantané : passez d'un site web à Excel, Google Sheets ou Notion en deux clics.
- Zéro maintenance : inutile de retoucher votre code quand un site change de mise en page — l'IA de Thunderbit s'ajuste pour vous.
Commercial, marketeur ou chercheur, si vous voulez vos données sur-le-champ sans apprendre Python ou Go, Thunderbit complète idéalement les outils open source de cette liste.
Envie de le voir à l'œuvre ? Téléchargez l'extension Chrome et faites votre propre essai.
Essayez Thunderbit AI Web Scraper
Conclusion : trouver le bon crawler Web auto-hébergé pour 2026
Lire davantage de guides sur le scraping Web Get Started Free
Jamais l'univers des alternatives open source à Firecrawl n'a été aussi foisonnant. Que vous recherchiez la puissance brute de Scrapy ou de Nutch, ou la fidélité d'archivage d'Heritrix, chaque scénario métier trouve sa solution. Tout l'enjeu consiste à accorder l'outil à vos besoins réels : ne sortez pas l'artillerie lourde pour une simple extraction ponctuelle, et n'investissez pas a minima si vous devez crawler à l'échelle d'internet.
Et gardez ceci en tête : si l'option open source s'avère trop technique ou trop chronophage, des outils d'IA comme Thunderbit prennent volontiers le relais.
Pour passer à l'action, lancez Scrapy sur votre prochain grand projet data, ou essayez Thunderbit pour une extraction simple et pilotée par l'IA. Et si vous voulez creuser le sujet du scraping web, le blog Thunderbit regorge d'analyses approfondies et de tutoriels.
Essayez Thunderbit pour l’extraction Web propulsée par l’IA
FAQ
1. Quel est le principal avantage d'utiliser des alternatives open source à Firecrawl ?
Les alternatives open source offrent de la souplesse, des économies et la possibilité d'auto-héberger et de personnaliser votre crawler. Vous échappez à l'enfermement propriétaire et bénéficiez du support et des mises à jour d'une communauté active.
2. Quel outil est le meilleur pour les utilisateurs non techniques qui ont besoin de résultats rapides ?
HTTrack constitue un choix open source solide pour la navigation hors ligne. Pour l'extraction de données structurées (des tableaux Excel, par exemple), nous recommandons toutefois l'outil bonus Thunderbit, grâce à ses capacités d'IA.
3. Comment gérer les sites dynamiques, riches en JavaScript ?
Puppeteer est votre meilleur atout : il pilote un véritable navigateur et peut donc extraire tout ce qu'un utilisateur voit à l'écran, SPA et contenu chargé via AJAX compris.
4. Quand recourir à un crawler lourd comme Apache Nutch ou StormCrawler ?
Dès qu'il faut crawler des millions de pages sur de nombreux domaines, ou assurer un crawling distribué en temps réel (pour des moteurs de recherche ou de la veille d'actualité, par exemple), ces outils sont conçus pour l'échelle et la fiabilité.
5. Vaut-il mieux créer mon propre crawler ou utiliser une solution open source existante ?
Pour la plupart des équipes, adopter et personnaliser un outil open source existant revient à gagner en rapidité, en économies et en fiabilité. Ne développez le vôtre que si vos besoins sont hautement spécialisés et que vous avez les moyens de l'entretenir dans la durée.
Bon crawling — et que vos données soient toujours fraîches, structurées et prêtes à l'emploi.
Essayez gratuitement Thunderbit AI Web Scraper Get Started Free
En savoir plus
- Top 5 des meilleurs logiciels de scraping de données Web en 2026
- Top 15 des meilleurs crawlers Web IA à connaître en 2025
- Top 5 des meilleurs logiciels de scraping de données Web en 2026
- 7 outils de scraping Web parmi les plus populaires à utiliser en 2026
- Top 6 des outils essentiels de web scraper pour réussir en 2025




