En 2025, le web n’a jamais été aussi gourmand en data, et s’impose clairement comme la solution de choix pour toutes les équipes qui veulent faire de l’extraction de données de façon intelligente et efficace. Que tu bosses dans la vente, l’e-commerce ou que tu sois juste un mordu de data comme moi, tu as sûrement remarqué que le web scraping, ce n’est plus juste « choper des infos » : il faut aller vite, passer à l’échelle, et surtout éviter de se faire blacklister son IP. Avec un marché du web scraping qui va exploser de 7,48 milliards de dollars en 2025 à près de 38,4 milliards d’ici 2034 (), la compétition est plus féroce que jamais.
Mais voilà le souci : le web d’aujourd’hui, c’est une vraie forteresse de contenus dynamiques, de pièges anti-bots et de structures qui changent tout le temps. J’ai vu plus de scrapers se casser les dents qu’il n’en faut, souvent parce qu’ils zappaient les bonnes pratiques ou sous-estimaient la créativité des protections anti-scraping. On va donc plonger dans les meilleures astuces concrètes pour booster ton web scraping avec Node.js, avec quelques anecdotes, un brin d’humour et surtout des conseils qui marchent vraiment.
Pourquoi Node.js est le top pour le web scraping ?
Si tu as déjà essayé d’extraire des centaines (voire des milliers) de pages en même temps, tu sais que la rapidité et la gestion de la concurrence, c’est la base. Et là, Node.js est imbattable. Son modèle asynchrone et non bloquant est taillé pour gérer un max de requêtes réseau en simultané — imagine-le comme le roi du multitâche sur le web (). Là où d’autres langages attendent que chaque requête se termine, Node.js continue de faire tourner sa boucle d’événements, jonglant avec les requêtes comme un pro.
J’ai vu Node.js dépasser Python et Java dans des situations où il faut du temps réel ou extraire de gros volumes, surtout quand les sites sont blindés de JavaScript. D’ailleurs, utilisent Node.js pour le backend et l’automatisation, ce qui en fait la techno web la plus populaire du moment.
Node.js vs. les autres frameworks de web scraping
Petit tableau comparatif pour situer Node.js face à la concurrence :
| Framework | Points forts | Points faibles | Cas d'usage idéaux |
|---|---|---|---|
| Node.js | Asynchrone, super gestion de la concurrence, énorme écosystème npm, JS natif pour sites dynamiques | Peut bouffer pas mal de mémoire, callbacks galère (si tu n’utilises pas async/await) | Scraping en temps réel, sites JS lourds, microservices scalables |
| Python | Plein de libs (BeautifulSoup, Scrapy), syntaxe simple | Moins performant pour la grosse concurrence, galère avec les sites JS | HTML statique, recherche, prototypage |
| Java | Typage fort, costaud pour l’entreprise | Verbeux, pas top pour les scripts rapides | Scraping massif, usage entreprise |
| Go | Rapide, concurrence efficace | Écosystème plus limité, apprentissage | Scraping haute perf, faible latence |
Pour la plupart des pros, Node.js c’est le meilleur compromis : rapide, flexible et parfaitement adapté au web moderne dominé par JavaScript ().
Monter un environnement Node.js de scraping solide
Un bon extracteur web commence par une base bien rangée. Voilà ma config préférée :
- Structure du projet : Reste modulaire. Utilise des dossiers comme
/src,/libset/config. Mets les infos sensibles (clés API, proxies) dans des variables d’environnement avecdotenv(). - Client HTTP : Prends , , ou pour envoyer tes requêtes.
- Parsing HTML : pour le statique, ou Playwright pour le dynamique.
- Utilitaires : pour manipuler les données, ou pour valider.
- Tests & Linting : Mocha pour les tests, ESLint pour garder un code propre ().
Les bibliothèques Node.js à ne pas rater pour le scraping
- axios/got/node-fetch : Pour envoyer les requêtes HTTP. Perso, j’aime bien Axios pour son API en promesse et sa gestion du JSON.
