
Chaque tutoriel sur fetch dans Node.js vous apprend à faire await fetch(url) et s’arrête là. Ensuite, en production, votre application avale silencieusement une erreur 500, une requête reste bloquée pendant 90 secondes sans délai d’attente, et vous passez votre vendredi soir à déboguer quelque chose qui aurait dû être évident.
Je construis depuis un moment des outils internes et des pipelines de données chez , et je peux vous le dire : l’écart entre « fetch fonctionne dans mon tutoriel » et « fetch fonctionne en production » est là où se concentrent l’essentiel des difficultés. Un développeur sur Reddit l’a très bien formulé : « quand vous passez en production, vous réalisez qu’il vous faut quelque chose de plus robuste que le fetch natif. »
Un autre a avoué : « J’ai travaillé 3 ans comme développeur web, et aujourd’hui j’ai appris que le bloc catch de l’API fetch n’est PAS destiné aux erreurs HTTP. » Ce guide couvre les cinq points que la plupart des tutoriels laissent de côté — le piège des erreurs, les délais d’attente avec AbortController, la logique de retry, la réutilisation des connexions, et le moment où il faut aller au-delà de fetch pour l’extraction de données structurées. Si vous avez déjà vu un appel fetch échouer silencieusement en production, ce guide est pour vous.
Qu’est-ce que l’API Fetch de Node.js ?
L’API Fetch de Node.js est le moyen intégré, compatible navigateur, d’effectuer des requêtes HTTP (GET, POST, PUT, DELETE, etc.) depuis Node.js — sans installer Axios, node-fetch, ni aucun autre package. Si vous avez déjà utilisé fetch() dans le navigateur, vous connaissez déjà la syntaxe. Désormais, la même API fonctionne côté serveur.
Voici le résumé de son évolution :
| Étape importante | Version de Node | Ce qui s’est passé |
|---|---|---|
| Drapeau expérimental fetch | v17.5.0 / v16.15.0 | fetch ajouté derrière --experimental-fetch |
| fetch global par défaut | v18.0.0 | fetch expérimental disponible globalement, propulsé par Undici |
| fetch stable | v21.0.0 | Plus expérimental |
| Base de production 2026 | v22 LTS / v24 LTS | Recommandé en production ; v20 est désormais EOL |
En coulisses, fetch de Node est alimenté par Undici — un client HTTP haute performance conçu spécifiquement pour Node.js. Il ne repose pas sur l’ancien module intégré http. L’avantage concret : vous obtenez une API HTTP moderne, basée sur les Promises, qui fonctionne de la même manière dans votre code navigateur, votre backend Express, votre fonction serverless et vos scripts CLI.
Pourquoi l’API Fetch de Node.js est importante pour vos projets
Avant Node 18, chaque nouveau projet commençait par le même rituel : npm install axios ou npm install node-fetch. En 2026, si votre projet tourne sur une version LTS maintenue de Node, les requêtes HTTP de base ne nécessitent aucune dépendance. C’est un vrai gain pour la taille du bundle, la sécurité de la chaîne d’approvisionnement, et l’onboarding (les développeurs front-end et back-end partagent enfin la même API).
Voici les cas où fetch natif brille :
| Scénario | Pourquoi fetch natif fonctionne bien | Point de vigilance en production |
|---|---|---|
| Backend Express/Fastify appelant des API REST | async/await familier, aucune dépendance | Ajoutez un timeout et des vérifications response.ok |
| Fonctions serverless (Lambda, Vercel, etc.) | Faible coût au démarrage, aucun package à installer | Gardez le timeout sous la durée maximale de la plateforme |
| Scripts CLI et automatisations | GET/POST simples sans configuration de projet | Ajoutez retry/backoff pour les API instables |
| Livraison ou transfert de webhooks | Méthodes et en-têtes HTTP standard | Ne relancez pas aveuglément les POST non idempotents |
| Rapports et tableaux de bord | Idéal pour récupérer du JSON depuis des API | Utilisez pagination et pooling de connexions pour les boucles |
| Communication entre microservices | Fonctionne pour des appels HTTP internes simples | Envisagez Got ou Undici directement pour retry, hooks ou HTTP/2 |
Pour les nouveaux projets Node 22+, fetch natif est le choix par défaut le plus sensé — sauf si vous savez que vous avez besoin de fonctionnalités qu’il ne fournit pas (intercepteurs, retry intégré, HTTP/2, etc.). Les chiffres de téléchargement npm racontent bien la transition en cours : , mais une grande partie provient d’héritage et de dépendances transitives. , , , et . La tendance est claire : fetch natif devient la nouvelle base, et les clients tiers servent à des besoins précis.
Fetch natif vs node-fetch vs Axios vs Got vs Ky : la matrice de décision 2026
La question la plus fréquente que je vois dans les forums de développeurs : « Quel client HTTP dois-je utiliser dans Node.js ? » Un utilisateur Reddit l’a résumée ainsi : « pourquoi importer une bibliothèque… quand le langage/le framework intègre déjà la fonctionnalité ? » Point juste — mais la réponse dépend de vos besoins.