- Cheerio : Parseur HTML ultra rapide, façon jQuery. Parfait pour les pages statiques — analyse en ~0,5s ().
- Puppeteer/Playwright : Automatisation de navigateur sans interface pour les sites dynamiques. Plus lent (~4s par page), mais indispensable pour le contenu chargé après le rendu ().
- dotenv : Pour gérer les variables d’environnement.
- csv-writer/jsonfile : Pour exporter tes données.
Les pièges classiques du web scraping avec Node.js
J’ai arrêté de compter les extracteurs web qui se font bloquer, planter ou qui sortent des données inutilisables. Les erreurs à éviter :
- Zapper robots.txt et les CGU : Toujours checker avant de scraper. Sinon, c’est ban d’IP ou pire, des soucis juridiques ().
- Surcharger les serveurs : N’inonde pas les sites de requêtes. Mets des délais aléatoires (1–3 secondes), limite la concurrence et évite de ressembler à un robot survolté ().
- Négliger la gestion des erreurs : Mets tes requêtes dans des try/catch, gère les erreurs HTTP et loggue les fails. Relance les erreurs temporaires avec un backoff exponentiel ().
- Oublier les headers : Utilise des User-Agent crédibles et fais-les tourner. Ajoute Accept-Language, Referer, etc. pour imiter un vrai navigateur ().
Passer les protections anti-scraping
Les sites modernes sont blindés de technos anti-bots. Mes astuces pour passer entre les gouttes :
- Rotation de proxies/IP : Utilise un pool de proxies et change d’IP régulièrement ().
- Headers aléatoires : Change User-Agent, Accept-Language, etc. à chaque requête.
- Navigation furtive : Utilise des plugins comme
puppeteer-extra-plugin-stealthpour masquer les traces d’automatisation. - Simuler un comportement humain : Ajoute des délais, des mouvements de souris, du scroll et même des fautes de frappe ().
Simuler l’humain dans tes extracteurs web Node.js
C’est là que ça devient fun (et un peu chelou). Plutôt que de cliquer et scroller à la vitesse de la lumière, programme ton extracteur web pour :
- Attendre des intervalles aléatoires entre les actions (
await page.waitForTimeout(randomDelay)) - Déplacer la souris par petits mouvements irréguliers (
page.mouse.move(x, y)) - Taper avec des délais et des fautes de frappe (
page.type(selector, text, {delay: random(100,200)})) - Scroller de façon non linéaire, pas juste jusqu’en bas
Ces techniques boostent tes chances de passer les sites protégés ().
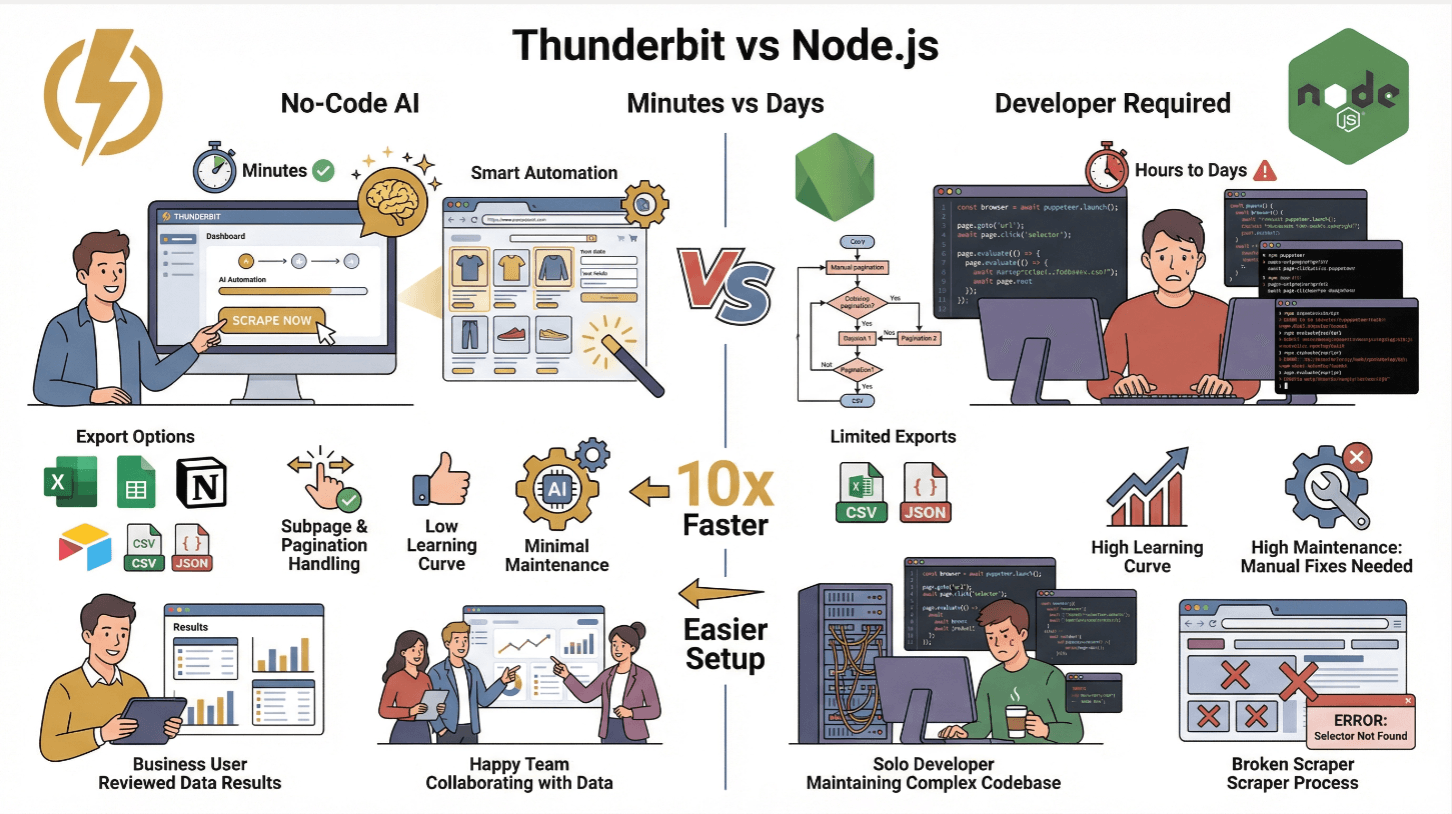
Simplifier l’extraction de données complexes avec Thunderbit
Soyons honnêtes : le scraping, c’est galère. Mais ça peut devenir simple. C’est pour ça qu’on a créé .
Thunderbit, c’est une extension Chrome d’extracteur web IA qui te permet d’extraire des données de n’importe quel site en langage naturel. Clique sur « Suggérer des champs IA », laisse l’IA analyser la page, puis lance l’extraction. C’est comme avoir un dev assistant qui ne dort jamais et ne râle jamais.
Encore mieux, Thunderbit propose une API pour s’intégrer direct à tes workflows Node.js. Plutôt que d’écrire des milliers de lignes de code, laisse Thunderbit gérer le contenu dynamique, les sous-pages, la pagination, etc. Tu récupères les données structurées (CSV, JSON, ou direct dans Google Sheets, Airtable, Notion) et tu peux passer à l’analyse ().