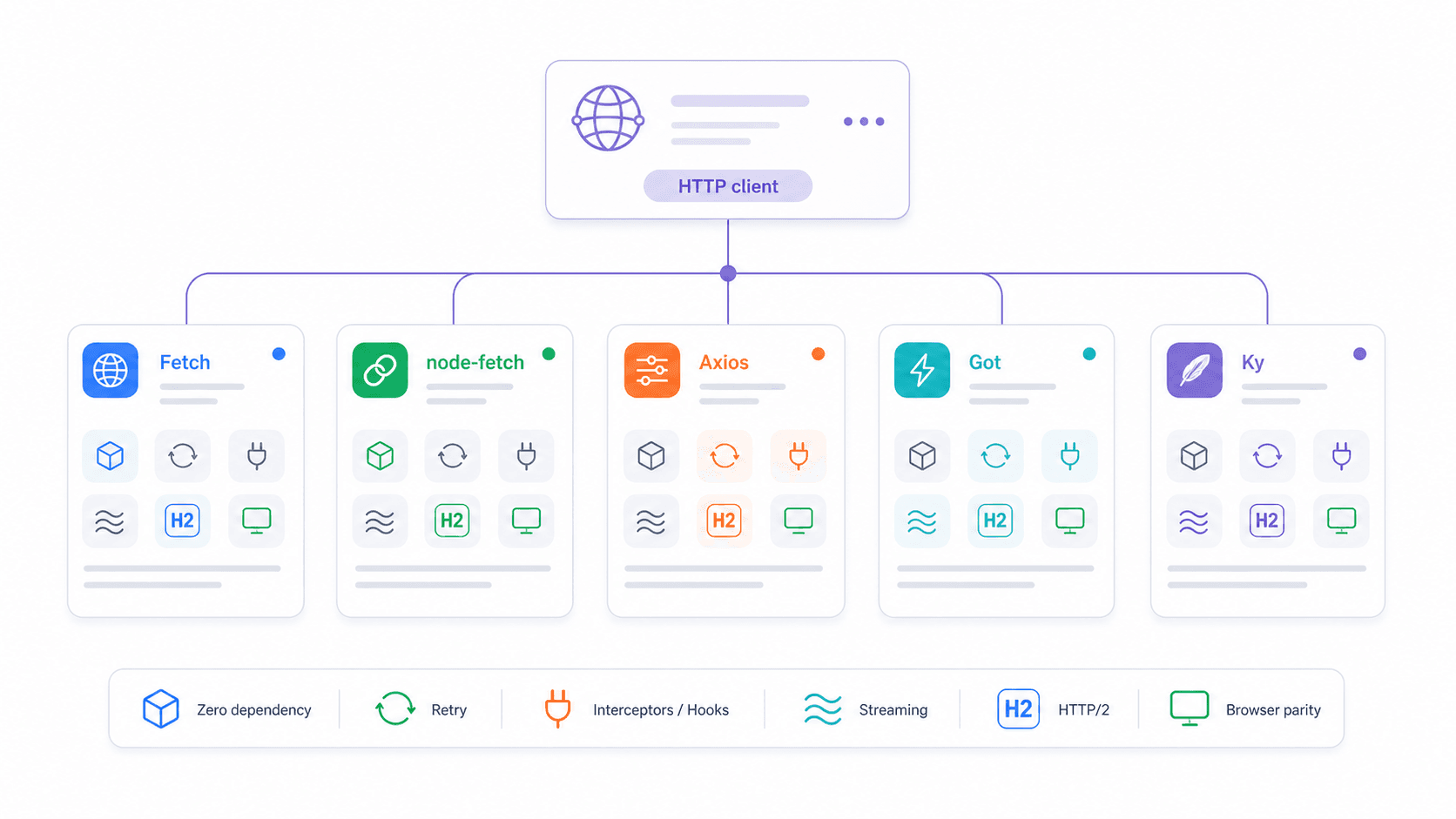
| Fonctionnalité | fetch natif | node-fetch v3 | axios | got v15 | ky v2 |
|---|---|---|---|---|---|
| Version de Node.js | ≥18 (recommandé 22/24 LTS) | ≥12.20 | Large | ≥22 | ≥22 |
| Installation requise | Non | Oui | Oui | Oui | Oui |
| Support ESM + CJS | Les deux (global) | ESM uniquement (v3) | Les deux | ESM uniquement | ESM uniquement |
| Rejet automatique sur 4xx/5xx | Non | Non | Oui | Oui | Oui |
| Retry intégré | Non | Non | Non | Oui | Oui |
| Intercepteurs de requêtes | Non | Non | Oui | Oui (hooks) | Oui (hooks) |
| Support du streaming | Web ReadableStream | Oui | Limité | Flux Node robustes | Basé sur fetch |
| Empreinte bundle/installation | 0 Ko | ~107 Ko, 3 dépendances | ~2,8 Mo, 4 dépendances | ~355 Ko, 12 dépendances | ~405 Ko, 0 dépendance |
| Support HTTP/2 | Via le dispatcher Undici | Non | Non | Oui | Non (wrapper fetch) |
Un mot rapide sur le casse-tête ESM/CJS : node-fetch v3 est ESM uniquement, ce qui a cassé beaucoup de projets utilisant require(). Fetch natif est global — il fonctionne dans les fichiers CJS comme ESM sans gymnastique d’import. Si vous êtes coincé sur node-fetch v2 à cause de CommonJS, fetch natif règle complètement le problème.
Et au sujet des inquiétudes initiales sur la stabilité : oui, il y a eu de vrais bugs dans l’implémentation initiale de fetch dans Node 18. Un développeur sur Reddit a dit : « J’ai récemment eu un bug sauvage avec le fetch natif de Node 18, donc j’ai dû convertir notre application. » C’était en 2023. En 2026, avec Node 22 et 24 LTS, ces problèmes sont résolus. Fetch natif est prêt pour la production.
Quand rester sur fetch natif
Optez pour fetch natif quand :
- Votre projet tourne sur Node 22 LTS ou Node 24 LTS.
- Les requêtes sont de simples appels REST (GET, POST, PUT, DELETE).
- Vous êtes prêt à ajouter un petit wrapper pour
response.ok, le parsing JSON, les timeouts et le retry. - Vous voulez zéro dépendance et moins de risques liés à la chaîne d’approvisionnement.
- Vous tenez à la parité entre API navigateur et API serveur.
- Vous êtes dans des environnements serverless ou edge où les API intégrées sont préférées.
Quand Axios, Got ou Ky sont plus pertinents
Axios est le bon choix lorsque votre équipe dépend d’intercepteurs de requête/réponse (par exemple, rafraîchissement automatique du token d’authentification, en-têtes multi-tenant, journalisation centralisée), lorsque vous souhaitez un rejet par défaut sur les erreurs HTTP, ou lorsque vous avez besoin d’une compatibilité avec d’anciennes versions de Node.
Got est conçu pour des services Node à fort débit qui ont besoin de retries intégrés, de hooks, de phases de timeout avancées, de streams, d’outils de pagination, de sockets Unix, de workflows proxy/cache ou du support HTTP/2. C’est le couteau suisse du travail HTTP côté Node.
Ky est le juste milieu si vous aimez la simplicité de fetch mais voulez moins de code répétitif — il ajoute retry, timeout, hooks et HTTPError dans un package minuscule et sans dépendances.
Comment faire des requêtes GET avec l’API Fetch de Node.js
Une requête GET avec async/await ressemble à ceci :
1const response = await fetch('https://jsonplaceholder.typicode.com/posts/1');
2const post = await response.json();
3console.log(post.title);
4// → "sunt aut facere repellat provident occaecati excepturi optio reprehenderit"Et si vous préférez la chaîne .then() :
1fetch('https://jsonplaceholder.typicode.com/posts/1')
2 .then(response => response.json())
3 .then(post => console.log(post.title))
4 .catch(error => console.error(error));Les deux fonctionnent. Mais aucun des deux n’est encore sûr pour la production (j’y reviens dans un instant).