Thunderbit vs. scraping Node.js classique
| Fonctionnalité | Thunderbit | Scraper Node.js traditionnel |
|---|---|---|
| Temps de mise en place | Quelques minutes (sans code) | Plusieurs heures à jours (codage, tests) |
| Gestion du contenu dynamique | Oui (IA + navigateur) | Oui (avec Puppeteer/Playwright) |
| Sous-pages & pagination | 1 clic | Codage manuel nécessaire |
| Export des données | Excel, Sheets, Notion, Airtable, CSV, JSON | CSV/JSON (code personnalisé) |
| Courbe d’apprentissage | Faible (utilisateurs métier) | Élevée (développeurs) |
| Maintenance | Minime (l’IA s’adapte) | Élevée (corrections manuelles lors de changements de site) |
Thunderbit, c’est parfait pour les équipes non techniques ou ceux qui veulent se concentrer sur l’analyse plutôt que sur la technique. Les utilisateurs avancés peuvent aussi automatiser le scraping à grande échelle via l’API Thunderbit ().
Mixer Cheerio et Puppeteer pour le contenu dynamique
C’est mon combo gagnant pour le scraping Node.js. Voilà comment je fais :
- Utilise Puppeteer pour charger la page et exécuter le JavaScript (attends
networkidlepour être sûr que tout est chargé). - Récupère le HTML avec
await page.content(). - Parse avec Cheerio : passe le HTML à Cheerio pour une extraction rapide façon jQuery.
Cette approche hybride, c’est le meilleur des deux mondes : la puissance de Puppeteer pour le dynamique, la rapidité de Cheerio pour l’analyse ().
Astuce perf : Sélectionne seulement les éléments utiles. Cheerio charge tout le DOM en mémoire, donc évite les sélecteurs trop larges et mets en cache les résultats si tu scrapes souvent les mêmes pages ().
Optimiser le parsing HTML et l’extraction de données
- Utilise des sélecteurs précis : Oublie
$('body *')— cible juste ce qu’il te faut. - Traite les grosses pages en flux : Pour les pages lourdes, pense au streaming ou découpe le boulot.
- Mets en cache le HTML rendu : Si tu revisites des URLs, stocke le HTML pour éviter les requêtes inutiles.
- Valide et nettoie les données : Utilise des libs de validation pour garantir la qualité ().
Déployer un extracteur web Node.js scalable dans le cloud
Besoin de passer à la vitesse supérieure ? Direction le cloud.
- Dockerise ton scraper : Écris un
Dockerfile, copie ton code, installe les dépendances et définis le point d’entrée. - Déploie dans le cloud : Utilise AWS EC2, Google Cloud Compute ou Azure VMs pour les petits jobs. Pour du lourd, passe à Kubernetes ou des services managés comme AWS ECS/EKS, Google Cloud Run ou Azure Kubernetes Service ().
- Orchestre avec Kubernetes : Lance plusieurs pods, auto-scale selon la demande, et répartis les URLs avec des load balancers.
- Planifie les tâches : Utilise les planificateurs cloud (CloudWatch Events, Cloud Scheduler) ou des cron jobs pour automatiser les extractions.
Dans un cas concret, doubler le nombre de pods Kubernetes (de 5 à 10) a permis de passer le scraping de 400 pages de plusieurs minutes à moins d’une minute ().
Surveiller et auto-scaler ton infra de scraping
- Logs : Envoie les logs vers CloudWatch, Stackdriver ou Datadog. Mets des alertes en cas d’erreur ou de ralentissement.
- Vérifs de santé : Utilise Prometheus et Grafana pour suivre le nombre de pages extraites par minute, le taux d’erreur et la santé des pods.
- Auto-scaling : Configure l’HPA Kubernetes (Horizontal Pod Autoscaler) pour ajuster le nombre de pods selon la charge CPU ou le nombre de requêtes.
Pense toujours à mettre en place des relances avec backoff exponentiel pour gérer les coupures réseau ou les blocages temporaires.
Bonnes pratiques pour stocker et traiter les données extraites
Une fois les données extraites, il faut les stocker et les nettoyer :
- Petits volumes : Exporte en CSV, JSON, ou pousse vers Google Sheets, Airtable ou Notion (Thunderbit le fait direct).
- Gros volumes : Utilise SQL (MySQL/PostgreSQL) pour les données structurées, ou NoSQL (MongoDB, DynamoDB) pour des schémas qui bougent ().