Les parseurs de réponse à connaître :
| Méthode | À utiliser quand |
|---|---|
response.json() | Le serveur renvoie du JSON |
response.text() | Le serveur renvoie du HTML, du texte brut, du CSV ou du Markdown |
response.arrayBuffer() | Vous avez besoin de données binaires (images, fichiers) |
response.body | Vous avez besoin d’un traitement en streaming / par morceaux |
Voici un meilleur schéma — qui vérifie réellement les erreurs :
1async function getPost(id) {
2 const response = await fetch(`https://jsonplaceholder.typicode.com/posts/$\{id\}`);
3 if (!response.ok) {
4 throw new Error(`HTTP $\{response.status\} $\{response.statusText\}`);
5 }
6 return response.json();
7}
8const post = await getPost(1);
9console.log(post.title);Cette ligne if (!response.ok) fait toute la différence entre un tutoriel et du code de production. Ce qui nous amène au plus grand piège.
Comment envoyer des requêtes POST avec l’API Fetch de Node.js
Les requêtes POST suivent la même structure — il suffit de définir la méthode, les en-têtes et le corps :
1const response = await fetch('https://jsonplaceholder.typicode.com/posts', {
2 method: 'POST',
3 headers: {
4 'Content-Type': 'application/json',
5 },
6 body: JSON.stringify({
7 title: 'Guide de fetch dans Node',
8 body: 'Fetch en production a besoin de gestion d’erreurs.',
9 userId: 1,
10 }),
11});
12if (!response.ok) {
13 throw new Error(`HTTP $\{response.status\}`);
14}
15const created = await response.json();
16console.log(created.id); // → 101Envoyer d’autres types de requêtes (PUT, DELETE, PATCH)
PUT, PATCH et DELETE utilisent exactement la même structure avec une valeur method différente :
1// PUT — remplacement complet
2await fetch('https://jsonplaceholder.typicode.com/posts/1', {
3 method: 'PUT',
4 headers: { 'Content-Type': 'application/json' },
5 body: JSON.stringify({ id: 1, title: 'Remplacé', body: 'Remplacement complet', userId: 1 }),
6});
7// PATCH — mise à jour partielle
8await fetch('https://jsonplaceholder.typicode.com/posts/1', {
9 method: 'PATCH',
10 headers: { 'Content-Type': 'application/json' },
11 body: JSON.stringify({ title: 'Mise à jour partielle' }),
12});
13// DELETE
14await fetch('https://jsonplaceholder.typicode.com/posts/1', {
15 method: 'DELETE',
16});Le piège body-parser dans Express : si vous envoyez du JSON en POST vers un serveur Express et que req.body revient undefined, la solution est presque toujours celle-ci : utilisez express.json(), pas express.urlencoded(). Le serveur a besoin du middleware express.json() avant votre route pour analyser les corps Content-Type: application/json. C’est l’une des questions les plus fréquentes sur Express, et cela piège tout le monde à un moment ou à un autre.
1import express from 'express';
2const app = express();
3app.use(express.json()); // ← C’est celui qu’il vous faut pour les corps JSON en POST
4app.post('/api/posts', (req, res) => {
5 res.json({ received: req.body });
6});Le piège de fetch() qui casse les applications de production
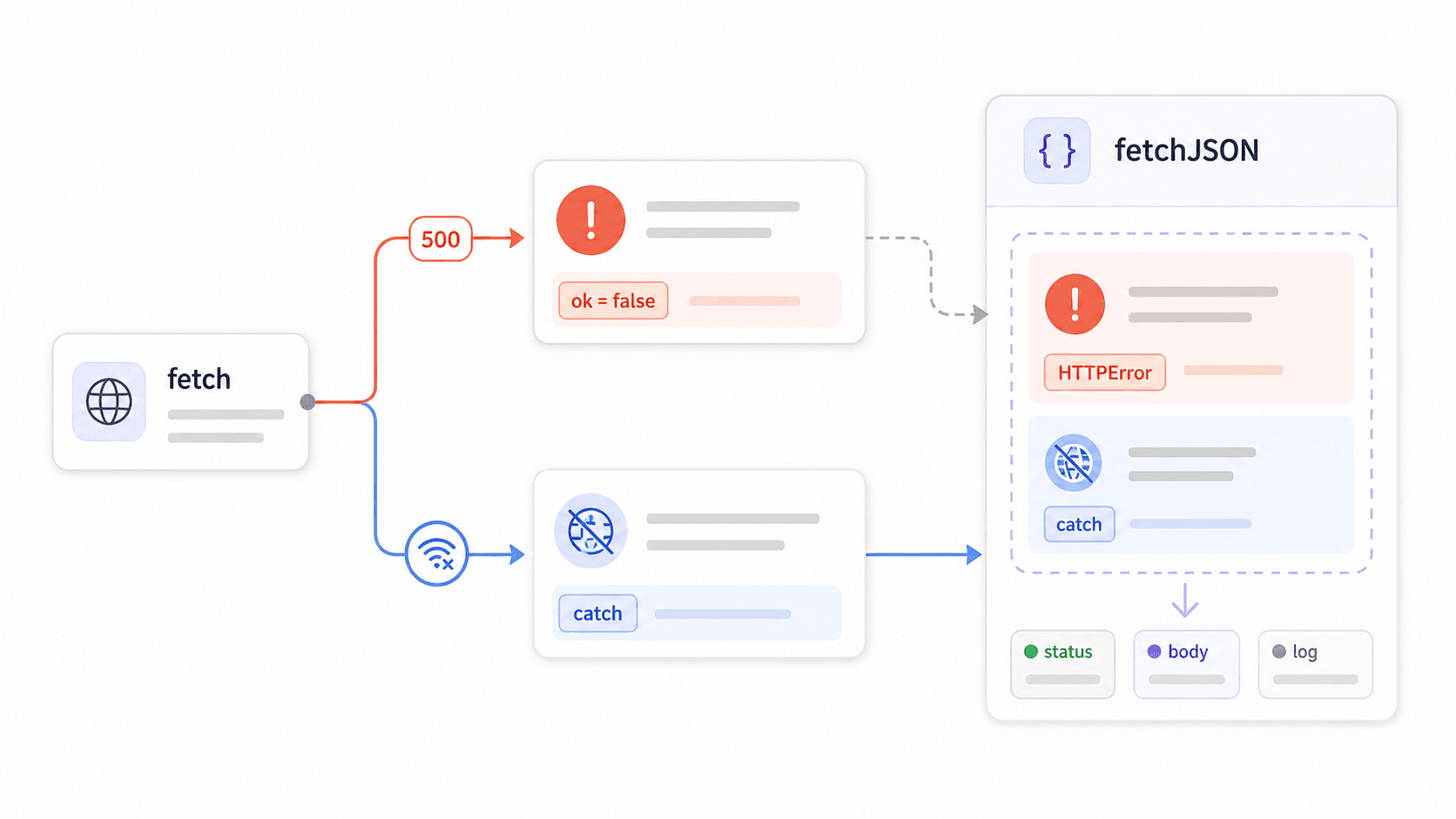
C’est ici que naissent la plupart des bugs de fetch en production.
fetch() ne rejette pas sa Promise sur les erreurs HTTP 4xx ou 5xx. Il ne rejette que sur les échecs au niveau réseau — erreurs DNS, absence d’internet, requêtes abandonnées. Si le serveur renvoie un 403 Forbidden ou un 500 Internal Server Error, fetch considère cela comme une réponse réussie. Votre bloc .catch() ne s’exécute jamais. Votre try/catch ne l’attrape jamais. Votre code traite gentiment tout ce que le serveur a renvoyé.
l’indique clairement, mais la plupart des tutoriels passent ce point sous silence. Résultat ? Un code comme celui-ci a l’air correct mais avale les erreurs sans rien dire :
1try {
2 const response = await fetch('https://api.example.com/private');
3 const data = await response.json(); // ← S’exécute même sur un 403
4 console.log('Apparemment réussi :', data);
5} catch (error) {
6 // Seuls les échecs réseau arrivent ici
7 console.error('Attrapé :', error);
8}Voici un résumé rapide de ce que chaque schéma attrape réellement :
| Schéma | Attrape les erreurs réseau | Attrape les 4xx/5xx | Parse le JSON en sécurité | Réutilisable |
|---|---|---|---|---|
Brut .then(res => res.json()) | Oui (via .catch()) | Non | Pas de garde sur le content-type | Non |
try/catch avec await fetch() | Oui | Non | Pas de garde sur le content-type | Non |
if (!res.ok) manuel à chaque appel | Oui | Oui | Dépend de chaque appel | Partiel |
Wrapper personnalisé fetchJSON() | Oui | Oui | Oui | Oui |
Construire un wrapper réutilisable fetchJSON()
Construisez un wrapper. Importez-le partout. Arrêtez de copier-coller if (!response.ok) dans chaque fichier :
1export class HTTPError extends Error {
2 constructor(message, { status, statusText, url, body }) {
3 super(message);
4 this.name = 'HTTPError';
5 this.status = status;
6 this.statusText = statusText;
7 this.url = url;
8 this.body = body;
9 }
10}
11export async function fetchJSON(url, options = {}) {
12 const response = await fetch(url, {
13 headers: {
14 Accept: 'application/json',
15 ...options.headers,
16 },
17 ...options,
18 });
19 const contentType = response.headers.get('content-type') || '';
20 const isJSON = contentType.includes('application/json');
21 const body = isJSON ? await response.json().catch(() => null) : await response.text();
22 if (!response.ok) {
23 throw new HTTPError(`HTTP $\{response.status\} $\{response.statusText\}`, {
24 status: response.status,
25 statusText: response.statusText,
26 url: response.url,
27 body,
28 });
29 }
30 return body;
31}Maintenant, quand le serveur renvoie un 403 :
1try {
2 const data = await fetchJSON('https://api.example.com/private');
3} catch (error) {
4 if (error instanceof HTTPError) {
5 console.error(`Le serveur a renvoyé $\{error.status\} :`, error.body);
6 } else {
7 console.error('Échec réseau ou autre :', error);
8 }
9}L’erreur contient le code de statut, le corps de la réponse et l’URL — tout ce qu’il vous faut pour la journalisation, les alertes ou les messages destinés aux utilisateurs. Importez cela une fois, utilisez-le partout.
AbortController et timeouts : le modèle de production pour l’API Fetch de Node.js
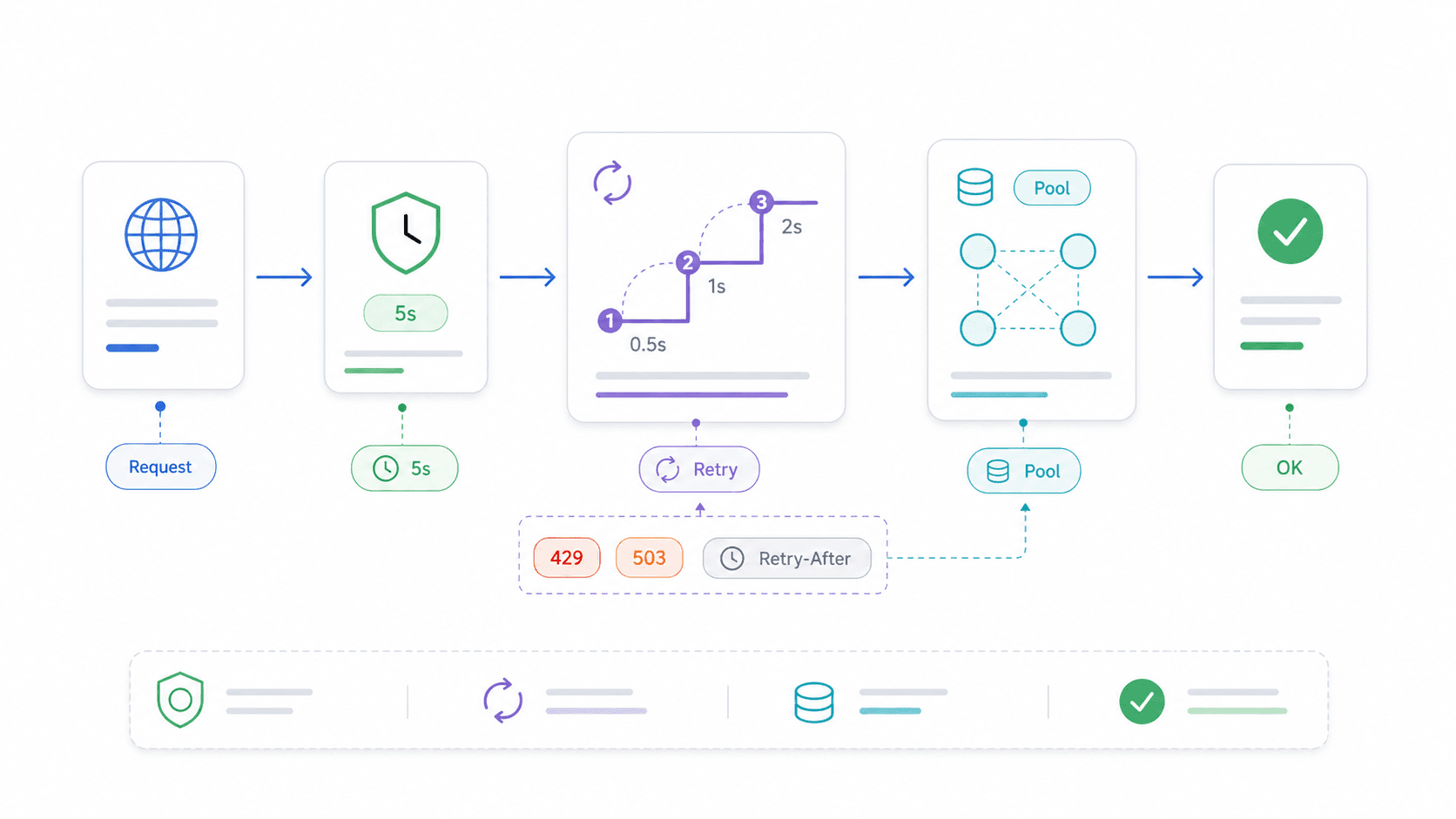
Sans timeout, un appel fetch reste bloqué indéfiniment quand le serveur distant ne répond plus. Votre route Express se bloque. Votre Lambda consomme tout son budget d’exécution. Votre script reste juste… là.