- Stockage cloud : S3 ou Google Cloud Storage pour les fichiers bruts et les backups.
- Nettoyage des données : Valide toujours les champs, normalise les formats (dates, nombres), et vire les doublons. Utilise des validateurs de schéma pour garantir la qualité ().
Garde à la fois les données brutes et nettoyées — ça peut servir pour du retraitement ou du debug.
Conclusion : Les essentiels pour un web scraping Node.js efficace
En résumé :
- Profite de la puissance asynchrone de Node.js pour scraper à grande échelle, surtout sur les sites blindés de JS.
- Combine les bons outils : axios/got pour les requêtes, Cheerio pour le statique, Puppeteer pour le dynamique, et mixe-les pour plus de flexibilité.
- Déjoue les pièges anti-bots : Fais tourner proxies et headers, simule un comportement humain, respecte robots.txt.
- Simplifie avec Thunderbit : Pour les utilisateurs métier ou le prototypage rapide, permet d’extraire des données complexes grâce à l’IA et de les intégrer à tes workflows Node.js via API.
- Déploie à l’échelle : Dockerise, orchestre avec Kubernetes, et surveille tout pour garantir la fiabilité.
- Stocke et nettoie tes données : Choisis le bon stockage selon tes besoins, et valide toujours avant d’utiliser.
Le web ne va pas se simplifier, mais avec ces bonnes pratiques, tes extracteurs web Node.js resteront rapides, fiables et toujours un cran d’avance sur les protections anti-bots. Et si tu en as marre de déboguer tes sélecteurs à 2h du mat, rappelle-toi : l’IA de Thunderbit, elle, ne dort jamais.
Envie d’aller plus loin ? Va faire un tour sur le pour d’autres analyses, ou teste pour découvrir la simplicité du scraping nouvelle génération.
FAQ
1. Pourquoi Node.js est-il particulièrement adapté au web scraping en 2025 ?
Grâce à son modèle asynchrone et orienté événements, Node.js gère des milliers de requêtes en même temps, ce qui le rend parfait pour extraire de gros volumes ou des données en temps réel. Son écosystème npm et son support natif du JavaScript sont idéaux pour les sites modernes blindés de JS ().
2. Comment éviter d’être bloqué lors du scraping avec Node.js ?
Utilise des proxies rotatifs, varie les headers des requêtes, ralentis le rythme avec des délais aléatoires et simule un comportement humain (mouvements de souris, scroll, frappe) avec des outils comme Puppeteer. Respecte toujours robots.txt et les conditions d’utilisation ().
3. Quand utiliser Cheerio ou Puppeteer dans un extracteur web Node.js ?
Cheerio est top pour analyser vite du HTML statique (quand les données sont dans le code source). Utilise Puppeteer pour les sites qui chargent le contenu dynamiquement via JavaScript. Pour de meilleurs résultats, rends la page avec Puppeteer puis parse le HTML avec Cheerio ().
4. Comment Thunderbit simplifie-t-il le web scraping avec Node.js ?
Thunderbit permet d’extraire des données structurées de n’importe quel site grâce à l’IA et à des instructions en langage naturel — sans coder. Il gère le contenu dynamique, les sous-pages, la pagination, et propose une API pour l’intégration Node.js. Les données peuvent être exportées direct vers Excel, Google Sheets, Airtable ou Notion ().
5. Quelle est la meilleure façon de déployer et surveiller des extracteurs web Node.js dans le cloud ?
Dockerise ton extracteur web, déploie-le sur Kubernetes ou des services cloud managés, et active l’auto-scaling pour gérer les pics de charge. Surveille logs et métriques avec des outils comme CloudWatch ou Prometheus, et configure des alertes en cas d’erreur ou de ralentissement ().
Prêt à passer à la vitesse supérieure ? Teste Thunderbit, et que tes extracteurs web soient rapides, discrets et toujours en avance sur les protections.
Pour aller plus loin