J’ai vérifié les meilleurs résultats de recherche : aucun tutoriel Node.js sur fetch ne couvre réellement l’annulation de requête ou les timeouts. Pourtant, les timeouts sont l’une des principales raisons pour lesquelles les développeurs restent sur Axios ou Got. Un fil Reddit est littéralement intitulé « Node fetch does not timeout ».
Utiliser AbortSignal.timeout() (Node 18.11+)
L’approche la plus simple — une option de plus :
1try {
2 const response = await fetch('https://api.example.com/data', {
3 signal: AbortSignal.timeout(5000), // 5 secondes
4 });
5 if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
6 const data = await response.json();
7 console.log(data);
8} catch (error) {
9 if (error.name === 'TimeoutError') {
10 console.error('La requête a expiré après 5 secondes.');
11 } else {
12 throw error;
13 }
14}Note : AbortSignal.timeout() lève une TimeoutError, et non une AbortError. C’est un détail que même certains développeurs expérimentés se trompent à propos.
Timeout manuel avec AbortController
Pour davantage de contrôle — ou si vous devez annuler une requête en fonction d’une action utilisateur, et pas seulement d’un minuteur :
1const controller = new AbortController();
2const timeout = setTimeout(() => controller.abort(), 5000);
3try {
4 const response = await fetch('https://api.example.com/data', {
5 signal: controller.signal,
6 });
7 const data = await response.json();
8 console.log(data);
9} catch (error) {
10 if (error.name === 'AbortError') {
11 console.error('La requête a été annulée manuellement.');
12 } else {
13 throw error;
14 }
15} finally {
16 clearTimeout(timeout);
17}Gérer AbortError vs TimeoutError
Cette distinction compte pour la journalisation et les messages côté utilisateur :
| Chemin d’annulation | Nom de l’erreur dans le bloc catch |
|---|---|
AbortSignal.timeout(ms) | TimeoutError |
controller.abort() | AbortError |
| Échec DNS/réseau | Typiquement TypeError: fetch failed |
Voici un cas concret — une route Express qui appelle une API externe et doit répondre en moins de 3 secondes :
1app.get('/dashboard', async (req, res, next) => {
2 try {
3 const data = await fetchJSON('https://api.example.com/report', {
4 signal: AbortSignal.timeout(3000),
5 });
6 res.json(data);
7 } catch (error) {
8 if (error.name === 'TimeoutError') {
9 res.status(504).json({ error: 'L’API amont a expiré' });
10 return;
11 }
12 next(error);
13 }
14});Sans ce schéma, une API amont lente bloquerait toute votre route jusqu’à ce que le client abandonne.
Logique de retry et réutilisation des connexions : rendre l’API Fetch de Node.js digne de la production
Fetch natif n’a pas de retry intégré. Une microcoupure réseau ou un 503 temporaire font simplement échouer la requête. Pour la plupart des opérations de lecture en production, ce n’est pas acceptable.
Un wrapper de retry composable avec backoff exponentiel
Le code est volontairement court — environ 10 lignes de logique réelle :
1const wait = ms => new Promise(resolve => setTimeout(resolve, ms));
2export async function fetchWithRetry(url, options = {}, retries = 2) {
3 for (let attempt = 0; ; attempt++) {
4 try {
5 const response = await fetch(url, options);
6 if (response.ok || ![408, 429, 500, 502, 503, 504].includes(response.status)) {
7 return response;
8 }
9 if (attempt >= retries) return response;
10 } catch (error) {
11 if (attempt >= retries) throw error;
12 }
13 await wait(250 * 2 ** attempt); // 250 ms, 500 ms, 1000 ms...
14 }
15}Quand relancer — et quand ne pas le faire
- À relancer : requêtes GET et HEAD idempotentes, statuts temporaires (408, 429, 500, 502, 503, 504), microcoupures réseau.
- À ne pas relancer : requêtes POST non idempotentes qui créent des enregistrements, débitent de l’argent ou déclenchent des effets de bord — sauf si vous utilisez des clés d’idempotence.
- Respectez
Retry-After: pour 429 (limite de débit) et 503 (service indisponible), vérifiez l’en-têteRetry-Afteravant de réduire le rythme.
Si vous préférez ne pas construire votre propre logique de retry, est un wrapper fetch léger qui ajoute retry, timeout, hooks et HTTPError prêt à l’emploi — sans dépendances.
Réutilisation des connexions avec l’Agent et le Pool d’Undici
Pour les boucles à haut débit — scraping de centaines de pages, appels API par lots, sondage d’un service — réutiliser les connexions TCP fait gagner un temps important. Chaque nouvelle connexion implique une nouvelle résolution DNS, un handshake TCP et, pour HTTPS, une négociation TLS.
Comme fetch de Node est propulsé par Undici, vous pouvez passer un dispatcher personnalisé :
1import { Agent } from 'undici';
2const agent = new Agent({
3 keepAliveTimeout: 10_000,
4 keepAliveMaxTimeout: 60_000,
5});
6const response = await fetch('https://api.example.com/data', {
7 dispatcher: agent,
8});Pour encore plus de contrôle avec une origine spécifique :
1import { Pool } from 'undici';
2const pool = new Pool('https://api.example.com', { connections: 10 });
3const response = await fetch('https://api.example.com/data', {
4 dispatcher: pool,
5});
6// Une fois terminé :
7await pool.close();Les montrent que la réutilisation des connexions et le pooling peuvent améliorer fortement le débit — undici - dispatch atteignait environ 22 234 requêtes/s contre environ 5 904 requêtes/s pour undici - fetch dans leur benchmark local. Les chiffres réels varieront, mais la tendance est claire : si vous envoyez beaucoup de requêtes vers la même origine, le pooling compte.
Autre point important : consommez ou annulez toujours les corps de réponse. Des corps non consommés peuvent provoquer des fuites de ressources dans les entrailles HTTP de Node.
Streaming de réponses avec l’API Fetch de Node.js
Téléchargements de gros fichiers, flux JSON découpés, événements envoyés par le serveur, sortie de LLM — dans ces cas, attendre la réponse complète avant de traiter fait perdre du temps et de la mémoire. Le streaming vous permet de traiter les données au fur et à mesure de leur arrivée.
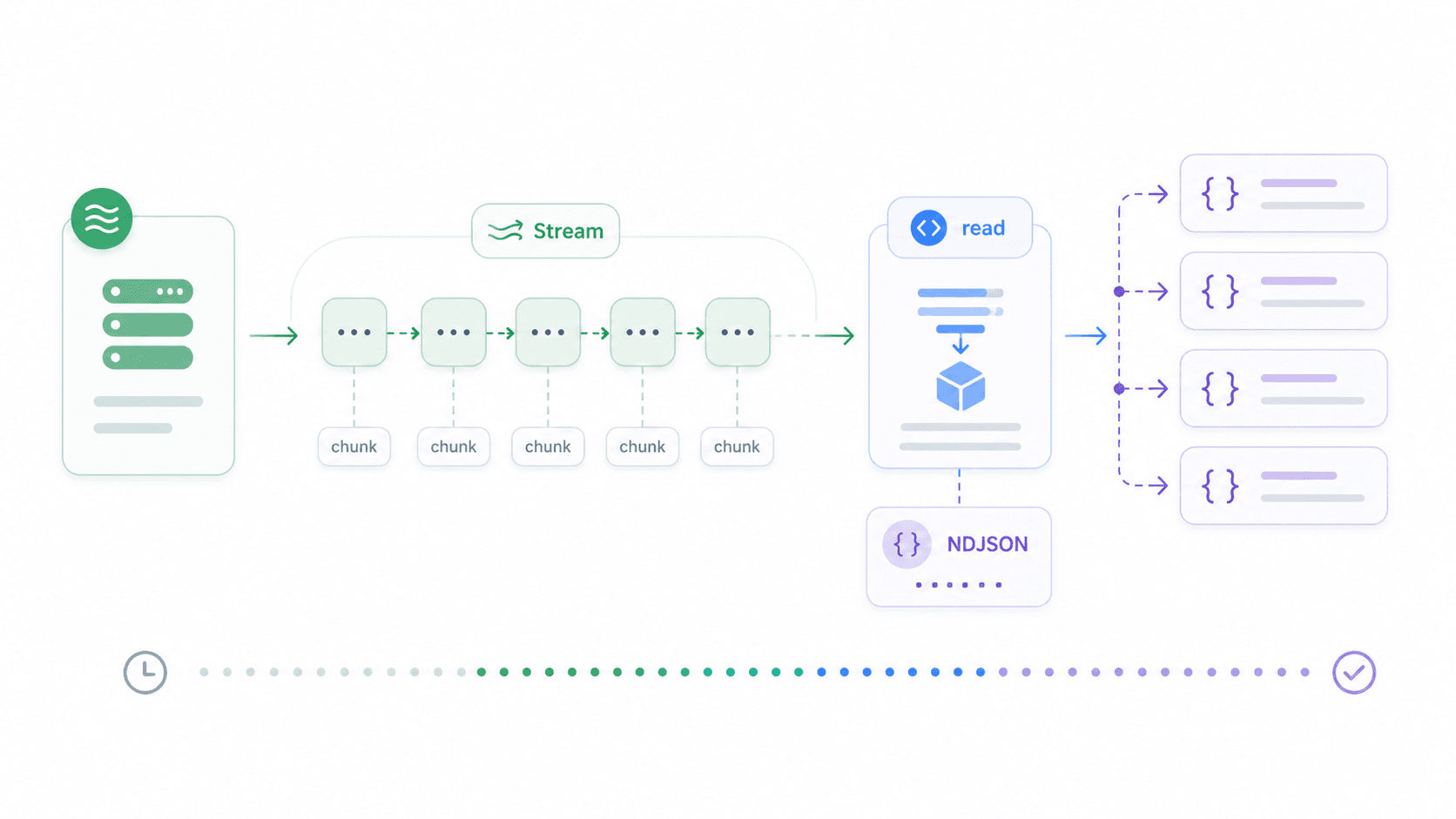
Node 18+ inclut ReadableStream, compatible navigateur. Voici comment streamer une réponse JSON délimitée par des retours à la ligne et traiter chaque ligne dès son arrivée :
1const response = await fetch('https://example.com/large-file.ndjson');
2if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
3const reader = response.body.getReader();
4const decoder = new TextDecoder();
5let buffer = '';
6while (true) {
7 const { value, done } = await reader.read();
8 if (done) break;
9 buffer += decoder.decode(value, { stream: true });
10 let newlineIndex;
11 while ((newlineIndex = buffer.indexOf('\n')) >= 0) {
12 const line = buffer.slice(0, newlineIndex).trim();
13 buffer = buffer.slice(newlineIndex + 1);
14 if (line) {
15 const item = JSON.parse(line);
16 console.log('Traité :', item.id);
17 }
18 }
19}Pour un streaming de texte plus simple (par exemple, rediriger la sortie d’un LLM vers stdout) :
1const response = await fetch('https://example.com/stream');
2const reader = response.body.getReader();
3const decoder = new TextDecoder();
4for (;;) {
5 const { value, done } = await reader.read();
6 if (done) break;
7 process.stdout.write(decoder.decode(value, { stream: true }));
8}Le streaming est un domaine où fetch natif et Got excellent tous les deux. Le support du streaming dans Axios est plus limité.
Quand fetch() atteint ses limites : l’extraction structurée de données web via API
À un moment donné, fetch n’est plus le goulot d’étranglement. Le vrai problème devient : « J’ai du HTML, et maintenant ? »
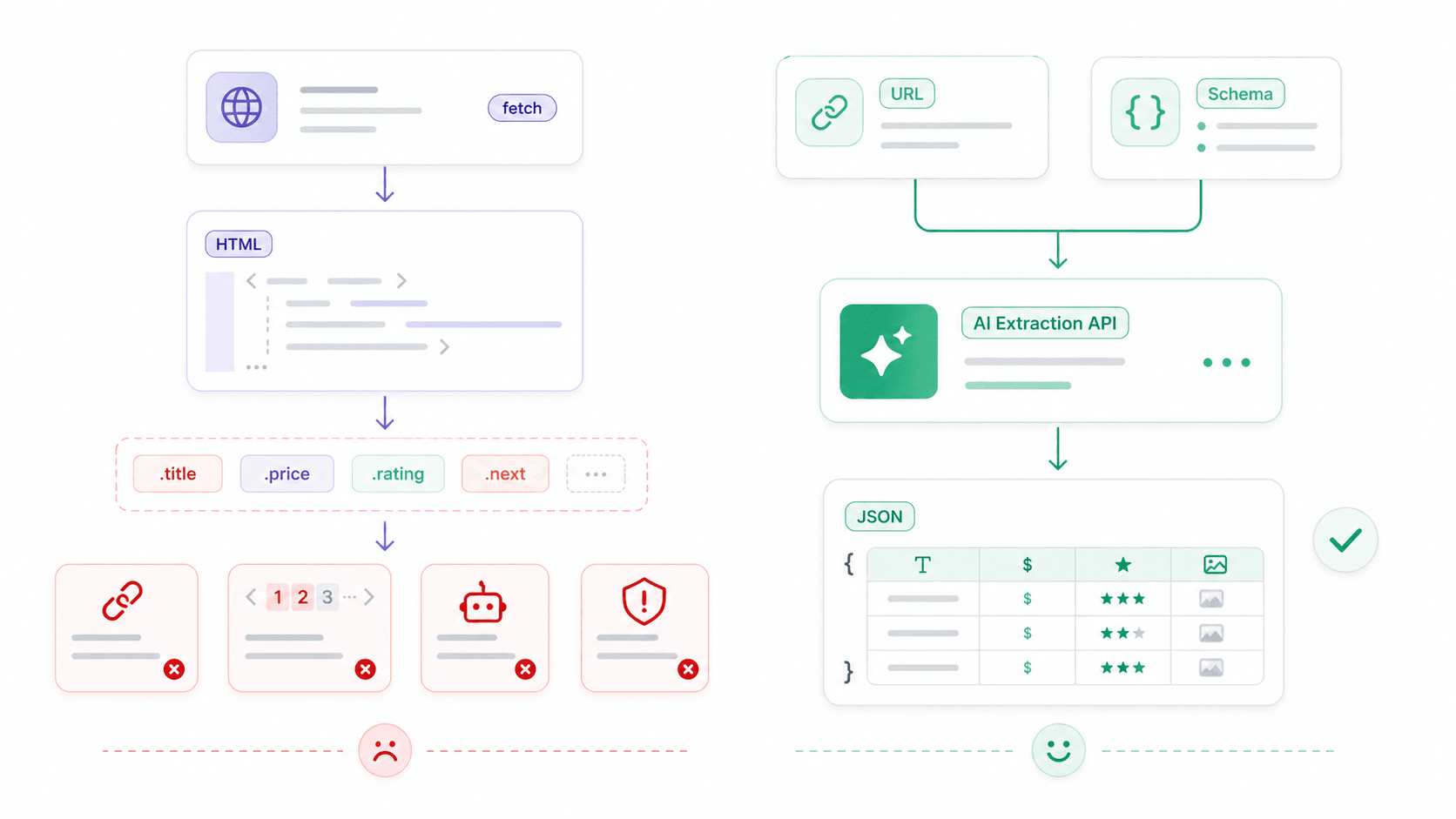
Fetch est un client HTTP — il récupère des octets, du texte, du JSON ou du HTML. Il n’a aucune notion de fiche produit, de prix, d’avis ou de tableau de contacts. Pour le web scraping structuré, la pile brute typique ressemble à ceci :
fetch()pour télécharger le HTML- Cheerio (ou équivalent) pour sélectionner les éléments avec des sélecteurs CSS
- Logique de pagination personnalisée
- Rendu JavaScript lorsque les pages sont côté client
- Gestion des proxy / anti-bot / CAPTCHA
- Maintenance des sélecteurs à chaque changement de mise en page du site
Voici un exemple classique fetch + Cheerio — une quinzaine de lignes pour extraire des titres de produits :
1import * as cheerio from 'cheerio';
2const response = await fetch('https://example-store.com/products');
3if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
4const html = await response.text();
5const $ = cheerio.load(html);
6const products = $('.product-card')
7 .map((_, el) => ({
8 name: $(el).find('.product-title').text().trim(),
9 price: $(el).find('.price').text().trim(),
10 url: new URL($(el).find('a').attr('href'), response.url).href,
11 }))
12 .get();
13console.log(products);Cela fonctionne pour des pages stables avec un HTML prévisible. Mais cela devient vite fragile — contenu rendu en JavaScript, noms de classes changeants, mesures anti-bot et pagination ajoutent tous de la complexité.
L’API ouverte de Thunderbit : du HTML brut aux données structurées en un seul appel
C’est là qu’un autre type d’outil devient utile. Chez , nous avons construit une couche API qui prend en charge les parties pénibles — rendu JavaScript, protection anti-bot, changements de mise en page — afin que vous puissiez vous concentrer sur les données que vous voulez vraiment.
Distill API (POST /distill) : convertit n’importe quelle URL en Markdown propre. Utile pour alimenter des LLM, construire des bases de connaissances ou faire de l’analyse de contenu — sans parseur HTML.
Extract API (POST /extract) : définissez un schéma JSON décrivant les données structurées que vous voulez (nom du produit, prix, note), et l’IA les extrait. Aucun sélecteur CSS, aucune casse quand la mise en page change.
Voici la même tâche d’extraction de produits avec l’Extract API de Thunderbit — appelée avec fetch natif :
1const response = await fetch('https://openapi.thunderbit.com/openapi/v1/extract', {
2 method: 'POST',
3 headers: {
4 Authorization: `Bearer $\{process.env.THUNDERBIT_API_KEY\}`,
5 'Content-Type': 'application/json',
6 },
7 body: JSON.stringify({
8 url: 'https://example-store.com/products',
9 renderMode: 'basic',
10 schema: {
11 type: 'object',
12 properties: {
13 products: {
14 type: 'array',
15 items: {
16 type: 'object',
17 properties: {
18 name: { type: 'string', description: 'Nom du produit' },
19 price: { type: 'string', description: 'Prix affiché du produit' },
20 rating: { type: 'number', description: 'Note moyenne des clients' },
21 },
22 required: ['name', 'price'],
23 },
24 },
25 },
26 required: ['products'],
27 },
28 }),
29});
30if (!response.ok) throw new Error(`Thunderbit API : $\{response.status\}`);
31const result = await response.json();
32console.log(result.data);La comparaison : environ 15 lignes de fetch + Cheerio (avec des sélecteurs fragiles) contre un seul appel API qui renvoie du JSON propre. Pour les traitements par lot, Thunderbit prend en charge jusqu’à 50 URL par appel d’extraction groupée et jusqu’à 100 URL par appel de distillation groupée.
Thunderbit ne remplace pas fetch — fetch est le transport. Thunderbit est la couche d’extraction à utiliser quand l’analyse du HTML brut devient le vrai problème. Si vous êtes curieux au sujet des tarifs, le vous offre 600 unités API pour expérimenter, et les offres payantes commencent à 6 $/mois. Vous pouvez aussi consulter l’ pour une extraction sans code directement dans votre navigateur.
Pour aller plus loin sur les approches d’extraction structurée, nos guides sur les , et détaillent des workflows précis.
Référence rapide : mémo de l’API Fetch de Node.js
Cette section mérite d’être mise en favori. Revenez-y quand vous aurez besoin d’un schéma à copier-coller.
| Schéma | Extrait |
|---|---|
| GET de base | const res = await fetch(url); const data = await res.json(); |
| POST de base | await fetch(url, { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(payload) }); |
| Vérification d’erreur HTTP | if (!res.ok) throw new Error(\HTTP ${res.status}`);` |
| Timeout (simple) | await fetch(url, { signal: AbortSignal.timeout(5000) }); |
| Annulation manuelle | const c = new AbortController(); setTimeout(() => c.abort(), 5000); await fetch(url, { signal: c.signal }); |
| Statuts à relancer | Relancez 408, 429, 500, 502, 503, 504. Ne relancez pas les POST à l’aveugle. |
| Wrapper JSON | Utilisez fetchJSON() pour vérifier ok, analyser le content-type et lever HTTPError. |
| Pool de connexions | import { Pool } from 'undici'; const pool = new Pool(origin, { connections: 10 }); fetch(url, { dispatcher: pool }); |
| Flux par morceaux | const reader = res.body.getReader(); bouclez sur await reader.read() |
| Extraction structurée | Utilisez l’Extract API de Thunderbit quand le but est d’obtenir des champs depuis une page web, pas du HTML brut. |
Conclusion et points clés à retenir
Fetch natif dans Node.js est prêt pour la production en 2026 — pas besoin de node-fetch pour les nouveaux projets, ni de dépendance Axios par défaut. Mais fetch() brut, à lui seul, ne constitue pas une stratégie HTTP de production.
Les cinq points que la plupart des tutoriels omettent — et que ce guide couvre :
- Le piège des erreurs :
fetch()ne lance pas d’exception sur les 4xx/5xx. Vérifiez toujoursresponse.okou utilisez un wrapper commefetchJSON(). - Les timeouts : utilisez
AbortSignal.timeout()pour les cas simples.AbortSignal.timeout()lèveTimeoutError;controller.abort()manuellement lèveAbortError. - La logique de retry : elle n’est pas intégrée. Ajoutez un backoff exponentiel pour les requêtes idempotentes et les échecs temporaires. Ou utilisez Ky pour un retry prêt à l’emploi, façon fetch.
- La réutilisation des connexions : pour les boucles à fort débit, utilisez
AgentouPoold’Undici via l’optiondispatcher. - L’extraction structurée : quand vous avez besoin de données depuis des pages web (et pas seulement du HTML brut), envisagez une API d’extraction comme Thunderbit au lieu de maintenir des sélecteurs CSS fragiles.
La matrice de décision en une phrase : utilisez fetch natif pour la plupart des projets, Axios pour les intercepteurs, Got pour le retry intégré et HTTP/2, Ky pour fetch avec de meilleurs réglages par défaut, et l’API de Thunderbit quand vos scripts de scraping basés sur fetch deviennent trop complexes à maintenir.
Essayez les schémas de ce guide. Et si vous voulez voir comment Thunderbit gère l’extraction structurée, le est un bon point de départ — ou regardez une démonstration sur la .
FAQ
1. Fetch est-il intégré à Node.js ou dois-je l’installer ?
Fetch est intégré à Node.js 18 et versions ultérieures — aucune installation requise. Il est devenu stable dans Node 21 et est pleinement pris en charge dans Node 22 LTS et Node 24 LTS. Pour les anciennes versions de Node, vous pouvez utiliser le package npm node-fetch, mais les nouveaux projets devraient viser une version LTS maintenue.
2. Fetch lève-t-il une erreur sur les réponses 404 ou 500 ?
Non. Fetch ne rejette sa Promise que pour les échecs au niveau réseau (erreurs DNS, absence de connexion, requêtes annulées). Les réponses HTTP comme 404, 403 et 500 se résolvent normalement avec response.ok === false. Vous devez vérifier explicitement response.ok ou response.status — ou utiliser un wrapper comme la fonction fetchJSON() présentée dans ce guide.
3. Comment ajouter un timeout à fetch dans Node.js ?
L’approche la plus simple est AbortSignal.timeout(ms), disponible à partir de Node 18.11+ : await fetch(url, { signal: AbortSignal.timeout(5000) }). Cela lève une TimeoutError si la requête dépasse 5 secondes. Pour plus de contrôle, créez manuellement un AbortController et appelez controller.abort() depuis un setTimeout. Attrapez AbortError pour le schéma manuel et TimeoutError pour AbortSignal.timeout().
4. Puis-je utiliser fetch pour le web scraping dans Node.js ?
Oui, mais fetch ne renvoie que du HTML brut. Vous aurez besoin d’un parseur comme Cheerio pour extraire des éléments précis, ainsi que d’une logique personnalisée pour la pagination, les pages rendues en JavaScript et les mesures anti-bot. Pour l’extraction de données structurées à grande échelle — lorsque vous voulez du JSON propre avec des noms de produits, des prix ou des coordonnées — envisagez , qui utilise l’IA pour renvoyer des données structurées sans sélecteurs CSS ni code dépendant de la mise en page.
5. Dois-je passer d’Axios à fetch natif en 2026 ?
Pour les nouveaux projets sur Node 22+, fetch natif est un excellent choix par défaut. Il n’a aucune dépendance, repose sur les Promises et partage la même API que fetch dans le navigateur. Conservez Axios si vous dépendez d’intercepteurs de requête/réponse, du rejet automatique des erreurs HTTP, ou d’une compatibilité avec d’anciennes versions de Node. Les deux sont des choix valides — tout dépend des fonctionnalités réellement utilisées par votre projet.
En savoir plus